强化学习 DPO 算法:基于人类偏好,颠覆 PPO 传统策略
目录
- 一、引言
- 二、强化学习基础回顾
- (一)策略
- (二)价值函数
- 三、近端策略优化(PPO)算法
- (一)算法原理
- (二)PPO 目标函数
- (三)代码示例(以 OpenAI Gym 环境 CartPole 为例)
- 四、直接偏好优化(DPO)算法
- (一)算法原理
- (二)DPO 目标函数
- (三)代码示例(简单示意,假设已有偏好数据)
- 五、DPO 与 PPO 对比
- (一)数据利用
- (二)优化目标
- (三)应用场景
- 六、案例分析
- (一)对话系统
- (二)自动驾驶
- 七、结论
一、引言
强化学习在近年来取得了巨大的进展,被广泛应用于机器人控制、游戏、自动驾驶等多个领域。近端策略优化(Proximal Policy Optimization,PPO)算法是强化学习中的经典算法之一,而直接偏好优化(Direct Preference Optimization,DPO)算法则是在其基础上发展而来的一种新算法,它在一些场景下展现出了独特的优势。本文将深入探讨 DPO 算法,通过与 PPO 算法的对比,帮助读者更好地理解这一算法的原理与应用。
二、强化学习基础回顾
在深入了解 DPO 算法之前,我们先来回顾一下强化学习的基本概念。强化学习是智能体(agent)在环境中通过不断试错来学习最优行为策略的过程。智能体根据当前的状态选择一个动作,环境会根据这个动作返回一个奖励和新的状态。智能体的目标是最大化长期累积奖励。
(一)策略
策略(policy)是智能体从状态到动作的映射,通常用 π ( a ∣ s ) \pi(a|s) π(a∣s) 表示在状态 s s s 下选择动作 a a a 的概率。可以把它想象成一个导航仪,根据你当前所处的位置(状态),告诉你应该往哪个方向走(动作)。
(二)价值函数
价值函数(value function)用于评估状态的好坏,分为状态价值函数 V π ( s ) V^{\pi}(s) Vπ(s) 和动作价值函数 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a) 。
状态价值函数: V π ( s ) = E π [ ∑ t = 0 ∞ γ t r t ∣ s 0 = s ] V^{\pi}(s) = E_{\pi}[\sum_{t=0}^{\infty}\gamma^{t}r_{t}|s_{0}=s] Vπ(s)=Eπ[t=0∑∞γtrt∣s0=s] 其中 γ \gamma γ 是折扣因子, r t r_{t} rt 是在时刻 t t t 获得的奖励。简单来说,它是在当前状态下,按照既定策略行动,未来能获得的所有奖励的总和(考虑了折扣因子,因为越远的奖励对当前决策的影响相对越小)。比如你现在站在一个路口,状态价值函数就代表了你从这个路口出发,按照一定的行走策略,最终能收获的所有 “好处” 的预估。
动作价值函数: Q π ( s , a ) = E π [ ∑ t = 0 ∞ γ t r t ∣ s 0 = s , a 0 = a ] Q^{\pi}(s,a) = E_{\pi}[\sum_{t=0}^{\infty}\gamma^{t}r_{t}|s_{0}=s,a_{0}=a] Qπ(s,a)=Eπ[t=0∑∞γtrt∣s0=s,a0=a] 它评估的是在当前状态下采取某个具体动作后,未来能获得的累积奖励。还是以上述路口为例,动作价值函数就是你在这个路口选择向左转、向右转或者直走等不同动作后,分别能得到的未来奖励总和。
三、近端策略优化(PPO)算法
(一)算法原理
PPO 算法的核心思想是在策略更新时,限制新策略与旧策略之间的差异,以保证策略更新的稳定性。这就好比你在学习骑自行车,你每次尝试的新姿势(新策略)不能和之前已经掌握的姿势(旧策略)相差太大,不然就很容易摔倒(策略不稳定)。它通过重要性采样来估计策略更新的梯度,然后使用截断的目标函数来优化策略。重要性采样可以理解为从旧策略中选取一些有代表性的样本,来指导新策略的更新,就像从过去的骑车经验中挑选一些关键的片段,来帮助你调整当前的骑车姿势。
(二)PPO 目标函数
PPO 使用的目标函数是截断的优势目标函数(clipped surrogate objective): L C L I P ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{CLIP}(\theta) = \mathbb{E}_{t}[\min(r_{t}(\theta)\hat{A}_{t}, \text{clip}(r_{t}(\theta), 1 - \epsilon, 1 + \epsilon)\hat{A}_{t})] LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
