RabbitMQ 从入门到精通:从工作模式到集群部署实战(一)
#作者:闫乾苓
文章目录
- RabbitMQ简介
- RabbitMQ与VMware的关系
- 架构
- 工作流程
- RabbitMQ 队列工作模式及适用场景
- 简单队列模式(Simple Queue)
- 工作队列模式(Work Queue)
- 发布/订阅模式(Publish/Subscribe)
- 路由模式(Routing)
- 主题模式(Topics)
- RPC模式(Remote Procedure Call)
- RabbitMQ Streams流工作模式及适用场景
- 多消费者共享消息模式
- 消息重放与时间点读取模式
- 安装部署
- 官方支持及版本选择
- RabbitMQ与Erlang的版本匹配
- 容器环境部署
- Docker部署单实例
- Kubernetes环境部署RabbitMQ集群
- 1.安装RabbitMQ Cluster Kubernetes Operator
- 2.通过Operator创建RabbitMQ 集群
- 3.RabbitMQ集群节点扩缩容
RabbitMQ简介
RabbitMQ 是一款可靠且成熟的消息传递和流式传输代理,可轻松部署在云环境、本地和本地计算机上。目前全球有数百万用户在使用。
它实现了高级消息队列协议(AMQP),并且支持多种消息协议(如MQTT、STOMP)广泛应用于分布式系统和微服务架构中,提供高性能、可靠的消息传递服务。其主要特点包括多协议支持、丰富的消息路由功能、消息持久化、高可用性、插件系统以及管理和监控功能等。
自 2007 年首次发布以来,RabbitMQ 一直是免费的开源软件,RabbitMQ 在 Apache 许可证 2.0 和 Mozilla 公共许可证 2 下获得双重许可。可以自由地使用和修改 RabbitMQ。
RabbitMQ与VMware的关系
收购历程
- 2009年,SpringSource收购了Rabbit Technologies Ltd.,这推动了RabbitMQ的发展。随后,SpringSource成为Pivotal(由EMC、VMware和GE联合成立的公司)的一部分,RabbitMQ也因此继续得到支持和发展。
- 2013年,RabbitMQ的主要开发者成立了RabbitMQ Inc.,这是一家专注于RabbitMQ商业支持和服务的独立公司。
- 2019年,VMware收购了Pivotal,RabbitMQ因此成为了VMware的一部分。
当前关系 - 作为VMware旗下的一部分,RabbitMQ继续得到VMware的支持和发展。RabbitMQ仍然是一个活跃的开源项目,定期发布新版本,添加新功能和改进。
- VMware为RabbitMQ提供了商业支持,并推动了其在企业中的应用和普及。
架构

- Broker:简单来说就是消息队列服务器实体。
- Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
- Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
- Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
- Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
- vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
- producer:消息生产者,就是投递消息的程序。
- consumer:消息消费者,就是接受消息的程序。
- channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务
工作流程
- 生产者发送消息:生产者通过RabbitMQ的客户端库创建消息,并指定交换机的名称和路由键。然后,生产者将消息发送到RabbitMQ服务器上的指定交换机。
- 交换机接收并路由消息:交换机接收到生产者的消息后,根据配置的路由规则和路由键将消息分发到相应的队列中。如果消息没有匹配到任何队列,则可能会被丢弃或返回给生产者。
- 消费者消费消息:消费者连接到RabbitMQ服务器,并监听指定的队列。当队列中有新消息时,消费者从队列中获取并处理消息。处理完成后,消费者可以选择发送确认消息给RabbitMQ服务器,以表示消息已被成功处理。
RabbitMQ 队列工作模式及适用场景
RabbitMQ 3.9.0 或更高版本适用
简单队列模式(Simple Queue)

- 特点:最简单的收发模式,只包含一个生产者和一个消费者。生产者将消息发送到队列中,消费者从队列中接收消息。
- 场景:适用于消息处理流程简单、不需要并发处理的场景。例如,一个OA系统中,用户通过接收手机验证码进行注册,验证码被放入消息队列,短信服务从队列中获取验证码并发送给用户。
工作队列模式(Work Queue)

- 特点:多个消费者可以监听同一个队列,但每个消息只能被一个消费者处理。RabbitMQ通过内部机制确保消息的唯一性,避免重复处理。此外,消息队列默认采用轮询的方式将消息平均发送给消费者。
- 场景:适用于分布式任务处理场景,多个消费者共享处理一组任务,从而提高系统的并发性能和吞吐量。例如,一个电商平台中,有多个订单服务,用户下单时,任意一个订单服务消费用户的下单请求生成订单即可。
- 动态负载均衡:RabbitMQ会根据消费者的处理能力动态分配消息。如果某个消费者处理速度较快,它会接收到更多的消息;如果某个消费者处理速度较慢或处于空闲状态,它会接收到较少的消息。
发布/订阅模式(Publish/Subscribe)

- 特点:相对于简单队列模式和工作队列模式,发布/订阅模式多了一个交换机(Exchange)。生产者先把消息发送到交换机,再由交换机把消息发送到绑定的队列中,每个绑定的队列都能收到由生产者发送的消息。
- 场景:适用于需要将消息广播给多个消费者的场景。例如,用户通知系统,当用户充值成功或转账完成时,系统通过短信、邮件等多种方式通知用户。
路由模式(Routing)

- 特点:在发布/订阅模式的基础上,增加了路由键(Routing Key)的概念。生产者发送消息时,需要指定一个路由键,交换机根据路由键将消息发送到匹配的队列中。
- 场景:适用于需要根据不同的路由键将消息发送到不同队列的场景。例如,一个日志系统可能需要根据日志级别(INFO、ERROR等)将日志发送到不同的队列中。
主题模式(Topics)
- 特点:主题模式是一种更灵活的路由模式,它允许使用通配符(如和#)来匹配路由键。例如,可以匹配一个单词,#可以匹配零个或多个单词。
- 场景:适用于需要根据复杂的路由规则将消息发送到不同队列的场景。例如,一个新闻系统可能需要根据新闻类别(如体育、娱乐等)和新闻来源(如新浪、腾讯等)将新闻发送到不同的队列中。
RPC模式(Remote Procedure Call)

