【Yolov8部署】 VS2019+opencv+onnxruntime 环境下部署目标检测模型
文章目录
- 前言
- 一、导出yolov8模型为onnx文件
- 二、VS2019中环境配置
- 三、源码与实际运行
前言
本文主要研究场景为工业场景下,在工控机与工业相机环境中运行的视觉缺陷检测系统,因此本文主要目的为实现c++环境下,将yolov8已训练好的检测模型使用onnxruntime 部署通过cpu或gpu cuda加速进行检测运算
一、导出yolov8模型为onnx文件
Yolo官方支持onnx的使用,直接使用yolo的官方库即可
配置好训练权重文件路径,输出参数按自己需求查手册配置
from ultralytics import YOLO# Load a model
#model = YOLO("yolov8n.pt") # Load an official model
model = YOLO(r"D:\deep_learning\YOLOv8.2\runs\train\exp9\weights\best.pt") # Load a custom trained model# Export the model
success = model.export(format="onnx", opset=11, simplify=True)
输出成功的文件会在权重文件同目录下

这里生成的文件为11.6MB,过小的onnx文件可能是生成失败产生的

获取了onnx文件后接下来配置调用onnx文件的部分
二、VS2019中环境配置
上篇文章中详细介绍了opencv在vs2019中的配置方法,这里就不再重复写了
opencv的配置见【Yolov8部署】 VS2019+opencv-dnn CPU环境下部署目标检测模型
YOLO官方提供的onnxruntime示例源码如下
https://github.com/ultralytics/ultralytics/tree/main/examples/YOLOv8-ONNXRuntime-CPP
