搭建一个经典的LeNet5神经网络
第一章:计算机视觉中图像的基础认知
第二章:计算机视觉:卷积神经网络(CNN)基本概念(一)
第三章:计算机视觉:卷积神经网络(CNN)基本概念(二)
第四章:搭建一个经典的LeNet5神经网络
一、LeNet-5背景
LeNet-5是一种经典的卷积神经网络(CNN)架构,由Yann LeCun(杨立昆)等人于1998年提出,最初用于手写字符识别任务。
传统的模式识别方法依赖于人工设计的特征提取方法,这些方法存在许多局限性,如特征选择困难、对数据分布敏感等。
而LeNet-5通过引入卷积层和池化层,利用图像的空间相关性来自动提取特征。
LeNet-5最初用于MNIST数据集的手写数字识别任务,取得了高达99.2%的准确率。这一成就标志着深度学习在图像识别领域的突破,并为后续的神经网络研究奠定了基础。
LeNet-5的结构相对简单,但它仍然是理解CNN基本原理的重要起点。
二、LeNet-5架构

LeNet-5的网络结构包括以下几层:
- 输入层:INPUT,接收32x32像素的灰度图像。
- 卷积层:Convolutions,包含多个卷积核,用于提取图像特征。LeNet-5有两组卷积层(C1、C3),Subsampling,每个卷积层后接一个平均池化层(S2和S4)。
- 全连接层:Full connection,将卷积层提取的特征图展平,并通过全连接层进行分类。
- 输出层:OUTPUT,使用softmax函数输出分类结果。
具体来说:
- C1层:使用5x5的卷积核,输出6个特征图。
- S2层:使用2x2的平均池化核,将特征图尺寸减半。
- C3层:使用5x5的卷积核,输出16个特征图。
- S4层:再次使用2x2的平均池化核,将特征图尺寸减半。
- C5层:使用5x5的卷积核,输出120个特征图。
- F6层:一个全连接层,输出84个特征。
- 输出层:使用softmax函数输出10个类别的概率。
LeNet-5 的命名中,“5”表示网络包含 5层可训练参数层(2卷积层 + 3全连接层)。以下为典型结构:
| 层级 | 参数配置 | 输出尺寸 | 说明 |
|---|---|---|---|
| 输入层 | - | 32×32×1 | 灰度图像输入 |
| Conv1 | 5×5卷积核,6通道 | 28×28×6 | 首次提取边缘特征 |
| Pool1 | 2×2池化,步长2 | 14×14×6 | 下采样减少计算量 |
| Conv2 | 5×5卷积核,16通道 | 10×10×16 | 提取高阶组合特征 |
| Pool2 | 2×2池化,步长2 | 5×5×16 | 进一步压缩空间维度 |
| Flatten | 展平操作 | 400 | 全连接层输入准备 |
| FC1 | 120神经元 | 120 | 非线性特征映射 |
| FC2 | 84神经元 | 84 | 进一步抽象特征 |
| Output | 10神经元(对应0-9数字) | 10 | 输出分类概率 |
Conv1层的卷积核为什么是5×5,通道为什么是 6?不知道为什么,可能是基于经验、实验得出的。
三、实现LeNet5神经网络模型
通过下面这段代码定义一个用于图像分类的卷积神经网络模型,并展示如何使用这个模型对输入数据进行预测。
3.1 定义模型
第一种实现方式
import torch
from torch import nn# 继承自 nn.Module,这是所有PyTorch模型的基础类。
class Model_1(nn.Module):"""自定义一个神经网络"""# 调用父类的构造函数 super(Model_1, self).__init__() 来初始化父类。def __init__(self, in_channels=1, n_classes=10):"""初始化"""super(Model_1, self).__init__()# conv1 和 conv2 是两个卷积层,分别输出6个和16个特征图(通道数)。# 每个卷积层使用5x5的卷积核,步长为1,不使用填充。self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5,stride=1,padding=0)# mp1 和 mp2 是最大池化层,用于减小特征图的空间尺寸。# 这两个层使用2x2的窗口大小,步长也为2,同样不使用填充。self.mp1 = nn.MaxPool2d(kernel_size=2, stride=2,padding=0)self.conv2 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5,stride=1,padding=0)self.mp2 = nn.MaxPool2d(kernel_size=2, stride=2,padding=0)# 展平为400维向量# flatten 层将前面得到的多维特征图展平成一维向量,以便输入到全连接层中。# 这里假设输入图像大小为32x32,在经过两次卷积和池化后,最终得到的是16通道的5x5特征图,# 因此展平后的向量长度为 16×5×5=400。self.flatten = nn.Flatten(start_dim=1,end_dim=-1)# fc1, fc2, fc3 分别是三个全连接层。# 第一个全连接层有120个神经元,第二个有84个,最后一个根据类别数量 n_classes 输出分类结果。