- 特点:RPC模式允许一个客户端远程调用另一个服务的方法,就像调用本地方法一样。RabbitMQ提供了一个简单的RPC机制,使得客户端可以发送请求到队列中,服务器监听队列并处理请求,然后将结果发送回客户端。
- 场景:适用于需要远程调用服务的场景。例如,一个分布式系统中,一个服务需要调用另一个服务的方法来获取数据或执行操作。
以上是RabbitMQ的六种主要队列工作模式,每种模式都有其独特的特点和适用场景。根据实际需求选择合适的工作模式,可以提高系统的性能、可靠性和可扩展性。
RabbitMQ Streams流工作模式及适用场景
RabbitMQ中的Streams是一种持久复制数据结构,它提供了与传统队列不同的消息存储和消费方式。
多消费者共享消息模式

场景描述:
当需要将相同的消息传递给多个订阅者时,传统的RabbitMQ队列需要为每个消费者绑定一个专用队列,这在消费者数量较大时可能变得效率低下,特别是当需要持久性和/或复制时。而Streams允许任意数量的消费者以非破坏性的方式消费来自同一队列的相同消息,从而避免了绑定多个队列的需要。
特点:
- 消息持久化:Streams默认持久化队列和消息,确保消息不会因消费者消费而被删除。
- 非破坏性消费:消费者可以多次读取相同的消息,而不会导致消息从队列中删除。
- 负载均衡:Stream消费者可以从副本中读取数据,允许读取负载在集群中分布。
消息重放与时间点读取模式

场景描述:
传统的RabbitMQ队列具有破坏性消费行为,即当消费者用完消息时,消息将从队列中删除,因此不可能重新读取已消费的消息。而Streams允许消费者从日志中的任何点连接并从那里读取,这为实现消息重放和从特定时间点读取消息提供了可能。
特点:
- 消息重放:消费者可以从队列的开始或任意时间点开始读取消息,实现消息的重放功能。
- 时间点读取:通过指定时间戳或偏移量,消费者可以精确地读取队列中特定位置的消息。
- 高性能设计:Streams旨在以有效的方式存储大量数据,并将内存开销降至最低,同时提供与现有基于日志的消息传递系统竞争的吞吐量。
在实际应用中,RabbitMQ Streams的这两种模式并不是孤立的,而是可以根据具体需求灵活组合使用的。例如,在一个需要同时支持多消费者共享消息和消息重放的场景中,可以配置一个Streams队列,并允许任意数量的消费者以非破坏性的方式读取消息,同时根据需要实现消息的重放和从特定时间点读取消息的功能。
安装部署
官方支持及版本选择
本文档以v3.13.7版本进行说明

RabbitMQ与Erlang的版本匹配
RabbitMQ使用Erlang语言编写, Erlang是RabbitMQ的核心开发语言。Erlang作为一种函数式编程语言,具有并发性强、可靠性高等特点,非常适合用于开发高性能、高可靠性的消息中间件。
RabbitMQ的许多核心功能和特性都是基于Erlang的并发模型和可靠性机制实现的。因此,Erlang的运行环境对RabbitMQ的稳定性和性能具有重要影响。
安装RabbitMQ之前,可以访问RabbitMQ官网(https://www.rabbitmq.com/docs/which-erlang)查看所需的Erlang版本,并确保两者版本匹配,以发挥最佳性能。
下面是RabbitMQ 3.13.x 与Erlang的版本适配关系截图:

容器环境部署
操作系统版本:
BigCloud Enterprise Linux For Euler 21.10
(GNU/Linux 4.19.90-2107.6.0.0100.oe1.bclinux.x86_64 x86_64)
Docker环境的安装请自行查阅相关文档。
Docker版本信息:
root@k8s-master1:[/root]docker version
Client:Version: 20.10.14API version: 1.41Go version: go1.16.15Git commit: a224086Built: Thu Mar 24 01:45:09 2022OS/Arch: linux/amd64Context: defaultExperimental: trueServer: Docker Engine - CommunityEngine:Version: 20.10.14API version: 1.41 (minimum version 1.12)Go version: go1.16.15Git commit: 87a90dcBuilt: Thu Mar 24 01:49:54 2022OS/Arch: linux/amd64Experimental: truecontainerd:Version: v1.5.11GitCommit: 3df54a852345ae127d1fa3092b95168e4a88e2f8runc:Version: 1.0.3GitCommit: v1.0.3-0-gf46b6ba2docker-init:Version: 0.19.0GitCommit: de40ad0
Docker部署单实例
使用docker启动单机实例,一般用于学习测试,因其不具体高可用,不建议生产环境使用。
[root@k8s-master2 ~]# docker run -it -- rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.13.6-management
参数:
--it 启动一个交互式shell终端
--rm 容器停止后自动删除容器
--name 给定容器启动后的名字
-p 端口映射 [宿主机端口] :[容器内端口]
如果需要以daemon后台方式启动容器,请使用以下命令:
[root@k8s-master2 ~]# docker run -d --name rabbitmq2 -p 5673:5672 -p 15673:15672 rabbitmq:3.13.6-management
参数:
-d 容器以后台方式启动,不可以与—rm参数同时使用-p 将容器内的5672端口映射到宿主机5673端口,注意端口冲突。
容器启动后显示如下内容即为启动成功。
Time to start RabbitMQ: 9033 ms
另外可以通查看端口是正常监听,5672为RabbitMQ服务默认端口,15672是RabbitMQ管理界面的默认端口。
[root@k8s-master2 ~]# ss -ntlp |grep 5672
LISTEN 0 128 0.0.0.0:15672 0.0.0.0:* users:(("docker-proxy",pid=53310,fd=4))
LISTEN 0 128 0.0.0.0:5672 0.0.0.0:* users:(("docker-proxy",pid=53381,fd=4))
LISTEN 0 128 [::]:15672 [::]:* users:(("docker-proxy",pid=53317,fd=4))
LISTEN 0 128 [::]:5672 [::]:* users:(("docker-proxy",pid=53395,fd=4))
通过浏览器访问web UI 管理页面,默认账号和密码都为:guest