可按需下载使用,本文提供另一种使用方法,下文会附上源码
首先需要下载ONNX Runtime gpu版本库
下载链接如下:
https://github.com/microsoft/onnxruntime/releases/tag/v1.21.0
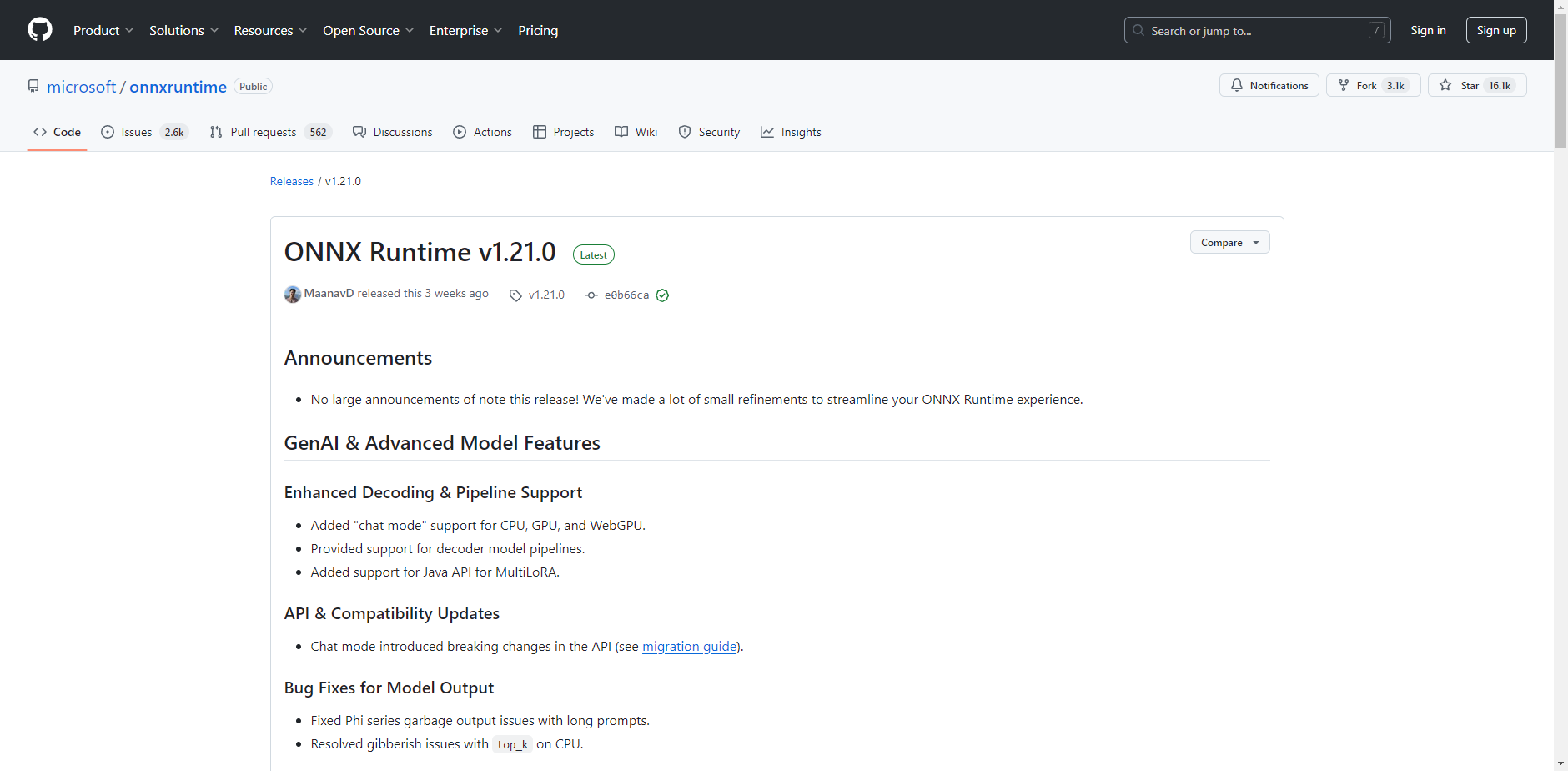
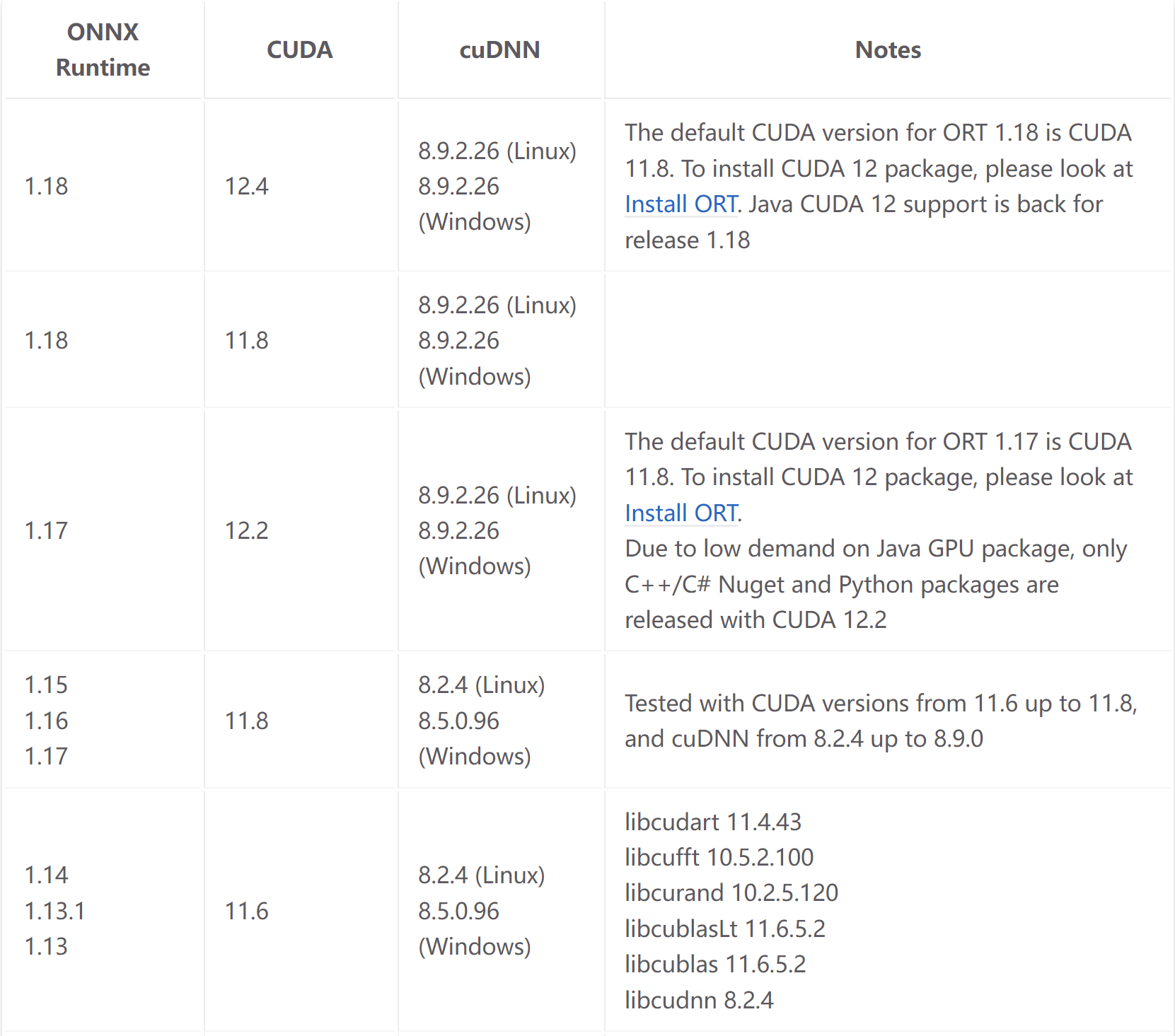
ONNX Runtime的版本需要注意与cuda版本对应
我的cuda版本装的是11.6,这里选用1.15版本的ONNX Runtime
使用onnxruntime推理不需要额外用opencv_gpu版本,cpu版本的opencv就可以满足要求
VS主要需要配置的是包含目录和三个动态库
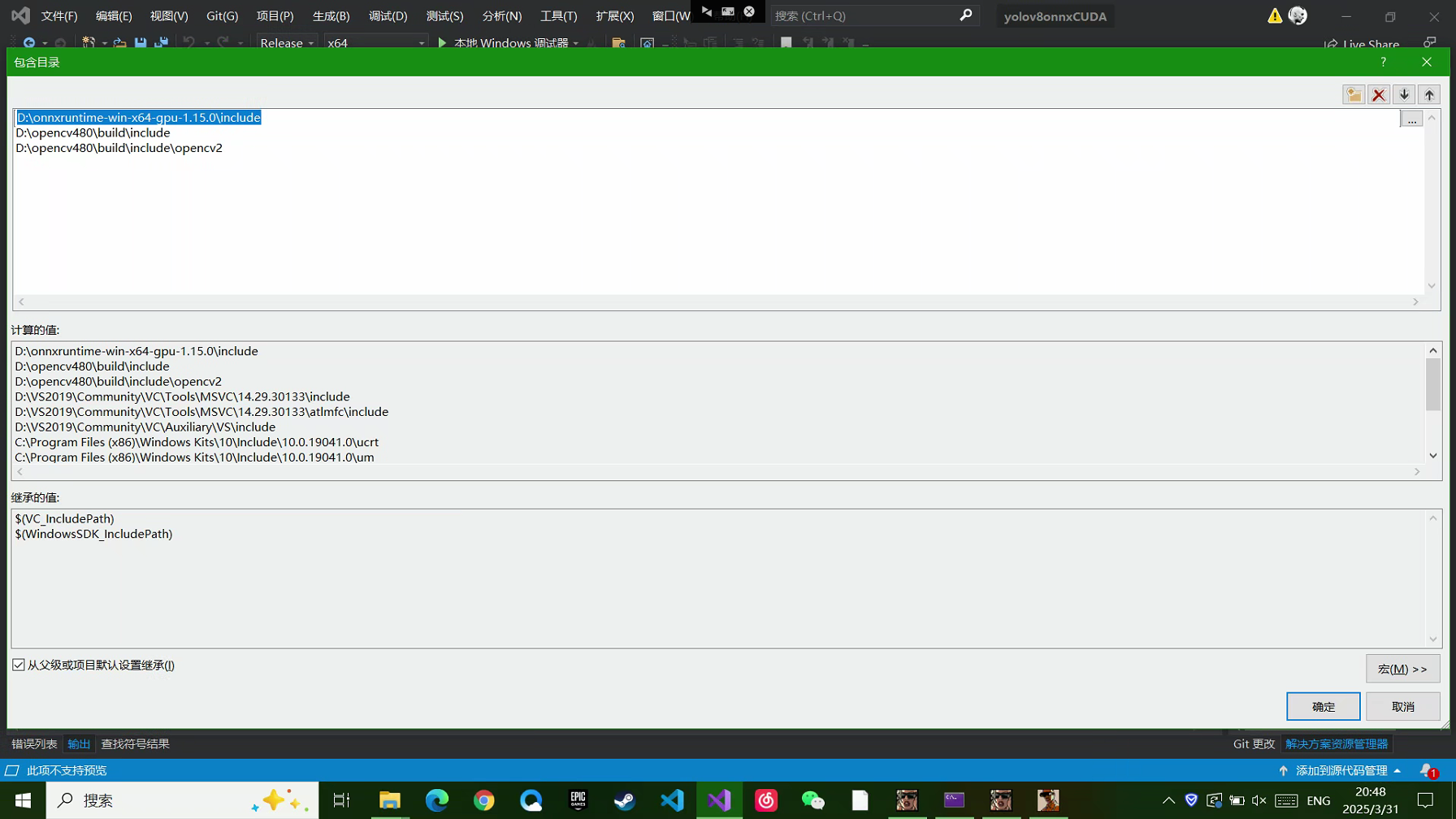
库目录配置
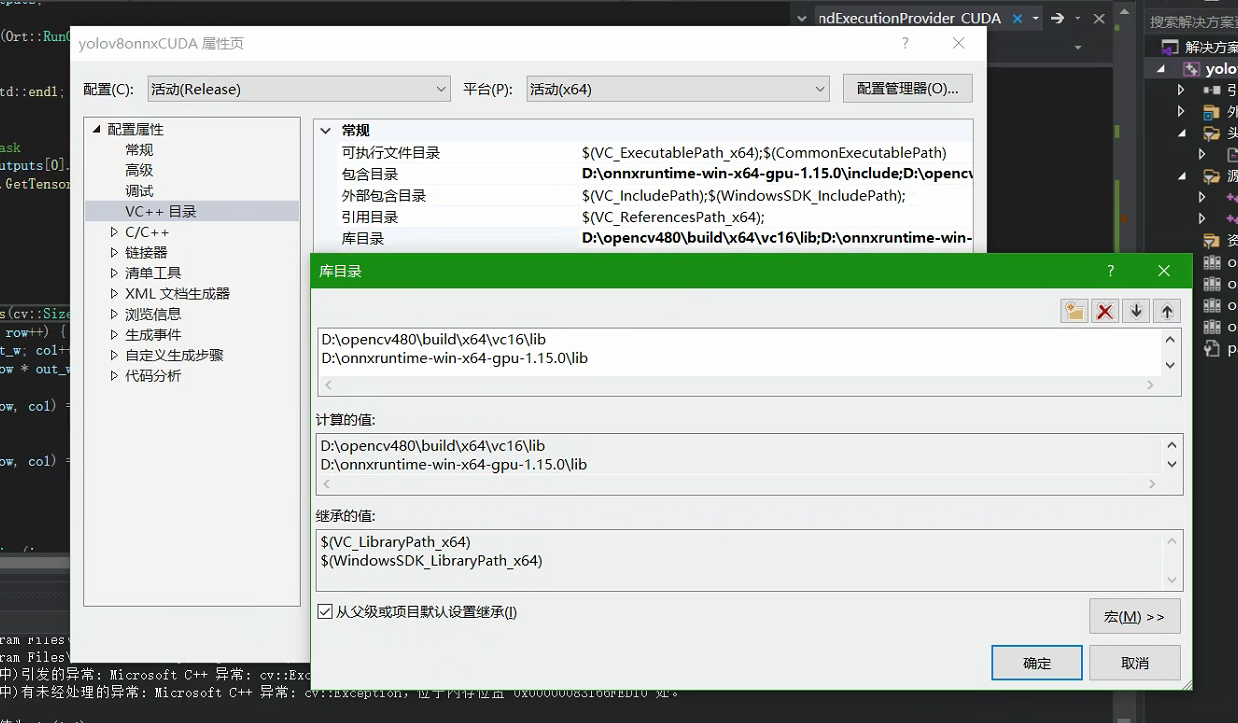
附加依赖项配置,将三个lib动态库都配置上

