DeepSeek开源周Day1:FlashMLA引爆AI推理性能革命!
项目地址:GitHub - deepseek-ai/FlashMLA
开源日历:2025-02-24起 每日9AM(北京时间)更新,持续五天!

一、开源周震撼启幕
继上周预告后,DeepSeek于北京时间今晨9点准时开源「FlashMLA」,打响开源周五连发第一枪!作为专为Hopper架构GPU(H800/H100)优化的高效解码内核,该项目一经发布便引爆社区:上线45分钟斩获400+ Star,3小时突破2.7k星标(截止笔者编写时已至6.2k),创下AI工程领域新纪录!
二、核心技术解析
1. 技术亮点速览
- 硬件级优化:实现3000GB/s内存带宽 & 580TFLOPS算力(H800实测)
- 动态序列处理:支持64分块KV缓存,完美适配长上下文推理
- 开箱即用:BF16精度支持,CUDA 12.3+/PyTorch 2.0+即插即用
2. MLA vs MHA 效率跃迁之谜
-
传统MHA:如同多个专家各自研读全套资料,计算资源重复消耗,多头注意力机制的"单兵作战"模式
-
创新MLA:构建协同工作小组,通过低秩变换实现知识共享,减少70%冗余计算,低秩协同的"团队协作"模式
# 快速使用示例 from flash_mla import get_mla_metadata, flash_mla_with_kvcachetile_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q*h_q//h_kv, h_kv) output, lse = flash_mla_with_kvcache(q, kvcache, block_table, cache_seqlens, dv, tile_metadata, num_splits, causal=True)
2.1. 传统MHA
技术本质:
MHA(Multi-Head Attention)通过独立维护多头(如8个头)的Q/K/V矩阵,每个头需完整计算注意力权重:
Attention(Q_i, K_i, V_i) = softmax(Q_iK_i^T/√d)V_i
效率瓶颈:
- 重复计算:每个头独立处理完整序列(如8个专家各自研读10万字文档)
- 内存爆炸:存储8组Q/K/V矩阵,复杂度为O(8n²d)
- 硬件低效:GPU显存带宽成主要瓶颈,H100理论利用率仅35%
类比解释:
如同8位互不交流的专家,每人独立阅读全部文献资料,各自撰写分析报告后再合并结果。每个专家需要重复阅读相同内容,导致整体效率低下。
2.2. 创新MLA
技术突破:
MLA(Multi-Linear Attention)通过数学重构,将多头计算转化为共享低秩结构:
Q_shared = Q × W_q (W_q ∈ ℝ^{d×r}, r << d)
KV_shared = [K; V] × W_kv (W_kv ∈ ℝ^{2d×r})
效率飞跃:
- 参数共享:通过秩r(如r=d/4)的共享投影矩阵,参数量减少70%
- 计算优化:注意力计算复杂度从O(n²d)降为O(n²r + nr²)
- 硬件友好:H100利用率提升至75%,推理速度提升2倍
类比解释:
如同组建一个高效团队:
- 先由2位速读专家(W_q/W_kv)提炼核心知识(低秩投影)
- 团队成员基于知识图谱协作分析(共享注意力计算)
- 最终综合产出结果(动态融合)
2.3. 核心差异对比
| 维度 | MHA(传统模式) | MLA(创新模式) |
|---|---|---|
| 计算结构 | 独立多头并行计算 | 共享低秩基底 + 动态融合 |
| 内存占用 | O(8n²d) | O(2n²r + 2nr²) |
| 计算强度 | 显存带宽瓶颈(3000GB/s) | 算力主导(580TFLOPS) |
| 硬件效率 | H100利用率≈35% | H100利用率≈75% |
| 适用场景 | 短序列推理 | 长上下文(128k+ tokens) |
2.4. 效率提升70%的奥秘
设原始维度d=1024,采用r=256的低秩投影:
- 参数量对比:
MHA参数:8×(3×d²) = 24,576d
MLA参数:2×(d×r) + 2×(2d×r) = 6dr = 1,572,864
→ 参数减少 93.75% (1 - 1.5M/24.5M) - 计算量对比(n=32k序列):
MHA计算:8×(2n²d) = 16n²d ≈ 1.7e15 FLOPs
MLA计算:2n²r + 2nr² ≈ 5.2e14 FLOPs
→ 计算量减少 69.4%
2.5. FlashMLA的三大黑科技
- 分块KV缓存:将128k上下文切分为64块,避免重复计算
- 异步流水线:计算与数据搬运重叠,GPU空闲时间减少80%
- 混合精度调度:BF16存储 + FP32累加,兼顾精度与速度
伪代码示例:
# FlashMLA典型工作流(对比传统MHA)
# 传统MHA
attn_outputs = [self_attention(q, k, v) for _ in range(8)]
output = concatenate(attn_outputs)# FlashMLA
shared_basis = low_rank_project(qkv) # 核心创新点
output = dynamic_fusion(shared_basis) # 硬件加速融合
2.6. 推理成本革命
以部署32k上下文的175B模型为例:
- 硬件需求:从8×H100缩减至2×H800
- 推理延迟:从350ms降至120ms
- 单位成本:每百万token成本从0.18降至0.18降至0.06
DeepSeek的开源实践证明:通过算法创新与硬件级优化的深度结合,大模型推理效率可实现量级跃迁。这种"软硬协同"的技术路线,正在重塑AI基础设施的竞争格局。
三、开发者热评
社区反响热烈,高赞评论揭示行业期待:
- "这才是真正的开源!工程优化的教科书级案例"
- "H100利用率从35%飙到75%,推理成本砍半不是梦"
- "Day1就王炸!坐等第五天的AGI彩蛋"

