【Linux系统编程】基础IO--磁盘文件
目录
前言
磁盘的机械构成
盘片介绍
盘片与磁头
数据的存储(硬件)
磁盘的物理存储
逻辑结构:磁道/柱面、扇面、扇区
磁盘I/O的基本单位与扇区的存储密度
CHS定位法:数据的查找
磁盘的逻辑存储
扇区的抽象结构(数据存储)
CHS定位法(抽象结构下的数据查找)
操作系统数据存储的基本单位
文件系统管理的方式(分区、分组)
文件系统
文件内容与属性
文件属性inode
inode相关数据结构
模拟文件系统检索inode
文件系统之文件的存储
文件系统之GDT
文件系统之Super Block
宏观角度理解文件系统
文件系统之目录文件
文件系统之再谈分区
软硬链接
软链接
硬链接
软硬链接原理
前言
在之前基础IO的内存文件中,我们介绍了关于被打开文件的方方面面,这些被打开的文件都是与进程强相关的,但一个系统中不可能都是被打开的文件,更多的其实是被保存在磁盘中的文件,这些文件都没有被打开,所以这些文件与进程之间没关系,而且这些文件的数量可能比被打开的文件多的多,所以操作系统也需要对这些文件进行管理,操作系统有自己的一套管理体系,而我们今天这篇博文,就详细介绍一下关于这些没有被打开的文件!而我们首先进入的第一个话题就是磁盘
磁盘的机械构成
如下图,是一个常见的磁盘

盘片介绍
由上图,我们看到,中间位置有一个像光盘一样的东西,这个东西也就是我们常说的盘片
盘片的功能:存储数据,也就是我们平时的文件、游戏....都被保存在这个盘片上
盘片的特点:
- 它既可以读,又可以写。也就是说我们可以随时擦除盘片上的数据,再向它写入数据
- 它正反两面都可以用。
注意:盘片在用于桌面级磁盘,也就是我们个人计算机使用时,一般都是一个盘片,但如今桌面级磁盘已经不是那么常用了,磁盘通常用于企业
盘片与磁头
企业级的磁盘一般盘片都是一摞一摞的,也就是说一块磁盘当中可能有多个盘片!
当然,除了盘片以外,我们还能在上图中看到一个像钟表上的时针一样的东西,这个东西我们称之为磁头,一般来说每个盘片都会有磁头,换句话来说一块磁盘当中可能有多个磁头
- 当计算机处于关机状态时,这个磁头会移动到它的起落区,如上图中的即是处于关机状态下磁头的指向!
- 当计算机启动时,这个磁头就会通过左右摇摆的方式快速回到盘片区域内,在之后磁头也是会左右摇摆的。
盘片的中间有一个小圆圈一样的东西,这个东西是一个马达,当磁盘工作时,这个马达会带动盘片进行告诉旋转,所以磁盘工作时盘片和磁头的运动应该如下图
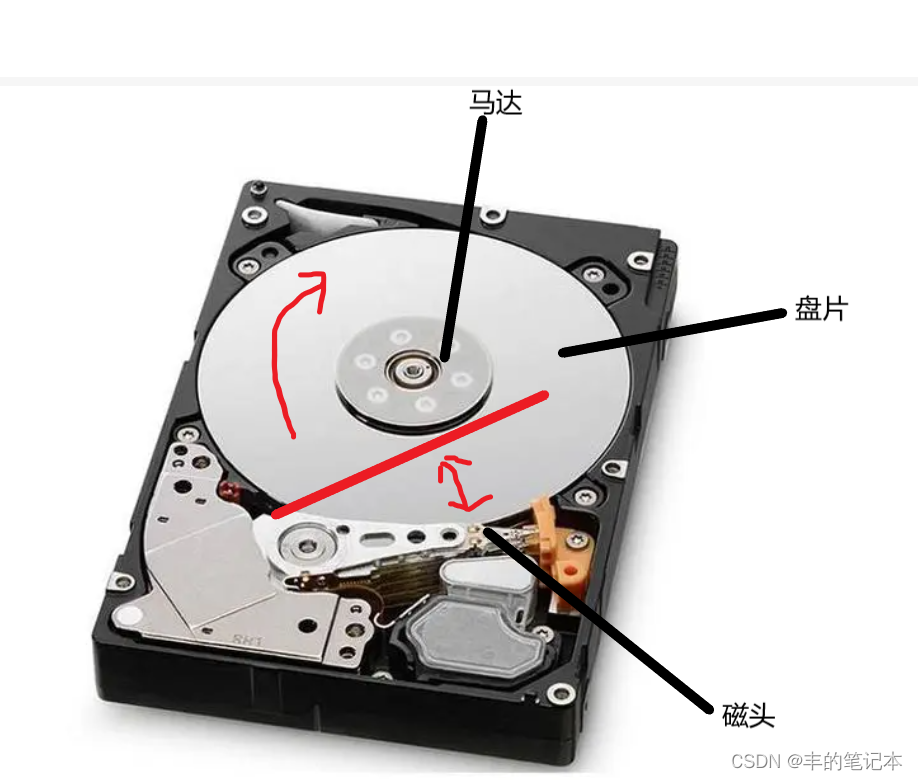
而盘片的旋转和磁头的摆动总的来说都是为了一个目的,就是要能在盘片上寻址
注意:当磁头左右摆动和盘片高速旋转时,磁头和盘片挨得很近,但他们之间并没有接触
实际上磁头和盘片也不能进行接触,因为当磁头和盘片进行接触时,可能会造成盘面的刮花
数据的存储(硬件)
而接下来的问题是关于盘片存储数据的问题
在我们以前的理解中,经常听到的一句话是计算机只认识二进制数据,也就是只认识0,1,但所以磁盘当中存储的都是0、1这样的数据吗?
实际上磁盘当中并不是存储的0、1这样的数据
我们可以把一个磁盘想象成由无数个小磁铁构成的,而磁铁我们规定出了它是有南极北极的,所以我们可以通过判断一块磁铁南北极的方式来判断它是0还是1,就比如我们规定北极是1,南极是0
而一块磁盘我们可以认为有上万亿个小磁铁,每一块小磁铁都有南北极。
数据本质上就是通过多个磁铁的南北极来表示的,而所谓的修改数据,本质上就是改变这些小磁铁的南北极朝向,就比如北极是1,南极是0,而我们现在有32个小磁铁,我把这32个小磁铁都改成南极,那么此时就能表示一个整形数据0
磁盘的物理存储
接下来要解决的问题是关于磁盘怎么存储数据以及如何定位扇区的问题
实际上由于磁盘中可以存数据的结构是盘片,所以我们接下来重点讨论的其实是盘片的存储形式
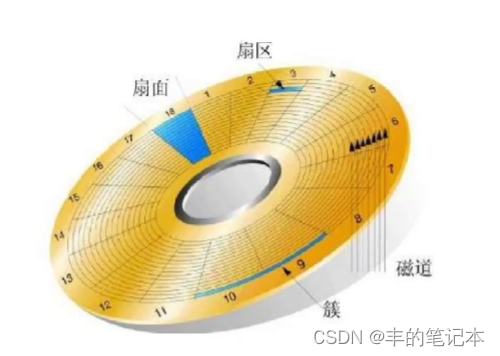
如图,为一个盘片的存储区域划分
逻辑结构:磁道/柱面、扇面、扇区
我们首先可以看到,一个盘片是由半径不相同的很多个圆构成的,而两个圆之间的区域,我们称之为磁道,或者称为柱面
而除了磁道以外,我们还能看到有许多贯穿所有磁道的竖划线,而两个竖划线之间的区域我们称之为扇面
而一个磁道所划分出来的区域与一个扇面所划分出来的区域的交集我们称之为扇区
磁盘I/O的基本单位与扇区的存储密度
扇区是磁盘IO的基本单位,但可能不是系统与磁盘IO的基本单位,一个扇区的大小一般是512KB
所谓的磁盘IO的基本单位的意思是假设你今天对数据只修改了一个比特位,但当你要写入到磁盘时,需要把一个扇区大小的数据全部写到磁盘当中
我们在图上可以看到,越靠近外侧的磁道所形成的扇区大小好像比内侧的扇区面积要大,难道他们都是存储512KB吗?
实际上确实是这样的,每一个扇区的大小都是固定的,这是通过控制数据密度的方式实现的,越靠近内侧的扇区由于所占的面积越小,所以它的密度就越大
CHS定位法:数据的查找
上述我们讲的都是同一个盘面,但实际上的企业级磁盘当中,是有很多个盘面的,与之对应的也就有很多个磁头,而这些盘面和磁头都有着自己的唯一的编号
除了盘面和磁头以外,同一个盘面上的磁道有很多个,而这些磁道也有着自己的编号,而同一个盘面的同一个磁道有很多个扇区,而这些扇区也有着自己的编号
所以,如果我想访问磁盘中的一个扇区,也就是定位一个扇区。只需要知道它在哪个盘面,再知道它在哪个磁道,再知道它在哪个扇区
而所谓的知道它在哪个盘面,其实就是选择该使用哪个磁头,因为每个盘面都有磁头
所谓的知道在哪个磁道,其实是通过磁头来定位的,磁头通过左右摇摆的方式就可以定位出磁道,这也是磁头要进行左右摇摆的原因
最后,通过盘片旋转的方式,即可定位出数据在哪个扇区中
而在物理层面上定位一个扇区的方法,我们称之为CHS定位法
只要能定位出一个扇区,就能定位出多个扇区,那么任何文件,本质上就是多个扇区承载的数据,所以我只需要定位出多个扇区,再把这些扇区的数据组合起来,此时一个文件就能被存储也能被找到
磁盘的逻辑存储
上述,我们聊了关于磁盘的物理存储,我们已经能在物理层面定位一个扇区了,但如果操作系统需要定位一个扇区,那么肯定不能按照物理的方式来,肯定要设计一种方式来适应代码的编写,而逻辑存储也就是解决这方面的问题
扇区的抽象结构(数据存储)
在我小学的时候,英语老师放听力,经常会拿出一个收音机,然后把一卷磁带放进去,收音机就开始放了,如下图

