python使用cookie、session、selenium实现网站登录(爬取信息)
一、使用cookie
这段代码演示了如何使用Python的urllib和http.cookiejar模块来实现网站的模拟登录,并在登录后访问需要认证的页面。
# 导入必要的库
import requests
from urllib import request, parse# 1. 导入http.cookiejar模块中的CookieJar类,用于存储和管理Cookie
from http.cookiejar import CookieJar# 2. 导入HTTPCookieProcessor,用于处理HTTP请求中的Cookie
from urllib.request import HTTPCookieProcessor# 设置请求头,模拟浏览器访问
header = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"
}# 创建一个CookieJar对象来存储和管理Cookie
cookiejar = CookieJar()# 创建一个HTTPCookieProcessor处理器,用于处理Cookie
handler = HTTPCookieProcessor(cookiejar)# 使用处理器构建一个opener对象,这个opener会自动处理Cookie
opener = request.build_opener(handler)# 准备登录表单数据
data = {'__VIEWSTATE': 'pm4yVT0tOjA36YHPhIUtUmKXH1wGoOp7OTyI8HH+3PU0Z6E4bohm2CzOOCCQ9w2fxqb7oHLCxM4uHc+BiH5Ul4xTGRDehq9E/QXr22y4HX+qpA4v+j5qfIvc3PU=','__VIEWSTATEGENERATOR': 'B6E3F9D8','txtUser': '', # 用户名'txtPass': '', # 密码'btnLogin': '' # 登录按钮 使用自己的
}# 登录页面的URL
loginurl = "http://210.44.176.97/datajudge/login.aspx"# 创建登录请求对象
# 注意:这里将表单数据编码为URL格式,并转换为字节流
req = request.Request(loginurl, data=parse.urlencode(data).encode("utf-8"), headers=header
)# 发送登录请求,opener会自动保存服务器返回的Cookie
opener.open(req)# 如果上面没有抛出异常,意味着登录成功
# 现在可以访问需要登录后才能查看的页面
url = " " #找到自己的# 创建访问请求对象
reqm = request.Request(url, headers=header)# 发送请求,opener会自动带上之前保存的Cookie
resp = opener.open(reqm)# 打印返回的页面内容
print(resp.read().decode("utf-8"))-
Cookie处理机制:
-
使用
CookieJar类创建Cookie容器 -
通过
HTTPCookieProcessor创建处理器,自动处理HTTP请求中的Cookie -
构建
opener对象,后续所有请求都通过这个opener发送,会自动管理Cookie
-
-
模拟登录过程:
-
准备登录表单数据(包括隐藏字段如
__VIEWSTATE) -
发送POST请求到登录页面
-
服务器返回的Cookie会被自动保存在
CookieJar中
-
-
访问受保护页面:
-
使用同一个
opener发送请求 -
opener会自动带上之前保存的Cookie,证明用户已登录
-
成功获取需要认证才能访问的页面内容
-
这种技术常用于:
-
爬取需要登录的网站数据
-
自动化测试需要认证的Web应用
-
模拟用户行为进行网站监控
注意:在实际应用中,应该遵守网站的robots.txt协议和使用条款,不要滥用这种技术。
运行结果:

二、使用session
# 导入requests库,用于发送HTTP请求
import requests# 设置请求头,模拟浏览器访问
# 注意:这里的User-Agent伪装成Chrome浏览器
header = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"
}# 准备登录表单数据
# 注意:ASP.NET网站通常会有__VIEWSTATE和__VIEWSTATEGENERATOR等隐藏字段
data = {'__VIEWSTATE': 'pm4yVT0tOjA36YHPhIUtUmKXH1wGoOp7OTyI8HH+3PU0Z6E4bohm2CzOOCCQ9w2fxqb7oHLCxM4uHc+BiH5Ul4xTGRDehq9E/QXr22y4HX+qpA4v+j5qfIvc3PU=','__VIEWSTATEGENERATOR': 'B6E3F9D8','txtUser': '', # 用户名输入框'txtPass': '', # 密码输入框'btnLogin': '' # 登录按钮 自己的
}# 创建一个会话对象
# 会话对象会自动保持Cookie,用于维持登录状态
session = requests.session()# 登录页面的URL
loginurl = "" #自己寻找# 发送POST请求进行登录
# 使用data参数发送表单数据,headers参数设置请求头
# 登录成功后,服务器返回的Cookie会自动保存在session中
session.post(loginurl, data=data, headers=header)# 如果上面没有抛出异常,意味着登录成功
# 现在可以访问需要登录后才能查看的页面
url = ""# 使用同一个session发送GET请求
# session会自动带上之前登录时获得的Cookie
resp = session.get(url, headers=header)# 打印返回的页面内容
# resp.text会自动解码响应内容
print(resp.text)-
请求头设置:
-
设置User-Agent模拟Chrome浏览器访问,避免被服务器识别为爬虫
-
-
表单数据准备:
-
__VIEWSTATE和__VIEWSTATEGENERATOR是ASP.NET特有的隐藏字段,用于表单状态管理 -
txtUser和txtPass分别对应登录表单的用户名和密码输入框 -
btnLogin是登录按钮的name属性
-
-
会话管理:
-
requests.session()创建一个会话对象,该对象会自动处理Cookie -
所有通过这个session对象发送的请求都会自动携带相同的Cookie
-
-
登录过程:
-
session.post()发送POST请求到登录页面 -
服务器验证成功后返回的Set-Cookie头会被自动保存
-
-
访问受保护页面:
-
使用同一个session对象发送GET请求
-
自动携带登录Cookie,证明用户已认证
-
获取需要登录才能访问的页面内容
-
-
会话保持:
-
requests.session()创建的会话对象会自动管理Cookie -
相比手动处理Cookie更加方便可靠
-
-
ASP.NET特性:
-
ASP.NET网站通常需要提交
__VIEWSTATE等隐藏字段 -
这些字段的值可以从网页源码或第一次GET请求的响应中获取
-
-
安全性注意事项:
-
代码中包含明文密码,实际应用中应该避免
-
可以考虑从配置文件或环境变量读取敏感信息
-
-
异常处理:
-
实际应用中应该添加try-except块处理网络异常
-
可以检查resp.status_code确认请求是否成功
-
典型应用场景
这种代码通常用于:
-
爬取需要登录的网站数据
-
自动化测试Web应用
-
监控需要认证的网页内容变化
-
自动化操作Web系统
注意:使用时应遵守目标网站的服务条款和robots.txt规定。
运行结果:

三、使用selenium
# 导入所需模块
import time # 用于添加等待时间
from selenium import webdriver # 主模块,用于浏览器自动化
from selenium.webdriver.chrome.service import Service as ChromeService # Chrome服务
from selenium.webdriver.common.by import By # 定位元素的方式# 设置ChromeDriver路径
driver_path = r"E:\chromedriver\chromedriver.exe" # ChromeDriver可执行文件路径# 创建Chrome服务实例
service = ChromeService(executable_path=driver_path)# 初始化Chrome浏览器驱动
driver = webdriver.Chrome(service=service)# 目标登录页面URL
loginurl = ""# 打开登录页面
driver.get(loginurl)# 使用XPath定位用户名输入框并输入用户名
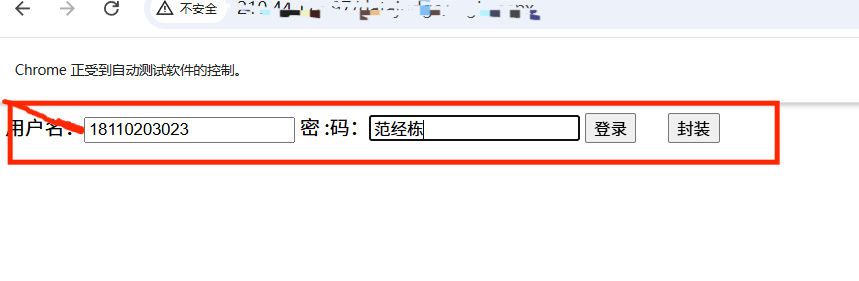
driver.find_element(By.XPATH, "//input[@id='txtUser']").send_keys("18110203023")# 使用XPath定位密码输入框并输入密码
driver.find_element(By.XPATH, "//input[@id='txtPass']").send_keys("范经栋")# 等待3秒,确保页面加载完成(实际应用中建议使用显式等待)
time.sleep(3)# 使用XPath定位登录按钮并点击
driver.find_element(By.XPATH, "//input[@id='btnLogin']").click()# 等待2秒,确保登录完成
time.sleep(2)# 打印当前页面的源代码(登录后的页面)
print(driver.page_source)# 注释掉的代码是之前使用requests库实现的版本,与当前selenium实现做对比
# session.post(loginurl,data=data,headers=header)
# # 意味着登录成功,session对象中已经存储了登录成功地数据
# url="http://210.44.176.97/datajudge/test.aspx"
#
# resp=session.get(url,headers=header)
# print(resp.text)-
初始化浏览器驱动:
-
通过
ChromeService指定ChromeDriver路径 -
创建
webdriver.Chrome实例来控制浏览器
-
-
页面导航:
-
driver.get(loginurl)打开登录页面
-
-
元素定位与操作:
-
使用XPath定位用户名输入框(
id='txtUser')并输入用户名 -
使用XPath定位密码输入框(
id='txtPass')并输入密码 -
使用XPath定位登录按钮(
id='btnLogin')并点击
-
-
等待机制:
-
time.sleep(3)在输入密码后等待3秒 -
time.sleep(2)在点击登录后等待2秒 -
(注:实际项目中建议使用selenium的显式等待
WebDriverWait)
-
-
结果获取:
-
driver.page_source获取当前页面的HTML源码
-
与requests实现的区别
-
模拟方式:
-
selenium实际控制浏览器操作,完全模拟用户行为
-
requests直接发送HTTP请求,更轻量但无法处理JavaScript
-
-
验证处理:
-
selenium能自动处理图片验证码等需要人工交互的情况
-
requests需要额外处理这类验证
-
-
性能:
-
selenium启动浏览器开销大,运行速度慢
-
requests更高效,适合大规模爬取
-
-
应用场景:
-
selenium适合需要完全模拟浏览器行为的复杂场景
-
requests适合简单的API调用或静态页面抓取
-
运行结果:

相关文章:
python使用cookie、session、selenium实现网站登录(爬取信息)
一、使用cookie 这段代码演示了如何使用Python的urllib和http.cookiejar模块来实现网站的模拟登录,并在登录后访问需要认证的页面。 # 导入必要的库 import requests from urllib import request, parse# 1. 导入http.cookiejar模块中的CookieJar类,用…...

vector模拟实现2
文章目录 vector的模拟实现erase函数resize拷贝构造赋值重载函数模版构造及其细节结语 我们今天又见面啦,给生活加点impetus!!开启今天的编程之路 今天我们来完善vector剩余的内容,以及再探迭代器失效! 作者ÿ…...

观察者模式在Java单体服务中的运用
观察者模式主要用于当一个对象发生改变时,其关联的所有对象都会收到通知,属于事件驱动类型的设计模式,可以对事件进行监听和响应。下面简单介绍下它的使用: 1 定义事件 import org.springframework.context.ApplicationEvent;pu…...
详解相机的内参和外参,以及内外参的标定方法
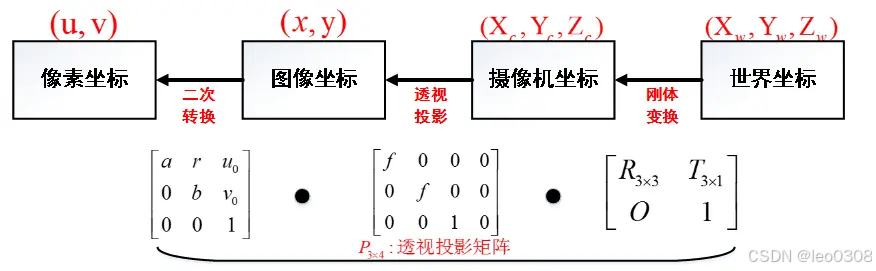
1 四个坐标系 要想深入搞清楚相机的内参和外参含义, 首先得清楚以下4个坐标系的定义: 世界坐标系: 名字看着很唬人, 其实没什么大不了的, 这个就是你自己定义的某一个坐标系。 比如, 你把房间的某一个点定…...

