Python中multiprocessing的使用详解
1.实现多进程
代码实现:
from multiprocessing import Process
import datetime
import timedef task01(name):current_time=datetime.datetime.now()start_time=current_time.strftime('%Y-%m-%d %H:%M:%S')+'.'+ "{:03d}".format(current_time.microsecond // 1000)print("{}开始执行时间: {}".format(name,start_time))time.sleep(5)current_time = datetime.datetime.now()end_time = current_time.strftime('%Y-%m-%d %H:%M:%S') + '.' + "{:03d}".format(current_time.microsecond // 1000)print("{}执行结束时间: {}".format(name,end_time))def task02(name):current_time=datetime.datetime.now()start_time = current_time.strftime('%Y-%m-%d %H:%M:%S')+'.'+ "{:03d}".format(current_time.microsecond // 1000)print("{}开始执行时间: {}".format(name, start_time))time.sleep(5)current_time = datetime.datetime.now()end_time = current_time.strftime('%Y-%m-%d %H:%M:%S')+'.'+ "{:03d}".format(current_time.microsecond // 1000)print("{}执行结束时间: {}".format(name, end_time))if __name__ == '__main__':##创建进程:target是进程要执行的方法, args是进程里要执行的方法的参数proc1 = Process(target=task01, args=('进程01',)) # 创建进程proc1proc2 = Process(target=task02, args=('进程02',)) # 创建进程proc2##启动进程proc1.start() # 启动进程proc1proc2.start() # 启动进程proc2print("进程内的方法未执行完,并行执行后面的代码")执行结果:

如果有些操作需要等进程内的方法执行完才能执行:使用join()

2.多进程池
上面我们是一个一个手动创建进程,我们还可以用Pool模块来替我们创建
Pool的常见方法:
apply():同步执行
apply_async():异步执行
close():等待所有进程结束后,才关闭进程池
terminate(): 立刻关闭进程池
join():主进程等待子进程执行完毕,必须在close()或 terminate()后调用
代码实现:
from multiprocessing import Pool
import datetime
import timedef task01(name):current_time=datetime.datetime.now()start_time=current_time.strftime('%Y-%m-%d %H:%M:%S')+'.'+ "{:03d}".format(current_time.microsecond // 1000)print("{}开始执行时间: {}".format(name,start_time))time.sleep(5)current_time = datetime.datetime.now()end_time = current_time.strftime('%Y-%m-%d %H:%M:%S') + '.' + "{:03d}".format(current_time.microsecond // 1000)print("{}执行结束时间: {}".format(name,end_time))def task02(name):current_time=datetime.datetime.now()start_time = current_time.strftime('%Y-%m-%d %H:%M:%S')+'.'+ "{:03d}".format(current_time.microsecond // 1000)print("{}开始执行时间: {}".format(name, start_time))time.sleep(5)current_time = datetime.datetime.now()end_time = current_time.strftime('%Y-%m-%d %H:%M:%S')+'.'+ "{:03d}".format(current_time.microsecond // 1000)print("{}执行结束时间: {}".format(name, end_time))if __name__ == '__main__':pool = Pool(processes=3) # 创建进程池,最大进程数为3func_dict = {'task01': '进程01', 'task02': '进程02'}for func_name, func_args in func_dict.items():pool.apply_async(eval(func_name), args=(func_args,)) # 异步执行进程print("进程内的方法未执行完,并行执行后面的代码")pool.close() # 关闭进程池pool.join() # 等待进程池中的所有进程执行完毕,必须在close()之后调用,必须调用执行结果:

3.多进程之间的通信
多进程之间通过安全队列和管道进行数据传递
Queue
Queu自身提供了函数put()和get()来完成数据的传递,put()往队列末尾添加数据,get()从队列的头部取出并删除一个数据。
代码实现:
from multiprocessing import Process,Queue'''定义函数01向队列里添加数据'''
def queue_add_data01(queue):for i in range(3):queue.put(i)print("向队列中添加数据:{}".format(i))'''定义函数02向队列里添加数据'''
def queue_add_data02(queue):for i in range(10,13):queue.put(i)print("向队列中添加数据:{}".format(i))print("========================")'''定义函数从队列里获取数据'''
def queue_get_data(queue):while not queue.empty():data=queue.get()print("从队列中获取数据:{}".format(data))if __name__ == '__main__':#创建队列queue = Queue()#创建进程producer_process01 = Process(target=queue_add_data01, args=(queue,))producer_process02 = Process(target=queue_add_data02, args=(queue,))consumer_process = Process(target=queue_get_data, args=(queue,))# 启动进程producer_process01.start()producer_process02.start()consumer_process.start()# 等待两个进程执行结束producer_process01.join()producer_process02.join()consumer_process.join()执行结果:

Pipe
Pipe实列化后返回两个对象,分别表示管道的发生端和接收端
代码实现:
from multiprocessing import Process,Pipe'''定义函数向管道中发送数据'''
def pipi_send_data(conn):for i in range(5):conn.send(i)print("向管道中发送数据:{}".format(i))print("===============================")'''定义函数从管道中接收数据'''
def pipi_receive_data(conn):while conn.poll():data=conn.recv()print("从管道中接收数据:{}".format(data))if __name__ == '__main__':# 创建管道send_conn, receive_conn = Pipe()# 创建两个进程,一个用于发送数据,一个用于接收数据sender_process = Process(target=pipi_send_data, args=(send_conn,))receiver_process = Process(target=pipi_receive_data, args=(receive_conn,))# 启动进程sender_process.start()receiver_process.start()# 等待两个进程执行结束sender_process.join()receiver_process.join()执行结果:

4.多进程数据共享
4.1 内存对象共享
进程间共享内存是一种高效的通信方式,它允许多个进程共享同一块内存区域。multiprocessing模块中提供了Value和Array类用来创建共享内存
Value
作用:创建一个可以在多个进程之间共享并可以进行修改的变量,这个共享的变量可以是整数、浮点数等基本数据类型
创建共享变量时有两个参数:数据类型、数据初始值,其中数据类型有:
i:整数
d:双精度浮点数
f:单精度浮点数
代码实现:
from multiprocessing import Process,Value##定义操作共享变量的方法
def shared_value(shared_val,name):print("初始值是:{}".format(shared_val.value))shared_val.value += 1print("{}操作后的值是:{}".format(name,shared_val.value))if __name__ == '__main__':##创建共享变量shared_val = Value('i', 0)##新建两个进程对共享变量进行操作process1 = Process(target=shared_value, args=(shared_val,"进程1"))process2 = Process(target=shared_value, args=(shared_val,"进程2"))##启动进程process1.start()process2.start()##等待进程执行结束process1.join()process2.join()执行结果:

Array
作用:用于创建允许多个进程共享和访问的共享数组
创建共享数组时有两个参数:数组元素类型、数组长度
代码实现:
from multiprocessing import Process,Array
import timedef shared_array_produce(shared_arr):for i in range(5):shared_arr[i] = i*2print("shared_array_produce操作后的数组是:{}".format(shared_arr[:]))def shared_array_consum(shared_arr):time.sleep(3) # 等待shared_array_produce操作print("shared_array_consum操作前数组的值是:{}".format(shared_arr[:]))for i in range(5):shared_arr[i] = shared_arr[i]*2print("shared_array_consum操作后的数组是:{}".format(shared_arr[:]))if __name__ == '__main__':##创建共享数组shared_arr = Array('i', 5) # i表示数组元素类型为整形,5表示数组长度##新建两个进程对共享变量进行操作process1 = Process(target=shared_array_produce, args=(shared_arr,))process2 = Process(target=shared_array_consum, args=(shared_arr,))##启动进程process1.start()process2.start()##等待进程执行结束process1.join()process2.join()执行结果:

4.2 全局变量共享
在 Python 的多进程环境中,全局变量在不同进程中并不会共享。为了在多进程中共享数据,需要使用 multiprocessing.Manager 中的共享数据结构,如 list、dict 等
没有使用Manage时:
import time
from multiprocessing import Processdef add_data(shared_list):for i in range(5):shared_list.append(i)print("add_data执行完后shared_list的值是:{}".format(shared_list))def use_data(shared_list):time.sleep(5)print("use_data使用前shared_list的值是:{}".format(shared_list))if __name__ == '__main__':# 定义一个全局变量shared_list =[]add_data_process = Process(target=add_data, args=(shared_list,))use_data_process = Process(target=use_data, args=(shared_list,))# 启动进程add_data_process.start()use_data_process.start()# 等待进程执行完毕add_data_process.join()use_data_process.join()
执行结果:

可以看到进程add_data_process执行完成后输出shared_list里面是有值的,use_data_process进程去使用shared_list时且是空的,原因:在 Python 的多进程环境中,全局变量在不同进程中并不会共享。解决办法:使用 multiprocessing.Manager 中的共享数据结构,如 list、dict 等

