python 常用的6个爬虫第三方库
Python中有非常多用于网络数据采集的库,功能非常强大,有的用于抓取网页,有的用于解析网页,这里介绍6个最常用的库。
1. BeautifulSoup
BeautifulSoup是最常用的Python网页解析库之一,可将 HTML 和 XML 文档解析为树形结构,能更方便地识别和提取数据。
BeautifulSoup可以自动将输入文档转换为 Unicode,将输出文档转换为 UTF-8。此外,你还可以设置 BeautifulSoup 扫描整个解析页面,识别所有重复的数据(例如,查找文档中的所有链接),只需几行代码就能自动检测特殊字符等编码。

from bs4 import BeautifulSoup # 假设这是我们从某个网页获取的HTML内容(这里直接以字符串形式给出)
html_content = """
<html>
<head> <title>示例网页</title>
</head>
<body> <h1>欢迎来到BeautifulSoup示例</h1> <p class="introduction">这是一个关于BeautifulSoup的简单示例。</p> <a href="https://www.example.com/about" class="link">关于我们</a>
</body>
</html>
""" # 使用BeautifulSoup解析HTML内容,这里默认使用Python的html.parser作为解析器
# 你也可以指定其他解析器,如'lxml'或'html5lib',但需要先安装它们
soup = BeautifulSoup(html_content, 'html.parser') # 提取并打印<title>标签的文本内容
print("网页标题:", soup.title.string) # 网页标题: 示例网页 # 提取并打印<p>标签的文本内容,这里使用class属性来定位
print("介绍内容:", soup.find('p', class_='introduction').string) # 介绍内容: 这是一个关于BeautifulSoup的简单示例。 # 提取并打印<a>标签的href属性和文本内容
link = soup.find('a', class_='link')
print("链接地址:", link['href']) # 链接地址: https://www.example.com/about
print("链接文本:", link.string) # 链接文本: 关于我们 # 注意:如果HTML内容中包含多个相同条件的标签,你可以使用find_all()来获取它们的一个列表
# 例如,要获取所有<a>标签的href属性,可以这样做:
all_links = [a['href'] for a in soup.find_all('a')]
print("所有链接地址:", all_links) # 假设HTML中有多个<a>标签,这里将列出它们的href属性
# 注意:上面的all_links列表在当前的HTML内容中只有一个元素,因为只有一个<a>标签
2. Scrapy
Scrapy是一个流行的高级爬虫框架,可快速高效地抓取网站并从其页面中提取结构化数据。
由于 Scrapy 主要用于构建复杂的爬虫项目,并且它通常与项目文件结构一起使用
Scrapy 不仅仅是一个库,还可以用于各种任务,包括监控、自动测试和数据挖掘。这个 Python 库包含一个内置的选择器(Selectors)功能,可以快速异步处理请求并从网站中提取数据。

# 假设这个文件名为 my_spider.py,但它实际上应该放在 Scrapy 项目的 spiders 文件夹中 import scrapy class MySpider(scrapy.Spider): # Spider 的名称,必须是唯一的 name = 'example_spider' # 允许爬取的域名列表(可选) # allowed_domains = ['example.com'] # 起始 URL 列表 start_urls = [ 'http://example.com/', ] def parse(self, response): # 这个方法用于处理每个响应 # 例如,我们可以提取网页的标题 title = response.css('title::text').get() if title: # 打印标题(在控制台输出) print(f'Title: {title}') # 你还可以继续爬取页面中的其他链接,这里只是简单示例 # 例如,提取所有链接并请求它们 # for href in response.css('a::attr(href)').getall(): # yield scrapy.Request(url=response.urljoin(href), callback=self.parse) # 注意:上面的代码只是一个 Spider 类的定义。
# 要运行这个 Spider,你需要将它放在一个 Scrapy 项目中,并使用 scrapy crawl 命令来启动爬虫。
# 例如,如果你的 Scrapy 项目名为 myproject,并且你的 Spider 文件名为 my_spider.py,
# 那么你应该在项目根目录下运行以下命令:
# scrapy crawl example_spider
3. Selenium
Selenium 是一款基于浏览器地自动化程序库,可以抓取网页数据。它能在 JavaScript 渲染的网页上高效运行,这在其他 Python 库中并不多见。
在开始使用 Python 处理 Selenium 之前,需要先使用 Selenium Web 驱动程序创建功能测试用例。
Selenium 库能很好地与任何浏览器(如 Firefox、Chrome、IE 等)配合进行测试,比如表单提交、自动登录、数据添加/删除和警报处理等。

