C语言常见3种排序
主要是三种排序方法:冒泡排序、选择排序、插入排序。
文章目录
一、冒泡排序
1.代码:
2.工作原理:
3.具体过程:
二、选择排序
1.代码
2. 工作原理
3.具体过程:
三、插入排序
1.代码
2.工作原理
3.具体过程
总结
一、冒泡排序
通过重复遍历待排序的列表,比较相邻元素并交换顺序错误的元素。(其名称源于较小的元素会像“气泡”一样逐渐“浮”到列表顶端。)
1.代码:
代码如下(示例):
//冒泡排序
//从小到大
int main()
{int i = 0;//i表示趟数int j = 0;int a[5] = { 5,3,8,4,6 };for (i = 0; i < 5; i++)//至少4趟,这里也可以写成i<4{for (j = 0; j < 5-i-1; j++){if (a[j] > a[j + 1]){int tmp = a[j];a[j] = a[j + 1];a[j + 1] = tmp;}}}for (i = 0; i < 5; i++){printf("%d ", a[i]);}return 0;
}
2.工作原理:
1. **比较相邻元素**:从列表的第一个元素开始,比较相邻的两个元素。
2. **交换元素**:如果顺序错误(如前一个元素大于后一个元素),则交换它们。
3. **重复遍历**:重复上述步骤,直到没有需要交换的元素,列表排序完成。
3.具体过程:
1. **第一轮**:
- 比较 5 和 3,交换,得 `[3, 5, 8, 4, 6]`
- 比较 5 和 8,不交换
- 比较 8 和 4,交换,得 `[3, 5, 4, 8, 6]`
- 比较 8 和 6,交换,得 `[3, 5, 4, 6, 8]`
- 第一轮结束,最大的元素 8 已“浮”到末尾。2. **第二轮**:
- 比较 3 和 5,不交换
- 比较 5 和 4,交换,得 `[3, 4, 5, 6, 8]`
- 比较 5 和 6,不交换
- 第二轮结束,第二大的元素 6 已“浮”到倒数第二位。3. **第三轮**:
- 比较 3 和 4,不交换
- 比较 4 和 5,不交换
- 第三轮结束,列表已排序完成。最终排序结果为 `[3, 4, 5, 6, 8]`。
### 时间复杂度
- **最坏情况**:O(n²),列表完全逆序时。
- **平均情况**:O(n²)。
- **最好情况**:O(n),列表已经有序时。
### 优点
- 实现简单。
- 对小规模数据有效。
### 缺点
- 效率低,尤其对大规模数据。
- 需要多次遍历和交换。
### 适用场景
适用于数据量小或对性能要求不高的场景。
二、选择排序
通过不断选择未排序部分的最小元素,并将其放到已排序部分的末尾。其核心思想是每次从未排序部分选出最小元素,与未排序部分的第一个元素交换。
1.代码
代码如下(示例):
//选择排序
int main()
{int i = 0;//i表示趟数int j = 0;int a[5] = { 64,65,12,22,11 };for (i = 0; i < 5; i++)//选择排序次数{int min = i;//假设每一趟第一个元素是最小的for (j = i; j < 5 ; j++)//元素个数{if (a[min]>a[j]){min = j; }}int tmp = a[i];a[i] = a[min];a[min] = tmp;}for (i = 0; i < 5; i++){printf("%d ", a[i]);}return 0;
}2. 工作原理
1. **找到最小元素**:在未排序部分中找到最小元素。
2. **交换元素**:将最小元素与未排序部分的第一个元素交换。
3. **重复步骤**:重复上述过程,直到所有元素排序完成。
3.具体过程:
1. **第一轮**:
- 找到最小元素 11,与第一个元素 64 交换,得 `[11, 25, 12, 22, 64]`
- 已排序部分为 `[11]`,未排序部分为 `[25, 12, 22, 64]`2. **第二轮**:
- 找到最小元素 12,与第一个元素 25 交换,得 `[11, 12, 25, 22, 64]`
- 已排序部分为 `[11, 12]`,未排序部分为 `[25, 22, 64]`3. **第三轮**:
- 找到最小元素 22,与第一个元素 25 交换,得 `[11, 12, 22, 25, 64]`
- 已排序部分为 `[11, 12, 22]`,未排序部分为 `[25, 64]`4. **第四轮**:
- 找到最小元素 25,已在正确位置,无需交换。
- 已排序部分为 `[11, 12, 22, 25]`,未排序部分为 `[64]`5. **第五轮**:
- 最后一个元素 64 已在正确位置。
- 最终排序结果为 `[11, 12, 22, 25, 64]`
### 时间复杂度
- **最坏情况**:O(n²),列表完全逆序时。
- **平均情况**:O(n²)。
- **最好情况**:O(n²),即使列表已经有序,仍需进行相同次数的比较。
### 优点
- 实现简单。
- 对小规模数据有效。
### 缺点
- 效率低,尤其对大规模数据。
- 需要多次遍历和交换。
### 适用场景
适用于数据量小或对性能要求不高的场景。
三、插入排序
通过构建有序序列,逐步将未排序部分的元素插入到已排序部分的适当位置。其核心思想是将每个未排序元素插入到已排序部分的正确位置,直到所有元素排序完成。
1.代码
代码如下(示例):
int main() {int arr[] = {12, 11, 13, 5, 6};int n = sizeof(arr) / sizeof(arr[0]);// 插入排序(直接写在 main 里)for (int i = 1; i < n; i++) {int key = arr[i]; // 当前要插入的元素int j = i - 1; // 已排序部分的最后一个位置// 把比 key 大的元素往后移while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key; // 插入到正确位置}// 输出排序后的数组printf("Sorted array: ");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;
}外层循环:从第 2 个元素(`i = 1`)开始遍历数组,因为第一个元素默认是“已排序”的。
内层循环:从 `i - 1` 开始往前找,如果 `arr[j] > key`,就把 `arr[j]` 往后移一位。
直到找到 `arr[j] <= key` 的位置,然后把 `key` 插入到 `j + 1` 的位置。
2.工作原理
1. **初始状态**:将第一个元素视为已排序部分,其余元素为未排序部分。
2. **插入元素**:从未排序部分取出第一个元素,与已排序部分的元素从后向前比较,找到合适的位置插入。
3. **重复步骤**:重复上述过程,直到所有元素排序完成。
3.具体过程
1. **第一轮**:
- 已排序部分为 `[12]`,未排序部分为 `[11, 13, 5, 6]`
- 取出 11,与 12 比较,插入到 12 前面,得 `[11, 12, 13, 5, 6]`
- 已排序部分为 `[11, 12]`,未排序部分为 `[13, 5, 6]`2. **第二轮**:
- 取出 13,与 12 比较,插入到 12 后面,得 `[11, 12, 13, 5, 6]`
- 已排序部分为 `[11, 12, 13]`,未排序部分为 `[5, 6]`3. **第三轮**:
- 取出 5,与 13、12、11 比较,插入到 11 前面,得 `[5, 11, 12, 13, 6]`
- 已排序部分为 `[5, 11, 12, 13]`,未排序部分为 `[6]`4. **第四轮**:
- 取出 6,与 13、12、11、5 比较,插入到 5 后面,得 `[5, 6, 11, 12, 13]`
- 已排序部分为 `[5, 6, 11, 12, 13]`,未排序部分为空
### 时间复杂度
- **最坏情况**:O(n²),列表完全逆序时。
- **平均情况**:O(n²)。
- **最好情况**:O(n),列表已经有序时。
### 优点
- 实现简单。
- 对小规模数据或基本有序的数据有效。
### 缺点
- 效率低,尤其对大规模数据。
- 需要多次比较和移动。
### 适用场景
适用于数据量小或基本有序的数据集。
总结
主要是三种排序方法:冒泡排序、选择排序、插入排序。
以及它们的工作原理,具体的工作流程,时间复杂度空间复杂度和适用场景
相关文章:

C语言常见3种排序
主要是三种排序方法:冒泡排序、选择排序、插入排序。 文章目录 一、冒泡排序 1.代码: 2.工作原理: 3.具体过程: 二、选择排序 1.代码 2. 工作原理 3.具体过程: 三、插入排序 1.代码 2.工作原理 3.具体过程 总结 一、…...
分析sys高问题的方法总结
一、背景 sys高的问题往往属于底层同学更需要关注的问题,sys高的问题往往表现为几种情况,一种是瞬间的彪高,一种是持续的彪高。这篇博客里,我们总结一下常用的分析方法和分析工具的使用来排查这类sys高的问题。 二、通过mpstat配…...

智谱发布AI Agent“AutoGLM沉思”,开启AI“边想边干”新时代
近日,智谱正式推出全新AI Agent产品——AutoGLM沉思,标志着人工智能从“思考”迈向“执行”的关键突破。该智能体不仅具备深度研究能力,还能自主完成实际操作,真正实现“边想边干”的智能化应用。 在演示环节,智谱展示…...

使用Leaflet对的SpringBoot天地图路径规划可视化实践-以黄花机场到橘子洲景区为例
目录 前言 一、路径规划需求 1、需求背景 2、技术选型 3、功能简述 二、Leaflet前端可视化 1、内容布局 2、路线展示 3、转折路线展示 三、总结 前言 在当今数字化与智能化快速发展的时代,路径规划技术已经成为现代交通管理、旅游服务以及城市规划等领域的…...
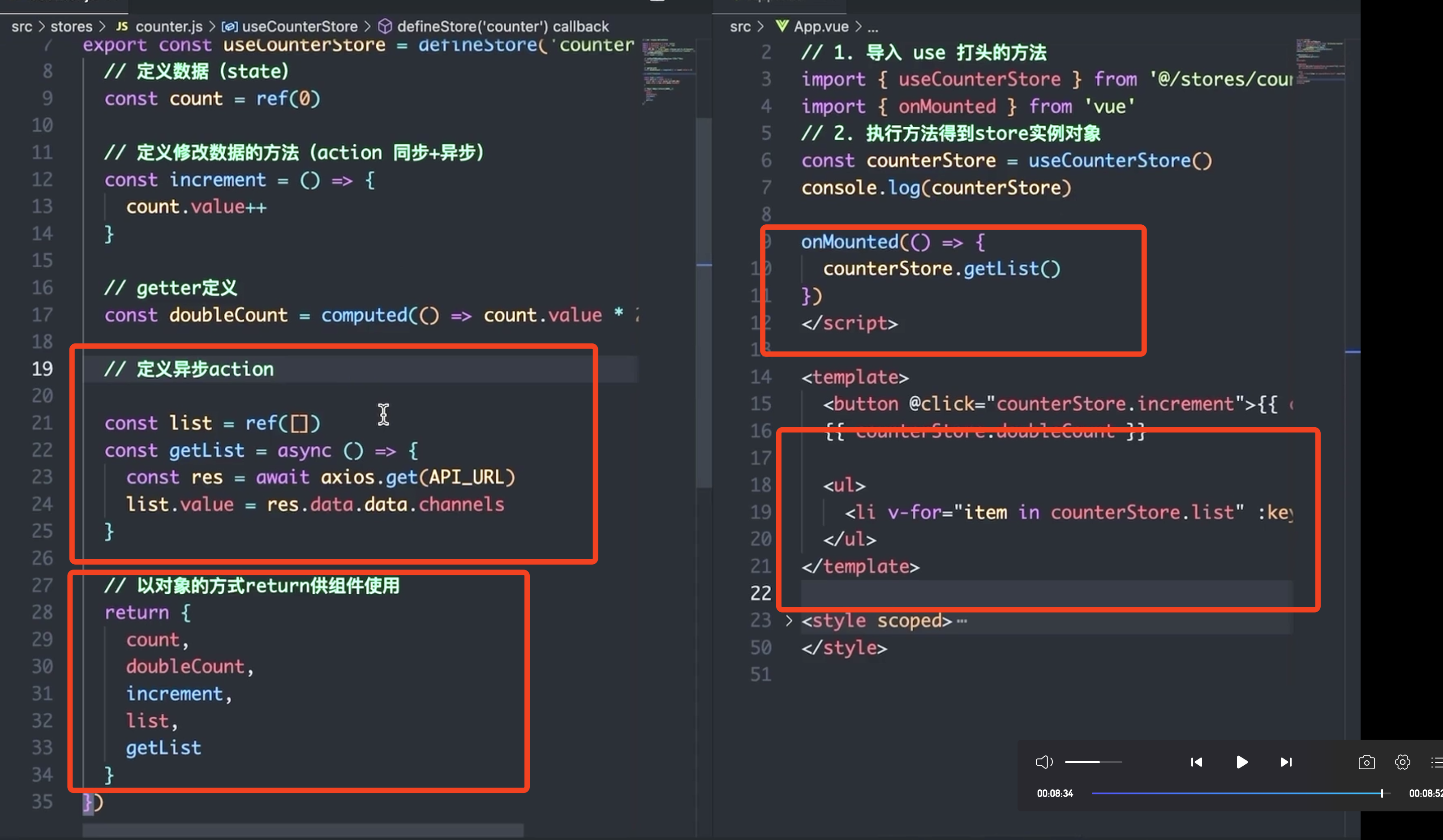
【小兔鲜】day02 Pinia、项目起步、Layout
【小兔鲜】day02 Pinia、项目起步、Layout 1. Pinia2. 添加Pinia到Vue项目3. 案例:Pinia-counter基础使用3.1 Store 是什么?3.2 应该在什么时候使用 Store? 4. Pinia-getters和异步action4.1 getters4.2 action如何实现异步 1. Pinia Pinia 是 Vue 的专…...
