Kafka消息丢失全解析!原因、预防与解决方案
作为一名高并发系统开发工程师,在使用消息中间件的过程中,无法避免遇到系统中消息丢失的问题,而Kafka作为主流的消息队列系统,消息丢失问题尤为常见。
在这篇文章中,将深入浅出地分析Kafka消息丢失的各种情况,并提供真实且实用的解决方案。
一、Kafka基础知识
Kafka是什么?
Kafka是一个分布式的流处理平台,被广泛用于构建实时数据管道和流式应用。它具有高吞吐量、可靠性、可扩展性的特点,已成为大数据生态系统中不可或缺的组件。
Kafka的核心概念

在上面的架构图中,Kafka的几个重要组件包括:
- Broker - Kafka服务器,负责接收、存储消息
- Producer - 生产者,负责发送消息到Kafka
- Consumer - 消费者,负责从Kafka获取消息并处理
- Topic - 主题,Kafka消息的逻辑分类
- Partition - 分区,每个Topic可以有多个分区,分布在不同Broker上
- Zookeeper - 管理Kafka集群元数据和协调
二、Kafka消息丢失的情况分析
Kafka虽然以高可靠性著称,但在三个环节仍可能发生消息丢失:
- 生产者端:消息发送失败或确认机制配置不当
- Broker端:服务器宕机或磁盘故障
- 消费者端:提交偏移量后处理消息失败
1. 生产者端消息丢失
生产者端消息丢失通常发生在以下情况:

生产者端丢失原因分析
-
Fire and Forget(发后即忘)模式
- 当使用acks=0配置时,生产者不等待服务器的确认就认为消息发送成功
- 如果网络出现问题或Broker宕机,消息会丢失但生产者不会感知
-
异步发送未处理回调
- 使用异步发送时,如果回调中未正确处理发送失败的情况
- 消息发送失败但程序继续执行,导致消息丢失
-
重试次数不足
- 当网络抖动或Broker临时不可用,默认重试次数不足可能导致消息丢失
2. Broker端消息丢失
Broker端的消息丢失主要与以下因素有关:

Broker端丢失原因分析
-
副本因子(replication.factor)设置过低
- 当副本因子为1时,表示数据只存在于一个Broker上
- 如果该Broker宕机,数据将完全丢失
-
最小同步副本(min.insync.replicas)配置不当
- 如果配置为1,则只要Leader副本确认就会返回ack
- 如果在数据同步到follower前Leader宕机,数据会丢失
-
允许非同步副本选举为Leader
- 默认配置unclean.leader.election.enable=false
- 如果设置为true,可能选举落后的副本作为新Leader,导致数据丢失
3. 消费者端消息丢失
消费者端丢失主要发生在以下情况:
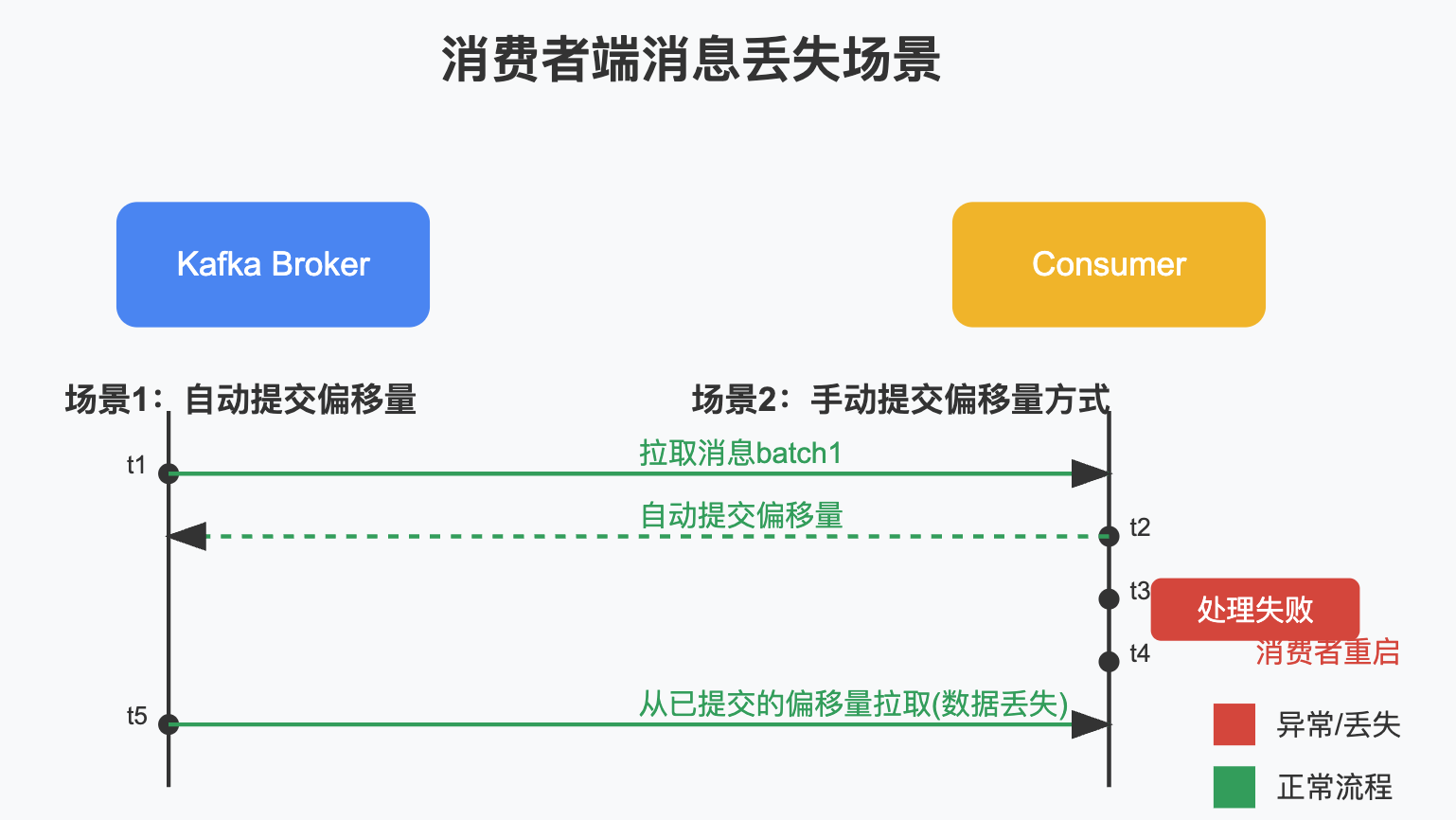
消费者端丢失原因分析
-
自动提交偏移量
- 默认情况下,消费者会自动提交偏移量(enable.auto.commit=true)
- 如果提交了偏移量但处理消息过程中失败,重启后会从已提交的偏移量开始消费,导致消息丢失
-
先提交偏移量再处理消息
- 如果手动提交偏移量时,在消息处理完成前就提交
- 处理过程中出现异常,消息实际未处理成功但偏移量已提交
三、如何防止Kafka消息丢失
现在让我们来看看如何在各环节防止消息丢失。
1. 生产者端防止消息丢失
// 1. 生产者配置示例
Properties props = new Properties();
// 设置broker集群地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092,broker3:9092");
// 设置key/value序列化器
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 设置确认机制为all,所有ISR副本都确认才算成功
props.put(ProducerConfig.ACKS_CONFIG, "all");
// 设置重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 10);
// 设置重试间隔
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
// 幂等性,避免消息重复
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 设置拦截器(可选)
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.example.kafka.MyProducerInterceptor");// 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 2. 同步发送示例
try {ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");// 同步发送,等待服务器确认RecordMetadata metadata = producer.send(record).get();System.out.println("Message sent successfully to partition " + metadata.partition() + " offset " + metadata.offset());
} catch (Exception e) {// 处理发送异常System.err.println("Error sending message: " + e.getMessage());// 可以进行重试或其他补偿措施
}// 3. 异步发送示例(带回调处理)
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception != null) {// 发送失败,进行错误处理System.err.println("Failed to send message: " + exception.getMessage());// 可以将消息保存到本地,稍后重试saveToLocalStorage(record);} else {// 发送成功System.out.println("Message sent successfully to partition " + metadata.partition() + " offset " + metadata.offset());}}
});// 关闭生产者
producer.close();
关键配置:
- acks=all:确保消息被所有同步副本(ISR)接收才视为成功
- retries:设置足够的重试次数,避免因网络抖动导致的发送失败
- enable.idempotence=true:启用幂等性,避免消息重复
- 使用同步发送或正确处理异步回调:捕获并处理发送异常
最佳实践:
- 使用带回调的异步发送提高性能,同时确保在回调中正确处理异常
- 对关键业务消息,可使用本地消息表或事务消息
- 实现自定义拦截器来记录发送失败的消息
2. Broker端防止消息丢失
# broker端配置示例 (server.properties)############################# 副本配置 #############################
# 设置Topic默认副本数为3
default.replication.factor=3# 设置最小同步副本数
min.insync.replicas=2# 禁止非同步副本成为Leader(默认值为false)
unclean.leader.election.enable=false############################# 数据可靠性配置 #############################
# 设置数据刷盘策略,有以下选项:
# 0: 由操作系统控制,性能最好但风险最高
# 1: 每秒刷盘一次,平衡性能和可靠性
# -1: 每次写入都刷盘,可靠性最高但性能最差
log.flush.interval.messages=1000
log.flush.interval.ms=1000# 指定分区在内存中的保留时间,默认为-1(不受限制)
log.retention.ms=604800000 # 7天############################# Topic默认配置 #############################
# 创建topic时的默认分区数
num.partitions=3############################# 其他重要配置 #############################