其中 r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_{t}(\theta)=\frac{\pi_{\theta}(a_{t}|s_{t})}{\pi_{\theta_{old}}(a_{t}|s_{t})} rt(θ)=πθold(at∣st)πθ(at∣st) 是重要性采样比, A ^ t \hat{A}_{t} A^t 是估计的优势函数, ϵ \epsilon ϵ 是截断参数。这个公式看起来复杂,但简单来说,就是通过比较新策略和旧策略的采样比,以及优势函数,来确保策略更新在一个合理的范围内(通过截断参数 ϵ \epsilon ϵ 来控制),避免更新幅度过大导致不稳定。
(三)代码示例(以 OpenAI Gym 环境 CartPole 为例)
import gymimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.distributions import Categorical# 定义策略网络class Policy(nn.Module):def __init__(self, state_size, action_size):super(Policy, self).__init__()self.fc1 = nn.Linear(state_size, 128)self.fc2 = nn.Linear(128, action_size)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return Categorical(logits=x)# 超参数gamma = 0.99epsilon = 0.2learning_rate = 3e-4num_epochs = 10# 初始化环境和策略网络env = gym.make('CartPole-v1')state_size = env.observation_space.shape[0]action_size = env.action_space.npolicy = Policy(state_size, action_size)optimizer = optim.Adam(policy.parameters(), lr=learning_rate)for epoch in range(num_epochs):states, actions, rewards = [], [], []state = env.reset()state = torch.FloatTensor(state)done = Falsewhile not done:states.append(state)dist = policy(state)action = dist.sample()actions.append(action)state, reward, done, _ = env.step(action.item())state = torch.FloatTensor(state)rewards.append(reward)returns = []R = 0for r in rewards[::-1]:R = r + gamma * Rreturns.insert(0, R)returns = torch.FloatTensor(returns)states = torch.stack(states)actions = torch.tensor(actions)old_log_probs = policy(states).log_prob(actions)for _ in range(3):dist = policy(states)log_probs = dist.log_prob(actions)ratios = torch.exp(log_probs - old_log_probs.detach())advantages = returns - policy(states).valuesurr1 = ratios * advantagessurr2 = torch.clamp(ratios, 1 - epsilon, 1 + epsilon) * advantagesloss = -torch.min(surr1, surr2).mean()optimizer.zero_grad()loss.backward()optimizer.step()env.close()
四、直接偏好优化(DPO)算法
(一)算法原理
DPO 算法直接利用人类偏好数据进行策略优化。想象你在学习画画,PPO 算法就像是你根据自己每次画画后的自我评价(环境奖励)来改进绘画技巧;而 DPO 算法则是直接参考老师或者其他专业人士对你画作的评价(人类偏好)来调整绘画方式。它通过构建一个偏好模型,将人类对不同策略产生的轨迹的偏好信息融入到策略更新中,从而使策略更符合人类的期望。
(二)DPO 目标函数
DPO 的目标函数基于 KL 散度来衡量新策略与参考策略之间的差异,同时考虑偏好奖励: L D P O ( θ ) = − E ( s , a ) ∼ π θ [ r p r e f ( s , a ) − α D K L ( π θ ( a ∣ s ) ∣ ∣ π r e f ( a ∣ s ) ) ] L^{DPO}(\theta) = - \mathbb{E}_{(s,a)\sim \pi_{\theta}}[r_{pref}(s,a) - \alpha D_{KL}(\pi_{\theta}(a|s)||\pi_{ref}(a|s))] LDPO(θ)=−E(s,a)∼πθ[rpref(s,a)−αDKL(πθ(a∣s)∣∣πref(a∣s))]