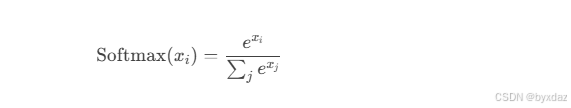
PyTorch 激活函数
激活函数是神经网络中至关重要的组成部分,它们为网络引入了非线性特性,使得神经网络能够学习复杂模式。PyTorch 提供了多种常用的激活函数实现。 常用激活函数 1. ReLU (Rectified Linear Unit) 数学表达式: PyTorch实现: torch.nn.ReLU(inplaceFals…...
魔塔社区使用llamafactory微调AI阅卷试题系统
启动 LLaMA-Factory 1. 安装 LLaMA-Factory 执行安装指令 git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch,metrics]"解决依赖冲突 如果遇到依赖冲突,可使用以下命令安装,不…...

Java面试黄金宝典29
1. 什么是普通索引和唯一性索引 定义: 普通索引:是最基本的索引类型,它为数据表中的某一列或多列建立索引,以加快数据的查询速度。它不限制索引列的值重复,允许存在多个相同的值。唯一性索引:在普通索引的基…...

git `switch` 命令详解与实用示例
文章目录 git switch 命令详解与实用示例git switch vs git checkoutgit switch 用法1. 切换到已有分支2. 创建并切换到新分支3. 切换到上一个分支4. 切换到远程分支(自动创建本地分支并追踪远程)5. 放弃未提交的修改并切换分支 总结 git switch 命令详解…...

Oracle中文一二三四排序【失败】
原文地址: Oracle数据库如何对中文的一二三四五六七八九十数进行正序排列排序_中文数字排序-CSDN博客 自定义排序函数 -- 自定义中文映射阿拉伯数字函数 CREATE OR REPLACE FUNCTION P_ORDER_CHINESE_TO_ARABIC(V_NUM VARCHAR2) RETURN NUMBER IS BEGIN-- 根据…...

