kafka 3.5.0 raft协议安装
前言
最近做项目,需要使用kafka进行通信,且只能使用kafka,笔者没有测试集群,就自己搭建了kafka集群,实际上笔者在很早之前就搭建了,因为当时还是zookeeper(简称ZK)注册元数据,现在新版kafka(3.0.0开始)已经自带了元数据能力(使用raft协议)减少了kafka对zk的依赖性。笔者在查询资料发现,说jdk至少jdk11,实测jdk8也能运行,且并不需要网上说的3+4节点,3+3即可,当然理论上broker节点越多越好,但是元数据节点建议3、5个最合适,raft的过半一致性和容错性的综合取舍。
准备
准备kafka安装包:Apache Kafka

笔者使用的kafka 3.5.0和scala 2.13,采用3台虚拟机,当然容器也不是不行,注意持久化pv pvc和配置的管理(ip换成域名,dns的切换支持),中间件建议使用虚拟机,可以降低很多容错性。
jdk使用open jdk,配置java_home和path,以Ubuntu为例
sudo apt install openjdk-8-jdk-headless
以macOS为例,创建一个ubuntu-server 最小安装的虚拟机(vmware,毕竟个人使用不要钱),然后安装openssh 和 openjdk,然后shutdown now

网络选择桥接,相当于一台“真实在”网络上的一台物理机

这样就得到了
192.168.0.108
192.168.0.107
192.168.0.106
3台虚拟机
步骤
先看kafka集群的架构图,实际上安装的过程就是架构图的执行过程

从图中可以看出已经没有zk的存在了,从kafka节点自己管理元数据,通过raft协议选主的方式。
1. kafka的准备
上传kafka安装包,必须是二进制安装包,不要源码包,编译比较麻烦,然后解压
tar -zxvf kafka_2.13-3.5.0.gz
查看配置目录会发现

明显多了kraft的配置目录,那么如果使用kafka raft元数据中心,则需要修改kraft目录,启动时指定kraft目录的配置
2. 配置修改
raft协议实际上跟zk差不多,使用raft协议的中间件就太多了,但是本质上每个节点都需要一个唯一id,zk也是如此,所以kafka kraft就相当于集成的zk。
在kraft下的有3个文件文件,其中启动相关的是server.properties中

执行配置修改
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller# The node id associated with this instance's roles
node.id=1# The connect string for the controller quorum
controller.quorum.voters=1@localhost:9093############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092,CONTROLLER://:9093# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://localhost:9092# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=/tmp/kraft-combined-logs# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
每一行都有注释,重点关注
笔者设定
192.168.0.106 nodeid 1
192.168.0.107 nodeid 2
192.168.0.108 nodeid 3

至此配置基本上完成,同理一个节点可以同时是controller和broker,也可以仅仅是controller或者broker,因为controller的负载比较轻,所以一般是和broker一起。其中有个log.dir这个的路径是下面元数据生成的路径(选主)和数据事务日志,索引日志的存储目录
3. 启动
1. 生成uuid

任意找一个节点执行:
./kafka-storage.sh random-uuid
每次执行uuid会不一样,这个uuid标识是一个集群,所以所有节点公用一个uuid,不要每个节点重新生成,会识别不了
![]()
然后执行format,如下标红是我生成的,这个每次不是固定的
./kafka-storage.sh format -t gZzkfRm4T1y8wSAY-ZNG5Q -c ../config/kraft/server.properties
格式化配置文件,同步其他节点
![]()
配置文件有什么变化?在日志配置的目录下出现

关键还是meta的文件,有集群id和节点id,版本号,这个对启动至关重要。
即在上面的log.dir的目录生成,所以尽量不能使用临时目录
2. 启动
启动就很简单了,使用刚刚配置的server.properties执行启动即可
./kafka-server-start.sh -daemon ../config/kraft/server.properties
不过为了方便查看启动日志,建议执行日志的console文件输出
先看事务日志和索引

