预训练(Pretraining)阶段为何被称为“自监督学习”(Self-Supervised Learning)?
预训练阶段为何被称为自监督学习?
在人工智能领域,尤其是自然语言处理(NLP)和深度学习的快速发展中,预训练(Pretraining)已经成为一种不可或缺的技术手段。而其中一个重要的概念是“自监督学习”(Self-Supervised Learning),它在预训练阶段扮演了核心角色。那么,为什么预训练阶段可以被称为自监督学习呢?让我们一起来探讨这个问题,并深入理解它的原理和意义。
什么是自监督学习?
自监督学习是一种介于监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)之间的方法。传统的监督学习需要大量带有明确标签的数据,例如在一组图片中标注“猫”或“狗”,由人工或外部来源提供这些标签。而无监督学习则完全不需要标签,通常用于发现数据中的隐藏模式,比如聚类。然而,自监督学习的独特之处在于,它从数据本身中生成“伪标签”(Pseudo-Labels),无需外部标注。
在自监督学习的框架下,模型通过解决一个设计好的任务来学习数据的内在表示。例如,在图像领域,一个常见的自监督任务是将图片的一部分遮挡,让模型预测被遮挡的内容。而在语言领域,任务可能是预测句子的下一个单词或填补被掩盖的词语。这种方法的核心在于,标签并不是人为提供的,而是从数据自身的结构中自然衍生出来的。
预训练中的自监督学习
在自然语言处理的预训练阶段,自监督学习得到了广泛应用。以著名的BERT模型为例,它通过“掩码语言模型”(Masked Language Model, MLM)任务进行预训练:随机遮盖输入句子中的某些单词,让模型根据上下文预测这些被遮盖的单词。而GPT系列模型则采用“因果语言模型”(Causal Language Model),通过预测句子的下一个单词来进行学习。
这些任务的标签从哪里来呢?答案是数据本身。以文本数据为例,当我们输入一段话时,句子的每个单词都可以作为预测目标,而无需额外的标注工作。例如,在句子“我今天去超市买了东西”中,如果任务是预测下一个单词,模型会基于“我今天去超市买了”来预测“东西”。这里的“东西”就是天然的标签,直接从原始数据中提取。这种利用数据自身结构生成标签的方式,正是自监督学习的精髓。
因此,预训练阶段被称为自监督学习,是因为它不需要人工标注的外部标签,而是通过设计巧妙的任务,让模型从无标签的数据中自我学习有意义的表示。
自监督学习的优势
自监督学习之所以在预训练中大放异彩,主要归功于以下几点优势:
-
利用大规模无标签数据
在现实世界中,获取大量标注数据往往成本高昂且耗时。而文本数据(如网页、书籍、文章)在互联网上几乎是无穷无尽的。通过自监督学习,我们可以充分利用这些未标注的数据进行模型训练,无需担心版权问题或标注资源的限制。 -
降低人工成本
由于标签直接从数据中生成,自监督学习省去了手动标注的步骤。这不仅提高了效率,还使得训练大规模模型成为可能。 -
学习通用表示
自监督学习的目标通常是捕捉数据的底层规律和特征。例如,在语言模型中,预训练阶段可以让模型理解语法、语义和上下文关系。这些通用的表示在后续的微调(Fine-tuning)阶段可以迁移到具体任务(如文本分类、机器翻译)中,表现出色。
自监督学习的挑战与未来
尽管自监督学习在预训练中取得了巨大成功,但它也面临一些挑战。例如,如何设计更高效的任务以提取更有意义的特征?如何确保模型不会过度依赖数据的表面模式,而忽略更深层次的语义?这些问题仍在研究中。
未来,随着计算能力和数据规模的进一步提升,自监督学习可能会在更多领域展现潜力。例如,在多模态学习中,结合文本、图像和音频的自监督方法正在兴起,为构建更智能的AI系统铺平道路。
总结
预训练阶段之所以被称为自监督学习,是因为它通过从数据本身生成标签的方式,巧妙地绕过了传统监督学习对外部标注的依赖。这种方法不仅高效地利用了大规模无标签数据集,还为模型提供了强大的通用表示能力。正因如此,自监督学习成为了现代AI技术发展的基石之一,推动了从语言理解到图像生成等众多领域的突破。
Why Is the Pretraining Stage Called Self-Supervised Learning?
The pretraining stage in modern artificial intelligence, particularly in natural language processing (NLP) and deep learning, is often referred to as “self-supervised learning.” But why is that? To answer this, let’s break it down step by step and explore the concept in a clear and concise way.
What Is Self-Supervised Learning?
Self-supervised learning sits somewhere between supervised learning and unsupervised learning. In supervised learning, models rely on large datasets with explicit labels—like tagging images as “cat” or “dog”—provided by humans or external sources. Unsupervised learning, on the other hand, works without labels, focusing on finding hidden patterns in the data, such as clustering similar items together. Self-supervised learning, however, takes a unique approach: it generates “pseudo-labels” directly from the data itself, eliminating the need for external annotations.
In this framework, the model learns by solving a task that’s cleverly designed to extract meaning from the data’s inherent structure. For example, in NLP, a common self-supervised task is predicting the next word in a sentence or filling in a blank where a word has been masked. The key here is that the labels aren’t provided by humans—they come from the data naturally.