# 控制器failover超时时间,大型集群可适当增加此值
controller.socket.timeout.ms=30000# Topic创建命令示例(针对特别重要的Topic单独配置)
bin/kafka-topics.sh --create --bootstrap-server broker1:9092 --topic important-topic \--partitions 6 --replication-factor 3 \--config min.insync.replicas=2 \--config flush.messages=1 \--config retention.ms=1209600000
关键配置:
- replication.factor=3:设置足够的副本数,通常为3
- min.insync.replicas=2:要求至少2个副本同步成功才认为写入成功
- unclean.leader.election.enable=false:禁止未同步的副本成为leader
- log.flush.interval.ms:控制数据刷盘频率,权衡性能和可靠性
最佳实践:
- 至少3个Broker的集群,保证高可用性
- 对重要Topic增加副本因子,提高可靠性
- 定期监控ISR副本数量,确保副本健康
- 合理配置刷盘策略,避免因服务器宕机导致数据丢失
3. 消费者端防止消息丢失
// 1. 消费者配置示例
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092,broker3:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-consumer-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 关闭自动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
// 如果使用自动提交,设置较大的提交间隔
// props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);// 从最早的偏移量开始消费(可选,首次消费时使用)
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));// 2. 手动确认 - 先处理消息再提交偏移量
try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));if (!records.isEmpty()) {// 处理消息批次processRecords(records);// 成功处理后再提交偏移量consumer.commitSync();}}
} catch (Exception e) {// 处理异常
} finally {consumer.close();
}// 3. 更精细的偏移量控制 - 按分区提交偏移量
try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));// 按分区处理记录Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();for (TopicPartition partition : records.partitions()) {List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);for (ConsumerRecord<String, String> record : partitionRecords) {// 处理单条消息processRecord(record);}// 获取该分区最后一条记录的偏移量long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();// 存储该分区的偏移量currentOffsets.put(partition, new OffsetAndMetadata(lastOffset + 1));}// 提交处理完的分区偏移量if (!currentOffsets.isEmpty()) {consumer.commitSync(currentOffsets);}}
} catch (Exception e) {// 处理异常
} finally {consumer.close();
}// 4. 处理消息的事务方式
private void processRecordsWithTransaction(ConsumerRecords<String, String> records) {// 开启数据库事务Connection conn = null;try {conn = dataSource.getConnection();conn.setAutoCommit(false);// 处理消息并执行数据库操作for (ConsumerRecord<String, String> record : records) {processRecordInTransaction(conn, record);}// 提交数据库事务conn.commit();// 提交Kafka偏移量consumer.commitSync();} catch (Exception e) {// 回滚数据库事务if (conn != null) {try {conn.rollback();} catch (SQLException ex) {ex.printStackTrace();}}throw new RuntimeException("Failed to process records", e);} finally {// 关闭连接if (conn != null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}
}
关键配置与策略:
- 关闭自动提交偏移量(enable.auto.commit=false):手动控制偏移量提交
- 先处理消息再提交偏移量:确保消息处理成功后再提交
- 按分区提交偏移量:更精细的控制,提高并发处理能力
- 使用事务处理:将数据库操作和偏移量提交放在同一事务中
最佳实践:
- 保证消息处理的幂等性,处理潜在的重复消费
- 实现消费失败重试机制,例如把失败消息放入"死信队列"
- 根据业务需求,考虑将重要消息持久化到本地
- 监控消费延迟,及时发现消费异常
四、深入理解Kafka可靠性机制
1. 生产者可靠性原理

