大数据学习之SparkSql

95.SPARKSQL_简介

96.SPARKSQL_发展史
97.SPARKSQL_与HIVE区别

98.SPARKSQL_SPARKSESSION

99.SPARKSQL_数据抽象


100.SPARKSQL_DATAFRAME概述

101.SPARKSQL_DATASET概述

102.SPARKSQL_DATAFRAME构成


103.SPARKSQL_创建项目


104.SPARKSQL_createDataFrame创建DF
SparkSQL_toDF创建DF


105.SPARKSQL_toDF创建DF

106.SPARKSQL_toDF使用样例创建DF



107.SPARKSQL_DataFrame转换RDD


108.SPARKSQL_创建DATASET


109.SPARKSQL_DATASET和RDD转换


110.SPARKSQL_DATASET和DATAFRAME转换


111.SPARKSQL_读写parquet文件



112.SPARKSQL_读写parquet文件扩展


113.SPARKSQL_读写text文件


114.SPARKSQL_读写JSON文件



115.SPARKSQL_读写csv文件


116.SPARKSQL_JDBC读写MYSQL


117.SPARKSQL_JDBC写MYSQL




118.SPARKSQL_SPARKONHIVE概述


119.SPARKSQL_SPARKONHIVE配置


120.SPARKSQL_SPARKONHIVE代码开发一


121.SPARKSQL_SPARKONHIVE代码开发二



122.SPARKSQL_SPARKONHIVE代码集群提交


123.SPARKSQL_DSL_API



124.SPARKSQL_数据去重



125.SPARKSQL_function包



126.SPARKSQL_SQL API



127.SPARKSQL_SQL API实战


128.SPARKSQL_自定义函数概述


129.SPARKSQL_自定义UDF函数



130.SPARKSQL_自定义UDF函数扩展



131.SPARKSQL_ARRAYTYPE返回值类型的UDF



132.SPARKSQL_UDAF函数OLD一



133.SPARKSQL_UDAF函数OLD二


134.SPARKSQL_UDAF函数OLD三


135.SPARKSQL_UDAF函数OLD四


136.SPARKSQL_UDAF函数NEW一


137.SPARKSQL_UDAF函数NEW二

138.SPARKSQL_UDAF函数NEW三


139.SPARKSQL_开窗函数概述


140.SPARKSQL_开窗函数实战



141.SPARKSQL实战_找出变化的行一

142.SPARKSQL实战_找出变化的行二


143.SPARKSQL实战_函数转换JSON数据


144.SPARKSQL实战_读取嵌套的json


145.SPARKSQL实战_解析JSONARRAY数据


146.SPARKSQL实战_行转换行一


147.SPARKSQL实战_行转换行二


148.SPARKSQL实战_行转换行三


149.SPARKSQL实战_行转换行四


150.SPARKSQL实战_用户7日留存分析一


151.SPARKSQL实战_用户7日留存分析二



152.SPARKSQL实战_用户7日留存分析三



153.SPARKSQL实战_统计访问总时长一


154.SPARKSQL实战_统计访问总时长二


155.SPARKSQL实战_用户在线分析_需求分析


156.SPARKSQL实战_用户在线分析_错位关联


157.SPARKSQL实战_用户在线分析_数据补全和过滤


158.SPARKSQL实战_用户在线分析_总时长_次数_最大时长


159.SPARKSQL实战_用户在线分析_每小时在线人数一


160.SPARKSQL实战_用户在线分析_每小时在线人数二


161.SPARKSQL实战_用户在线分析_每小时在线人数三


162.SPARKSQL实战_用户在线分析_每小时在线人数四


相关文章:
大数据学习之SparkSql
95.SPARKSQL_简介 网址: https://spark.apache.org/sql/ Spark SQL 是 Spark 的一个模块,用于处理 结构化的数据 。 SparkSQL 特点 1 易整合 无缝的整合了 SQL 查询和 Spark 编程,随时用 SQL 或 DataFrame API 处理结构化数据。并且支…...