Self-Supervised Learning in Pretraining
In the pretraining phase of models like BERT or GPT, self-supervised learning shines. Take BERT’s “Masked Language Model” (MLM) as an example: it randomly masks certain words in a sentence and asks the model to predict them based on the surrounding context. GPT, meanwhile, uses a “Causal Language Model,” predicting the next word in a sequence. In both cases, the “label” for training isn’t something added externally—it’s already part of the dataset.
For instance, in the sentence “I went to the store today,” a model might be tasked with predicting “today” based on “I went to the store.” Here, “today” serves as the label, derived directly from the text itself. This ability to use the data’s own structure to create training targets is what makes pretraining self-supervised. No human intervention is needed to label the data—the model supervises itself.
Why It’s Called Self-Supervised
The term “self-supervised” comes from this process: the supervision (i.e., the labels or targets) is self-generated from the unlabeled dataset. Unlike supervised learning, where an external teacher provides the answers, or unsupervised learning, where there’s no explicit task, self-supervised learning creates its own teacher within the data. That’s why pretraining fits this category perfectly—it leverages vast amounts of unstructured text (like books or web pages) and turns it into a structured learning problem without extra effort.
Benefits of Self-Supervised Learning in Pretraining
This approach has some powerful advantages:
-
Access to Massive Unlabeled Data: Labeled datasets are expensive and time-consuming to create, but unlabeled data—like text scraped from the internet—is abundant. Self-supervised learning taps into this resource effortlessly.
-
No Manual Labeling: Since the labels come from the data itself, there’s no need for costly human annotation, making it scalable and efficient.
-
General-Purpose Representations: By learning from broad, diverse datasets, models develop versatile features (like understanding grammar or context) that can later be fine-tuned for specific tasks.
Final Thoughts
The pretraining stage earns its “self-supervised learning” title because it ingeniously uses the data’s own content as both the question and the answer. This method has revolutionized AI, enabling models to learn from the vast, messy world of unlabeled data and paving the way for breakthroughs in language understanding and beyond. So, next time you hear about self-supervised learning, you’ll know it’s all about letting the data teach itself!
后记
2025年3月1日13点26分于上海,在grok3大模型辅助下完成。
相关文章:
阶段为何被称为“自监督学习”(Self-Supervised Learning)?)
预训练(Pretraining)阶段为何被称为“自监督学习”(Self-Supervised Learning)?
预训练阶段为何被称为自监督学习? 在人工智能领域,尤其是自然语言处理(NLP)和深度学习的快速发展中,预训练(Pretraining)已经成为一种不可或缺的技术手段。而其中一个重要的概念是“自监督学习…...

