学习笔记—数据结构—二叉树(链式)
目录
二叉树(链式)
概念
结构
初始化
遍历
前序遍历
中序遍历
后序遍历
层序遍历
结点个数
叶子结点个数
第k层结点个数
深度/高度
查找值为x的结点
销毁
判断是否为完整二叉树
总结
头文件Tree.h
Tree.c
测试文件test.c
补充文件Queue.h
补充文件Queue.c
二叉树(链式)
概念
用链表来表示⼀棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址
结构
//二叉树结点的结构
typedef int BTDataType;
typedef struct BinaryTreeNode
{BTDataType data; //值域struct BinaryTreeNode* left; //左孩子struct BinaryTreeNode* right; //右孩子
}BTNode;
初始化
//初始化
BTNode* buyNode(BTDataType x)
{BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL){perror("mallor fail!");exit(1);}newnode->data = x;newnode->left = newnode->right = NULL;return newnode;
}遍历

前序遍历
前序遍历(Preorder Traversal 亦称先序遍历):访问根结点的操作发生在遍历其左右⼦树之前
访问顺序为:根结点、左子树、右子树
//前序遍历--根左右
void PreOrder(BTNode* root)
{if (root == NULL){return;}printf("%d ", root->data);PreOrder(root->left);PreOrder(root->right);
}中序遍历
中序遍历(Inorder Traversal):访问根结点的操作发生在遍历其左右子树之中(间)
访问顺序为:左子树、根结点、右子树
//中序遍历--左根右
void InOrder(BTNode* root)
{if (root == NULL){return;}InOrder(root->left);printf("%d ", root->data);InOrder(root->right);
}后序遍历
后序遍历(Postorder Traversal):访问根结点的操作发生在遍历其左右子树之后
访问顺序为:左子树、右子树、根结点
//后续遍历--左右根
void PostOrder(BTNode* root)
{if (root == NULL){return;}PostOrder(root->left);PostOrder(root->right);printf("%d ", root->data);}层序遍历
在二叉树的层序遍历是指按照树的层次顺序,从上到下、从左到右逐层访问二叉树的节点。这种遍历方式可以帮助我们了解二叉树的结构布局,特别是在处理树状数据结构时非常有用。
对于这么一个二叉树来说,我们通过层序遍历最后得到的是1 2 3 4 5 6
这里我们是不能通过递归来实现的
但是我们可以借助队列来实现这么一个结构
队列的结构是先进先出
恰好我们队列的底层结构就是链表来实现的,和这里的链式二叉树一样的
我们将之前写的Queue.c文件和Queue.h文件复制到我们链式二叉树的文件夹里面
typedef struct BinaryTreeNode* QDataType;
struct BinaryTreeNode*这个就是我们要保存在队列中的数据类型
之前的在队列中保存的数据类型是int类型
队列中存储的是堆节点的地址
那么存储的就是节点的指针,那么我们将这个类型重新定义
//层序遍历
void Levelorder(BTNode* root)
{//创建一个队列结构Queue q;QueueInit(&q);//进行初始化//第一步:让根节点直接入队列QueuePush(&q, root);//往队列中push根节点while (!Queuempty(&q))//只要队列不为空,我们就一直取队头数据{//取队头数据BTNode* front = QueueFront(&q);//将队头取出,返回值是节点的地址//打印对头printf("%d ", front->data);//让队头出队列QueuePop(&q);//那么此时的队列是空的//将队头节点的左右孩子入队列if (front->left)//如果这个节点的左孩子不是空的,那么我们将这个节点往队列中入{QueuePush(&q, front->left);}if (front->right)//如果这个节点的右孩子不是空的,那么我们将这个节点往队列中入{QueuePush(&q, front->right);}}QueueDestroy(&q);//销毁
}结点个数
利用递归的方法,左右子树调用,如果该节点为NULL 便会返回0,否则返回1。

// 二叉树结点个数
int BinaryTreeSize(BTNode* root)
{if (root == NULL){return 0;}//递归return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right);
}叶子结点个数