生产者工作原理
-
消息累加器(RecordAccumulator):生产者并不是每条消息都立即发送,而是会缓存到一个消息累加器中,等到达一定条件后批量发送
-
消息累加器触发条件:
- batch.size:当累积的数据量达到设定值
- linger.ms:当数据累积时间达到设定值
-
Sender线程:单独的线程负责将消息批次从累加器中取出并发送到对应的Broker
-
确认机制(acks):
- acks=0:不等待确认
- acks=1:只等待Leader副本确认
- acks=all:等待所有ISR副本确认
2. Broker数据可靠性原理

Broker副本机制
-
ISR(In-Sync Replicas):与Leader保持同步的副本集合,只有ISR中的副本才能被选为新Leader
-
HW(High Watermark):消费者能看到的最高偏移量,ISR中所有副本都复制了的位置
- HW之前的消息对消费者可见
- 只有写入HW之前的消息才被认为是"已提交"的消息
-
LEO(Log End Offset):每个副本的日志末端位置
- Leader副本LEO > HW:表示有新消息写入但未同步完成
- Follower副本LEO < Leader LEO:表示副本正在追赶Leader
-
数据同步流程:
- Leader接收消息后追加到本地日志
- Follower通过fetch请求从Leader拉取消息
- Leader更新HW(取所有ISR副本LEO的最小值)
- 当acks=all时,只有消息被所有ISR副本同步后才返回成功
3. 消费者可靠性原理

消费者偏移量管理
-
偏移量(Offset)概念:
- 每条消息在分区中的唯一标识
- 消费者通过记录消费偏移量来追踪消费进度
-
偏移量存储:
- 0.9版本之前:存储在ZooKeeper中
- 0.9版本之后:存储在名为__consumer_offsets的内部Topic中
-
提交偏移量的方式:
- 自动提交:enable.auto.commit=true,按固定时间间隔自动提交
- 同步手动提交:commitSync(),阻塞直到提交成功
- 异步手动提交:commitAsync(),不阻塞,通过回调获取结果
-
消息处理与偏移量提交顺序:
- 先消费后提交:可能重复消费,但不会丢失
- 先提交后消费:可能丢失消息,但不会重复
-
消费者再均衡:
- 消费者加入/离开群组时触发再均衡
- 再均衡过程中,分区所有权会转移,需要正确处理偏移量提交
- 通过ConsumerRebalanceListener接口可以处理再均衡事件
五、扩展话题,Kafka消息保证语义
1. 消息传递语义