其中, r p r e f ( s , a ) r_{pref}(s,a) rpref(s,a) 是偏好奖励, α \alpha α 是平衡系数, π r e f \pi_{ref} πref 是参考策略。这个公式的意思是,在优化策略时,既要考虑人类偏好奖励(你画画得到的专业评价分数),又要控制新策略与参考策略(比如一些经典的绘画风格)之间的差异不要太大(通过 KL 散度来衡量)。
(三)代码示例(简单示意,假设已有偏好数据)
import torchimport torch.nn as nnimport torch.optim as optim# 假设已有偏好数据 (states, actions, preferences)states = torch.FloatTensor([[1.0, 2.0], [3.0, 4.0]])actions = torch.tensor([0, 1])preferences = torch.FloatTensor([0.8, 0.6])# 定义策略网络class DPO_Policy(nn.Module):def __init__(self, state_size, action_size):super(DPO_Policy, self).__init__()self.fc1 = nn.Linear(state_size, 128)self.fc2 = nn.Linear(128, action_size)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return nn.functional.softmax(x, dim=-1)state_size = 2action_size = 2policy = DPO_Policy(state_size, action_size)optimizer = optim.Adam(policy.parameters(), lr=3e-4)alpha = 0.1for _ in range(10):dist = policy(states)log_probs = torch.log(dist.gather(1, actions.unsqueeze(1)))ref_dist = torch.FloatTensor([[0.5, 0.5], [0.5, 0.5]]) # 假设参考策略分布kl_divergence = torch.sum(dist * (torch.log(dist) - torch.log(ref_dist)), dim=1)loss = -torch.mean(preferences * log_probs - alpha * kl_divergence)optimizer.zero_grad()loss.backward()optimizer.step()
五、DPO 与 PPO 对比
(一)数据利用
-
PPO:主要利用环境反馈的奖励数据进行策略优化。就像自己独自摸索学习,通过自己的成功和失败来总结经验。
-
DPO:直接利用人类偏好数据,能更好地捕捉人类的意图和价值观。如同有老师指导,直接获取专业的建议和评价。
(二)优化目标
-
PPO:通过截断目标函数来优化策略,关注策略更新的稳定性。强调在学习过程中稳步前进,避免突然的大幅度改变。
-
DPO:基于 KL 散度和偏好奖励,使策略更符合人类偏好。侧重于让学习结果符合专业标准或大众期望。
(三)应用场景
-
PPO:适用于大多数传统强化学习场景,如机器人控制、游戏等。在这些场景中,通过不断试错来优化策略是可行的。
-
DPO:在需要考虑人类偏好的场景中表现出色,如对话系统、推荐系统等。因为这些场景需要符合人类的交流习惯和兴趣偏好。
六、案例分析
(一)对话系统
在对话系统中,PPO 算法可以通过最大化奖励(如用户满意度评分)来优化对话策略。而 DPO 算法可以直接利用人类标注的对话偏好数据,例如人类标注员对不同对话回复的偏好,使对话策略更符合人类期望的交流方式。比如,对于用户询问 “今天天气如何”,PPO 可能通过不断尝试不同回复并根据用户反馈(奖励)来优化回复方式;而 DPO 则可以参考人类标注员认为更自然、更合适的回复,直接向这个方向优化。
(二)自动驾驶
在自动驾驶中,PPO 可以通过优化车辆行驶的安全性和效率相关的奖励来学习驾驶策略。DPO 则可以利用人类专家对不同驾驶行为的偏好,例如对更平稳驾驶行为的偏好,来优化驾驶策略。例如,在遇到红绿灯时,PPO 可能根据通过路口的速度和时间等奖励来决定驾驶动作;DPO 则可以根据人类专家认为更舒适、更安全的驾驶方式(如提前减速、平稳停车等偏好)来调整驾驶策略。
七、结论
DPO 算法作为强化学习中的一种新方法,通过直接利用人类偏好数据,为策略优化提供了新的思路。与传统的 PPO 算法相比,它在一些需要考虑人类因素的场景中具有独特的优势。然而,DPO 算法也面临着一些挑战,如偏好数据的获取和标注成本较高等。未来,随着技术的不断发展,相信 DPO 算法将在更多领域得到应用和改进。
相关文章:

强化学习 DPO 算法:基于人类偏好,颠覆 PPO 传统策略
目录 一、引言二、强化学习基础回顾(一)策略(二)价值函数 三、近端策略优化(PPO)算法(一)算法原理(二)PPO 目标函数(三)代码示例&…...

【HDSF】ProtobufRpcEngine 和 ProtobufRpcEngine2
ProtobufRpcEngine2的call方法实现如下,它对历史版本的protobuf实现进行了兼容。 即同时支持protobuf 2.5.0 和protobuf 3.x版本的RPC通信。 看下具体是怎么实现的? @SuppressWarnings("deprecation")protected Writable call(RPC.Server server, String connecti…...

Redis中的某一热点数据缓存过期了,此时有大量请求访问怎么办?
1、提前设置热点数据永不过期 2、分布式中用redis分布式锁(锁可以在多个 JVM 实例之间协调)、单体中用synchronized(锁只在同一个 JVM 内有效) 编写服务类 import com.redisson.api.RLock; import com.redisson.api.RedissonCli…...

IntelliJ IDEA 安装与使用完全教程:从入门到精通
一、引言 在当今竞争激烈的软件开发领域,拥有一款强大且高效的集成开发环境(IDE)是开发者的致胜法宝。IntelliJ IDEA 作为 JetBrains 公司精心打造的一款明星 IDE,凭借其丰富多样的功能、智能精准的代码提示以及高效便捷的开发工…...

自动化xpath定位元素(附几款浏览器xpath插件)
在 Web 自动化测试、数据采集、前端调试中,XPath 仍然是不可或缺的技能。虽然 CSS 选择器越来越强大,但面对复杂 DOM 结构时,XPath 仍然更具灵活性。因此,掌握 XPath,不仅能提高自动化测试的稳定性,还能在爬…...

PromptSource官方文档翻译
目录 核心概念解析 提示模板(Prompt Template) P3数据集 安装指南 基础安装(仅使用提示) 开发环境安装(需创建提示) API使用详解 基本用法 子数据集处理 批量操作 提示创建流程 Web界面操作 手…...
2025年软件测试五大趋势:AI、API安全、云测试等前沿实践
随着软件开发的不断进步,测试方法也在演变。企业需要紧跟新兴趋势,以提升软件质量、提高测试效率,并确保安全性,在竞争激烈的技术环境中保持领先地位。本文将深入探讨2025年最值得关注的五大软件测试趋势。 Parasoft下载https://…...

js的DOM一遍过
一、获取元素 1.根据id获取 document.getElementById(id);2.根据标签名获取 使用 getElementsByTagName() 方法可以返回带有指定标签名的对象的集合。 document.getElementsByTagName(标签名);获取某个元素(父元素)内部所有指定标签名的子元素。 element.getElementsByTag…...

Machine Learning:Introduction
文章目录 Machine LearningTrainingStep 1.Contract Function with Unknown ParametersStep 2.Define Loss from Training DataStep 3.Optimization Linear ModelPiecewise Linear CurveBeyond Piecewise Liner?FunctionLossOptimization Model Deformation Machine Learning …...

Excel 笔记
实际问题记录 VBA脚本实现特殊的行转列 已知:位于同一Excel工作簿文件中的两个工作表:Sheet1、Sheet2。 问题:现要将Sheet2中的每一行,按Sheet1中的样子进行转置: Sheet2中每一行的黄色单元格,为列头。…...

基于 GEE 利用插值方法填补缺失影像
目录 1 完整代码 2 运行结果 利用GEE合成NDVI时,如果研究区较大,一个月的影像覆盖不了整个研究区,就会有缺失的地方,还有就是去云之后,有云量的地区变成空值。 所以今天来用一种插值的方法来填补缺失的影像…...

如何设置爬虫的IP代理?
在爬虫开发中,设置IP代理是避免被目标网站封禁、提升爬取效率和保护隐私的重要手段。以下是设置爬虫IP代理的详细方法和注意事项: 一、获取代理IP 免费代理IP: 可以通过一些免费的代理IP网站获取代理IP,但这些IP的稳定性和速度通…...

如何在浏览器中搭建开源Web操作系统Puter的本地与远程环境
文章目录 前言1.关于Puter2.本地部署Puter3.Puter简单使用4. 安装内网穿透5.配置puter公网地址6. 配置固定公网地址 前言 嘿,小伙伴们!是不是每次开机都要像打地鼠一样不停地点击各种网盘和应用程序的登录按钮,感觉超级麻烦?更让…...