# 全连接层1self.fc1 = nn.Linear(in_features=400,out_features=120)# 全连接层2self.fc2 = nn.Linear(in_features=120,out_features=84)# 输出层self.fc3 = nn.Linear(in_features=84,out_features=n_classes)def forward(self, x):"""前向传播在 forward 方法中定义了数据通过网络时的计算流程:1.输入张量 x 首先通过第一个卷积层 conv1,然后是第一个最大池化层 mp1,接着是第二个卷积层 conv2 和第二个最大池化层 mp2。2.然后,将特征图展平并通过三个全连接层 fc1, fc2, fc3 进行分类处理。3.最终返回分类结果。"""x = self.conv1(x)x = self.mp1(x)x = self.conv2(x)x = self.mp2(x)x = self.flatten(x)x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)return x第一种实现方式直接定义了每个层(如卷积层、池化层和全连接层)作为类的属性,并在forward方法中顺序调用这些层。
第二种实现方式
class Model_2(nn.Module):"""自定义一个神经网络"""def __init__(self, in_channels=1, n_classes=10):"""初始化"""super(Model_2, self).__init__()# 1. 特征抽取self.feature_extractor = nn.Sequential(# 卷积层1nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5,stride=1,padding=0),# 池化层1nn.MaxPool2d(kernel_size=2, stride=2,padding=0),# 卷积层2nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5,stride=1,padding=0),# 池化层2nn.MaxPool2d(kernel_size=2, stride=2,padding=0))# 2. 分类输出self.classifier = nn.Sequential(nn.Flatten(start_dim=1, end_dim=-1),nn.Linear(in_features=400, out_features=120),nn.Linear(in_features=120, out_features=84),nn.Linear(in_features=84, out_features=n_classes))def forward(self, x):"""前向传播"""# 1. 先做特征抽取x = self.feature_extractor(x)# 2. 再做分类回归x = self.classifier(x)return x
第二种实现方式将特征抽取部分和分类输出部分分别封装到两个Sequential对象中,使代码更简洁易读。这种组织方式有助于分离关注点,使得网络结构更清晰。
上面有两个类定义,但实际上它们是重复的,只是第二种实现方式更加模块化。
3.2 层的解释
nn.Conv2d: 卷积层,用于提取图像的局部特征。第一个卷积层有6个5x5的滤波器,第二个卷积层有16个5x5的滤波器。nn.MaxPool2d: 最大池化层,用于降低特征图的空间维度。这里使用的是2x2的窗口大小。nn.Flatten: 将多维的输入一维化,常用在从卷积层过渡到全连接层时。nn.Linear: 全连接层(线性层),用于执行从输入特征到输出类别得分的映射。这里有三个连续的全连接层,最后的输出大小为n_classes,即类别数。
3.3 前向传播过程
在forward函数中,输入数据首先通过一系列卷积和池化操作进行特征提取,然后通过Flatten层展平成一维张量,最后通过几个全连接层完成分类任务。
计算过程(输入为32x32图像):
- Conv1:(32-5)/1 + 1 = 28 → 输出 6通道的28x28特征图
- MaxPool1:28/2 = 14 → 输出6通道的14x14特征图
- Conv2:(14-5)/1 + 1 = 10 → 输出16通道的10x10特征图
- MaxPool2:10/2 = 5 → 最终得到16通道的5x5特征图
3.4 模型测试
# 创建了一个`Model`实例,指定输入通道数为1(例如灰度图像)
model = Model_2(in_channels=1)
# 使用`torch.randn`生成形状为`(2, 1, 32, 32)`的随机输入数据,表示2个样本,每个样本是一个1通道32x32像素的图像
X = torch.randn(2, 1, 32, 32)
# 调用模型`model(X)`进行前向传播,得到预测结果`y_pred`
y_pred = model(X)
# 打印`y_pred`的形状,预期输出形状应该是`(2, n_classes)`,
# 其中`n_classes`是在初始化模型时指定的类别数量,默认为10
print(y_pred.shape)
print(model) # 查看模型的结构
输出:
torch.Size([2, 10])