from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC # 设置WebDriver的路径(根据你的系统路径和WebDriver版本修改)
driver_path = '/path/to/your/chromedriver' # 初始化WebDriver
driver = webdriver.Chrome(executable_path=driver_path) try: # 打开网页 driver.get('https://www.example.com') # 等待页面加载完成(这里使用隐式等待,针对所有元素) # 注意:隐式等待可能会影响性能,通常在脚本开始时设置一次 driver.implicitly_wait(10) # 秒 # 查找并输入文本到搜索框(假设搜索框有一个特定的ID或类名等) # 这里以ID为'search'的输入框为例 search_box = driver.find_element(By.ID, 'search') search_box.send_keys('Selenium WebDriver') # 提交搜索(假设搜索按钮是一个类型为submit的按钮或是一个可以点击的输入框) # 如果搜索是通过按Enter键触发的,可以直接在search_box上使用send_keys(Keys.ENTER) # 这里假设有一个ID为'submit'的按钮 submit_button = driver.find_element(By.ID, 'submit') submit_button.click() # 等待搜索结果加载完成(这里使用显式等待作为示例) # 假设搜索结果页面有一个特定的元素,我们等待它出现 wait = WebDriverWait(driver, 10) # 等待最多10秒 element = wait.until(EC.presence_of_element_located((By.ID, 'results'))) # 执行其他操作... finally: # 关闭浏览器 driver.quit()
4. requests
不用多说,requests 是 Python 中一个非常流行的第三方库,用于发送各种 HTTP 请求。它简化了 HTTP 请求的发送过程,使得从网页获取数据变得非常简单和直观。
requests 库提供了丰富的功能和灵活性,支持多种请求类型(如 GET、POST、PUT、DELETE 等),可以发送带有参数、头信息、文件等的请求,并且能够处理复杂的响应内容(如 JSON、XML 等)。

import requests # 目标URL
url = 'https://httpbin.org/get' # 发送GET请求
response = requests.get(url) # 检查请求是否成功
if response.status_code == 200: # 打印响应内容 print(response.text)
else: # 打印错误信息 print(f'请求失败,状态码:{response.status_code}')
5. urllib3
urllib3 是 Python内置网页请求库,类似于 Python 中的requests库,主要用于发送HTTP请求和处理HTTP响应。它建立在Python标准库的urllib模块之上,但提供了更高级别、更健壮的API。
urllib3可以用于处理简单身份验证、cookie 和代理等复杂任务。

import urllib3 # 创建一个HTTP连接池
http = urllib3.PoolManager() # 目标URL
url = 'https://httpbin.org/get' # 使用连接池发送GET请求
response = http.request('GET', url) # 检查响应状态码
if response.status == 200: # 打印响应内容(注意:urllib3默认返回的是bytes类型,这里我们将其解码为str) print(response.data.decode('utf-8'))
else: # 如果响应状态码不是200,则打印错误信息 print(f'请求失败,状态码:{response.status}') # 注意:urllib3没有直接的方法来处理JSON响应,但你可以使用json模块来解析
# 如果响应内容是JSON,你可以这样做:
# import json
# json_response = json.loads(response.data.decode('utf-8'))
# print(json_response)
6. lxml
lxml是一个功能强大且高效的Python库,主要用于处理XML和HTML文档。它提供了丰富的API,使得开发者可以轻松地读取、解析、创建和修改XML和HTML文档。