// 二叉树叶子结点个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}if (root->left ==NULL && root->right ==NULL){return 1;}//进行递归return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}第k层结点个数
假设查找第三层,K为3 ,每次递归K–,知道K== 1 的时候 返回1

// 二叉树第k层结点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}return BinaryTreeLevelKSize(root->left, (k - 1)) + BinaryTreeLevelKSize(root->right, (k - 1));
}深度/高度
利用 left和right记录左右子树的个数,然后比较 选择较大的一个。

// 二叉树的深度/高度
int BinaryTreeDepth(BTNode* root)
{if (root == NULL){return 0;}int leftDep = BinaryTreeDepth(root->left);int rightDep = BinaryTreeDepth(root->right);return leftDep > rightDep ? leftDep + 1 : rightDep + 1;
}查找值为x的结点
节点的查找,如果节点为NULL饭后NULL,如果此节点的data等于x,返回节点的地址。
// 二叉树查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL){return 0;}if (root->data == x){return 1;}BTNode* leftFind = BinaryTreeFind(root->left,x);if (leftFind){return leftFind;}BTNode* rightFind = BinaryTreeFind(root->right,x);if (leftFind){return rightFind;}return NULL;
}销毁

// 二叉树销毁
void BinaryTreeDestory(BTNode** root)
{if (*root == NULL){return 0;}BinaryTreeDestory(&((*root)->left));BinaryTreeDestory(&((*root)->right));free(*root);*root = NULL;
}判断是否为完整二叉树
除了最后一层,其它层的节点数达到最大,那么这个数就是完全二叉树
这里涉及到每层,那么这里还是要借助队列这么一个结构的
我们先取根节点放进队列,队列不为空,我们将队列中的节点取出来
然后将这个节点的左右孩子一起放进队列中去
我们再将队头取出,将队头的左右孩子放进去,如果孩子为空放个NULL进去
如果我们队列剩下的都是NULL的话,我们将队列中第一个NULL取出
那么我们取到的数据为空,取到为空的情况我们就跳出循环