验证
验证很简单,查看bin同级目录下的日志即可

日志带有[2025-02-08 08:34:12,286] INFO [KafkaRaftServer nodeId=1] Kafka Server started (kafka.server.KafkaRaftServer)
如果生成用途可以安装kafka的控制台,kafka-ui,不过我这里就不安装了,因为docker安装比较容易。
总结
kafka从3.0.0开始推出了raft模式的元数据中心,实际上类似zk,kafka自己命名kraft。使用这种方式搭建kafka集群将不再需要zk,同理,kafka的集群的每个节点可以同时是broker和controller(以前zk充当),也可以是单独的broker,controller(负载不重,不建议单独controller,跟zk没区别),官方说明需要jdk11及以上,实测jdk8可以运行,但是生成建议严格按照官方标定的jdk执行,jdk是向下兼容的,但是不确定是否会涉及新api或新特性的使用。
另外实际使用中,可能会涉及使用iptables做nat限制kafka的连接方,比如在kafka节点通过iptables限制发送者或者消费端的ip
iptables -t nat -A PREROUTING -p tcp -m tcp --dport 9093 -j DNAT --to-destination kafkaxxx:9093
kafkaxxx --- 指定的是 Kafka 服务所在的机器地址
如果kafka是对接方提供,则在nat打通时,需要客户端连接的服务器也执行iptables,否则可能出现连接kafka正常,但是不能消费。
iptables -t nat -A POSTROUTING -p tcp -m tcp --dport 9093 -j SNAT --to-source natxxx
natxxx --- 指定的是配置 iptables 的本机的地址
相关文章:
kafka 3.5.0 raft协议安装
前言 最近做项目,需要使用kafka进行通信,且只能使用kafka,笔者没有测试集群,就自己搭建了kafka集群,实际上笔者在很早之前就搭建了,因为当时还是zookeeper(简称ZK)注册元数据&#…...

用Kibana实现Elasticsearch索引的增删改查:实战指南
在大数据时代,Elasticsearch(简称 ES)和 Kibana 作为强大的数据搜索与可视化工具,受到了众多开发者的青睐。Kibana 提供了一个直观的界面,可以方便地对 Elasticsearch 中的数据进行操作。本文将详细介绍如何使用 Kiban…...

Redis基础笔记
一、基础知识 连接方式 CLI (Command Line Interface)API (Application Programming Interface)GUI (Graphical User Interface) 启动 redis-server连接到Redis(Redis CLI Client) redis redis-cli telnet 127.0.0.1 6379退出 quit/exit查看过期时…...

前后端服务配置
1、安装虚拟机(VirtualBox或者vmware),在虚拟机上配置centos(选择你需要的Linux版本),配置如nginx服务器等 1.1 VMware 下载路径Sign In注册下载 1.2 VirtualBox 下载路径https://www.virtualbox.org/wiki/Downloads 2、配置服…...

springboot 事务管理
在Spring Boot中,事务管理是通过Spring框架的事务管理模块来实现的。Spring提供了声明式事务管理和编程式事务管理两种方式。通常,我们使用声明式事务管理,因为它更简洁且易于维护。 1. 声明式事务管理 声明式事务管理是通过注解来实现的。…...

基于Typescript,使用Vite构建融合Vue.js的Babylon.js开发环境
一、创建Vite项目 使用Vite初始化一个VueTypeScript项目: npm create vitelatest my-babylon-app -- --template vue-ts cd my-babylon-app npm create vitelatest my-babylon-app -- --template vue-ts 命令用于快速创建一个基于 Vite 的 Vue TypeScript 项目。…...

在阿里云ECS上一键部署DeepSeek-R1
DeepSeek-R1 是一款开源模型,也提供了 API(接口)调用方式。据 DeepSeek介绍,DeepSeek-R1 后训练阶段大规模使用了强化学习技术,在只有极少标注数据的情况下提升了模型推理能力,该模型性能对标 OpenAl o1 正式版。DeepSeek-R1 推出…...

git SourceTree 使用
Source Tree 使用原理 文件的状态 创建仓库和提交 验证 再克隆的时候发发现一个问题,就是有一个 这个验证,起始很简单 就是 gitee 的账号和密码,但是要搞清楚的是账号不是名称,我之前一直再使用名称登录老是出问题 这个很简单的…...

游戏引擎学习第94天
仓库:https://gitee.com/mrxiao_com/2d_game_2 回顾上周的渲染器工作 完成一款游戏的开发,完全不依赖任何库和引擎,这样我们能够全面掌握游戏的开发过程,确保没有任何细节被隐藏。我们将深入探索每一个环节,犹如拿着手电筒翻看床…...

win32汇编环境,结构体的使用示例二
;运行效果 ;win32汇编环境,结构体的使用示例二 ;举例说明结构体的定义,如何访问其中的成员,使用assume指令指向某个结构体,计算结构数组所需的偏移量得到某个成员值等 ;直接抄进RadAsm可编译运行。重要部分加备注。 ;下面为asm文件 ;>>…...