实际上,这个磁带上面也是可以存储数据的,而如果我们把一个磁带卷起来,会发现磁带其实和磁盘的盘片是有点像的,它们上面都能存储数据,如果我们把磁带拉直,它会变成线性结构。
那么我们如果把盘片上的磁道连起来,不就也可以实现一种线性结构了吗?而磁道上面是一个一个的扇区,所以我们如果把盘片上所有的磁道连起来变成了一个线性结构后,这一个线性结构上是一个一个的扇区
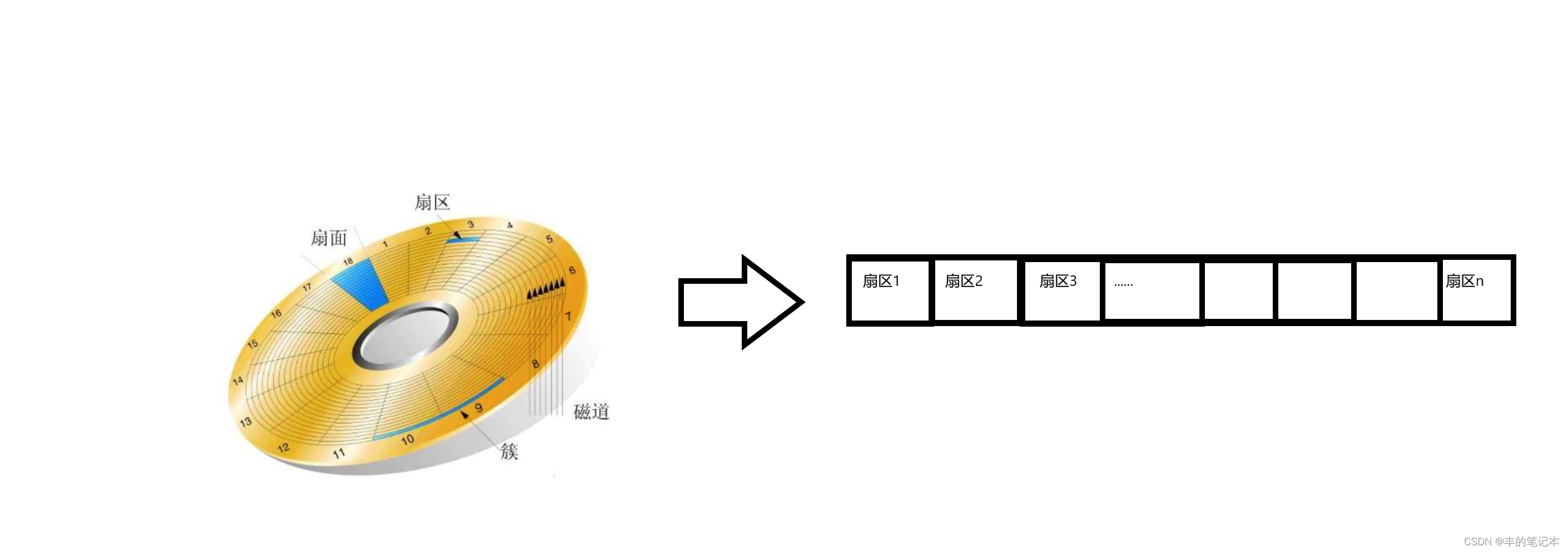
线性结构在计算机当中,可以用数组表示,而这个数组的元素也就是一个一个的扇区
而此时,对磁盘的管理就变成了对数组的增删查改,就把一个物理结构抽象成了计算机的逻辑结构
而在实际当中,可能一个磁盘不只一个盘片,不过无伤大雅,其他盘片抽象成逻辑结构后直接往这个数组后面加上即可
CHS定位法(抽象结构下的数据查找)
还记得我们上面说的CHS定位法吗?在物理结构中我们可以找到一个具体的扇区,那么抽象成逻辑结构以后物理上如何访问一个扇区呢?
假设一个磁道的大小是400M,一张盘片的大小是200G,盘片总大小800G,扇区大小512字节
假设我此时要访问这个数组中编号为123456789的扇区
CHS定位法要知道参数分别是:
1、这个扇区位于哪个盘片,也就是使用哪个磁头
- 计算在哪个盘片:编号/盘片扇区个数 = 盘片编号
123456789/419430400 = 0
这个扇区位于0号盘片
2、这个扇区位于0号盘片的哪个磁道
- 编号%盘片扇区个数 = temp
- temp/磁道扇区个数 = 结果
123456789 % 419430400 = 123456789
123456789 / 819200 = 150
3、我是特定磁道当中的哪个扇区
- temp%一个磁道上的扇区的个数 = 结果
123456789%819200 = 576789
最终得出结果:线性结构当中编号为123456789的扇区转化为物理结构就是第0号盘片的第150号磁道的第576789个扇区
这个线性结构当中的编号我们称为线性地址,此时我们可以把线性地址转化为CHS,而这个工作实际上是由磁盘自己完成的
操作系统数据存储的基本单位
上述我们说的逻辑结构是以扇区为单位的,这是因为磁盘IO的基本单位是扇区,但实际上操作系统认为磁盘IO的效率太慢了,一次只能IO一个扇区,也就是512字节,所以OS的文件系统认为IO的基本单位是4KB(一般情况)
也就是把连续的8个扇区(4KB)定义为一个数据块,而数组的元素是以数据块为单位的,如下图
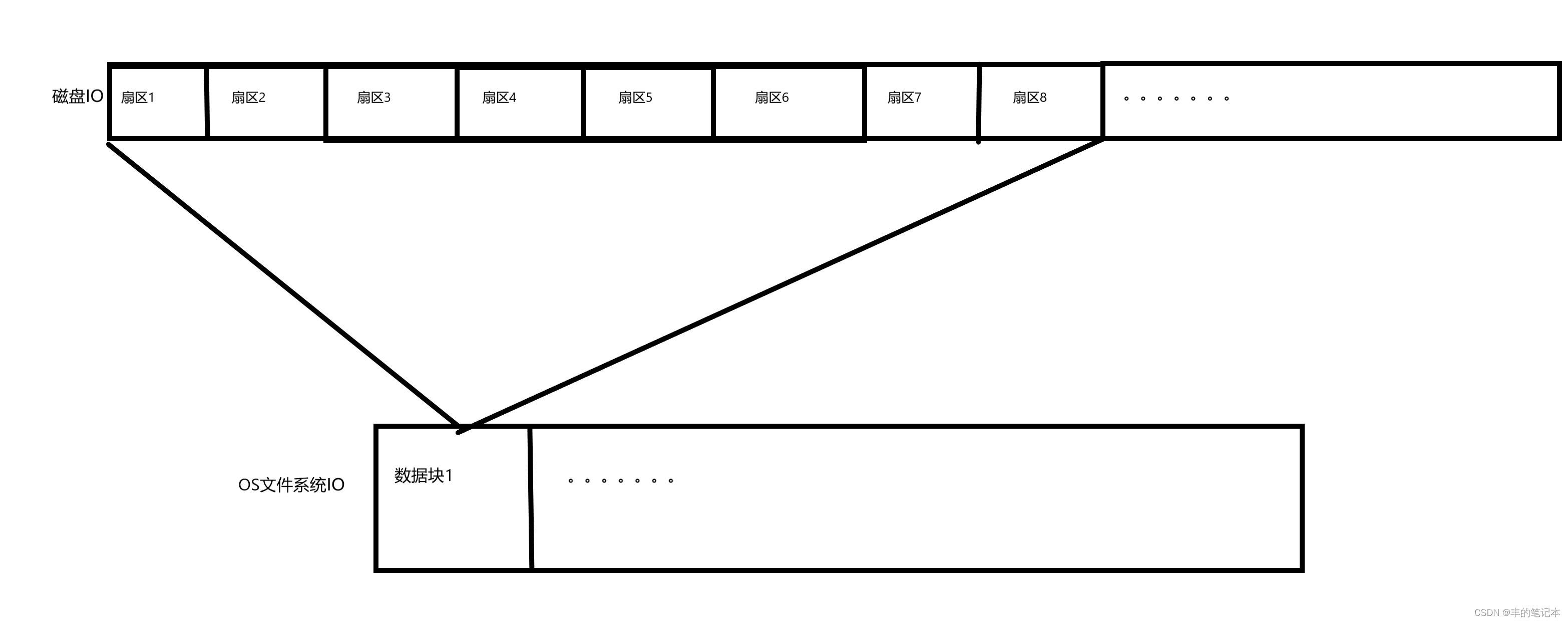
而这个元素是数据块的数组我们一般称之为LBA(logical Block Address)
而通过数据块我们也能访问到指定的扇区
指定扇区 = 数据块编号 * 8 +(0,1,2,3,4,5,6,7,8)
注意:数据块编号从0开始
文件系统管理的方式(分区、分组)