Kafka支持三种消息传递语义:
-
At Most Once (最多一次)
- 消息可能丢失,但绝不重复
- 性能最好,可靠性最低
- 适用场景:日志收集、指标监控等允许少量数据丢失的场景
-
At Least Once (至少一次)
- 消息不会丢失,但可能重复
- 性能较好,可靠性较高
- 适用场景:大多数业务场景,需要确保消费端实现幂等性
-
Exactly Once (恰好一次)
- 消息既不丢失也不重复
- 需要Kafka 0.11+版本支持
- 通过生产者幂等性和事务特性实现
- 适用场景:金融交易、计费系统等对数据精确性要求高的场景
2. 实现Exactly Once语义
Kafka 0.11版本后引入了事务支持,可以实现真正的Exactly Once语义:
// 1. 生产者端实现Exactly Once (使用事务API)
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092,broker3:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 启用幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 设置事务ID (必须唯一)
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional-id");
// 设置事务超时时间
props.put(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 60000); // 60秒KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 初始化事务
producer.initTransactions();try {// 开始事务producer.beginTransaction();// 在事务中发送消息for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key-" + i, "value-" + i);producer.send(record);}// 提交事务producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// 这些异常无法恢复,需要关闭生产者producer.close();
} catch (KafkaException e) {// 其他异常可以中止事务producer.abortTransaction();
} finally {producer.close();
}// 2. 消费者端实现Exactly Once
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092,broker3:9092");
consumerProps.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group-id");
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 设置隔离级别,只读取已提交的消息
consumerProps.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
// 关闭自动提交
consumerProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Arrays.asList("my-topic"));// 3. 消费-处理-生产模式 (消费者端读取+生产者端写入,事务性处理)
Properties processorProps = new Properties();
// ... 设置基础配置同上 ...// 设置事务ID
processorProps.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-processor-transactional-id");
// 启用幂等性
processorProps.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);KafkaProducer<String, String> processorProducer = new KafkaProducer<>(processorProps);
processorProducer.initTransactions();try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));if (!records.isEmpty()) {// 存储当前消费的偏移量Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();for (ConsumerRecord<String, String> record : records) {TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset() + 1);offsets.put(topicPartition, offsetAndMetadata);}// 开始事务processorProducer.beginTransaction();try {// 处理消息并产生新消息for (ConsumerRecord<String, String> record : records) {// 业务处理String processedValue = processRecord(record.value());// 发送处理后的消息ProducerRecord<String, String> outputRecord = new ProducerRecord<>("output-topic", record.key(), processedValue);processorProducer.send(outputRecord);}// 在同一事务中提交消费者偏移量processorProducer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());// 提交事务processorProducer.commitTransaction();} catch (Exception e) {// 发生异常,中止事务processorProducer.abortTransaction();throw e;}}}
} finally {processorProducer.close();consumer.close();
}// 简单的消息处理方法
private static String processRecord(String input) {// 实际的业务处理逻辑return "processed-" + input;
}
事务API关键点:
-
Transactional ID
- 每个生产者需要指定一个唯一的事务ID
- 事务ID可以跨会话保持事务状态,实现故障恢复
-
事务的基本操作
- initTransactions():初始化事务环境
- beginTransaction():开始一个新事务
- commitTransaction():提交事务
- abortTransaction():中止事务
-
消费-处理-生产场景
- 在同一个事务中可以将消费者偏移量与生产者发送的消息绑定
- 通过sendOffsetsToTransaction()方法实现
-
消费者隔离级别
- 通常设置为read_committed,只读取已提交的事务消息
- 避免读取到可能会被中止的事务消息
六、Kafka消息丢失的监控与告警
为了及时发现消息丢失问题,建立健全的监控系统至关重要。
1. 关键监控指标
-
生产者端
- errors-per-second:错误率
- record-error-rate:消息错误率
- record-retry-rate:消息重试率
-
Broker端
- UnderReplicatedPartitions:副本同步不足的分区数
- OfflinePartitionsCount:离线分区数
- ISRShrink/ISRExpand:ISR收缩/扩大事件
-
消费者端
- records-lag:消费延迟(表示有多少消息未消费)
- records-lag-max:最大消费延迟
- records-lag-avg:平均消费延迟
2. 监控系统搭建
常用监控组合:
- Kafka内置JMX监控 + Prometheus + Grafana
- Kafka Manager/CMAK + 自定义告警
- Confluent Control Center(商业版)
七、面试热点问题
1. Kafka如何保证消息不丢失?
生产者端:
- 使用acks=all确保所有副本接收消息
- 配置足够的重试次数
- 实现异步发送的错误回调处理
- 必要时使用事务API
Broker端:
- 配置合理的副本因子(至少3)
- 设置min.insync.replicas >= 2
- 禁用unclean.leader.election
- 合理配置数据持久化策略
消费者端:
- 关闭自动提交或增加自动提交间隔
- 使用手动提交,并在处理成功后提交
- 实现消息处理的幂等性
2. Kafka的消息传递语义有哪些?各适用于什么场景?
- At Most Once:适用于允许少量数据丢失的场景,如日志收集
- At Least Once:适用于大多数业务场景,要求实现消费端幂等性
- Exactly Once:适用于金融、计费等对数据精确性要求高的场景
3. Kafka如何实现Exactly Once语义?
实现Exactly Once需要从两方面保证:
- 生产者到Broker:使用幂等性生产者(enable.idempotence=true)和事务API
- Broker到消费者:设置消费者隔离级别为read_committed,只读取已提交的事务消息
- 端到端:通过事务机制将消费者偏移量提交和生产者发送消息绑定在同一事务中
关键实现技术:
- 生产者PID(Producer ID)和序列号实现幂等性
- 事务协调者(Transaction Coordinator)管理事务状态
- 控制消息(Control Messages)标记事务边界
4. 如何处理Kafka的消息积压问题?
- 定位原因:确定是生产速度过快还是消费速度过慢
- 提高消费能力:
- 增加消费者数量(需要增加分区数支持)
- 优化消费者处理逻辑,减少单条消息处理时间
- 提高消费者批量处理能力(max.poll.records)
- 临时措施:
- 启动独立消费者组进行"追赶"处理
- 对非关键消息实现"丢弃策略"
- 消息间隔采样消费
5. Kafka的LEO和HW是什么?与消息丢失有什么关系?
LEO (Log End Offset):分区中最后一条消息的偏移量+1,表示下一条待写入消息的偏移量。
HW (High Watermark):所有ISR副本都已复制的最高偏移量,只有HW之前的消息对消费者可见。
与消息丢失的关系:
- 只有HW之前的消息才被认为已提交,对消费者可见
- Leader宕机时,新选举的Leader将截断日志到HW位置,HW之后的消息会丢失
- min.insync.replicas设置过小可能导致消息在HW提交前丢失
6. 在Kafka系统中,消息重复和消息丢失哪个更容易处理?为什么?
消息重复通常比消息丢失更容易处理:
-
重复处理:可以通过设计幂等性操作解决重复问题
- 使用唯一ID去重
- 依赖数据库唯一约束
- 使用业务状态机
-
消息丢失:一旦丢失,数据可能无法恢复
- 需要从源头重新生成数据
- 可能需要进行数据修复和业务补偿
- 有时无法确定哪些数据丢失了
所以在设计系统时,通常宁可接受重复也不接受丢失。
总结
Kafka消息丢失是生产环境中常见的问题,但通过正确的配置和设计可以有效避免。
对于不同的业务场景,我们需要根据数据可靠性要求和性能需求,选择合适的解决方案。
- 对于一般业务,At Least Once语义加上消费端幂等设计是最佳选择
- 对于金融、支付等核心业务,应考虑使用Exactly Once语义
- 对于日志、监控等非关键业务,可以使用At Most Once语义以获得更好的性能
最后,建立完善的监控系统,及时发现并处理潜在的消息丢失问题,是保障Kafka系统稳定运行的重要保障。
Kafka不丢失消息的配置就像我们日常生活中的"安全带+安全气囊+ABS"组合,层层保护,共同确保消息传输的安全可靠。只有理解了原理,我们才能更加胸有成竹地应对各种挑战。
相关文章:
Kafka消息丢失全解析!原因、预防与解决方案
作为一名高并发系统开发工程师,在使用消息中间件的过程中,无法避免遇到系统中消息丢失的问题,而Kafka作为主流的消息队列系统,消息丢失问题尤为常见。 在这篇文章中,将深入浅出地分析Kafka消息丢失的各种情况…...