鸿蒙UI(ArkUI-方舟UI框架)- 使用文本
返回主章节 → 鸿蒙UI(ArkUI-方舟UI框架) 文本使用 文本显示 (Text/Span) Text是文本组件,通常用于展示用户视图,如显示文章的文字内容。Span则用于呈现显示行内文本。 创建文本 string字符串 Text("我是一段文本"…...

Spider 数据集上实现nlp2sql训练任务
NLP2SQL(自然语言处理到 SQL 查询的转换)是一个重要的自然语言处理(NLP)任务,其目标是将用户的自然语言问题转换为相应的 SQL 查询。这一任务在许多场景下具有广泛的应用,尤其是在与数据库交互的场景中&…...

数据结构——【树模板】
#思路 1、 结点类: 属性:数据,孩子结点列表 功能1:认孩子: 前提:在父子都是结点的情况下 2. 树类: 属性:根节点,生成初始化的总结点 功能1:获取初始化…...

R 数组:高效数据处理的基础
R 数组:高效数据处理的基础 引言 在数据科学和统计分析领域,R 语言以其强大的数据处理和分析能力而备受推崇。R 数组是 R 语言中用于存储和操作数据的基本数据结构。本文将详细介绍 R 数组的创建、操作和优化,帮助读者掌握 R 数组的使用技巧…...

【DeepSeek】DeepSeek概述 | 本地部署deepseek
目录 1 -> 概述 1.1 -> 技术特点 1.2 -> 模型发布 1.3 -> 应用领域 1.4 -> 优势与影响 2 -> 本地部署 2.1 -> 安装ollama 2.2 -> 部署deepseek-r1模型 1 -> 概述 DeepSeek是由中国的深度求索公司开发的一系列人工智能模型,以其…...

npm link,lerna,pnmp workspace区别
npm link、Lerna 和 pnpm workspace 是三种不同的工具/功能,用于处理 JavaScript 项目的依赖管理和 Monorepo 场景。它们的核心区别如下: 1. npm link 用途 本地调试依赖:将本地开发的包(Package A)临时链接到另一个…...

ASP.NET Core 使用 WebClient 从 URL 下载
本文使用 ASP .NET Core 3.1,但它在.NET 5、 .NET 6和.NET 8上也同样适用。如果使用较旧的.NET Framework,请参阅本文,不过,变化不大。 如果想要从 URL 下载任何数据类型,请参阅本文:HttpClient 使用WebC…...

【CubeMX-HAL库】STM32F407—无刷电机学习笔记
目录 简介: 学习资料: 跳转目录: 一、工程创建 二、板载LED 三、用户按键 四、蜂鸣器 1.完整IO控制代码 五、TFT彩屏驱动 六、ADC多通道 1.通道确认 2.CubeMX配置 ①开启对应的ADC通道 ②选择规则组通道 ③开启DMA ④开启ADC…...

vue3 点击图标从相册选择二维码图片,并使用jsqr解析二维码(含crypto-js加密解密过程)
vue3 点击图标从相册选择二维码图片,并使用jsqr解析二维码(含crypto-js加密解密过程) 1.安装 jsqr 和 crypto-js npm install -d jsqr npm install crypto-js2.在util目录下新建encryptionHelper.js文件,写加密解密方法。 // e…...

kafka 3.5.0 raft协议安装
前言 最近做项目,需要使用kafka进行通信,且只能使用kafka,笔者没有测试集群,就自己搭建了kafka集群,实际上笔者在很早之前就搭建了,因为当时还是zookeeper(简称ZK)注册元数据&#…...

用Kibana实现Elasticsearch索引的增删改查:实战指南
在大数据时代,Elasticsearch(简称 ES)和 Kibana 作为强大的数据搜索与可视化工具,受到了众多开发者的青睐。Kibana 提供了一个直观的界面,可以方便地对 Elasticsearch 中的数据进行操作。本文将详细介绍如何使用 Kiban…...