DeepSeek从入门到精通教程PDF清华大学出版
DeepSeek爆火以来,各种应用方式层出不穷,对于很多人来说,还是特别模糊,有种雾里看花水中望月的感觉。 最近,清华大学新闻与传播学院新媒体研究中心,推出了一篇DeepSeek的使用教程,从最基础的是…...

【PDF提取内容】如何批量提取PDF里面的文字内容,把内容到处表格或者批量给PDF文件改名,基于C++的实现方案和步骤
以下分别介绍基于 C 批量提取 PDF 里文字内容并导出到表格,以及批量给 PDF 文件改名的实现方案、步骤和应用场景。 批量提取 PDF 文字内容并导出到表格 应用场景 文档数据整理:在处理大量学术论文、报告等 PDF 文档时,需要提取其中的关键信…...

SSA-TCN麻雀算法优化时间卷积神经网络时间序列预测未来Matlab实现
SSA-TCN麻雀算法优化时间卷积神经网络时间序列预测未来Matlab实现 目录 SSA-TCN麻雀算法优化时间卷积神经网络时间序列预测未来Matlab实现预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现SSA-TCN麻雀算法优化时间卷积神经网络时间序列预测未来(优…...

大模型推理——MLA实现方案
1.整体流程 先上一张图来整体理解下MLA的计算过程 2.实现代码 import math import torch import torch.nn as nn# rms归一化 class RMSNorm(nn.Module):""""""def __init__(self, hidden_size, eps1e-6):super().__init__()self.weight nn.Pa…...

深度学习-神经机器翻译模型
以下为你介绍使用Python和深度学习框架Keras(基于TensorFlow后端)实现一个简单的神经机器翻译模型的详细步骤和代码示例,该示例主要处理英 - 法翻译任务。 1. 安装必要的库 首先,确保你已经安装了以下库: pip insta…...

Android Camera API 介绍
一 StreamConfigurationMap 1. StreamConfigurationMap 的作用 StreamConfigurationMap 是 Android Camera2 API 中的一个核心类,用于描述相机设备支持的输出流配置,包含以下信息: 支持的格式与分辨率:例如 YUV_420_888、JPEG、…...
大数据项目2:基于hadoop的电影推荐和分析系统设计和实现
前言 大数据项目源码资料说明: 大数据项目资料来自我多年工作中的开发积累与沉淀。 我分享的每个项目都有完整代码、数据、文档、效果图、部署文档及讲解视频。 可用于毕设、课设、学习、工作或者二次开发等,极大提升效率! 1、项目目标 本…...
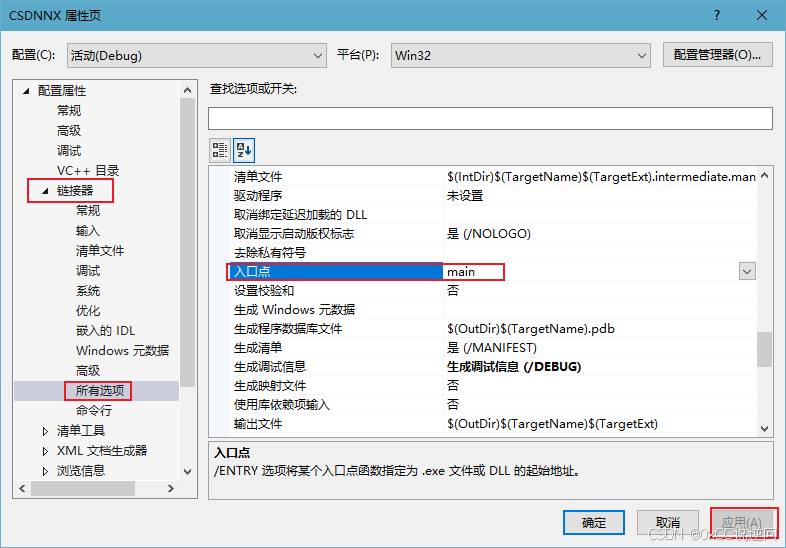
Windows逆向工程入门之汇编环境搭建
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 Visual Studio逆向工程配置 基础环境搭建 Visual Studio 官方下载地址安装配置选项(后期可随时通过VS调整) 使用C的桌面开发 拓展可选选项 MASM汇编框架 配置MASM汇编项目 创建新项目 选择空…...