from lxml import etree # 假设我们有一段HTML或XML内容,这里以HTML为例
html_content = """
<html> <head> <title>示例页面</title> </head> <body> <h1>欢迎来到我的网站</h1> <p class="description">这是一个使用lxml解析的示例页面。</p> <ul> <li>项目1</li> <li>项目2</li> </ul> </body>
</html>
""" # 使用lxml的etree模块来解析HTML或XML字符串
# 注意:对于HTML内容,我们使用HTMLParser解析器
parser = etree.HTMLParser()
tree = etree.fromstring(html_content, parser=parser) # 查找并打印<title>标签的文本
title = tree.find('.//title').text
print("页面标题:", title) # 查找并打印class为"description"的<p>标签的文本
description = tree.find('.//p[@class="description"]').text
print("页面描述:", description) # 查找所有的<li>标签,并打印它们的文本
for li in tree.findall('.//li'): print("列表项:", li.text) # 注意:lxml也支持XPath表达式来查找元素,这里只是简单展示了find和findall的用法
# XPath提供了更强大的查询能力
其他爬虫工具
除了Python库之外,还有其他爬虫工具可以使用。
八爪鱼爬虫
八爪鱼爬虫是一款功能强大的桌面端爬虫软件,主打可视化操作,即使是没有任何编程基础的用户也能轻松上手。
官网下载:https://affiliate.bazhuayu.com/hEvPKU
八爪鱼支持多种数据类型采集,包括文本、图片、表格等,并提供强大的自定义功能,能够满足不同用户需求。此外,八爪鱼爬虫支持将采集到的数据导出为多种格式,方便后续分析处理。

亮数据爬虫
亮数据平台提供了强大的数据采集工具,比如Web Scraper IDE、亮数据浏览器、SERP API等,能够自动化地从网站上抓取所需数据,无需分析目标平台的接口,直接使用亮数据提供的方案即可安全稳定地获取数据。
网站使用:https://get.brightdata.com/webscra
亮数据浏览器支持对多个网页进行批量数据抓取,适用于需要JavaScript渲染的页面或需要进行网页交互的场景。

Web Scraper
Web Scraper是一款轻便易用的浏览器扩展插件,用户无需安装额外的软件,即可在Chrome浏览器中进行爬虫。插件支持多种数据类型采集,并可将采集到的数据导出为多种格式。


无论是Python库还是爬虫软件,都能实现数据采集任务,可以选择适合自己的。当然记得在使用这些工具时,一定要遵守相关网站的爬虫政策和法律法规。
相关文章:
python 常用的6个爬虫第三方库
Python中有非常多用于网络数据采集的库,功能非常强大,有的用于抓取网页,有的用于解析网页,这里介绍6个最常用的库。 1. BeautifulSoup BeautifulSoup是最常用的Python网页解析库之一,可将 HTML 和 XML 文档解析为树形…...
blender场景导入Unity的流程(个人总结)
处理找不到贴图的问题 blender场景导入Unity遇到的主要问题是贴图找不到。经研究是blender里材质的着色器结构不是贴图-原理化BSDF-输出导致的。目前还没有自动解决方法,总结了一个效率还可以的手动解决流程。 打开后到材质预览,看一下显示没问题&…...
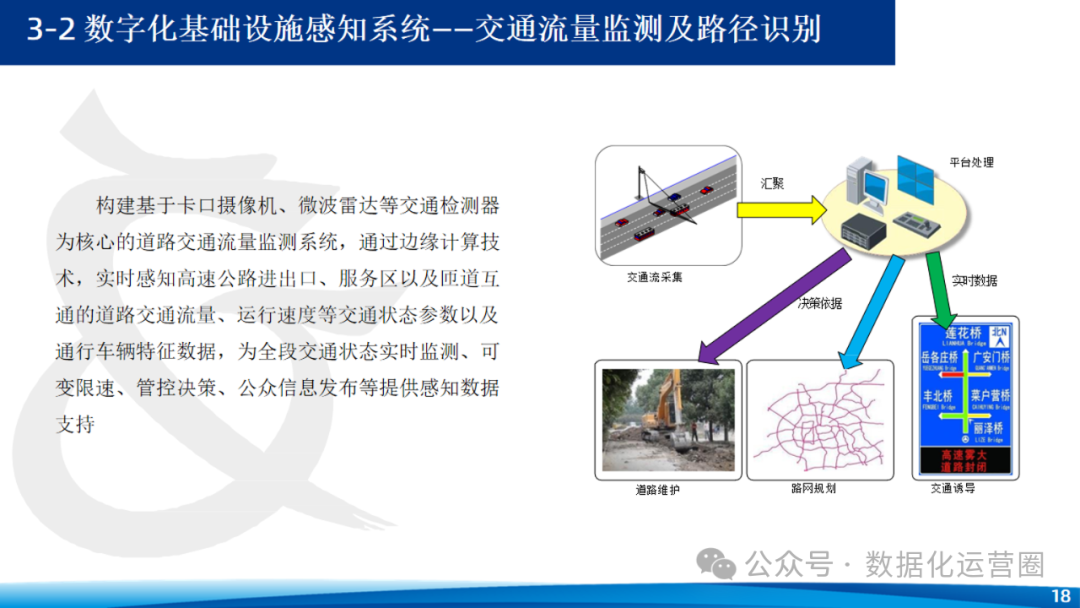
可编辑36页PPT | “新基建”在数字化智慧高速公路中的支撑应用方案智慧高速解决方案智慧交通方案
这份文档是一份关于“新基建”在数字化智慧高速公路中支撑应用方案的PPT内容介绍,它详细阐述了新基建在智慧高速建设中的背景、总体要求和建设内容。从政策背景来看,多个政府部门发布了相关政策文件,推动交通运输基础设施的数字化升级和智慧交…...

