Redis Cluster 详解
Redis Cluster 详解
1. 为什么需要 Redis Cluster?
Redis 作为一个高性能的内存数据库,在单机模式下可能会遇到以下问题:
- 单机容量受限:Redis 是基于内存存储的,单机的内存资源有限,单实例的 Redis 只能存储有限的数据。
- 单点故障(SPOF):单机 Redis 宕机后,所有缓存数据都无法访问,影响业务可用性。
- 性能瓶颈:单机 Redis 受 CPU 和 I/O 限制,无法支撑高并发的访问需求。
- 扩展性差:单机模式不支持水平扩展,无法通过增加机器来提高存储和计算能力。
Redis Cluster(集群模式) 是 Redis 官方提供的分布式解决方案,主要用于解决以上问题。
2. Redis Cluster 解决了什么问题?有什么优势?
Redis Cluster 解决了以下问题:
- 数据分片存储,突破单机限制
- 通过 哈希槽(hash slot)+ 多节点 的方式,将数据存储到多个 Redis 实例中,实现水平扩展。
- 解决了单机存储受限的问题。
- 无中心化架构,避免单点故障
- 传统的 Redis Sentinel 模式存在 主从架构 + 哨兵管理,但仍然有中心节点。
- Redis Cluster 去中心化,所有节点都存储集群信息,任何节点都可以提供集群状态。
- 解决了单点故障的问题。
- 主从复制 + 自动故障转移
- Redis Cluster 采用主从架构,每个 Master 可以有多个 Slave 备份。
- 如果某个 Master 宕机,Redis Cluster 会自动提升 Slave 为新的 Master,保证集群可用性。
- 动态扩展,支持水平扩容
- Redis Cluster 允许 动态添加 / 删除节点,可以在运行时扩展 Redis 集群,而不会影响业务。
- 解决了 Redis 单机模式扩展性差的问题。
Redis Cluster 的核心优势
| 特点 | Redis Cluster 解决方案 |
|---|---|
| 存储受限 | 数据分片存储,支持多个节点 |
| 单点故障 | 无中心化架构,主从复制 |
| 故障恢复 | 自动故障转移 |
| 性能瓶颈 | 多主架构,支持并行读写 |
| 扩展性 | 可动态扩容 / 缩容 |
3. Redis Cluster 是如何分片的?
Redis Cluster 采用 哈希槽(hash slot)+ 数据分片 机制进行数据分片:
-
整个集群有 16384 个哈希槽(slot)。
-
每个 Key 通过哈希算法分配到某个哈希槽:
slot = CRC16(key) % 16384CRC16是一种高效的哈希计算方法。
-
哈希槽分布到不同的 Redis 节点:
-
例如:3 个 Redis 节点,每个节点存储部分哈希槽:
节点 A:0 - 5460 节点 B:5461 - 10922 节点 C:10923 - 16383 -
如果有新的节点加入,Redis Cluster 会重新分配哈希槽。
-
4. 为什么 Redis Cluster 的哈希槽是 16384 个?
Redis Cluster 选择 16384 作为固定的哈希槽数量,主要基于以下考虑:
- 兼容 CRC16 计算
- Redis 使用
CRC16算法计算 Key 的哈希值,并使用 模运算(% 16384) 确定哈希槽。 - 16384(2¹⁴)是 2 的幂,计算高效。
- Redis 使用
- 负载均衡
- 16384 个槽足够均匀地分配到多个节点,避免热点数据集中在某个节点。
- 迁移成本低
- 槽的数量适中,在节点增加/删除时,可以快速迁移哈希槽,减少数据重新分布的影响。
- 适用于大规模集群
- 16384 个槽能支持数百个 Redis 节点,适用于不同规模的集群扩展。
5. 如何确定给定 key 应该分布到哪个哈希槽中?
Redis Cluster 通过 CRC16 哈希算法 计算 key 的哈希槽:
slot = CRC16(key) % 16384
示例:
import crcmodcrc16 = crcmod.predefined.Crc('crc-16')
crc16.update(b'mykey')
slot = crc16.crcValue % 16384
print(slot) # 输出哈希槽号
