深度学习处理文本(6)
理解词嵌入
重要的是,进行one-hot编码时,你做了一个与特征工程有关的决策。你向模型中注入了有关特征空间结构的基本假设。这个假设是:你所编码的不同词元之间是相互独立的。事实上,one-hot向量之间都是相互正交的。对于单词而言,这个假设显然是错误的。单词构成了一个结构化的空间,单词之间共享信息。在大多数句子中,“movie”和“film”这两个词是可以互换的,所以表示“movie”的向量与表示“film”的向量不应该正交,它们应该是同一个向量,或者非常相似。说得更抽象一点,两个词向量之间的几何关系应该反映这两个单词之间的语义关系。例如,在一个合理的词向量空间中,同义词应该被嵌入到相似的词向量中,一般来说,任意两个词向量之间的几何距离(比如余弦距离或L2距离)应该与这两个单词之间的“语义距离”有关。含义不同的单词之间应该相距很远,而相关的单词应该相距更近。词嵌入是实现这一想法的词向量表示,它将人类语言映射到结构化几何空间中。
one-hot编码得到的向量是二进制的、稀疏的(大部分元素是0)、高维的(维度大小等于词表中的单词个数),而词嵌入是低维的浮点向量(密集向量,与稀疏向量相对),如图11-2所示。常见的词嵌入是256维、512维或1024维(处理非常大的词表时)。与此相对,one-hot编码的词向量通常是20 000维(词表中包含20 000个词元)或更高。因此,词嵌入可以将更多的信息塞入更少的维度中。
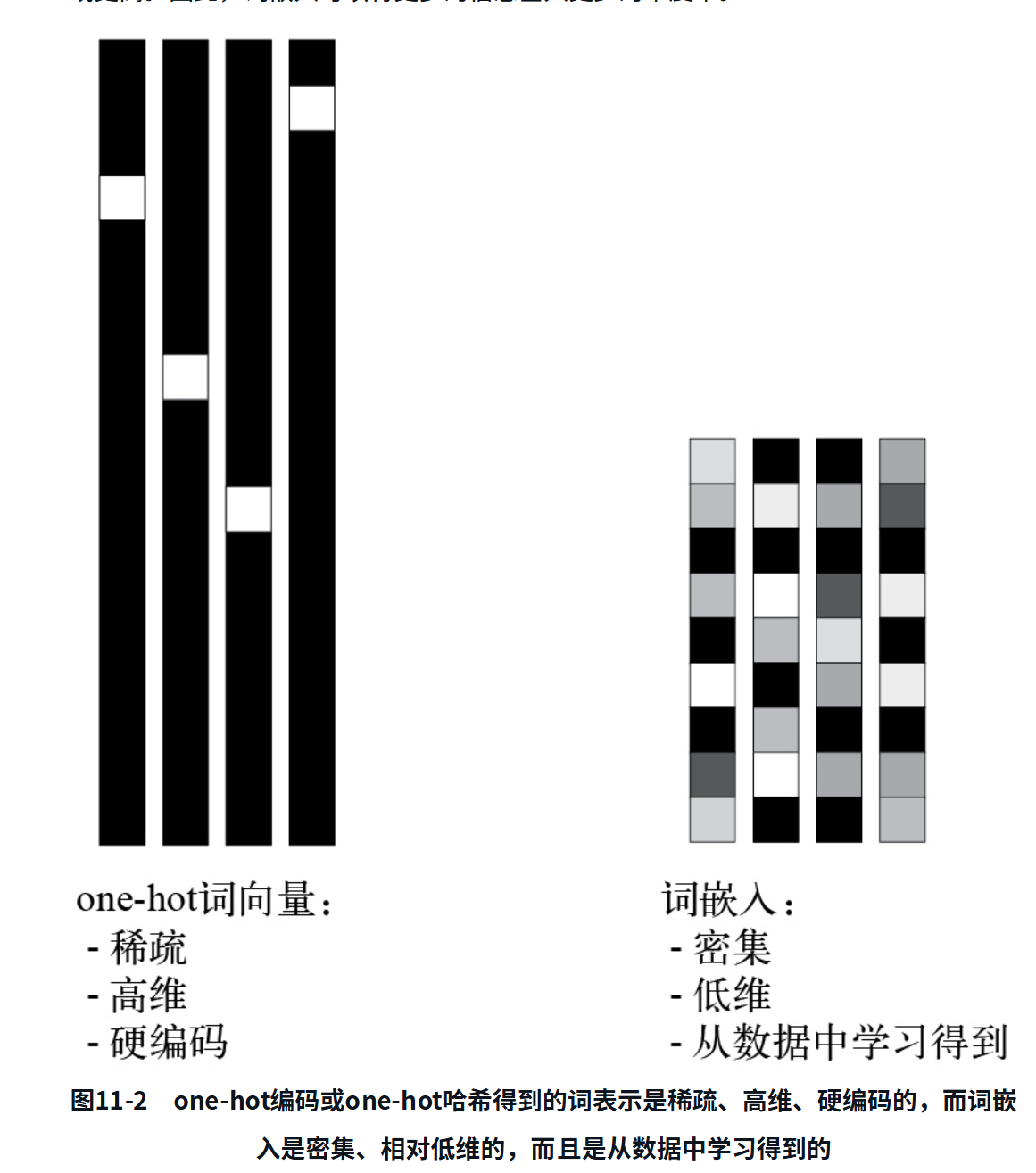
词嵌入是密集的表示,也是结构化的表示,其结构是从数据中学习得到的。相似的单词会被嵌入到相邻的位置,而且嵌入空间中的特定方向也是有意义的。为了更清楚地说明这一点,我们来看一个具体示例。在图11-3中,4个词被嵌入到二维平面中:这4个词分别是Cat(猫)、Dog(狗)、Wolf(狼)和Tiger(虎)。利用我们这里选择的向量表示,这些词之间的某些语义关系可以被编码为几何变换。例如,从Cat到Tiger的向量与从Dog到Wolf的向量相同,这个向量可以被解释为“从宠物到野生动物”向量。同样,从Dog到Cat的向量与从Wolf到Tiger的向量也相同,这个向量可以被解释为“从犬科到猫科”向量。