三、源码与实际运行
以下是调用推理源码
main.cpp
#include <opencv2/opencv.hpp>
#include "onnxruntime_cxx_api.h"int main()
{// 预测的目标标签数std::vector<std::string> labels;labels.push_back("bright_collision");labels.push_back("dark_collision");std::filesystem::path current_path = std::filesystem::current_path();std::filesystem::path imgs_path = current_path / "images";for (auto& i : std::filesystem::directory_iterator(imgs_path)){if (i.path().extension() == ".jpg" || i.path().extension() == ".png" || i.path().extension() == ".jpeg"){std::string img_path = i.path().string();cv::Mat img = cv::imread(img_path);}}// 测试图片cv::Mat image = cv::imread("D:\\VsEnvironment\\yolov8onnxCUDA\\yolov8onnxCUDA\\images\\Image_20241126165712899.jpg");cv::imshow("输入图", image);// ******************* 1.初始化ONNXRuntime环境 *******************Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "D:\\VsEnvironment\\dataSet\\best.onnx");// ***************************************************************// ******************* 2.设置会话选项 *******************// 创建会话Ort::SessionOptions session_options;// 优化器级别:基本的图优化级别session_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);// 线程数:4session_options.SetIntraOpNumThreads(4);// 设备使用优先使用GPU而是才是CPUOrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);//此条屏蔽则使用为cpu//OrtSessionOptionsAppendExecutionProvider_CPU(session_options, 1);std::cout << "onnxruntime inference try to use GPU Device" << std::endl;// ******************************************************// ******************* 3.加载模型并创建会话 *******************// onnx训练模型文件std::string onnxpath = "D:\\VsEnvironment\\dataSet\\best.onnx";std::wstring modelPath = std::wstring(onnxpath.begin(), onnxpath.end());// 加载模型并创建会话Ort::Session session_(env, modelPath.c_str(), session_options);// ************************************************************// ******************* 4.获取模型输入输出信息 *******************int input_nodes_num = session_.GetInputCount(); // 输入节点输int output_nodes_num = session_.GetOutputCount(); // 输出节点数std::vector<std::string> input_node_names; // 输入节点名称std::vector<std::string> output_node_names; // 输出节点名称Ort::AllocatorWithDefaultOptions allocator; // 创建默认配置的分配器实例,用来分配和释放内存// 输入图像尺寸int input_h = 0;int input_w = 0;// 获取模型输入信息for (int i = 0; i < input_nodes_num; i++) {// 获得输入节点的名称并存储auto input_name = session_.GetInputNameAllocated(i, allocator);input_node_names.push_back(input_name.get());// 显示输入图像的形状auto inputShapeInfo = session_.GetInputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();int ch = inputShapeInfo[1];input_h = inputShapeInfo[2];input_w = inputShapeInfo[3];std::cout << "input format: " << ch << "x" << input_h << "x" << input_w << std::endl;}// 获取模型输出信息int num = 0;int nc = 0;for (int i = 0; i < output_nodes_num; i++) {// 获得输出节点的名称并存储auto output_name = session_.GetOutputNameAllocated(i, allocator);output_node_names.push_back(output_name.get());// 显示输出结果的形状auto outShapeInfo = session_.GetOutputTypeInfo(i).GetTensorTypeAndShapeInfo().GetShape();num = outShapeInfo[0];nc = outShapeInfo[1];std::cout << "output format: " << num << "x" << nc << std::endl;}// **************************************************************// ******************* 5.