深度学习-神经机器翻译模型
以下为你介绍使用Python和深度学习框架Keras(基于TensorFlow后端)实现一个简单的神经机器翻译模型的详细步骤和代码示例,该示例主要处理英 - 法翻译任务。
1. 安装必要的库
首先,确保你已经安装了以下库:
pip install tensorflow keras numpy pandas
2. 代码实现
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense# 示例数据,实际应用中应使用大规模数据集
english_sentences = ['I am a student', 'He likes reading books', 'She is very beautiful']
french_sentences = ['Je suis un étudiant', 'Il aime lire des livres', 'Elle est très belle']# 对输入和目标文本进行分词处理
input_tokenizer = Tokenizer()
input_tokenizer.fit_on_texts(english_sentences)
input_sequences = input_tokenizer.texts_to_sequences(english_sentences)target_tokenizer = Tokenizer()
target_tokenizer.fit_on_texts(french_sentences)
target_sequences = target_tokenizer.texts_to_sequences(french_sentences)# 获取输入和目标词汇表的大小
input_vocab_size = len(input_tokenizer.word_index) + 1
target_vocab_size = len(target_tokenizer.word_index) + 1# 填充序列以确保所有序列长度一致
max_input_length = max([len(seq) for seq in input_sequences])
max_target_length = max([len(seq) for seq in target_sequences])input_sequences = pad_sequences(input_sequences, maxlen=max_input_length, padding='post')
target_sequences = pad_sequences(target_sequences, maxlen=max_target_length, padding='post')# 定义编码器模型
encoder_inputs = Input(shape=(max_input_length,))
encoder_embedding = Dense(256)(encoder_inputs)
encoder_lstm = LSTM(256, return_state=True)
_, state_h, state_c = encoder_lstm(encoder_embedding)
encoder_states = [state_h, state_c]# 定义解码器模型
decoder_inputs = Input(shape=(max_target_length,))
decoder_embedding = Dense(256)(decoder_inputs)
decoder_lstm = LSTM(256, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_embedding, initial_state=encoder_states)
decoder_dense = Dense(target_vocab_size, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)# 定义完整的模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)# 编译模型
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy')# 训练模型
model.fit([input_sequences, target_sequences[:, :-1]], target_sequences[:, 1:],epochs=100, batch_size=1)# 定义编码器推理模型
encoder_model = Model(encoder_inputs, encoder_states)# 定义解码器推理模型
decoder_state_input_h = Input(shape=(256,))
decoder_state_input_c = Input(shape=(256,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_embedding, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs,[decoder_outputs] + decoder_states)# 实现翻译函数
def translate_sentence(input_seq):states_value = encoder_model.predict(input_seq)target_seq = np.zeros((1, 1))target_seq[0, 0] = target_tokenizer.word_index['<start>'] # 假设存在 <start> 标记stop_condition = Falsedecoded_sentence = ''while not stop_condition:output_tokens, h, c = decoder_model.predict([target_seq] + states_value)sampled_token_index = np.argmax(output_tokens[0, -1, :])sampled_word = target_tokenizer.index_word[sampled_token_index]decoded_sentence += ' ' + sampled_wordif (sampled_word == '<end>' orlen(decoded_sentence) > max_target_length):stop_condition = Truetarget_seq = np.zeros((1, 1))target_seq[0, 0] = sampled_token_indexstates_value = [h, c]return decoded_sentence# 测试翻译
test_input = input_tokenizer.texts_to_sequences(['I am a student'])
test_input = pad_sequences(test_input, maxlen=max_input_length, padding='post')
translation = translate_sentence(test_input)
print("Translation:", translation)
3. 代码解释
- 数据预处理:使用
Tokenizer对英文和法文句子进行分词处理,将文本转换为数字序列。然后使用pad_sequences对序列进行填充,使所有序列长度一致。 - 模型构建:
- 编码器:使用LSTM层处理输入序列,并返回隐藏状态和单元状态。
- 解码器:以编码器的状态作为初始状态,使用LSTM层生成目标序列。
- 全连接层:将解码器的输出通过全连接层转换为目标词汇表上的概率分布。
- 模型训练:使用
fit方法对模型进行训练,训练时使用编码器输入和部分解码器输入来预测解码器的下一个输出。 - 推理阶段:分别定义编码器推理模型和解码器推理模型,通过迭代的方式生成翻译结果。
4. 注意事项
- 此示例使用的是简单的示例数据,实际应用中需要使用大规模的平行语料库,如WMT数据集等。
- 可以进一步优化模型,如使用注意力机制、更复杂的网络结构等,以提高翻译质量。
相关文章:

深度学习-神经机器翻译模型
以下为你介绍使用Python和深度学习框架Keras(基于TensorFlow后端)实现一个简单的神经机器翻译模型的详细步骤和代码示例,该示例主要处理英 - 法翻译任务。 1. 安装必要的库 首先,确保你已经安装了以下库: pip insta…...

Android Camera API 介绍
一 StreamConfigurationMap 1. StreamConfigurationMap 的作用 StreamConfigurationMap 是 Android Camera2 API 中的一个核心类,用于描述相机设备支持的输出流配置,包含以下信息: 支持的格式与分辨率:例如 YUV_420_888、JPEG、…...
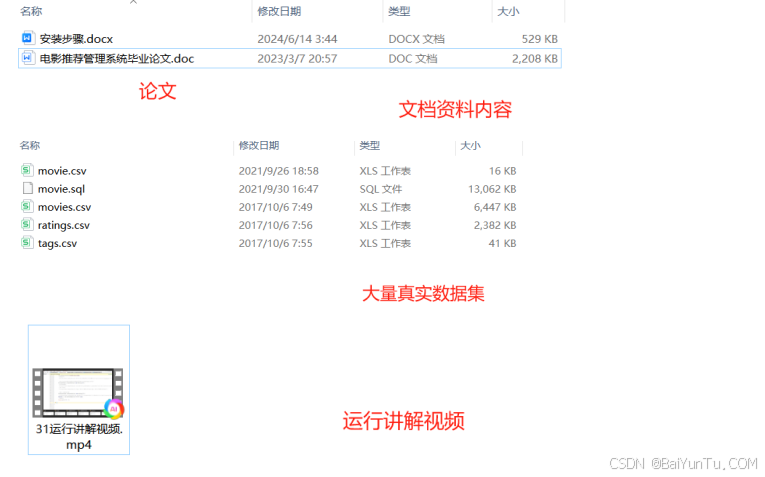
大数据项目2:基于hadoop的电影推荐和分析系统设计和实现
前言 大数据项目源码资料说明: 大数据项目资料来自我多年工作中的开发积累与沉淀。 我分享的每个项目都有完整代码、数据、文档、效果图、部署文档及讲解视频。 可用于毕设、课设、学习、工作或者二次开发等,极大提升效率! 1、项目目标 本…...
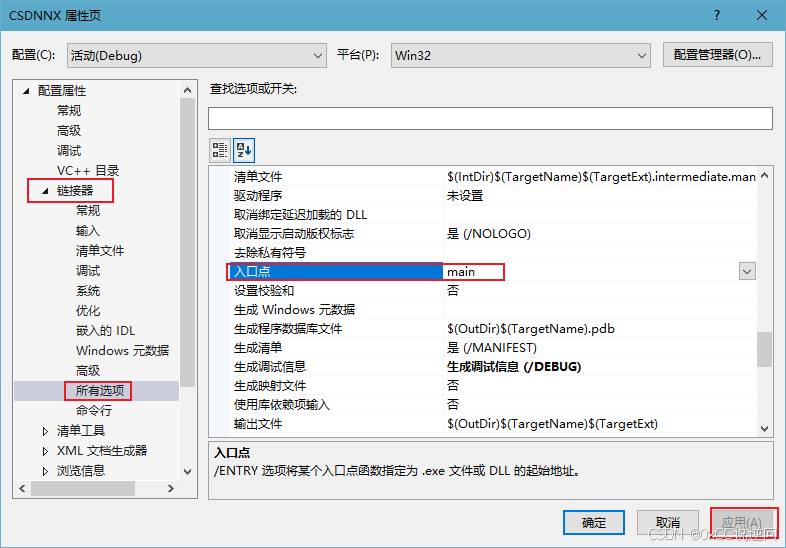
Windows逆向工程入门之汇编环境搭建
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 Visual Studio逆向工程配置 基础环境搭建 Visual Studio 官方下载地址安装配置选项(后期可随时通过VS调整) 使用C的桌面开发 拓展可选选项 MASM汇编框架 配置MASM汇编项目 创建新项目 选择空…...