Model_2((feature_extractor): Sequential((0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(classifier): Sequential((0): Flatten(start_dim=1, end_dim=-1)(1): Linear(in_features=400, out_features=120, bias=True)(2): Linear(in_features=120, out_features=84, bias=True)(3): Linear(in_features=84, out_features=10, bias=True))
)
四、参数规模
卷积层参数量:(5x5x1x6 + 6) + (5x5x6x16 + 16) = 156 + 2416 = 2572
全连接层参数量:(400x120+ 120) + (120x84+84) + (84x10+10) = 48,120 + 10,164 + 850 = 59,134
维度变化:32x32 → 28x28 → 14x14 → 10x10 → 5x5 → 400 → 120 → 84 → 10
卷积层参数量的计算公式
对于 Conv2d(in_channels=C_in, out_channels=C_out, kernel_size=K):
- 权重参数:
K × K × C_in × C_out - 偏置参数:
C_out(每个输出通道一个偏置) - 总参数量 = 权重参数 + 偏置参数 =
K²×C_in×C_out + C_out
1. 第一层卷积 Conv1
- 输入通道:
C_in=1 - 输出通道:
C_out=6 - 卷积核:
5×5 - 权重参数:
5×5×1×6 = 150 - 偏置参数:
6 - 总参数量:
150 + 6 = 156
2. 第二层卷积 Conv2
- 输入通道:
C_in=6 - 输出通道:
C_out=16 - 卷积核:
5×5 - 权重参数:
5×5×6×16 = 2400 - 偏置参数:
16 - 总参数量:
2400 + 16 = 2416
3. 卷积层总参数量
- 总计:
156 (Conv1) + 2416 (Conv2) = 2572
全连接层参数计算(以 fc1 为例)
Linear(in_features=400, out_features=120)- 权重参数:
400×120 = 48,000 - 偏置参数:
120 - 总参数量:
48,000 + 120 = 48,120
全网络总参数量
| 层类型 | 参数量计算式 | 参数量 |
|---|---|---|
| Conv1 | 5×5×1×6 + 6 | 156 |
| Conv2 | 5×5×6×16 + 16 | 2416 |
| FC1 | 400×120 + 120 | 48,120 |
| FC2 | 120×84 + 84 | 10,164 |
| FC3 | 84×10 + 10 | 850 |
| 总计 | 61,706 |
使用下面代码,可以看到具体参数量:
# 遍历模型的所有子模块
for name, param in model.named_parameters():if param.requires_grad:print(f"Layer: {name}")if 'weight' in name:print(f"Weights:{param.data.shape}")if 'bias' in name:print(f"Bias:{param.data.shape}\n")
输出:
Layer: feature_extractor.0.weight
Weights:torch.Size([6, 1, 5, 5])
Layer: feature_extractor.0.bias
Bias:torch.Size([6])Layer: feature_extractor.2.weight
Weights:torch.Size([16, 6, 5, 5])
Layer: feature_extractor.2.bias
Bias:torch.Size([16])Layer: classifier.1.weight
Weights:torch.Size([120, 400])
Layer: classifier.1.bias
Bias:torch.Size([120])Layer: classifier.2.weight
Weights:torch.Size([84, 120])
Layer: classifier.2.bias
Bias:torch.Size([84])Layer: classifier.3.weight
Weights:torch.Size([10, 84])
Layer: classifier.3.bias
Bias:torch.Size([10])
这整个过程演示了如何定义一个简单的卷积神经网络模型,并使用该模型对一批输入数据进行分类预测。
五、总结
LeNet-5 是深度学习史上的里程碑,其设计哲学至今仍深刻影响着计算机视觉领域。尽管现代模型在深度和复杂度上远超LeNet-5,但其核心思想——通过卷积和池化逐步提取层级特征——仍然是所有CNN模型的基石。理解LeNet-5不仅能掌握CNN的基本原理,更能体会深度学习从理论到实践的关键突破。
相关文章:
搭建一个经典的LeNet5神经网络
第一章:计算机视觉中图像的基础认知 第二章:计算机视觉:卷积神经网络(CNN)基本概念(一) 第三章:计算机视觉:卷积神经网络(CNN)基本概念(二) 第四章:搭建一个经典的LeNet5神经网络 一、LeNet-5背景 LeNet-…...