VS Code 云服务器远程开发完整指南
VS Code Ubuntu 云服务器远程开发完整指南 远程开发是现代开发者的标配之一,特别是在使用云服务器(如 Ubuntu)进行部署、测试或大项目开发时,利用 VS Code 的 Remote-SSH 插件,可以像本地一样顺滑操作远程服务器。本…...

Linux孤儿进程和僵尸进程
目录 1、孤儿进程 2、僵尸进程 在 Linux 系统中,父子进程关系的生命周期不同,导致会产生两类特殊进程:孤儿进程和僵尸进程。这两类进程在系统资源管理中起着重要作用。 1、孤儿进程 孤儿进程指的是父进程先于子进程结束,导致子…...

【Rtklib入门指南】4. 使用RTKLIB进行载波相位差分定位(RTK)
RTK RTK(Real-Time Kinematic,实时动态)定位技术是一种高精度的卫星导航技术。相比传统的GPS定位技术,RTK能够在厘米级别的精度范围内提供定位结果。这使得RTK技术在无人机、自动驾驶、工程测绘、农业机械自动化等领域具有广泛应用…...

【SECS】初识SECS协议
【SECS】初识SECS协议 基本知识流和功能函数数量官方文件中缩写标注正常是不是都是主机向设备端?对数据信息中第1字节第1-2位官网介绍 S1F1双向指令说明测试H发起端E发起端 参考资料 基本知识 SECS(SEMI Equipment Communications Standard)即半导体设…...