Kubernetes环境部署RabbitMQ集群
在Kubernetes(以下简称k8s)上部署RabbitMQ集群,官方文档使用Operator进行部署。
RabbitMQ 团队开发并维护两个kubernetes Operators
1.安装RabbitMQ Cluster Kubernetes Operator
功能说明
自动配置、管理和操作在 Kubernetes 上运行的 RabbitMQ 集群
源码:https://github.com/rabbitmq/cluster-operator
operator版本
v2.11.0
https://github.com/rabbitmq/cluster-operator/releases
operator适配的rabbitmq和k8s版本
默认使用 RabbitMQ 3.13.7
可适用于任何受支持的 RabbitMQ 版本和 Kubernetes 版本。官方建议使用Kubernetes 1.19 或更高版本(建议使用1.25 或更高版本,特别是对于使用RabbitMQ Streams的环境)
安装步骤
# 下载cluster-operator.yml
wget https://github.com/rabbitmq/cluster-operator/releases/latest/download/cluster-operator.yml# 将yaml文件apply到k8s集群
kubectl apply –f cluster-operator.yml
# 以下为k8s的输出信息,可以看到都创建了哪些资源
namespace/rabbitmq-system created
customresourcedefinition.apiextensions.k8s.io/rabbitmqclusters.rabbitmq.com created
serviceaccount/rabbitmq-cluster-operator created
role.rbac.authorization.k8s.io/rabbitmq-cluster-leader-election-role created
clusterrole.rbac.authorization.k8s.io/rabbitmq-cluster-operator-role created
clusterrole.rbac.authorization.k8s.io/rabbitmq-cluster-service-binding-role created
rolebinding.rbac.authorization.k8s.io/rabbitmq-cluster-leader-election-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/rabbitmq-cluster-operator-rolebinding created
deployment.apps/rabbitmq-cluster-operator created
安装 Cluster Operator 会创建大量 Kubernetes 资源
- 一个新的命名空间rabbitmq-system。
Cluster Operator 部署在此命名空间中创建,并在此名称空间中创建rabbitmq的控制器的相关资源,确保pod rabbitmq-cluster-operato-xxxx-xxxx 为running状态,可能会因网络原因pod的imags 不能下载导致pod启动失败,可视具体情况进行修复。
root@k8s-master1:[/root/rabbitmq]kubectl get all -n rabbitmq-system
NAME READY STATUS RESTARTS AGE
pod/rabbitmq-cluster-operator-5645454b96-mpt4h 1/1 Running 2 (51s ago) 52sNAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/rabbitmq-cluster-operator 1/1 1 1 52sNAME DESIRED CURRENT READY AGE
replicaset.apps/rabbitmq-cluster-operator-5645454b96 1 1 1 52s
- 新的自定义资源rabbitmqclusters.rabbitmq.com
自定义资源允许我们定义用于创建 RabbitMQ 集群的 API。
root@k8s-master1:[/root/rabbitmq]kubectl get customresourcedefinitions.apiextensions.k8s.io |grep rabbit
rabbitmqclusters.rabbitmq.com 2024-10-23T08:41:55Z
- 一些 RBAC 角色
Operator需要这些角色来创建、更新和删除 RabbitMQ 集群
2.通过Operator创建RabbitMQ 集群
通过以上步骤我们已经部署了 Operator,现在可以创建 RabbitMQ 集群了。
创建RabbitMQ 集群,通过编写k8s的yaml资源清单文件,可以参考官方示例:
https://github.com/rabbitmq/cluster-operator/tree/main/docs/examples
准备RabbitMQ 集群的yaml文件
下面即为参考官方示例编写的创建RabbitMQ 集群的yaml文件:
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:name: rabbitmq-cluster-01namespace: rabbitmq-cluster-01
spec:replicas: 3image: rabbitmq:3.12.16-managementresources:requests:cpu: 2000mmemory: 4Gilimits:cpu: 2000mmemory: 4Girabbitmq:additionalConfig: |cluster_partition_handling = pause_minoritydisk_free_limit.relative = 1.0collect_statistics_interval = 10000channel_max = 1050vm_memory_high_watermark_paging_ratio = 0.7total_memory_available_override_value = 4GBpersistence:storageClassName: nfsstorage: "20Gi"affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: app.kubernetes.io/nameoperator: Invalues:- rabbitmq-cluster-01podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: app.kubernetes.io/nameoperator: Invalues:- rabbitmq-cluster-01topologyKey: kubernetes.io/hostnameservice:type: NodePort
yaml资源清单文件详细解释
-
基本信息
apiVersion: 指定了所使用的 API 版本,这里是 rabbitmq.com/v1beta1。
kind: 表示资源类型,这里是 RabbitmqCluster,意味着这是一个 RabbitMQ 集群的定义。
metadata:
name: 集群的名称是 rabbitmq-cluster01。
namespace: 资源所在的命名空间是 rabbitmq-test。 -
集群规格
spec:
replicas: 集群中的副本数量,这里设置为 3,表示会运行 3 个 RabbitMQ 实例。
image: 使用的 RabbitMQ 镜像版本是 rabbitmq:3.13.7-management,包含管理插件。
在实际生产环境部署时,为避免因网络等因素导致镜像下载失败,可以提前下载好镜像,并上传到内网私有镜像仓库(harbor,nexus等),在此处将镜像改为从内网私有镜像仓库下载。 -
资源管理
resources:
requests: 资源请求,表示每个 Pod 至少需要 500m 的 CPU 和 1Gi 的内存。
limits: 资源限制,表示每个 Pod 最多可以使用 2000m 的 CPU 和 4Gi 的内存。
请根据业务并发或者长期监控,酌情调整此处的资源值。 -
RabbitMQ 配置
rabbitmq:
additionalConfig: 自定义 RabbitMQ 配置参数,后面将对一下参数进行详细描述。此处简要标出主要意思。
cluster_partition_handling = pause_minority: 当集群分区时,暂停少数节点。
disk_free_limit.relative = 1.0: 设置磁盘空间限制。
collect_statistics_interval = 10000: 统计收集间隔设置为 10 秒。
channel_max = 1050: 每个节点最多支持 1050 个通道。
vm_memory_high_watermark_paging_ratio = 0.7: 设置高水位标记。
total_memory_available_override_value = 4GB: 内存可用总量设置为 4GB。 -
持久化设置
persistence:
storageClassName: 指定存储类为的名字 nfs,用于持久化存储。需要注意的是,nfs的持久化存储需要事先部署完成,也可以是其他类型的后端持久化存储比如cephfs.后端相关。
storage: 为 RabbitMQ 指定了 20Gi 的存储空间。 -
调度策略
affinity: 亲和性设置,确保 Pod 在不同节点上调度。
podAntiAffinity: 指定 Pod 反亲和性规则,确保同一 RabbitMQ 集群的 Pod 不会在同一节点上运行,提升集群高可用性
另外如果想将rabbit的pod调度到指定的node节点,也就使用node节点亲和性并给某些node节点打labels实现。
podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: app.kubernetes.io/nameoperator: Invalues:- rabbitmq-cluster
- 服务配置
service:
type: 设置svc类型为NodePort,这样方便通过节点的 IP 地址和指定端口进行访问。比如通过浏览器访问RabbitMQ的web UI 管理界面。
此处经查看不支持设置固定的NodePort端口。