gc buffer busy acquire导致的重大数据库性能故障
📢📢📢📣📣📣 作者:IT邦德 中国DBA联盟(ACDU)成员,10余年DBA工作经验 Oracle、PostgreSQL ACE CSDN博客专家及B站知名UP主,全网粉丝10万 擅长主流Oracle、MySQL、PG、高斯…...
)
前端学习-页面加载事件和页面滚动事件(三十二)
目录 前言 页面加载事件和页面滚动事件 页面加载事件 load事件 语法 注意 DOMContentLoaded事件 语法 总结 页面加载事件有哪两个?如何添加? load 事件 DOMContentLoaded事件 页面滚动事件 存在原因 scroll监听整个页面滚动 页面滚动事件-获取位置 scrollLef…...

C++:将函数参数定义为const T的意义
C++很多函数的参数都会定义为const T&,那么这么做的意义是什么呢? 避免拷贝:通过引用传递参数而不是值传递,可以避免对象的拷贝,从而提高性能,特别是当对象较大时。 保护数据:使用const关键字可以防止函数修改传入的参数,确保数据的安全性和一致性。 对于保护数据这…...

Formily 如何进行表单验证
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

安宝特方案 | AR眼镜:远程医疗的“时空折叠者”,如何为生命争夺每一分钟?
行业痛点:当“千里求医”遇上“资源鸿沟” 20世纪50年代,远程会诊的诞生曾让医疗界为之一振——患者不必跨越山河,专家无需舟车劳顿,一根电话线、一张传真纸便能架起问诊的桥梁。然而,传统远程医疗的局限也日益凸显&a…...

使用git commit时‘“node“‘ 不是内部或外部命令,也不是可运行的程序
第一种: 使用git commit -m "xxx"时会报错,我看网上的方法是在命令行后面添加--no-verify:git commit -m "主题更新" --no-verify,但是不可能每次都添加。 最后解决办法是:使用git config --lis…...

Python分享20个Excel自动化脚本
在数据处理和分析的过程中,Excel文件是我们日常工作中常见的格式。通过Python,我们可以实现对Excel文件的各种自动化操作,提高工作效率。 本文将分享20个实用的Excel自动化脚本,以帮助新手小白更轻松地掌握这些技能。 1. Excel单…...

nodejs - vue 视频切片上传,本地正常,线上环境导致磁盘爆满bug
nodejs 视频切片上传,本地正常,线上环境导致磁盘爆满bug 原因: 然后在每隔一分钟执行du -sh ls ,发现文件变得越来越大,即文件下的mp4文件越来越大 最后导致磁盘直接爆满 排查原因 1、尝试将m3u8文件夹下的所有视…...

瑞友天翼应用虚拟化系统 GetPwdPolicy SQL注入漏洞复现
免责声明 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在使…...

【MySQL — 数据库基础】深入解析MySQL的聚合查询
1. 聚合查询 1.1 聚合函数 函数说明COUNT ( [DISTINCT] expr)返回查询到的数据的数量( 行数 )SUM ( [DISTINCT] expr)返回查询到的数据的总和,不是数字没有意义AVG ( [DISTINCT] expr)返回查询到的数据的平均值,不是数字没有意义MAX( [DISTINCT] expr)…...

22.3、IIS安全分析与增强
目录 IIS安全威胁分析iis安全机制iis安全增强 IIS安全威胁分析 iis是微软公司的Web服务软件,主要提供网页服务,除此之外还可以提供其他服务,第一个最主要的是网页服务,第二个是SMTP邮件服务,第三个是FTP文件传输服务。…...

windows平台本地部署DeepSeek大模型+Open WebUI网页界面(可以离线使用)
环境准备: 确定部署方案请参考:DeepSeek-R1系列(1.5b/7b/8b/32b/70b/761b)大模型部署需要什么硬件条件-CSDN博客 根据本人电脑配置:windows11 + i9-13900HX+RTX4060+DDR5 5600 32G内存 确定部署方案:DeepSeek-R1:7b + Ollama + Open WebUI 1. 安装 Ollama Ollama 是一…...

