机器学习的起点:线性回归Linear Regression
机器学习的起点:线性回归Linear Regression
作为机器学习的起点,线性回归是理解算法逻辑的绝佳入口。我们从定义、评估方法、应用场景到局限性,用生活化的案例和数学直觉为你构建知识框架。
回归算法
一、线性回归的定义与核心原理
定义:线性回归是一种通过线性方程(如Y = AX + B)建立自变量(X)与因变量(Y)关系的统计方法。
-
数学表达:简单线性回归的公式为
y = β 0 + β 1 x + ϵ y = \beta_0 + \beta_1 x + \epsilon y=β0+β1x+ϵ
其中:- β 0 \beta_0 β0是截距(当X=0时Y的起点)
- β 1 \beta_1 β1是斜率(X每增加1单位,Y的平均变化量)
- ϵ \epsilon ϵ是误差项(代表无法用线性关系解释的随机波动)
直观理解:想象在散点图上找一条“最佳直线”,让所有数据点到这条直线的垂直距离之和最小。这条直线代表了变量间的整体趋势,例如身高与体重的关系、学习时间与考试成绩的关联等。
二、如何评估模型训练效果?
线性回归的目标是找到最优的 β 0 \beta_0 β0和 β 1 \beta_1 β1,使得预测值与真实值的误差最小
常用的评估指标是平方残差和(Residual Sum of Squares, RSS)或均方误差(MSE):
RSS = ∑ i = 1 n ( y i − y ^ i ) 2 \text{RSS} = \sum_{i=1}^n (y_i - \hat{y}_i)^2 RSS=i=1∑n(yi−y^i)2
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
为什么用平方?
- 避免正负误差相互抵消(如+3和-3的总误差为0,但平方和为18)。
- 对大误差更敏感,模型会更努力减少明显偏离的点(但这也意味着对异常值敏感)。
延伸指标:
- R²(决定系数):衡量模型解释数据变动的能力,范围0~1,越接近1拟合越好。
例如,若R²=0.8,说明模型能解释80%的Y值变化。
三、线性回归的应用场景
线性回归的预测能力在多个领域大放异彩,以下是典型应用案例:
-
排队问题
- 场景:预测新加入者的排队位置。
- 逻辑:假设排队时间与人数呈线性关系,若当前排队人数为X,每人的平均处理时间为斜率β₁,则可预测新人的等待时间Y。
-
身高与体重的关系
- 场景:已知某人身高(X),预测其体重(Y)。
- 模型:通过大量样本数据拟合Y = β₀ + β₁X,例如β₁=0.7表示身高每增加1cm,体重平均增加0.7kg。
-
人口与GDP预测
- 场景:分析某地区人口(X)与经济规模(Y)的关系。
- 扩展:若数据包含多个变量(如教育水平、资源储量),可升级为多元线性回归:
Y = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β n X n Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \cdots + \beta_nX_n Y=β0+β1X1+β2X2+⋯+βnXn
例如,GDP可能同时与人口、工业产值相关。
四、线性回归的局限性
尽管简单高效,线性回归并非万能,其核心问题包括:
-
无法捕捉非线性关系
- 例子:若数据呈现抛物线分布(如温度与冰淇淋销量的关系),强行用直线拟合会导致预测偏差。
- 解决方案:引入多项式回归(如 Y = β 0 + β 1 X + β 2 X 2 Y = \beta_0 + \beta_1X + \beta_2X^2 Y=β0+β1X+β2X2)或使用决策树等非线性模型。
-
对异常值敏感
- 例子:若数据中存在极端值(如身高2.5米的人),会显著拉偏拟合直线的斜率。
- 解决方案:清洗数据或使用鲁棒回归(如Huber损失函数)。
-
多重共线性问题
- 场景:在多元回归中,若自变量高度相关(如“房间数”和“房屋面积”),会导致模型参数不稳定。
- 解决方案:剔除冗余变量或使用正则化技术(如岭回归)。
五、案例
通过 scikit-learn 练习线性回归是一个绝佳的实践方式!
以下是分步指南,涵盖数据生成、模型训练、评估、可视化以及应对局限性的解决方案:
1. 环境准备
确保安装以下库:
pip install numpy matplotlib scikit-learn
2. 基础线性回归(单变量)
生成模拟数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score# 生成数据:y = 2x + 5 + 噪声
np.random.seed(42)
X = np.random.rand(100, 1) * 10 # 生成0~10之间的100个随机数
y = 2 * X + 5 + np.random.randn(100, 1) * 2 # 添加高斯噪声# 可视化数据
plt.scatter(X, y, alpha=0.7, label='真实数据')
plt.xlabel("X (自变量)")
plt.ylabel("y (因变量)")
plt.title("线性回归示例数据")
plt.show()
训练模型并预测
# 创建模型并训练
model = LinearRegression()
model.fit(X, y)# 查看参数
print(f"截距 (β0): {model.intercept_[0]:.2f}")
print(f"斜率 (β1): {model.coef_[0][0]:.2f}")# 预测新数据
X_new = np.array([[2.5], [7.0]]) # 预测X=2.5和X=7.0时的y值
y_pred = model.predict(X_new)
print(f"预测值: {y_pred.flatten()}")
评估与可视化
# 计算评估指标
y_pred_all = model.predict(X)
mse = mean_squared_error(y, y_pred_all)
r2 = r2_score(y, y_pred_all)
print(f"MSE: {mse:.2f}, R²: {r2:.2f}")# 可视化拟合直线
plt.scatter(X, y, alpha=0.7, label='真实数据')
plt.plot(X, y_pred_all, color='red', label='拟合直线')
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.title("线性回归拟合结果")
plt.show()
输出结果:
线性回归示例数据:

线性回归拟合结果

控制台输出结果
截距 (β0): 5.43
斜率 (β1): 1.91
预测值: [10.2003057 18.7865098]
MSE: 3.23, R²: 0.91
3. 多元线性回归(多变量)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split# 加载数据集(这里以加州房价为例)
data = fetch_california_housing()
X = data.data # 多个特征(如收入、房龄等)
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)# 评估测试集
y_pred = model.predict(X_test)
print(f"MSE: {mean_squared_error(y_test, y_pred):.2f}")
print(f"R²: {r2_score(y_test, y_pred):.2f}")# 查看特征重要性(系数)
feature_names = data.feature_names
for name, coef in zip(feature_names, model.coef_):print(f"{name}: {coef:.2f}")
4. 应对线性回归的局限性
问题1:非线性关系 → 多项式回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号from sklearn.preprocessing import PolynomialFeatures# 生成非线性数据(抛物线)
np.random.seed(42)
X = np.linspace(-3, 3, 100).reshape(-1, 1)
y = 0.5 * X**2 + X + 2 + np.random.randn(100, 1) * 0.5# 将特征转换为多项式(如X²)
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X)# 训练多项式回归模型
model = LinearRegression()
model.fit(X_poly, y)# 预测并可视化
X_test = np.linspace(-3, 3, 100).reshape(-1, 1)
X_test_poly = poly.transform(X_test)
y_pred = model.predict(X_test_poly)plt.scatter(X, y, alpha=0.7, label='真实数据')
plt.plot(X_test, y_pred, color='red', label='多项式回归')
plt.legend()
plt.show()
输出结果:

问题2:异常值 → 鲁棒回归(Huber损失)
# 异常值 → 鲁棒回归(Huber损失)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号from sklearn.linear_model import HuberRegressor# 生成带异常值的数据
X = np.random.rand(50, 1) * 10
y = 3 * X + 5 + np.random.randn(50, 1) * 2
y[45:] += 30 # 添加异常值# 对比普通线性回归和Huber回归
model_linear = LinearRegression()
model_linear.fit(X, y)model_huber = HuberRegressor()
model_huber.fit(X, y.ravel()) # HuberRegressor需要y为一维数组# 可视化对比
X_test = np.linspace(0, 10, 100).reshape(-1, 1)
y_pred_linear = model_linear.predict(X_test)
y_pred_huber = model_huber.predict(X_test)plt.scatter(X, y, alpha=0.7, label='数据(含异常值)')
plt.plot(X_test, y_pred_linear, color='red', label='普通线性回归')
plt.plot(X_test, y_pred_huber, color='green', label='Huber回归')
plt.legend()
plt.show()
输出结果:

问题3:多重共线性 → 岭回归
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler# 生成高共线性数据(两个强相关特征)
np.random.seed(42)
X1 = np.random.rand(100, 1) * 10
X2 = X1 + np.random.randn(100, 1) * 0.1 # X2与X1高度相关
X = np.hstack([X1, X2])
y = 2 * X1 + 3 * X2 + 5 + np.random.randn(100, 1) * 2# 标准化数据(岭回归对尺度敏感)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 对比普通线性回归和岭回归
model_linear = LinearRegression()
model_linear.fit(X_scaled, y)model_ridge = Ridge(alpha=10) # alpha是正则化强度
model_ridge.fit(X_scaled, y)print("普通线性回归系数:", model_linear.coef_)
print("岭回归系数:", model_ridge.coef_)
输出结果:

参考文献视频:点击跳转
相关文章:
机器学习的起点:线性回归Linear Regression
机器学习的起点:线性回归Linear Regression 作为机器学习的起点,线性回归是理解算法逻辑的绝佳入口。我们从定义、评估方法、应用场景到局限性,用生活化的案例和数学直觉为你构建知识框架。 回归算法 一、线性回归的定义与核心原理 定义&a…...

