深入解析SQL Server高级SQL技巧
SQL Server 是一种功能强大的关系型数据库管理系统,广泛应用于各种数据驱动的应用程序中。在开发过程中,掌握一些高级SQL技巧,不仅能提高查询性能,还能优化开发效率。这篇文章将全面深入地探讨SQL Server中的一些高级技巧,并结合实际例子,探索这些技巧在实际的应用。
一、使用CTE(公共表表达式)简化复杂查询
什么是CTE?
公共表表达式(CTE,Common Table Expression)是SQL Server的一种查询功能,它允许临时定义一个结果集,在查询的后续部分引用这个结果集。通过使用CTE,我们可以编写更简洁、更易于维护的SQL查询。
CTE的基本语法
WITH CTE_Name AS( SELECT column1, column2, ... FROM table_name WHERE condition )
SELECT * FROM CTE_Name;例子
假设有一张员工表Employees,我们需要查询每个部门的最高薪资员工:
WITH Department_MaxSalaryAS ( SELECT DepartmentID, MAX(Salary) AS MaxSalary FROM Employees GROUP BY DepartmentID )
SELECT E.EmployeeName, E.DepartmentID, E.Salary
FROM Employees E JOIN Department_MaxSalary DMS
ON E.DepartmentID = DMS.DepartmentIDAND E.Salary = DMS.MaxSalary;优势
- 使查询结构更清晰,尤其在需要多次引用某个复杂查询结果时。
- 递归查询:CTE支持递归操作,适合层级结构数据(如树状结构)查询。
注意
- CTE仅在当前查询的生命周期内有效,因此它不会影响全局的查询性能或结构。
二、窗口函数(Window Functions)
什么是窗口函数?
窗口函数允许我们在结果集中对某些行进行操作,而不必在查询中重新分组。常见的窗口函数包括ROW_NUMBER()、RANK()、DENSE_RANK()、NTILE()和SUM()等。
窗口函数的基本语法
SELECT column1, column2, WINDOW_FUNCTION() OVER (PARTITION BY column ORDER BY column) AS WindowFunctionResult FROM table_name;例子:使用ROW_NUMBER()为每个部门的员工排名
SELECT EmployeeName, DepartmentID, Salary, ROW_NUMBER()OVER (PARTITION BY DepartmentID ORDER BY Salary DESC) AS Rank FROM Employees;在这个例子中,ROW_NUMBER()为每个部门的员工按薪资排名,PARTITION BY用于指定分区,ORDER BY用于确定排序规则。
优势
- 不需要子查询或复杂的连接,简化查询结构。
- 可以执行复杂的排名、累计、移动平均等操作。
注意
- 窗口函数的执行顺序是按
OVER子句中的PARTITION BY和ORDER BY排序的,因此理解它们的使用方式非常重要。
三、使用MERGE语句进行数据同步
什么是MERGE?
MERGE语句用于将两个表的数据进行比较,并在匹配的情况下更新数据,在不匹配的情况下插入或删除数据。它是处理增量数据同步的一个有效工具。
MERGE的基本语法
MERGE INTO target_table AS target USING source_table AS source ON target.column = source.column WHEN MATCHED THEN UPDATE SET target.column1 = source.column1 WHEN NOT MATCHED BY TARGET THEN INSERT (column1, column2) VALUES (source.column1, source.column2) WHEN NOT MATCHED BY SOURCE THEN DELETE;例子:将SourceData表的数据同步到TargetData表
MERGE INTO TargetData AS target USING SourceDataAS source ON target.ID = source.ID WHEN MATCHED
THEN UPDATE SET target.Name = source.Name, target.Age = source.Age
WHEN NOT MATCHED BY
TARGET THEN INSERT (ID, Name, Age) VALUES (source.ID, source.Name, source.Age) WHEN NOT MATCHED BY SOURCE THEN DELETE;优势
- 通过单一的