如果image为私有仓库,并且 需要账号密码身份验证,则需要按照以下步骤允许 Kubernetes 拉取映像
apiVersion: v1
kind: ServiceAccount
metadata:name: rabbitmq-cluster-operatornamespace: rabbitmq-systemkubectl -n rabbitmq-system create secret \
docker-registry rabbitmq-cluster-registry-access \
--docker-server=DOCKER-SERVER \
--docker-username=DOCKER-USERNAME \
--docker-password=DOCKER-PASSWORD
DOCKER-SERVER 私有仓库的URL。
DOCKER-USERNAME 私有仓库的用户名。
DOCKER-PASSWORD 是私有仓库的密码。
比如
kubectl -n rabbitmq-system create secret \
docker-registry rabbitmq-cluster-registry-access \
--docker-server=docker.io/my-registry \
--docker-username=my-username \
--docker-password=example-password1
将创建RabbitMQ集群的资源清单文件应用到k8s
root@k8s-master1:[/root/rabbitmq]kubectl apply -f rabbitmq-cluster.yaml
rabbitmqcluster.rabbitmq.com/rabbitmq-cluster01 configured
等待几分钟后,查看rabbitmq-test 名称空间中资源创建是符合预期,重点关注pod的数量和运行状态,是否调度到了不同的node节点。另外还有webUI的端口及nodeport随机映射端口,此处为15672映射为64650。

获取Management UI default-user账号和密码
# 查看default-user的secrets 名称
root@k8s-master1:[/root]kubectl get secrets -n rabbitmq-test
NAME TYPE DATA AGE
default-token-rc7gm kubernetes.io/service-account-token 3 162m
rabbitmq-cluster01-default-user Opaque 7 157m
rabbitmq-cluster01-erlang-cookie Opaque 1 157m
rabbitmq-cluster01-server-token-w7k9f kubernetes.io/service-account-token 3 162m# 通过secrets 获取账号和密码
root@k8s-master1:[/root]username="$(kubectl get secrets rabbitmq-cluster01-default-user -n rabbitmq-test -o jsonpath='{.data.username}' | base64 --decode)"
root@k8s-master1:[/root]echo $username
default_user_iZYCpOBVHIirdDvfzGTroot@k8s-master1:[/root]password="$(kubectl get secrets rabbitmq-cluster01-default-user -n rabbitmq-test -o jsonpath='{.data.password}' | base64 --decode)"
root@k8s-master1:[/root]echo $password
zrGIIoeH0q1d9N8r1yhABG-OcmNzdKoc
通过浏览器访问Management UI
http://192.168.123.240:64650 输入上面步骤获取的账号和密码登录。

登录后查看集群状态正常,可以进行后续其他操作。

RabbitMQ集群参数优化
集群的参数优化,RabbitMQ operator 提供了在创建集群时在YAML文件中增加相关的配置的参数的方式对集群参数进行优化,如下图

集群创建后,会在RabbitMQ 集群节点pod中存放到以下文件中:
/etc/rabbitmq/conf.d/90-userDefinedConfiguration.conf


如果是集群刚创建成功,还没有创建exchang,queue时,对YAML文件中相关参数进行修改并提交k8s,集群会触发滚动更新,从数值编号大的pod开始重启并加载修改的参数值。如果集群中已经有数据了,则不会执行滚动更新。

