Java Stream API:高效数据处理的利器引言
Java Stream API:高效数据处理的利器引言
在 Java 编程中,数据处理是一项极为常见且关键的任务。传统的 for 循环在处理数据集合时,往往会导致代码变得冗长、复杂,这不仅增加了代码的编写难度,还降低了代码的可读性和可维护性。Java 8 引入的 Stream API 则为我们提供了一种全新的、更加高效和简洁的数据处理方式。Stream API 允许我们以声明式的方式处理数据集合,将数据处理的逻辑与数据的存储和遍历分离开来,使得代码更加清晰、易于理解和维护。本文将深入、详细地介绍 Stream API 的各个组成部分,包括数据源、中间操作和终止操作,并通过丰富多样的示例代码展示如何使用 Stream API 替代传统的 for 循环进行数据处理。
一、Stream 管道流的组成
Stream 管道流主要由三个核心部分构成:一个数据源、零个或多个中间操作以及一个终止操作。下面我们将对这三个部分进行全面且详细的介绍。
1.1 数据源
数据源是 Stream 的起始点,它可以是多种形式,如数组、集合、生成器函数、I/O 管道等。Stream API 提供了丰富的方法来从不同的数据源创建流。
1.1.1 从数组创建流
使用 Arrays.stream() 方法能够轻松地从数组创建流。数组是一种常见的数据存储形式,通过将其转换为流,我们可以利用 Stream API 提供的强大功能进行数据处理。以下是一个详细的示例代码:
import java.util.Arrays;public class StreamDataSourceFromArray {public static void main(String[] args) {String[] array = {"apple", "banana", "cherry"};// 使用 Arrays.stream() 方法从数组创建流Arrays.stream(array).forEach(System.out::println);}
}在上述代码中,Arrays.stream(array) 方法将数组 array 转换为一个流。forEach 是一个终止操作,它会对流中的每个元素执行指定的操作,这里使用了方法引用 System.out::println,表示将每个元素打印到控制台。通过这种方式,我们可以方便地遍历数组中的元素。
1.1.2 从集合创建流
集合类(如 List、Set 等)提供了 stream() 方法来创建流。集合是 Java 中常用的数据结构,将其转换为流后,我们可以利用 Stream API 进行更高效的数据处理。以下是一个从 List 创建流的示例:
import java.util.Arrays;
import java.util.List;public class StreamDataSourceFromList {public static void main(String[] args) {List<String> list = Arrays.asList("dog", "cat", "elephant");// 使用 list.stream() 方法从集合创建流list.stream().forEach(System.out::println);}
}在这个示例中,list.stream() 方法将 List 集合转换为一个流。同样,使用 forEach 方法遍历并打印集合中的元素。与传统的 for 循环相比,使用 Stream API 可以使代码更加简洁和易读。
1.1.3 从生成器函数创建流
除了数组和集合,我们还可以使用生成器函数创建流。Stream.generate() 方法可以接受一个 Supplier 接口的实现,用于生成流中的元素。以下是一个生成随机数流的示例:
import java.util.Random;
import java.util.stream.Stream;public class StreamDataSourceFromGenerator {public static void main(String[] args) {Random random = new Random();// 使用 Stream.generate() 方法创建一个无限流,生成随机数Stream.generate(random::nextInt).limit(5) // 限制流的元素数量为 5.forEach(System.out::println);}
}在上述代码中,Stream.generate(random::nextInt) 创建了一个无限流,其中每个元素都是一个随机整数。为了避免无限循环,我们使用 limit(5) 方法限制流的元素数量为 5。最后,使用 forEach 方法打印这 5 个随机数。
1.1.4 从 I/O 管道创建流
在处理文件或网络数据时,我们可以从 I/O 管道创建流。例如,使用 Files.lines() 方法可以从文件中读取每一行并创建一个流。以下是一个简单的示例:
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.stream.Stream;public class StreamDataSourceFromIO {public static void main(String[] args) {try {// 从文件中读取每一行并创建一个流Stream<String> lines = Files.lines(Paths.get("example.txt"));lines.forEach(System.out::println);lines.close(); // 关闭流} catch (IOException e) {e.printStackTrace();}}
}在这个示例中,Files.lines(Paths.get("example.txt")) 从名为 example.txt 的文件中读取每一行,并创建一个流。然后使用 forEach 方法打印每一行。最后,需要调用 close() 方法关闭流,以释放资源。
1.2 中间操作
中间操作是 Stream 管道流中的重要组成部分,它可以将一个流转换为另一个流。中间操作是惰性的,即只有在终止操作被调用时才会真正执行。这意味着我们可以链式调用多个中间操作,而不会立即进行数据处理,直到遇到终止操作。常见的中间操作包括 filter、map、flatMap 等,下面我们将逐一详细介绍。
1.2.1 filter 方法
filter 方法用于过滤流中的元素,只保留满足指定条件的元素。它接受一个 Predicate 函数式接口作为参数,该接口的 test 方法用于判断元素是否满足条件。以下是一个过滤偶数的示例:
import java.util.Arrays;
import java.util.List;public class FilterExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);numbers.stream().filter(n -> n % 2 == 0) // 过滤出偶数.forEach(System.out::println);}
}在上述代码中,filter(n -> n % 2 == 0) 表示只保留流中能被 2 整除的元素,即偶数。最终,只有满足条件的元素会被传递给 forEach 方法进行打印输出。filter 方法可以帮助我们快速筛选出符合特定条件的数据,提高数据处理的效率。
1.2.2 map 方法
map 方法用于将流中的每个元素映射为另一个元素。它接受一个 Function 函数式接口作为参数,该接口的 apply 方法用于对每个元素进行转换。例如,将字符串转换为大写:
import java.util.Arrays;
import java.util.List;public class MapExample {public static void main(String[] args) {List<String> words = Arrays.asList("hello", "world");words.stream().map(String::toUpperCase) // 将每个单词转换为大写.forEach(System.out::println);}
}在这个示例中,map(String::toUpperCase) 将流中的每个字符串元素转换为大写形式,然后传递给 forEach 方法进行打印。map 方法可以用于对数据进行各种转换,如类型转换、数据提取等。
1.2.3 mapToInt 方法
mapToInt 方法用于将流中的元素映射为 int 类型。它接受一个 ToIntFunction 函数式接口作为参数,该接口的 applyAsInt 方法用于将元素转换为 int 类型。例如,将字符串转换为整数:
import java.util.Arrays;
import java.util.List;public class MapToIntExample {public static void main(String[] args) {List<String> numbers = Arrays.asList("1", "2", "3");numbers.stream().mapToInt(Integer::parseInt) // 将字符串转换为整数.forEach(System.out::println);}
}这里,mapToInt(Integer::parseInt) 将流中的每个字符串元素解析为整数,形成一个 IntStream。IntStream 提供了一些专门用于处理整数的方法,如 sum()、average() 等。与普通的 Stream<Integer> 相比,IntStream 可以更高效地处理整数数据。
1.2.4 flatMap 方法
flatMap 方法用于将流中的每个元素展开为多个元素。它接受一个 Function 函数式接口作为参数,该接口的 apply 方法返回一个流。例如,将嵌套列表展开:
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;public class FlatMapExample {public static void main(String[] args) {List<List<Integer>> nestedList = Arrays.asList(Arrays.asList(1, 2),Arrays.asList(3, 4));List<Integer> flattenedList = nestedList.stream().flatMap(List::stream) // 展开嵌套列表.collect(Collectors.toList());System.out.println(flattenedList);}
}在这个示例中,flatMap(List::stream) 将嵌套的 List 展开为一个包含所有元素的流。具体来说,对于每个内部列表,List::stream 方法会将其转换为一个流,然后 flatMap 方法会将这些流合并成一个新的流。最后,使用 collect(Collectors.toList()) 方法将流中的元素收集到一个新的 List 中。flatMap 方法在处理嵌套数据结构时非常有用。
1.2.5 distinct 方法
distinct 方法用于去除流中的重复元素。它根据元素的 equals() 方法来判断元素是否重复。以下是一个示例:
import java.util.Arrays;
import java.util.List;public class DistinctExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 3, 3);numbers.stream().distinct() // 去除重复元素.forEach(System.out::println);}
}在上述代码中,distinct() 方法会去除流中的重复元素,只保留每个不同元素的一个实例。最终,输出结果将是 1、2、3。
1.2.6 sorted 方法
sorted 方法用于对流中的元素进行排序。它有两种重载形式:一种是无参的,使用元素的自然顺序进行排序;另一种是接受一个 Comparator 接口的实现,用于自定义排序规则。以下是一个使用自然顺序排序的示例:
import java.util.Arrays;
import java.util.List;public class SortedExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(3, 1, 2);numbers.stream().sorted() // 使用自然顺序排序.forEach(System.out::println);}
}在这个示例中,sorted() 方法会将流中的元素按照自然顺序进行排序,最终输出结果将是 1、2、3。如果需要自定义排序规则,可以传递一个 Comparator 接口的实现,例如:
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;public class SortedWithComparatorExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(3, 1, 2);numbers.stream().sorted(Comparator.reverseOrder()) // 按降序排序.forEach(System.out::println);}
}在这个示例中,Comparator.reverseOrder() 表示按降序排序,最终输出结果将是 3、2、1。
1.2.7 peek 方法
peek 方法用于在流的每个元素上执行一个操作,但不会改变流中的元素。它主要用于调试和监控流的处理过程。以下是一个示例:
import java.util.Arrays;
import java.util.List;public class PeekExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3);numbers.stream().peek(n -> System.out.println("Processing: " + n)) // 打印每个元素.map(n -> n * 2).forEach(System.out::println);}
}在上述代码中,peek(n -> System.out.println("Processing: " + n)) 会在每个元素被处理之前打印一条消息,方便我们监控流的处理过程。最终,流中的每个元素会被乘以 2 并打印输出。
1.2.8 limit 方法
limit 方法用于限制流的元素数量。它接受一个 long 类型的参数,表示要保留的元素数量。以下是一个示例:
import java.util.Arrays;
import java.util.List;public class LimitExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);numbers.stream().limit(3) // 只保留前 3 个元素.forEach(System.out::println);}
}在这个示例中,limit(3) 方法会只保留流中的前 3 个元素,最终输出结果将是 1、2、3。
1.2.9 skip 方法
skip 方法用于跳过流中的前几个元素。它接受一个 long 类型的参数,表示要跳过的元素数量。以下是一个示例:
import java.util.Arrays;
import java.util.List;public class SkipExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);numbers.stream().skip(2) // 跳过前 2 个元素.forEach(System.out::println);}
}在上述代码中,skip(2) 方法会跳过流中的前 2 个元素,最终输出结果将是 3、4、5。
1.3 终止操作
终止操作是 Stream 管道流的最后一步,它会触发中间操作的执行并产生最终结果。常见的终止操作包括 forEach、collect、count 等,下面我们将分别详细介绍。
1.3.1 forEach 方法
forEach 方法用于对流中的每个元素执行指定的操作。它接受一个 Consumer 函数式接口作为参数,该接口的 accept 方法用于定义要执行的操作。例如,遍历并打印元素:
import java.util.Arrays;
import java.util.List;public class ForEachExample {public static void main(String[] args) {List<String> names = Arrays.asList("Alice", "Bob", "Charlie");names.stream().forEach(System.out::println);}
}在上述代码中,forEach(System.out::println) 表示对流中的每个元素执行打印操作。forEach 方法是一个终端操作,一旦调用,流的处理过程就会结束。
1.3.2 collect 方法
collect 方法用于将流中的元素收集到一个集合中。它接受一个 Collector 接口的实现作为参数,Collector 接口定义了如何将流中的元素收集到目标集合中。Java 提供了一些预定义的 Collector 实现,如 Collectors.toList()、Collectors.toSet() 等。以下是一个将计算后的元素收集到一个新的 List 中的示例:
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;public class CollectExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);List<Integer> squaredNumbers = numbers.stream().map(n -> n * n) // 计算每个数的平方.collect(Collectors.toList());System.out.println(squaredNumbers);}
}在这个示例中,map(n -> n * n) 计算每个元素的平方,然后 collect(Collectors.toList()) 将计算后的元素收集到一个新的 List 中。除了 toList(),我们还可以使用 toSet() 将元素收集到一个 Set 中,使用 toMap() 将元素收集到一个 Map 中,等等。
1.3.3 count 方法
import java.util.Arrays;
import java.util.List;public class CountExample {public static void main(String[] args) {List<String> names = Arrays.asList("Alice", "Bob", "Charlie");long count = names.stream().count();System.out.println("Number of names: " + count);}
}在上述代码里,count() 方法会对流中的元素进行计数。由于 names 列表中有 3 个元素,所以最终输出的结果是 Number of names: 3。count 方法在需要快速知晓集合元素数量时非常实用,而且结合中间操作使用时,能统计出符合特定条件的元素数量。例如:
import java.util.Arrays;