所以此时文件系统就有了一个元素大小为4KB的数组,我们假设磁盘的大小是800GB
但有了800GB的数组以后,操作系统对这个数组的管理也是比较难得,因为数据量大
所以操作系统就把这个数组分为了多个区域,我假设分为了4个200GB的区域,这一个过程我们称之为分区,如下
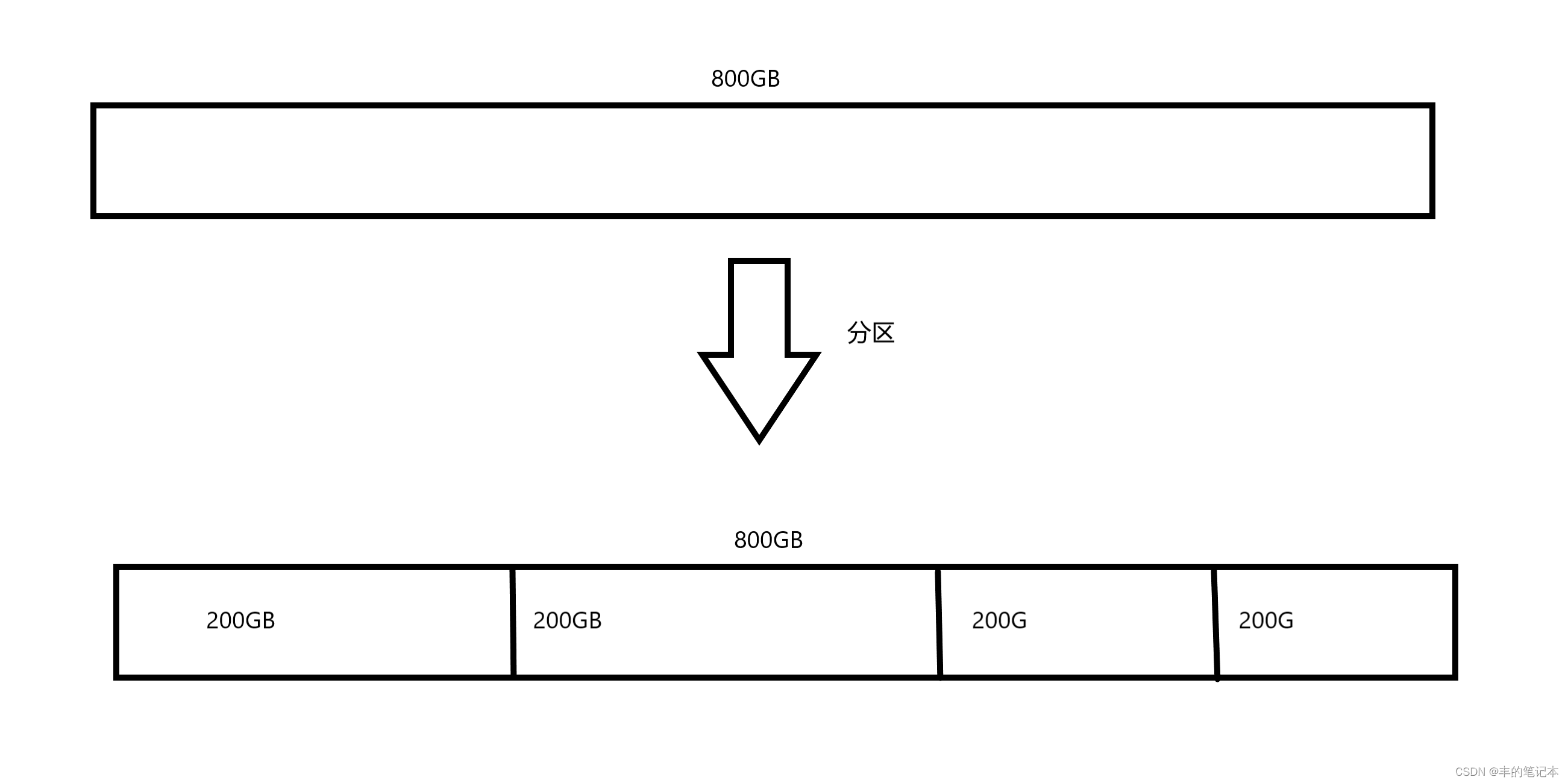
而此时操作系统只要管理好了一个200GB的区域,然后把管理这个区域的方式复制粘贴到另一个区域,那么另一个区域也能管理好,换句话来说就是从管理800GB到管理200GB
但对于操作系统来说,管理这200GB的区域也还是太大了,所以把这个200GB的区域继续划分,划分为若干个10GB的区域,这一过程我们称之为分组,如下图
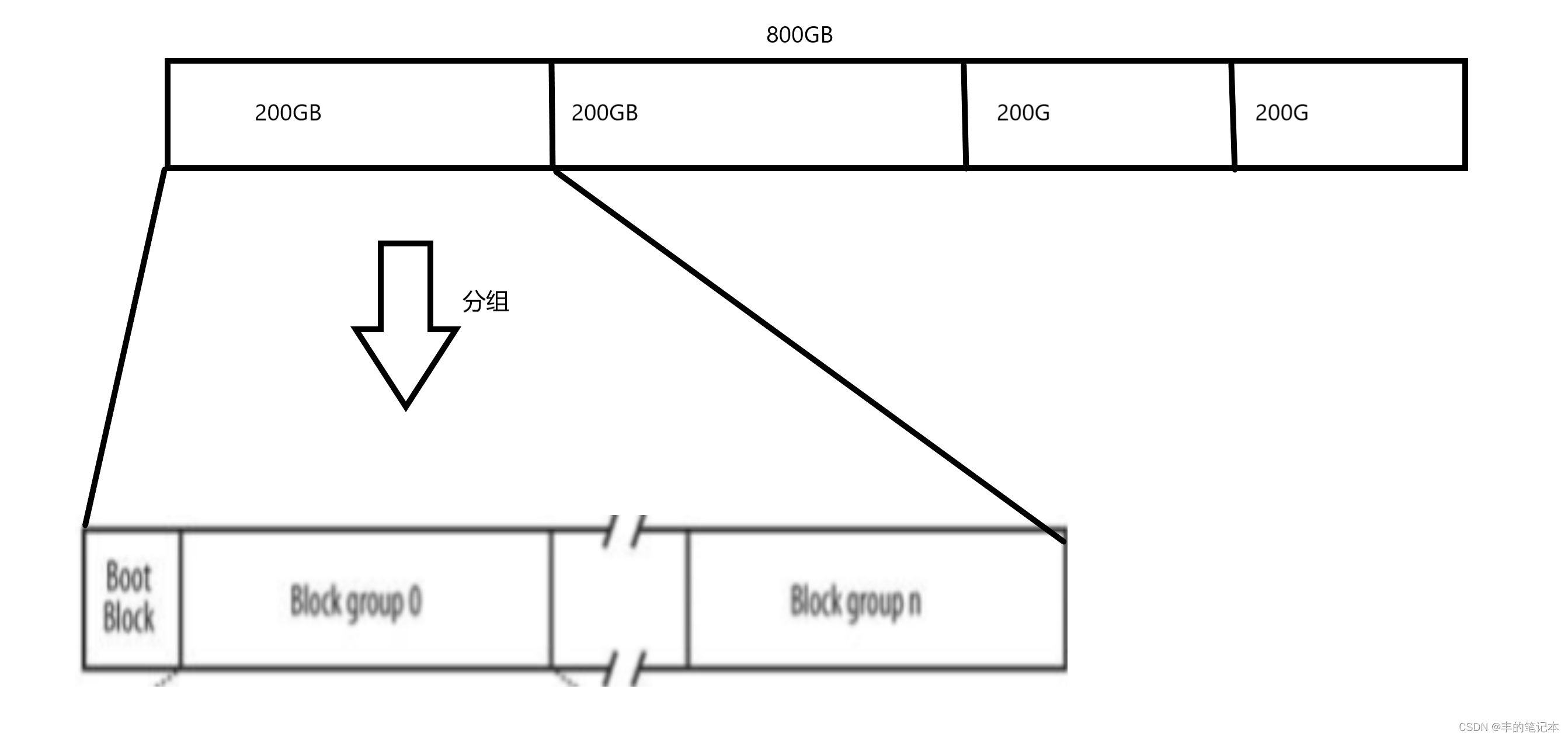
而在上图中每一个Block group就是一个10GB的区域
而同样的,只要管理好了一个Block group,再把管理这个Block group的方式复制粘贴到其他的Block group,那么所有的Block group都能管理好,于是接下来的问题就是研究如何管理一个Block group。
文件系统
文件内容与属性
接下来我以Block group 0为例,它里面的内容大概如下
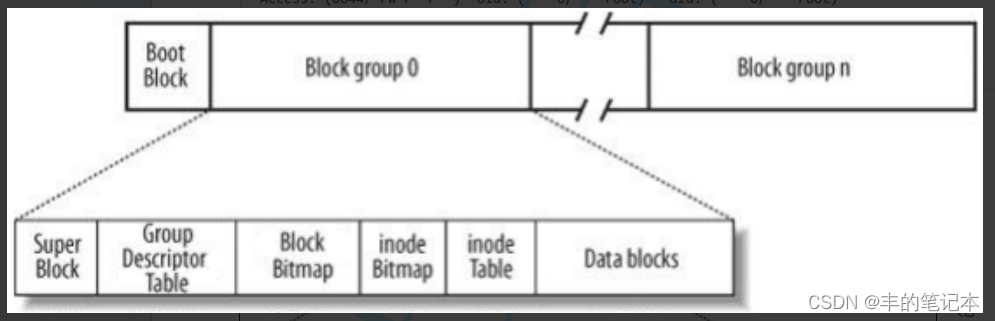
之前我们说过,文件 = 内容 + 属性
接下来要补充一些概念
1、内容的大小是不固定的,而属性的大小是固定的
对于内容的大小是不固定的,这很好理解
对于属性的大小是固定的,就好比一个人的属性是确定的,身高年龄等,虽然每个人的身高和年龄的值可能不相同,但每个人肯定都有这个身高和年龄。而一个文件的属性,以权限为例,虽然可能两个文件的权限的内容不相同,但每个文件都有权限这个属性,它们所用的类型都是一样的,大小也就是一样的,也就是说可以用一个结构体来描述文件的属性。当然,两个文件的文件名大小可能是不同的,但文件名不是文件属性。
文件属性inode
在Linux中,磁盘文件的属性都是存储在一个结构体当中的,这个结构体我们称之为inode,这个结构体当中除了各种文件的属性以外,还有在分区当中唯一标识自己的inode编号
struct inode
{类别;大小;权限;时间;//.....inode编号;
}而在bash中,我们可以使用ls 带i选项查看每个文件的inode编号
yyf@VM-24-5-centos test]$ touch test1 test2 test3 test4
[yyf@VM-24-5-centos test]$ ll -i
total 0
794971 -rw-rw-r-- 1 yyf yyf 0 Jul 2 17:23 test1
794972 -rw-rw-r-- 1 yyf yyf 0 Jul 2 17:23 test2