我用Ai学Android Jetpack Compose之CircularProgressIndicator
答案来自 通义千问 Q: 我想学习CircularProgressIndicator,麻烦你介绍一下 当然可以!CircularProgressIndicator 是 Jetpack Compose 中的一个组件,用于显示一个循环的圆形进度条。它非常适用于需要指示加载状态或进程完成度的场景。接下来…...

DeepSeek-R1:通过强化学习激励大型语言模型的推理能力
摘要 我们介绍了第一代推理模型DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练而成的模型,无需监督微调(SFT)作为初步步骤,展示了卓越的推理能力。通过RL,DeepSeek-R1-Zero自然涌现出许多强大而有趣的推理行为。然而,它也面临诸如…...

为什么要选择3D机器视觉检测
选择3D机器视觉检测的原因主要包括以下几点: 高精度测量 复杂几何形状:能够精确测量复杂的三维几何形状。 微小细节:可捕捉微小细节,适用于高精度要求的行业。全面数据获取 深度信息:提供深度信息,弥补2D视…...

Unity 编辑器热更C# FastScriptReload
工具源码:https://github.com/handzlikchris/FastScriptReload 介绍 用于运行时修改C#后能快速重新编译C#并生效,避免每次改C#,unity全部代码重新编译,耗时旧且需要重启游戏。 使用 需要手动调整AssetPipeline自动刷新模式&…...
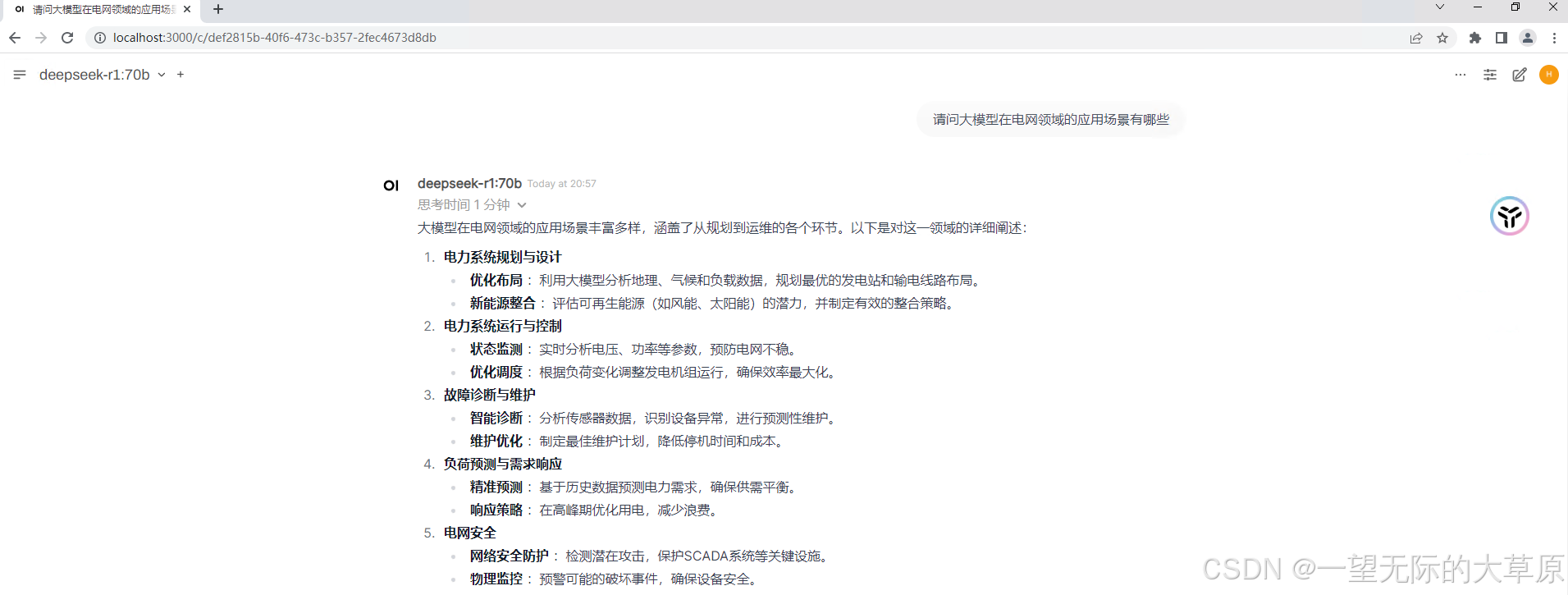
DeepSeek在linux下的安装部署与应用测试
结合上一篇文章,本篇文章主要讲述在Redhat linux环境下如何部署和使用DeepSeek大模型,主要包括ollama的安装配置、大模型的加载和应用测试。关于Open WebUI在docker的安装部署,Open WebUI官网也提供了完整的docker部署说明,大家可…...