【已解决】pyodbc 5.2 [ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序
问题 当升级 pyodbc 5.2 版本后,连接 sqlserver 数据库,报错如下: 连接失败: (IM002, [IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序 (0) (SQLDriverConnect); [IM002] [Microsoft][ODBC 驱动程序管理…...

时钟树的理解
对应电脑的主板,CPU,硬盘,内存条,外设进行学习 AHB总线 -72MHZ max APB1总线 -36MHZ max APB2-72MHZ max 时序逻辑电路需要时钟线控制 ,含有记忆性的原件的存在。(只有时钟信号才能工作&…...

AI 实战2 - face -detect
人脸检测 环境安装源设置conda 环境安装依赖库 概述数据集wider_face转yolo环境依赖标注信息格式转换图片处理生成 train.txt 文件 数据集展示数据集加载和处理 参考文章 环境 安装源设置 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/f…...

CentOS vs Ubuntu - 常用命令深度对比及最佳实践指南20250302
CentOS vs Ubuntu - 常用命令深度对比及最佳实践指南 引言 在 Linux 服务器操作系统领域,CentOS 和 Ubuntu 是广泛采用的发行版。它们在命令集、默认工具链及生态系统方面各有特点。本文深入剖析 CentOS 与 Ubuntu 在常用命令层面的异同,并结合实践案例…...

问题修复-后端返给前端的时间展示错误
问题现象: 后端给前端返回的时间展示有问题。 需要按照yyyy-MM-dd HH:mm:ss 的形式展示 两种办法: 第一种 在实体类的属性上添加JsonFormat注解 第二种(建议使用) 扩展mvc框架中的消息转换器 代码: 因为配置类继…...

为AI聊天工具添加一个知识系统 之127 详细设计之68 编程 核心技术:Cognitive Protocol Language 之1
本文要点 要点 今天讨论的题目:本项目(为使用AI聊天工具的两天者加挂一个知识系统) 详细程序设计 之“编程的核心技术” 。 source的三个子类(Instrument, Agent, Effector) 分别表示--实际上actually ,…...

多个pdf合并成一个pdf的方法
将多个PDF文件合并优点: 能更容易地对其进行归档和备份.打印时可以选择双面打印,减少纸张的浪费。比如把住宿发票以及滴滴发票、行程单等生成一个pdf,双面打印或者无纸化办公情况下直接发送给财务进行存档。 方法: 利用PDF24 Tools网站 …...

周边游平台设计与实现(代码+数据库+LW)
摘 要 在如今社会上,关于信息上面的处理,没有任何一个企业或者个人会忽视,如何让信息急速传递,并且归档储存查询,采用之前的纸张记录模式已经不符合当前使用要求了。所以,对旅游信息管理的提升,…...

深入解析Crawl4AI:为AI应用量身定制的高效开源爬虫框架
引言 在当今数据驱动的时代,人工智能(AI)和大型语言模型(LLM)的发展对高质量数据的需求日益增长。如何高效地从互联网上获取、处理和提取有价值的数据,成为了研究人员和开发者面临的关键挑战。Crawl4AI作为…...

python量化交易——金融数据管理最佳实践——qteasy创建本地数据源
文章目录 qteasy金融历史数据管理总体介绍本地数据源——DataSource对象默认数据源查看数据表查看数据源的整体信息最重要的数据表其他的数据表 从数据表中获取数据向数据表中添加数据删除数据表 —— 请尽量小心,删除后无法恢复!!总结 qteas…...

Python标准库【os】5 文件和目录操作2
文章目录 8 文件和目录操作8.7 浏览目录下的内容8.8 查看文件或目录的信息8.9 文件状态修改文件标志位文件权限文件所属用户和组其它 8.10 浏览Windows的驱动器、卷、挂载点8.11 系统配置信息 os模块提供了各种操作系统接口。包括环境变量、进程管理、进程调度、文件操作等方面…...

