利用 LangChain 和一个大语言模型(LLM)构建一个链条,自动从用户输入的问题中提取相关的 SQL 表信息,再生成对应的 SQL 查询
示例代码:
from langchain_core.runnables import RunnablePassthrough
from langchain.chains import create_sql_query_chain
from operator import itemgetter
from langchain.chains.openai_tools import create_extraction_chain_pydantic# 系统消息,要求 LLM 返回与问题相关的 SQL 表类别
system = """Return the names of the SQL tables that are relevant to the user question. \
The tables are:Music
Business"""# 初始化 LLM 模型
table_extractor_llm = init_chat_model("llama3-70b-8192", model_provider="groq", temperature=0)# 创建提取链:将用户问题转换为 Table 模型的实例
category_chain = create_extraction_chain_pydantic(pydantic_schemas=Table, llm=table_extractor_llm, system_message=system)# 定义一个函数,根据 Table 对象映射到具体的 SQL 表名
def get_tables(categories: List[Table]) -> List[str]:"""将类别名称映射到对应的 SQL 表名列表."""tables = []for category in categories:if category.name == "Music":tables.extend(["Album","Artist","Genre","MediaType","Playlist","PlaylistTrack","Track",])elif category.name == "Business":tables.extend(["Customer", "Employee", "Invoice", "InvoiceLine"])return tables# 将类别提取链与映射函数组合,得到一个返回 SQL 表名列表的链
table_chain = category_chain | get_tables # 定义自定义 SQL 提示模板,用于生成 SQL 查询
custom_prompt = PromptTemplate(input_variables=["dialect", "input", "table_info", "top_k"],template="""You are a SQL expert using {dialect}.
Given the following table schema:
{table_info}
Generate a syntactically correct SQL query to answer the question: "{input}".
Don't limit the results to {top_k} rows.
Return only the SQL query without any additional commentary or Markdown formatting.
"""
)# 创建 SQL 查询链
query_chain = create_sql_query_chain(table_extractor_llm, db, prompt=custom_prompt)# 利用 bind 将固定参数绑定到 SQL 查询链中
bound_chain = query_chain.bind(dialect=db.dialect,table_info=db.get_table_info(),top_k=55
)# 将输入中的 "question" 键复制到 "input" 键,同时保留原始数据
table_chain = (lambda x: {**x, "input": x["question"]}) | table_chain# 使用 RunnablePassthrough.assign 将提取到的表名添加到上下文中,然后与 SQL 查询链组合
full_chain = RunnablePassthrough.assign(table_names_to_use=table_chain) | bound_chain# 调用整个链,生成 SQL 查询
query = full_chain.invoke({"question": "What are all the genres of Alanis Morisette songs? Do not repeat!"}
)
print(query)这段代码主要展示如何利用 LangChain 和一个大语言模型(LLM)构建一个链条,自动从用户输入的问题中提取相关的 SQL 表信息,再生成对应的 SQL 查询。下面我将分步详细解释每个部分的作用,并通过举例说明每段代码的输入和输出。
1. 定义系统消息和初始化 LLM 模型
system = """Return the names of the SQL tables that are relevant to the user question. \
The tables are:Music
Business"""
-
作用:
这段系统消息告诉 LLM:请根据用户的问题返回与问题相关的 SQL 表类别,这里限定了两类——“Music”和“Business”。 -
举例:
如果用户的问题涉及音乐信息(例如歌曲、专辑等),那么 LLM 会返回 “Music”;如果涉及客户、发票等信息,则返回 “Business”。
table_extractor_llm = init_chat_model("llama3-70b-8192", model_provider="groq", temperature=0)
-
作用:
初始化一个 LLM 模型(此处使用 llama3-70b-8192,由 groq 提供,温度设为 0 以保证回答确定性),后续会用这个模型进行类别提取和 SQL 查询生成。 -
输出:
返回一个 LLM 实例table_extractor_llm。
2. 创建提取链:从问题中抽取相关表类别
category_chain = create_extraction_chain_pydantic(pydantic_schemas=Table, llm=table_extractor_llm, system_message=system)
-
作用:
这里利用create_extraction_chain_pydantic创建了一个链,该链的任务是将用户输入的问题转换为一个或多个符合 Pydantic 模型Table的实例。也就是说,LLM 会分析问题并输出如Table(name="Music")或Table(name="Business")的结果。 -
输入:
用户问题(例如 “What are all the genres of Alanis Morisette songs? Do not repeat!”)。 -
输出:
一个或多个Table对象,指明问题相关的表类别。例如,对于这个问题,可能返回[Table(name="Music")]。