输入数据预处理 *******************// 默认是BGR需要转化成RGBcv::Mat rgb, blob;cv::cvtColor(image, rgb, cv::COLOR_BGR2RGB);// 对图像尺寸进行缩放cv::resize(rgb, blob, cv::Size(input_w, input_h));blob.convertTo(blob, CV_32F);// 对图像进行标准化处理blob = blob / 255.0; // 归一化cv::subtract(blob, cv::Scalar(0.485, 0.456, 0.406), blob); // 减去均值cv::divide(blob, cv::Scalar(0.229, 0.224, 0.225), blob); //除以方差// CHW-->NCHW 维度扩展cv::Mat timg = cv::dnn::blobFromImage(blob);std::cout << timg.size[0] << "x" << timg.size[1] << "x" << timg.size[2] << "x" << timg.size[3] << std::endl;// ********************************************************// ******************* 6.推理准备 *******************// 占用内存大小,后续计算是总像素*数据类型大小size_t tpixels = 3 * input_h * input_w;std::array<int64_t, 4> input_shape_info{ 1, 3, input_h, input_w };// 准备数据输入auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(allocator_info, timg.ptr<float>(), tpixels, input_shape_info.data(), input_shape_info.size());// 模型输入输出所需数据(名称及其数量),模型只认这种类型的数组const std::array<const char*, 1> inputNames = { input_node_names[0].c_str() };const std::array<const char*, 1> outNames = { output_node_names[0].c_str() };// **************************************************// ******************* 7.执行推理 *******************std::vector<Ort::Value> ort_outputs;try {ort_outputs = session_.Run(Ort::RunOptions{ nullptr }, inputNames.data(), &input_tensor_, 1, outNames.data(), outNames.size());}catch (std::exception e) {std::cout << e.what() << std::endl;}// **************************************************// ******************* 8.后处理推理结果 *******************// 1x5 获取输出数据并包装成一个cv::Mat对象,为了方便后处理const float* pdata = ort_outputs[0].GetTensorMutableData<float>();cv::Mat prob(num, nc, CV_32F, (float*)pdata);// 后处理推理结果cv::Point maxL, minL; // 用于存储图像分类中的得分最小值索引和最大值索引(坐标)double maxv, minv; // 用于存储图像分类中的得分最小值和最大值cv::minMaxLoc(prob, &minv, &maxv, &minL, &maxL);// 获得最大值的索引,只有一行所以列坐标既为索引int max_index = maxL.x;std::cout << "label id: " << max_index << std::endl;// ********************************************************// 在测试图像上加上预测的分类标签cv::putText(image, labels[max_index], cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);cv::imshow("输入图像", image);cv::waitKey(0);// ******************* 9.释放资源*******************session_options.release();session_.release();// *************************************************return 0;
}
由于预处理与推理都是调用onnxruntime_cxx_api.h中的部分,所以直接写在main.cpp中测试
通过OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);可以控制是使用cpu推理还是gpu_cuda进行推理
实际推理耗时如下
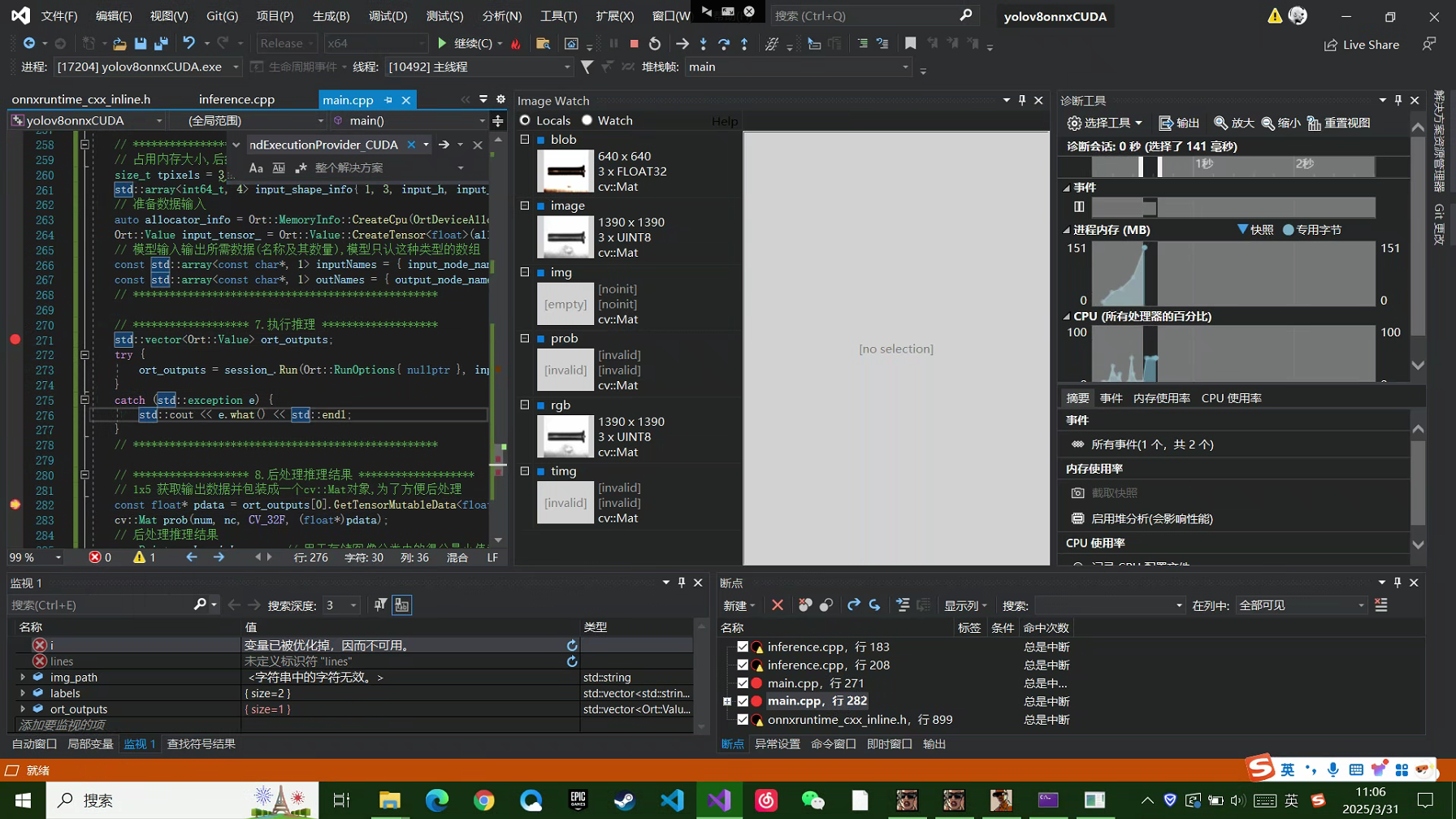
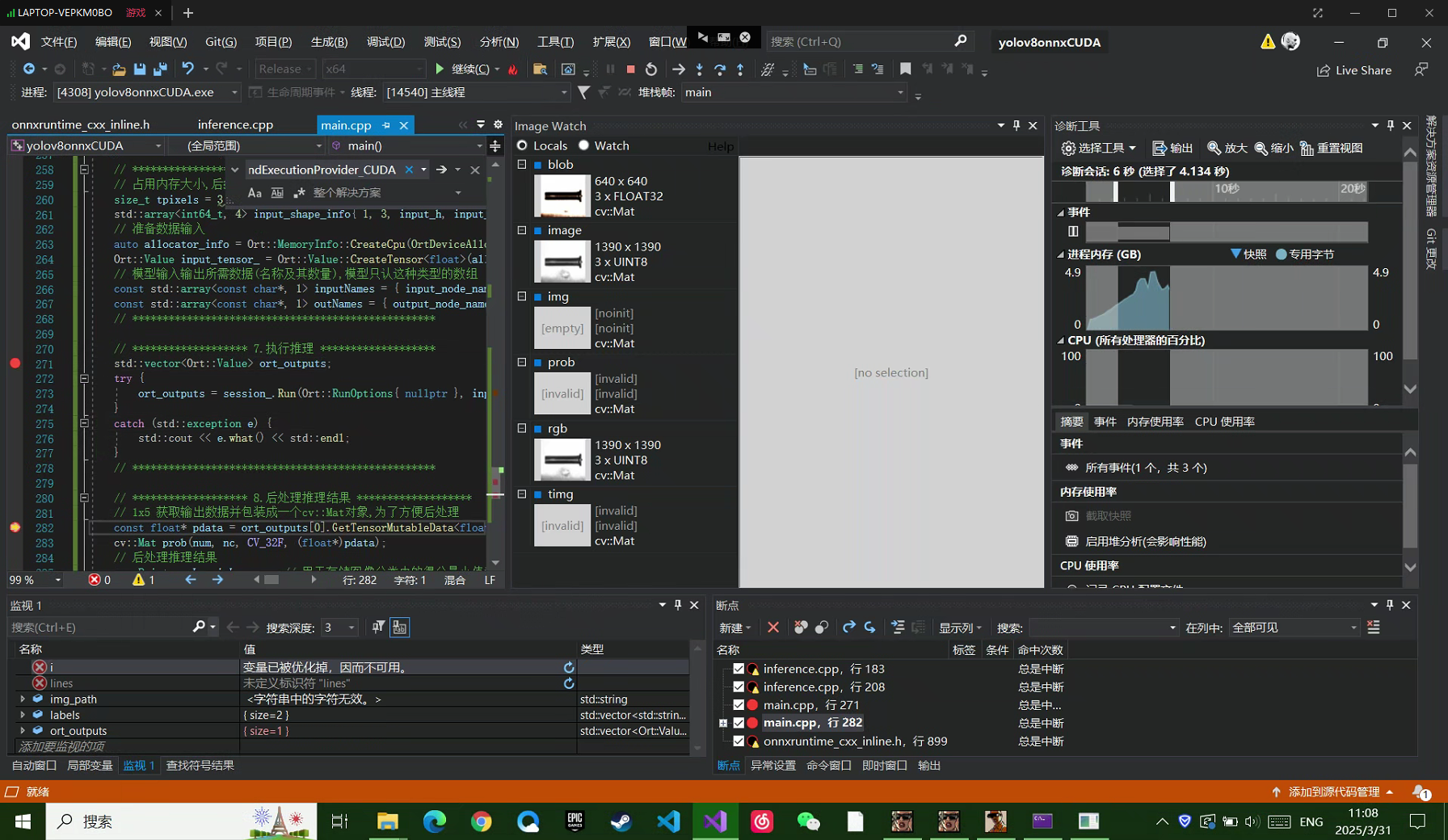
cpu用时141毫秒而gpu用时4.134秒
这里硬件环境是r7-3750h 1650-4g 16g运行内存
两者运行时间差异太大
可能是gpu计算分配耗时比较久,有知道原因的小伙伴可以在博客下留言告知
相关文章:
【Yolov8部署】 VS2019+opencv+onnxruntime 环境下部署目标检测模型
文章目录 前言一、导出yolov8模型为onnx文件二、VS2019中环境配置三、源码与实际运行 前言 本文主要研究场景为工业场景下,在工控机与工业相机环境中运行的视觉缺陷检测系统,因此本文主要目的为实现c环境下,将yolov8已训练好的检测模型使用o…...