MERGE语句完成数据的插入、更新和删除操作,避免了使用多个INSERT、UPDATE和DELETE语句。 - 适合用于数据仓库的ETL操作。
注意
MERGE操作的执行可能较慢,尤其是在处理大量数据时,因此在使用时需要特别注意性能问题。
四、索引优化:创建合适的索引
为什么需要索引?
索引可以加速查询操作,尤其是在查询条件中涉及大量数据的情况下。如果没有索引,SQL Server会扫描整个表,导致查询性能低下。
创建索引的基本语法
CREATE INDEX index_name ON table_name (column1, column2, ...);例子:为Employees表的DepartmentID列创建索引
CREATE INDEX IX_DepartmentID ON Employees(DepartmentID);覆盖索引
覆盖索引(Covering Index)是指包含查询所需的所有列的索引。在某些查询中,SQL Server可以仅通过索引查找数据,而无需回到数据表进行检索,从而提高性能。
CREATE INDEX IX_CoveringIndex ON Employees(DepartmentID, Salary, EmployeeName);优势
- 提高查询性能,尤其是对于大数据量的表。
- 减少了查询时的磁盘I/O操作。
注意
- 创建索引时需要权衡空间和性能的消耗,过多的索引会导致插入、更新和删除操作的性能下降。
- 根据实际查询的特点,选择合适的列进行索引创建。
五、查询优化:避免不必要的DISTINCT和GROUP BY
为什么要避免DISTINCT?
DISTINCT操作通常需要对整个结果集进行排序和去重,可能会消耗大量的计算资源。对于某些查询,尤其是涉及大数据量时,DISTINCT会导致不必要的性能损失。
例子
假设我们有一个订单表Orders,查询不重复的客户ID。
SELECT DISTINCT CustomerID FROM Orders;这个查询本质上是对所有CustomerID进行去重。在某些情况下,我们可以通过其他方式优化:
SELECT CustomerID FROM Orders GROUP BY CustomerID;优势
- 在处理大数据时,避免使用
DISTINCT或GROUP BY,可以减少不必要的计算负担。 - 可以通过索引优化查询性能。
注意
- 在查询中使用
DISTINCT和GROUP BY时,需要确保它们的必要性和效率,避免不必要的性能浪费。
六、优化查询:使用查询计划
查询计划是什么?
查询计划是SQL Server生成的一个操作计划,描述了如何执行一个SQL查询。通过分析查询计划,可以优化SQL查询的执行路径,从而提高查询性能。
查看查询计划
可以使用SET SHOWPLAN_ALL命令查看查询的执行计划:
SET SHOWPLAN_ALL ON; GO SELECT * FROM Orders WHERE CustomerID = 'ALFKI'; GO
SET SHOWPLAN_ALL OFF;优势
- 通过分析查询计划,可以了解查询的瓶颈,并对数据库进行索引、统计信息等优化。
- 可以通过SQL Server Management Studio(SSMS)中的“实际执行计划”选项,直观地查看查询的执行步骤。
注意
- 查询计划仅适用于优化查询的性能,而不是优化数据库设计或架构。
七、使用 PARTITION BY 优化分区查询
什么是分区查询?
在SQL Server中,PARTITION BY 是窗口函数的一部分,它能够按照特定的列对数据进行分区,然后对每个分区进行独立的计算。通过分区,你可以实现更加灵活且高效的查询。
例子:按部门计算每个员工的薪资排名
SELECT EmployeeName,DepartmentID, Salary, RANK() OVER (PARTITION BY DepartmentID ORDER BY Salary DESC) AS Rank
FROM Employees;优势
- 提高查询性能:通过分区,SQL Server能够更快速地处理分组后的数据,而不需要进行全表扫描。
- 优化查询逻辑:当你需要对每个分区的数据进行计算时,
PARTITION BY是非常有用的工具。
注意
- 分区查询特别适用于复杂的聚合或排序操作,如分组排名、分区求和等。
八、避免使用 SELECT *,明确列出需要的字段
为什么要避免 SELECT *?
虽然使用 SELECT * 可以快速获取表中的所有列数据,但它通常会导致不必要的性能开销,特别是当表非常大或包含许多不必要的列时。使用 SELECT * 还可能导致列的冗余提取,影响数据库I/O操作。
例子:明确列出查询需要的字段
假设有一张用户表Users,你只需要查询UserName和Email字段:
SELECT UserName, Email FROM Users;与之相对,以下查询使用了 SELECT *:
SELECT * FROM Users;优势
- 减少数据传输量:只获取需要的字段,避免了多余的列数据传输和I/O负担。
- 提高查询效率:减少了数据库在执行查询时的计算工作量。