import java.util.List;public class ConditionalCountExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);long evenCount = numbers.stream().filter(n -> n % 2 == 0).count();System.out.println("Number of even numbers: " + evenCount);}
}这里先使用 filter 方法筛选出偶数,再用 count 方法统计偶数的数量,最终输出偶数的个数。
1.3.4 reduce 方法
reduce 方法用于将流中的元素进行合并,得到一个最终结果。它有几种重载形式,最常用的是接受一个二元操作符(BinaryOperator)作为参数。以下是一个计算整数列表元素总和的示例:
import java.util.Arrays;
import java.util.List;
import java.util.Optional;public class ReduceExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);Optional<Integer> sum = numbers.stream().reduce((a, b) -> a + b);sum.ifPresent(result -> System.out.println("Sum: " + result));}
}在上述代码中,reduce((a, b) -> a + b) 会将流中的元素依次进行累加。reduce 方法返回一个 Optional 对象,因为流可能为空,使用 ifPresent 方法可以安全地处理可能为空的结果。如果流不为空,就会打印出元素的总和。
还有一种重载形式可以提供一个初始值,如下所示:
import java.util.Arrays;
import java.util.List;public class ReduceWithInitialValueExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);int sum = numbers.stream().reduce(10, (a, b) -> a + b);System.out.println("Sum with initial value: " + sum);}
}这里初始值为 10,最终结果是初始值加上流中元素的总和。
1.3.5 min 和 max 方法
min 和 max 方法分别用于找出流中的最小值和最大值。它们接受一个 Comparator 接口的实现作为参数,用于定义元素之间的比较规则。如果没有提供 Comparator,则使用元素的自然顺序。以下是一个找出整数列表中最小值的示例:
import java.util.Arrays;
import java.util.List;
import java.util.Optional;public class MinExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5);Optional<Integer> min = numbers.stream().min(Integer::compareTo);min.ifPresent(result -> System.out.println("Minimum value: " + result));}
}在上述代码中,min(Integer::compareTo) 使用 Integer 的自然顺序比较元素,找出最小值。同样,max 方法的使用方式类似:
import java.util.Arrays;
import java.util.List;
import java.util.Optional;public class MaxExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5);Optional<Integer> max = numbers.stream().max(Integer::compareTo);max.ifPresent(result -> System.out.println("Maximum value: " + result));}
}1.3.6 anyMatch、allMatch 和 noneMatch 方法
anyMatch方法:用于判断流中是否至少有一个元素满足指定条件。它接受一个Predicate函数式接口作为参数。以下是一个示例:
import java.util.Arrays;
import java.util.List;public class AnyMatchExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);boolean hasEven = numbers.stream().anyMatch(n -> n % 2 == 0);System.out.println("Has even number: " + hasEven);}
}在这个例子中,anyMatch(n -> n % 2 == 0) 检查流中是否有偶数,只要有一个偶数就返回 true。
allMatch方法:用于判断流中的所有元素是否都满足指定条件。示例如下:
import java.util.Arrays;
import java.util.List;public class AllMatchExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(2, 4, 6, 8);boolean allEven = numbers.stream().allMatch(n -> n % 2 == 0);System.out.println("All numbers are even: " + allEven);}
}这里 allMatch(n -> n % 2 == 0) 检查流中的所有元素是否都是偶数,只有当所有元素都满足条件时才返回 true。
noneMatch方法:用于判断流中是否没有元素满足指定条件。示例如下:
import java.util.Arrays;
import java.util.List;public class NoneMatchExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 3, 5, 7);boolean noEven = numbers.stream().noneMatch(n -> n % 2 == 0);System.out.println("No even numbers: " + noEven);}
}noneMatch(n -> n % 2 == 0) 检查流中是否没有偶数,只有当没有一个元素满足条件时才返回 true。
1.3.7 findFirst 和 findAny 方法
findFirst方法:用于返回流中的第一个元素。它返回一个Optional对象,因为流可能为空。以下是一个示例:
import java.util.Arrays;
import java.util.List;
import java.util.Optional;public class FindFirstExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);Optional<Integer> first = numbers.stream().findFirst();first.ifPresent(result -> System.out.println("First number: " + result));}
}在上述代码中,findFirst() 方法返回流中的第一个元素,如果流不为空,就打印出该元素。
findAny方法:用于返回流中的任意一个元素。在顺序流中,通常返回第一个元素;在并行流中,可能返回任意一个元素。示例如下:
import java.util.Arrays;
import java.util.List;
import java.util.Optional;public class FindAnyExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);Optional<Integer> any = numbers.stream().findAny();any.ifPresent(result -> System.out.println("Any number: " + result));}
}findAny() 方法在并行处理时比较有用,因为它可以快速返回一个可用的元素,而不必等待找到第一个元素。
1.3.8 toArray 方法
toArray 方法用于将流中的元素收集到一个数组中。它有两种重载形式:一种是无参的,返回一个 Object 数组;另一种是接受一个 IntFunction<T[]> 作为参数,用于指定数组的类型。以下是一个示例:
import java.util.Arrays;
import java.util.List;public class ToArrayExample {public static void main(String[] args) {List<String> names = Arrays.asList("Alice", "Bob", "Charlie");String[] nameArray = names.stream().toArray(String[]::new);System.out.println(Arrays.toString(nameArray));}
}在这个例子中,toArray(String[]::new) 将流中的元素收集到一个 String 数组中,并打印出数组的内容。
二、综合示例