论文阅读:Dual Anchor Graph Fuzzy Clustering for Multiview Data
论文地址:Dual Anchor Graph Fuzzy Clustering for Multiview Data | IEEE Journals & Magazine | IEEE Xplore 代码地址:https://github.com/BBKing49/DAG_FC 摘要 多视角锚图聚类近年来成为一个重要的研究领域,催生了多个高效的方法。然而&#…...

Lambda 表达式是什么以及如何使用
目录 📌 Kotlin 的 Lambda 表达式详解 🎯 什么是 Lambda 表达式? 🔥 1. Lambda 表达式的基本语法 ✅ 示例 1:Lambda 基本写法 ✅ 示例 2:使用 it 关键字(单参数简化) ✅ 示例 3…...

乐橙R10 AI智能锁:以「技术减法」终结智能家居「参数内卷」
1 行业迷思:当「技术内卷」背离用户真实需求 “三摄猫眼”、“0.3秒人脸解锁”、“DeepSeek大模型”……智能锁行业的营销话术日益浮夸,但用户体验却陷入“功能冗余”与“操作复杂”的泥潭。 一位用户在社交平台直言:“我的智能锁有六个摄像…...

如何使用 FastAPI 构建 MCP 服务器
哎呀,各位算法界的小伙伴们!今天咱们要聊聊一个超酷的话题——MCP 协议!你可能已经听说了,Anthropic 推出了这个新玩意儿,目的是让 AI 代理和你的应用程序之间的对话变得更顺畅、更清晰。不过别担心,为你的…...

基于Python的Django框架的手机购物商城管理系统
标题:基于Python的Django框架的手机购物商城管理系统 内容:1.摘要 随着互联网的快速发展,手机购物逐渐成为人们日常生活中不可或缺的一部分。本研究的目的是开发一个基于Python的Django框架的手机购物商城管理系统,以提高购物商城的管理效率和用户体验。…...

【UE5.3.2】初学1:适合初学者的入门路线图和建议
3D人物的动作制作 大神分析:3D人物的动作制作通常可以分为以下几个步骤: 角色绑定(Rigging):将3D人物模型绑定到一个骨骼结构上,使得模型能够进行动画控制。 动画制作(Animation):通过控制骨骼结构,制作出人物的各种动作,例如走路、跳跃、打斗等。 动画编辑(Ani…...
当 EcuBus-Pro + UTA0401 遇上 NSUC1500
文章目录 1.前言2.EcuBus-Pro简介2.1 官方地址2.2 概览 3.纳芯微NSUC1500简介3.1 NSUC1500概述3.2 产品特性 4.测试环境5.基础功能5.1 数据发送5.2 数据监控 6.自动化功能6.1 脚本创建6.2 脚本编辑6.3 脚本编辑与测试 7.音乐律动7.1 导入例程7.2 效果展示 ECB工程 1.前言 最近…...

qml 中的anchors
理解 QML 中的 anchors(锚定) 在 QML 中,anchors 是一种强大的布局机制,用于相对于父元素或同级元素定位和调整组件大小。它比简单的 x/y 坐标定位更灵活,能够自动适应不同屏幕尺寸。 基本概念 在你的代码中&#x…...