794973 -rw-rw-r-- 1 yyf yyf 0 Jul 2 17:23 test3
794974 -rw-rw-r-- 1 yyf yyf 0 Jul 2 17:23 test4#第一排就是inode编号inode相关数据结构
inodeTable
一个分组当中的所有文件的inode都是被连续存储的,而连续存储inode的区域我们称之为inode Table
除此之外,一个inode的大小在Linux当中是固定的128字节
inodeBitmap
我们此时虽然有了一个表来存储inode,但是我们并不知道一个inode编号是否被使用过,所以在分组中还有一个inode位图用来表示对应编号的inode是否被使用过
inode位图中比特位的位置表示的是第几个node,比特位的内容表示该inode是否被使用(1表示已被使用,0表示没被使用)
DataBlock
当然,对于一个分组来说,仅仅有文件的属性是不行的,还得要有文件的内容,而文件的内容实际上是存储在Data Block中的,Data Block当中存放了很多数据块,用来存储文件的内容
Data Block当中的数据块实际上是有编号的。
文件内容索引数组
有了存储文件内容的地方还不够,文件必须还能找到它所对应的内容,所以文件的inode当中除了保存文件属性及其inode编号以外,还保存了一个数组,这个数组的内容就是文件在Data Block当中所使用的数据块编号,如下
struct inode
{类别;大小;权限;时间;//.....inode编号;int blcok[15];//存储的是Data block中数据块的编号
}BlockBitmap
现在,我们虽然可以使用Data Block当中的数据块来存储文件内容,并且也能通过inode来找到当前文件所使用的数据块,但我们无法知道有哪些数据块已经被使用,那么当系统分配数据块时就会出问题,所以分组当中还有一个字段是Block位图
这个位图与inode位图差不多
Block位图中比特位的位置表示的是数据块的编号,比特位的内容表示的是对应的数据块是否被使用(1表示已被使用,0表示没被使用)
模拟文件系统检索inode
在文件系统中查找一个inode
假设一个分区当中有十万个inode,我要找的inode的编号是66666,那么我下一步应该做的是找到这个66666所在的分组,因为分区不对具体文件属性和内容进行管理,分组才对文件的inode和数据块进行管理。假设我把这个分区分成了10个等份的组,那么每个组当中的inode应该是10000个,而此时我只需要知道第一组的inode的起始位置就可以找到对应的组,因为文件系统当中每个组保存的inode都是有编号范围的,就比如第一个组保存的inode的inode编号是[1,10000],那么第二组保存的就是[10001,20000],以此类推,如下图
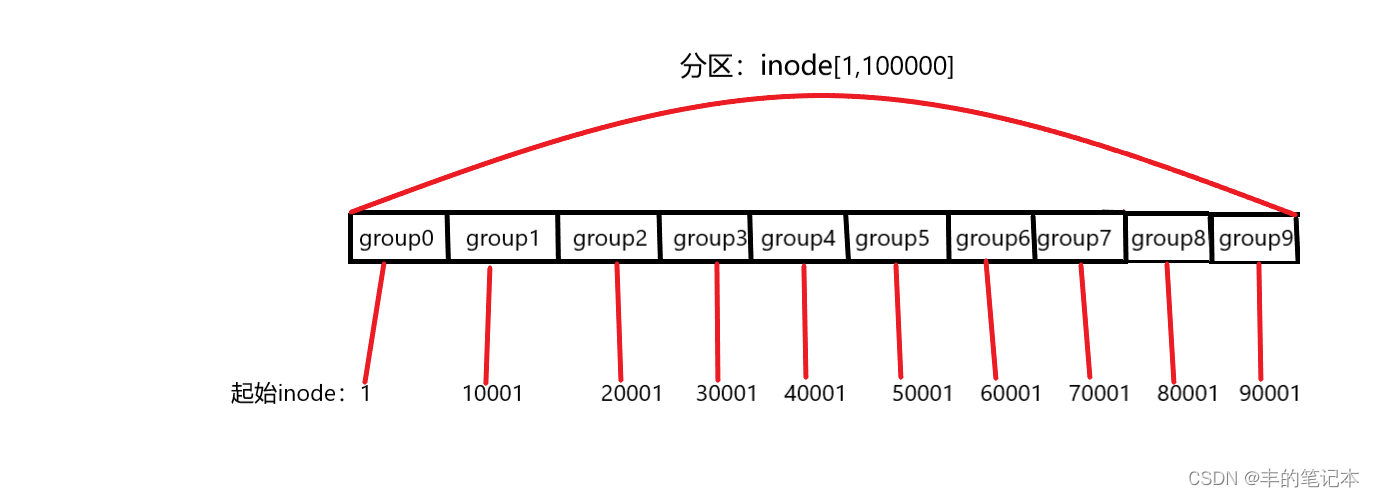