在线sql 转 rust 模型(Diesel、SeaORM),支持多数据 mysql, pg等
SQL 转 Rust 在 Rust 语言中,常用 Diesel 和 SeaORM 进行数据库操作。手写 ORM 模型繁琐,gotool.top 提供 SQL 转 Diesel、SeaORM 工具,自动生成 Rust 代码,提高开发效率。 特色 支持 Diesel / SeaORM,生成符合规范…...

高并发内存池(二):Central Cache的实现
前言:本文将要讲解的高并发内存池,它的原型是Google的⼀个开源项⽬tcmalloc,全称Thread-Caching Malloc,近一个月我将以学习为目的来模拟实现一个精简版的高并发内存池,并对核心技术分块进行精细剖析,分享在…...
[Windows] VutronMusic v1.6.0 音乐播放器纯净版,可登录同步
VutronMusic-简易好看的PC音乐播放器 链接:https://pan.xunlei.com/s/VOMq7P_fTyhLUXeGerDVhrCTA1?pwduvut# VutronMusic v1.6.0 音乐播放器纯净版,可登录同步...

macvlan 和 ipvlan 实现原理及设计案例详解
一、macvlan 实现原理 1. 核心概念 macvlan 允许在单个物理网络接口上创建多个虚拟网络接口,每个虚拟接口拥有 独立的 MAC 地址 和 IP 地址。工作模式: bridge 模式(默认):虚拟接口之间可直接通信,类似交…...
【蓝桥杯】每日练习 Day19,20
目录 前言 蒙德里安的梦想 分析 最短Hamilton路径 分析 代码 乌龟棋 分析 代码 松散子序列 分析 代码 代码 前言 今天不讲数论(因为上课学数论真是太难了,只学了高斯消元)所以今天就不单独拿出来讲高斯消元了。今天讲一下昨天和…...

《AI大模型应知应会100篇》第7篇:Prompt Engineering基础:如何与大模型有效沟通
第7篇:Prompt Engineering基础:如何与大模型有效沟通 摘要 Prompt Engineering(提示工程)是与大模型高效沟通的关键技能。通过精心设计的Prompt,可以让模型生成更准确、更有用的结果。本文将从基础知识到高级策略&…...

微服务架构技术栈选型避坑指南:10大核心要素深度拆解
微服务架构的技术栈选型直接影响系统的稳定性、扩展性和可维护性。以下从10大核心要素出发,结合主流技术方案对比、兼容性评估、失败案例及优化策略,提供系统性选型指南。 1. 服务框架与通信 关键考量点 扩展性:框架需支持定制化扩展&#x…...

Elasticsearch 正排索引
一、正排索引基础概念 在 Elasticsearch 中,正排索引用于存储完整的文档内容,以便通过文档ID 快速定位文档的字段值。正排索引通过 Doc Values 和 Store Fields 两种形式,为聚合、排序、脚本计算等场景提供高效支持。Doc Values 的列式存储设…...
Spring实现WebScoket
SpringWeb编程方式分为Servlet模式和响应式。Servlet模式参考官方文档:Web on Servlet Stack :: Spring Framework,响应式(Reacive)参考官方文档:Web on Reactive Stack :: Spring Framework。 WebSocket也有两种编程方…...

Token是什么?
李升伟 整理 “Token” 是一个多义词,具体含义取决于上下文。以下是几种常见的解释: 1. 计算机科学中的 Token 定义:在编程和计算机科学中,Token 是源代码经过词法分析后生成的最小单位,通常用于编译器和解释器。 …...

odoo-045 ModuleNotFoundError: No module named ‘_sqlite3‘
文章目录 一、问题二、解决思路 一、问题 就是项目启动,本来好好地,忽然有一天报错,不知道什么原因。 背景: 我是在虚拟环境中使用的python3.7。 二、解决思路 虚拟环境和公共环境直接安装 sqlite3 都会报找不到这个库的问题…...

cesium加载CTB生成的地形数据
由于CTB生成的地形数据是压缩的(gzip)格式,需要在nginx加上特殊配置才可以正常加载,NGINX全部配置如下 worker_processes 1; events {worker_connections 1024; } http {include mime.types;default_type application/o…...