Redis 客户端会计算 Key 的哈希槽,并直接请求对应的 Redis 节点。
6. Redis Cluster 支持重新分配哈希槽吗?
是的,Redis Cluster 允许动态调整哈希槽分配,以支持扩容或缩容:
- 增加新节点:
- 新增节点后,部分哈希槽会从已有 Master 迁移到新节点。
- 使用
redis-cli --cluster reshard进行槽位重新分配。
- 删除节点:
- 删除节点时,节点上的哈希槽会迁移到其他节点。
哈希槽迁移过程:
- CLUSTER SETSLOT IMPORTING
- CLUSTER SETSLOT MIGRATING
- 数据同步
- 更新哈希槽信息
7. Redis Cluster 扩容/缩容期间可以提供服务吗?
可以!Redis Cluster 支持在线扩容/缩容,在数据迁移过程中仍然可以提供服务:
- 客户端访问时,可能会遇到 MOVED 重定向
- 例如:客户端请求 Key 时,如果 Key 的哈希槽迁移到了新的节点,返回
MOVED <slot> <new-node-ip>,客户端会重新请求正确的节点。
- 例如:客户端请求 Key 时,如果 Key 的哈希槽迁移到了新的节点,返回
- 数据在后台迁移,不影响正常读写
- Redis Cluster 采用 渐进式迁移,不会一次性移动所有数据,而是逐步将哈希槽数据转移到新节点。
8. Redis Cluster 中的节点是如何通信的?
Redis Cluster 采用 Gossip 协议 进行节点间通信,保证集群状态一致:
- PING:定期发送心跳检测其他节点的状态。
- PONG:响应
PING,并附带本节点的状态信息。 - MEET:新节点加入集群时,使用
MEET命令。 - FAIL:如果多数节点判定某个 Master 故障,则广播
FAIL信息,触发故障转移。
每个 Redis Cluster 节点都维护整个集群的拓扑信息,即便某些节点故障,集群仍然可以继续运行。
9. Redis Cluster 缓存的数据量太大怎么办?
当 Redis Cluster 的数据量过大时,可以采取以下措施:
- 水平扩展(增加节点):增加新的 Redis 节点,并重新分配哈希槽,使新节点分担数据存储压力。
- 数据淘汰策略:使用
maxmemory-policy进行数据淘汰,如volatile-lru、allkeys-lru等。 - 数据压缩:对于字符串、JSON 数据,可以使用 Snappy、Gzip 等方式进行压缩,减少存储占用。
- 冷热数据分层:将热数据存入 Redis,冷数据存入 MySQL、MongoDB 等持久化存储中。
- 使用 BigKey 拆分:避免存储大 key(如超大列表、集合、哈希),可以拆分为多个小 key 存储。
10. Redis Cluster 的基本架构
一个典型的 Redis Cluster 由多个 Redis 实例组成,每个实例可以是主节点(Master)或从节点(Slave):
- 主节点(Master):负责存储数据并处理客户端请求,每个 Master 管理一部分哈希槽。
- 从节点(Slave):作为 Master 的备份,提供高可用性,Master 宕机时从节点可自动提升为 Master。
- 客户端(Client):连接 Redis Cluster,向不同的 Master 发送请求,并根据哈希槽计算数据存储位置。
Redis Cluster 默认使用 无中心化架构,每个节点既存储数据,又维护整个集群的元数据(比如槽位信息、其他节点状态等)。
总结
| 问题 | 解答 |
|---|---|
| 为什么需要 Redis Cluster? | 解决单机存储、可用性、性能瓶颈问题。 |
| Redis Cluster 如何分片? | 采用 16384 个哈希槽,通过 CRC16(Key) % 16384 计算槽位,并分布到不同节点。 |
| 为什么是 16384 个哈希槽? | 兼顾计算效率、负载均衡、扩展性和数据迁移成本。 |
| Redis Cluster 能动态扩容吗? | 支持在线扩容/缩容,迁移期间不影响业务。 |
| Redis Cluster 节点如何通信? | 采用 Gossip 协议,进行 PING/PONG 心跳检测,支持自动故障转移。 |
| 数据量太大怎么办? | 采用水平扩展、数据淘汰策略、数据压缩、冷热分层等优化方案。 |