四、部署指南
环境要求
| 组件 | 版本要求 |
|---|---|
| GPU架构 | NVIDIA Hopper |
| CUDA | ≥12.3 |
| PyTorch | ≥2.0 |
- CUDA安装指南
- GPU-pytorch 安装指南
性能测试
安装
git clone https://github.com/deepseek-ai/FlashMLA.git
python setup.py install
python tests/test_flash_mla.py # 在H800上体验极致速度
使用 CUDA 12.6,在 H800 SXM5 上实现高达 3000 GB/s 的内存绑定配置和 580 TFLOPS 的计算绑定配置。
使用示例
from flash_mla import get_mla_metadata, flash_mla_with_kvcachetile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)for i in range(num_layers):...o_i, lse_i = flash_mla_with_kvcache(q_i, kvcache_i, block_table, cache_seqlens, dv,tile_scheduler_metadata, num_splits, causal=True,)...
参考引用
- DeepSeek-Github
- GitHub - deepseek-ai/FlashMLA
- DeepSeek放出重磅开源!一文详解FlashMLA
- DeepSeek开源FlashMLA,推理加速核心技术,Star量飞涨中
- DeepSeek !开源周第一天 - FlashMLA
专业术语解释
- MHA(Multi-Head Attention):通过独立维护多头的Q/K/V矩阵,每个头需完整计算注意力权重。类似于多个专家各自研读全套资料,计算资源重复消耗。
- MLA(Multi-Linear Attention):通过数学重构,将多头计算转化为共享低秩结构,减少冗余计算。类似于先由速读专家提炼核心知识,团队成员再基于知识图谱协作分析。
- Hopper架构GPU:NVIDIA推出的一种GPU架构。可比喻为性能更强的新型电脑显卡架构。
- BF16精度:一种数据精度格式。类似于更精简但仍能满足一定精度要求的数字表达方式。
- CUDA:NVIDIA推出的一种并行计算平台和编程模型。如同为计算机提供的一种高效运算的工具套装。
- PyTorch:一个常用的深度学习框架。类似于为开发者搭建深度学习模型的便捷工具箱。
- KV缓存:用于存储键值对(Key-Value)的数据缓存。类似于快速存储和读取常用信息的仓库。
- 异步流水线:计算与数据搬运重叠,提高效率的技术。类似于工厂中生产流程的协同作业,减少等待时间。
- 混合精度调度:结合不同精度进行计算的策略。类似在计算中根据需要选择合适精度的工具,以兼顾效果和效率。
此次开源标志着大模型推理进入「硬件级优化」新纪元。DeepSeek团队透露,后续四天将持续放出训练框架、多模态工具链等重磅项目,值得开发者保持关注!
"The whale is making waves!" —— 社区用这句经典台词致敬DeepSeek的开源精神。在AI军备竞赛白热化的当下,中国企业正以开放姿态引领核心技术突破,这或许才是通向AGI的正确道路。
相关文章:
DeepSeek开源周Day1:FlashMLA引爆AI推理性能革命!
项目地址:GitHub - deepseek-ai/FlashMLA 开源日历:2025-02-24起 每日9AM(北京时间)更新,持续五天! 一、开源周震撼启幕 继上周预告后,DeepSeek于北京时间今晨9点准时开源「FlashMLA」,打响开源周五连…...