【C++项目】从零实现RPC框架「三」:项⽬抽象层实现
🌈 个人主页:Zfox_ 🔥 系列专栏:C++从入门到精通 目录 一:🔥 常⽤的零碎功能接⼝类实现🦋 简单⽇志宏实现🦋 Json 序列化/反序列化🦋 UUID ⽣成二:🔥 项⽬消息类型字段信息定义 🦋 请求字段宏定义🦋 消息类型定义🦋 响应码类型定义🦋 RPC 请求类型定…...

webcam video demo
一个 demo,使用 OpenCV,手动操作 webcam,保持相机打开,防止频繁的 开关损坏摄像头硬件。 这是ROS情景下的一个节点,展示了ROS节点的常见格式。代码很简单,单展示了持续视频流的发布,还展示了基…...

ARM-LDS链接文件
关键字 ALIGN 在链接脚本中,ALIGN关键字:ALIGN(X)中的X表示多少个字节对齐。 在汇编文件中,是伪操作 .align x 实现的:表示2的x次幂个字节对齐; 2.X的取值也是有讲究的,必须是2的整数次幂。例如…...

相机镜头景深
文章目录 定义影响因素实际应用特殊情况 参考:B站优致谱视觉 定义 景深是指在摄影机镜头或其他成像器前沿着能够取得清晰图像的成像器轴线所测定的物体距离范围。简单来说,就是在一张照片中,从前景到背景,能够保持清晰锐利的区域…...

Linux基础入门:从零开始掌握Linux命令行操作
🙋大家好!我是毛毛张! 🌈个人首页: 神马都会亿点点的毛毛张 🎈有没有觉得电影里的黑客🐒酷毙了?他们只用键盘⌨就能搞定一切。今天,毛毛张要带你们体验这种快感😀&…...

C++第13届蓝桥杯省b组习题笔记
1.九进制转十进制 九进制正整数 (2022)9转换成十进制等于多少? 第一位乘9的0次方,第二位乘9的1次方,第三位乘9的二次方以此类推 #include <iostream> using namespace std;int main() {// 请在此输入您的代码int t2022;int res0;int c…...

探索 Gaggol:理解 10^^^100 的宇宙级常数
一、常数概述: Gaggol 是一个极其巨大的数学常数,其数值表示为 10^^^100。这个常数是通过对数字 10 进行超递归幂运算得到的结果。 二、Gaggol 的定义: Gaggol 被定义为 10 的超多层超递归幂,即 10 被连续地提升到自身幂的层次达…...

python-leetcode 61.N皇后
题目: 按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击 给你一个整数 n ,返回所有不同的 n 皇后问题 的解…...

Centos8 系統Lnmp服務器環境搭建
Centos8 系統Lnmp服務器環境搭建 服務器環境 Centos8 [rootcentos8 ~]# uname -a Linux centos8 4.18.0-348.el8.x86_64 #1 SMP Tue Oct 19 15:14:17 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux# 更新軟件包列表 rootdebian:~# dnf update安裝信息 PHP 版本8.2.27 https://ww…...

产教融合|暴雨技术专家执裁江苏省职业院校技能大赛
3月28-30日,由江苏省教育厅、省发改委、省工信厅等15家单位主办的2025年江苏省职业院校技能大赛网络系统管理赛项如期举办。此次赛事吸引了全省52支参赛队伍、156名选手踊跃参与,参赛人数再创新高。 暴雨信息技术专家李明宇作为此赛项的往届省赛冠军&am…...

BUUCTF-web刷题篇(6)
15.PHP 知识点: ①__wakeup()//将在反序列化之后立即调用(当反序列化时变量个数与实际不符是会绕过)我们可以通过一个cve来绕过:CVE-2016-7124。将Object中表示数量的字段改成比实际字段大的值即可绕过wakeup函数。条件:PHP5<…...

AIP-203 域行为文档
编号203原文链接AIP-203: Field behavior documentation状态批准创建日期2018-07-17更新日期2018-07-17 在定义protocol buffer中的域时,按惯例要向用户解释域行为的某些方面(例如域是必需的还是可选的)。此外,让其他工具理解域行…...