gc buffer busy acquire导致的重大数据库性能故障
📢📢📢📣📣📣 作者:IT邦德 中国DBA联盟(ACDU)成员,10余年DBA工作经验 Oracle、PostgreSQL ACE CSDN博客专家及B站知名UP主,全网粉丝10万 擅长主流Oracle、MySQL、PG、高斯…...
)
前端学习-页面加载事件和页面滚动事件(三十二)
目录 前言 页面加载事件和页面滚动事件 页面加载事件 load事件 语法 注意 DOMContentLoaded事件 语法 总结 页面加载事件有哪两个?如何添加? load 事件 DOMContentLoaded事件 页面滚动事件 存在原因 scroll监听整个页面滚动 页面滚动事件-获取位置 scrollLef…...

C++:将函数参数定义为const T的意义
C++很多函数的参数都会定义为const T&,那么这么做的意义是什么呢? 避免拷贝:通过引用传递参数而不是值传递,可以避免对象的拷贝,从而提高性能,特别是当对象较大时。 保护数据:使用const关键字可以防止函数修改传入的参数,确保数据的安全性和一致性。 对于保护数据这…...

Formily 如何进行表单验证
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

安宝特方案 | AR眼镜:远程医疗的“时空折叠者”,如何为生命争夺每一分钟?
行业痛点:当“千里求医”遇上“资源鸿沟” 20世纪50年代,远程会诊的诞生曾让医疗界为之一振——患者不必跨越山河,专家无需舟车劳顿,一根电话线、一张传真纸便能架起问诊的桥梁。然而,传统远程医疗的局限也日益凸显&a…...

使用git commit时‘“node“‘ 不是内部或外部命令,也不是可运行的程序
第一种: 使用git commit -m "xxx"时会报错,我看网上的方法是在命令行后面添加--no-verify:git commit -m "主题更新" --no-verify,但是不可能每次都添加。 最后解决办法是:使用git config --lis…...

Python分享20个Excel自动化脚本
在数据处理和分析的过程中,Excel文件是我们日常工作中常见的格式。通过Python,我们可以实现对Excel文件的各种自动化操作,提高工作效率。 本文将分享20个实用的Excel自动化脚本,以帮助新手小白更轻松地掌握这些技能。 1. Excel单…...

nodejs - vue 视频切片上传,本地正常,线上环境导致磁盘爆满bug
nodejs 视频切片上传,本地正常,线上环境导致磁盘爆满bug 原因: 然后在每隔一分钟执行du -sh ls ,发现文件变得越来越大,即文件下的mp4文件越来越大 最后导致磁盘直接爆满 排查原因 1、尝试将m3u8文件夹下的所有视…...

瑞友天翼应用虚拟化系统 GetPwdPolicy SQL注入漏洞复现
免责声明 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在使…...

【MySQL — 数据库基础】深入解析MySQL的聚合查询
1. 聚合查询 1.1 聚合函数 函数说明COUNT ( [DISTINCT] expr)返回查询到的数据的数量( 行数 )SUM ( [DISTINCT] expr)返回查询到的数据的总和,不是数字没有意义AVG ( [DISTINCT] expr)返回查询到的数据的平均值,不是数字没有意义MAX( [DISTINCT] expr)…...

22.3、IIS安全分析与增强
目录 IIS安全威胁分析iis安全机制iis安全增强 IIS安全威胁分析 iis是微软公司的Web服务软件,主要提供网页服务,除此之外还可以提供其他服务,第一个最主要的是网页服务,第二个是SMTP邮件服务,第三个是FTP文件传输服务。…...

windows平台本地部署DeepSeek大模型+Open WebUI网页界面(可以离线使用)
环境准备: 确定部署方案请参考:DeepSeek-R1系列(1.5b/7b/8b/32b/70b/761b)大模型部署需要什么硬件条件-CSDN博客 根据本人电脑配置:windows11 + i9-13900HX+RTX4060+DDR5 5600 32G内存 确定部署方案:DeepSeek-R1:7b + Ollama + Open WebUI 1. 安装 Ollama Ollama 是一…...