【现代深度学习技术】现代卷积神经网络06:残差网络(ResNet)

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、函数类
- 二、残差块
- 三、ResNet模型
- 四、训练模型
- 小结
随着我们设计越来越深的网络,深刻理解“新添加的层如何提升神经网络的性能”变得至关重要。更重要的是设计网络的能力,在这种网络中,添加层会使网络更具表现力,为了取得质的突破,我们需要一些数学基础知识。
一、函数类
首先,假设有一类特定的神经网络架构 F \mathcal{F} F,它包括学习速率和其他超参数设置。对于所有 f ∈ F f \in \mathcal{F} f∈F,存在一些参数集(例如权重和偏置),这些参数可以通过在合适的数据集上进行训练而获得。现在假设 f ∗ f^* f∗是我们真正想要找到的函数,如果是 f ∗ ∈ F f^* \in \mathcal{F} f∗∈F,那我们可以轻而易举的训练得到它,但通常我们不会那么幸运。相反,我们将尝试找到一个函数 f F ∗ f^*_\mathcal{F} fF∗,这是我们在 F \mathcal{F} F中的最佳选择。例如,给定一个具有 X \mathbf{X} X特性和 y \mathbf{y} y标签的数据集,我们可以尝试通过解决以下优化问题来找到它:
f F ∗ : = a r g m i n f L ( X , y , f ) , f ∈ F (1) f^*_\mathcal{F} := \mathop{\mathrm{argmin}}_f L(\mathbf{X}, \mathbf{y}, f) ,\quad f \in \mathcal{F} \tag{1} fF∗:=argminfL(X,y,f),f∈F(1)
那么,怎样得到更近似真正 f ∗ f^* f∗的函数呢?唯一合理的可能性是,我们需要设计一个更强大的架构 F ′ \mathcal{F}' F′。换句话说,我们预计 f F ′ ∗ f^*_{\mathcal{F}'} fF′∗比 f F ∗ f^*_{\mathcal{F}} fF∗“更近似”。然而,如果 F ⊈ F ′ \mathcal{F} \not\subseteq \mathcal{F}' F⊆F′,则无法保证新的体系“更近似”。事实上, f F ′ ∗ f^*_{\mathcal{F}'} fF′∗可能更糟:如图1所示,对于非嵌套函数(non-nested function)类,较复杂的函数类并不总是向“真”函数 f ∗ f^* f∗靠拢(复杂度由 F 1 \mathcal{F}_1 F1向 F 6 \mathcal{F}_6 F6递增)。在图1的左边,虽然 F 3 \mathcal{F}_3 F3比 F 1 \mathcal{F}_1 F1更接近 f ∗ f^* f∗,但 F 6 \mathcal{F}_6 F6却离的更远了。相反对于图1右侧的嵌套函数(nested function)类 F 1 ⊆ … ⊆ F 6 \mathcal{F}_1 \subseteq \ldots \subseteq \mathcal{F}_6 F1⊆…⊆F6,我们可以避免上述问题。

因此,只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function) f ( x ) = x f(\mathbf{x}) = \mathbf{x} f(x)=x,新模型和原模型将同样有效。同时,由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。
针对这一问题,何恺明等人提出了残差网络(ResNet)。它在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。于是,残差块(residual blocks)便诞生了,这个设计对如何建立深层神经网络产生了深远的影响。凭借它,ResNet赢得了2015年ImageNet大规模视觉识别挑战赛。
二、残差块
让我们聚焦于神经网络局部:如图2所示,假设我们的原始输入为 x x x,而希望学出的理想映射为 f ( x ) f(\mathbf{x}) f(x)(作为图2上方激活函数的输入)。图2左图虚线框中的部分需要直接拟合出该映射 f ( x ) f(\mathbf{x}) f(x),而右图虚线框中的部分则需要拟合出残差映射 f ( x ) − x f(\mathbf{x}) - \mathbf{x} f(x)−x。残差映射在现实中往往更容易优化。以本节开头提到的恒等映射作为我们希望学出的理想映射 f ( x ) f(\mathbf{x}) f(x),我们只需将图2中右图虚线框内上方的加权运算(如仿射)的权重和偏置参数设成0,那么 f ( x ) f(\mathbf{x}) f(x)即为恒等映射。实际中,当理想映射 f ( x ) f(\mathbf{x}) f(x)极接近于恒等映射时,残差映射也易于捕捉恒等映射的细微波动。图2右图是ResNet的基础架构–残差块(residual block)。在残差块中,输入可通过跨层数据线路更快地向前传播。