2024贵州大学计算机考研复试上机真题
历年贵州大学计算机考研复试上机真题 2024贵州大学计算机考研复试上机真题 2023贵州大学计算机考研复试上机真题 贵州大学计算机考研复试上机真题 在线 oj 测评:https://app2098.acapp.acwing.com.cn/problem/list/ 字符串翻转 题目描述 给定一个字符串…...

17、什么是智能指针,C++有哪几种智能指针【高频】
智能指针其实不是指针,而是一个(模板)类,用来存储指向某块资源的指针,并自动释放这块资源,从而解决内存泄漏问题。主要有以下四种: auto_ptr 它的思想就是当当一个指针对象赋值给另一个指针对…...
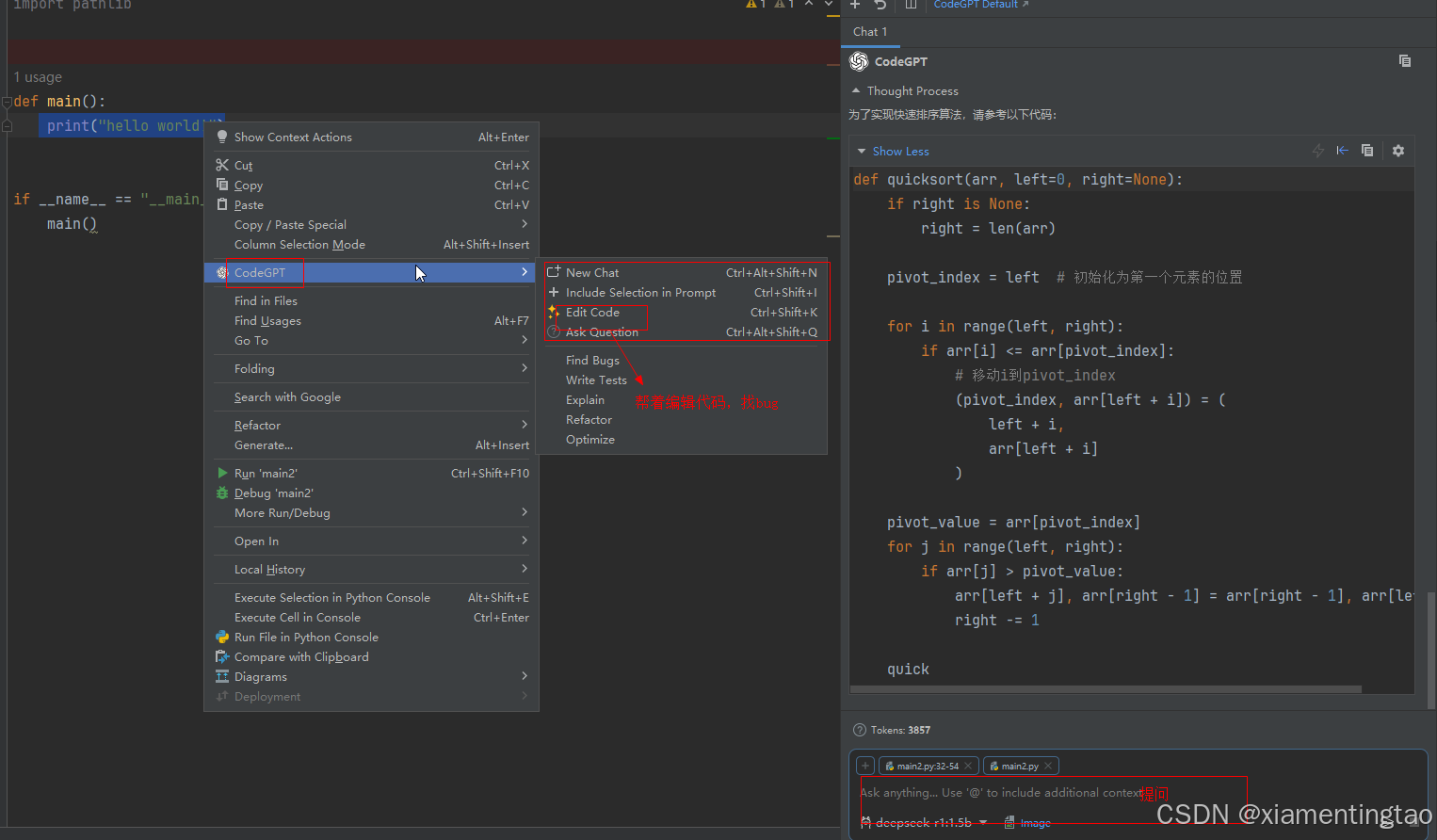
PyCharm接入本地部署DeepSeek 实现AI编程!【支持windows与linux】
今天尝试在pycharm上接入了本地部署的deepseek,实现了AI编程,体验还是很棒的。下面详细叙述整个安装过程。 本次搭建的框架组合是 DeepSeek-r1:1.5b/7b Pycharm专业版或者社区版 Proxy AI(CodeGPT) 首先了解不同版本的deepsee…...