下面通过一个综合示例,展示如何使用 Stream API 进行复杂的数据处理。假设我们有一个包含多个学生信息的列表,每个学生有姓名、年龄和成绩,我们要筛选出年龄大于 18 岁且成绩大于 80 分的学生,并将他们的姓名收集到一个新的列表中。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;class Student {private String name;private int age;private double score;public Student(String name, int age, double score) {this.name = name;this.age = age;this.score = score;}public String getName() {return name;}public int getAge() {return age;}public double getScore() {return score;}
}public class ComprehensiveExample {public static void main(String[] args) {List<Student> students = new ArrayList<>();students.add(new Student("Alice", 20, 85));students.add(new Student("Bob", 17, 75));students.add(new Student("Charlie", 22, 90));students.add(new Student("David", 19, 70));List<String> qualifiedStudents = students.stream().filter(student -> student.getAge() > 18 && student.getScore() > 80).map(Student::getName).collect(Collectors.toList());System.out.println("Qualified students: " + qualifiedStudents);}
}在上述代码中,首先定义了一个 Student 类来表示学生信息。然后创建了一个包含多个学生的列表。接着使用 Stream API 进行数据处理:
filter(student -> student.getAge() > 18 && student.getScore() > 80)筛选出年龄大于 18 岁且成绩大于 80 分的学生。map(Student::getName)将筛选后的学生对象映射为他们的姓名。collect(Collectors.toList())将姓名收集到一个新的列表中。
最后打印出符合条件的学生姓名列表。
三、总结
Stream API 为 Java 开发者提供了一种强大而简洁的数据处理方式。通过将数据处理逻辑封装在流管道中,我们可以避免传统 for 循环带来的代码冗余和复杂性,提高代码的可读性和可维护性。在实际开发中,我们应该尽量使用 Stream API 来替代传统的 for 循环,充分发挥其优势。同时,需要注意中间操作的惰性和终止操作的触发机制,合理组合各种操作来实现高效的数据处理。希望本文的详细介绍和丰富示例能够帮助你更好地理解和使用 Java Stream API。
四、并行流的使用及注意事项
4.1 并行流的基本概念
并行流是 Stream API 提供的一种能够充分利用多核处理器性能的数据处理方式。它将流中的元素分成多个部分,在多个线程中并行处理这些部分,最后将结果合并。通过并行流,可以显著提高大规模数据处理的效率。
4.2 并行流的创建与使用
可以使用 parallelStream() 方法直接从集合创建并行流,也可以通过 parallel() 方法将顺序流转换为并行流。以下是示例代码:
import java.util.Arrays;
import java.util.List;public class ParallelStreamExample {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 直接从集合创建并行流long sum1 = numbers.parallelStream().mapToInt(Integer::intValue).sum();System.out.println("Sum using parallelStream(): " + sum1);// 将顺序流转换为并行流long sum2 = numbers.stream().parallel().mapToInt(Integer::intValue).sum();System.out.println("Sum using parallel(): " + sum2);}
}在上述代码中,parallelStream() 直接创建了一个并行流,而 parallel() 方法将原本的顺序流转换为并行流。两种方式最终都对元素进行求和操作。
4.3 并行流的性能考量
虽然并行流可以提高处理效率,但并非在所有情况下都适用。以下是一些需要考虑的因素:
- 数据规模:对于小规模数据,使用并行流可能会因为线程创建和管理的开销而导致性能下降。只有当数据规模足够大时,并行流才能发挥出优势。例如,处理少量元素的列表时,顺序流可能更快:
import java.util.Arrays;
import java.util.List;public class ParallelStreamPerformanceSmallData {public static void main(String[] args) {List<Integer> smallNumbers = Arrays.asList(1, 2, 3, 4, 5);long startTimeSeq = System.currentTimeMillis();int sumSeq = smallNumbers.stream().mapToInt(Integer::intValue).sum();long endTimeSeq = System.currentTimeMillis();System.out.println("Sequential sum: " + sumSeq + ", Time taken: " + (endTimeSeq - startTimeSeq) + " ms");long startTimePar = System.currentTimeMillis();int sumPar = smallNumbers.parallelStream().mapToInt(Integer::intValue).sum();long endTimePar = System.currentTimeMillis();System.out.println("Parallel sum: " + sumPar + ", Time taken: " + (endTimePar - startTimePar) + " ms");}
}- 操作复杂度:如果流中的操作非常简单,如简单的映射或过滤,并行流的线程管理开销可能会超过并行处理带来的好处。而对于复杂的操作,并行流可能更具优势。
- 数据结构:不同的数据结构在并行流中的性能表现不同。例如,
ArrayList等可随机访问的数据结构在并行流中表现较好,因为可以很容易地将其分割成多个部分;而LinkedList等顺序访问的数据结构在并行流中的性能可能较差。
4.4 并行流的线程安全问题
使用并行流时,需要特别注意线程安全问题。如果在并行流的操作中涉及到共享可变状态,可能会导致数据不一致或其他并发问题。例如,以下代码存在线程安全问题:
import java.util.Arrays;
import java.util.List;public class ParallelStreamThreadSafetyIssue {private static int sharedSum = 0;public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);numbers.parallelStream().forEach(n -> sharedSum += n);System.out.println("Shared sum: " + sharedSum);}
}在上述代码中,多个线程同时对 sharedSum 进行累加操作,可能会导致数据不一致。为了解决这个问题,可以使用线程安全的数据结构或同步机制,或者使用 reduce 等方法进行安全的聚合操作:
import java.util.Arrays;
import java.util.List;public class ParallelStreamThreadSafe {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);int sum = numbers.parallelStream().reduce(0, Integer::sum);System.out.println("Safe sum: " + sum);}
}五、Stream API 与函数式编程的结合
5.1 函数式接口在 Stream API 中的应用
Stream API 大量使用了函数式接口,如 Predicate、Function、Consumer 等。这些函数式接口允许我们以简洁的方式定义数据处理逻辑。例如,在 filter 方法中使用 Predicate 接口来筛选元素:
import java.util.Arrays;
import java.util.List;
import java.util.function.Predicate;public class FunctionalInterfaceInStream {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);Predicate<Integer> isEven = n -> n % 2 == 0;numbers.stream().filter(isEven).forEach(System.out::println);}
}在上述代码中,定义了一个 Predicate 接口的实现 isEven,用于判断一个数是否为偶数,然后将其传递给 filter 方法。