设置环境变量
RabbitMQ 使用的所有环境变量都使用前缀RABBITMQ_(除了在rabbitmq-env.conf或 rabbitmq-env-conf.bat中定义的)
RabbitMQ使用rabbitmq-env.conf覆盖 RabbitMQ 脚本和 CLI 工具中内置的默认值,spec.rabbitmq.envConfig的值将写入/etc/rabbitmq/rabbitmq-env.conf
比如:RABBITMQ_DISTRIBUTION_BUFFER_SIZE用于节点间通信连接的传出数据缓冲区大小限制(以千字节为单位)。不建议使用低于 64 MB 的值。默认值:128M
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:name: rabbitmqcluster-sample
spec:rabbitmq:envConfig: |RABBITMQ_DISTRIBUTION_BUFFER_SIZE=256000
其他变量可以参考官方文档:
https://www.rabbitmq.com/docs/3.13/configure#supported-environment-variables
附加启动更多插件
RabbitMQ Cluster Kubernetes Operator默认情况下
已启用rabbitmq_peer_discovery_k8s、rabbitmq_prometheus、rabbitmq_management
如需启用更多插件,比如增加联邦,铲子的插件,请进行如下配置:
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:name: rabbitmqcluster-sample
spec:rabbitmq:additionalPlugins:- rabbitmq_federation- rabbitmq_federation_management- rabbitmq_shovel- rabbitmq_shovel_management
如果需要配置社区插件,则应将其包含在自定义镜像中或在节点启动时下载
RabbitMQ 高级配置
将写入/etc/rabbitmq/advanced.config文件的高级配置。
比如:配置 RabbitMQ 的预写日志 (WAL) 的存储路径。
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:name: rabbitmqcluster-sample
spec:rabbitmq:advancedConfig: |[{ra, [{wal_data_dir, '/var/lib/rabbitmq/quorum-wal'}]}].
更多高级配置请参考官方文档:https://www.rabbitmq.com/docs/3.13/configure#advanced-config-file
3.RabbitMQ集群节点扩缩容
RabbitMQ官方建议集群节点为大于等于3的奇数个,比如3, 5, 7… ,原因为rabbitmq中的个高可用方案中,使用了镜像队列或者仲裁队列,为避免集群有节点故障是产生脑裂(leader选举过半机制)和集群资源利用最大化(3节点和4节点集群在1个节点故障时高可用性是一样的),关于镜像队列和仲裁队列的详细信息,后面章节将会详细描述。
在k8s环境部署的RabbitMQ集群扩缩容比较简单,只需修改创建RabbitMQ集群时的资源清单文件中的metadata.spec.replicas 的值即可,比如从3个节点改为5个节点。
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:name: rabbitmq-cluster01namespace: rabbitmq-test
spec:replicas: 5
修改完成后,将yaml文件重新apply到k8s集群,RabbitMQ operater会自动完成集群节点的增减操作。
root@k8s-master1:[/root/rabbitmq]kubectl apply -f rabbitmq-cluster.yaml
rabbitmqcluster.rabbitmq.com/rabbitmq-cluster01 configured


RabbitMQ Operator 暂不支持集群缩容
RabbitMQ 官方 Operator 的设计主要是为了简化集群管理和操作。在这种设计中,集群节点的扩容和缩容操作受到一定限制,原因如下:
- 数据一致性:RabbitMQ 集群通过共享状态和队列实现数据一致性。减少节点数量可能导致数据迁移和分配问题,从而影响系统的稳定性和数据完整性。
- 高可用性:在高可用模式下,RabbitMQ 通过复制队列来确保数据的可靠性。如果减少节点,可能会影响到已有的复制策略,导致高可用性受到威胁。
- 操作复杂性:缩容操作通常涉及复杂的数据迁移和状态更新,这可能会增加系统出错的风险。相较之下,扩容操作相对简单,系统能自动处理新节点的加入。
- 集群配置管理:RabbitMQ 官方 Operator 旨在提供一致的集群管理体验,缩容操作的复杂性使得其难以在 Operator 的逻辑中实现自动化管理。
因此,虽然技术上可以实现缩容操作,但为了维护系统的稳定性和数据安全性,RabbitMQ 官方 Operator 选择限制该功能,只支持扩容。
将修改YAML文件中的metadata.spec.replicas 的值由7改为5并提交k8s执行时,可以从RabbitMQ operater pod的日志中查询相关限制缩容的相关信息。



安装RabbitMQ Messaging Topology Operator
Messaging Topology Operator可以管理通过 RabbitMQ Cluster Kubernetes Operator 部署的 RabbitMQ 集群内对象(统称为消息传递拓扑),它允许通过声明式的Kubernetes API来创建和管理部署在RabbitMQ集群中的消息拓扑。如:vhost、exchange、queue等。
源码:https://github.com/rabbitmq/messaging-topology-operator
核心功能
- 创建和管理RabbitMQ消息拓扑:
该操作器可以创建和管理RabbitMQ集群中的消息拓扑,包括交换机(exchanges)、队列(queues)、绑定(bindings)和策略(policies)。通过这些组件,开发者可以构建特定的消息传递或流处理场景。 - 与RabbitMQ Cluster Operator协同工作:
RabbitMQ Messaging Topology Operator与RabbitMQ Cluster Kubernetes Operator紧密协作。
RabbitMQ Cluster Operator用于管理和部署RabbitMQ集群,而Messaging Topology Operator则在此基础上进一步管理消息拓扑。
安装要求:
- Kubernetes 1.19 或更高版本
- RabbitMQ Cluster Operator 1.7.0+
安装 Operator 有两种方式:
- 使用 cert-manager 安装
- 安装生成的证书
相关文章:
RabbitMQ 从入门到精通:从工作模式到集群部署实战(一)
#作者:闫乾苓 文章目录 RabbitMQ简介RabbitMQ与VMware的关系架构工作流程RabbitMQ 队列工作模式及适用场景简单队列模式(Simple Queue)工作队列模式(Work Queue)发布/订阅模式(Publish/Subscribeÿ…...