深入解析SQL Server高级SQL技巧
SQL Server 是一种功能强大的关系型数据库管理系统,广泛应用于各种数据驱动的应用程序中。在开发过程中,掌握一些高级SQL技巧,不仅能提高查询性能,还能优化开发效率。这篇文章将全面深入地探讨SQL Server中的一些高级技巧…...

PyCharm怎么集成DeepSeek
PyCharm怎么集成DeepSeek 在PyCharm中集成DeepSeek等大语言模型(LLM)可以借助一些插件或通过代码调用API的方式实现,以下为你详细介绍两种方法: 方法一:使用JetBrains AI插件(若支持DeepSeek) JetBrains推出了AI插件来集成大语言模型,不过截至2024年7月,官方插件主要…...

Hive之正则表达式RLIKE详解及示例
目录 一、RLIKE 语法及核心特性 1. 基本语法 2. 核心特性 二、常见业务场景及示例 场景1:过滤包含特定模式的日志(如错误日志) 场景2:验证字段格式(如邮箱、手机号) 场景3:提取复杂文本中…...

fluent-ffmpeg 依赖详解
fluent-ffmpeg 是一个用于在 Node.js 环境中与 FFmpeg 进行交互的强大库,它提供了流畅的 API 来执行各种音视频处理任务,如转码、剪辑、合并等。 一、安装 npm install fluent-ffmpeg二、基本使用 要使用 fluent-ffmpeg,首先需要确保系统中…...

【定昌Linux系统】部署了java程序,设置开启启动
将代码上传到相应的目录,并且配置了一个.sh的启动脚本文件 文件内容: #!/bin/bash# 指定JAR文件的路径(如果JAR文件在当前目录,可以直接使用文件名) JAR_FILE"/usr/local/java/xs_luruan_client/lib/xs_luruan_…...

Java零基础入门笔记:(7)异常
前言 本笔记是学习狂神的java教程,建议配合视频,学习体验更佳。 【狂神说Java】Java零基础学习视频通俗易懂_哔哩哔哩_bilibili 第1-2章:Java零基础入门笔记:(1-2)入门(简介、基础知识)-CSDN博客 第3章…...

【字符串】最长公共前缀 最长回文子串
文章目录 14. 最长公共前缀解题思路:模拟5. 最长回文子串解题思路一:动态规划解题思路二:中心扩散法 14. 最长公共前缀 14. 最长公共前缀 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符…...

【软路由】ImmortalWrt 编译指南:从入门到精通
对于喜欢折腾路由器,追求极致性能和定制化的玩家来说,OpenWrt 无疑是一个理想的选择。而在众多 OpenWrt 衍生版本中,ImmortalWrt 以其更活跃的社区、更激进的特性更新和对新硬件的支持而备受关注。 本文将带你深入了解 ImmortalWrt࿰…...

react 中,使用antd layout布局中的sider 做sider的展开和收起功能
一 话不多说,先展示效果: 展开时: 收起时: 二、实现代码如下 react 文件 import React, {useState} from react; import {Layout} from antd; import styles from "./index.module.less"; // 这个是样式文件&#…...

easyExcel使用案例有代码
easyExcel 入门,完成web的excel文件创建和导出 easyExcel官网 EasyExcel 的主要特点如下: 1、高性能:EasyExcel 采用了异步导入导出的方式,并且底层使用 NIO 技术实现,使得其在导入导出大数据量时的性能非常高效。 2、易于使…...

CPU、SOC、MPU、MCU--详细分析四者的区别
一、CPU 与SOC的区别 1.CPU 对于电脑,我们经常提到,处理器,内存,显卡,硬盘四大部分可以组成一个基本的电脑。其中的处理器——Central Processing Unit(中央处理器)。CPU是一台计算机的运算核…...