使用EVE-NG-锐捷实现单臂路由
一、基础知识 1.三层vlan vlan在三层环境中通常用作网关vlan配上ip网关内部接口ip 2.vlan创建步骤 创建vlan将接口划分到不同的vlan给vlan配置ip地址 二、项目案例 1、项目拓扑 2、项目实现 PC1配置 配置PC1IP地址为192.168.1.10/24网关地址为192.168.1.1 ip 192.168.1…...

二、通义灵码插件保姆级教学-IDEA(使用篇)
一、IntelliJ IDEA 中使用指南 1.1、代码解释 选择需要解释的代码 —> 右键 —> 通义灵码 —> 解释代码 解释代码很详细,感觉很强大有木有,关键还会生成流程图,对程序员理解业务非常有帮忙,基本能做到哪里不懂点哪里。…...

水下 SLAM 定位模组的设计与实现
标题:水下 SLAM 定位模组的设计与实现 内容:1.摘要 摘要:本文介绍了水下 SLAM 定位模组的设计与实现。首先,对水下定位技术的背景和需求进行了分析。然后,详细阐述了模组的设计思路和关键技术,包括传感器选型、数据融合算法等。接…...
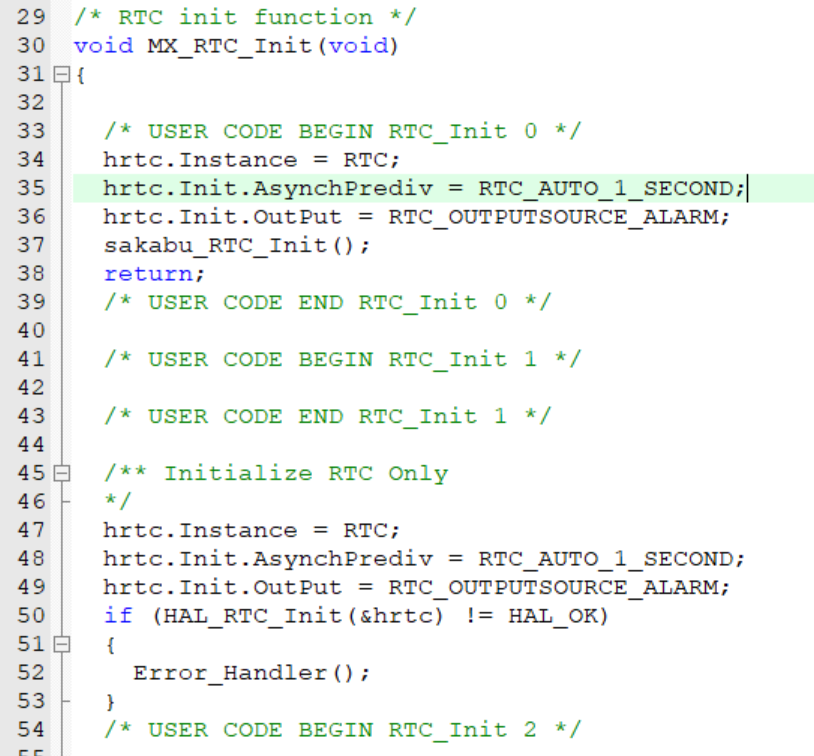
HAL库外设宝典:基于CubeMX的STM32开发手册(持续更新)
目录 前言 GPIO(通用输入输出引脚) 推挽输出模式 浮空输入和上拉输入模式 GPIO其他模式以及内部电路原理 输出驱动器 输入驱动器 中断 外部中断(EXTI) 深入中断(内部机制及原理) 外部中断/事件控…...

HarmonyOS 5.0应用开发——ContentSlot的使用
【高心星出品】 文章目录 ContentSlot的使用使用方法案例运行结果 完整代码 ContentSlot的使用 用于渲染并管理Native层使用C-API创建的组件同时也支持ArkTS创建的NodeContent对象。 支持混合模式开发,当容器是ArkTS组件,子组件在Native侧创建时&#…...