也就是说只要知道第一组的起始inode以及每一个组所保存的inode个数,就能知道每个组的inode编号范围
当我们拿着inode为66666去找对应的组时,由于70001>66666>60001,所以66666在group6
找到这个组以后,每个组的管理字段结构都是一样的,换句话来说,group6当中的位图只有10000个比特位,如何表示这个inode为66666的位置呢?
实际上只需要减去这个group的起始inode即可,例如上述的group6的起始inode是60001,所以66666-60001 = 6665,所以先在inode位图当中的查看第6665个位置的比特位是否为1(block位图同理),如果为1就去inode表当中找到第6665个inode即可
在文件系统中创建一个inode
如果是创建一个文件,那么就是给它分配一个inode编号,然后通过分组的inode范围确定在哪个分组当中创建,然后把这个inode编号-分组的起始inode编号,而减完以后这个值一定是小于10000的,假设为n(n<10000),也就能在inode位图当中找到第n个位置的比特位,之后把这个比特位的值由0改为1即可,然后找到inode表当中的第n个inode结构体填充完inode字段即可。而对于inode当中的inode编号实际上就是当前n+当前分组的起始inode
在文件系统中删除一个inode
如果是删除一个文件的话,那么还是拿着分区当中唯一的inode,确定出inode所在的分组,再把这个inode-分组起始inode,得到n,然后在inode位图当中找到第n个位置的比特位,把这个比特位的值由1设置为0即可。
注意:删除一个inode不需要删除inode表当中的对应字段,因为位图当中的比特位为0还是为1表示这个inode是否被文件使用
文件系统之文件的存储
前面我们说过,文件的存储是由inode结构体当中的block数组控制的,这个数组当中存的是当前文件所占用的数据块的编号
struct inode
{....int blcok[15];....
}block数组的索引结构
但从表面上看这个block好像只能存储15个整形,也就是只能存储60B的数据,这显然有些太小了
实际上这个block数组确实是存储的数据块编号,但它数据块里面的内容其实是有自己的一套规律的
一般来说对于下标为[0,11]的元素,它指向的数据块存储的是文件的相关内容
而下标为[12,13]的元素,它指向的数据块存储的是其他数据块的编号,而其他数据块当中存储的才是文件的相关内容,而一个数据块当中能存储的编号为1024个,也就是说此时有8M左右的大小可以给这个文件使用了,但显然,这可能还不是很大,所以下标为14对应的数据块当中存储是其他数据块的编号,而其他数据块当中存储的也是其他数据块的编号,如果我们称数据块当中存储其他数据块编号这个过程为1次索引,那么下标14的block元素就是进行了两次索引,两次索引之后才会保存文件的相关内容
如下图:

而经过两次索引以后,这个文件可以使用的大小大概为4G,此时对于一个文件来说已经差不多了,如果需要更大的话可以进行三次索引,以此类推
文件系统之GDT
之前一直说每个组都有起始的inode,那么这个起始的inode是从哪来的呢?
实际上就是从每个组当中的GDT中来的,GDT是对当前组进行管理的字段,它里面不仅仅包含了当前组的起始inode,还包含了其他各种各样的对组进行管理的字段,换句话来说GDT其实是对之前介绍的4个组内结构进行管理的,如下图

而既然是对组内进行管理的,所以每一个分组当中都有GDT
我们现在已经有了可以对组内进行管理的字段,但对于分区来说还有很多信息需要管理,就比如当前分区的block和inode的个数,最后一次写入数据的时间等等,这些分区的管理信息也需要有结构来管理,所以就有了Super Block
文件系统之Super Block
Super Block存放的是文件系统本身的结构信息,也就是说它是用来管理文件系统本身的,如果一个分区当中的Super Block被破坏掉了,那么这个文件系统的结构就被破坏了,也就是说整个分区都出问题了!
基于上述的原因,所以在一个文件系统中就有多个Super Block,这些Super Block的数据是同步的。当然,也不是每一个组当中都有Super Block,文件系统会自己来对一些特殊的分组进行写入Super Block,当一个Super Block被破坏掉时,还有另外的Super Block可以直接覆盖掉原先被破坏的Super Block,所以文件系统设置多个Super Block的原因是因为要实现Super Block的备份,方便修复。
既然如此,那么为什么不能每个分组都写入Super Block呢?
这是因为效率的问题,当你一个Super Block修改时,其他的Super Block要同步进行修改,这样当分组多时,效率就变得非常低了!
上述,我们介绍了关于Linux的文件系统的大概思路,而这种文件系统我们称之为Ext*(2)
除了Ext*(2)以外,还有其他的文件系统,并且所有的分区都可以写入不同或者相同的文件系统
宏观角度理解文件系统
所谓的分区,在Windows当中的表现就是D盘和C盘这种一个一个的盘,而对C盘和D盘进行格式化,首先做的也就是写入一个全新的文件系统
而我们的计算机当中可能会有非常多的分区,也就有非常多的文件系统,那么操作系统是否要管理这些文件系统呢?
显然是要的,如何管理呢?
先描述,后组织
所以操作系统当中也有描述文件系统的结构体,然后把这些结构体用链表连起来,此时对文件系统的管理就变成了对链表的增删查改
我们从上述中可以得出了一个结论,只要拿到一个文件的inode编号,就能找到这个文件的属性和内容,但我们在Linux命令行操作的时候可从来都没有使用inode编号,我们使用的是文件名,那么我们是如何通过文件名找到文件的属性和内容的呢?
实际上,根据我们的常识可以知道,每一个普通文件都是被放到目录当中的
由此,要解答上述的问题,我们首先得了解一下Linux当中的目录文件
文件系统之目录文件
第一个问题,目录文件是文件吗?
这毋庸置疑,肯定是的,而只要是一个文件,那么它就会被分配inode用于保存文件的属性,也会被分配数据块用于保存文件的内容,那么目录文件当中的数据块保存的是什么内容呢?
实际上目录文件的数据块中保存的是文件名与inode编号之间的映射关系
也就是说只要我们可以通过文件名找到它的inode编号,这也解答了为什么我们在Linux当中使用的都是文件名,而系统却能找到inode
所以在《Linux基础概念》中,我曾说过如果一个目录如果没有读权限,那么我们无法查看目录中的文件的属性或名字,因为目录的内容就是文件的属性或名字
我还说过,如果一个目录文件没有写权限,那么就无法创建或删除一个文件,这是因为当目录文件没有写权限时,就无法在目录文件的数据块当中添加文件名与inode编号之间的映射关系,所以就无法创建一个文件,而删除一个文件实际上就是在目录文件的数据块当中删去一个文件名与inode之间的映射关系,没有写权限意味着无法去掉这个映射关系
所以,从上述我们可以知道,对于如何通过文件名拿到一个普通文件的inode,我们只需要到它所处的目录下,就能拿到这个普通文件的inode。
但接下来的问题是如何找到普通文件所处目录的inode呢?
实际上,一个非根目录的目录文件,它一定也是在某一个目录下的,而它所处的目录文件中的数据块也保存了它的inode与文件名的映射关系
举一个例子,假设某一个文件的路径如下:
/a/b/c/d/e
我们假设e这个文件是一个普通文件
首先是e这个文件名和inode的映射关系保存在了d目录中,所以e文件可以找到,问题变为了如何找到d文件
d目录文件的文件名与inode的映射关系保存到了c文件中,所以d可以被找到,文件变为了如何找到c这个目录文件
以此类推,最终会到了根目录
而在Linux当中,根目录的inode是确定的,一般都为2,至此这条路径上的所有目录的inode都能确定
而实际上,上述的这些目录文件本质上也是文件,当我们要访问它的内容的时候也要把它进行打开,所以Linux当中可能会存在很多被打开的目录文件,而Linux要对这些目录文件进行管理,管理的方式就是先描述后组织,实际上对路径上目录文件的管理也是对路径的缓存。第一次我访问的路径是/a/b/c/d/e,而第二次我访问的路径是/a/b/f,那么第二次a和b的目录信息已经被加载到了内核数据结构中,也就是它俩已经被缓存了,只需对f目录文件描述组织即可
文件系统之再谈分区
当然,除了通过文件名拿到inode之外,关于文件系统其实还有一个问题,我们以上的所有理论都是基于我们已经确定了文件在哪个分区当中,而确定了分区以后我们对文件的内容和属性的管理、判断文件所处分组用的都是inode,但一个操作系统当中可能有很多个分区,这些分区之间用的不是同一套文件系统,而这也就导致了inode只适用于一个分区。所以接下来的问题是我该怎么确定文件所处的分区呢?这也是我们上面提到的所有理论的前提
首先,分区是将磁盘分割成多个逻辑部分的过程,而不管在Linux中分区到底是什么,它也不可能是目录文件。
而我们在使用Linux的时候都是通过目录索引的方式来访问文件的,所以一个分区单单写入文件系统也无法被Linux直接使用,还要先让这个具有文件系统的分区转化为Linux我们常用的目录以后才能使用!
而这个转化的过程我们称之为挂载
其实所谓的挂载就是让目录和分区具有联系,然后当用户访问目录时,目录可以通过某个字段找到并使用挂载到这个目录的分区管理信息,而在上层用户看来这个目录就等于挂载的分区,底层这个目录和挂载到它上的分区之间的关系是映射关系
在Linux中,我们可以使用df指令查看当前系统所挂载的分区,如下
[yyf@VM-24-5-centos ~]$ df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 1012260 0 1012260 0% /dev
tmpfs 1023248 24 1023224 1% /dev/shm
tmpfs 1023248 608 1022640 1% /run
tmpfs 1023248 0 1023248 0% /sys/fs/cgroup
/dev/vda1 41152716 7588360 31786532 20% /
tmpfs 204652 0 204652 0% /run/user/1001其中Filesystem为文件系统所对应分区,Mounted on为这个分区所挂载的目录
所以,以后我们的文件只要是处于Mounted on的目录下时,系统通过你文件的路径然后根据你路径的前缀就会知道你是在哪个分区,就比如上述假设你在/目录下,系统就会自动匹配你是在/dev/vda1这个分区
软硬链接
接下来是基于文件系统的内容,我们来讨论Linux当中的软硬链接
软链接
我们先看在Linux当中如何建立软硬链接,及其软硬链接的操作现象
在Linux当中,我们使用如下指令为一个文件建立软链接
ln -s [目标文件名] [链接名]如下示例:
[yyf@VM-24-5-centos 24.07.05]$ ln -s test.txt test.soft
[yyf@VM-24-5-centos 24.07.05]$ ll -i
total 0
1183797 lrwxrwxrwx 1 yyf yyf 8 Jul 5 10:26 test.soft -> test.txt
1183796 -rw-rw-r-- 1 yyf yyf 0 Jul 5 10:25 test.txt首先,我们发现建立的软链接与目标文件之间的inode是不相同的
这说明软链接本质上是一个独立的文件,因为它有自己独立的inode
硬链接
接下来我们再看看硬链接
在Linux当中,我们使用如下指令为一个文件建立硬链接
ln [目标文件名] [硬链接名]如下示例:
[yyf@VM-24-5-centos 24.07.05]$ ll -i
total 0
1183796 -rw-rw-r-- 2 yyf yyf 0 Jul 5 10:25 test.hard
1183797 lrwxrwxrwx 1 yyf yyf 8 Jul 5 10:26 test.soft -> test.txt
1183796 -rw-rw-r-- 2 yyf yyf 0 Jul 5 10:25 test.txt继续观察现象,我们会发现创建的硬链接与目标文件名是相同的
这说明硬链接本质上不是一个独立的文件,因为它与目标文件共享的同一个inode
其次,我们会发现权限右边的这一排数字由1变为了2,这排数字其实表示的是当前inode对应的硬链接数
除了上述之外,当我向目标文件写入数据时,查看软硬链接的内容也会发生变化,如下
[yyf@VM-24-5-centos 24.07.05]$ echo Hello,World > test.txt
[yyf@VM-24-5-centos 24.07.05]$ cat test.soft
Hello,World
[yyf@VM-24-5-centos 24.07.05]$ cat test.hard
Hello,World软硬链接原理
那么接下来,我们谈一谈软硬链接的原理
软链接本质上是一个独立的文件,那么除了它有独立的inode以外,还会有独立的数据块!
那么软链接的数据块当中放的是什么内容呢?
实际上,软链接里面放的就是目标文件所处的路径
软链接类似我们在Windows当中的快捷方式
而当我们使用Bash自带的指令时,对软链接的操作都会转化为对软链接数据块当中的文件的操作
当然,不仅仅如此,当我们写了一个程序,然后把这个程序建立软链接,当用户运行这个软链接的时候就会自动在内容中通过指定路径找到指定程序并运行这个程序
硬链接本质上不是一个独立的文件,那么它是什么呢?
之前我们说过,目录当中存储的是文件名与inode的映射关系,实际上所谓的硬链接就是让指定目录重新生成一份文件名与inode的映射关系,就比如上述的test.txt和test.hard
当用户要访问一个文件的内容和属性的时候,不仅仅可以通过test.txt找到,也能通过test.hard找到
至此,Linux中常见的关于磁盘文件的内容就介绍到这了,内容太多,码字不易,希望多多三连
相关文章:
【Linux系统编程】基础IO--磁盘文件
目录 前言 磁盘的机械构成 盘片介绍 盘片与磁头 数据的存储(硬件) 磁盘的物理存储 逻辑结构:磁道/柱面、扇面、扇区 磁盘I/O的基本单位与扇区的存储密度 CHS定位法:数据的查找 磁盘的逻辑存储 扇区的抽象结构(数据…...