| 基本架构? | 由多个 Master 节点和 Slave 节点组成,每个 Master 负责一部分哈希槽。 |
Redis Cluster 通过数据分片 + 无中心化架构 + 自动故障恢复,实现了高可用、可扩展的分布式 Redis! 🚀
扩展阅读
1. Redis Cluster 的哈希槽为什么是 16384?
Redis Cluster 采用 16384 个哈希槽(slot)来进行数据分片和管理,主要基于以下几个原因:
(1) 兼顾性能与灵活性
- 太少的哈希槽:如果哈希槽数量太少,例如 1024,数据分布会很粗糙,负载均衡效果不佳。
- 太多的哈希槽:如果哈希槽数量过多(如 10^6 级别),每次集群管理和迁移操作都会涉及大量计算,增加开销。
16384 是一个合理的折中方案,它既能保证数据分布的均衡性,又能在扩展和迁移时保持较低的计算和存储成本。
(2) CRC16 计算的高效性
Redis Cluster 采用 CRC16(循环冗余校验)算法计算哈希槽:
Slot = CRC16(Key) % 16384
CRC16 是一种高效的哈希计算方式,16384(2¹⁴)是 2 的幂,可以通过位运算高效计算哈希槽。
(3) 分片和迁移的平衡
-
16384 个槽可以被
多个 Master 节点
平均分配。例如:
- 3 个 Master:每个 Master 约管理 5461 个槽(16384 ÷ 3)。
- 6 个 Master:每个 Master 约 2730 个槽(16384 ÷ 6)。
-
这样,扩容和数据迁移时,不会造成太大的数据重分布,迁移成本较低。
(4) 兼容性
Redis Cluster 设计时考虑到 多个 Redis 实例部署在多个服务器上,16384 适用于不同规模的集群:
- 小规模集群(3~6 个节点)→ 适量的槽可保证均衡分配。
- 大规模集群(数十个节点)→ 16384 个槽依然可以较好地分片。
2. 什么是 Gossip 协议?
(1) Gossip 协议的基本概念
Gossip 协议是一种 去中心化的分布式通信协议,用于 节点之间同步信息,类似于“八卦传播”:
- 每个节点只与部分其他节点通信,而不是全网广播。
- 信息在多个通信轮次后,逐步传播到整个集群。
Redis Cluster 采用 Gossip 协议 来管理节点状态,保持集群的可用性。
(2) Redis Cluster 中的 Gossip 协议
在 Redis Cluster 中,每个节点都会定期向部分节点 发送状态信息,以此来同步集群状态,确保各个节点了解彼此的情况。
Gossip 协议中的几种消息
- PING:节点定期向其他节点发送
PING消息,询问对方状态。 - PONG:收到
PING后,节点返回PONG作为响应,并附带自己的状态信息。 - MEET:新节点加入集群时,使用
MEET消息通知集群中的其他节点。 - FAIL:如果某个 Master 节点被大多数节点判定为不可用,整个集群会广播
FAIL消息,触发故障转移。
示例
假设 Redis Cluster 有 6 个节点:
A B C D E F
- A 发送 PING 给 B 和 C。
- B 发送 PING 给 D 和 E。
- C 发送 PING 给 F 和 A。
- 经过几轮传播后,所有节点都可以获取最新的集群状态。
(3) Gossip 协议的优点
- 去中心化:无中心服务器,避免单点故障。
- 高效传播:不像传统的全网广播,Gossip 只向部分节点发送信息,网络开销更小。
- 容错性强:即使部分节点故障,其他节点仍可继续传播信息,保证集群健康。
总结
| 问题 | 解答 |
|---|---|
| Redis Cluster 的哈希槽为什么是 16384? | 16384 是 2¹⁴,兼顾数据分片均衡、迁移效率、CRC16 计算高效性。 |
| Gossip 协议是什么? | 一种去中心化的分布式通信协议,Redis Cluster 通过 Gossip 进行节点状态同步。 |
| Gossip 协议在 Redis Cluster 中的作用? | 负责集群节点状态同步、故障检测(PING/PONG)、节点加入(MEET)、故障传播(FAIL)。 |
Gossip 让 Redis Cluster 实现了 去中心化管理、高效容错,结合 16384 哈希槽的设计,使得 Redis Cluster 既能 高效分片存储,又能 保证集群高可用!
相关文章:

Redis Cluster 详解
Redis Cluster 详解 1. 为什么需要 Redis Cluster? Redis 作为一个高性能的内存数据库,在单机模式下可能会遇到以下问题: 单机容量受限:Redis 是基于内存存储的,单机的内存资源有限,单实例的 Redis 只能…...

基于CNN的FashionMNIST数据集识别6——ResNet模型
前言 之前我们在cnn已经搞过VGG和GoogleNet模型了,这两种较深的模型出现了一些问题: 梯度传播问题 在反向传播过程中,梯度通过链式法则逐层传递。对于包含 L 层的网络,第 l 层的梯度计算为: 其中 a(k) 表示第 k层的…...

0323-B树、B+树
多叉树---->B树(磁盘)、B树 磁盘由多个盘片组成,每个盘片分为多个磁道和扇区。数据存储在这些扇区中,扇区之间通过指针链接,形成链式结构。 内存由连续的存储单元组成,每个单元有唯一地址,数…...

深度学习3-pytorch学习
深度学习3-pytorch学习 Tensor 定义与 PyTorch 操作 1. Tensor 定义: Tensor 是 PyTorch 中的数据结构,类似于 NumPy 数组。可以通过不同方式创建 tensor 对象: import torch# 定义一个 1D Tensor x1 torch.Tensor([3, 4])# 定义一个 Fl…...

【工作记录】F12查看接口信息及postman中使用
可参考 详细教程:如何从前端查看调用接口、传参及返回结果(附带图片案例)_f12查看接口及参数-CSDN博客 1、接口信息 接口基础知识2:http通信的组成_接口请求信息包括-CSDN博客 HTTP类型接口之请求&响应详解 - 三叔测试笔记…...

正则表达式-万能表达式
1、正则 正则表达式是一组由字母和符号组成的特殊文本, 它可以用来从文本中找 出满足你想要的格式的句子. {“basketId”: 0, “count”: 1, “prodId”: #prodId#, “shopId”: 1, “skuId”: #skuId#} #prodId# re相关的文章: https://www.cnblogs.com/Simple-S…...

2024年认证杯SPSSPRO杯数学建模B题(第二阶段)神经外科手术的定位与导航全过程文档及程序
2024年认证杯SPSSPRO杯数学建模 B题 神经外科手术的定位与导航 原题再现: 人的大脑结构非常复杂,内部交织密布着神经和血管,所以在大脑内做手术具有非常高的精细和复杂程度。例如神经外科的肿瘤切除手术或血肿清除手术,通常需要…...

Android 12系统源码_系统启动(二)Zygote进程
前言 Zygote(意为“受精卵”)是 Android 系统中的一个核心进程,负责 孵化(fork)应用进程,以优化应用启动速度和内存占用。它是 Android 系统启动后第一个由 init 进程启动的 Java 进程,后续所有…...

MOSN(Modular Open Smart Network)-05-MOSN 平滑升级原理解析
前言 大家好,我是老马。 sofastack 其实出来很久了,第一次应该是在 2022 年左右开始关注,但是一直没有深入研究。 最近想学习一下 SOFA 对于生态的设计和思考。 sofaboot 系列 SOFAStack-00-sofa 技术栈概览 MOSN(Modular O…...