5.2 Lambda 表达式的优势
Lambda 表达式是函数式编程的核心特性之一,它与 Stream API 结合使用可以使代码更加简洁和易读。相比于传统的匿名内部类,Lambda 表达式减少了样板代码,让开发者可以更专注于业务逻辑。例如,比较使用匿名内部类和 Lambda 表达式的区别:
import java.util.Arrays;
import java.util.List;public class LambdaVsAnonymousClass {public static void main(String[] args) {List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用匿名内部类numbers.stream().filter(new java.util.function.Predicate<Integer>() {@Overridepublic boolean test(Integer n) {return n % 2 == 0;}}).forEach(System.out::println);// 使用 Lambda 表达式numbers.stream().filter(n -> n % 2 == 0).forEach(System.out::println);}
}可以看到,使用 Lambda 表达式的代码更加简洁明了。
5.3 方法引用的使用
方法引用是 Lambda 表达式的一种简化形式,它允许我们直接引用已有的方法。在 Stream API 中,方法引用可以使代码更加简洁和直观。例如,使用方法引用进行元素的打印:
import java.util.Arrays;
import java.util.List;public class MethodReferenceInStream {public static void main(String[] args) {List<String> names = Arrays.asList("Alice", "Bob", "Charlie");names.stream().forEach(System.out::println);}
}在上述代码中,System.out::println 是一个方法引用,它等价于 n -> System.out.println(n)。
六、Stream API 在实际项目中的应用场景
6.1 数据筛选与过滤
在实际项目中,经常需要从大量数据中筛选出符合特定条件的数据。例如,从用户列表中筛选出年龄大于 18 岁的用户:
import java.util.ArrayList;
import java.util.List;class User {private String name;private int age;public User(String name, int age) {this.name = name;this.age = age;}public int getAge() {return age;}public String getName() {return name;}
}public class DataFilteringExample {public static void main(String[] args) {List<User> users = new ArrayList<>();users.add(new User("Alice", 20));users.add(new User("Bob", 15));users.add(new User("Charlie", 22));List<User> adultUsers = users.stream().filter(user -> user.getAge() > 18).collect(java.util.stream.Collectors.toList());adultUsers.forEach(user -> System.out.println(user.getName()));}
}6.2 数据转换与映射
在处理数据时,可能需要将一种数据类型转换为另一种数据类型,或者提取数据中的某些信息。例如,从商品列表中提取商品的名称:
import java.util.ArrayList;
import java.util.List;class Product {private String name;private double price;public Product(String name, double price) {this.name = name;this.price = price;}public String getName() {return name;}
}public class DataMappingExample {public static void main(String[] args) {List<Product> products = new ArrayList<>();products.add(new Product("Apple", 2.5));products.add(new Product("Banana", 1.5));products.add(new Product("Cherry", 3.0));List<String> productNames = products.stream().map(Product::getName).collect(java.util.stream.Collectors.toList());productNames.forEach(System.out::println);}
}6.3 数据聚合与统计
在数据分析和报表生成中,需要对数据进行聚合和统计操作,如求和、求平均值、求最大值等。例如,统计订单列表的总金额:
import java.util.ArrayList;
import java.util.List;class Order {private double amount;public Order(double amount) {this.amount = amount;}public double getAmount() {return amount;}
}public class DataAggregationExample {public static void main(String[] args) {List<Order> orders = new ArrayList<>();orders.add(new Order(100.0));orders.add(new Order(200.0));orders.add(new Order(300.0));double totalAmount = orders.stream().mapToDouble(Order::getAmount).sum();System.out.println("Total order amount: " + totalAmount);}
}6.4 数据分组与分区
在处理数据时,可能需要根据某些条件对数据进行分组或分区。例如,将员工按部门进行分组:
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;class Employee {private String name;private String department;public Employee(String name, String department) {this.name = name;this.department = department;}public String getDepartment() {return department;}public String getName() {return name;}
}public class DataGroupingExample {public static void main(String[] args) {List<Employee> employees = new ArrayList<>();employees.add(new Employee("Alice", "HR"));employees.add(new Employee("Bob", "IT"));employees.add(new Employee("Charlie", "HR"));Map<String, List<Employee>> employeesByDepartment = employees.stream().collect(Collectors.groupingBy(Employee::getDepartment));employeesByDepartment.forEach((department, empList) -> {System.out.println("Department: " + department);empList.forEach(emp -> System.out.println(" " + emp.getName()));});}
}七、总结与展望
7.1 总结
Java Stream API 为我们提供了一种强大而灵活的数据处理方式,通过将数据源、中间操作和终止操作组合成流管道,我们可以以声明式的方式处理数据,提高代码的可读性和可维护性。同时,并行流的支持使得我们能够充分利用多核处理器的性能,加速大规模数据的处理。函数式编程的特性,如 Lambda 表达式和方法引用,与 Stream API 紧密结合,进一步简化了代码的编写。
7.2 展望
随着 Java 技术的不断发展,Stream API 可能会进一步完善和扩展。例如,可能会提供更多的中间操作和终止操作,以满足更复杂的数据处理需求;并行流的性能可能会得到进一步优化,减少线程管理的开销;与其他 Java 特性(如模块化、响应式编程等)的集成也可能会更加紧密。开发者在实际项目中应该充分利用 Stream API 的优势,不断探索和创新,以提高开发效率和代码质量。
相关文章:

Java Stream API:高效数据处理的利器引言
Java Stream API:高效数据处理的利器引言 在 Java 编程中,数据处理是一项极为常见且关键的任务。传统的 for 循环在处理数据集合时,往往会导致代码变得冗长、复杂,这不仅增加了代码的编写难度,还降低了代码的可读性和…...
--开发工具介绍)
RK3568实战项目(六)--开发工具介绍
目录 一、引言 二、开发工具 ------>2.1、trust_merger ------>2.2、boot_merger ------>2.3、loaderimage ------>2.4、resource_tool ------>2.5、mkimage ------>2.6、mkbootimg ------>2.7、unpack_bootimg ------>2.8、repack-bootimg …...

Unity3D仿星露谷物语开发28之切换场景
1、目标 Player可以在Scene1_Farm和Scene2_Field之间自动切换。通过Trigger实现该功能。同时创建一个预设体绑定该功能,这样可以把预设体放到任何场景中,通过配置即可实现Player在Scene之间的自由切换。 2、创建场景切换的工具对象 在Hierarchy中&…...

阿里通义实验室提出AnyStory:开启个性化文本到图像生成的新篇章!
在这个数字化时代,生成式AI技术正以前所未有的速度改变着我们的创作方式。近期,阿里通义实验室发表了一篇题为《AnyStory: Towards Unified Single and Multi-Subject Personalization in Text-to-Image Generation》的论文,该论文提出了一种…...