3. 定义映射函数,将类别映射到具体的 SQL 表名
def get_tables(categories: List[Table]) -> List[str]:"""将类别名称映射到对应的 SQL 表名列表."""tables = []for category in categories:if category.name == "Music":tables.extend(["Album","Artist","Genre","MediaType","Playlist","PlaylistTrack","Track",])elif category.name == "Business":tables.extend(["Customer", "Employee", "Invoice", "InvoiceLine"])return tables
-
作用:
此函数接收前面提取链返回的Table对象列表,根据类别名称映射到具体的 SQL 表名列表:- 如果类别是 “Music”,则映射为音乐相关的多个表(如 Album、Artist、Genre 等)。
- 如果类别是 “Business”,则映射为商业相关的表(如 Customer、Invoice 等)。
-
举例:
- 输入:
[Table(name="Music")] - 输出:
["Album", "Artist", "Genre", "MediaType", "Playlist", "PlaylistTrack", "Track"]
- 输入:
4. 组合提取链和映射函数
table_chain = category_chain | get_tables
-
作用:
利用管道操作符(|)将category_chain和get_tables组合起来。整个链条(table_chain)的作用就是:接收用户问题 → 利用 LLM 提取相关类别 → 将类别映射为具体的 SQL 表名列表。 -
输入:
一个包含用户问题的字典(例如{"question": "..."})。 -
输出:
一个 SQL 表名列表,如上例中的音乐相关表名列表。

5. 定义自定义 SQL 提示模板
custom_prompt = PromptTemplate(input_variables=["dialect", "input", "table_info", "top_k"],template="""You are a SQL expert using {dialect}.
Given the following table schema:
{table_info}
Generate a syntactically correct SQL query to answer the question: "{input}".
Don't limit the results to {top_k} rows.
Return only the SQL query without any additional commentary or Markdown formatting.
"""
)
-
作用:
该模板为生成 SQL 查询提供指令:- 指定 SQL 方言(如 MySQL、PostgreSQL 等)。
- 提供数据库的表结构信息。
- 告诉 LLM 根据问题(
{input})生成正确的 SQL 查询。 - 不要限制返回行数,并且只返回 SQL 语句本身,无额外说明。
-
举例:
如果传入:dialect: “SQLite”input: “What are all the genres of Alanis Morisette songs? Do not repeat!”table_info: 数据库所有表的结构信息top_k: 55
那么模板会指导 LLM 输出类似下面的 SQL 查询(实际内容由 LLM 根据 schema 生成):
SELECT DISTINCT Genre.Name FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId JOIN Artist ON Track.ArtistId = Artist.ArtistId WHERE Artist.Name = 'Alanis Morisette';
6. 创建 SQL 查询链并绑定固定参数
query_chain = create_sql_query_chain(table_extractor_llm, db, prompt=custom_prompt)
- 作用:
利用同一个 LLM 实例和预定义的 SQL 提示模板,创建一个 SQL 查询链。该链将根据数据库表结构(db)和用户问题生成 SQL 查询。
bound_chain = query_chain.bind(dialect=db.dialect,table_info=db.get_table_info(),top_k=55
)
-
作用:
通过bind方法将一些固定的参数绑定到 SQL 查询链上:dialect:数据库使用的 SQL 方言。table_info:数据库中所有表的结构信息。top_k:限制返回的行数,这里设定为 55 行,但指令中说明不要限制,所以其实这个参数仅作为提示的一部分。
-
输出:
得到一个参数已经固定的 SQL 查询链bound_chain,后续调用时只需要传入用户问题(以及其他动态数据)。
7. 调整输入数据格式
table_chain = (lambda x: {**x, "input": x["question"]}) | table_chain
-
作用:
这行代码先用一个 lambda 函数将输入字典中的"question"键复制一份到"input"键,目的是统一变量名称(因为上面的 SQL 提示模板要求有input变量)。然后再将结果传递给table_chain。 -
举例:
- 输入:
{"question": "What are all the genres of Alanis Morisette songs? Do not repeat!"} - lambda 输出:
{"question": "What are all the genres of Alanis Morisette songs? Do not repeat!", "input": "What are all the genres of Alanis Morisette songs? Do not repeat!"} - 最终经过 table_chain 输出: 列表形式的 SQL 表名,如
["Album", "Artist", "Genre", "MediaType", "Playlist", "PlaylistTrack", "Track"]
- 输入:
8. 组合整个链条,生成最终 SQL 查询
full_chain = RunnablePassthrough.assign(table_names_to_use=table_chain) | bound_chain
-
作用:
这里使用RunnablePassthrough.assign将从table_chain得到的 SQL 表名列表赋值到上下文中的table_names_to_use键,然后通过管道传递给已经绑定参数的 SQL 查询链bound_chain。这一步确保了在生成 SQL 查询时,上下文中不仅包含用户的原始问题,还包含了与之相关的 SQL 表名信息。 -
输入:
包含用户问题的字典(经过前面的处理已包含"input"键)。 -
输出:
经过整个链条处理后,输出最终生成的 SQL 查询语句。
9. 调用链条并生成 SQL 查询
query = full_chain.invoke({"question": "What are all the genres of Alanis Morisette songs? Do not repeat!"}
)
print(query)
-
作用:
这里将包含用户问题的字典传递给full_chain。整个流程如下:- 提取表类别:首先通过
table_chain将"question"转换为"input",然后利用 LLM 提取出与问题相关的类别(预期为 “Music”)。 - 映射表名称:根据类别映射出所有与音乐相关的 SQL 表名。
- 生成 SQL 查询:利用绑定好的
bound_chain(包含 SQL 模板、数据库 schema 信息等),结合用户的问题和上下文信息,生成一个正确的 SQL 查询。
- 提取表类别:首先通过
-
输出举例:
假设 LLM 理解问题并生成的 SQL 查询可能为:SELECT DISTINCT Genre.Name FROM Track JOIN Genre ON Track.GenreId = Genre.GenreId JOIN Artist ON Track.ArtistId = Artist.ArtistId WHERE Artist.Name = 'Alanis Morisette';(实际生成的 SQL 语句会依赖于 LLM 的理解和数据库的 schema 信息。)
最后运行这个SQL语句
db.run(query)
输出:

总结
这段代码整体实现了一个智能化的数据查询过程:
- 输入: 用户问题(如关于 Alanis Morisette 歌曲的查询)。
- 内部处理:
- 利用 LLM 提取相关 SQL 表类别。
- 根据类别映射出具体的 SQL 表名称。
- 结合数据库的表结构和预定义的 SQL 提示模板,生成正确的 SQL 查询语句。
- 输出: 一条 SQL 查询语句,用来从数据库中获取答案。
这种链式结构使得整个流程模块化、可扩展:可以分别替换提取逻辑、映射逻辑和 SQL 查询生成逻辑,非常适合在实际应用中自动生成数据库查询。
相关文章:
利用 LangChain 和一个大语言模型(LLM)构建一个链条,自动从用户输入的问题中提取相关的 SQL 表信息,再生成对应的 SQL 查询
示例代码: from langchain_core.runnables import RunnablePassthrough from langchain.chains import create_sql_query_chain from operator import itemgetter from langchain.chains.openai_tools import create_extraction_chain_pydantic# 系统消息ÿ…...

力扣hot 100之矩阵四题解法总结
本期总结hot100 中二维矩阵的题,时空复杂度就不分析了 1.矩阵置零 原地标记,用第一行和第一列作为当前行列是否为0的标记,同时用两个标签分别记录0行、0列的标记空间中原本是否有0 class Solution:def setZeroes(self, matrix: List[List[…...

使用python运行网格世界环境下 TD算法
一、概述 本代码实现了在网格世界环境中使用 TD (0)(Temporal Difference (0))算法进行策略评估,并对评估结果进行可视化展示。通过模拟智能体在网格世界中的移动,不断更新状态值函数,最终得到每个状态的价值估计。 二…...

在Linux上使用APT安装Sniffnet的详细步骤
一、引言 Sniffnet 是一款开源的网络流量监控工具,适用于多种Linux发行版。如果你的Linux系统使用APT(Advanced Package Tool)作为包管理器,以下是如何通过APT安装Sniffnet的详细步骤。 二、系统要求 在开始安装之前࿰…...

zookeeper-docker版
Zookeeper-docker版 1 zookeeper概述 1.1 什么是zookeeper Zookeeper是一个分布式的、高性能的、开源的分布式系统的协调(Coordination)服务,它是一个为分布式应用提供一致性服务的软件。 1.2 zookeeper应用场景 zookeeper是一个经典的分…...