//判断二叉树是否为完全二叉树
//借助队列
bool BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);//进行初始化//将二叉树根节点入队列QueuePush(&q, root);//往队列中push根节点while (!Queuempty(&q))//队列不为空,我们就循环取队头{BTNode* front = QueueFront(&q);//将队头取出QueuePop(&q);//让队头出队,保证下次取到的是最新的队头数据//如果我们取到的front是空的话if (front == NULL)//如果此时的队头是空的,那么我们就取不到左右孩子{break;}//将队头的左右孩子取出放到队列中QueuePush(&q, front->left);QueuePush(&q, front->right);}//此时队列不一定为空while (!Queuempty(&q))//只要队列不为空{BTNode* front = QueueFront(&q);//取队头QueuePop(&q);//出队列//如果我们在队列中剩下的节点中遇到了节点的话,那么这个树就不是一个完全二叉树了if (front != NULL){QueueDestroy(&q);//销毁return false;}}QueueDestroy(&q);//销毁//到这里就说明没有找到完全二叉树return true;
}总结
头文件Tree.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>//定义二叉树链式结构
//二叉树结点的结构
typedef int BTDataType;
typedef struct BinaryTreeNode
{BTDataType data; //值域struct BinaryTreeNode* left; //左孩子struct BinaryTreeNode* right; //右孩子
}BTNode;//前序遍历
void PreOrder(BTNode* root);
//中序遍历
void InOrder(BTNode* root);
//后续遍历
void PostOrder(BTNode* root);// 二叉树结点个数
int BinaryTreeSize(BTNode* root);
// 二叉树叶子结点个数
int BinaryTreeLeafSize(BTNode* root);
// 二叉树第k层结点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
// 二叉树的深度/高度
int BinaryTreeDepth(BTNode * root);
// 二叉树查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
// 二叉树销毁
void BinaryTreeDestory(BTNode** root);//层序遍历---借助数据结构(队列)
void Levelorder(BTNode* root);
//判断二叉树是否为完全二叉树
bool BinaryTreeComplete(BTNode* root);Tree.c
#include"Tree.h"
#include"Queue.h"
//前序遍历--根左右
void PreOrder(BTNode* root)
{if (root == NULL){return;}printf("%d ", root->data);PreOrder(root->left);PreOrder(root->right);
}//中序遍历--左根右
void InOrder(BTNode* root)
{if (root == NULL){return;}InOrder(root->left);printf("%d ", root->data);InOrder(root->right);
}//后续遍历--左右根
void PostOrder(BTNode* root)
{if (root == NULL){return;}PostOrder(root->left);PostOrder(root->right);printf("%d ", root->data);}// 二叉树结点个数
int BinaryTreeSize(BTNode* root)
{if (root == NULL){return 0;}//递归return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right);
}// 二叉树叶子结点个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}if (root->left ==NULL && root->right ==NULL){return 1;}//进行递归return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}// 二叉树第k层结点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}return BinaryTreeLevelKSize(root->left, (k - 1)) + BinaryTreeLevelKSize(root->right, (k - 1));
}// 二叉树的深度/高度
int BinaryTreeDepth(BTNode* root)
{if (root == NULL){return 0;}int leftDep = BinaryTreeDepth(root->left);int rightDep = BinaryTreeDepth(root->right);return leftDep > rightDep ? leftDep + 1 : rightDep + 1;
}// 二叉树查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL){return 0;}if (root->data == x){return 1;}BTNode* leftFind = BinaryTreeFind(root->left,x);if (leftFind){return leftFind;}BTNode* rightFind = BinaryTreeFind(root->right,x);if (leftFind){return rightFind;}return NULL;
}// 二叉树销毁
void BinaryTreeDestory(BTNode** root)
{if (*root == NULL){return 0;}BinaryTreeDestory(&((*root)->left));BinaryTreeDestory(&((*root)->right));free(*root);*root = NULL;
}//层序遍历
void Levelorder(BTNode* root)
{//创建一个队列结构Queue q;QueueInit(&q);//进行初始化//第一步:让根节点直接入队列QueuePush(&q, root);//往队列中push根节点while (!Queuempty(&q))//只要队列不为空,我们就一直取队头数据{//取队头数据BTNode* front = QueueFront(&q);//将队头取出,返回值是节点的地址//打印对头printf("%d ", front->data);//让队头出队列QueuePop(&q);//那么此时的队列是空的//将队头节点的左右孩子入队列if (front->left)//如果这个节点的左孩子不是空的,那么我们将这个节点往队列中入{QueuePush(&q, front->left);}if (front->right)//如果这个节点的右孩子不是空的,那么我们将这个节点往队列中入{QueuePush(&q, front->right);}}QueueDestroy(&q);//销毁
}//判断二叉树是否为完全二叉树
//借助队列
bool BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);//进行初始化//将二叉树根节点入队列QueuePush(&q, root);//往队列中push根节点while (!Queuempty(&q))//队列不为空,我们就循环取队头{BTNode* front = QueueFront(&q);//将队头取出QueuePop(&q);//让队头出队,保证下次取到的是最新的队头数据//如果我们取到的front是空的话if (front == NULL)//如果此时的队头是空的,那么我们就取不到左右孩子{break;}//将队头的左右孩子取出放到队列中QueuePush(&q, front->left);QueuePush(&q, front->right);}//此时队列不一定为空while (!Queuempty(&q))//只要队列不为空{BTNode* front = QueueFront(&q);//取队头QueuePop(&q);//出队列//如果我们在队列中剩下的节点中遇到了节点的话,那么这个树就不是一个完全二叉树了if (front != NULL){QueueDestroy(&q);//销毁return false;}}QueueDestroy(&q);//销毁//到这里就说明没有找到完全二叉树return true;
