排序算法3-交换排序
目录
1.常见排序算法
2.排序算法的预定函数
2.1交换函数
2.2测试算法运行时间的函数
2.3已经实现过的排序算法
3.交换排序的实现
3.1冒泡排序
3.2快速排序
3.2.1递归的快速排序
3.2.1.1hoare版本的排序
3.2.1.2挖坑法
3.2.1.3lomuto前后指针法
3.2.2非递归版本的快速排序
4.总结
1.常见排序算法

前面一讲已经讲解了插入排序和选择排序,这一讲我将讲解交换排序,但是有些算法的实现将依靠之前的数据结构知识,所以如果想要看懂这些算法的实现需要打牢数据结构的基础。每一个算法都需要一定的测试用例,所以我们需要给定一些测试用例来测试该算法是否适用于每一个算法,我们现在给定一些测试用例:1 2 3 4 5 6 7 8 9;9 8 4 2 4 1 3 7 5 ;2 3 4 3 4 2 7 9 2 4;100 101 195 124 125 129;以上四种测试用例对于不同的排序算法每一个测试用例可能会表现出不同的时间复杂度,每一个测试用例也有每一个测试用例对应的时间复杂度最好的一种或几种算法,我们在实现排序时我们需要一些预定的函数,如:交换函数,测试运行时间的函数等。
2.排序算法的预定函数
2.1交换函数
我们需要两个整型类型的指针(之后我们排序排列的都是整型),我们暂时不用typedef了,否则这样比较难理解。
//交换函数
void Swap(int* a, int* b)
{int p = *a;*a = *b;*b = p;
}2.2测试算法运行时间的函数
这个函数我们权当只是用来测试每一个排序算法最终在实际运用时的表现,我们先进行自己的测试用例的测试,代码无误了再进行实际运用的测试。我们每一次学完这个算法就把这个算法的注释删除即可。
// 测试排序的性能对⽐
void TestOP()
{srand(time(0));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();MergeSort(a6, N);int end6 = clock();int begin7 = clock();BubbleSort(a7, N);int end7 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);printf("HeapSort:%d\n", end4 - begin4);printf("QuickSort:%d\n", end5 - begin5);printf("MergeSort:%d\n", end6 - begin6);printf("BubbleSort:%d\n", end7 - begin7);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);free(a7);
}上面的排序算法除了冒泡排序外我们之前基本上没学过,所以每一次我们都和之前学过的排序算法进行比较。
2.3已经实现过的排序算法
这个是为了测试之前的算法和现在实现的算法的比较,我们已经讲解过了插入排序,所以下面代码列出了插入排序的两个代码和选择排序的两个代码:
//直接插入排序(升序)
void InsertSort1(int* arr, int n)
{for (int i = 0; i < n - 1; i++){//我们把需要比较的数放入tmp中,然后先与第i个数据比较,依次往前进行比较插入int end = i;int tmp = arr[end + 1];while (end >= 0){if (arr[end] > tmp){arr[end + 1] = arr[end];end--;}else{break;}}//如果end=-1我们不能进行数组越界,所以要进行+1操作arr[end + 1] = tmp;}
}
//希尔排序
void ShellSort1(int* arr, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = tmp;}}
}
//直接选择排序
void SelectSort1(int* arr, int n)
{int begin = 0, end = n - 1;while (begin < end){int max, min;max = min = begin;for (int i = begin + 1; i <= end; i++){//我们从开始位置后面的数据进行遍历,原因不用解释if (arr[i] < arr[min]){min = i;}if (arr[i] > arr[max]){max = i;}}if (max == begin){max = min;}Swap(&arr[min], &arr[begin]);Swap(&arr[max], &arr[end]);begin++;end--;}
}
其中堆排序代码过长,我这里就不复制了,需要的可以去看我之前的博客:数据结构初阶-堆的代码实现-CSDN博客。
3.交换排序的实现
3.1冒泡排序
冒泡排序是通过比较相邻的两个数来进行交换实现升序(降序)的过程,之前我们都有了解过,所以这里就不赘述了,我们只分析它与其他算法的对比即可,代码实现如下:
//冒泡排序
void BubbleSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){int exchange = 0;for (int j = 0; j < n - i - 1; j++){if (arr[j] > arr[j + 1]){exchange = 1;Swap(&arr[j], &arr[j + 1]);}}if (exchange == 0){break;}}
}排序之后的结果如下:




冒泡排序在实际应用中的表现如何呢?
 我们发现冒泡排序直接用了79s,等得我都觉得我的代码有问题了,这个算法也是非常的烂,不像我们的堆排序也是只有7ms啊,这种算法太低端了,所以之后不要总用冒泡排序了!
我们发现冒泡排序直接用了79s,等得我都觉得我的代码有问题了,这个算法也是非常的烂,不像我们的堆排序也是只有7ms啊,这种算法太低端了,所以之后不要总用冒泡排序了!
3.2快速排序
基本思想:任取待排序元素序列中的一个元素作为基准值,按照该排序码讲待排序的集合分割成量子序列,左子序列的所有元素均小于基准值,右子序列中的所有元素均大于基准值,然后分割出的左子序列和右子序列重复该过程,这类似于我们的二叉树,需要用到递归思想,但是我们也有非递归的快速排序,只是递归排序代码比较简单而已。
3.2.1递归的快速排序
3.2.1.1hoare版本的排序
我们默认基准值为第一个元素,然后创建两个指针,一个从左到右找比基准值大的,一个从右往左找比基准值小的,然后把二者交换,left++,right--直至相遇,所以最终代码如下:
//hoare版本找基准值排序
int _QuickSort(int* arr, int left, int right)
{int key = left;left++;while (left <= right){//right从右往左找小//并且不能让left>right否则会越界//第一个循环不能省略这个条件,可能在第一个循环的遍历过程中出现right<=leftwhile (arr[right] > arr[key] && left <= right){right--;}//left从左往右找大while (arr[left] < arr[key] && left <= right){left++;}if (left <= right){Swap(&arr[left++], &arr[right--]);}}Swap(&arr[key], &arr[right]);return right;
}
//快速排序
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}//找基准值并进行排序int key = _QuickSort(arr, left, right);//把数组分为三部分: [left,key-1] key [key+1,right]QuickSort(arr, left, key - 1);QuickSort(arr, key + 1, right);
}我们运行后结果如下:



发现排序没有问题,我们要理解这个思想:
为什么不在内存循环中加一个=呢?
如果我们加个等号,我们假设有这个数组:1 8 1 8 1 8 1 8 1 8我们第一次循环结束后,没交换的情况下,right=1,left=1,所以我们相遇后最终返回的是下标0(后面要--),所以这样的排序很烂,直接用相等的时候也结束循环是可以的。
我们来测试一下hoare版本的快速排序算法,我们可以把模式改为Release版本,因为这样我们就不需要调试了,我们已经验证过代码无误了(等待的时间很久,主要是冒泡排序花的时间太久了),结果如下:

这个快速排序用了21ms,竟然比堆排序的运行时间还久!主要是这个快排算法需要两层循环,如果在最坏的情况下时间复杂度达到了O(n^2),最坏的情况当然是数组已经排成升序,每一次循环都直接导致了第二个循环都没开始就结束了,递归了n次又加上循环了n次,所以导致时间较久,但相对于堆排序至少代码简单多了,这个已经算初级的快速排序了,还有很多。
3.2.1.2挖坑法
思路:创建左右指针,从右往左找出比基准值小的数据,找到后立即放入左边坑中,当前位置成为新的“坑”,然后从左往右找出比基准值大的数据,找到后立即放入右边的坑中……依次类推,直至左>右为止,把基准值放入最后一个坑中,返回最后一个坑的下标,这个算法只是改变了找基准值的方法,并且我们需要再循环中找的是小的和大的,不需要找相等的,这相对于另外一个算法就循环次数少一些,因为我们可以每次循环使更多的数据被交换。代码实现如下:
//挖坑法找基准值排序
int _QuickSort(int* arr, int left, int right)
{int hole = left;int key = arr[hole];while (left < right){while (left < right && arr[right] >= key){right--;}arr[hole] = arr[right];hole = right;while (left < right && arr[left] <= key){left++;}arr[hole] = arr[left];hole = left;}arr[hole] = key;return hole;
}
//快速排序
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}//找基准值并进行排序int key = _QuickSort(arr, left, right);//把数组分为三部分: [left,key-1] key [key+1,right]QuickSort(arr, left, key - 1);QuickSort(arr, key + 1, right);
}我们遇到几个问题,我在这里解释一下:
为什么开始的时候不用left++,这样不会多循环一次吗?
假设第一个元素(基准值)就是最小值,如果此时left++,那么会导致我们最终hole到达了下标为1 的位置,这样我们就会导致第一步或者前面出错,所以不能这样。
为什么不要在相等的时候交换?
这样根本没有意义,这个hole改来改去结果一点意义都没有,放到前面和后面的hole没有多少区别,而且这样循环也会变多,没必要。
为什么不在相等的时候继续循环?
如果hole==0那么就会导致最终结果越界了,所以我们不能这样做,我们最终一个元素不用排序。
我们来测试一下这个方法的实际应用中的表现吧!最终运行结果如下:

可能这个随机数有些乱,也是直接无语了好吧,这个冒泡排序都用了80s,但是这个快速排序还是比较快的,所以我们说快速排序还算快的一种算法,实现也比较简单!
3.2.1.3lomuto前后指针法
初始时prev指向序列开头,cur指向prev指针的后一个位置,cur指向的数据比基准值要小的情况下,我们让prev++,prev和cur数据交换,再cur++;如果cur只想的数据不小于基准值,则cur++。这个方法也是比较难理解,主要是我们要找到的是小于的位置,而prev位置一直是小于基准值的位置,最后我们让基准值和prev位置的数据交换,思想都差不多,代码如下:
// lomuto前后指针法
int _QuickSort(int* arr, int left, int right)
{int prev = left;int cur = prev + 1;//key也可以不创建,之后又不会发生改变,只是方便理解而已int key = left;while (cur <= right){if (arr[cur] < arr[key] && ++prev != cur){//我们如果把一个位置的数进行交换是没必要的//并且如果把++prev放到前面就会先执行该语句会出错Swap(&arr[cur], &arr[prev]);}++cur;}Swap(&arr[prev], &arr[key]);return prev;
}
//快速排序
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}//找基准值并进行排序int key = _QuickSort(arr, left, right);//把数组分为三部分: [left,key-1] key [key+1,right]QuickSort(arr, left, key - 1);QuickSort(arr, key + 1, right);
}最终运行结果如下:




我们来测试它在实际应用中的表现:

可能是我的电脑没电了还是什么,运行也是越来越慢了,但是快速排序还是一如竟往的快,但是这个冒泡排序也太慢了。
3.2.2非递归版本的快速排序
这个版本的快速排序需要借助数据结构-栈,至于栈的东西我之前写过博客,需要的直接去看:数据结构初阶-栈及其应用-CSDN博客 。主要思想如下:我们开始先把数组的right入栈,再把数组的left入栈,然后出栈,先出的是begin,后出的是end,然后和之前的找基准值的方法一样,只不过最终我们是用循环来实现的,其中,如果key+1>right则越界了,不要入栈,无右序列,若left==right,则只有一个元素,不要入栈,同理,若key-1<begin也不用入栈,直至栈为 空循环结束,最终代码如下:
// 之前没有在代码中实现这个函数,所以在这里添上
// 取栈顶元素
STDataType StackTop(ST* ps)
{assert(!StackEmpty(ps));return ps->arr[ps->size - 1];
}
// 非递归版本的快速排序
void QuickSort(int* arr, int left, int right)
{ST st;SLInit(&st);//先让right和left入栈,防止栈为空StackPush(&st, right);StackPush(&st, left);while (!StackEmpty(&st)){//取栈顶元素int begin = StackTop(&st);//要出栈StackPop(&st);int end = StackTop(&st);StackPop(&st);//对[begin,end]使用双指针法int prev = begin;int cur = prev + 1;int key = begin;while (cur <= end){if (arr[cur] < arr[key] && ++prev != cur){Swap(&arr[prev], &arr[cur]);}++cur;}Swap(&arr[key], &arr[prev]);//记得加上这句话,之前递归的是直接返回了prev,而这里不行,我刚刚也没发现问题key = prev;//数组分为以下三部分:[begin,prev-1]prev [prev+1,end]//先入右子数组//从右至左开始入if (prev + 1 < end){StackPush(&st, end);StackPush(&st, prev + 1);}//再入左子数组if (key - 1 > begin){StackPush(&st, key - 1);StackPush(&st, begin);}}STDestroy(&st);
}结果如下:
![]()