RabbitMQ的死信队列的产生与处理
死信队列(Dead Letter Queue, DLQ) 1. 死信(Dead Letter)是怎么产生的? 在 RabbitMQ 中,消息会变成 死信(Dead Letter)的常见情况有以下几种: 消息被拒绝(R…...

[AI]Mac本地部署Deepseek R1模型 — — 保姆级教程
[AI]Mac本地部署DeepSeek R1模型 — — 保姆级教程 DeepSeek R1是中国AI初创公司深度求索(DeepSeek)推出大模型DeepSeek-R1。 作为一款开源模型,R1在数学、代码、自然语言推理等任务上的性能能够比肩OpenAI o1模型正式版,并采用MI…...
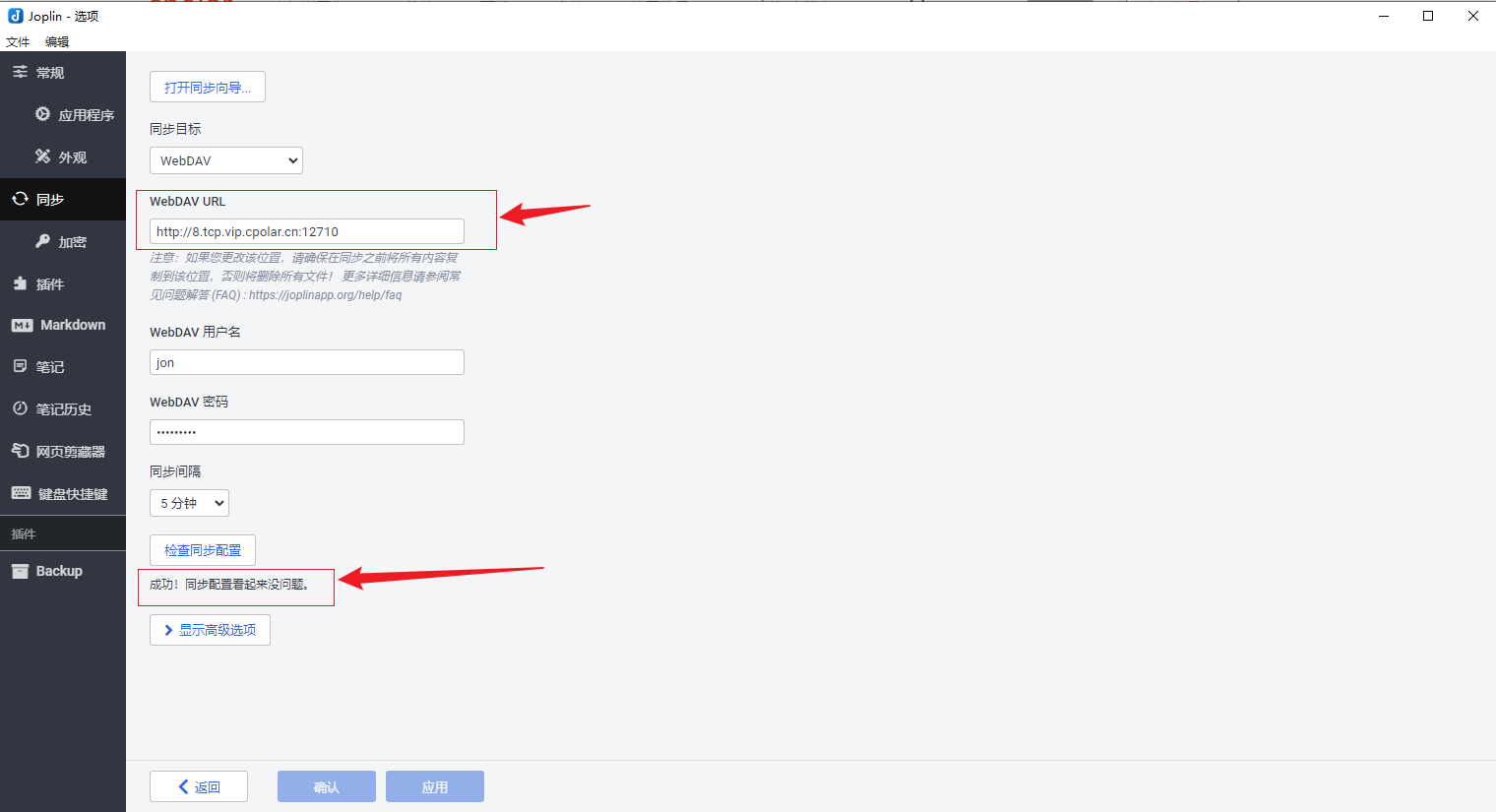
群晖NAS如何通过WebDAV和内网穿透实现Joplin笔记远程同步
文章目录 前言1. 检查群晖Webdav 服务2. 本地局域网IP同步测试3. 群晖安装Cpolar工具4. 创建Webdav公网地址5. Joplin连接WebDav6. 固定Webdav公网地址7. 公网环境连接测试 前言 在数字化浪潮的推动下,笔记应用已成为我们记录生活、整理思绪的重要工具。Joplin&…...