注意
- 在表结构发生变化时,
SELECT *可能导致意外的行为,因此在开发时要避免使用它,而是明确列出查询所需的字段。
九、优化子查询:避免使用嵌套的SELECT语句
为什么要避免嵌套查询?
嵌套查询在某些情况下会导致性能瓶颈,尤其是在大数据量时。嵌套的 SELECT 查询通常会导致SQL Server多次扫描表,尤其是子查询返回的结果集非常大时。
例子:使用连接代替嵌套查询
假设我们有两张表:Orders 和 Customers,需要查询所有下过订单的客户信息。
使用嵌套查询:
SELECT CustomerID, CustomerName
FROM Customers WHERE CustomerID IN (SELECT CustomerID FROM Orders);使用连接:
SELECT DISTINCT C.CustomerID,C.CustomerName
FROM Customers C JOIN Orders O ON C.CustomerID = O.CustomerID;优势
- 减少多次扫描:通过连接代替嵌套查询,减少了SQL Server在执行过程中多次扫描相同的数据表。
- 提高性能:在复杂查询中,连接查询通常比嵌套查询更高效,尤其是当连接的列有索引时。
注意
- 当处理较大的数据集时,连接查询往往比嵌套查询要快,但需要确保连接条件的正确性,避免笛卡尔积等错误结果。
十、使用 IN 和 EXISTS 时的优化选择
IN 与 EXISTS 的区别
IN 和 EXISTS 都用于测试某个条件是否满足,但它们在执行时有不同的效率表现。通常情况下,EXISTS 在处理大数据量时比 IN 更高效,因为 IN 会将子查询的结果集全部加载到内存中,而 EXISTS 会在找到第一个匹配项时停止执行。
例子:使用 EXISTS 代替 IN
假设我们需要查询那些下过订单的客户:
SELECTCustomerID, CustomerName
FROM Customers C
WHERE EXISTS (SELECT 1 FROM Orders O WHERE O.CustomerID = C.CustomerID);相反,使用 IN 的查询如下:
SELECT CustomerID, CustomerName
FROM Customers
WHERE CustomerID IN (SELECT CustomerID FROM Orders);优势
- 性能提升:对于大型数据集,
EXISTS通常比IN更高效,因为它在找到匹配时就会停止。 - 减少内存占用:
EXISTS不需要将整个子查询结果集加载到内存中,而是实时检查条件。
注意
- 如果子查询的返回结果非常小(如一个小范围的ID集合),
IN的性能可能与EXISTS相当,甚至更好。 - 对于大型子查询,优先选择
EXISTS。
十一、批量更新和删除操作优化
为什么需要批量操作?
在大数据量的操作中,直接进行全表的 UPDATE 或 DELETE 可能会导致数据库锁定、性能下降等问题。为了避免这些问题,可以将操作拆分成多个小批次进行。
例子:分批删除数据
假设我们需要删除Orders表中所有过期的订单数据,但由于数据量过大,直接删除会导致性能问题。我们可以采用批量删除的方式:
SET ROWCOUNT 1000; -- 每次删除1000条记录
DELETE FROM Orders WHERE OrderDate < '2022-01-01'; SET ROWCOUNT 0; -- 恢复默认行为优势
- 减少锁竞争:分批次操作可以减少对数据库表的锁定,避免长时间占用资源。
- 提高性能:分批操作可以减少每次操作的数据量,优化数据库的执行时间。
注意
- 批量操作需要根据实际数据量进行合理调整,避免一次性操作过多数据导致系统资源消耗过大。
十二、优化联接(JOIN)操作
使用合适的连接类型
在SQL中,我们通常使用 INNER JOIN、LEFT JOIN、RIGHT JOIN 或 FULL JOIN 来连接多个表。在选择连接类型时,理解各个连接的使用场景对优化查询至关重要。
优化 INNER JOIN
INNER JOIN 是最常见的连接类型,它只返回两个表中匹配的记录。如果可能,使用 INNER JOIN 优化查询,因为它通常比其他类型的连接要高效。
SELECT O.OrderID,C.CustomerName
FROM Orders O
INNER JOIN Customers C ON O.CustomerID = C.CustomerID;使用 OUTER JOIN 时的优化
OUTER JOIN 可以返回左表或右表中没有匹配的记录,但它通常比 INNER JOIN 更慢。只有在确实需要包含无匹配项的记录时,才使用 OUTER JOIN。
优势
- 更高效的连接:使用
INNER JOIN优化查询,尤其在数据表索引良好的情况下。 - 减少数据量:如果只需要返回匹配记录,尽量使用
INNER JOIN来提高查询效率。
注意
- 对于较大的数据集,尤其是当涉及
LEFT JOIN或RIGHT JOIN时,要特别关注性能,确保数据库设计和索引优化良好。
相关文章:

深入解析SQL Server高级SQL技巧
SQL Server 是一种功能强大的关系型数据库管理系统,广泛应用于各种数据驱动的应用程序中。在开发过程中,掌握一些高级SQL技巧,不仅能提高查询性能,还能优化开发效率。这篇文章将全面深入地探讨SQL Server中的一些高级技巧…...

PyCharm怎么集成DeepSeek
PyCharm怎么集成DeepSeek 在PyCharm中集成DeepSeek等大语言模型(LLM)可以借助一些插件或通过代码调用API的方式实现,以下为你详细介绍两种方法: 方法一:使用JetBrains AI插件(若支持DeepSeek) JetBrains推出了AI插件来集成大语言模型,不过截至2024年7月,官方插件主要…...

Hive之正则表达式RLIKE详解及示例
目录 一、RLIKE 语法及核心特性 1. 基本语法 2. 核心特性 二、常见业务场景及示例 场景1:过滤包含特定模式的日志(如错误日志) 场景2:验证字段格式(如邮箱、手机号) 场景3:提取复杂文本中…...

fluent-ffmpeg 依赖详解
fluent-ffmpeg 是一个用于在 Node.js 环境中与 FFmpeg 进行交互的强大库,它提供了流畅的 API 来执行各种音视频处理任务,如转码、剪辑、合并等。 一、安装 npm install fluent-ffmpeg二、基本使用 要使用 fluent-ffmpeg,首先需要确保系统中…...

【定昌Linux系统】部署了java程序,设置开启启动
将代码上传到相应的目录,并且配置了一个.sh的启动脚本文件 文件内容: #!/bin/bash# 指定JAR文件的路径(如果JAR文件在当前目录,可以直接使用文件名) JAR_FILE"/usr/local/java/xs_luruan_client/lib/xs_luruan_…...

Java零基础入门笔记:(7)异常
前言 本笔记是学习狂神的java教程,建议配合视频,学习体验更佳。 【狂神说Java】Java零基础学习视频通俗易懂_哔哩哔哩_bilibili 第1-2章:Java零基础入门笔记:(1-2)入门(简介、基础知识)-CSDN博客 第3章…...

【字符串】最长公共前缀 最长回文子串
文章目录 14. 最长公共前缀解题思路:模拟5. 最长回文子串解题思路一:动态规划解题思路二:中心扩散法 14. 最长公共前缀 14. 最长公共前缀 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符…...

【软路由】ImmortalWrt 编译指南:从入门到精通
对于喜欢折腾路由器,追求极致性能和定制化的玩家来说,OpenWrt 无疑是一个理想的选择。而在众多 OpenWrt 衍生版本中,ImmortalWrt 以其更活跃的社区、更激进的特性更新和对新硬件的支持而备受关注。 本文将带你深入了解 ImmortalWrt࿰…...

react 中,使用antd layout布局中的sider 做sider的展开和收起功能
一 话不多说,先展示效果: 展开时: 收起时: 二、实现代码如下 react 文件 import React, {useState} from react; import {Layout} from antd; import styles from "./index.module.less"; // 这个是样式文件&#…...

easyExcel使用案例有代码
easyExcel 入门,完成web的excel文件创建和导出 easyExcel官网 EasyExcel 的主要特点如下: 1、高性能:EasyExcel 采用了异步导入导出的方式,并且底层使用 NIO 技术实现,使得其在导入导出大数据量时的性能非常高效。 2、易于使…...