}测试文件test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"tree.h"BTNode* buyNode(BTDataType x)//创建一个节点
{BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL){perror("malloc fail!");exit(1);}newnode->data = x;newnode->left = newnode->right = NULL;return newnode;
}
void test01()
{BTNode* node1 = buyNode(1);BTNode* node2 = buyNode(2);BTNode* node3 = buyNode(3);BTNode* node4 = buyNode(4);/*BTNode* node5 = buyNode(5);BTNode* node6 = buyNode(6);*/node1->left = node2;node1->right = node3;node2->left = node4;/*node2->right = node5;node3->left = node6;*///前序遍历PreOrder(node1);// 1 2 4 3printf("\n");//中序遍历InOrder(node1);// 4 2 1 3//二叉树节点的个数printf("size:%d\n", BinaryTreeSize(node1));//4printf("size:%d\n", BinaryTreeSize(node2));//2// 二叉树叶子结点的个数printf("leaf size:%d\n", BinaryTreeLeafSize(node1));//第k层节点的个数printf("k size:%d\n", BinaryTreeLevelKSize(node1, 3));//二叉树的高度printf("depth/height :%d\n", BinaryTreeDepth(node1));//查找值为x的节点BTNode*find=BinaryTreeFind(node1, 5);printf("%s\n", find == NULL ? "没找到":"找到了");//层序遍历Levelorder(node1);//判断是否为完全二叉树bool ret = BinaryTreeComplete(node1);printf("%s\n", ret == false ? "不是完全二叉树" : "是完全二叉树");//二叉树的销毁BinaryTreeDestory(&node1);}
int main()
{test01();return 0;
}补充文件Queue.h
#pragma once#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>//定义队列结构
//typedef int QDataType;typedef struct BinaryTreeNode* QDataType;
//struct BinaryTreeNode*这个就是我们要保存在队列中的数据类型
//struct BinaryTreeNode*这个是个数据类型,和之前的
//之前的在队列中保存的数据类型是int类型
//因为我们在tree.h中将结构体类型重命名了
//那么我们可以这么写
//typedef struct BTNode* QDataType;typedef struct QueueNode
{QDataType data;struct QueueNode* next;}QueueNode;typedef struct Queue
{QueueNode* phead;//指向头节点的指针---队头--删除数据QueueNode* ptail;//指向尾节点的指针---队尾--插入数据int size;//保存队列有效个数
}Queue;//初始化
void QueueInit(Queue* pq);//入队列,队尾 插入数据
void QueuePush(Queue* pq, QDataType x);//出队列,队头 删除数据
void QueuePop(Queue* pq);//判断队列是否为空
bool Queuempty(Queue* pq);//取队头数据
QDataType QueueFront(Queue* pq);//取队尾数据
QDataType QueueBack(Queue* pq);//队列有效元素个数
int QueueSize(Queue* pq);//队列的销毁
void QueueDestroy(Queue* pq);
补充文件Queue.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Queue.h"//初始化
void QueueInit(Queue* pq)
{assert(pq);//传过来的不能是空指针 pq->phead = pq->ptail = NULL;//空的队列pq->size = 0;
}//判断队列是否为空
bool Queuempty(Queue* pq)
{assert(pq);return pq->phead == NULL && pq->ptail == NULL;//如果后面的表达式成立,那么就是真,返回的是true//就是说如果这里的是空队列的话,那么就返回的是true
}//入队列,队尾 插入数据
void QueuePush(Queue* pq, QDataType x)
{assert(pq);//申请新节点QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));//申请一个节点大小的空间if (newnode == NULL){perror("malloc dail!");exit(1);}//对newnode进行初始化操作newnode->data = x;newnode->next = NULL;if (pq->phead == NULL)//说明队列为空{pq->phead = pq->ptail = newnode;//那么此时的newnode不仅是头结点也是尾节点}else//队列不为空{pq->ptail->next = newnode;//那么此时的newnode 就是新的ptailpq->ptail = newnode;}pq->size++;
}//出队列,队头 删除数据 从头结点开始删除数据
void QueuePop(Queue* pq)
{assert(pq);//队列为空(不可删除数据,因为没有数据)//队列不为空(可删除数据)assert(!Queuempty(pq));//队列为空白的话就报错//处理只有一个节点的情况,避免ptail变成野指针//判断只有一个节点的情况if (pq->ptail == pq->phead)//头尾指针相同,说明只有一个节点{free(pq->phead);//随便释放pq->phead = pq->ptail = NULL;}else//处理多个节点的情况{//删除队头元素//那么我们现将下个节点的位置进行保存QueueNode* next = pq->phead->next;//存储好之后我们直接将头结点进行释放free(pq->phead);pq->phead = next;//那么之前存的next就是新的头结点了}pq->size--;
}//取队头数据
QDataType QueueFront(Queue* pq)//返回队头数据
{assert(pq);assert(!Queuempty(pq));//队列不为空return pq->phead->data;//将队头里面的数据直接返回就行了
}//取队尾数据
QDataType QueueBack(Queue* pq)
{assert(pq);assert(!Queuempty(pq));//队列不为空return pq->ptail->data;
}//队列有效元素个数
int QueueSize(Queue* pq)
{assert(pq);//下面这种遍历的话效率太低了//int size = 0;//定义一个指针进行遍历//QueueNode* pcur = pq->phead;//指向队列的头结点//while (pcur)//pcur不为空就往后走//{// size++;// pcur = pcur->next;//}//return size;return pq->size;
}//队列的销毁
void QueueDestroy(Queue* pq)
{assert(pq);//assert(!Queuempty(pq));//队列不为空//遍历QueueNode* pcur = pq->phead;while (pcur){//销毁之前先把下个节点进行保存QueueNode* next = pcur->next;free(pcur);//将Pcur销毁之后,那么之前保存的next就是新的头结点pcur = next;}pq->phead = pq->ptail = NULL;pq->size = 0;
}相关文章:
学习笔记—数据结构—二叉树(链式)
目录 二叉树(链式) 概念 结构 初始化 遍历 前序遍历 中序遍历 后序遍历 层序遍历 结点个数 叶子结点个数 第k层结点个数 深度/高度 查找值为x的结点 销毁 判断是否为完整二叉树 总结 头文件Tree.h Tree.c 测试文件test.c 补充文件Qu…...