⭐算法OJ⭐矩阵的相关操作【动态规划 + 组合数学】(C++ 实现)Unique Paths 系列
文章目录 62. Unique Paths动态规划思路实现代码复杂度分析 组合数学思路实现代码复杂度分析 63. Unique Paths II动态规划定义状态状态转移方程初始化复杂度分析 优化空间复杂度状态转移方程 62. Unique Paths There is a robot on an m x n grid. The robot is initially lo…...

【Java基础】Java中new一个对象时,JVM到底做了什么?
Java中new一个对象时,JVM到底做了什么? 在Java编程中,new关键字是我们创建对象的最常用方式。但你是否想过,当你写下new MyClass()时,Java虚拟机(JVM)到底在背后做了哪些工作?今天&…...

Baklib云内容中台的核心架构是什么?
云内容中台分层架构解析 现代企业内容管理系统的核心在于构建动态聚合与智能分发的云端中枢。以Baklib为代表的云内容中台采用三层架构设计,其基础层为数据汇聚工具集,通过标准化接口实现多源异构数据的实时采集与清洗,支持从CRM、ERP等业务…...

一个基于vue3的图片瀑布流组件
演示 介绍 基于vue3的瀑布流组件 演示地址: https://wanning-zhou.github.io/vue3-waterfall/ 安装 npm npm install wq-waterfall-vue3yarn yarn add wq-waterfall-vue3pnpm pnpm add wq-waterfall-vue3使用 <template><Waterfall :images"imageList&qu…...

内存中的缓存区
在 Java 的 I/O 流设计中,BufferedInputStream 和 BufferedOutputStream 的“缓冲区”是 内存中的缓存区(具体是 JVM 堆内存的一部分),但它们的作用是优化数据的传输效率,并不是直接操作硬盘和内存之间的缓存。以下是详…...

【pytest框架源码分析一】pluggy源码分析之hook常用方法
简单看一下pytest的源码,其实很多地方是依赖pluggy来实现的。这里我们先看一下pluggy的源码。 pluggy的目录结构如下: 这里主要介绍下_callers.py, _hooks.py, _manager.py,其中_callers.py主要是提供具体调用的功能,_hooks.py提…...

《Kafka 理解: Broker、Topic 和 Partition》
Kafka 核心架构解析:从概念到实践 Kafka 是一个分布式流处理平台,广泛应用于日志收集、实时数据分析和事件驱动架构。本文将从 Kafka 的核心组件、工作原理、实际应用场景等方面进行详细解析,帮助读者深入理解 Kafka 的架构设计及其在大数据领域的重要性。 1. Kafka 的背…...

【AHK】资源管理器自动化办公实例/自动连点设置
此处为一个自动连续点击打开检查的自动化操作案例,没有quicker的鼠键录制,不常用了,做个备份 #MaxThreadsPerHotkey 2 ; 这个是核心!!!!确保可以同时运行多个热键或标签global isRunning : tru…...