我们来测试它在实际应用中的表现吧!结果如下:

可以看尺寸这个排序算法的时间比希尔排序时间还久,所以说之前的递归的快速排序更好一些,而且那些更容易理解,这个只能看代码而很难想出来!
4.总结
快速排序的实现方式有很多种,以后我们学习了C++等可能有更好的排序算法,总体来说快速排序的运行时间较短,是一个好的算法,非常建议大家在实战中使用该算法!下节我准备把归并排序和非比较排序直接讲了,就不和其他的算法进行比较了,只要知道这个算法就可以了,喜欢的可以一键三连哦,下节再见!
相关文章:
排序算法3-交换排序
目录 1.常见排序算法 2.排序算法的预定函数 2.1交换函数 2.2测试算法运行时间的函数 2.3已经实现过的排序算法 3.交换排序的实现 3.1冒泡排序 3.2快速排序 3.2.1递归的快速排序 3.2.1.1hoare版本的排序 3.2.1.2挖坑法 3.2.1.3lomuto前后指针法 3.2.2非递归版本的快…...

【Qt】数据库管理
数据库查询工具开发学习笔记 一、项目背景与目标 背景:频繁编写数据库查询语句,希望通过工具简化操作,提升效率。 二、总体设计思路 1. 架构设计 MVC模式:通过Qt控件实现视图(UI),业务逻辑…...

Ant Design Vue 中的table表格高度塌陷,造成行与行不齐的问题
前言: Ant Design Vue: 1.7.2 Vue2 less 问题描述: 在通过下拉框选择之后,在获取接口数据,第一列使用了fixed:left,就碰到了高度塌陷,查看元素的样式结果高度不一致,如&#x…...

面经-项目
项目 项目(重点)问题1:描述在网页中题目点击提交后到题目结果出现的一系列后台反应【1】如何获取到用户提交的代码的?【2】_1. 题目细节都有哪些?【2】_2. 题目信息怎么存储的?【3】负载均衡算法的实现?【4】oj_server怎么连接对应的compile_server(编译主机)的?【5】oj_…...