ResNet沿用了VGG完整的 3 × 3 3\times 3 3×3卷积层设计。残差块里首先有2个有相同输出通道数的 3 × 3 3\times 3 3×3卷积层。每个卷积层后接一个批量规范化层和ReLU激活函数。然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。如果想改变通道数,就需要引入一个额外的 1 × 1 1\times 1 1×1卷积层来将输入变换成需要的形状后再做相加运算。残差块的实现如下:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lclass Residual(nn.Module): #@savedef __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)
如图3所示,此代码生成两种类型的网络:一种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。另一种是当use_1x1conv=True时,添加通过 1 × 1 1 \times 1 1×1卷积调整通道和分辨率。

下面我们来查看输入和输出形状一致的情况。
blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
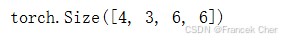
我们也可以在增加输出通道数的同时,减半输出的高和宽。
blk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shape

三、ResNet模型
ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的 7 × 7 7 \times 7 7×7卷积层后,接步幅为2的 3 × 3 3 \times 3 3×3的最大汇聚层。不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
GoogLeNet在后面接了4个由Inception块组成的模块。ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
下面我们来实现这个模块。注意,我们对第一个模块做了特别处理。
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk
接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(), nn.Linear(512, 10))
每个模块有4个卷积层(不包括恒等映射的 1 × 1 1\times 1 1×1卷积层)。加上第一个 7 × 7 7\times 7 7×7卷积层和最后一个全连接层,共有18层。因此,这种模型通常被称为ResNet-18。通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。图4描述了完整的ResNet-18。

在训练ResNet之前,让我们观察一下ResNet中不同模块的输入形状是如何变化的。在之前所有架构中,分辨率降低,通道数量增加,直到全局平均汇聚层聚集所有特征。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)

四、训练模型
同之前一样,我们在Fashion-MNIST数据集上训练ResNet。
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
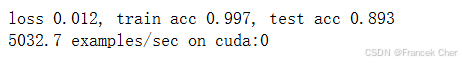

小结
- 学习嵌套函数(nested function)是训练神经网络的理想情况。在深层神经网络中,学习另一层作为恒等映射(identity function)较容易(尽管这是一个极端情况)。
- 残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零。
- 利用残差块(residual blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播。
- 残差网络(ResNet)对随后的深层神经网络设计产生了深远影响。
相关文章:
【现代深度学习技术】现代卷积神经网络06:残差网络(ResNet)
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

SpringBoot分布式项目订单管理实战:Mybatis最佳实践全解
一、架构设计与技术选型 典型分布式订单系统架构: [网关层] → [订单服务] ←→ [分布式缓存]↑ ↓ [用户服务] [支付服务]↓ ↓ [MySQL集群] ← [分库分表中间件]技术栈组合: Spring Boot 3.xMybatis-Plus 3.5.xShardingSpher…...

《异常检测——从经典算法到深度学习》30. 在线服务系统中重复故障的可操作和可解释的故障定位
《异常检测——从经典算法到深度学习》 0 概论1 基于隔离森林的异常检测算法 2 基于LOF的异常检测算法3 基于One-Class SVM的异常检测算法4 基于高斯概率密度异常检测算法5 Opprentice——异常检测经典算法最终篇6 基于重构概率的 VAE 异常检测7 基于条件VAE异常检测8 Donut: …...

题解:蓝桥杯 2023 省 B 接龙数列 - dp + 哈希map
题解:蓝桥杯 2023 省 B 接龙数列 题目传送门 P9242 [蓝桥杯 2023 省 B] 接龙数列 一、题目描述 给定一个长度为N的整数数列,我们需要计算最少删除多少个数,可以使剩下的序列成为接龙序列。接龙序列的定义是:对于序列中相邻的两…...

RAG 优化:高效解析并接入图文、表格密集型文档
写在前面 检索增强生成 (Retrieval-Augmented Generation, RAG) 已成为构建智能问答、文档摘要、内容创作等应用的利器。然而,标准的 RAG 流程往往假设输入是纯文本。当我们面对现实世界中更常见的文档——那些充斥着大量图片、图表和表格的报告、手册、论文或网页时,传统的…...

nut-ui下拉选的实现方式:nut-menu
nut-ui下拉选的实现方式:nut-menu 官方文档:https://nutui.jd.com/h5/vue/4x/#/zh-CN/component/menu 案例截图: nut-tab选项卡组件实现: 官方组件地址:https://nutui.jd.com/h5/vue/4x/#/zh-CN/component/tabs nut…...