Spring 核心技术解析【纯干货版】- XV:Spring 网络模块 Spring-Web 模块精讲
Spring Framework 作为 Java 生态中最流行的企业级开发框架,提供了丰富的模块化支持。其中,Spring Web 模块是支撑 Web 开发的基础组件,无论是传统的 MVC 应用,还是 REST API 及微服务架构,都离不开它的核心能力。 本篇…...

一文解读DeepSeek在保险业的应用
引言 随着人工智能技术的深度渗透,保险行业正经历从传统经验驱动向数据智能驱动的转型。作为国产高性能开源大模型的代表,DeepSeek 凭借其低成本、高推理效率及跨模态处理能力,已成为保险机构突破服务瓶颈、重构业务逻辑的核心工具。截止目前…...

MD编辑器中的段落缩进怎么操作
在 Markdown(MD)编辑器中,段落的缩进通常可以通过 HTML 空格符、Markdown 列表缩进、代码块缩进等方式 实现。以下是几种常见的段落缩进方法: 1. 使用全角空格 ( ) 在一些 Markdown 编辑器(如 Typora)中&…...

Oracle OCP知识点详解2:管理用户密码期限
一、Oracle密码期限管理机制 Oracle数据库通过**概要文件(Profile)**来管理用户的密码策略。默认情况下,所有用户都使用名为DEFAULT的概要文件,该文件的密码过期时间通常设置为180天。这种机制旨在强制用户定期更改密码ÿ…...

物联网时代,HMI 设计的创新机遇与挑战
随着物联网(IoT)技术的蓬勃发展,各种智能设备如雨后春笋般涌现,从智能家居到智慧城市,物联网的应用场景愈发广泛。作为人与设备之间的桥梁,人机界面(HMI)设计在物联网时代扮演着至关…...

系统调用与中断
中断与系统调用 中断(Interrupt)和系统调用(Syscall)是操作系统中两个关键机制,分别用于处理硬件事件和用户程序与内核的交互。它们虽然都涉及从用户模式到内核模式的切换,但设计目的和触发方式不同。以下…...

数据结构和算法——汉诺塔问题
前言 先讲个故事,传说古代印度有三根黄金柱,64个石盘,需要将石盘从第一根移动到第三根上,规定每次只能移动一片,并且小盘在放置时必须在大盘上。 当石盘移动完毕时,世界就会毁灭。 汉诺塔——递归 接下来…...

【区块链安全 | 第二十四篇】单位和全局可用变量(二)
文章目录 单位和全局可用变量(Units and Globally Available Variables)特殊变量和函数1. 区块和交易属性2. ABI 编码和解码函数3. bytes 成员函数4. string 成员函数5. 错误处理6. 数学和加密函数7. 地址类型成员函数8. 与合约相关9. 类型信息 单位和全…...