Win10安装Linux的三种方法
通过 Windows 子系统 for Linux(WSL)安装 启用 “适用于 Linux 的 Windows 子系统” 可选功能: 图形界面方式:在【设置 -> 更新与安全 -> 开发者选项】中开启【开发人员模式】;在【程序和功能 -> 启用或关闭…...
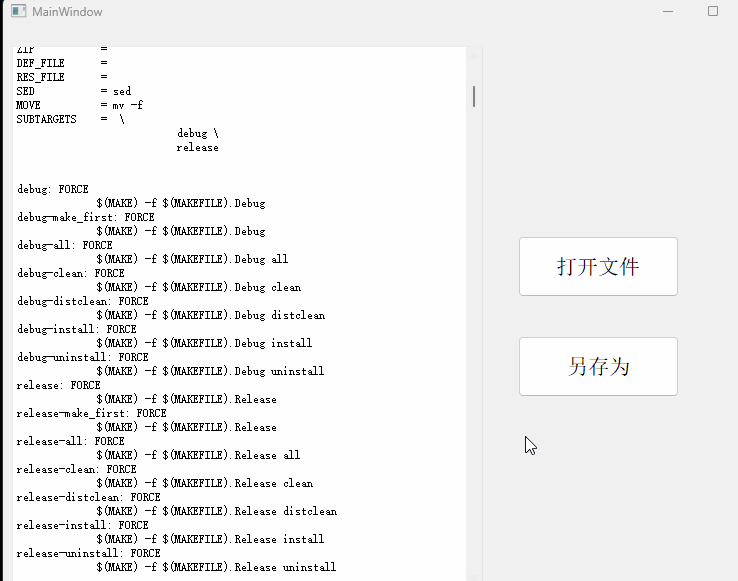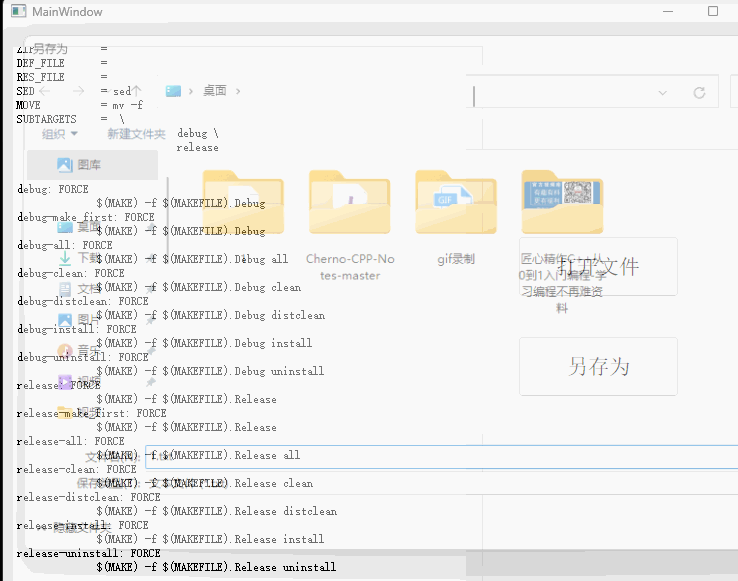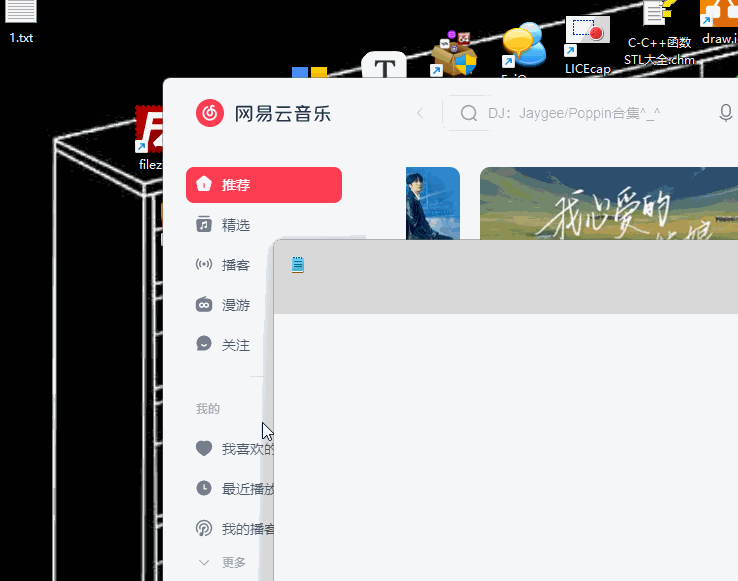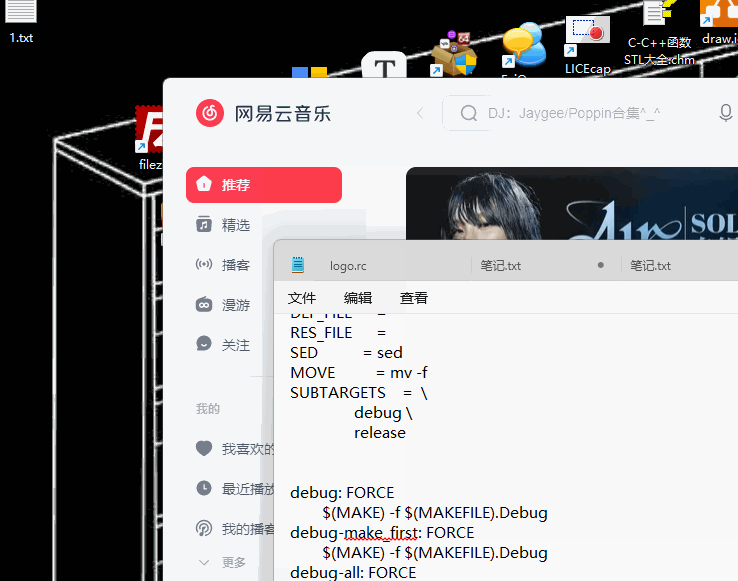
【qt】文件类(QFile)
很高兴你能看到这篇文章,同时我的语雀文档也更新了许多嵌入式系列的学习笔记希望能帮到你 : https://www.yuque.com/alive-m4b9n 目录 QFile 主要功能QFile 操作步骤QFile 其他常用函数案例分析及实现功能一实现:打开文件并显示功能二实现:另…...
)
力扣hot100——最长连续序列(哈希unordered_set)
题目链接:最长连续序列 1、错解:数组做哈希表(内存超出限制) int longestConsecutive(vector<int>& nums) {vector<bool> hash(20000000010, false);for(int i0; i<nums.size();i){hash[1000000000nums[i]]t…...