计算机网络笔记再战——理解几个经典的协议4
目录 IP——网际协议 IP地址 1. A类地址 2. B类地址 3. C类地址 4. D类地址(组播地址) 5. E类地址(保留地址) 特殊地址与私有地址 广播地址 IP多播 子网掩码 传统分类与CIDR/VLSM的对比 路由控制 默认路由 主机路由…...
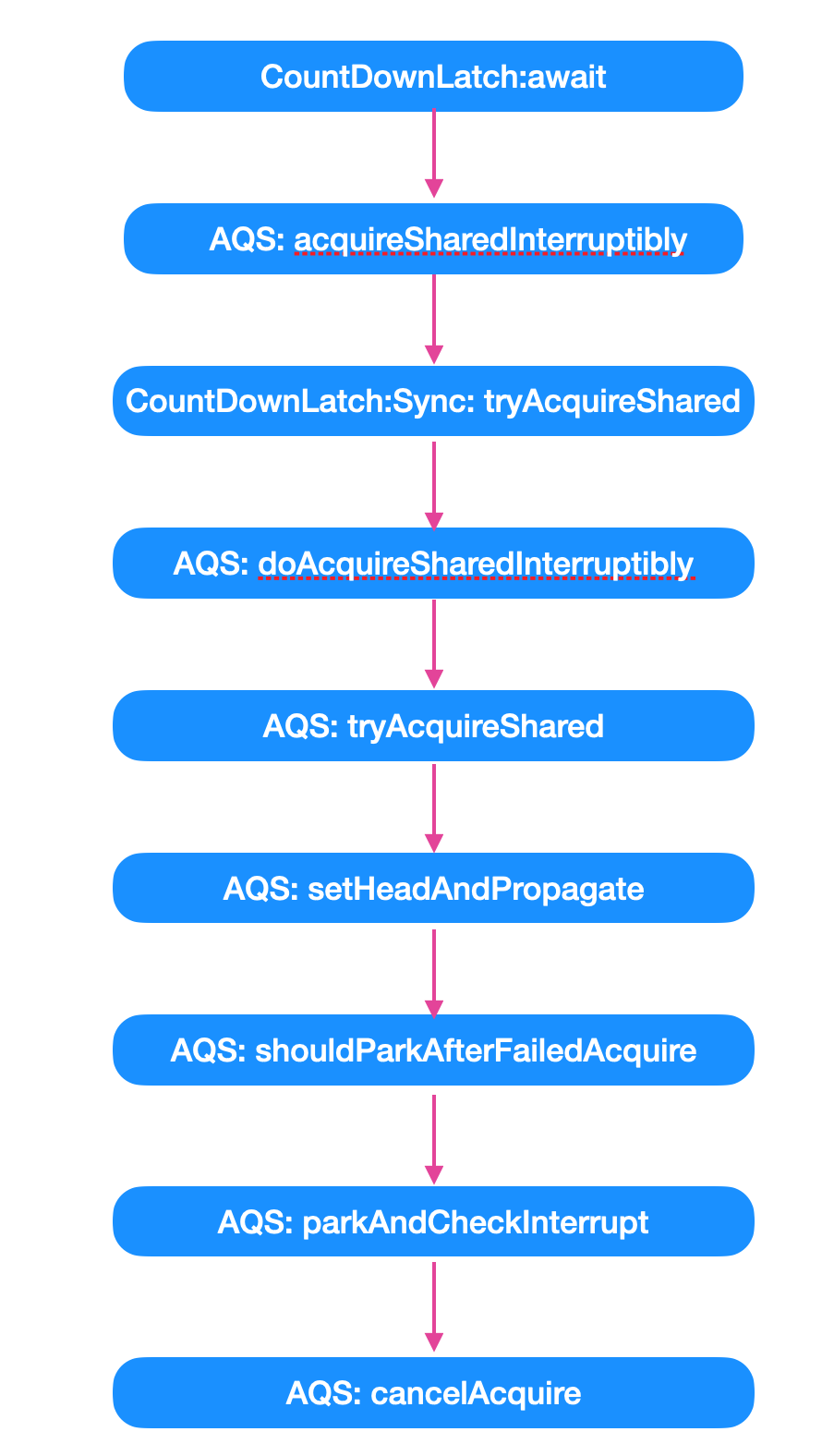
Java CountDownLatch 用法和源码解析
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

深度学习在文本情感分析中的应用
引言 情感分析是自然语言处理(NLP)中的一个重要任务,旨在识别和提取文本中的主观信息。随着深度学习技术的发展,我们可以使用深度学习模型来提高情感分析的准确性和效率。本文将介绍如何使用深度学习进行文本情感分析,…...
关于C++标准库STL在使用中的一些规范和建议)
C++编码规范(六)关于C++标准库STL在使用中的一些规范和建议
C 标准库STL是 C 编程语言的重要组成部分,为开发者提供了丰富的功能和工具,极大地提高了开发效率和代码的可移植性。 其主要包括:标准容器库,输入 / 输出流库,算法库,迭代器库,字符串库…...

两种文件类型(pdf/图片)打印A4半张纸方法
环境:windows10、Adobe Reader XI v11.0.23 Pdf: 1.把内容由横排变为纵排: 2.点击打印按钮: 3.选择打印页范围和多页: 4.内容打印在纸张上部 图片: 1.右键图片点击打印: 2.选择打印类型: 3.打印配置&am…...

Vue3状态管理: Pinia使用技巧与最佳实践
Vue3状态管理: Pinia使用技巧与最佳实践 随着Web应用复杂度的提升,前端状态管理变得愈发重要。而在Vue3中,Pinia作为一种全新的状态管理工具,为我们提供了更加灵活和强大的状态管理解决方案。本文将从Pinia的基本概念入手,深入探讨…...

stm32点灯 GPIO的输出模式
目录 1.选择RCC时钟 2.SYS 选择调试模式 SW 3.GPIO 配置 4.时钟树配置( 默认不变)HSI 高速内部时钟8Mhz 5.项目配置 6.代码 延时1s循环LED亮灭 1.选择RCC时钟 2.SYS 选择调试模式 SW 3.GPIO 配置 4.时钟树配置( 默认不变)…...

