深入解析Crawl4AI:为AI应用量身定制的高效开源爬虫框架
引言
在当今数据驱动的时代,人工智能(AI)和大型语言模型(LLM)的发展对高质量数据的需求日益增长。如何高效地从互联网上获取、处理和提取有价值的数据,成为了研究人员和开发者面临的关键挑战。Crawl4AI作为一款专为AI应用设计的开源爬虫框架,凭借其高性能、灵活性和易用性,正在成为解决这一挑战的有力工具。
一、Crawl4AI概述
1.1 项目背景
Crawl4AI由开源社区开发,旨在为AI应用和LLM提供高效的数据抓取和处理方案。其设计初衷是简化网页数据的获取过程,为模型训练和数据分析提供可靠的数据来源。
1.2 核心特点
- 高性能:采用异步编程模型,支持多URL并行抓取,极大提升了数据采集效率。
- 多格式支持:能够输出JSON、清洁的HTML、Markdown等多种格式,方便后续的数据处理和模型训练。
- 灵活定制:提供自定义钩子、用户代理设置、JavaScript执行等功能,满足不同场景下的数据抓取需求。
- 媒体和链接提取:自动提取网页中的图片、音频、视频等媒体资源,以及所有内外部链接,丰富了数据的多样性。
- 开源免费:遵循Apache-2.0许可协议,开发者可以自由使用、修改和分发。
二、技术架构与实现
2.1 异步编程模型
Crawl4AI采用Python的asyncio库,实现了异步编程模型。相比传统的同步爬虫,异步模型允许在同一时间处理多个请求,避免了阻塞操作,提高了爬取速度和资源利用率。
import asyncio
from crawl4ai import AsyncWebCrawlerasync def main():async with AsyncWebCrawler(verbose=True) as crawler:result = await crawler.arun(url="https://www.example.com")print(result.markdown)if __name__ == "__main__":asyncio.run(main())
在上述示例中,AsyncWebCrawler通过异步上下文管理器实现了高效的资源管理和并发处理。
2.2 内容解析与提取
Crawl4AI结合了BeautifulSoup和lxml等解析库,对获取的HTML/XML内容进行深度解析。通过CSS选择器和XPath等方式,精确定位并提取网页中的关键信息。
from bs4 import BeautifulSouphtml_content = "<html><body><h1>Hello, World!</h1></body></html>"
soup = BeautifulSoup(html_content, 'lxml')
heading = soup.find('h1').text
print(heading) # 输出:Hello, World!
此外,Crawl4AI还支持正则表达式,用于匹配和提取特定模式的数据,增强了数据提取的灵活性。
2.3 动态内容处理
面对现代网页中广泛存在的动态内容,Crawl4AI集成了Playwright和Selenium等浏览器自动化工具,能够执行JavaScript代码,渲染动态页面,从而获取完整的网页内容。
from crawl4ai import AsyncWebCrawlerasync def main():async with AsyncWebCrawler(verbose=True) as crawler:result = await crawler.arun(url="https://www.dynamicwebsite.com",js_code=["document.querySelector('button.load-more').click();"],css_selector="div.content")print(result.markdown)if __name__ == "__main__":asyncio.run(main())
通过在爬取过程中执行自定义的JavaScript代码,Crawl4AI可以模拟用户操作,加载更多内容,确保数据的完整性。
2.4 高级提取策略
Crawl4AI提供了多种高级提取策略,如余弦聚类和LLM等,帮助用户从海量数据中提取高质量、相关性强的信息。
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from pydantic import BaseModel, Fieldclass ProductInfo(BaseModel):name: str = Field(..., description="Product name")price: str = Field(..., description="Product price")strategy = LLMExtractionStrategy(provider="openai/gpt-4",api_token="your_openai_api_key",schema=ProductInfo.schema(),extraction_type="schema",instruction="Extract product names and prices from the page."
)
通过定义数据模型和提取策略,Crawl4AI能够自动从网页中提取结构化的数据,减少人工干预,提高效率。
四、实战操作:爬取股票信息
4.1 爬取实时股票数据
以下示例展示如何使用Crawl4AI爬取股票市场的实时数据。
import asyncio
from crawl4ai import AsyncWebCrawlerasync def fetch_stock_data():url = "https://finance.yahoo.com/quote/AAPL"async with AsyncWebCrawler(verbose=True) as crawler:result = await crawler.arun(url=url, css_selector="div#quote-header-info")print(result.markdown)if __name__ == "__main__":asyncio.run(fetch_stock_data())
该代码从Yahoo Finance抓取Apple(AAPL)股票的最新行情,并解析关键数据。
4.2 解析与存储数据
爬取的股票信息可以进一步解析,并存入数据库或文件进行后续分析。
import jsondef save_to_json(data, filename="stock_data.json"):with open(filename, "w") as f:json.dump(data, f, indent=4)stock_data = {"symbol": "AAPL", "price": 150.75, "change": "+1.25"}
save_to_json(stock_data)
这样,Crawl4AI不仅可以爬取实时股票信息,还能将数据存储下来,便于后续分析和预测。
通过以上步骤,开发者可以利用Crawl4AI快速构建高效的爬虫,获取实时股票数据,为AI模型提供精准的数据支持。
相关文章:

深入解析Crawl4AI:为AI应用量身定制的高效开源爬虫框架
引言 在当今数据驱动的时代,人工智能(AI)和大型语言模型(LLM)的发展对高质量数据的需求日益增长。如何高效地从互联网上获取、处理和提取有价值的数据,成为了研究人员和开发者面临的关键挑战。Crawl4AI作为…...

python量化交易——金融数据管理最佳实践——qteasy创建本地数据源
文章目录 qteasy金融历史数据管理总体介绍本地数据源——DataSource对象默认数据源查看数据表查看数据源的整体信息最重要的数据表其他的数据表 从数据表中获取数据向数据表中添加数据删除数据表 —— 请尽量小心,删除后无法恢复!!总结 qteas…...

Python标准库【os】5 文件和目录操作2
文章目录 8 文件和目录操作8.7 浏览目录下的内容8.8 查看文件或目录的信息8.9 文件状态修改文件标志位文件权限文件所属用户和组其它 8.10 浏览Windows的驱动器、卷、挂载点8.11 系统配置信息 os模块提供了各种操作系统接口。包括环境变量、进程管理、进程调度、文件操作等方面…...

⭐算法OJ⭐矩阵的相关操作【动态规划 + 组合数学】(C++ 实现)Unique Paths 系列
文章目录 62. Unique Paths动态规划思路实现代码复杂度分析 组合数学思路实现代码复杂度分析 63. Unique Paths II动态规划定义状态状态转移方程初始化复杂度分析 优化空间复杂度状态转移方程 62. Unique Paths There is a robot on an m x n grid. The robot is initially lo…...

【Java基础】Java中new一个对象时,JVM到底做了什么?
Java中new一个对象时,JVM到底做了什么? 在Java编程中,new关键字是我们创建对象的最常用方式。但你是否想过,当你写下new MyClass()时,Java虚拟机(JVM)到底在背后做了哪些工作?今天&…...

Baklib云内容中台的核心架构是什么?
云内容中台分层架构解析 现代企业内容管理系统的核心在于构建动态聚合与智能分发的云端中枢。以Baklib为代表的云内容中台采用三层架构设计,其基础层为数据汇聚工具集,通过标准化接口实现多源异构数据的实时采集与清洗,支持从CRM、ERP等业务…...

一个基于vue3的图片瀑布流组件
演示 介绍 基于vue3的瀑布流组件 演示地址: https://wanning-zhou.github.io/vue3-waterfall/ 安装 npm npm install wq-waterfall-vue3yarn yarn add wq-waterfall-vue3pnpm pnpm add wq-waterfall-vue3使用 <template><Waterfall :images"imageList&qu…...

内存中的缓存区
在 Java 的 I/O 流设计中,BufferedInputStream 和 BufferedOutputStream 的“缓冲区”是 内存中的缓存区(具体是 JVM 堆内存的一部分),但它们的作用是优化数据的传输效率,并不是直接操作硬盘和内存之间的缓存。以下是详…...

【pytest框架源码分析一】pluggy源码分析之hook常用方法
简单看一下pytest的源码,其实很多地方是依赖pluggy来实现的。这里我们先看一下pluggy的源码。 pluggy的目录结构如下: 这里主要介绍下_callers.py, _hooks.py, _manager.py,其中_callers.py主要是提供具体调用的功能,_hooks.py提…...