Python利用pyobdc和tkinter框架连接数据库2-保存配置文件
为了实现保存用户输入的数据库连接信息,并在下次打开程序时自动加载这些信息,可以使用配置文件(如 .txt 或 .json 文件)来存储这些信息。以下是一个完整的实现方案,结合了动态输入和自动加载配置文件的功能。 实现步骤…...

C# .NET Core HttpClient 和 HttpWebRequest 使用
HttpWebRequest 这是.NET创建者最初开发用于使用HTTP请求的标准类。HttpWebRequest是老版本.net下常用的,较为底层且复杂,访问速度及并发也不甚理想,但是使用HttpWebRequest可以让开发者控制请求/响应流程的各个方面,如 timeouts,…...

[3/11]C#性能优化-实现 IDisposable 接口-每个细节都有示例代码
[3]C#性能优化-实现 IDisposable 接口-每个细节都有示例代码 前言 在C#开发中,性能优化是提升系统响应速度和资源利用率的关键环节。 当然,同样是所有程序的关键环节。 通过遵循下述建议,可以有效地减少不必要的对象创建,从而减…...

Python的pdf2image库将PDF文件转换为PNG图片
您可以使用Python的pdf2image库将PDF文件转换为PNG图片。以下是一个完整的示例,包含安装步骤、代码示例和注意事项。 安装依赖库 首先,您需要安装pdf2image库: pip install pdf2imagepdf2image依赖于poppler库来解析PDF文件。 Windows系统…...

java2025热点面试题之springmvc
1. 请解释Spring MVC的工作原理。 答案: Spring MVC是一个基于Java的MVC框架,用于构建Web应用程序。其工作原理如下: 客户端发送请求到DispatcherServlet,它是Spring MVC的前端控制器。DispatcherServlet查询HandlerMapping&…...

第十三届蓝桥杯大赛软件赛决赛C/C++ 大学 B 组
A 【2022——暴力DP / 优雅背包】-CSDN博客 B 【钟表——类日期问题】-CSDN博客 C 【卡牌——二分】-CSDN博客 D 【最大数字——DFS】-CSDN博客 E 【出差——Dijkstra】-CSDN博客 F 【费用报销——01背包】-CSDN博客 G 【故障——条件概率】-CSDN博客 H 【机房—…...

C#上位机--关键字
引言 在 C# 上位机开发领域,关键字是构建程序的基石。它们是编程语言赋予的特殊词汇,每个关键字都有其独特的用途和功能。了解并熟练运用这些关键字,能够让开发者更加高效地编写代码,实现各种复杂的功能。本文将深入探讨 C# 中一…...