PCL 点云添加高斯噪声
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 在点云模型中将所有的点沿其法向量方向随机偏移一定距离,以此来得到点云实体的噪声点,偏移的幅度与点云尺度有关,偏移距离服从高斯分布,以此来获得高斯分布的噪声数据。 二、实现代码 // 标准文件 #include &l…...

通过恒定带宽服务器调度改进时间敏感网络(TSN)流量整形
论文标题 英文标题:Improving TSN Traffic Shaping with Constant Bandwidth Server Scheduling 中文标题:通过恒定带宽服务器调度改进时间敏感网络(TSN)流量整形 作者信息 作者:Benjamin van Seggelen 指导教师&am…...

软件测试高频面试题
以下是一些软件测试高频面试题: 基础概念类 HTTP和HTTPS的区别:HTTPS使用SSL/TLS协议对传输数据加密,HTTP没有加密;HTTPS可确保数据完整性,防止传输中被篡改,HTTP不保证;HTTP默认用80端口&…...

英语学习DAY5
内心旁白 关于我为什么从2月5号开的这个篇章现在才第五天这件事? 咳咳咳,容许我狡辩一下,我是有事去忙了,我真的很想每日学习英语(信我兄弟们)! 虽然英语学习对我来说真的很难,你…...

如何查看图片的原始格式
问题描述:请求接口的时候,图片base64接口报错,使用图片url请求正常 排查发现是图片格式的问题: 扩展名可能被篡改:如果文件损坏或扩展名被手动修改,实际格式可能与显示的不同,需用专业工具验证…...
:让自然梯度在深度学习中飞起来)
Kronecker分解(K-FAC):让自然梯度在深度学习中飞起来
Kronecker分解(K-FAC):让自然梯度在深度学习中飞起来 在深度学习的优化中,自然梯度下降(Natural Gradient Descent)是一个强大的工具,它利用Fisher信息矩阵(FIM)调整梯度…...
赛前启航 | 三场重磅直播集结,予力微软 AI 开发者挑战赛!
随着微软 AI 开发者挑战赛的火热进行,赛前指导直播已成为众多参赛者获取技术干货、灵感碰撞和实战技巧的绝佳平台。继前两期的精彩呈现,第三、四、五期直播即将接连登场,为开发者们带来更加深入的 AI 技术剖析和项目实战指引。无论你是想进一…...

VMware安装Centos 9虚拟机+设置共享文件夹+远程登录
一、安装背景 工作需要安装一台CentOS-Stream-9的机器环境,所以一开始的安装准备工作有: vmware版本:VMware Workstation 16 镜像版本:CentOS-Stream-9-latest-x86_64-dvd1.iso (kernel-5.14.0) …...

【HarmonyOS Next】地图使用详解(一)
背景 这系列文章主要讲解鸿蒙地图的使用,当前可以免费使用,并提供了丰富的SDK给开发者去自定义控件开发。目前可以实现个性化显示地图、位置搜索和路径规划等功能,轻松完成地图构建工作。需要注意的是,现在测试只能使用实体手机去…...

【NLP 37、激活函数 ③ relu激活函数】
—— 25.2.23 ReLU广泛应用于卷积神经网络(CNN)和全连接网络,尤其在图像分类(如ImageNet)、语音识别等领域表现优异。其高效性和非线性特性使其成为深度学习默认激活函数的首选 一、定义与数学表达式 ReLU࿰…...

顶刊配图复现:Origin+DeepSeek完美协同
学习目标: (1)软件掌握熟练安装并配置Origin,掌握基础操作与核心功能。学会利用Origin进行多类型图表绘制及美化。掌握DeepSeek的数据清洗、统计分析与可视化方法。(2)设计能力理解顶刊图表的设计原则&…...
与自然梯度下降:机器学习中的优化利器)
Fisher信息矩阵(Fisher Information Matrix, FIM)与自然梯度下降:机器学习中的优化利器
Fisher信息矩阵与自然梯度下降:机器学习中的优化利器 在机器学习尤其是深度学习中,优化模型参数是一个核心任务。我们通常依赖梯度下降(Gradient Descent)来调整参数,但普通的梯度下降有时会显得“笨拙”,…...

Scratch032(百发百中)
提示:知识回顾 1、排列克隆体的方法 2、复习“发送广播并等待”积木 3、“获取第几个字符”积木的使用 4、使用角色显示得分 前言 提示:中国射箭拥有悠久的历史,是最早进入教育体系的运动项目之一,君子六艺中“礼,乐,射,御,书,数”的射 ,就是指的射箭。这节课我带你…...