AWS S3 和 Lambda 使用
目录: AWS概述 EMR Serverless AWS VPC及其网络 关于AWS网络架构的思考 AWS S3 和 Lambda 使用 本文将通过一个实例来说明如何使用 AWS S3 和 Lambda。 使用场景:通过代码将文件上传到S3,该文件需要是公开访问的,并对上传的文件进…...

Mysql 在什么样的情况下会产生死锁?
在 MySQL 中,死锁是指两个或多个事务相互等待对方释放锁,导致所有相关事务无法继续执行的情况。死锁会影响数据库的并发性能,因此需要及时检测并处理。假设有两个事务 T1 和 T2: 事务 T1 首先锁定 表 A 的行 1。然后尝试锁定 表 B…...

符号秩检验
内容来源 非参数统计(第2版) 清华大学出版社 王星 褚挺进 编著 符号秩检验 在符号检验的基础上,增加了数据绝对值大小的信息 检验统计量 用一个简单的例子来说明 样本数据 X i , i 1 , ⋯ , 6 X_i,i1,\cdots,6 Xi,i1,⋯,6 如下 X …...

RainbowDash 的 Robot
H RainbowDash 的 Robot - 第七届校赛正式赛 —— 补题 题目大意: 给一个 n ∗ m n*m n∗m 的二维网格,在第 i i i 列中,前 a i a_i ai 单元格被阻断,无法通行,即 [ 1 , a i ] [1,a_i] [1,ai] 。 一个机器人正…...

yum repolist all全部禁用了 怎么办
文章目录 步骤思考解决yum仓库全部被禁用的问题步骤思考: 检查仓库状态:运行yum repolist all,查看所有仓库的启用状态。 被禁用的仓库会显示为disabled。 启用所有仓库:可以逐一启用,或者使用命令批量启用。 例如使用yum-config-manager --enable ‘*’,但需要注意是否有…...

SQL WHERE 与 HAVING
WHERE 和 HAVING 都是 SQL 中用于筛选数据的子句,但它们有重要的区别 WHERE 子句 在 分组前 过滤数据 作用于 原始数据行 不能使用聚合函数 执行效率通常比 HAVING 高 SELECT column1, column2 FROM table WHERE condition; HAVING 子句 在 分组后 过滤数据 …...

如何在 Unity3D 导入 Spine 动画
一、前言 《如何在 Unity3D 项目中导入 Spine 动画》,虽然在网上有很多这种文章,直接将问题交给 DeepSeek 也能得到具体的操作流程,但是照着他们提供的方法还是能遇到几个问题,比如: AI 回答没有提到 Unity 无法识别.…...

子网划分2
子网分配的问题,下列vlsm如何设置? 某公司申请了一个C类202.60.31.0的IP地址,要求设置三个子网,一个为100台主机,一个为50台主机,另一个为50台主机,用VLSM如何设置? 哪位高手指教一…...

C++的UDP连接解析域名地址错误
背景 使用c开发一个udp连接功能的脚本,可以接收发送数据,而且地址是经过内网穿透到外网的 经过 通常发送数据给目标地址,需要把目的地址结构化,要么使用inet_addr解析ip地址,要么使用inet_pton sockaddr_in target…...