K8S运行时切换-从Docker到Containerd的切换实战
1. 切换的原因 性能提升:Containerd通过减少抽象层提升了整体性能。 安全性增强:它提供了更直接的系统调用,减少了潜在的安全风险。 简化架构:Containerd拥有更简洁的设计,使得维护和故障排除更为容易。 官方支持趋…...

腾讯会议win7二维码展示不出来
问题:win64更新后二维码展示不出来,手机等登陆都不行 安装所在位置创建文档命名TBSDEBUG并去掉后缀...

swift 专题三 swift 规范一
一、Swift编码命名规范 对类、结构体、枚举和协议等类型的命名应该采用大驼峰法,如 SplitViewController。 文件名采用大驼峰法,如BlockOperation.swift。 对于扩展文件,有时扩展定义在一个独立的文件中,用“原始类型名 扩展名…...

WPS计算机二级•幻灯片放映与会议
听说这是目录哦 放映PPT时常用的快捷技巧🥬设置放映模式🥕演讲备注的添加和隐藏🫚在PPT中插入附件并放映时打开🫛隐藏幻灯片 不被放映和打印🍄🟫演讲计时模式🥦能量站😚 放映PPT时…...

联想拯救者开机进入bios
如果你的联想拯救者(Lenovo Legion)笔记本电脑开机后直接进入 BIOS 设置界面,可能是以下原因之一导致的。以下是解决方法: 1. 检查启动顺序 进入 BIOS 后,找到 Boot(启动)选项卡。检查启动顺序…...

云原生周刊:K8s引领潮流
开源项目推荐 KWOK KWOK(Kubernetes WithOut Kubelet)是一个开源项目,旨在提供一个轻量级的 K8s 集群模拟环境,允许用户在不依赖真实节点的情况下,本地模拟整个 K8s 集群。它通过模拟 Kubelet 和其他集群组件的行为&…...

FBX SDK的使用:基础知识
Windows环境配置 FBX SDK安装后,目录下有三个文件夹: include 头文件lib 编译的二进制库,根据你项目的配置去包含相应的库samples 官方使用案列 动态链接 libfbxsdk.dll, libfbxsdk.lib是动态库,需要在配置属性->C/C->预…...

计算机网络笔记再战——理解几个经典的协议6——TCP与UDP
目录 先说端口号 TCP 使用序号保证顺序性和应答来保证有效性 超时重传机制 TCP窗口机制 UDP 路由协议 协议分类:IGP和EGP 几个经典的路由算法 RIP OSPF 链路状态数据库(LSDB) LSA(Link State Advertisement࿰…...

Android 单例模式:实现可复用数据存储
引言 在 Java 开发中,我们经常会遇到需要在整个应用程序中共享数据的场景。例如,配置信息、缓存数据等,这些数据需要在不同的模块或类中被访问和使用。为了确保数据的一致性和避免重复创建,我们可以使用单例模式来实现一个可复用的…...

【技海登峰】Kafka漫谈系列(二)Kafka高可用副本的数据同步与选主机制
【技海登峰】Kafka漫谈系列(二)Kafka高可用副本的数据同步与选主机制 一. 数据同步 在之前的学习中有了副本Replica的概念,解决了数据备份的问题。我们还需要面临一个设计难题即:如何处理分区中Leader与Follwer节点数据同步不匹配问题所带来的风险,这也是保证数据高可用的…...

【Linux】curl命令详解
【Linux】curl命令详解 【一】curl命令介绍【1】curl命令简介【2】curl命令的基本语法【3】常用的curl命令选项【4】常用的curl命令参数 【二】curl命令示例用法【1】下载文件【2】发送 POST 请求【3】发送请求时附加头部信息【4】请求方法【5】指定用户名和密码进行身份验证【…...