CPU、SOC、MPU、MCU--详细分析四者的区别
一、CPU 与SOC的区别 1.CPU 对于电脑,我们经常提到,处理器,内存,显卡,硬盘四大部分可以组成一个基本的电脑。其中的处理器——Central Processing Unit(中央处理器)。CPU是一台计算机的运算核…...

机器学习:监督学习、无监督学习和强化学习
机器学习(Machine Learning, ML)是人工智能(AI)的一个分支,它使计算机能够从数据中学习,并在没有明确编程的情况下执行任务。机器学习的核心思想是使用算法分析数据,识别模式,并做出…...

SpringBoot项目注入 traceId 来追踪整个请求的日志链路
SpringBoot项目注入 traceId 来追踪整个请求的日志链路,有了 traceId, 我们在排查问题的时候,可以迅速根据 traceId 查找到相关请求的日志,特别是在生产环境的时候,用户可能只提供一个错误截图,我们作为开发…...

苹果廉价机型 iPhone 16e 影像系统深度解析
【人像拍摄差异】 尽管iPhone 16e支持后期焦点调整功能,但用户无法像iPhone 16系列那样通过点击屏幕实时切换拍摄主体。前置摄像头同样缺失人像深度控制功能,不过TrueTone原彩闪光灯系统在前后摄均有保留。 很多人都高估了 iPhone 的安全性,查…...

视觉图像坐标转换
1. 透镜成像 相机的镜头系统将三维场景中的光线聚焦到一个平面(即传感器)。这个过程可以用小孔成像模型来近似描述,尽管实际相机使用复杂的透镜系统来减少畸变和提高成像质量。 小孔成像模型: 假设有一个理想的小孔,…...

汽车电子电控软件开发中因复杂度提升导致的架构恶化问题
针对汽车电子电控软件开发中因复杂度提升导致的架构恶化问题,建议从以下方向进行架构优化和开发流程升级,以提升灵活性、可维护性和扩展性: 一、架构设计与模块化优化 分层架构与模块解耦 采用AUTOSAR标准的分层架构(应用层、运行…...

2024年第十五届蓝桥杯大赛软件赛省赛Python大学A组真题解析《更新中》
文章目录 试题A: 拼正方形(本题总分:5 分)解析答案试题B: 召唤数学精灵(本题总分:5 分)解析答案试题C: 数字诗意解析答案试题D:回文数组试题A: 拼正方形(本题总分:5 分) 【问题描述】 小蓝正在玩拼图游戏,他有7385137888721 个2 2 的方块和10470245 个1 1 的方块,他需…...

脚本无法获取响应主体(原因:CORS Missing Allow Credentials)
背景: 前端的端口号8080,后端8000。需在前端向后端传一个参数,让后端访问数据库去检测此参数是否出现过。涉及跨域请求,一直有这个bug是404文件找不到。 在修改过程当中不小心删除了一段代码,出现了这个bug࿰…...

leetcode第39题组合总和
原题出于leetcode第39题https://leetcode.cn/problems/combination-sum/description/题目如下: 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以…...

在 macOS 系统上安装 kubectl
在 macOS 系统上安装 kubectl 官网:https://kubernetes.io/zh-cn/docs/tasks/tools/install-kubectl-macos/ 用 Homebrew 在 macOS 系统上安装 如果你是 macOS 系统,且用的是 Homebrew 包管理工具, 则可以用 Homebrew 安装 kubectl。 运行…...

SQLark 数据迁移|断点续迁已上线(Oracle-达梦)
数据迁移是 SQLark 最受企业和个人用户欢迎的功能之一,截止目前已帮助政府、金融、能源、通信等 50 家单位完成从 Oracle、MySQL 到达梦的全量迁移,自动化迁移成功率达 96% 以上。 在 Oracle 到达梦数据库迁移过程中,SQLark V3.3 新增 断点续…...

Element Plus中el-tree点击的节点字体变色加粗
el-tree标签设置 <el-tree class"tree":data"treeData":default-expand-all"true":highlight-current"true"node-click"onTreeNodeClick"><!-- 自定义节点内容,点击的节点字体变色加粗 --><!-- 动…...

vmware安装firepower ftd和fmc
在vmware虚拟机中安装cisco firepower下一代防火墙firepower threat defence(ftd)和管理中心firepower management center(fmc)。 由于没有cisco官网下载账号,无法下载其中镜像。使用eveng模拟器中的ftd和fmc虚拟镜像…...