23种设计模式中的观察者模式
定义了一种一对多的依赖关系,当一个对象的状态发生改变时,其所有依赖者都会收到通知并自动更新。 观察者模式是一种发布-订阅模式。它让发送通知的一方(被观察者)和接收通知的一方(观察者)能够解耦…...
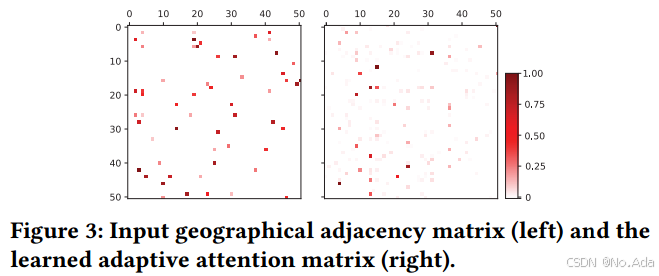
论文笔记:ASTTN模型
研究现状 现有研究大多通过分别考虑空间相关性和时间相关性或在滑动时间窗口内对这种时空相关性进行建模,而未能对直接的时空相关性进行建模。受最近图领域Transformer成功的启发,该模型提出利用局部多头自关注,在自适应时空图上直接建立跨时…...

Java单例模式详解
单例模式详解 一、单例模式概述 单例模式(Singleton Pattern)是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来访问这个实例。 核心特点 唯一实例:保证一个类只有一个实例存在全局访问:提供统一的访问入…...

Linux命令-tar
tar 命令的完整参数列表: 参数 描述 -c 创建新的归档文件 -x 解压归档文件 -t 列出归档文件内容 -r 追加文件到归档文件 -u 更新归档文件中的文件 -d 从归档文件中删除文件 -f 指定归档文件的名称 -v 显示详细信息(verbose) -z 使用 gzip 压缩…...

深入解析 Git Submodule:从基础到高级操作指南
深入解析 Git Submodule:从基础到高级操作指南 一、Git Submodule 是什么? git submodule 是 Git 提供的一个强大功能,允许在一个 Git 仓库(主仓库)中嵌入另一个独立的 Git 仓库(子模块)。主仓…...

2025-4-2 蓝桥杯刷题情况(分布式队列)
1.题目描述 小蓝最近学习了一种神奇的队列:分布式队列。简单来说,分布式队列包含 N 个节点(编号为0至N-1,其中0号为主节点),其中只有一个主节点,其余为副节点。 主/副节点中都各自维护着一个队列,当往分布式队列中添加…...

C/C++指针核心难点全解析:从内存模型到实战避坑指南
引言:指针为何被称为C/C的“灵魂”? 指针是C/C语言中最强大的工具之一,也是开发者通往底层编程的必经之路。它直接操作内存地址的能力,赋予了程序极高的灵活性和性能优势。然而,指针的复杂性也让无数初学者“折戟沉沙…...
)
ray.rllib-入门实践-12-2:在自定义policy中注册使用自定义model(给自定义model新增参数)
建议先看博客 ray.rllib-入门实践-12-1:在自定义policy中注册使用自定义model , 本博客与之区别在于可以给自定义的 model 新增自定义的参数,并通过 config.model["custom_model_config"] 传入自定义的新增参数。 环境配置…...

【Java中级】10章、内部类、局部内部类、匿名内部类、成员内部类、静态内部类的基本语法和细节讲解配套例题巩固理解【5】
❤️ 【内部类】干货满满,本章内容有点难理解,需要明白类的实例化,学完本篇文章你会对内部类有个清晰的认知 💕 内容涉及内部类的介绍、局部内部类、匿名内部类(重点)、成员内部类、静态内部类 🌈 跟着B站一位老师学习…...

swift-7-汇编分析闭包本质
一、汇编分析 fn1里面存放的东西 func testClosure2() {class Person {var age: Int 10}typealias Fn (Int) -> Intvar num 0func plus(_ i: Int) -> Int {num ireturn num}return plus} // 返回的plus和num形成了闭包var fn1 getFn()print(fn1(1)) // 1print(fn1(…...

Linux: 进程信号初识
目录 一 前言 二 信号的感性认识 三 信号处理常见方式 四 系统信号列表 五 信号的保存 六 信号的产生 1. 通过终端按键产生信号 2. 通过系统调用向进程发送信号 3. 硬件异常产生信号 4. 软件条件产生信号 一 前言 在Linux操作系统中,进程信号是一个非常重…...