1.C语言初识
C语言初识 C语言初识基础知识hello world数据类型变量、常量变量命名变量分类变量的使用变量的作用域 常量字符字符串转义字符 选择语句循环语句 函数;数组函数数组数组下标 操作符操作符算术操作符移位操作符、位操作符赋值操作符单目操作符关系操作符逻辑操作符条…...

软件测试中的BUG
文章目录 软件测试的生命周期BugBug 的概念描述 Bug 的要素案例Bug 级别Bug 的生命周期与开发产生争执怎么办?【高频面试题】先检查自身,Bug 是否描述的不清楚站在用户角度考虑并抛出问题Bug 的定级要有理有据提⾼自身技术和业务水平,做到不仅…...

TinyEngine v2.2版本发布:支持页面嵌套路由,提升多层级路由管理能力开发分支调整
2025年春节假期已过,大家都带着慢慢的活力回到了工作岗位。为了让大家在新的一年继续感受到 Tiny Engine 的成长与变化,我们很高兴地宣布:TinyEngine v2.2版本正式发布!本次更新带来了重要的功能增强------页面支持嵌套路由&#…...

Web自动化之Selenium添加网站Cookies实现免登录
在使用Selenium进行Web自动化时,添加网站Cookies是实现免登录的一种高效方法。通过模拟浏览器行为,我们可以将已登录状态的Cookies存储起来,并在下次自动化测试或爬虫任务中直接加载这些Cookies,从而跳过登录步骤。 Cookies简介 …...

Storm实时流式计算系统(全解)——中
storm编程的基本概念-topo-spout-bolt 例如下: storm 编程接口-spout的结构及组件实现 storm编程案例-spout组件-实现 这是我的第一个组件(spout组件继承BaseRichSput)所有重写内部的三个方法,用于接收数据(这里数据是…...

【算法工程】大模型局限性新发现之解决能连github但无法clone项目的问题
最近,linux服务器遇到一个奇怪的问题,能ping通github,但是无法clone git项目,尝试了各种大模型,都提到代理啥的问题,发现没有一个能解决问题。 后来尝试设置 http.sslVerify 为 false,才解决问题…...

让deepseek更专业的提示词教程
一、明确需求和目标 在使用DeepSeek之前,首先要明确你的需求和目标。例如,你是要生成一篇学术论文的摘要,还是一个商业文案的大纲,亦或是一段技术分析。明确的目标可以帮助你更有针对性地编写提示词。 二、使用专业术语和结构化…...

《Python实战进阶》No 9:使用 Celery 实现异步任务队列
第9集:使用 Celery 实现异步任务队列 引言 在现代 Web 应用中,许多操作(如发送邮件、处理文件上传、执行复杂计算等)可能需要耗费较长时间。如果这些操作直接在主线程中执行,会导致用户请求阻塞,降低用户体…...

【Mark】记录用宝塔+Nginx+worldpress+域名遇到的跨域,301,127.0.0.1,CSS加载失败问题
背景 想要用宝塔搭建worldpress,然后用域名直接转https,隐藏掉ipport。 结果被折磨了1天,一直在死活在301,127.0.0.1打转 还有css加载不了的情况 因为worldpress很多是301重定向的,所以改到最后我都不知道改了什么&am…...
Linux | Ubuntu 与 Windows 双系统安装 / 高频故障 / UEFI 安全引导禁用
注:本文为 “buntu 与 Windows 双系统及高频故障解决” 相关文章合辑。 英文引文,机翻未校。 How to install Ubuntu 20.04 and dual boot alongside Windows 10 如何将 Ubuntu 20.04 和双启动与 Windows 10 一起安装 Dave’s RoboShack Published in…...

计算机毕业设计SpringBoot+Vue.js手机商城 (源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

CSS—隐藏元素:1分钟掌握与使用隐藏元素的方法
个人博客:haichenyi.com。感谢关注 1. 目录 1–目录2–display:none3–visibility: hidden4–opacity: 05–position: absolute;与 left: -9999px;6–z-index 和 position7–clip-path: circle(0%) 2. display:none 标签会挂载在html中,但是不会在页面上…...

EtherCAT总线学习笔记
一、EtherCAT的概述: EtherCAT是由德国BECKHOFF自动化公司于2003年提出的 实时工业以太网技术。它具有高速和高数据有效率的特点,支持多种设备连接拓扑结构。其 从站节点使用专用控制芯片,主站使用标准的以太网控制器。 EtherCAT的主要特点如…...

自学微信小程序的第八天
DAY8 1、使用动画API即可完成动画效果的制作,先通过wx.createAnimation()方法获取Animation实例,然后调用Animation实例的方法实现动画效果。 表40:wx.createAnimation()方法的常用选项 选项 类型 说明 duration number 动画持续时间,单位为毫秒,默认值为400毫秒 timing…...

WebRTC与PJSIP:呼叫中心系统技术选型指南
助力企业构建高效、灵活的通信解决方案 在数字化时代,呼叫中心系统的技术选型直接影响客户服务效率和业务扩展能力。WebRTC与PJSIP作为两大主流通信技术,各有其核心优势与适用场景。本文从功能、成本、开发门槛等维度为您深度解析,助您精准匹…...
Vue-Flow绘制流程图(Vue3+ElementPlus+TS)简单案例
本文是vue3Elementplusts框架编写的简单可拖拽绘制案例。 1.效果图: 2.Index.vue主代码: <script lang"ts" setup> import { ref, markRaw } from "vue"; import {VueFlow,useVueFlow,MarkerType,type Node,type Edge } fro…...

PDF文件转换为PNG图像
要实现将PDF文件转换为PNG图像,可以使用Python的pdf2image库。pdf2image是一个基于poppler和Pillow(PIL)的库,可以将PDF页面转换为图像。 首先,需要安装必要的库: pip install pdf2image在安装pdf2image时…...

c++中的静态多态和动态多态简介
在 C 中,多态性(Polymorphism) 分为 静态多态(Static Polymorphism) 和 动态多态(Dynamic Polymorphism),二者通过不同的机制实现代码的灵活性。以下是详细对比和核心要点࿱…...

如何通过 LlamaIndex 将数据导入 Elasticsearch
作者:来自 Elastic Andre Luiz 逐步介绍如何使用 RAG 和 LlamaIndex 提取数据并进行搜索。 在本文中,我们将使用 LlamaIndex 来索引数据,从而实现一个常见问题搜索引擎。 Elasticsearch 将作为我们的向量数据库,实现向量搜索&am…...

Boosting
Boosting 学习目标 知道boosting集成原理和实现过程知道bagging和boosting集成的区别知道AdaBoost集成原理 Boosting思想 Boosting思想图 每一个训练器重点关注前一个训练器不足的地方进行训练通过加权投票的方式,得出预测结果串行的训练方式 1 什么是boosting 随着…...

【通俗讲解电子电路】——从零开始理解生活中的电路(一)
导言:电子电路为什么重要? ——看不见的“魔法”,如何驱动你的生活? 清晨,当你的手机闹钟响起时,你可能不会想到,是电子电路在精准控制着时间的跳动;当你用微波炉加热早餐时&#…...

LeetCode72编辑距离(动态规划)
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换一个字符 示例 1: 输入:word1 “horse”, word2 “ros” 输出…...