前端JS高阶技法:序列化、反序列化与多态融合实战
✨ 摘要 序列化与反序列化作为数据转换的核心能力,与多态这一灵活代码设计的核心理念,在现代前端开发中协同运作,提供了高效的数据通信与扩展性支持。 本文从理论到实践,系统解析: 序列化与反序列化的实现方式、使用…...

TS中的Class
基本用法 implements implements 关键字用于传递对类产生约束的数据类型 interface AnimalInfo{name:stringrace:stringage:number }interface AnimalCls{info:AnimalInfosayName():void} class Animal implements AnimalCls{info:AnimalInfoconstructor(info:AnimalInfo) {t…...
RustDesk 开源远程桌面软件 (支持多端) + 中继服务器伺服器搭建 ( docker版本 ) 安装教程
在需要控制和被控制的电脑上安装软件 github开源仓库地址 https://github.com/rustdesk/rustdesk/releases 蓝奏云盘备份 ( exe ) https://geek7.lanzouw.com/iPf592sadqrc 密码:4esi 中继服务器设置 使用docker安装 sudo docker image pull rustdesk/rustdesk-server sudo…...
)
【计网速通】计算机网络核心知识点与高频考点——数据链路层(二)
数据链路层核心知识点(二) 涵盖局域网、广域网、介质访问控制(MAC层)及数据链路层设备 上文链接:https://blog.csdn.net/weixin_73492487/article/details/146571476 一、局域网(LAN,Loacl Area Network&am…...
STM32单片机入门学习——第3-4节: [2-1、2]软件安装和新建工程
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.01 STM32开发板学习——第一节: [1-1]课程简介 前言开发板说明引用解答和…...

W3C XML Schema 活动
W3C XML Schema 活动 概述 W3C XML Schema(XML Schema)是万维网联盟(W3C)定义的一种数据描述语言,用于定义XML文档的结构和约束。XML Schema为XML文档提供了一种结构化的方式,确保数据的一致性和有效性。本文将详细介绍W3C XML Schema的活动,包括其发展历程、主要特点…...

爬虫【Scrapy-redis分布式爬虫】
Scrapy-redis分布式爬虫 1.Scrapy-redis实现增量爬虫 增量爬虫的含义 就是前面所说的的暂停、恢复爬取 安装 # 使用scrapy-redis之前最好将scrapy版本保持在2.8.0版本, 因为2.11.0版本有兼容性问题 pip install scrapy==2.8.0 pip install scrapy-redis -i https://pypi.tun…...
intellij Idea 和 dataGrip下载和安装教程
亲测有效 第一步:卸载老版本idea/Datagrip (没有安装过的可跳过此步骤) 第二步:下载idea/dataGrip安装包 建议选择2022以后的版本 官网: https://www.jetbrains.com/datagrip/download/other.html 选择dataGrip 的…...

轻量级搜索接口技术解析:快速实现关键词检索的Java/Python实践
Hi,你好! 轻量级搜索接口技术解析:快速实现关键词检索的Java/Python实践 接口特性与适用场景 本接口适用于需要快速集成搜索能力的开发场景,支持通过关键词获取结构化搜索结果。典型应用场景包括: 垂直领域信息检索…...
架构设计基础系列:事件溯源模式浅析
图片来源网络,侵权删 1. 引言 1.1 研究背景 传统CRUD模型的局限性:状态覆盖导致审计困难、无法追溯历史。分布式系统复杂性的提升:微服务架构下数据一致性、回滚与调试的需求激增。监管合规性要求:金融、医疗等领域对数…...

ResNet系列和ViT系列预训练模型权重文件下载
一、简单介绍 OpenAI CLIP项目提供的预训练模型权重文件列表,主要包含两种架构系列和不同规模配置: ResNet系列 (RN) 基础版本:RN50(ResNet-50)扩展版本:RN50x4、RN50x16、RN50x64(宽度扩展&am…...