Flink介绍与安装
Apache Flink是一个在有界数据流和无界数据流上进行有状态计算分布式处理引擎和框架。Flink 设计旨在所有常见的集群环境中运行,以任意规模和内存级速度执行计算。 一、主要特点和功能 1. 实时流处理: 低延迟: Flink 能够以亚秒级的延迟处理数据流,非常…...

【gradio】从零搭建知识库问答系统-Gradio+Ollama+Qwen2.5实现全流程
从零搭建大模型问答系统-GradioOllamaQwen2.5实现全流程(一) 前言一、界面设计(计划)二、模块设计1.登录模块2.注册模块3. 主界面模块4. 历史记录模块 三、相应的接口(前后端交互)四、实现前端界面的设计co…...

PowerBI,用度量值实现表格销售统计(含合计)的简单示例
假设我们有产品表 和销售表 我们想实现下面的效果 表格显示每个产品的信息,以及单个产品的总销量 有一个切片器能筛选各个门店的产品销量 还有一个卡片图显示所筛选条件下,所有产品的总销量 实现方法: 1.我们新建一个计算表,把…...

Mac 常用命令
一、文件操作(必知必会) 1. 快速导航 cd ~/Documents # 进入文档目录 cd .. # 返回上级目录 pwd # 显示当前路径 2. 文件管理 touch new_file.txt # 创建空文件 mkdir -p project/{src,docs} # 递归创建目录 cp …...

26考研——查找_树形查找_二叉排序树(BST)(7)
408答疑 文章目录 三、树形查找二叉排序树(BST)二叉排序树中结点值之间的关系二叉树形查找二叉排序树的查找过程示例 向二叉排序树中插入结点插入过程示例 构造二叉排序树的过程构造示例 二叉排序树中删除结点的操作情况一:被删除结点是叶结点…...

美摄科技开启智能汽车车内互动及娱乐解决方案2.0
在科技飞速发展的今天,汽车已不再仅仅是简单的代步工具,而是逐渐演变为集出行、娱乐、社交于一体的智能移动空间。美摄科技,作为前沿视觉技术与人工智能应用的领航者,凭借其卓越的技术实力和创新精神,携手汽车行业&…...

【行驶证识别】批量咕嘎OCR识别行驶证照片复印件图片里的文字信息保存表格或改名字,基于QT和腾讯云api_ocr的实现方式
项目背景 在许多业务场景中,如物流管理、车辆租赁、保险理赔等,常常需要处理大量的行驶证照片复印件。手动录入行驶证上的文字信息,像车主姓名、车辆型号、车牌号码等,不仅效率低下,还容易出现人为错误。借助 OCR(光学字符识别)技术,能够自动识别行驶证图片中的文字信…...

Vue-admin-template安装教程
#今天配置后台管理模板发现官方文档的镜像网站好像早失效了,自己稍稍总结了一下方法# 该项目环境需要node17及以下,如果npm install这一步报错可能是这个原因 git clone https://github.com/PanJiaChen/vue-admin-template.git cd vue-admin-template n…...

21.Excel自动化:如何使用 xlwings 进行编程
一 将Excel用作数据查看器 使用 xlwings 中的 view 函数。 1.导包 import datetime as dt import xlwings as xw import pandas as pd import numpy as np 2.view 函数 创建一个基于伪随机数的DataFrame,它有足够多的行,使得只有首尾几行会被显示。 df …...

LabVIEW FPGA与Windows平台数据滤波处理对比
LabVIEW在FPGA和Windows平台均可实现数据滤波处理,但两者的底层架构、资源限制、实时性及应用场景差异显著。FPGA侧重硬件级并行处理,适用于高实时性场景;Windows依赖软件算法,适合复杂数据处理与可视化。本文结合具体案例&#x…...