计算机毕业设计SpringBoot+Vue.js医院资源管理系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

[含文档+PPT+源码等]精品基于Python实现的微信小程序的乡村医疗咨询系统
基于Python实现的微信小程序的乡村医疗咨询系统背景,可以从以下几个方面进行阐述: 一、社会背景 医疗资源分布不均:在我国,城乡医疗资源分布不均是一个长期存在的问题。乡村地区由于地理位置偏远、经济条件有限,往往…...

Python实现GO鹅优化算法优化BP神经网络回归模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后关注获取。 1.项目背景 传统BP神经网络的局限性:BP(Back Propagation)神经网络作为一种…...
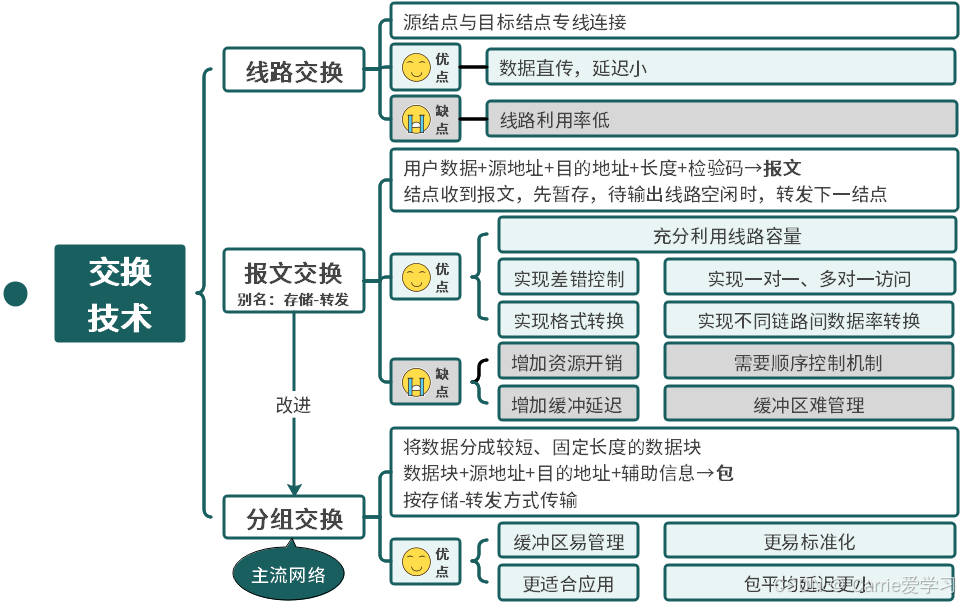
7.1.2 计算机网络的分类
文章目录 分布范围交换方式 分布范围 计算机网络按照分布范围可分为局域网、广域网、城域网。局域网的范围在10m~1km,例如校园网,网速高,主要用于共享网络资源,拓扑结构简单,约束少。广域网的范围在100km,例…...

千峰React:Hooks(上)
什么是Hooks ref引用值 普通变量的改变一般是不好触发函数组件的渲染的,如果想让一般的数据也可以得到状态的保存,可以使用ref import { useState ,useRef} from reactfunction App() {const [count, setCount] useState(0)let num useRef(0)const h…...

设置同一个局域网内远程桌面Ubuntu
1、安装xrdp: 打开终端,运行以下命令来安装xrdp: sudo apt update sudo apt install xrdp 2、启动 XRDP 并设置开机自启 sudo systemctl start xrdp sudo systemctl enable xrdp 3、验证 XRDP 运行状态 sudo systemctl status xrdp 如果显示 active (ru…...

深入 Python:变量与数据类型的奥秘
在 Python 编程的世界里,变量和数据类型是构建程序大厦的基石。它们看似简单,却蕴含着无尽的奥秘和强大的功能。今天,就让我们一起深入探索 Python 中变量与数据类型的奇妙世界。 常量和表达式:数学世界的 Python 映射 在 Pytho…...