5.Python多进程信息同步
5.1 方式一:锁 Lock
作用:在多进程环境中创建一个锁对象,用于控制多个进程对共享资源的访问。当一个进程获得了锁,其他进程就无法获得该锁,直到锁被释放。
通过acquire()方法可以获取锁,通过release()方法可以释放锁。这样可以确保在同一时刻只有一个进程能够访问受锁保护的共享资源
代码实现:
import datetime
from multiprocessing import Process,Lockdef lock_func_file(lock,name):current_time = datetime.datetime.now()formatted_time = current_time.strftime('%Y-%m-%d %H:%M:%S') + '.' + "{:03d}".format(current_time.microsecond // 1000)#获取锁lock.acquire()print("{}开始执行时间: {}".format(name,formatted_time))text = formatted_time + " " + "测试内容\n"with open('test_lock.txt','a') as f:f.write(text)#释放锁lock.release()if __name__ == '__main__':# 创建锁对象lock = Lock()proc1 = Process(target=lock_func_file, args=(lock,"进程1")) # 创建进程proc1proc2 = Process(target=lock_func_file, args=(lock,"进程2")) # 创建进程proc2proc1.start() #启动进程proc1proc2.start() # 启动进程proc2proc1.join() #等待进程proc1执行结束在执行下面的代码proc2.join() #等待进程proc2执行结束执行下面的代码
执行结果:

用进程池的方式调用:

用进程池调用的方式,如果还是直接定义锁对象lock = Lock(),会出现当执行
pool.apply_async(lock_func_file,args=(lock,))时,不会执行方法lock_func_file,原因是:在使用apply_async时,它使用pickle模块将任务发送给子进程,所以需要确保被传递的参数是可以被pickle序列化的。multiprocessing.Lock 对象默认是不可序列化的,因此可能会导致该问题 ,解决方法:使用Manager().Lock()来创建一个可序列化的锁对象:lock = Manager().Lock()
5.2 方式二:信号量 Semaphore
作用:控制对共享资源的访问 ,它有一个内部计数器,该计数器限制了可以同时访问共享资源的进程数量。当进程要访问共享资源时,它必须先获取信号量。如果信号量的计数器大于零,进程将减少计数器并继续执行。如果计数器为零,进程将被阻塞直到有其他进程释放了信号量。
有两个重要方法:
acquire([blocking]): 获取信号量,如果计数器的值大于0,则将其减1并立即返回
release(): 释放信号量。将计数器的值加1
代码实现:
import datetime
from multiprocessing import Process, Semaphoredef semaphore_func_file(semaphore,name):current_time = datetime.datetime.now()formatted_time = current_time.strftime('%Y-%m-%d %H:%M:%S') + '.' + "{:03d}".format(current_time.microsecond // 1000)#获取信号量semaphore.acquire()print("semaphore:{}开始执行时间: {}".format(name,formatted_time))text = formatted_time + " " + "semaphore测试内容\n"with open('test_semaphore.txt','a') as f:f.write(text)#释放信号量semaphore.release()if __name__ == '__main__':#创建信号量对象,允许一个进程同时访问资源semaphore = Semaphore(1)proc1 = Process(target=semaphore_func_file, args=(semaphore, "进程1")) # 创建进程proc1proc2 = Process(target=semaphore_func_file, args=(semaphore, "进程2")) # 创建进程proc2proc1.start() # 启动进程proc1proc2.start() # 启动进程proc2proc1.join() # 等待进程proc1执行结束在执行下面的代码proc2.join() # 等待进程proc2执行结束执行下面的代码执行结果:

5.3 方式三:条件变量 Condition
作用:它允许多个进程在特定条件下等待或者唤醒其他进程 ,通常需要与Lock()结合使用,以确保多个进程之间对共享资源的安全访问,条件变量的作用包括以下几个方面:
- 线程间的通信:条件变量允许一个或多个进程等待另一个进程满足特定条件时进行通知。
- 线程间的协调:条件变量可以协调多个进程,确保它们在同一时间一起执行或者按照特定的顺序执行。
- 避免忙等待:使用条件变量可以避免进程在等待时持续占用 CPU 资源,因为进程可以在条件不满足时进入休眠状态。
代码实现:
import datetime
import time
from multiprocessing import Process,Condition,Managerdef condition_producer(condition,shared_list):current_time = datetime.datetime.now()formatted_time = current_time.strftime('%Y-%m-%d %H:%M:%S') + '.' + "{:03d}".format(current_time.microsecond // 1000)print("condition_producer执行时间:{}".format(formatted_time))# 获取信号量print("生产数据开始")time.sleep(3) #加一个等待时间,让消费进程等待for i in range(3):with condition:shared_list.append(i)condition.notify_all() # 通知消费者进程print("生产一次后的数据:{}".format(shared_list))def condition_consumer(condition,shared_list):current_time = datetime.datetime.now()formatted_time = current_time.strftime('%Y-%m-%d %H:%M:%S') + '.' + "{:03d}".format(current_time.microsecond // 1000)print("condition_consumer执行时间:{}".format(formatted_time))print("消费进程开始前shared_list里的数据:{}".format(shared_list))for i in range(3):with condition:while len(shared_list) == 0:print("consumer waiting.....")condition.wait(timeout=3) # 等待生产者进程通知、唤醒,等待时间3sprint("Consumed:", shared_list.pop(0))if __name__ == '__main__':# 实列化Condition对象condition = Condition()#创建共享数据列表shared_list = Manager().list() # 使用Manager来创建共享的list#创建进程producer_process =Process(target=condition_producer, args=(condition,shared_list))consumer_process = Process(target=condition_consumer, args=(condition,shared_list))producer_process.start()consumer_process.start()producer_process.join()consumer_process.join()
执行结果:

with condition 的解释
在Python中,with语句用于创建一个运行时上下文,它在进入和退出该上下文时执行特定的操作。对于Condition对象,with condition的表示在进入和退出该上下文时,将自动获取和释放底层的锁。在示例中,with condition用于获取Condition对象的锁,这意味着当进程进入with块时,它会获得锁,当离开with块时,锁会被释放。这确保了在with块中的临界区代码在同一时间只能被一个进程执行,从而避免了多个进程同时修改共享数据可能引发的问题。
5.4 方式四:Event
作用:可以在进程间传递状态信息,Event有两种状态:已设置和未设置。它的运行机制是:全局定义了一个Flag,默认值为false。
如果Flag值为 false,当程序执行event.wait()方法时就会阻塞
如果Flag值为true时,程序执行event.wait()方法时不会阻塞继续执行,执行wait()后,Flag值又变为false,直达再次执行set()后,Flag的值才会变为true。
除了wait()和set()外,Event还提供了其他两个方法:
clear()方法:将Flag的值改成False
is_set()方法:判断当前的Flag的值
代码实现:
import datetime
import time
from multiprocessing import Process,Event,Managerdef event_producer(event,shared_list):print("生产者先等待3s")time.sleep(3)current_time = datetime.datetime.now()formatted_time = current_time.strftime('%Y-%m-%d %H:%M:%S') + '.' + "{:03d}".format(current_time.microsecond // 1000)print("生产者开始执行的时间是:{}".format(formatted_time))for i in range(4):shared_list.append(i)print("数据生产完了.......")print("生产完的数据如下:{}".format(shared_list))print("通过Set()通知消费者")event.set() #Flag为Truedef event_consumer(event,shared_list):current_time = datetime.datetime.now()formatted_time = current_time.strftime('%Y-%m-%d %H:%M:%S') + '.' + "{:03d}".format(current_time.microsecond // 1000)print("进入消费进程的时间:{}".format(formatted_time))print("消费者需要使用数据shared_list,但生产者还没有生产完,此时Flag状态还是false,通过wait阻塞等待")event.wait()print("Flag状态变为True")print("消费者使用数据前的数据为:{}".format(shared_list))for i in range(4):print("Consumed:", shared_list.pop(0))if __name__ == '__main__':#创建Event对象event=Event()#创建共享数据列表shared_list = Manager().list() # 使用Manager来创建共享的list#创建进程producer_process =Process(target=event_producer, args=(event,shared_list))consumer_process = Process(target=event_consumer, args=(event,shared_list))#启动进程producer_process.start()consumer_process.start()#等待进程执行完毕producer_process.join()consumer_process.join()执行结果:

相关文章:
Python中multiprocessing的使用详解
1.实现多进程 代码实现: from multiprocessing import Process import datetime import timedef task01(name):current_timedatetime.datetime.now()start_timecurrent_time.strftime(%Y-%m-%d %H:%M:%S). "{:03d}".format(current_time.microsecond //…...

强化学习与神经网络结合(以 DQN 展开)
目录 基于 PyTorch 实现简单 DQN double DQN dueling DQN Noisy DQN:通过噪声层实现探索,替代 ε- 贪心策略 Rainbow_DQN如何计算连续型的Actions 强化学习中,智能体(Agent)通过与环境交互学习最优策略。当状态空间或动…...

函数式组件中的渲染函数 JSX
在 Vue.js 和 React 等现代前端框架中,函数式组件已成为一种非常流行的设计模式。函数式组件是一种没有内部状态和生命周期方法的组件,其主要功能是接受 props 并渲染 UI。随着这些框架的演进,渲染函数和 JSX(JavaScript XML&…...