【NLP 48、大语言模型的神秘力量 —— ICL:in context learning】
目录 一、ICL的优势 1.传统做法 2.ICL做法 二、ICL的发展 三、ICL成因的两种看法 1.meta learning 2.Bayesian Inference 四、ICL要点 ① 语言模型的规模 ② 提示词prompt中提供的examples数量和顺序 ③ 提示词prompt的形式(format) 五、fine-tune VS I…...

vue 中渲染 markdown 格式的文本
文章目录 需求分析第一步:安装依赖第二步:创建 Markdown 渲染组件第三步,使用实例扩展功能1. 代码高亮:2. 自定义渲染规则:需求 渲染 markdown 格式的文本 分析 在Vue 3中实现Markdown渲染的常见方法。通常有两种方式:使用现有的Markdown解析库,或者自己编写解析器…...

工业4G路由器赋能智慧停车场高效管理
工业4G路由器作为智慧停车场管理系统通信核心,将停车场内的各个子系统连接起来,包括车牌识别系统、道闸控制系统、车位检测系统、收费系统以及监控系统等。通过4G网络,将这些系统采集到的数据传输到云端服务器或管理中心,实现信息…...
)
卡尔曼滤波入门(二)
核心思想 卡尔曼滤波的核心就是在不确定中寻找最优,那么怎么定义最优呢?答案是均方误差最小的,便是最优。 卡尔曼滤波本质上是一种动态系统状态估计器,它回答了这样一个问题: 如何从充满噪声的观测数据中,…...

企业如何平稳实现从Tableau到FineBI的信创迁移?
之前和大家分享了《如何将Tableau轻松迁移到Power BI》。但小编了解到,如今有些企业更愿意选择国产BI平台。为此,小编今天以Fine BI为例子,介绍如何从Tableau轻松、低成本地迁移到国产BI平台。 在信创政策全面推进的背景下,企业数…...