微前端 - 以无界为例
一、微前端核心概念 微前端是一种将单体前端应用拆分为多个独立子应用的架构模式,每个子应用可独立开发、部署和运行,具备以下特点: 技术栈无关性:允许主应用和子应用使用不同框架(如 React Vue)。独立部…...

DIskgenius使用说明
文章目录 一、概述1. 软件简介2. 系统要求 二、核心功能1. 分区管理(1) 查看磁盘分区(2) 创建与删除分区(3) 调整分区大小(4) 格式化分区 2. 数据恢复(1) 恢复已删除文件(2) 恢复丢失分区(3) 恢复误格式化分区 3. 磁盘复制(1) 克隆磁盘(2) 磁盘镜像 4. 文件操作(1) 文件复制与移…...
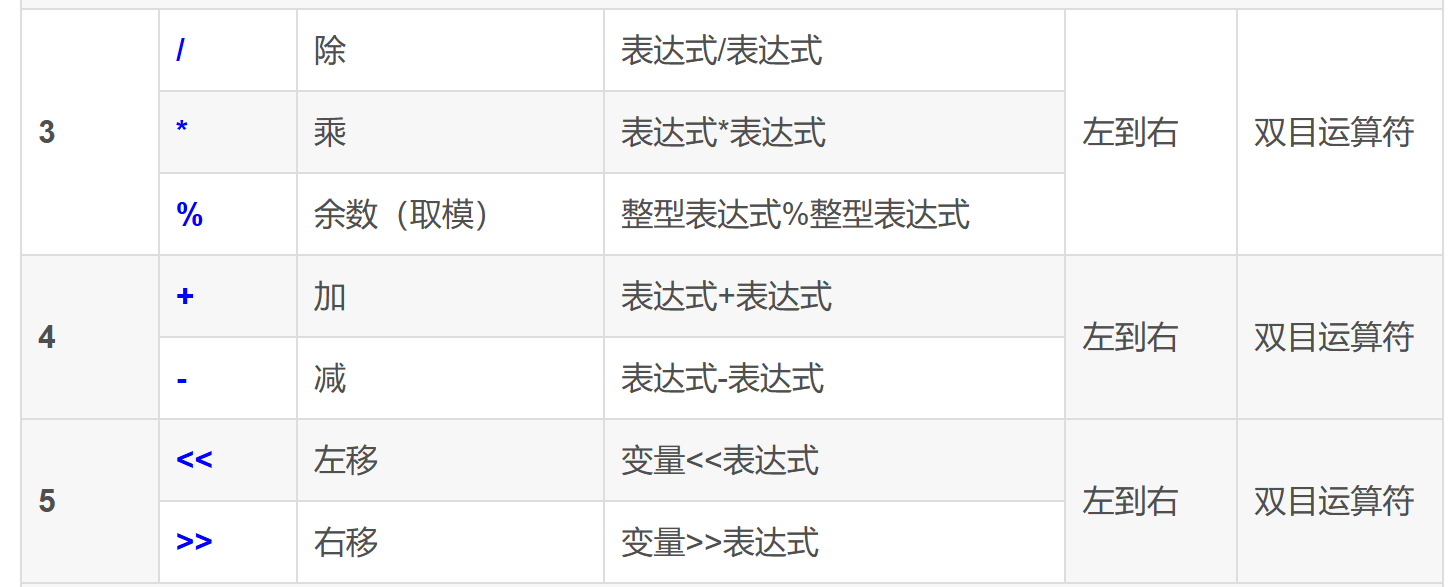
深入理解指针5
sizeof和strlen的对比 sizeof的功能 **sizeof是**** 操作符****,用来**** 计算****变量或类型或数组所占**** 内存空间大小****,**** 单位是字节,****他不管内存里是什么数据** int main() {printf("%zd\n", sizeof(char));p…...