StableDiffusion本地部署 3 整合包猜想
本地部署和整合包制作猜测 文章目录 本地部署和整合包制作猜测官方部署第一种第二种 StabilityMatrix下载整合包制作流程猜测 写了这么多python打包和本地部署的文章,目的是向做一个小整合包出来,不要求有图形界面,只是希望一键就能运行。 但…...

数据结构(初阶)(七)----树和二叉树(前中后序遍历)
实现链式结构的二叉树 实现链式结构的二叉树遍历前序遍历中序遍历后序遍历 节点个数叶子节点个数⼆叉树第k层结点个数⼆叉树的深度/⾼度查找值为X的节点二叉树的销毁 层序遍历判断二叉树是否为完全二叉树 ⽤链表来表⽰⼀棵⼆叉树,即⽤链来指⽰元素的逻辑关系。 通常…...

SOME/IP 教程知识点总结
总结关于SOME/IP的教程,首先通读整个文件,理解各个部分的内容。看起来这个教程从介绍开始,讲到了为什么在车辆中使用以太网,然后详细讲解了SOME/IP的概念、序列化、消息传递、服务发现(SOME/IP-SD)、发布/订阅机制以及支持情况。 首先,我需要确认每个章节的主要知识点。…...

安装 Windows Docker Desktop - WSL问题
一、关联文章: 1、Docker Desktop 安装使用教程 2、家庭版 Windows 安装 Docker 没有 Hyper-V 问题 3、打开 Windows Docker Desktop 出现 Docker Engine Stopped 问题 二、问题解析 打开 Docker Desktop 出现问题,如下: Docker Desktop - WSL update failed An error o…...

科技赋能筑未来 中建海龙MiC建筑技术打造保障房建设新标杆
近日,深圳梅林路6号保障房项目顺利封顶,标志着国内装配式建筑领域又一里程碑式突破。中建海龙科技有限公司(以下简称“中建海龙”)以模块化集成建筑(MiC)技术为核心,通过科技创新与工业化建造深…...

json介绍、python数据和json数据的相互转换
目录 一 json介绍 json是什么? 用处 Json 和 XML 对比 各语言对Json的支持情况 Json规范详解 二 python数据和json数据的相互转换 dumps() : 转换成json loads(): 转换成python数据 总结 一 json介绍 json是什么? 实质上是一条字符串 是一种…...

关于学习一门新的编程语言的策略
实践 实践 实践 那么如何实践呢 ,very easy,测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测验 测…...

Rust 是什么
Rust 是什么 Rust 是一种由 Mozilla 开发的系统级编程语言,它于 2010 年首次亮相,在 2015 年发布 1.0 版本,此后迅速发展并受到广泛关注。 内存安全:Rust 最大的亮点之一是它在编译阶段就能够避免常见的内存错误,如空指针引用、数据竞争和内存泄漏等。它通过所有权(Owne…...

C#开发——时间间隔类TimSpan
TimeSpan 是 C# 中的一个结构( struct ),用于表示时间间隔或持续时间。它位于 System 命名空间中,是处理时间相关操作时非常重要的工具,尤其是在计算两个日期或时间之间的差值、表示时间段或执行时间相关的运算…...

计算机毕设JAVA——某高校宿舍管理系统(基于SpringBoot+Vue前后端分离的项目)
文章目录 概要项目演示图片系统架构技术运行环境系统功能简介 概要 网络上许多计算机毕设项目开发前端界面设计复杂、不美观,而且功能结构十分单一,存在很多雷同的项目:不同的项目基本上就是套用固定模板,换个颜色、改个文字&…...

[随手笔记]C#保留小数防止四舍五入有效解决办法
private decimal 截断小数(decimal 原小数值, int 保留小数个数) { string 原小数转字符串值 原小数值.ToString(); try { if (原小数转字符串值.Contains(".")) { int 原小数总长度 原小数转字符串值.Length; …...

C++ 二叉树代码
二叉树代码,见下 #include <iostream> using namespace std;template<typename T> struct TreeNode{T val;TreeNode *left;TreeNode *right;TreeNode():val(0), left(NULL), right(NULL)TreeNode(T x):val(x), left(NULL), right(NULL){} };template&l…...