北斗导航 | 基于因子图优化的GNSS/INS组合导航完好性监测算法研究,附matlab代码
以下是一篇基于因子图优化(FGO)的GNSS/INS组合导航完好性监测算法的论文框架及核心内容,包含数学模型、完整Matlab代码及仿真分析基于因子图优化的GNSS/INS组合导航完好性监测算法研究 摘要 针对传统卡尔曼滤波在组合导航完好性监测中对非线性与非高斯噪声敏感的问题,本文…...
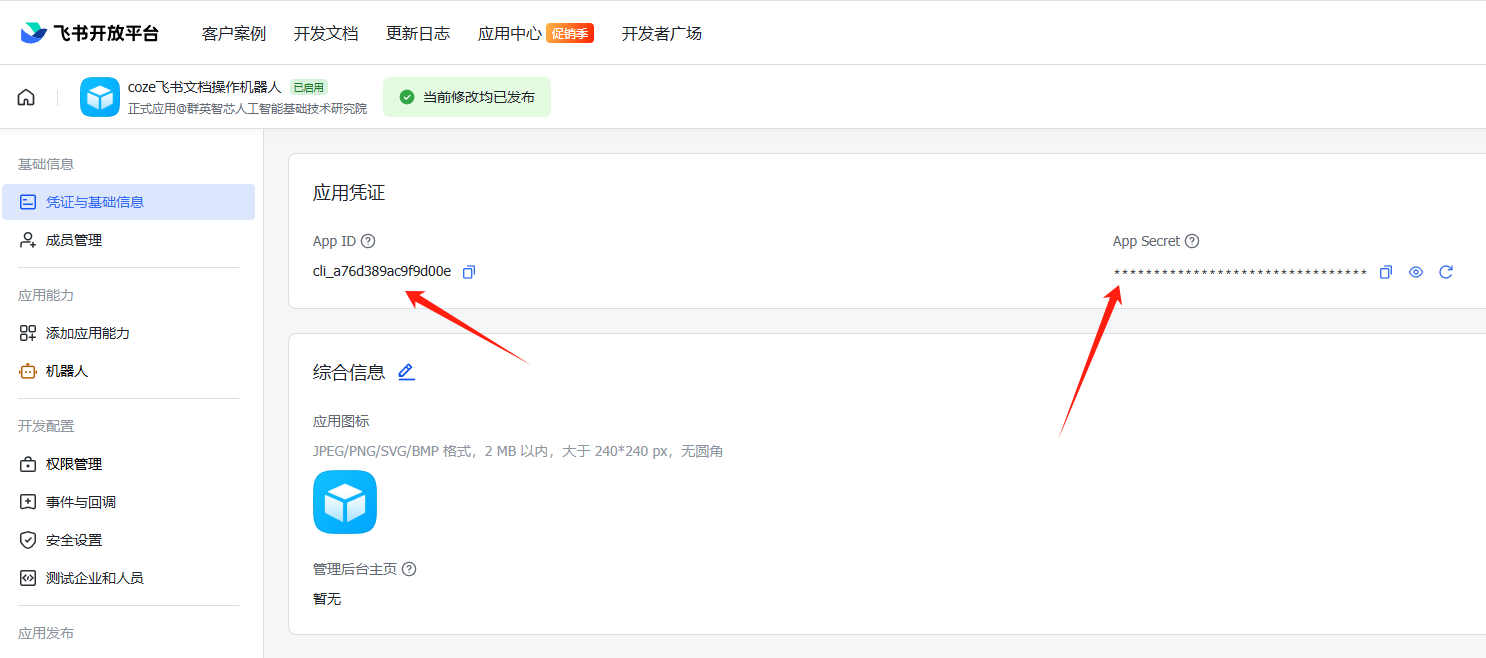
飞书电子表格自建应用
背景 coze官方的插件不支持更多的飞书电子表格操作,因为需要自建应用 飞书创建文件夹 创建应用 开发者后台 - 飞书开放平台 添加机器人 添加权限 创建群 添加刚刚创建的机器人到群里 文件夹邀请群 创建好后,就可以拿到id和key 参考教程: 创…...