港中文腾讯提出可穿戴3D资产生成方法BAG,可自动生成服装和配饰等3D资产如,并适应特定的人体模型。
今天给大家介绍一种名为BAG(Body-Aligned 3D Wearable Asset Generation)的新方法,可以自动生成可穿戴的3D资产,如服装和配饰,以适应特定的人体模型。BAG方法通过构建一个多视图图像扩散模型,生成与人体对齐…...
模型:实现机器翻译)
【人工智能】Python中的序列到序列(Seq2Seq)模型:实现机器翻译
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 序列到序列(Seq2Seq)模型是自然语言处理(NLP)中一项核心技术,广泛应用于机器翻译、语音识别、文本摘要等任务。本文深入探讨Seq2Seq模…...

34.日常算法
1.合并区间 题目来源 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入&#x…...
架构设计指南)
DeepSeek深度思考:客户端(Android/iOS)架构设计指南
目标读者:中高级开发者、架构师 适用场景:大型复杂应用开发、跨团队协作、长期维护迭代 一、架构设计核心原则 1.模块化(Modularization) 横向拆分:按功能边界划分(如登录、支付、消息模块)纵向…...

2025 年前端开发现状分析:卷疯了还是卷麻了?
一、前端现状:框架狂飙,开发者崩溃 如果你是个前端开发者,那么你大概率经历过这些场景: 早上打开 CSDN(或者掘金,随便),发现又有新框架发布了,名字可能是 VueXNext.js 之…...

数据库 绪论
目录 数据库基本概念 一.基本概念 1.信息 2.数据 3.数据库(DB) 4.数据库管理系统(DBMS) 5.数据库系统(DBS) 二.数据管理技术的发展 1.人工管理阶段 2.文件系统阶段 3.数据库系统阶段 4.数据库管…...

【AIGC魔童】DeepSeek v3提示词Prompt书写技巧
【AIGC魔童】DeepSeek v3提示词Prompt书写技巧 (1)基础通用公式(适用80%场景)(2)问题解决公式(决策支持)(3)创意生成公式(4)学习提升公…...

Docker 部署 RabbitMQ | 自带延时队列
一、获取镜像 docker pull farerboy/rabbitmq:3.9.9 二、运行镜像 docker run -d --name rabbitmq \n --hostname rabbitmq \n -p 15672:15672/tcp \n -p 5672:5672/tcp \n -v /wwwroot/opt/docker/rabbitmq:/var/lib/rabbitmq \n farerboy/rabbitmq:3.9.9 备注:…...

【Unity】Unity中物体的static属性作用
Unity中物体的static属性主要用于优化游戏性能和简化渲染过程。 Unity中物体的static属性的作用 优化渲染性能:当物体被标记为static时,Unity会在游戏运行时将其视为静止的物体,这意味着这些物体的渲染信息不会随着每一帧的更新而变化…...

网络编程基础1
七层协议模型和四层协议模型 七层协议模型:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层 四层协议模型:链路层、网络层、传输层、应用层 TCP通信流程 服务器端 (1)创建socket(socket) (2)绑定自己的IP(bind) (3)监听客户端连接(liste…...

跨越边界,大模型如何助推科技与社会的完美结合?
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 概述 2024年,大模型技术已成为人工智能领域的焦点。这不仅仅是一项技术进步,更是一次可能深刻影响社会发展方方面面的变革。大模型的交叉能否推动技术与社会的真正融合?2025年…...

kafka生产端之架构及工作原理
文章目录 整体架构元数据更新 整体架构 消息在真正发往Kafka之前,有可能需要经历拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)等一系列的作用,那么在此之后又会…...

在 Windows 上使用 ZIP 包安装 MySQL 的详细步骤
以下是使用官方 ZIP 包在 Windows 上安装 MySQL 的详细步骤,确保能通过 mysql -uroot -p 成功连接。 步骤 1:下载 MySQL ZIP 包 访问 MySQL 官方下载页面: https://dev.mysql.com/downloads/mysql/选择 Windows (x86, 64-bit), ZIP Archive&…...

【web自动化】指定chromedriver以及chrome路径
selenium自动化,指定chromedriver,以及chrome路径 对应这篇文章,可以点击查看,详情 from selenium import webdriverdef get_driver():# 获取配置对象option webdriver.ChromeOptions()option.add_experimental_option("de…...