【力扣hot100题】(035)二叉树的中序遍历
正常方法递归很简单,于是又学了一种栈的方法。 原理如下:每次循环先尽量将目前节点入栈并左移,没有左节点时回到栈首节点将目前节点放入结果容器中并移出栈外,目前节点变为该节点的右节点,循环结束条件是目前节点为nu…...

《数字图像处理》教材寻找合作者
Rafael Gonzalez和Richard Woods所著的《数字图像处理》关于滤波器的部分几乎全错,完全从零开始写,困难重重。关于他的问题已经描述在《数字图像处理(面向新工科的电工电子信息基础课程系列教材)》。 现寻找能够共同讨论、切磋、…...
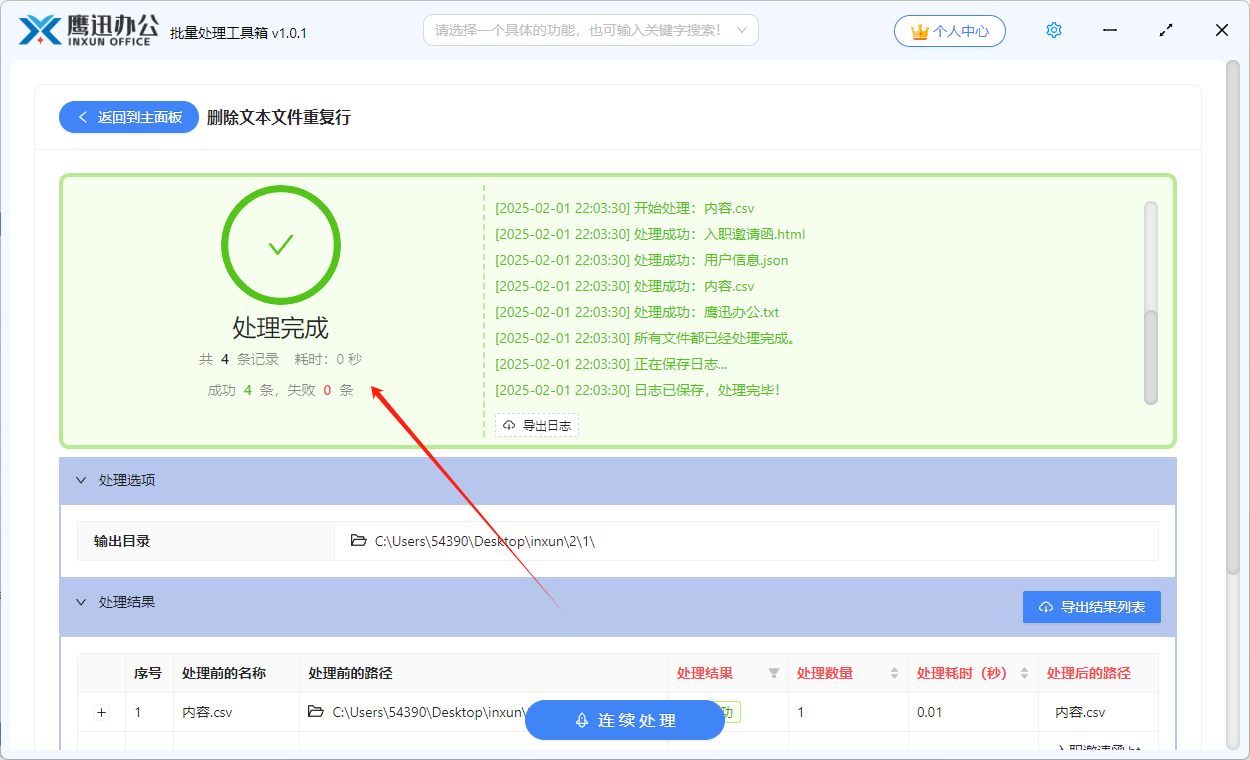
批量删除 txt/html/json/xml/csv 等文本文件中的重复行
在文本文件中,可能会存在一些重复的数据行,这可能不是我们期望的,因此我们会碰到需要删除文本文件中重复行的情况。如果是人工删除,当文件较大或者数量较多的时候,处理的难度会较大。今天就给大家介绍一下批量删除文本…...