HTML中数字和字母不换行显示
HTML中数字和字母不换行显示的默认行为及如何通过CSS的word-wrap和word-break属性进行调整。 在HTML中标签中的数字和字母默认是不换行的,如果要将他们换行,在CSS中添加”word-wrap: break-word;” 即可解决 语法:word-wrap: normal|break-w…...

鸿蒙NEXT小游戏开发:扫雷
1. 引言 本文将介绍如何使用鸿蒙NEXT框架开发一个简单的扫雷游戏。通过本案例,您将学习到如何利用鸿蒙NEXT的组件化特性、状态管理以及用户交互设计来构建一个完整的游戏应用。 2. 环境准备 电脑系统:windows 10 工程版本:API 12 真机&…...

【doris】Apache Doris简介
目录 1. 概述2. 技术特点2.1 高性能查询2.2 实时数据导入2.3 易于使用2.4 高可扩展性2.5 数据模型2.6 容错性 3. 适用场景4. 部署与架构4.1 部署方式4.2 架构特点 5. 优势 1. 概述 1.Apache Doris(原名Palo)最早诞生于百度广告报表业务,2017…...

LangChain4j 入门(二)
LangChain 整合 SpringBoot 下述代码均使用 阿里云百炼平台 提供的模型。 创建项目,引入依赖 通过 IDEA 创建 SpringBoot 项目,并引入 Spring Web 依赖,SpringBoot 推荐使用 3.x 版本。 引入 LangChain4j 和 WebFlux 依赖 <!--阿里云 D…...
对输入的音频数据进行加密处理,通过UDP发送加密后的音频数据)
小智机器人关键函数解析:MqttProtocol::SendAudio()对输入的音频数据进行加密处理,通过UDP发送加密后的音频数据
MqttProtocol::SendAudio()对输入的音频数据进行加密处理,通过UDP发送加密后的音频数据。 源码: void MqttProtocol::SendAudio(const std::vector<uint8_t>& data) {// 使用互斥锁保护临界区,确保同一时间只有一个线程可以访问该…...

npm i 失败
当npm i 失败 且提示下面的错误 尝试降低npm 的版本 npm install npm6.14.15 -g...

音视频基础(音视频的录制和播放原理)
文章目录 一、录制原理**1. 音视频数据解析****2. 音频处理流程****3. 视频处理流程****4. 同步控制****5. 关键技术点****总结** 二、播放原理**1. 音视频数据解析****2. 音频处理流程****3. 视频处理流程****4. 同步控制****5. 关键技术点****总结** 一、录制原理 这张图展示…...

CoAP Shell 笔记
CoAP Shell 笔记 1. 概述 CoAP (Constrained Application Protocol) 是一种专为物联网 (IoT) 中资源受限的节点和网络设计的 RESTful Web 传输协议。CoAP Shell 是一个基于命令行的交互式工具,用于与支持 CoAP 的服务器进行交互。 2. 主要功能 协议支持ÿ…...

回溯(子集型):分割回文串
一、多维递归 -> 回溯 1.1:17. 电话号码的字母组合(力扣hot100) 代码: mapping ["","", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv&qu…...

2022年蓝桥杯第十三届CC++大学B组真题及代码
目录 1A:九进制转十进制 2B:顺子日期(存在争议) 3C:刷题统计 解析代码(模拟) 4D:修剪灌木 解析代码(找规律) 5E:X进制减法 解析代码1&…...

1.oracle修改配置文件
1.找到oracle的安装路径 D:\app\baozi\product\11.2.0\dbhome_1\NETWORK\ADMIN ,修改下面的两个文件。如果提示没有权限,可以先把这两个文件复制到桌面,修改完后,在复制回来。 2.查看自己电脑的主机名, 右击 - 此电脑 …...

通义万相2.1 你的视频创作之路
通义万相2.1的全面介绍 一、核心功能与技术特点 通义万相2.1是阿里巴巴达摩院研发的多模态生成式AI模型,以视频生成为核心,同时支持图像、3D内容及中英文文字特效生成。其核心能力包括: 复杂动作与物理规律建模 能够稳定生成包含人体旋转、…...