Spring Boot 测试:单元、集成与契约测试全解析
一、Spring Boot 分层测试策略 Spring Boot 应用采用经典的分层架构,不同层级的功能模块对应不同的测试策略,以确保代码质量和系统稳定性。 Spring Boot 分层架构: Spring Boot分层架构 A[客户端] -->|HTTP 请求| B[Controller 层] …...

Oracle 数据库基础入门(四):分组与联表查询的深度探索(上)
在 Oracle 数据库的学习进程中,分组查询与联表查询是进阶阶段的重要知识点,它们如同数据库操作的魔法棒,能够从复杂的数据中挖掘出有价值的信息。对于 Java 全栈开发者而言,掌握这些技能不仅有助于高效地处理数据库数据࿰…...

机器学习的起点:线性回归Linear Regression
机器学习的起点:线性回归Linear Regression 作为机器学习的起点,线性回归是理解算法逻辑的绝佳入口。我们从定义、评估方法、应用场景到局限性,用生活化的案例和数学直觉为你构建知识框架。 回归算法 一、线性回归的定义与核心原理 定义&a…...

2024贵州大学计算机考研复试上机真题
历年贵州大学计算机考研复试上机真题 2024贵州大学计算机考研复试上机真题 2023贵州大学计算机考研复试上机真题 贵州大学计算机考研复试上机真题 在线 oj 测评:https://app2098.acapp.acwing.com.cn/problem/list/ 字符串翻转 题目描述 给定一个字符串…...

17、什么是智能指针,C++有哪几种智能指针【高频】
智能指针其实不是指针,而是一个(模板)类,用来存储指向某块资源的指针,并自动释放这块资源,从而解决内存泄漏问题。主要有以下四种: auto_ptr 它的思想就是当当一个指针对象赋值给另一个指针对…...
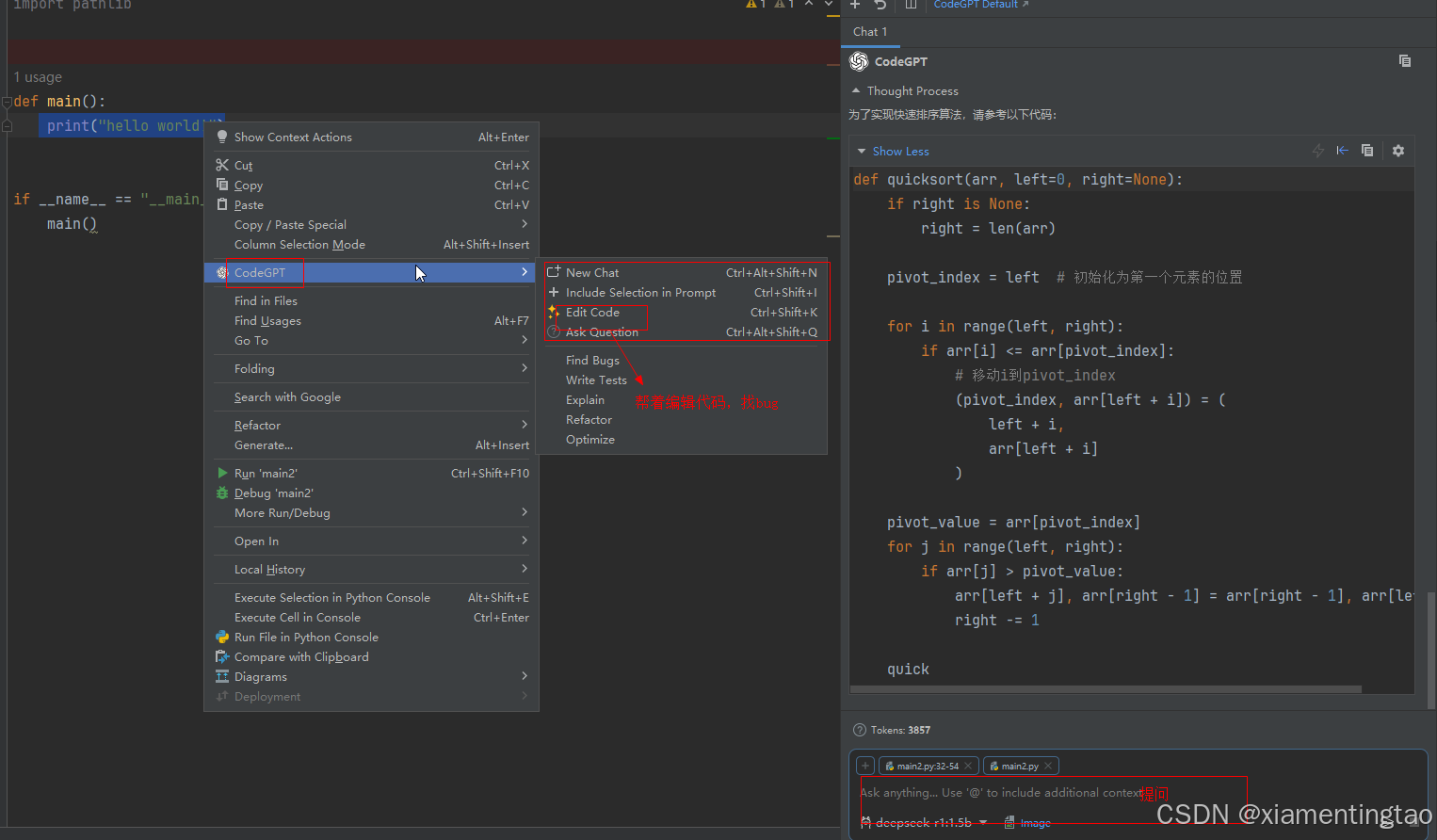
PyCharm接入本地部署DeepSeek 实现AI编程!【支持windows与linux】
今天尝试在pycharm上接入了本地部署的deepseek,实现了AI编程,体验还是很棒的。下面详细叙述整个安装过程。 本次搭建的框架组合是 DeepSeek-r1:1.5b/7b Pycharm专业版或者社区版 Proxy AI(CodeGPT) 首先了解不同版本的deepsee…...