CSS3+动画
浏览器内核以及其前缀 css标准中各个属性都要经历从草案到推荐的过程,css3中的属性进展都不一样,浏览器厂商在标准尚未明确的情况下提前支持会有风险,浏览器厂商对新属性的支持情况也不同,所有会加厂商前缀加以区分。如果某个属性…...

C++ list介绍
文章目录 1. list简介2. list的实现框架2.1 链表结点2.2 链表迭代器2.3 链表 3. list迭代器及反向迭代器设计3.1 list迭代器3.2 list反向迭代器3.3 list迭代器失效 4. list与vector比较 1. list简介 list,即链表。 链表的种类有很多,是否带头结点&#…...

Java - 在Linux系统上使用OpenCV和Tesseract
系统环境 确保Linux系统安装了cmake构建工具,以及java和ant(这两者如果没有,可能会影响到后面编译opencv生成.so和.jar文件)。 sudo apt-get update sudo apt-get install build-essential sudo apt install cmake build-essen…...

自有服务与软件包
—— 小 峰 编 程 目录 编辑 一、自有服务概述 二、systemctl管理服务命令 1、显示服务 2、查看启动和停止服务 3、服务持久化 三、常用自有服务(ntp,firewalld,crond) 1、ntp时间同步服务 1)NTP同步服务器原理 2)到哪里去找NPT服务…...

Python 鼠标轨迹 - 防止游戏检测
一.简介 鼠标轨迹算法是一种模拟人类鼠标操作的程序,它能够模拟出自然而真实的鼠标移动路径。 鼠标轨迹算法的底层实现采用C/C语言,原因在于C/C提供了高性能的执行能力和直接访问操作系统底层资源的能力。 鼠标轨迹算法具有以下优势: 模拟…...

BootstrapBlazor Table组件 使用的注入 数据服务 实现类:使用 EF Core
一、使用示例:UsersManager.razor 注:TLog 相关内容参见 .NET 9.0 的 Blazor Web App 项目、Bootstrap Blazor 组件库、自定义日志 TLog 使用备忘-CSDN博客 page "/Log/TLogManager"<Table TItem"TLogEntity" DataService&qu…...

chrome-mojo C++ Bindings API
概述 Mojo C 绑定 API 利用C 系统 API提供一组更自然的原语,用于通过 Mojo 消息管道进行通信。结合从Mojom IDL 和绑定生成器生成的代码,用户可以轻松地跨任意进程内和进程间边界连接接口客户端和实现。 本文档通过示例代码片段提供了绑定 API 用法的详…...

git如何把多个commit合成一个
在 Git 中,如果你想把多个提交(commit)合并成一个,可以使用 git rebase 或 git reset 来完成。下面是两种常用方法: 方法一:使用 git rebase(推荐) git rebase 是合并多个提交为一…...

java: framework from BLL、DAL、IDAL、MODEL、Factory using oracle
oracel 21c sql: -- 创建 School 表 CREATE TABLE School (SchoolId CHAR(5) NOT NULL,SchoolName NVARCHAR2(500) NOT NULL,SchoolTelNo VARCHAR2(8) NULL,PRIMARY KEY (SchoolId) );CREATE OR REPLACE PROCEDURE addschool(p_school_id IN CHAR,p_school_name IN NVARCHAR2,p…...