Muduo网络库实现 [四] - Channel模块
设计思路 具体来说每一个套接字都会对应一个 Channel 对象,用于对它的事件进行管理。可以对于描述符的监控事件在用户态更容易维护,以及触发事件后的操作流程更加的清晰 Channel模块是用于对一个描述符所需要监控的事件以及事件触发之后要执行的回调函…...

“自动驾驶背后的数学” 专栏导读
专栏链接: 自动驾驶背后的数学 专栏以“自动驾驶背后的数学”为主题,从基础到深入,再到实际应用和未来展望,全面解析自动驾驶技术中的数学原理。开篇用基础数学工具搭建自动驾驶的整体框架,吸引儿童培养兴趣࿰…...

XSS 攻击(详细)
目录 引言 一、XSS 攻击简介 二、XSS 攻击类型 1.反射型 XSS 2.存储型 XSS 3.基于 DOM 的 XSS 4.Self - XSS 三、XSS 攻击技巧 1.基本变形 2.事件处理程序 3.JS 伪协议 4.编码绕过 5.绕过长度限制 6.使用标签 四、XSS 攻击工具与平台 1.XSS 攻击平台 2.BEEF 五…...

K8s负载均衡全解析:从入门到实战的完整指南
Kubernetes(K8s)作为容器编排的标准,其负载均衡机制是构建高可用、高弹性应用的关键。本文将全面介绍K8s负载均衡的核心概念、实现方式及最佳实践,帮助开发者和运维人员构建稳定高效的云原生应用。 一、K8s负载均衡的基础概念 在Kubernetes生态系统中,负载均衡是指将工作负…...

《ZooKeeper Zab协议深度剖析:构建高可用分布式系统的基石》
《ZooKeeper Zab协议深度剖析:构建高可用分布式系统的基石》 一、分布式协调的挑战与ZooKeeper的解决方案 1.1 分布式系统一致性难题 #mermaid-svg-iigak7YlgEw7o6lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-sv…...

OpenCV 图形API(6)将一个矩阵(或图像)与一个标量值相加的函数addC()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 addC 函数将给定的标量值加到给定矩阵的每个元素上。该功能可以用矩阵表达式替换: dst src1 c \texttt{dst} \texttt{src1} \te…...

同步SVPWM调制策略的初步学习记录
最近项目需要用到一些同步调制SVPWM相关的内容(现在的我基本都是项目驱动了),因此对该内容进行一定的学习。 1 同步SVPWM调制的背景 我们熟知的一些知识是:SVPWM(空间矢量脉宽调制)是一种用于逆变器的调制…...
(程序替换、exec流程示意图、核心特性))
六十天Linux从0到项目搭建(第十五天)(程序替换、exec流程示意图、核心特性)
1 为什么要有程序替换? 程序替换(Process Replacement)是操作系统中一个关键机制,它的核心目的是:让一个正在运行的进程(通常是子进程)停止执行当前代码,转而加载并执行一个全新的程…...

排序算法3-交换排序
目录 1.常见排序算法 2.排序算法的预定函数 2.1交换函数 2.2测试算法运行时间的函数 2.3已经实现过的排序算法 3.交换排序的实现 3.1冒泡排序 3.2快速排序 3.2.1递归的快速排序 3.2.1.1hoare版本的排序 3.2.1.2挖坑法 3.2.1.3lomuto前后指针法 3.2.2非递归版本的快…...

【Qt】数据库管理
数据库查询工具开发学习笔记 一、项目背景与目标 背景:频繁编写数据库查询语句,希望通过工具简化操作,提升效率。 二、总体设计思路 1. 架构设计 MVC模式:通过Qt控件实现视图(UI),业务逻辑…...

Ant Design Vue 中的table表格高度塌陷,造成行与行不齐的问题
前言: Ant Design Vue: 1.7.2 Vue2 less 问题描述: 在通过下拉框选择之后,在获取接口数据,第一列使用了fixed:left,就碰到了高度塌陷,查看元素的样式结果高度不一致,如&#x…...

面经-项目
项目 项目(重点)问题1:描述在网页中题目点击提交后到题目结果出现的一系列后台反应【1】如何获取到用户提交的代码的?【2】_1. 题目细节都有哪些?【2】_2. 题目信息怎么存储的?【3】负载均衡算法的实现?【4】oj_server怎么连接对应的compile_server(编译主机)的?【5】oj_…...