Redis基础笔记
一、基础知识 连接方式 CLI (Command Line Interface)API (Application Programming Interface)GUI (Graphical User Interface) 启动 redis-server连接到Redis(Redis CLI Client) redis redis-cli telnet 127.0.0.1 6379退出 quit/exit查看过期时…...

前后端服务配置
1、安装虚拟机(VirtualBox或者vmware),在虚拟机上配置centos(选择你需要的Linux版本),配置如nginx服务器等 1.1 VMware 下载路径Sign In注册下载 1.2 VirtualBox 下载路径https://www.virtualbox.org/wiki/Downloads 2、配置服…...

springboot 事务管理
在Spring Boot中,事务管理是通过Spring框架的事务管理模块来实现的。Spring提供了声明式事务管理和编程式事务管理两种方式。通常,我们使用声明式事务管理,因为它更简洁且易于维护。 1. 声明式事务管理 声明式事务管理是通过注解来实现的。…...

基于Typescript,使用Vite构建融合Vue.js的Babylon.js开发环境
一、创建Vite项目 使用Vite初始化一个VueTypeScript项目: npm create vitelatest my-babylon-app -- --template vue-ts cd my-babylon-app npm create vitelatest my-babylon-app -- --template vue-ts 命令用于快速创建一个基于 Vite 的 Vue TypeScript 项目。…...

在阿里云ECS上一键部署DeepSeek-R1
DeepSeek-R1 是一款开源模型,也提供了 API(接口)调用方式。据 DeepSeek介绍,DeepSeek-R1 后训练阶段大规模使用了强化学习技术,在只有极少标注数据的情况下提升了模型推理能力,该模型性能对标 OpenAl o1 正式版。DeepSeek-R1 推出…...

git SourceTree 使用
Source Tree 使用原理 文件的状态 创建仓库和提交 验证 再克隆的时候发发现一个问题,就是有一个 这个验证,起始很简单 就是 gitee 的账号和密码,但是要搞清楚的是账号不是名称,我之前一直再使用名称登录老是出问题 这个很简单的…...

游戏引擎学习第94天
仓库:https://gitee.com/mrxiao_com/2d_game_2 回顾上周的渲染器工作 完成一款游戏的开发,完全不依赖任何库和引擎,这样我们能够全面掌握游戏的开发过程,确保没有任何细节被隐藏。我们将深入探索每一个环节,犹如拿着手电筒翻看床…...

win32汇编环境,结构体的使用示例二
;运行效果 ;win32汇编环境,结构体的使用示例二 ;举例说明结构体的定义,如何访问其中的成员,使用assume指令指向某个结构体,计算结构数组所需的偏移量得到某个成员值等 ;直接抄进RadAsm可编译运行。重要部分加备注。 ;下面为asm文件 ;>>…...

DeepSeek从入门到精通教程PDF清华大学出版
DeepSeek爆火以来,各种应用方式层出不穷,对于很多人来说,还是特别模糊,有种雾里看花水中望月的感觉。 最近,清华大学新闻与传播学院新媒体研究中心,推出了一篇DeepSeek的使用教程,从最基础的是…...

【PDF提取内容】如何批量提取PDF里面的文字内容,把内容到处表格或者批量给PDF文件改名,基于C++的实现方案和步骤
以下分别介绍基于 C 批量提取 PDF 里文字内容并导出到表格,以及批量给 PDF 文件改名的实现方案、步骤和应用场景。 批量提取 PDF 文字内容并导出到表格 应用场景 文档数据整理:在处理大量学术论文、报告等 PDF 文档时,需要提取其中的关键信…...

SSA-TCN麻雀算法优化时间卷积神经网络时间序列预测未来Matlab实现
SSA-TCN麻雀算法优化时间卷积神经网络时间序列预测未来Matlab实现 目录 SSA-TCN麻雀算法优化时间卷积神经网络时间序列预测未来Matlab实现预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现SSA-TCN麻雀算法优化时间卷积神经网络时间序列预测未来(优…...