【FreeRTOS】裸机开发与操作系统区别
🔎【博主简介】🔎 🏅CSDN博客专家 🏅2021年博客之星物联网与嵌入式开发TOP5 🏅2022年博客之星物联网与嵌入式开发TOP4 🏅2021年2022年C站百大博主 🏅华为云开发…...

Deepseek API+Python 测试用例一键生成与导出 V1.0.4 (接口文档生成接口测试用例保姆级教程)
接口文档生成接口测试用例保姆级教程 随着测试需求的复杂性增加,测试用例的设计和生成变得愈发重要。Deepseek API+Python 测试用例生成工具在 V1.0.4 中进行了全方位的优化和功能扩展,特别是对接口测试用例设计的支持和接口文档的智能解析处理。本文将详细介绍 V1.0.4 版本…...

CET-4增量表
CET-4词表-增量表 注: 【1】所谓增量,是相对于高中高考之增量 即,如果你是在读大学生,高中英语单词过关了,准备考CET-4,那么侧重下面的增量词表的学习,也算是一条捷径吧 ^_^ 【2】本结果数据 官…...

DeepSeek详解:探索下一代语言模型
文章目录 前言一、什么是DeepSeek二、DeepSeek核心技术2.1 Transformer架构2.1.1 自注意力机制 (Self-Attention Mechanism)(a) 核心思想(b) 计算过程(c) 代码实现 2.1.2 多头注意力 (Multi-Head Attention)(a) 核心思想(b) 工作原理(c) 数学描述(d) 代码实现 2.1.3 位置编码 (…...
,何时 Detach()?)
深入解析主线程退出与子线程管理:何时 Join(),何时 Detach()?
在多线程编程中,主线程退出时如何正确管理子线程是一个关键问题。如果子线程没有 Join() 或 Detach(),不同的操作系统会有不同的行为,可能导致内存泄漏、资源竞争、甚至程序崩溃。本文将深入探讨主线程退出时子线程的管理策略,并提…...

AWS API Gateway Canary部署实战:Lambda到ECS的平滑迁移指南
在云原生架构中,如何实现服务平滑迁移是一个常见挑战。本文将详细介绍如何利用AWS API Gateway的Canary部署功能,实现从Lambda函数到ECS服务的无缝迁移,同时保证客户端无感知并提供便捷的回退机制。 一、迁移方案概述 在本方案中,我们将实现以下目标: 将现有Lambda服务平…...

Docker学习--容器操作相关命令--docker export 命令
docker export 命令的作用: 用于将 Docker 容器的文件系统导出为一个 tar 归档文件。主要用于备份或迁移容器的文件系统,而不包括 Docker 镜像的所有层和元数据。 语法: docker export [参数选项] CONTAINER(要操作的容器&#x…...

【Easylive】获取request对象的两种方式
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 1. 通过方法参数直接注入(Spring MVC 推荐) 在 Controller 方法中直接声明 HttpServletRequest 参数,Spring 会自动注入当前请求的 request 对象&#…...

FOC 控制笔记【三】磁链观测器
一、磁链观测器基础 1.1 什么是磁链 磁链(magnetic linkage)是电磁学中的一个重要概念,指导电线圈或电流回路所链环的磁通量。单位为韦伯(Wb),又称磁通匝。 公式为: 线圈匝数 穿过单匝数的…...

SpringBoot项目读取自定义的配置文件
先说使用场景: 开发时在resource目录下新建一个 config 文件夹, 在里面存放 myconf.properties 文件, 打包后这个文件会放到与jar包同级的目录下, 如下图 关键点:自定义的文件名(当然后缀是.properties),自定义的存放路径。 主要的要求是在打包后运行过…...

UniApp快速表单组件
环境:vue3 uni-app 依赖库:uview-plus、dayjs 通过配置项快速构建 form 表单 使用 <script setup>import CustomCard from /components/custom-card.vue;import { ref } from vue;import CustomFormItem from /components/form/custom-form-it…...

在PyCharm 中免费集成Amazon CodeWhisperer
CodeWhisperer 是Amazon发布的一款免费的AI 编程辅助小工具,可在你的集成开发环境(IDE)中生成实时单行或全函数代码建议,帮助你快速构建软件。简单来说,Amazon CodeWhisperer就是你写一段注释(支持中文&…...
)
语音克隆(Voice Cloning)
要将文字转化为“自己声音”的音频,需要用到语音克隆(Voice Cloning)技术。这种技术通常要求用户提供一定量的语音样本(几分钟到几小时不等),然后通过 AI 模型生成与你声音相似的音频。目前市面上完全免费且…...