开启蓝耘之旅:DeepSeek R1 模型在智算平台的起步教程
----------------------------------------------------------我的个人主页-------------------- 动动你的手指----------------------------------------点赞👍 收藏❤--------------------------------------------------------------- 引言 在深度学习的广袤领…...

LVS + KeepAlived 配置HA集群的步骤
LVS KeepAlived 配置HA集群的步骤 (一)集群准备 准备vmvare linux虚拟主机4台,假设对外提供的VIP是192.168.174.110 主机IP备注LVS1192.168.174.101提供4层代理-主机LVS2192.168.174.102提供4层代理-备用Apache1192.168.174.201真实服务器…...

ISAAC Sim 1.1. Isaac Sim 4.2.0 环境配置
我使用的系统是ubuntu20.04,根据推荐使用Binary installation 1.下载和安装 1.1. Isaac Sim 参照Installation using Isaac Sim Binaries — Isaac Lab Documentation完成ISAAC SIM安装。 1.2. Isaac Lab “Isaac Lab 提供您需要的工具,以便您根据项…...
活动预告 | Power Hour: Copilot 引领商业应用的未来
课程介绍 智能化时代,商业应用如何实现突破?微软全球副总裁 Charles Lamanna 将为您深度解析,剖析其中关键因素。 在本次线上研讨会中,Charles Lamanna 将分享他在增强商业运营方面的独到见解与实战策略,深度解读商业…...

Gemini 2.0模型更新:谷歌最新AI大模型全面开启智能时代
引言 2025年2月5日,谷歌人工智能实验室(Google DeepMind)发布了最新的Gemini 2.0模型系列更新,包括2.0 Flash、Flash-Lite和Pro实验版本。这些AI大模型的发布标志着人工智能技术在性能、效率和多模态能力上的进一步突破ÿ…...

前端布局与交互实现技巧
前端布局与交互实现技巧 1. 保持盒子在中间位置 在网页设计中,经常需要将某个元素居中显示。以下是一种常见的实现方式: HTML 结构 <!doctype html> <html lang"en"> <head><meta charset"UTF-8"><m…...

乘 DeepSeek 之风,破工作传统之浪,驶向智能高效新航道⭐
引言:当工作场景遭遇认知革命 在数字化转型的浪潮中,人工智能正以指数级速度重塑职场生态。DeepSeek作为国内领先的认知智能平台,其技术突破已超越简单的信息检索工具,正在演变为职场人的"第二大脑"。本文将系统解构De…...

Java | RESTful 接口规范
关注:CodingTechWork 引言 作为一名程序员,制定清晰、一致且高效的 RESTful 接口规范对于团队的开发效率和项目的长期维护至关重要。本文将详细介绍 RESTful 接口的设计理念、请求方法分类、核心规范,以及正确和错误的示例,帮助团…...

ASN.1 格式与Java类转换
ASN.1(Abstract Syntax Notation One)是一种用于描述数据结构的标准,常用于网络协议和数据编码。要将ASN.1格式的数据与Java类进行转换,通常需要使用ASN.1编译器或库来生成Java类,并使用这些类来编码和解码ASN.1数据。…...

从零开始掌握Python人工智能:实战案例、学习路径与职业建议
想必大家最近也都关注了实时,最近AI及deep seek可谓是火遍全球啊!小米总裁还说:大学生应该赶紧学会使用人工智能,你越早学会,你就比其他人更有优势。我也这样的感觉,deep seek现在可以和很多软件运用,完成绝…...

Oracle 变更redo log文件位置
更改Oracle数据库的Redo log文件位置,可以按照以下步骤操作。 1.查询当前Redo log文件信息 select * from v$log; select * from v$logfile;通过查询结果可知Redo log文件放在/oradata/redofile 目录下。 2.拷贝redo log文件到新的位置/Data/redolog $cd /orada…...

C++ 中信号转异常机制:在磁盘 I/O 内存映射场景下的应用与解析
C 中信号转异常机制:在磁盘 I/O 内存映射场景下的应用与解析 在现代 C 开发中,处理底层系统信号与高层 C 异常之间的转换是一项极具挑战性但又至关重要的任务。尤其是在涉及磁盘 I/O 操作且使用内存映射文件时,这种转换显得尤为关键。本文将围…...
--derivedStateOf)
Compose笔记(四)--derivedStateOf
这一节了解一下derivedStateOf,它用于创建一个派生状态。派生状态是一种特殊的状态,它的值是根据其他状态计算得出的。当依赖的状态发生变化时,派生状态会自动重新计算。使用 derivedStateOf 的主要目的是优化重组,避免不必要的重组ÿ…...