DeepSeek技术全景解析:架构创新与行业差异化竞争力
一、DeepSeek技术体系的核心突破 架构设计:效率与性能的双重革新 Multi-head Latent Attention (MLA):通过将注意力头维度与隐藏层解耦,实现显存占用降低30%的同时支持4096超长上下文窗口。深度优化的MoE架构:结合256个路由专家…...
认证培训)
开课倒计时 | 3月1-2日,DeepSeek时代下的可观测性(Observability)认证培训
前言: 随着DeepSeek等前沿AI技术的广泛应用,企业对可观测性的需求日益增长。DeepSeek作为一款强大的AI模型,已经在多个领域展现出其卓越的性能。然而,随着技术复杂性的增加,如何有效监控和优化这些系统成为关键挑战。…...
)
相似性搜索(2)
在本篇中,我们通过播客相似性搜索为例,进一步研究基于chroma 的相似性搜索: 参考: https://www.kaggle.com/code/switkowski/building-a-podcast-recommendation-engine/notebook 数据集来源: https://www.kaggle.…...

Python天梯赛L1-018-大笨钟详解
018-大笨钟 微博上有个自称“大笨钟V”的家伙,每天敲钟催促码农们爱惜身体早点睡觉。不过由于笨钟自己作息也不是很规律,所以敲钟并不定时。一般敲钟的点数是根据敲钟时间而定的,如果正好在某个整点敲,那么“当”数就等于那个整点…...

HTTP代理与HTTPS代理的区别及HTTPS的工作原理
在互联网世界中,数据的传输与访问安全性是用户和企业共同关注的焦点。HTTP和HTTPS代理作为两种常用的网络协议代理,它们在工作原理和应用场景上存在显著区别。本文将深入浅出地解析HTTP代理与HTTPS代理的区别,并简明扼要地介绍HTTPS的工作原理…...

【Godot4.3】静态模板字符串函数库
概述 Godot的静态函数从3.4版本一直用到现在的4.3,也曾经编写过不少的静态函数库。 但是一直没怎么用过静态变量。这几天有心重新开发一下静态网页生成器。需要编写一些类,还有保存HTML页面或局部的模板字符串以及生成函数。静态变量就刚好用上了。 这…...

Minio分布式多节点多驱动器集群部署
Minio分布式多节点多驱动器集群部署 Minio分布式多节点多驱动器集群部署节点规划先决条件开放防火墙端口设置主机名更新域名映射文件时间同步存储要求内存要求 增加虚拟机磁盘(所有机器都要执行)部署分布式 MinIO测试上传与预览测试高可用MinIO 配置限制模拟单节点磁盘故障模拟…...

忽略Git文件的修改,让它不被提交
使用Git托管的工程中,经常有这样的需求,希望文件只是本地修改,不提交到服务端。 如果仅仅是本地存在的文件,我们可以通过.gitignore配置避免文件被提交。 有的时候文件是由git托管的,但是我们希望只在本地修改&#…...

EntityFrameCore DbFirst 迁移
ORM框架:不用关心sql语句,只需要以类为单位,去操作数据库,以面向对象的思想来完成对数据库的操作。 EntityFrameCore-DbFirst Nuget引入程序集 Microsoft.EntityFrameworkCore Microsoft.EntityFrameworkCore.SqlServer Microsoft.EntityFrameworkCore.SqlServer.Design…...

【信号量】
信号量 目录操作系统信号信号的默认处理动作示例解释信号的捕获与处理使用 signal 函数使用 sigaction 函数 信号的阻塞 信号的生命周期1. 信号产生2. 信号在进程中注册3. 信号在进程中注销4. 信号处理main 7 signal命令含义使用场景手册页包含的关键信息1. 信号概述2. 信号列表…...

安卓cmake修改版本设置路径
有两个位置需要修改: 1、local.properties 在这里设置cmake的本地路径 cmake.dirE\:\\Android_Studio\\sdk\\cmake\\3.22.1 sdk.dirE\:\\Android_Studio\\sdk2、build.gradle里面内容的修改 apply plugin: com.android.applicationandroid {compileSdkVersion 24b…...