[7-02-02].第15节:生产经验 - 消费者相关操作
Kafka笔记大纲 五、生产经验——分区的分配以及再平衡: 4.1.生产经验——分区的分配以及再平衡 4.2.参数: 5.4.1 Range 以及再平衡...
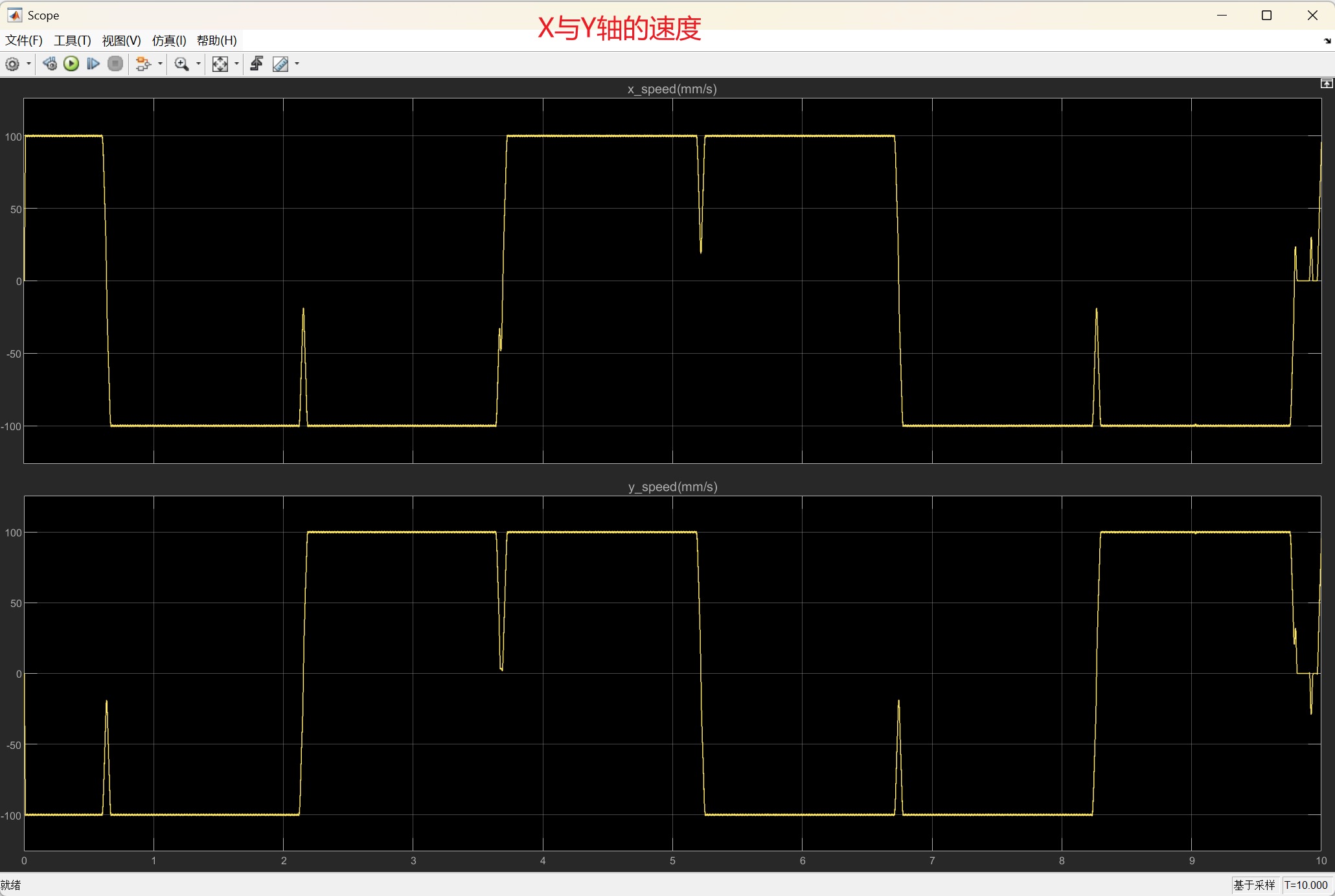
Matlab_Simulink中导入CSV数据与仿真实现方法
前言 在Simulink仿真中,常需将外部数据(如CSV文件或MATLAB工作空间变量)作为输入信号驱动模型。本文介绍如何高效导入CSV数据至MATLAB工作空间,并通过From Workspace模块实现数据到Simulink的精确传输,适用于运动控制…...

vue3大屏适配
最近写大屏,发现适配真的好难统一,不是这有问题就是那有问题,要不然页面拉伸的就变形了,在网上找到了一个好用的插件,暂时用起来没问题,如果后续有问题或者大家有什么好的想法可以在评论区说一下。 插件 bi…...
文件操作与IO—File类
目录 1 属性 2 构造方法 3 常用方法 4 示例代码 1 属性 修饰符与类型 属性 含义 static String pathSeparator 依赖于系统的路径分隔符,String类型的表示 static char pathSeparator 依赖于系统的路径分隔符,char类型的表示 2 构造方法 构造…...

音频进阶学习二十四——IIR滤波器设计方法
文章目录 前言一、滤波器设计要求1.选频滤波器种类2.通带、阻带、过度带3.滤波器设计指标 二、IIR滤波器的设计过程1.设计方法2.常见的模拟滤波器设计1)巴特沃斯滤波器(Butterworth Filter)2)切比雪夫滤波器(Chebyshev…...

OpenBMC:BmcWeb 处理http请求2 查找路由对象
OpenBMC:BmcWeb 处理http请求1 生成Request和AsyncResp对象_bmc web-CSDN博客 当接收到http请求,并且完成解析后,调用了App::handle处理请求 而App::handle又调用了router.handle(req, asyncResp);来处理请求 1.Router::handle void handle(const std::shared_ptr<Requ…...

MVC编程
MVC基本概述 例子——显示本地文件系统结构 先分别拖入ListView,TableView,TreeView 然后在进行布局 在widget.cpp 结果 mock测试 1,先加入json测试对象 2.创建后端目录 3,在src添加新文件 在models文件夹里 在mybucket.h,添加测试用例的三个字段 4.在…...

怎么对asp.web api进行单元测试?
在 ASP.NET Web API 中进行单元测试是一种确保代码质量和功能正确性的重要实践。单元测试的重点是针对 API 控制器中的逻辑进行测试,而不依赖于外部依赖(如数据库、文件系统或网络请求)。以下是实现 ASP.NET Web API 单元测试的步骤和方法&am…...