Chirpy3D:用于创意 3D 鸟类生成的连续部分潜在特征
Chirpy3D框架可以将细粒度的2D图像理解提升至3D生成的全新境界。当前的3D生成方法往往只关注于重构简单的对象,缺乏细致的特征和创造性。Chirpy3D通过结合多视角扩散模型和连续的部件潜在空间,能够生成全新且合理的3D鸟类模型。该系统不仅能够保持细致的…...
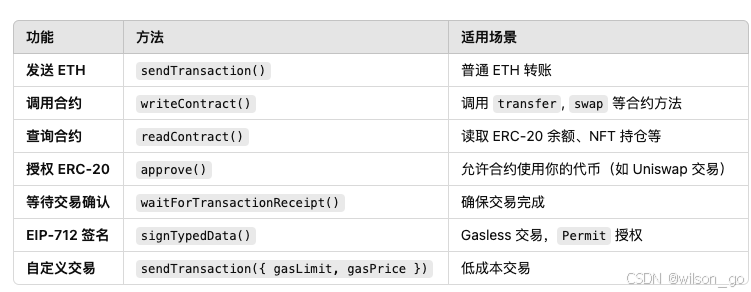
viem库
viem是一个用于和以太坊进行交互的javascript库,它提供了简单的API进行智能合约的读取和写入操作,你可以使用它来与区块链上智能合约进行交互,查询链上数据等。 基本功能 1,创建公有客户端 createPublicClient 可以创建一个链接…...

【每日一题 | 2025】2.3 ~ 2.9
个人主页:GUIQU. 归属专栏:每日一题 文章目录 1. 【2.3】P8784 [蓝桥杯 2022 省 B] 积木画2. 【2.4】P8656 [蓝桥杯 2017 国 B] 对局匹配3. 【2.5】[ABC365D] AtCoder Janken 34. 【2.6】P8703 [蓝桥杯 2019 国 B] 最优包含5. 【2.7】P8624 [蓝桥杯 2015…...

整数拆分cpp
题目如下 思路:根据数论知识,要使乘积最大化,将该数拆分成3和2即可,一直对该数进行减三操作,直到该数小于等于4即可 代码如下 谢谢观看...

DeepSeek之Api的使用(将DeepSeek的api集成到程序中)
一、DeepSeek API 的收费模式 前言:使用DeepSeek的api是收费的 免费版: 可能提供有限的免费额度(如每月一定次数的 API 调用),适合个人开发者或小规模项目。 付费版: 超出免费额度后,可能需要按…...

如何在WPS和Word/Excel中直接使用DeepSeek功能
以下是将DeepSeek功能集成到WPS中的详细步骤,无需本地部署模型,直接通过官网连接使用:1. 下载并安装OfficeAI插件 (1)访问OfficeAI插件下载地址:OfficeAI助手 - 免费办公智能AI助手, AI写作,下载…...

神经网络常见激活函数 6-RReLU函数
文章目录 RReLU函数导函数函数和导函数图像优缺点pytorch中的RReLU函数tensorflow 中的RReLU函数 RReLU 随机修正线性单元:Randomized Leaky ReLU 函数导函数 RReLU函数 R R e L U { x x ≥ 0 a x x < 0 \rm RReLU \left\{ \begin{array}{} x \quad x \ge 0…...

【分布式理论7】分布式调用之:服务间的(RPC)远程调用
文章目录 一、RPC 调用过程二、RPC 动态代理:屏蔽远程通讯细节1. 动态代理示例2. 如何将动态代理应用于 RPC 三、RPC序列化与协议编码1. RPC 序列化2. RPC 协议编码2.1. 协议编码的作用2.2. RPC 协议消息组成 四、RPC 网络传输1. 网络传输流程2. 关键优化点 一、RPC…...

【Maven】项目管理工具-Maven
目录 1. Maven简介 1.1 项目管理 1.2 项目构建 1.3 项目构建工具 1.4 Maven的四大特征 1.4.1 依赖管理系统 1.4.2 多模块构建 1.4.3 一致的项目结构 1.4.4 一致的构建模型和插件机制 1.5 Maven模型 编辑 2.maven的安装配置 2.1 Maven的安装配置 2.1.1检测jdk的版…...
:从理论到实战(附代码))
集成学习(二):从理论到实战(附代码)
接上一篇续写《集成学习(一):从理论到实战(附代码)》 五、实用算法 5.1 随机森林 随机森林在数据集的各个子样本上拟合许多决策树分类器,并使用平均来提高预测精度和控制过拟合。每一个分类器拟合了一部分随机样本,…...

ASP.NET Core WebSocket、SignalR
目录 WebSocket SignalR SignalR的基本使用 WebSocket WebSocket基于TCP协议,支持二进制通信,双工通信。性能和并发能力更强。WebSocket独立于HTTP协议,不过我们一般仍然把WebSocket服务器端部署到Web服务器上,因为可以借助HT…...

【学术投稿】第五届计算机网络安全与软件工程(CNSSE 2025)
重要信息 官网:www.cnsse.org 时间:2025年2月21-23日 地点:中国-青岛 简介 第五届计算机网络安全与软件工程(CNSSE 2025)将于2025年2月21-23日在中国-青岛举行。CNSSE 2025专注于计算机网络安全、软件工程、信号处…...

26~31.ppt
目录 26.北京主要的景点 题目 解析 27.创新产品展示及说明会 题目 解析 28.《小企业会计准则》 题目 解析 29.学习型社会的学习理念 题目 解析 30.小王-产品展示信息 题目 解析 31.小王-办公理念-信息工作者的每一天 题目 解析 26.北京主要的景点…...