蓝桥与力扣刷题(蓝桥 蓝桥骑士)
题目:小明是蓝桥王国的骑士,他喜欢不断突破自我。 这天蓝桥国王给他安排了 N 个对手,他们的战力值分别为 a1,a2,...,an,且按顺序阻挡在小明的前方。对于这些对手小明可以选择挑战,也可以选择避战。 身为高傲的骑士&a…...
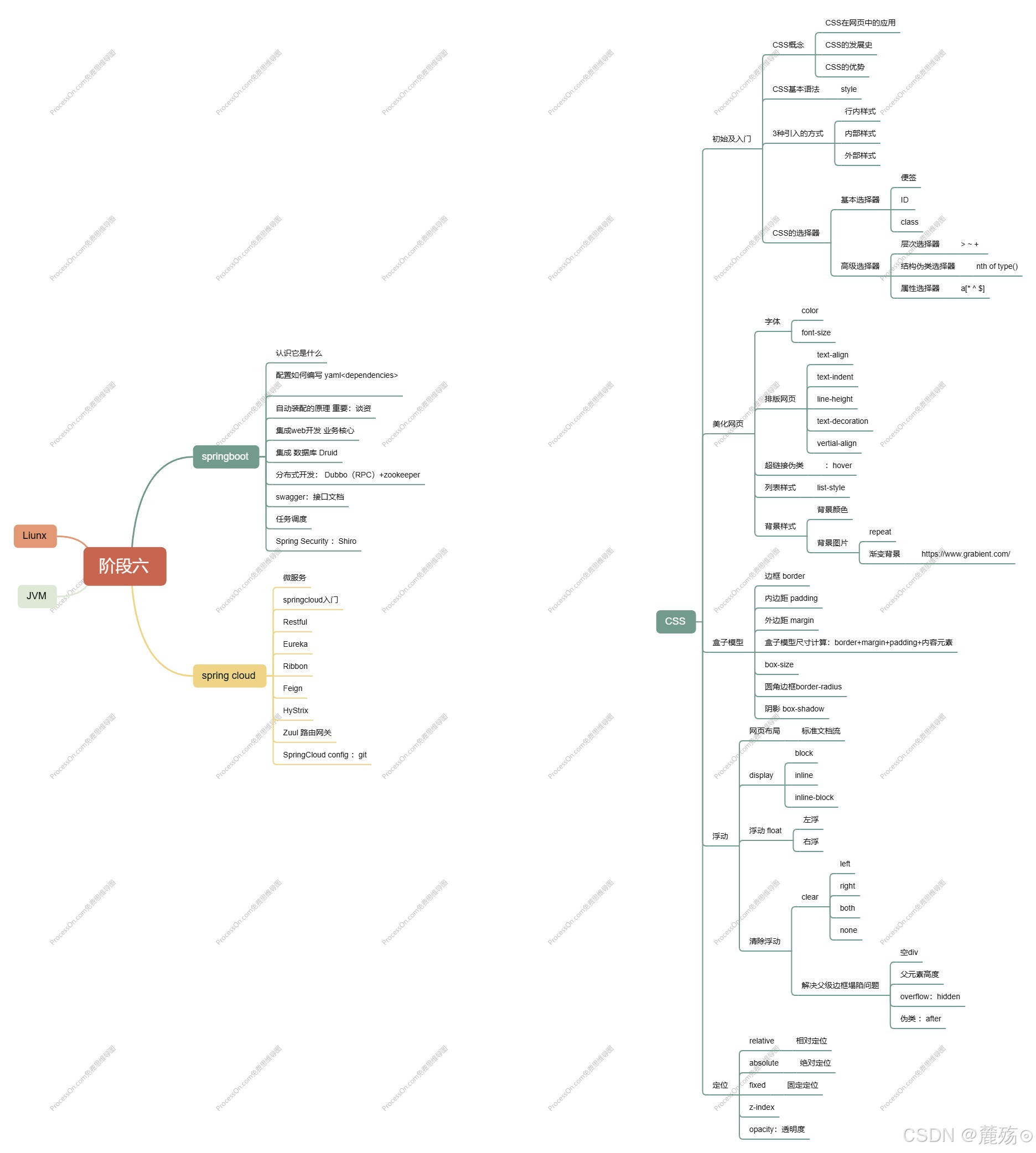
前端学习笔记--CSS
HTMLCSSJavaScript 》 结构 表现 交互 如何学习 1.CSS是什么 2.CSS怎么用? 3.CSS选择器(重点,难点) 4.美化网页(文字,阴影,超链接,列表,渐变。。。) 5…...

阶段一:Java基础语法
目标:掌握Java的基本语法,理解变量、数据类型、运算符、控制结构等。 1. Java开发环境搭建 安装JDK配置环境变量编写第一个Java程序 代码示例: // HelloWorld.java public class HelloWorld { // 定义类名为 HelloWorldpublic static vo…...

31天Python入门——第15天:日志记录
你好,我是安然无虞。 文章目录 日志记录python的日志记录模块创建日志处理程序并配置输出格式将日志内容输出到控制台将日志写入到文件 logging更简单的一种使用方式 日志记录 日志记录是一种重要的应用程序开发和维护技术, 它用于记录应用程序运行时的关键信息和…...
PyTorch张量简介)
深度学习框架PyTorch——从入门到精通(10)PyTorch张量简介
这部分是 PyTorch介绍——YouTube系列的内容,每一节都对应一个youtube视频。(可能跟之前的有一定的重复) 创建张量随机张量和种子张量形状张量数据类型 使用PyTorch张量进行数学与逻辑运算简单介绍——张量广播关于张量更多的数学操作原地修改…...

前端批量导入方式
webpack批量导入 webpack中使用 require.context 实现自动导入 const files require.context(./modules, false, /\.ts$/); const modules {}; files.keys().forEach((key) > {if (key ./index.ts) { return; }modules[key.replace(/(\.\/|\.ts)/g, )] files(key).def…...