大模型推理——MLA实现方案
1.整体流程 先上一张图来整体理解下MLA的计算过程 2.实现代码 import math import torch import torch.nn as nn# rms归一化 class RMSNorm(nn.Module):""""""def __init__(self, hidden_size, eps1e-6):super().__init__()self.weight nn.Pa…...

深度学习-神经机器翻译模型
以下为你介绍使用Python和深度学习框架Keras(基于TensorFlow后端)实现一个简单的神经机器翻译模型的详细步骤和代码示例,该示例主要处理英 - 法翻译任务。 1. 安装必要的库 首先,确保你已经安装了以下库: pip insta…...

Android Camera API 介绍
一 StreamConfigurationMap 1. StreamConfigurationMap 的作用 StreamConfigurationMap 是 Android Camera2 API 中的一个核心类,用于描述相机设备支持的输出流配置,包含以下信息: 支持的格式与分辨率:例如 YUV_420_888、JPEG、…...
大数据项目2:基于hadoop的电影推荐和分析系统设计和实现
前言 大数据项目源码资料说明: 大数据项目资料来自我多年工作中的开发积累与沉淀。 我分享的每个项目都有完整代码、数据、文档、效果图、部署文档及讲解视频。 可用于毕设、课设、学习、工作或者二次开发等,极大提升效率! 1、项目目标 本…...
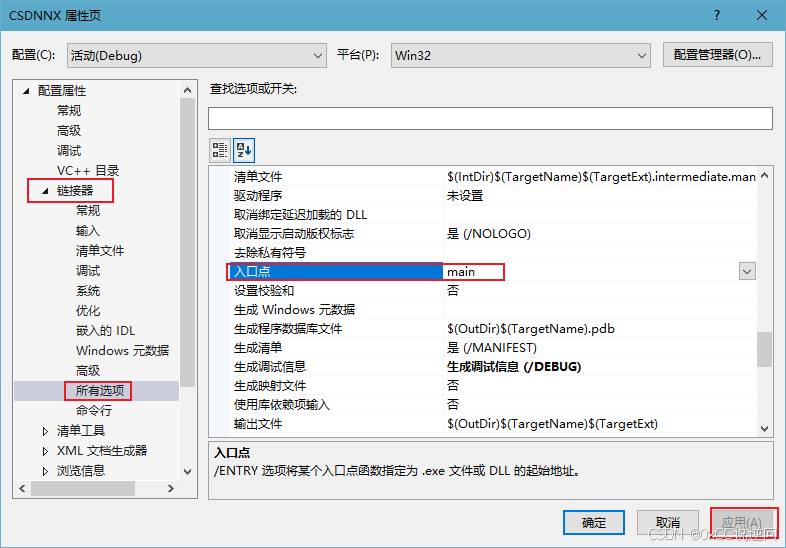
Windows逆向工程入门之汇编环境搭建
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 Visual Studio逆向工程配置 基础环境搭建 Visual Studio 官方下载地址安装配置选项(后期可随时通过VS调整) 使用C的桌面开发 拓展可选选项 MASM汇编框架 配置MASM汇编项目 创建新项目 选择空…...

gc buffer busy acquire导致的重大数据库性能故障
📢📢📢📣📣📣 作者:IT邦德 中国DBA联盟(ACDU)成员,10余年DBA工作经验 Oracle、PostgreSQL ACE CSDN博客专家及B站知名UP主,全网粉丝10万 擅长主流Oracle、MySQL、PG、高斯…...
)
前端学习-页面加载事件和页面滚动事件(三十二)
目录 前言 页面加载事件和页面滚动事件 页面加载事件 load事件 语法 注意 DOMContentLoaded事件 语法 总结 页面加载事件有哪两个?如何添加? load 事件 DOMContentLoaded事件 页面滚动事件 存在原因 scroll监听整个页面滚动 页面滚动事件-获取位置 scrollLef…...