C语言:指针数组、函数、二级指针
1.指针数组 指针数组是一个数组,数组中的每个元素都是指针。这些指针可以指向各种类型的数据,如整数、字符、结构体等,甚至可以指向其他数组或函数。 指针数组的声明格式通常为: 数据类型 *数组名[数组大小];其中,数…...
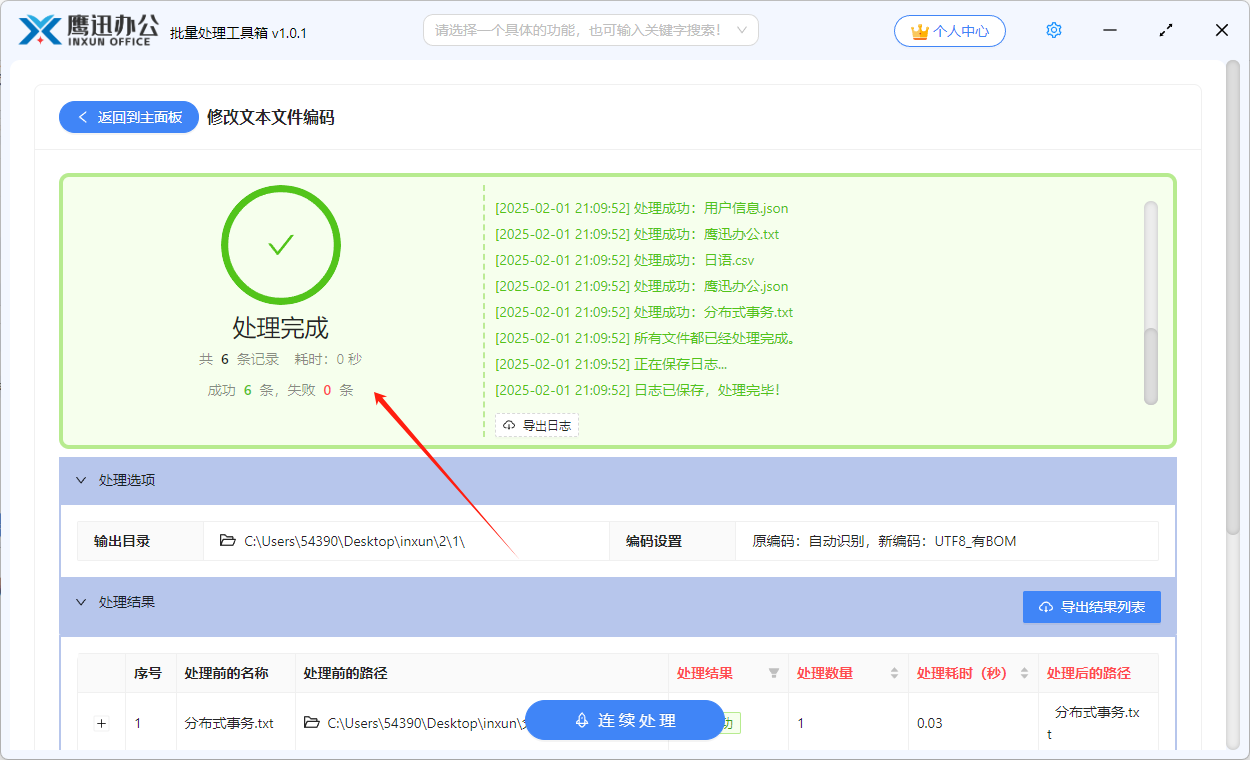
批量修改记事本文本文件编码,可以解决文本文件乱码问题
对于文本文件来说,通常都可以设置不同的编码格式,每一种不同的编码格式支持的字符都可能是不一样的。因此当编码格式出现错误的时候,文本文件可能会出现乱码的问题。如何将文本文件的编码由一种格式变为另外一种格式呢?如果文件出…...

亚马逊云科技提供完全托管的DeepSeek-R1模型
近日,亚马逊云科技宣布在Amazon Bedrock上线完全托管的DeepSeek-R1模型。DeepSeek是首个登陆Amazon Bedrock的国产大模型,自今年1月底推出以来,已有数千客户使用Amazon Bedrock的自定义模型导入功能部署了DeepSeek-R1模型。 DeepSeek在过去几…...

Kafka简要介绍与快速入门示例
1、什么是Kafka? Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。 Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer&…...