深入解析SQL Server高级SQL技巧
SQL Server 是一种功能强大的关系型数据库管理系统,广泛应用于各种数据驱动的应用程序中。在开发过程中,掌握一些高级SQL技巧,不仅能提高查询性能,还能优化开发效率。这篇文章将全面深入地探讨SQL Server中的一些高级技巧…...

PyCharm怎么集成DeepSeek
PyCharm怎么集成DeepSeek 在PyCharm中集成DeepSeek等大语言模型(LLM)可以借助一些插件或通过代码调用API的方式实现,以下为你详细介绍两种方法: 方法一:使用JetBrains AI插件(若支持DeepSeek) JetBrains推出了AI插件来集成大语言模型,不过截至2024年7月,官方插件主要…...

Hive之正则表达式RLIKE详解及示例
目录 一、RLIKE 语法及核心特性 1. 基本语法 2. 核心特性 二、常见业务场景及示例 场景1:过滤包含特定模式的日志(如错误日志) 场景2:验证字段格式(如邮箱、手机号) 场景3:提取复杂文本中…...

fluent-ffmpeg 依赖详解
fluent-ffmpeg 是一个用于在 Node.js 环境中与 FFmpeg 进行交互的强大库,它提供了流畅的 API 来执行各种音视频处理任务,如转码、剪辑、合并等。 一、安装 npm install fluent-ffmpeg二、基本使用 要使用 fluent-ffmpeg,首先需要确保系统中…...

【定昌Linux系统】部署了java程序,设置开启启动
将代码上传到相应的目录,并且配置了一个.sh的启动脚本文件 文件内容: #!/bin/bash# 指定JAR文件的路径(如果JAR文件在当前目录,可以直接使用文件名) JAR_FILE"/usr/local/java/xs_luruan_client/lib/xs_luruan_…...

Java零基础入门笔记:(7)异常
前言 本笔记是学习狂神的java教程,建议配合视频,学习体验更佳。 【狂神说Java】Java零基础学习视频通俗易懂_哔哩哔哩_bilibili 第1-2章:Java零基础入门笔记:(1-2)入门(简介、基础知识)-CSDN博客 第3章…...

【字符串】最长公共前缀 最长回文子串
文章目录 14. 最长公共前缀解题思路:模拟5. 最长回文子串解题思路一:动态规划解题思路二:中心扩散法 14. 最长公共前缀 14. 最长公共前缀 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符…...