在 Cloud Run 上使用 Gemini API 构建聊天应用
李升伟 编译 (🎨 封面由 Gemini 中的 Imagen 3 生成!) 欢迎来到我的谷歌AI工具构建系列博客!本文将带您创建一个由Gemini驱动并托管在Cloud Run上的简易聊天应用。如果您正在探索大语言模型或希望将AI集成到网页应用中,那么您来…...

周总结aa
上周学习了Java中有关字符串的内容,与其有关的类和方法 学习了static表示静态的相关方法和类的使用。 学习了继承(extends) 多态(有继承关系,有父类引用指向子类对象) 有关包的知识,final关键字的使用,及有…...

31天Python入门——第17天:初识面向对象
你好,我是安然无虞。 文章目录 面向对象编程1. 什么是面向对象2. 类(class)3. 类的实例关于self 4. 对象的初始化5. __str__6. 类之间的关系继承关系组合关系 7. 补充练习 面向对象编程 1. 什么是面向对象 面向对象编程是一种编程思想,它将现实世界的概念和关系映…...

计算机视觉准备八股中
一边记录一边看,这段实习跑路之前运行完3DGAN,弄完润了,现在开始记忆八股 1.CLIP模型的主要创新点: 图像和文本两种不同模态数据之间的深度融合、对比学习、自监督学习 2.等效步长是每一步操作步长的乘积 3.卷积层计算输入输出…...

【C语言】文件操作(2)
一、文件的随机读写 在前面我们学习了文件的顺序读写的函数,那么当我们要读取某个指定位置的内容的时候,是否只能顺序的读取到这个内容?还有在对文件进行输入的时候,需要对指定的位置进行写入,那么此时应该怎么办呢&a…...

CCCC天梯赛L1-094 剪切粘贴
题目链接: 字符串函数: 1、截取字符串: //起始位置为3,结束位置为5string s "aabcdefg";//下标从0开始 [从开始位置,结束位置]string sub s.substr(3,3);//输出cde, 有返回值string//并且原字符串不改变, s"aab…...

C语言:多线程
多线程概述 定义 多线程是指在一个程序中可以同时运行多个不同的执行路径(线程),这些线程可以并发或并行执行。并发是指多个线程在宏观上同时执行,但在微观上可能是交替执行的;并行则是指多个线程真正地同时执行&…...

livekit ICE连接失败的一些总结
在使用livekit做的项目过程中碰到了一些ICE连接失败的问题, 一个时在同网段的局域网下 ,livekti服务和客户端不能联通,后来发现是服务端是多网卡,通过网络抓包才知道服务端在stun binding的时候使用了错误的网卡,在co…...

Python神经网络1000个案例算法汇总
【2025最新版】Python神经网络优化1000个案例算法汇总(长期更新版) 本文聚焦神经网络、优化算法,神经网络改进,优化算法改进,优化算法优化神经网络权重、超参数等,现在只需订阅即可拥有,简直是人工智能初学者的天堂。…...

某地81栋危房自动化监测试点项目
1. 项目简介 房屋进入老龄化阶段后,结构安全风险越来越大。近10年来,每年都会产生房屋倒塌人员伤亡的重大安全事故。调研分析显示,老旧房屋结构安全风险管理的有效路径为,通过“人防技防”的组合模式,对房屋安全风险进…...

远程装个Jupyter-AI协作笔记本,Jupyter容器镜像版本怎么选?安装部署教程
通过Docker下载Jupyter镜像部署,输入jupyter会发现 有几个版本,不知道怎么选?这几个版本有什么差别? 常见版本有: jupyter/base-notebookjupyter/minimal-notebookjupyter/scipy-notebookjupyter/datascience-notebo…...

python文件的基本操作和文件读写
目录 文件的基本操作 文件读写 文件的基本操作 Python 中对文件的基本操作主要包括打开文件、读取文件、写入文件和关闭文件等操作。下面是一个简单的示例: 打开文件: file open(example.txt, r) # 使用 open() 函数打开一个名为 example.txt 的文…...

山东大学软件学院项目创新实训开发日志(4)之中医知识问答数据存储、功能结构、用户界面初步设计
目录 数据库设计: 功能设计: 用户界面: 数据库设计: --对话表 (1个对话包含多条消息) CREATE TABLE conversations ( conv_id VARCHAR(36) PRIMARY KEY, -- 对话ID user_id VARCHAR(36) NOT NULL, -- 所属用户 title VARCHAR(100), -- 对话…...