一文详解QT环境搭建:Windows使用CLion配置QT开发环境
在当今的软件开发领域,跨平台应用的需求日益增长,Qt作为一款流行的C图形用户界面库,因其强大的功能和易用性而备受开发者青睐。与此同时,CLion作为一款专为C/C打造的强大IDE,提供了丰富的特性和高效的编码体验。本文将…...

NE 综合实验3:基于 IP 配置、链路聚合、VLAN 管理、路由协议及安全认证的企业网络互联与外网访问技术实现(H3C)
综合实验3 实验拓扑 设备名称接口IP地址R1Ser_1/0与Ser_2/0做捆绑MP202.100.1.1/24G0/0202.100.2.1/24R2Ser_1/0与Ser_2/0做捆绑MP202.100.1.2/24G0/0172.16.2.1/24G0/1172.16.1.1/24G0/2172.16.5.1/24R3G5/0202.100.2.2/24G0/0172.16.2.2/24G0/1172.16.3.1/24G0/2172.16.7.1/…...
:机器学习中的“真相”基准)
Ground Truth(真实标注数据):机器学习中的“真相”基准
Ground Truth:机器学习中的“真相”基准 文章目录 Ground Truth:机器学习中的“真相”基准引言什么是Ground Truth?Ground Truth的重要性1. 模型训练的基础2. 模型评估的标准3. 模型改进的指导 获取Ground Truth的方法1. 人工标注2. 众包标注…...

双重token自动续期解决方案
Token自动续期实现方案详解 Token自动续期是提升用户体验和保障系统安全的关键机制,其核心在于无感刷新和安全可控。以下从原理、实现方案、安全措施和最佳实践四个维度展开说明: 一、核心原理:双Token机制 Token自动续期通常采用 Access …...