机器学习:监督学习、无监督学习和强化学习
机器学习(Machine Learning, ML)是人工智能(AI)的一个分支,它使计算机能够从数据中学习,并在没有明确编程的情况下执行任务。机器学习的核心思想是使用算法分析数据,识别模式,并做出…...

SpringBoot项目注入 traceId 来追踪整个请求的日志链路
SpringBoot项目注入 traceId 来追踪整个请求的日志链路,有了 traceId, 我们在排查问题的时候,可以迅速根据 traceId 查找到相关请求的日志,特别是在生产环境的时候,用户可能只提供一个错误截图,我们作为开发…...

苹果廉价机型 iPhone 16e 影像系统深度解析
【人像拍摄差异】 尽管iPhone 16e支持后期焦点调整功能,但用户无法像iPhone 16系列那样通过点击屏幕实时切换拍摄主体。前置摄像头同样缺失人像深度控制功能,不过TrueTone原彩闪光灯系统在前后摄均有保留。 很多人都高估了 iPhone 的安全性,查…...

视觉图像坐标转换
1. 透镜成像 相机的镜头系统将三维场景中的光线聚焦到一个平面(即传感器)。这个过程可以用小孔成像模型来近似描述,尽管实际相机使用复杂的透镜系统来减少畸变和提高成像质量。 小孔成像模型: 假设有一个理想的小孔,…...

汽车电子电控软件开发中因复杂度提升导致的架构恶化问题
针对汽车电子电控软件开发中因复杂度提升导致的架构恶化问题,建议从以下方向进行架构优化和开发流程升级,以提升灵活性、可维护性和扩展性: 一、架构设计与模块化优化 分层架构与模块解耦 采用AUTOSAR标准的分层架构(应用层、运行…...

2024年第十五届蓝桥杯大赛软件赛省赛Python大学A组真题解析《更新中》
文章目录 试题A: 拼正方形(本题总分:5 分)解析答案试题B: 召唤数学精灵(本题总分:5 分)解析答案试题C: 数字诗意解析答案试题D:回文数组试题A: 拼正方形(本题总分:5 分) 【问题描述】 小蓝正在玩拼图游戏,他有7385137888721 个2 2 的方块和10470245 个1 1 的方块,他需…...

脚本无法获取响应主体(原因:CORS Missing Allow Credentials)
背景: 前端的端口号8080,后端8000。需在前端向后端传一个参数,让后端访问数据库去检测此参数是否出现过。涉及跨域请求,一直有这个bug是404文件找不到。 在修改过程当中不小心删除了一段代码,出现了这个bug࿰…...

leetcode第39题组合总和
原题出于leetcode第39题https://leetcode.cn/problems/combination-sum/description/题目如下: 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以…...

在 macOS 系统上安装 kubectl
在 macOS 系统上安装 kubectl 官网:https://kubernetes.io/zh-cn/docs/tasks/tools/install-kubectl-macos/ 用 Homebrew 在 macOS 系统上安装 如果你是 macOS 系统,且用的是 Homebrew 包管理工具, 则可以用 Homebrew 安装 kubectl。 运行…...

SQLark 数据迁移|断点续迁已上线(Oracle-达梦)
数据迁移是 SQLark 最受企业和个人用户欢迎的功能之一,截止目前已帮助政府、金融、能源、通信等 50 家单位完成从 Oracle、MySQL 到达梦的全量迁移,自动化迁移成功率达 96% 以上。 在 Oracle 到达梦数据库迁移过程中,SQLark V3.3 新增 断点续…...

Element Plus中el-tree点击的节点字体变色加粗
el-tree标签设置 <el-tree class"tree":data"treeData":default-expand-all"true":highlight-current"true"node-click"onTreeNodeClick"><!-- 自定义节点内容,点击的节点字体变色加粗 --><!-- 动…...

vmware安装firepower ftd和fmc
在vmware虚拟机中安装cisco firepower下一代防火墙firepower threat defence(ftd)和管理中心firepower management center(fmc)。 由于没有cisco官网下载账号,无法下载其中镜像。使用eveng模拟器中的ftd和fmc虚拟镜像…...

计算机毕业设计SpringBoot+Vue.js医院资源管理系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

[含文档+PPT+源码等]精品基于Python实现的微信小程序的乡村医疗咨询系统
基于Python实现的微信小程序的乡村医疗咨询系统背景,可以从以下几个方面进行阐述: 一、社会背景 医疗资源分布不均:在我国,城乡医疗资源分布不均是一个长期存在的问题。乡村地区由于地理位置偏远、经济条件有限,往往…...

Python实现GO鹅优化算法优化BP神经网络回归模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后关注获取。 1.项目背景 传统BP神经网络的局限性:BP(Back Propagation)神经网络作为一种…...