深度学习四大核心架构:神经网络(NN)、卷积神经网络(CNN)、循环神经网络(RNN)与Transformer全概述
目录 📂 深度学习四大核心架构 🌰 知识点概述 🧠 核心区别对比表 ⚡ 生活化案例理解 🔑 选型指南 📂 深度学习四大核心架构 第一篇: 神经网络基础(NN) 🌰 知识点概述…...
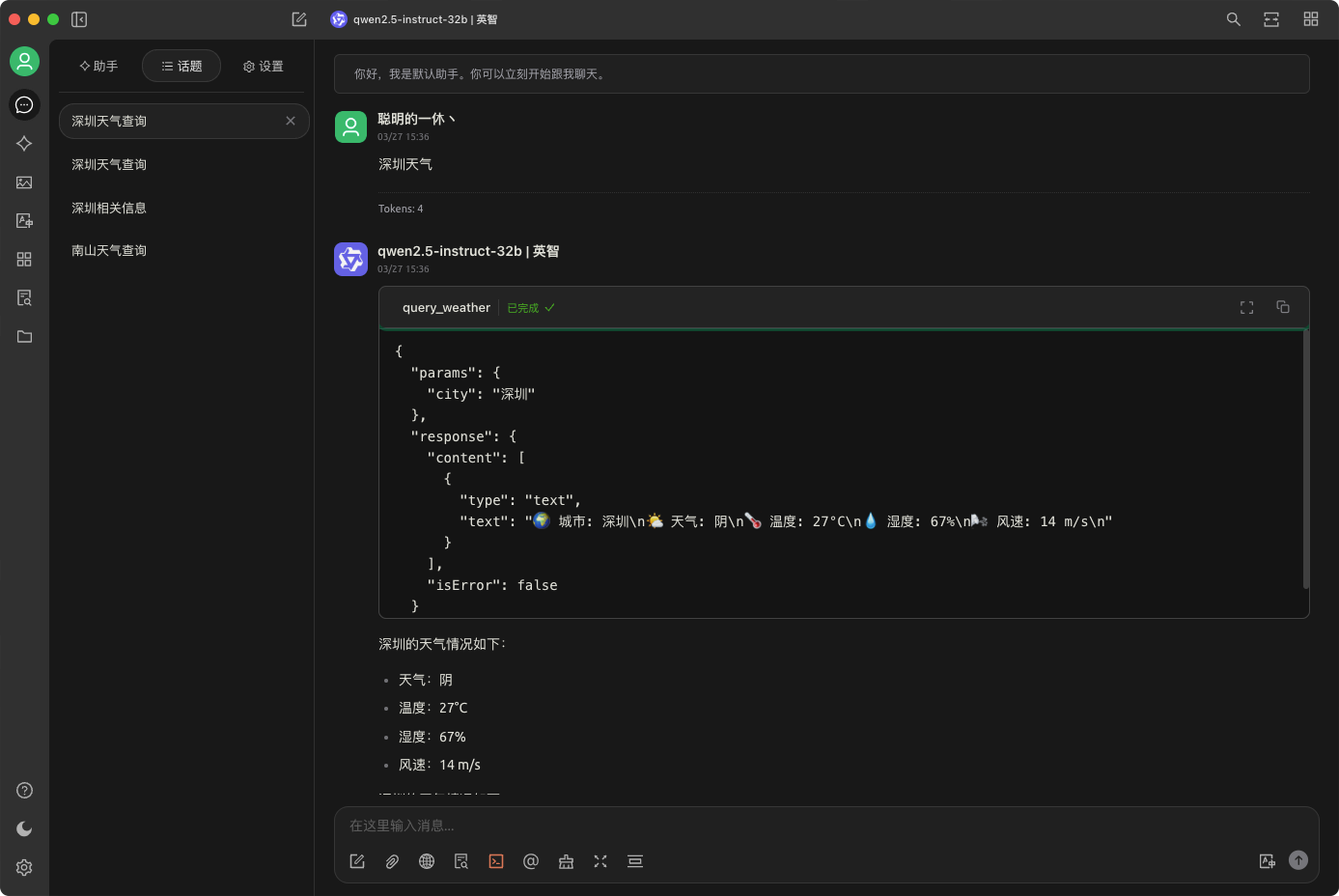
MCP Server 实现一个 天气查询
Step1. 环境配置 安装 uv curl -LsSf https://astral.sh/uv/install.sh | shQuestion: 什么是 uv 呢和 conda 比有什么区别? Answer: 一个用 Rust 编写的超快速 (100x) Python 包管理器和环境管理工具,由 Astral 开发。定位为 pip 和 venv 的替代品…...

《强化学习基础概念:四大模型与两大损失》
强化学习基础概念一、策略模型1. 策略的定义2. 策略的作用3.策略模型 二、价值模型1. 价值函数的定义(1)状态值函数(State Value Function)(2)动作值函数(Action Value Function) 2.…...

Headless Chrome 优化:减少内存占用与提速技巧
在当今数据驱动的时代,爬虫技术在各行各业扮演着重要角色。传统的爬虫方法往往因为界面渲染和资源消耗过高而无法满足大规模数据采集的需求。本文将深度剖析 Headless Chrome 的优化方案,重点探讨如何利用代理 IP、Cookie 和 User-Agent 设置实现内存占用…...

知识就是力量——HELLO GAME WORD!
你好!游戏世界! 简介环境配置前期准备好文章介绍创建头像小功能组件安装本地中文字库HSV颜色空间音频生成空白的音频 游戏UI开发加载动画注册登录界面UI界面第一版第二版 第一个游戏(贪吃蛇)第二个游戏(俄罗斯方块&…...