我与数学建模之启程
下面的时间线就是从我的大二上开始 9月开学就迎来了本科阶段最重要的数学建模竞赛——国赛,这个比赛一般是在9月的第二周开始。 2021年国赛是我第一次参加国赛,在报名前我还在纠结队友,后来经学长推荐找了另外两个学长。其实第一次国赛没啥…...
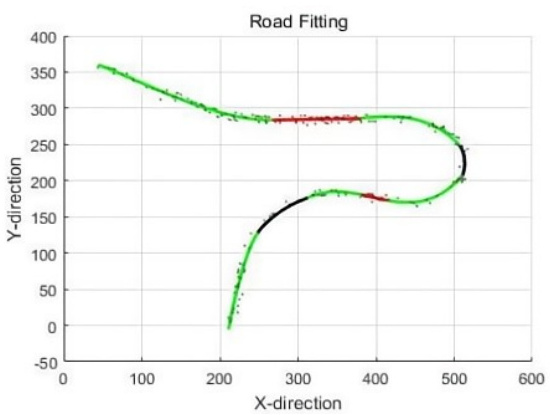
多段圆弧拟合离散点实现切线连续
使用多段圆弧来拟合一个由离散点组成的曲线,并且保证切线连续。也就是说,生成的每一段圆弧之间在连接点处必须有一阶导数连续,也就是切线方向相同。 点集分割 确保每个段的终点是下一段的起点,相邻段共享连接点,避免连接点位于数…...

烧结银:解锁金刚石超强散热潜力
烧结银:解锁金刚石超强散热潜力 在材料科学与热管理领域,金刚石凭借超高的热导率,被誉为 “散热之王”,然而,受限于其特殊的性质,金刚石在实际应用中难以充分发挥散热优势。而烧结银AS9335的出现&#x…...

【蓝桥杯】第十四届C++B组省赛
⭐️个人主页:小羊 ⭐️所属专栏:蓝桥杯 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 试题A:日期统计试题B:01串的熵试题C:冶炼金属试题D:飞机降落试题E:接…...

企业级海外网络专线行业应用案例及服务商推荐
在全球化业务快速发展的今天,传统网络技术已难以满足企业需求。越来越多企业开始选择新型海外专线解决方案,其中基于SD-WAN技术的企业级海外网络专线备受关注。这类服务不仅能保障跨国数据传输,还能根据业务需求灵活调整网络配置。接下来我们…...

阿里云服务器安装docker以及mysql数据库
(1) 官方下载路径 官方下载地址: Index of linux/static/stable/x86_64/阿里云镜像地址: https://mirrors.aliyun.com/docker-ce/下载最新的 Docker 二进制文件:wget https://download.docker.com/linux/static/stable/x86_64/docker-20.10.23.tgz登录到阿里云服务…...
)
力扣经典算法篇-5-多数元素(哈希统计,排序,摩尔投票法)
题干: 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入:nums [3,2,3] 输出&…...

axios介绍以及配置
Axios 是一个基于 Promise 的 HTTP 客户端,用于浏览器和 Node.js 环境中进行 HTTP 请求。 一、特点与基本用法 1.特点 浏览器兼容性好:能在多种现代浏览器中使用,包括 Chrome、Firefox、Safari 等。支持 Promise API:基于 Prom…...

深入解析:HarmonyOS Design设计语言的核心理念
深入解析:HarmonyOS Design设计语言的核心理念 在当今数字化迅速发展的时代,用户对操作系统的体验要求越来越高。华为的HarmonyOS(鸿蒙操作系统)应运而生,旨在为用户提供全场景、全设备的智慧体验。其背后的设计语言—…...

大数据技术之Scala:特性、应用与生态系统
摘要 Scala 作为一门融合面向对象编程与函数式编程范式的编程语言,在大数据领域展现出独特优势。本文深入探讨 Scala 的核心特性,如函数式编程特性、类型系统以及与 Java 的兼容性等。同时,阐述其在大数据处理框架(如 Apache Spa…...
:竞价指标剖析与流量对接要点)
程序化广告行业(47/89):竞价指标剖析与流量对接要点
程序化广告行业(47/89):竞价指标剖析与流量对接要点 大家好!一直以来,我都希望能和大家一同深入探索程序化广告行业的奥秘,这也是我持续撰写这一系列博客的动力。今天,咱们接着来剖析程序化广告…...