创建模态框和非模态框
主要的精简代码就这些 #include <QDialog>// 创建模态框 QDialog dialog(this); // 添加各种部件 // ... // 因为创建在栈上面,所以需要阻止程序继续运行 dialog.exec();// 非模态框 QDialog dialog new Dialog(this); // 添加各种部件 // ... dialog.show(…...
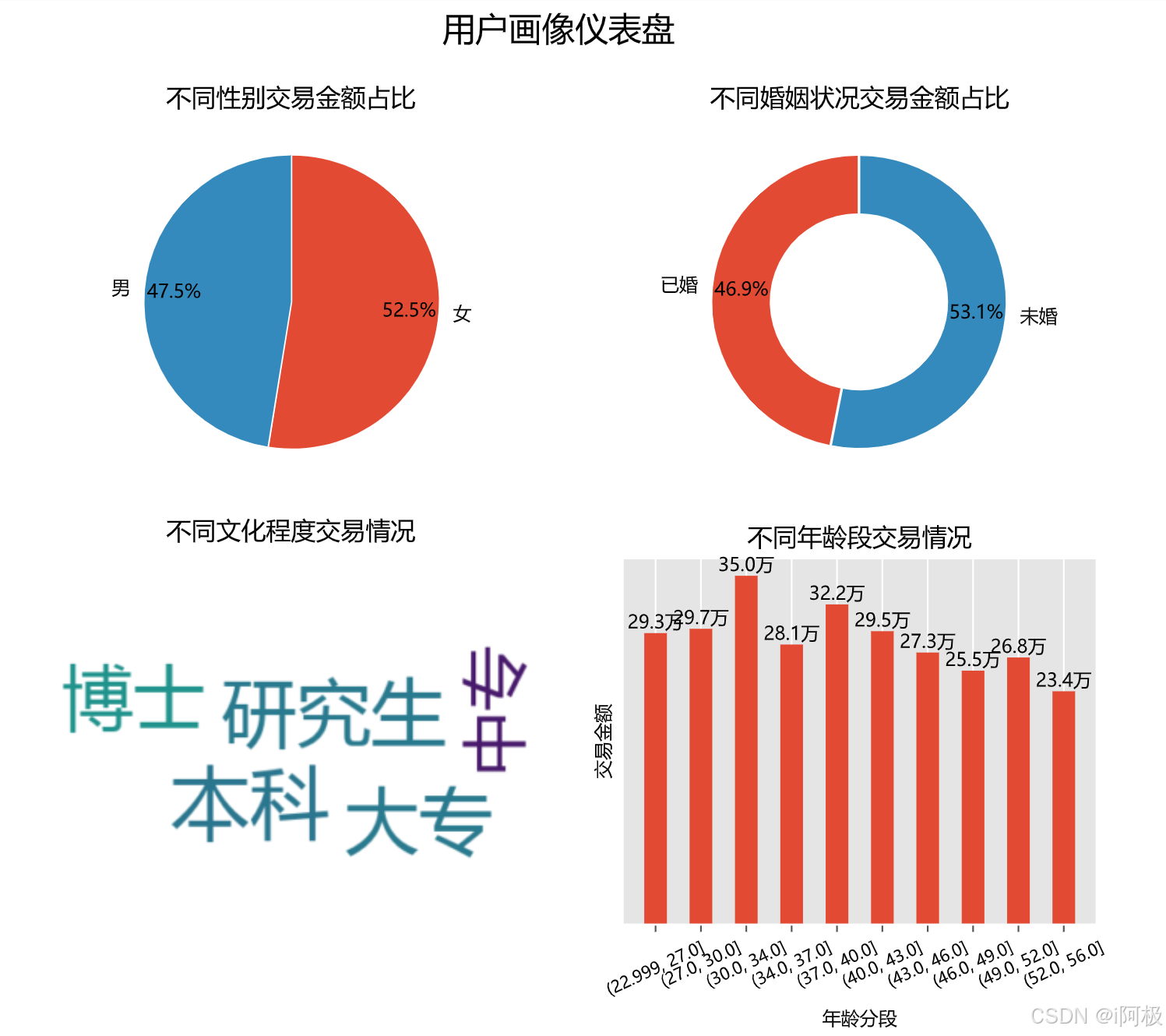
电商用户画像数据可视化分析
电商用户画像数据可视化分析 作者:i阿极 作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论&am…...

Vue3.5常用特性整理
Vue3.5 发布已近半年,抽空整理下常用的新增/改动特性 响应式 Props 解构 Vue3.5 中 Props 正式支持解构了,并添加了响应式跟踪 设置默认值 使用 JavaScript 原生的默认值语法声明 props 默认值 以前 const props withDefaults(defineProps<{ co…...

Android Studio:Application 和 Activity的区别
Application 和 Activity 是 Android 中非常重要的两个组件,它们分别负责不同的生命周期管理和应用的不同层次的操作。 Application 是应用级别的生命周期管理,它在整个应用运行时只有一个实例,负责应用的全局初始化和资源管理。Activity 是…...

深入解析“Self-Contained”——从技术到日常的全方位应用
深入解析“Self-Contained”——从技术到日常的全方位应用 一、引言 在阅读技术文档、编程指南或产品说明时,你可能经常看到 self-contained 这个短语。例如: Our end goal is a self-contained project containing two parts. https://howistart.org/p…...

2024年12月 Scratch 图形化(一级)真题解析 中国电子学会全国青少年软件编程等级考试
202412 Scratch 图形化(一级)真题解析 中国电子学会全国青少年软件编程等级考试 一、单选题(共25题,共50分) 第 1 题 点击下列哪个按钮,可以将红框处的程序放大?( ) A. B. C. D. 标…...

llama.cpp GGML Quantization Type
llama.cpp GGML Quantization Type 1. GGML Quantization Type2. static const struct ggml_type_traits type_traits[GGML_TYPE_COUNT]3. Q#_K_M and Q#_KReferences 什么神仙妖魔,不过是他们禁锢异族命运的枷锁! GGUF https://huggingface.co/docs/hu…...
)
【深度学习框架】MXNet(Apache MXNet)
MXNet(Apache MXNet)是一个 高性能、可扩展 的 开源深度学习框架,支持 多种编程语言(如 Python、R、Scala、C 和 Julia),并能在 CPU、GPU 以及分布式集群 上高效运行。MXNet 是亚马逊 AWS 官方支持的深度学…...

游戏引擎学习第87天
当直接使用内存时,可能会发生一些奇怪的事情 在直接操作内存时,一些意外的情况可能会发生。由于内存实际上只是一个大块的空间,开发者可以完全控制它,而不像高级语言那样必须遵守许多规则,因此很容易发生错误。在一个…...

【物联网】ARM核常用指令(详解):数据传送、计算、位运算、比较、跳转、内存访问、CPSR/SPSR
文章目录 指令格式(重点)1. 立即数2. 寄存器位移 一、数据传送指令1. MOV指令2. MVN指令3. LDR指令 二、数据计算指令1. ADD指令1. SUB指令1. MUL指令 三、位运算指令1. AND指令2. ORR指令3. EOR指令4. BIC指令 四、比较指令五、跳转指令1. B/BL指令2. l…...

Qt展厅播放器/多媒体播放器/中控播放器/帧同步播放器/硬解播放器/监控播放器
一、前言说明 音视频开发除了应用在安防监控、视频网站、各种流媒体app开发之外,还有一个小众的市场,那就是多媒体展厅场景,这个场景目前处于垄断地位的软件是HirenderS3,做的非常早而且非常全面,都是通用的需求&…...