3. 实战(一):Spring AI Trae ,助力开发微信小程序
1、前言 前面介绍了Spring boot快速集成Spring AI实现简单的Chat聊天模式。今天立马来实战一番,通过Trae这个火爆全网的工具,来写一个微信小程序。照理说,我们只是极少量的编码应该就可以完成这项工作。开撸~ 2、需求描述 微信小程序实现一…...

MySQL高级语句深度解析与应用实践
一、窗口函数:数据分析的利器 1. 窗口函数基础概念 窗口函数(Window Function)是MySQL 8.0引入的强大特性,它可以在不减少行数的情况下对数据进行聚合计算和分析 SELECT employee_name,department,salary,RANK() OVER (PARTITION BY department ORDER…...

SSE服务器主动推送至浏览器客户端,让你不再需要websocket
Server-Sent Events(SSE)是一种服务器向客户端推送实时更新的技术,基于HTTP协议。客户端通过EventSource API来接收事件流,而服务器则保持一个长连接,持续发送数据。这与传统的请求-响应模式不同,允许服务器…...

UE5新材质系统效果Demo展示
1、玉质材质,透明玻璃材质,不同透射和散射。 2、浅水地面,地面层,水层,地面湿度,水面高度,水下扰动,水下浇洒,水下折射 Substrate-Water Substrate-Water-CodeV2...

wps 怎么显示隐藏文字
wps 怎么显示隐藏文字 》文件》选项》视图》勾选“隐藏文字” wps怎么设置隐藏文字 wps怎么设置隐藏文字...
 上使用 Vite 进行 Build 打包时 Node 进程内存溢出的问题)
解决 macOS (M1 Pro) 上使用 Vite 进行 Build 打包时 Node 进程内存溢出的问题
解决 macOS (M1 Pro) 上使用 Vite 进行 Build 打包时 Node 进程内存溢出的问题 在搭载 M1 Pro 芯片的 macOS 系统上,使用 Vite 进行项目构建(build)时,您可能会遇到 Node 进程内存溢出的错误。特别是在使用较新版本的 Node.js&am…...

页面重构过程中如何保证良好的跨浏览器一致性?
在页面重构的过程中,为了确保网页能够在不同的浏览器中呈现一致的效果,我们需要采取一系列措施来提高跨浏览器的一致性。以下是几个关键步骤和技术要点: 使用标准化的HTML和CSS:始终遵循最新的Web标准编写代码,例如采用…...

CXL UIO Direct P2P学习
前言: 在CXL协议中,UIO(Unordered Input/Output) 是一种支持设备间直接通信(Peer-to-Peer, P2P)的机制,旨在绕过主机CPU或内存的干预,降低延迟并提升效率。以下是UIO的核心概念及UI…...

leetcode138.随即链表的复制
思路源于 【力扣hot100】【LeetCode 138】随机链表的复制|哈希表 采用一个哈希表,键值对为<原链表的结点,新链表的结点>,第一次遍历原链表结点时只创建新链表的结点,第二次遍历原链表结点时,通过键拿…...

03_MySQL工具介绍
文章目录 一、Navicat for MySQL1.1、安装 二、SQLyog2.1、安装 多数时候使用SQL语句对数据库进行操作不是很方便,特别是在查询操作时,显示的内容不够直观,此时我们需要借助图形化工具对数据库进行操作。 操作MySQL常用的图形工具如下&#x…...

《网络管理》实践环节01:OpenEuler22.03sp4安装zabbix6.2
兰生幽谷,不为莫服而不芳; 君子行义,不为莫知而止休。 1 环境 openEuler 22.03 LTSsp4PHP 8.0Apache 2Mysql 8.0zabbix6.2.4 表1-1 Zabbix网络规划(用你们自己的特征网段规划) 主机名 IP 功能 备注 zbx6svr 19…...