如何安装VMware
安装VM...
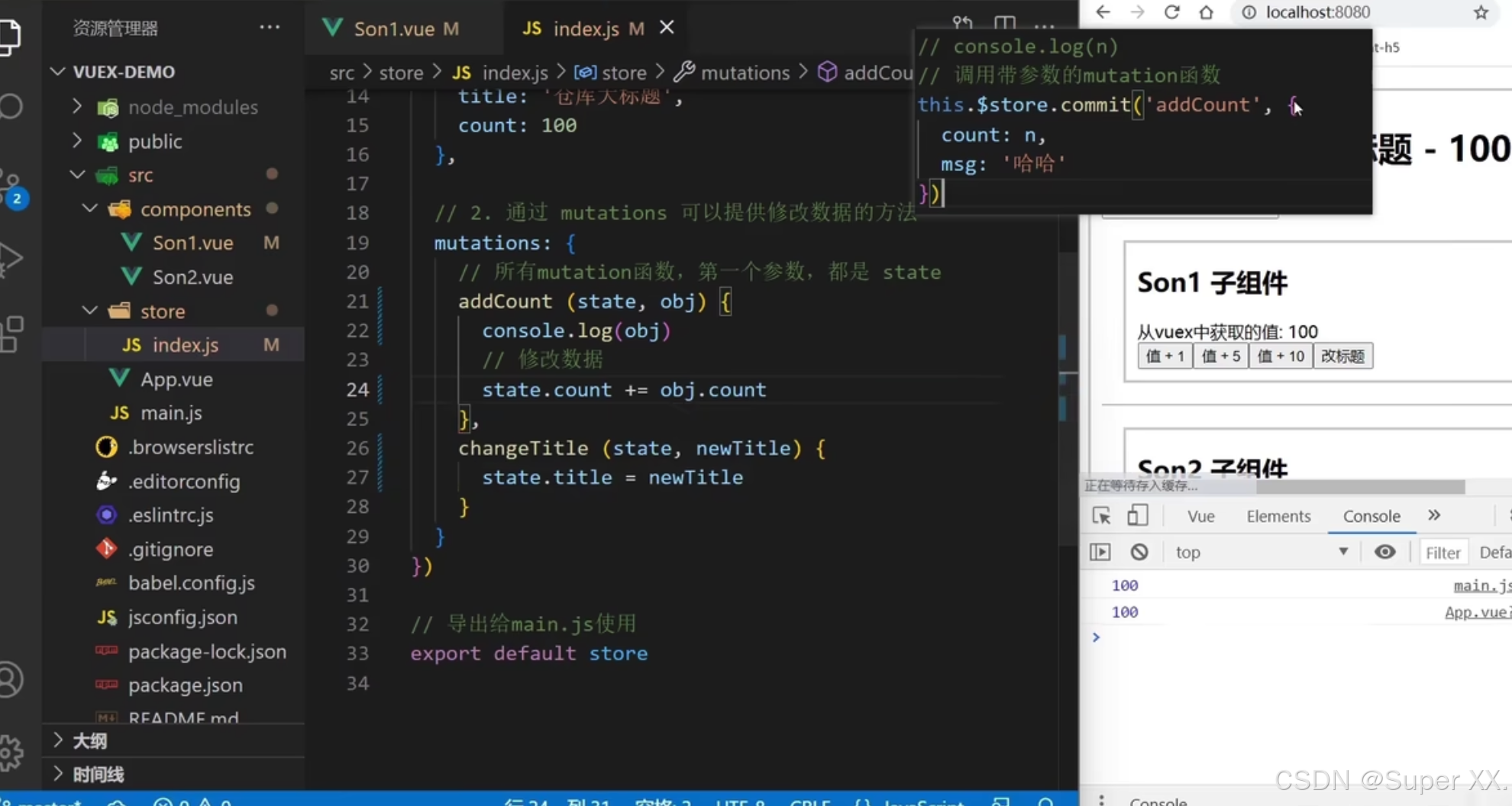
一篇文章学懂Vuex
一、基于VueCli自定义创建项目 233 344 二、Vuex 初始准备 建项目的时候把vuex勾选上就不用再yarn add vuex3了 store/index.js // 这里面存放的就是vuex相关的核心代码 import Vuex from vuex import Vue from vue// 插件安装 Vue.use(Vuex)// 创建仓库(空仓库…...

DeepSeek 助力 Vue 开发:打造丝滑的二维码生成(QR Code)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...

选择排序:简单高效的选择
大家好,今天我们来聊聊选择排序(Selection Sort)算法。这是一个非常简单的排序算法,适合用来学习排序的基本思路和操作。选择排序在许多排序算法中以其直观和易于实现的特点著称,虽然它的效率不如其他高效算法…...

图像处理篇---图像处理中常见参数
文章目录 前言一、分贝(dB)的原理1.公式 二、峰值信噪比(PSNR, Peak Signal-to-Noise Ratio)1.用途2.公式3.示例 三、信噪比(SNR, Signal-to-Noise Ratio)1.用途2.公式3.示例 四、动态范围(Dyna…...