dfs记忆化搜索刷题 + 总结
文章目录 记忆化搜索 vs 动态规划斐波那契数题解代码 不同路径题解代码 最长递增子序列题解代码 猜数字大小II题解代码 矩阵中的最长递增路径题解代码 总结 记忆化搜索 vs 动态规划 1. 记忆化搜索:有完全相同的问题/数据保存起来,带有备忘录的递归 2.记忆…...

vue2 全局封装axios统一管理api
在vue项目中,经常会使用到axios来与后台进行数据交互,axios丰富的api满足我们基本的需求。但是对于项目而言,每次都需要对异常进行捕获或者处理的话,代码会很繁重冗余。我们需要将其公共部分封装起来,比如异常处理&…...

大模型有哪些算法
大模型(Large-scale Models)通常指参数量大、架构复杂、在特定任务或领域表现出色的深度学习模型。这些模型的算法核心往往基于Transformer 架构及其变体,同时结合了大规模数据、硬件加速和优化技巧。以下是当前主流大模型及其核心算法的分类…...

【Linux】进程的详讲(中上)
目录 📖1.什么是进程? 📖2.自己写一个进程 📖3.操作系统与内存的关系 📖4.PCB(操作系统对进程的管理) 📖5.真正进程的组成 📖6.形成进程的过程 📖7、Linux环境下的进程知识 7.1 task_s…...

Python Cookbook-4.17 字典的并集与交集
任务 给定两个字典,需要找到两个字典都包含的键(交集),或者同时属于两个字典的键(并集)。 解决方案 有时,尤其是在Python2.3中,你会发现对字典的使用完全是对集合的一种具体化的体现。在这个要求中,只需要考虑键&am…...
优选算法的巧思之径:模拟专题
专栏:算法的魔法世界 个人主页:手握风云 目录 一、模拟 二、例题讲解 2.1. 替换所有的问号 2.2. 提莫攻击 2.3. Z字形变换 2.4. 外观数列 2.5. 数青蛙 一、模拟 模拟算法说简单点就是照葫芦画瓢,现在草稿纸上模拟一遍算法过程…...

【云服务器】在Linux CentOS 7上快速搭建我的世界 Minecraft 服务器搭建,并实现远程联机,详细教程
【云服务器】在Linux CentOS 7上快速搭建我的世界 Minecraft 服务器搭建,详细详细教程 一、 服务器介绍二、下载 Minecraft 服务端三、安装 JDK 21四、搭建服务器五、本地测试连接六、添加服务,并设置开机自启动 前言: 推荐使用云服务器部署&…...

文本分析(非结构化数据挖掘)——特征词选择(基于TF-IDF权值)
TF-IDF是一种用于信息检索和文本挖掘的常用加权算法,用于评估一个词在文档或语料库中的重要程度。它结合了词频(TF)和逆文档频率(IDF)两个指标,能够有效过滤掉常见词(如“的”、“是”等&#x…...

【JavaSE】小练习 —— 图书管理系统
【JavaSE】JavaSE小练习 —— 图书管理系统 一、系统功能二、涉及的知识点三、业务逻辑四、代码实现4.1 book 包4.2 user 包4.3 Main 类4.4 完善管理员菜单和普通用户菜单4.5 接着4.4的管理员菜单和普通用户菜单,进行操作选择(1查找图书、2借阅图书.....…...

命令模式介绍及应用案例
命令模式介绍 命令模式(Command Pattern) 是一种行为设计模式,它将请求封装为一个对象,从而使你可以用不同的请求对客户进行参数化,并且支持请求的排队、记录日志、撤销操作等功能。命令模式的核心思想是将“请求”封…...

多线程(多线程案例)(续~)
目录 一、单例模式 1. 饿汉模式 2. 懒汉模式 二、阻塞队列 1. 阻塞队列是什么 2. 生产者消费者模型 3. 标准库中的阻塞队列 4. 自实现阻塞队列 三、定时器 1. 定时器是什么 2. 标准库中的定时器 欢迎观看我滴上一篇关于 多线程的博客呀,直达地址…...