线程池自顶向下
在一些场景下,线程会被频繁创建和销毁,但他们却始终在完成相似的任务 这个场景下我们回去引入一个线程池的概念 可以简单总结为: 任务提交 → 核心线程执行 → 任务队列缓存 → 非核心线程执行 → 拒绝策略处理。 话不多说先看一个简单的…...

利用 Chrome devTools Source Override 实现JS逆向破解案例
之前讲解 Chrome 一大强势技术 override 时,给的案例貌似没有给大家留下多深的印象 浏览器本地替换(local overrides)快速定位前端样式问题的案例详解(也是hook js的手段)_浏览器的 overrides 替换功能-CSDN博客 其实…...

Springboot 中使用 List<Integer> 与 JSONArray 处理 JSON 数组的性能与实践
深入对比:Springboot 中使用 List 与 JSONArray 处理 JSON 数组的性能与实践 引言 在现代 Web 开发中,处理 JSON 格式的数据是常见需求。当面对 POST 请求中的 JSON 数组时,开发者常需在 List<Integer> 和 JSONArray 两种方案间抉择。…...

容器C++ ——STL常用容器
string容器 string构造函数 #include<iostream> using namespace std; #include<string.h> void test01() {string s1;//默认构造const char* str "hello world";string s2(str);//传入char*cout << "s2" << s2 << endl;s…...
npu踩坑记录
之前使用qwen系列模型在ascend 910a卡进行了一些生成任务, 贴出踩坑过程也许对遇到类似问题的同学有帮助: ) 目录 千问 qwq32环境配置 代码部署 生成内容清洗 已生成内容清洗 生成过程优化 Failed to initialize the HCCP process问题 assistant 的历史回答丢失 推理执…...

Linux信号——信号的产生(1)
注:信号vs信号量:两者没有任何关系! 信号是什么? Linux系统提供的,让用户(进程)给其他进程发送异步信息的一种方式。 进程看待信号的方式: 1.信号在没有发生的时候,进…...

【机器学习】——机器学习思考总结
摘要 这篇文章深入探讨了机器学习中的数据相关问题,重点分析了神经网络(DNN)的学习机制,包括层级特征提取、非线性激活函数、反向传播和梯度下降等关键机制。同时,文章还讨论了数据集大小的标准、机器学习训练数据量的…...

html处理Base文件流
处理步骤 从服务返回的字符串中提取文件流数据,可能是Base64或二进制。将数据转换为Blob对象。创建对象URL。创建<a>元素,设置href和download属性。触发点击事件以下载文件。删除缓存数据 代码 // 假设这是从服务返回的Base64字符串(…...

力扣每日一题:2712——使所有字符相等的最小成本
使所有字符相等的最小成本 题目示例示例1示例2 题解这些话乍一看可能看不懂,但是多读两遍就明白了。很神奇的解法,像魔术一样。 题目 给你一个下标从 0 开始、长度为 n 的二进制字符串 s ,你可以对其执行两种操作: 选中一个下标…...
:深入了解QMfcApp)
在MFC中使用Qt(六):深入了解QMfcApp
前言 此前系列文章回顾: 在MFC中使用Qt(一):玩腻了MFC,试试在MFC中使用Qt!(手动配置编译Qt) 在MFC中使用Qt(二):实现Qt文件的自动编译流程 在M…...

JMeter进行分布式压测
从机: 1、确认防火墙是否关闭; 2、打开网络设置,关闭多余端口;(避免远程访问不到) 3、打开JMeter/bin 目录底下的jmeter.properties; remove_hosts设置当前访问地址,192.XXXXX&…...