电脑连不上手机热点会出现的小bug
一、问题展示 注意: 不要打开 隐藏热点 否则他就会在电脑上 找不到自己的热点 二、解决办法 把隐藏热点打开即可...

unity 做一个圆形分比图
// 在其他脚本中控制多段进度 using System.Collections.Generic; using UnityEngine;public class GameManager : MonoBehaviour {public MultiCircleProgress circleProgress;void Start(){// 初始化数据circleProgress.segments new List<MultiCircleProgress.ProgressS…...
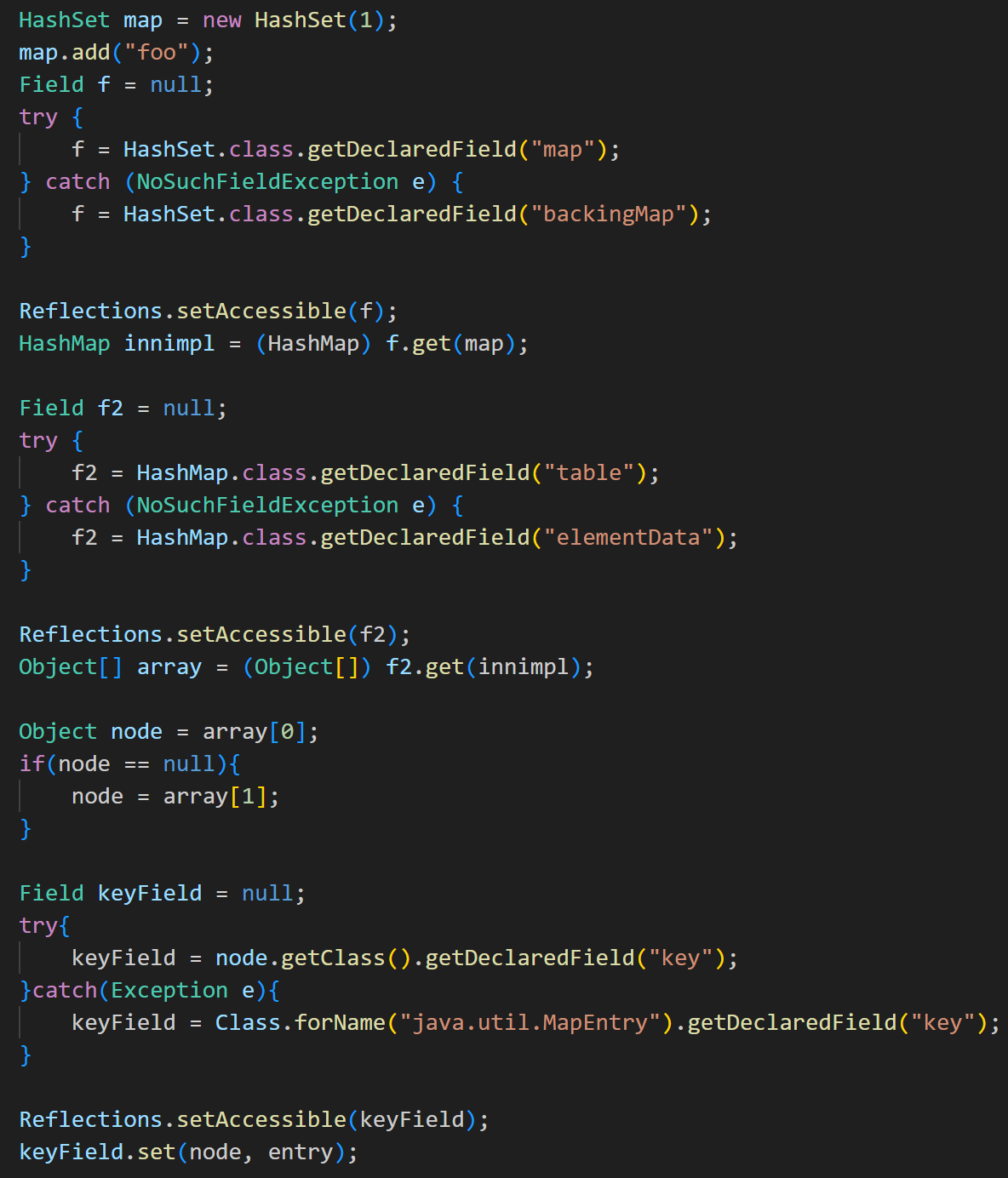
JAVA反序列化深入学习(八):CommonsCollections6
与CC5相似: 在 CC5 中使用了 TiedMapEntry#toString 来触发 LazyMap#get在 CC6 中是通过 TiedMapEntry#hashCode 来触发 LazyMap#get 之前看到了 hashcode 方法也会调用 getValue() 方法然后调用到其中 map 的 get 方法触发 LazyMap,那重点就在于如何在反…...

鸿蒙项目源码-外卖点餐-原创!原创!原创!
鸿蒙外卖点餐外卖平台项目源码含文档包运行成功ArkTS语言。 我半个月写的原创作品,请尊重原创。 原创作品,盗版必究!!! 原创作品,盗版必究!!! 原创作品,盗版…...

计算机二级WPS Office第十一套WPS演示
解题过程...