《Kafka 理解: Broker、Topic 和 Partition》
Kafka 核心架构解析:从概念到实践 Kafka 是一个分布式流处理平台,广泛应用于日志收集、实时数据分析和事件驱动架构。本文将从 Kafka 的核心组件、工作原理、实际应用场景等方面进行详细解析,帮助读者深入理解 Kafka 的架构设计及其在大数据领域的重要性。 1. Kafka 的背…...

【AHK】资源管理器自动化办公实例/自动连点设置
此处为一个自动连续点击打开检查的自动化操作案例,没有quicker的鼠键录制,不常用了,做个备份 #MaxThreadsPerHotkey 2 ; 这个是核心!!!!确保可以同时运行多个热键或标签global isRunning : tru…...

在docker容器中运行vllm部署deepseek-r1大模型
# 在本地部署python环境 cd /app/ python -m venv myenv # 激活虚拟环境 source /app/myenv/activate # 要撤销激活一个虚拟环境,请输入: deactivate# 进入虚拟环境安装modelscope pip install modelscope# 下载大模型(7B为例) modelscope do…...
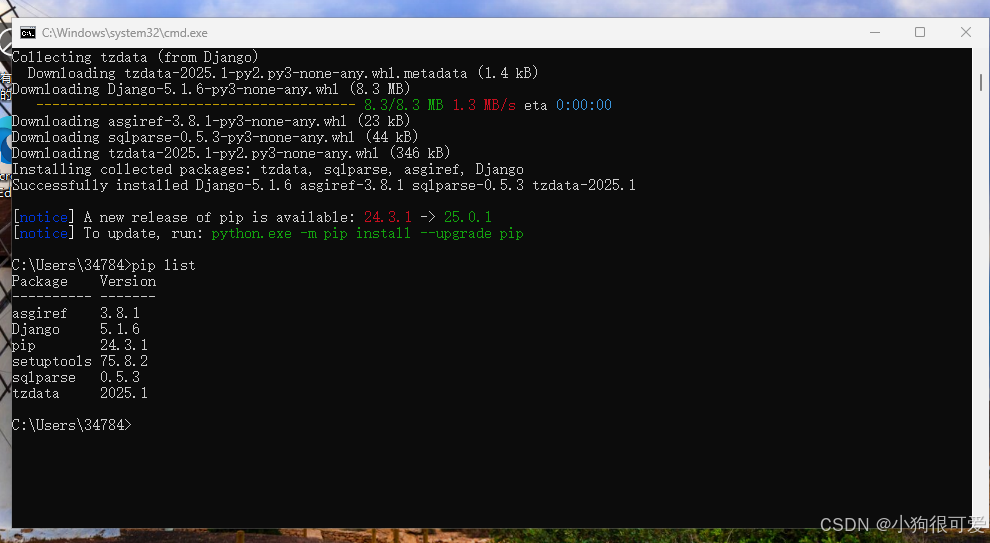
Django基础环境准备
Django基础环境准备 文章目录 Django基础环境准备1.准备的环境 win11系统(运用虚拟环境搭建)1.1详见我的资源win11环境搭建 2.准备python环境2.1 winr 打开命令提示符 输入cmd 进入控制台2.2 输入python --version 查看是否有python环境2.3在pyhton官网下…...

使用DeepSeek实现自动化编程:类的自动生成
目录 简述 1. 通过注释生成C类 1.1 模糊生成 1.2 把控细节,让结果更精准 1.3 让DeepSeek自动生成代码 2. 验证DeepSeek自动生成的代码 2.1 安装SQLite命令行工具 2.2 验证DeepSeek代码 3. 测试代码下载 简述 在现代软件开发中,自动化编程工具如…...

nio使用
NIO : new Input/Output,,在java1.4中引入的一套新的IO操作API,,,旨在替代传统的IO(即BIO:Blocking IO),,,nio提供了更高效的 文件和网络IO的 操作…...

【考试大纲】中级网络工程师考试大纲(最新版与旧版对比)
目录 引言考试科目1:网络工程师基础知识考试科目2:网络工程师应用技术引言 最新的网络工程师考试大纲出版于 2024 年 10 月,本考试大纲基于此版本整理。 考试科目1:网络工程师基础知识 计算机系统知识1.1 计算机硬件知识 1.2 操作系统知识 1.3 系统管理 系统开发和运行…...

Spring的下载与配置
1. 下载spring开发包 下载地址:https://repo.spring.io/webapp/#/artifacts/browse/simple/General/libs-release-local/org/springframework/spring 打开之后可以看到有很多版本供选择,因为视频教程用的是4.2.4版本,于是我也选择这个 右键…...