VNC远程控制Mac
前言 macOS系统自带有VNC远程桌面,我们可以在控制端上安装配置VNC客户端,以此来实现远程控制macOS。但通常需要在不同网络下进行远程控制,为此,我们可以在macOS被控端上使用cpolar做内网穿透,映射VNC默认端口5…...

Next.js国际化:next-i18next
引言 next-i18next 是专门为 Next.js 项目量身定制的国际化解决方案,它基于强大的 i18next 库,能帮助开发者轻松地为 Next.js 应用添加多语言支持 next-i18next 初相识 项目简介 next-i18next 是一个专为 Next.js 应用程序打造的国际化解决方案&#…...

计算机视觉:卷积神经网络(CNN)基本概念(一)
第一章:计算机视觉中图像的基础认知 第二章:计算机视觉:卷积神经网络(CNN)基本概念(一) 第三章:计算机视觉:卷积神经网络(CNN)基本概念(二) 第四章:搭建一个经典的LeNet5神经网络 一、引言 卷积神经网络&…...

Python的那些事第二十三篇:Express(Node.js)与 Python:一场跨语言的浪漫邂逅
摘要 在当今的编程世界里,Node.js 和 Python 像是两个性格迥异的超级英雄,一个以速度和灵活性著称,另一个则以强大和优雅闻名。本文将探讨如何通过 Express 框架将 Node.js 和 Python 结合起来,打造出一个高效、有趣的 Web 应用。我们将通过一系列幽默风趣的实例和表格,展…...

核货宝外贸订货系统:批发贸易企业出海的强劲东风
在全球贸易一体化的汹涌浪潮中,批发贸易企业正积极探寻海外市场的广阔天地,试图开辟新的增长版图。然而,出海之路绝非坦途,众多难题如暗礁般潜藏在前行的航道上。从复杂繁琐的跨境交易流程、变幻莫测的国际市场需求,到…...

最新智能优化算法: 阿尔法进化(Alpha Evolution,AE)算法求解23个经典函数测试集,MATLAB代码
一、阿尔法进化算法 阿尔法进化(Alpha Evolution,AE)算法是2024年提出的一种新型进化算法,其核心在于通过自适应基向量和随机步长的设计来更新解,从而提高算法的性能。以下是AE算法的主要步骤和特点: 主…...

数据结构与算法面试专题——堆排序
完全二叉树 完全二叉树中如果每棵子树的最大值都在顶部就是大根堆 完全二叉树中如果每棵子树的最小值都在顶部就是小根堆 设计目标:完全二叉树的设计目标是高效地利用存储空间,同时便于进行层次遍历和数组存储。它的结构使得每个节点的子节点都可以通过简…...

MongoDB索引介绍
索引简述 索引是什么 索引在数据库技术体系中占据了非常重要的位置,其主要表现为一种目录式的数据结构,用来实现快速的数据查询。通常在实现上,索引是对数据库表(集合)中的某些字段进行抽取、排列之后,形成的一种非常易于遍历读取…...

【一文读懂】WebRTC协议
WebRTC(Web Real-Time Communication)协议 WebRTC(Web Real-Time Communication)是一种支持浏览器和移动应用程序之间进行 实时音频、视频和数据通信 的协议。它使得开发者能够在浏览器中实现高质量的 P2P(点对点&…...

【弹性计算】容器、裸金属
容器、裸金属 1.容器和云原生1.1 容器服务1.2 弹性容器实例1.3 函数计算 2.裸金属2.1 弹性裸金属服务器2.2 超级计算集群 1.容器和云原生 容器技术 起源于虚拟化技术,Docker 和虚拟机和谐共存,用户也找到了适合两者的应用场景,二者对比如下图…...

【个人开发】deepspeed+Llama-factory 本地数据多卡Lora微调
文章目录 1.背景2.微调方式2.1 关键环境版本信息2.2 步骤2.2.1 下载llama-factory2.2.2 准备数据集2.2.3 微调模式2.2.3.1 zero-3微调2.2.3.2 zero-2微调2.2.3.3 单卡Lora微调 2.3 踩坑经验2.3.1 问题一:ValueError: Undefined dataset xxxx in dataset_info.json.2…...