React程序打包与部署
===================== 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 为生产环境准备React应用最小化和打包环境变量错误处理部署到托管服务部署到Netlify探索高级主题:Hooks、Su…...

ubuntu 创建新用户
给实验室服务器建用户,会担心除了基本的用户创建以外有没有别的没考虑到的。问了一下似乎没有,就按最基础的来就可以 # linux 自带的基础命令 # 创建用户,指定 home,设置 owner,设置密码 sudo useradd -d /home/abc a…...
106.从中序与后序遍历序列构造二叉树(▲)
代码随想录刷题day53|(二叉树篇)106.从中序与后序遍历序列构造二叉树(▲
目录 一、二叉树理论知识 二、构造二叉树思路 2.1 构造二叉树流程(给定中序后序 2.2 整体步骤 2.3 递归思路 2.4 给定前序和后序 三、相关算法题目 四、易错点 一、二叉树理论知识 详见:代码随想录刷题day34|(二叉树篇)二…...

Leetcode算法方法总结
1. 双指针法解决链表/数组题目 只要数组有序,就要想到双指针做法。还有二分法 回文串一般也会用到双指针,回文串的长度由于可能是奇数也可能是偶数,所以在寻找时,既需要寻找奇数长度的回文串,也需要寻找偶数长度的回文…...

全包圆玛奇朵样板间亮相,极简咖啡风引领家装新潮流
在追求品质生活的当下,家居装修风格的选择成为了许多消费者关注的焦点。近日,全包圆家居装饰有限公司精心打造的玛奇朵样板间正式对外开放,以其独特的咖啡色系极简风格,为家装市场带来了一股清新的潮流。玛奇朵样板间不仅展示了全…...

小红书多账号运营:如何实现每个账号独立 IP发布文章
一、多账号管理与 IP 隔离方案 1.电脑端实现:推荐使用指纹浏览器工具,为每个账号生成独立设备指纹(模拟不同 MAC 地址、内存等信息),并搭配兔子ip代理等服务商的 SOCKS5 代理,实现一机多开且每个账号独立 …...

大数据学习(92)-spark详解
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

免费下载 | 2025年网络安全报告
报告总结了2024年的网络安全态势,并对2025年的安全趋势进行了预测和分析。报告涵盖了勒索软件、信息窃取软件、云安全、物联网设备安全等多个领域的安全事件和趋势,并提供了安全建议和最佳实践。 一、报告背景与目的 主题:2024企业信息安全峰…...

《Android低内存设备性能优化实战:深度解析Dalvik虚拟机参数调优》
1. 痛点分析:低内存设备的性能困局 现象描述:大应用运行时频繁GC导致卡顿 根本原因:Dalvik默认内存参数与硬件资源不匹配 解决方向:动态调整堆内存参数以平衡性能与资源消耗 2. 核心调优参数全景解析 关键参数矩阵࿱…...

RCE--解法
目录 一、利用php伪协议 1.代码分析 2.过程 3.结果 编辑 4.防御手段 二、RCE(php中点的构造) 1.代码分析 2.过程 一、利用php伪协议 <?php error_reporting(0); if(isset($_GET[c])){$c $_GET[c];if(!preg_match("/flag|system|php|cat|sort…...

JAVA反序列化深入学习(九):CommonsCollections7与CC链总结
CC7 依旧是寻找 LazyMap 的触发点 CC6使用了 HashSet而CC6使用了 Hashtable JAVA环境 java version "1.8.0_74" Java(TM) SE Runtime Environment (build 1.8.0_74-b02) Java HotSpot(TM) 64-Bit Server VM (build 25.74-b02, mixed mode) 依赖版本 Apache Commons …...

HTML元素小卖部:表单元素 vs 表格元素选购指南
刚学HTML的同学经常把表单和表格搞混,其实它们就像超市里的食品区和日用品区——虽然都在同一个超市,但用途完全不同。今天带你3分钟分清这两大元素家族! 一、表单元素家族(食品区:收集用户输入) 1. <i…...

如何使用 Bash 脚本自动化清理 Nacos 日志文件
如何使用 Bash 脚本自动化清理 Nacos 日志文件 在现代的分布式系统中,Nacos 作为服务发现、配置管理和动态服务管理的核心组件,其日志文件的管理显得尤为重要。随着系统的运行,日志文件会不断累积,占用大量磁盘空间。如果不及时清理,可能会导致磁盘空间不足,影响系统性能…...

群体智能优化算法-算术优化算法(Arithmetic Optimization Algorithm, AOA,含Matlab源代码)
摘要 算术优化算法(Arithmetic Optimization Algorithm, AOA)是一种新颖的群体智能优化算法,灵感来源于加、减、乘、除四种基本算术运算。在优化过程中,AOA 通过乘除操作实现全局探索,通过加减操作强化局部开发&#…...

Redis6数据结构之String类型
redis的String类型是存储字符串类型的key-value。 应用场景:验证码、计数器(包括点赞数、文章/视频浏览数)、订单重复提交、用户登录信息、商品详情。 常用命令: set/get设置和获取key-valuemset/mget批量设置或获取多个key的…...