解决IDEA使用Ctrl + / 注释不规范问题
问题描述: ctrl/ 时,注释缩进和代码规范不一致问题 解决方式 设置->编辑器->代码样式->java->代码生成->注释代码...
学术小助手智能体
学术小助手:开学季的学术领航员 文心智能体平台AgentBuilder | 想象即现实 文心智能体平台AgentBuilder,是百度推出的基于文心大模型的智能体平台,支持广大开发者根据自身行业领域、应用场景,选取不同类型的开发方式,…...

kafka-leader -1问题解决
一. 问题: 在 Kafka 中,leader -1 通常表示分区的领导者副本尚未被选举出来,或者在获取领导者信息时出现了问题。以下是可能导致出现 kafka leader -1 的一些常见原因及相关分析: 1. 副本同步问题: 在 Kafka 集群中&…...

【开源-鸿蒙土拨鼠大理石系统】鸿蒙 HarmonyOS Next App+微信小程序+云平台
✨本人自己开发的开源项目:土拨鼠充电系统 ✨踩坑不易,还希望各位大佬支持一下,在GitHub给我点个 Start ⭐⭐👍👍 ✍GitHub开源项目地址👉:https://github.com/lusson-luo/HarmonyOS-groundhog-…...

HBuilder X中,uni-app、js的延时操作及定时器
完整源码下载 https://download.csdn.net/download/luckyext/90430165 在HBuilder X中,uni-app、js的延时操作及定时器可以用setTimeout和setInterval这两个函数来实现。 1.setTimeout函数用于在指定的毫秒数后执行一次函数。 例如, 2秒后弹出一个提…...

下载pyenv
安装 1、git clone https://gitclone.com/github.com/pyenv/pyenv.git ~/.pyenv 备用:git clone https://hub.fgit.ml/pyenv/pyenv.git ~/.pyenv 配置环境变量 export PYENV_ROOT"$HOME/.pyenv" export PATH"$PYENV_ROOT/bin:$PATH"然后&…...

升级TTSDK抖音小游戏banner广告接入
升级TTSDK抖音小游戏banner广告接入 介绍修改总结 介绍 我们原来使用的是unity2021,这次为了抖音新出的TTSDK中的新的API升级我们将项目升级为了unity2022,这次抖音官方剔除了原来StartSDKUnityTools和Start Asset Analyser(startmini&#x…...

vue 项目部署到nginx 服务器
一 vue 项目打包 1 本地环境 npm run build 2 打包完成生成一个dist 文件夹,将其放到服务器指定的文件夹,此文件夹可以在nginx 配置文件中配置 二 nginx 1 根据对应的系统搜索安装命令 sudo yum install nginx 2 查看conf位置 如果不知道的话 ng…...

ubuntu终端指令集 shell编程基础(一)
磁盘指令 连接与查看:磁盘与 Ubuntu 有两种连接方式;使用ls /dev/sd*查看是否连接成功,通过df系列指令查看磁盘使用信息。若 U 盘已挂载,相关操作可能失败,需用umount取消挂载。磁盘操作:使用sudo fdisk 磁…...

win11编译pytorch cuda128版本流程
Geforce 50xx系显卡最低支持cuda128,torch cu128 release版本目前还没有释放,所以自己基于2.6.0源码自己编译wheel包。 1. 前置条件 1. 使用visual studio installer 安装visual studio 2022,工作负荷选择【使用c的桌面开发】,安装完成后将…...

STM32G431RBT6——(1)芯片命名规则
相信很多新手入门STM学的芯片,是STM32F103C8T6,假如刷到个项目换个芯片类型,就会感到好难啊,看不懂,就无从下手,不知所云。其实没什么难的,对于一个个不同的芯片的区别,就像是学习包…...

mac Homebrew安装、更新失败
我这边使用brew安装git-lfs 一直报这个错: curl: (35) LibreSSL SSL_connect: SSL_ERROR_SYSCALL更新brew update也是报这个错误。最后使用使用大佬提供的脚本进行操作: /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/mast…...

Ecode前后端传值
说明 在泛微 E9 系统开发过程中,使用 Ecode 调用后端接口并进行传值是极为常见且关键的操作。在上一篇文章中,我们探讨了 Ecode 调用后端代码的相关内容,本文将深入剖析在 Ecode 中如何向后端传值,以及后端又该如何处理接收这些值…...