两步在 Vite 中配置 Tailwindcss
第一步:安装依赖 npm i -D tailwindcss tailwindcss/vite第二步:引入 tailwindcss 更改配置 // src/main.js import tailwindcss/index// vite.config.js import vue from vitejs/plugin-vue import tailwindcss from tailwindcss/viteexport default …...

使用 HTML CSS 和 JAVASCRIPT 的黑洞动画
使用 HTML CSS 和 JAVASCRIPT 的黑洞动画 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Black Ho…...

计算机视觉-尺度不变区域
一、尺度不变性 1.1 尺度不变性 找到一个函数,实现尺度的选择特性。 1.2 高斯偏导模版求边缘 1.3 高斯二阶导 用二阶过零点检测边缘 高斯二阶导有两个参数:方差和窗宽(给定方差可以算出窗宽) 当图像与二阶导高斯滤波核能匹配…...

SNARKs 和 UTXO链的未来
1. 引言 SNARKs 经常被视为“解决”扩容问题的灵丹妙药。虽然 SNARKs 可以提供令人难以置信的好处,但也需要承认其局限性——SNARKs 无法解决区块链目前面临的现有带宽限制。 本文旨在通过对 SNARKs 对比特币能做什么和不能做什么进行(相对)…...
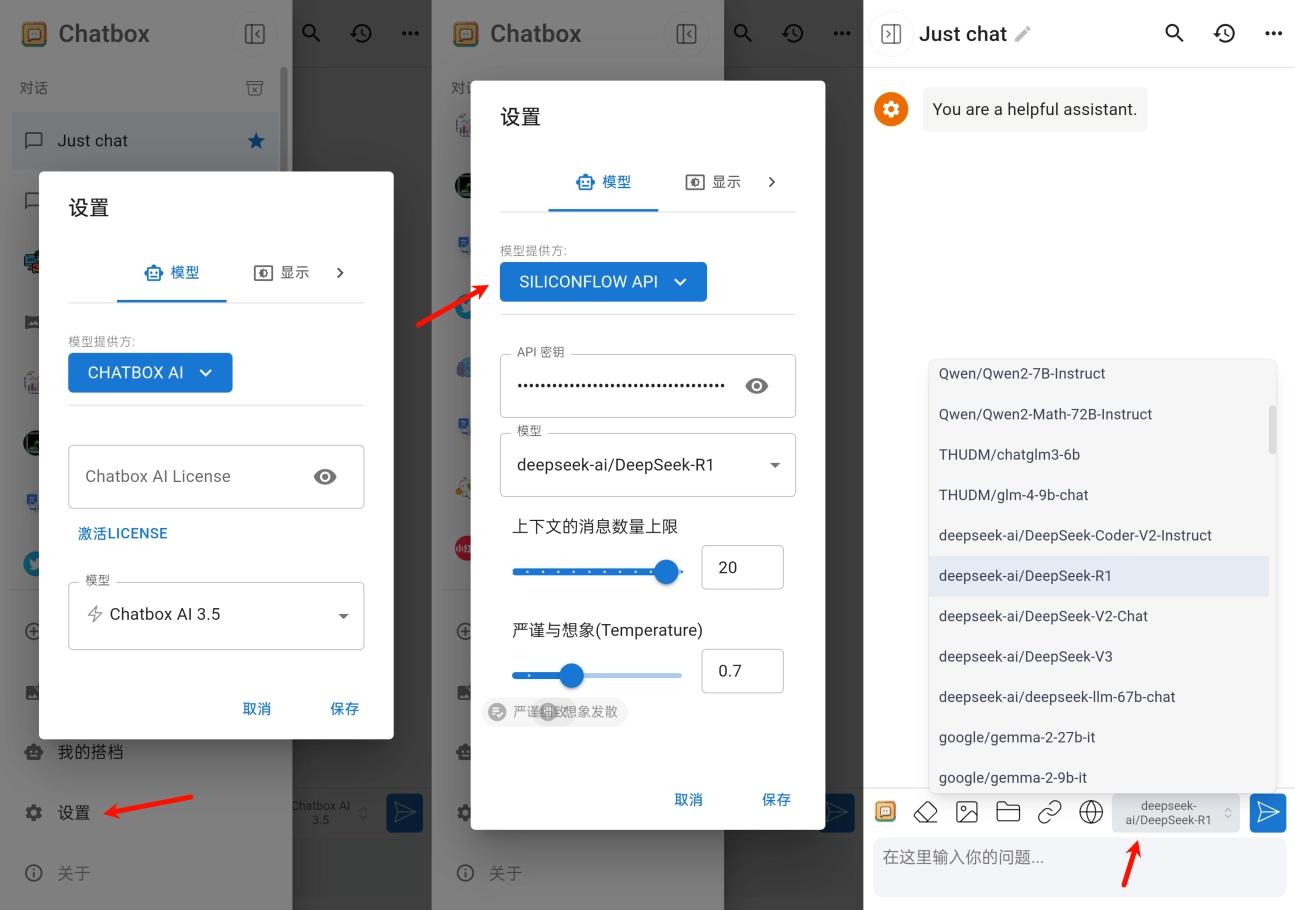
DeepSeek 通过 API 对接第三方客户端 告别“服务器繁忙”
本文首发于只抄博客,欢迎点击原文链接了解更多内容。 前言 上一期分享了如何在本地部署 DeepSeek R1 模型,但通过命令行运行的本地模型,问答的交互也要使用命令行,体验并不是很好。这期分享几个第三方客户端,涵盖了桌…...