Qt Creator 中文 “error: C2001: 常量中有换行符“ 问题解决方法
Qt Creator 编译时出现中文 error: C2001: 常量中有换行符的问题,通常由文件编码与编译器字符集不兼容导致。 一、修改文件编码格式 添加 UTF-8 BOM 签名 在 Qt Creator 中设置:工具 -> 选项 -> 文本编辑器 -> 行为 -> UTF-8 BOM&a…...
)
Charles 抓包配置保姆教程(PC、IOS、Android)
抓包工具基础配置与使用指南 大家好,我是十一!今天给大家分享一篇关于抓包工具的基础配置与使用指南。无论是开发、测试还是安全分析,抓包工具都是不可或缺的利器。本文将详细介绍如何配置和使用抓包工具,并特别推荐一款功能强大…...

洛谷题单1-P1001 A+B Problem-python-流程图重构
题目描述 输入两个整数 a,b,输出它们的和(∣a∣,∣b∣≤109)。 输入格式 两个以空格分开的整数。 输出格式 一个整数。 输入输出样例 输入 20 30输出 50方式-print class Solution:staticmethoddef oi_input():"""从…...

el-table 动态给每行增加class属性
el-table 动态给每行增加class属性 html代码 row-class-name属性,绑定方法 :row-class-name“tableRowClassName”, <el-table :data"tableData" border :row-class-name"tableRowClassName"> </el-table>js代码 tableRowClassNam…...

Opencv计算机视觉编程攻略-第四节 图直方图统计像素
Opencv计算机视觉编程攻略-第四节 图直方图统计像素 1.计算图像直方图2.基于查找表修改图像3.直方图均衡化4.直方图反向投影进行内容查找5.用均值平移法查找目标6.比较直方图搜索相似图像7.用积分图统计图像 1.计算图像直方图 图像统计直方图的概念 图像统计直方图是一种用于描…...

深度学习处理时间序列(5)
Keras中的循环层 上面的NumPy简单实现对应一个实际的Keras层—SimpleRNN层。不过,二者有一点小区别:SimpleRNN层能够像其他Keras层一样处理序列批量,而不是像NumPy示例中的那样只能处理单个序列。也就是说,它接收形状为(batch_si…...

Mysql 索引性能分析
1.查看CRUD次数 show global status like Com_______(7个下划线) show global status like Com_______ 2.慢SQL分析 SET GLOBAL slow_query_log ON;-- 设置慢SQL日志记录开启 SET GLOBAL long_query_time 2; -- 设置执行超过 2 秒的查询为慢查询 开…...

win11+ubuntu双系统安装
操作步骤: 官网下载ubuntu 最新镜像文件 准备U盘 准备一个容量不小于 8GB 的 U 盘,用于制作系统安装盘。制作过程会格式化 U 盘,请注意提前备份数据。 制作U盘启动盘 使用rufus工具,或者 balenaEtcher工具(官网安…...

linux-5.10.110内核源码分析 - 写磁盘(从VFS系统调用到I/O调度及AHCI写磁盘)
1、VFS写文件到page缓存(vfs_write) 1.1、写裸盘(dd) 使用如下命令写裸盘: dd if/dev/zero of/dev/sda bs4096 count1 seek1 1.2、系统调用(vfs_write) 系统调用栈如下: 对于调用栈的new_sync_write函数,buf为写磁盘的内容的内存地址&…...

arinc818 fpga单色图像传输ip
arinc818协议支持的常用线速率如下图 随着图像分辨率的提高,单lane的速率无法满足特定需求,一种方式是通过多个LANE交叉的去传输图像,另外一种是通过降低图像的带宽,即通过只传单色图像达到对应的效果 程序架构如下图所示&#x…...

业务流程先导及流程图回顾
一、测试流程回顾  1. 备测内容回顾  备测内容: 本次测试涵盖买家和卖家的多个业务流程,包括下单流程、发货流程、搜索退货退款、支付抢购、换货流程、个人中心优惠券等。 2. 先测业务强调  1)测试业务流程 …...

HCIP(RSTP+MSTP)
一、STP的重新收敛: 复习STP接口状态 STP初次收敛至少需要50秒的时间。STP的重新收敛情况: 检测到拓扑变化:当网络中的链路故障或新链路加入时,交换机会检测到拓扑变化。 选举新的根桥:如果原来的根桥故障或与根桥直…...