在docker容器中运行vllm部署deepseek-r1大模型
# 在本地部署python环境 cd /app/ python -m venv myenv # 激活虚拟环境 source /app/myenv/activate # 要撤销激活一个虚拟环境,请输入: deactivate# 进入虚拟环境安装modelscope pip install modelscope# 下载大模型(7B为例) modelscope do…...
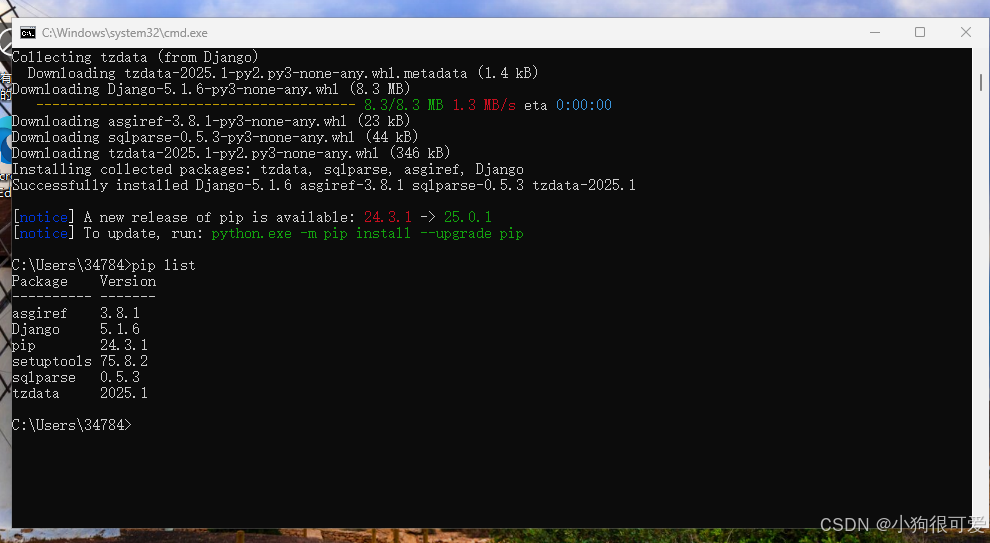
Django基础环境准备
Django基础环境准备 文章目录 Django基础环境准备1.准备的环境 win11系统(运用虚拟环境搭建)1.1详见我的资源win11环境搭建 2.准备python环境2.1 winr 打开命令提示符 输入cmd 进入控制台2.2 输入python --version 查看是否有python环境2.3在pyhton官网下…...

使用DeepSeek实现自动化编程:类的自动生成
目录 简述 1. 通过注释生成C类 1.1 模糊生成 1.2 把控细节,让结果更精准 1.3 让DeepSeek自动生成代码 2. 验证DeepSeek自动生成的代码 2.1 安装SQLite命令行工具 2.2 验证DeepSeek代码 3. 测试代码下载 简述 在现代软件开发中,自动化编程工具如…...

nio使用
NIO : new Input/Output,,在java1.4中引入的一套新的IO操作API,,,旨在替代传统的IO(即BIO:Blocking IO),,,nio提供了更高效的 文件和网络IO的 操作…...

【考试大纲】中级网络工程师考试大纲(最新版与旧版对比)
目录 引言考试科目1:网络工程师基础知识考试科目2:网络工程师应用技术引言 最新的网络工程师考试大纲出版于 2024 年 10 月,本考试大纲基于此版本整理。 考试科目1:网络工程师基础知识 计算机系统知识1.1 计算机硬件知识 1.2 操作系统知识 1.3 系统管理 系统开发和运行…...

Spring的下载与配置
1. 下载spring开发包 下载地址:https://repo.spring.io/webapp/#/artifacts/browse/simple/General/libs-release-local/org/springframework/spring 打开之后可以看到有很多版本供选择,因为视频教程用的是4.2.4版本,于是我也选择这个 右键…...

解决IDEA使用Ctrl + / 注释不规范问题
问题描述: ctrl/ 时,注释缩进和代码规范不一致问题 解决方式 设置->编辑器->代码样式->java->代码生成->注释代码...
学术小助手智能体
学术小助手:开学季的学术领航员 文心智能体平台AgentBuilder | 想象即现实 文心智能体平台AgentBuilder,是百度推出的基于文心大模型的智能体平台,支持广大开发者根据自身行业领域、应用场景,选取不同类型的开发方式,…...

kafka-leader -1问题解决
一. 问题: 在 Kafka 中,leader -1 通常表示分区的领导者副本尚未被选举出来,或者在获取领导者信息时出现了问题。以下是可能导致出现 kafka leader -1 的一些常见原因及相关分析: 1. 副本同步问题: 在 Kafka 集群中&…...

【开源-鸿蒙土拨鼠大理石系统】鸿蒙 HarmonyOS Next App+微信小程序+云平台
✨本人自己开发的开源项目:土拨鼠充电系统 ✨踩坑不易,还希望各位大佬支持一下,在GitHub给我点个 Start ⭐⭐👍👍 ✍GitHub开源项目地址👉:https://github.com/lusson-luo/HarmonyOS-groundhog-…...