性格测评小程序07用户登录
目录 1 创建登录页2 在首页检查登录状态3 搭建登录功能最终效果总结 小程序注册功能开发好了之后,就需要考虑登录的问题。首先要考虑谁作为首页,如果把登录页作为首页,比较简单,每次访问的时候都需要登录。 如果把功能页作为首页&…...

红队视角出发的k8s敏感信息收集——日志与监控系统
针对 Kubernetes 日志与监控系统 的详细攻击视角分析,聚焦 集群审计日志 和 Prometheus/Grafana 暴露 的潜在风险及利用方法 攻击链示例 1. 攻击者通过容器逃逸进入 Pod → 2. 发现未认证的 Prometheus 服务 → 3. 查询环境变量标签获取数据库密码 → 4. 通过审…...

deepseek多列数据对比,联想到excel的高级筛选功能
目录 1 业务背景 2 deepseek提示词输入 3 联想分析 4 EXCEL高级搜索 1 业务背景 系统上线的时候经常会遇到一个问题,系统导入的数据和线下的EXCEL数据是否一致,如果不一致,如何快速找到差异值,原来脑海第一反应就是使用公…...

国产编辑器EverEdit - “切换文件类型”的使用场景
1 “切换文件类型”的使用场景 1.1 应用背景 一般的编辑器都是通过扩展名映射到对应的语法高亮规则的,比如:文件test.xml中的扩展名“xml"对应XML的语法高亮,在编辑器中打开test.xml就会给不同标识符显示不同的颜色。 但有时一些应用程…...

VSCode 接入DeepSeek V3大模型,附使用说明
VSCode 接入DeepSeek V3大模型,附使用说明 由于近期 DeepSeek 使用人数激增,服务器压力较大,官网已 暂停充值入口 ,且接口响应也开始不稳定,建议使用第三方部署的 DeepSeek,如 硅基流动 或者使用其他模型/插件,如 豆包免费AI插件 MarsCode、阿里免费AI插件 TONGYI Lin…...

JavaScript 内置对象-数组对象
在JavaScript中,数组(Array)是一种非常重要的数据结构,它允许我们以列表的形式存储多个值,并提供了丰富的内置方法来操作这些值。无论是处理简单的数值集合还是复杂的对象数组,数组对象都能提供强大的支持。…...

在linux系统中安装Anaconda,并使用conda
系统 : ubuntu20.04 显卡:NVIDIA GTX1650 目录 安装Anaconda第一步:下载合适版本的Anconda1. 查看自己Linux的操作系统及架构命令:uname -a2. 下载合适版本的Anconda 第二步:安装Aanconda1. 为.sh文件设置权限2. 执行.sh文件2.1 .…...

机械学习基础-5.分类-数据建模与机械智能课程自留
data modeling and machine intelligence - CLASSIFICATION 为什么我们不将回归技术用于分类?贝叶斯分类器(The Bayes Classifier)逻辑回归(Logistic Regression)对逻辑回归的更多直观理解逻辑 /sigmoid 函数的导数我们…...