Python实现音频数字水印方法
数字水印技术可以将隐藏信息嵌入到音频文件中而不明显影响音频质量。下面我将介绍几种在Python中实现音频数字水印的方法。 方法一:LSB (最低有效位) 水印 import numpy as np from scipy.io import wavfile def embed_watermark_lsb(audio_path, watermark, ou…...
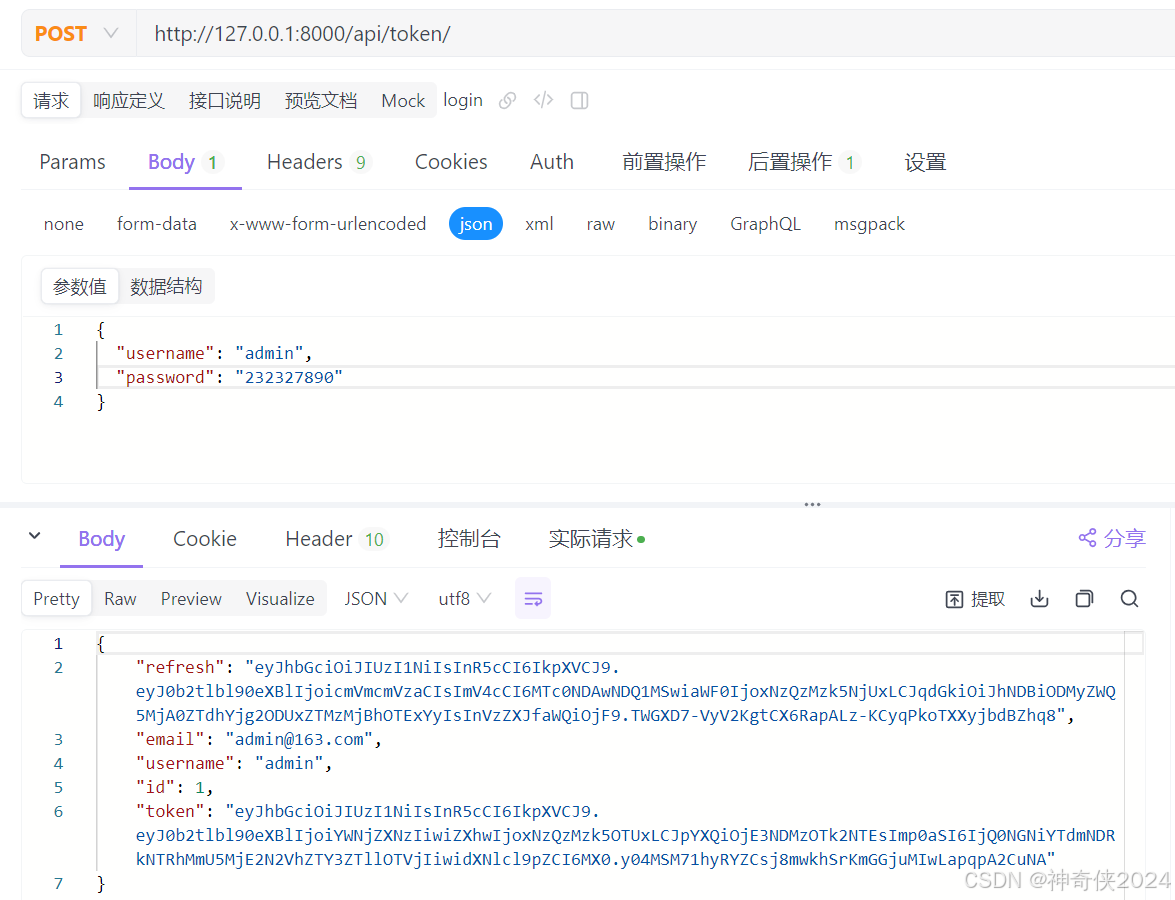
快速入手-基于Django-rest-framework的第三方认证插件(SimpleJWT)权限认证扩展返回用户等其他信息(十一)
1、修改serializer.py,增加自定义类 # 自定义用户登录token等返回信息 class MyTokenObtainPair(TokenObtainPairView): def post(self, request, *args, **kwargs): serializer self.get_serializer(datarequest.data) try: serializer.is_valid(raise_exceptio…...

关于IP免实名的那些事
IP技术已成为个人与企业保护隐私、提升网络效率的重要工具。其核心原理是通过中介服务器转发用户请求,隐藏真实IP地址,从而实现匿名访问、突破地域限制等目标。而“免实名”代理IP的出现,进一步简化了使用流程,用户无需提交身份信…...

【SQL性能优化】预编译SQL:从注入防御到性能飞跃
🔥 开篇:直面SQL的"阿喀琉斯之踵" 假设你正在开发电商系统🛒,当用户搜索商品时: -- 普通SQL拼接(危险!) String sql "SELECT * FROM products WHERE name "…...