在现实世界的词嵌入空间中,常见的有意义的几何变换示例包括“性别”向量和“复数”向量。例如,将“king”(国王)向量加上“female”(女性)向量,得到的是“queen”(女王)向量。将“king”(国王)向量加上“plural”(复数)向量,得到的是“kings”向量。词嵌入空间通常包含上千个这种可解释的向量,它们可能都很有用。我们来看一下在实践中如何使用这样的嵌入空间。有以下两种方法可以得到词嵌入。在完成主任务(比如文档分类或情感预测)的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,学习方式与学习神经网络权重相同。在不同于待解决问题的机器学习任务上预计算词嵌入,然后将其加载到模型中。这些词嵌入叫作预训练词嵌入(pretrained word embedding)。我们来分别看一下这两种方法。
利用Embedding层学习词嵌入
是否存在一个理想的词嵌入空间,它可以完美地映射人类语言,并可用于所有自然语言处理任务?这样的词嵌入空间可能存在,但我们尚未发现。此外,并不存在人类语言这种东西。世界上有许多种语言,它们之间并不是同构的,因为语言反映的是特定文化和特定背景。但从更实际的角度来说,一个好的词嵌入空间在很大程度上取决于你的任务,英语影评情感分析模型的完美词嵌入空间,可能不同于英语法律文件分类模型的完美词嵌入空间,因为某些语义关系的重要性因任务而异。因此,合理的做法是对每个新任务都学习一个新的嵌入空间。幸运的是,反向传播让这种学习变得简单,Keras则使其变得更简单。我们只需学习Embedding层的权重,如代码清单11-15所示。
代码清单11-15 将Embedding层实例化
embedding_layer = layers.Embedding(input_dim=max_tokens, output_dim=256) ←---- Embedding层至少需要两个参数:词元个数和嵌入维度(这里是256)
你可以将Embedding层理解为一个字典,它将整数索引(表示某个单词)映射为密集向量。它接收整数作为输入,在内部字典中查找这些整数,然后返回对应的向量。Embedding层的作用实际上就是字典查询,
如图11-4所示。

Embedding层的输入是形状为(batch_size, sequence_length)的2阶整数张量,其中每个元素都是一个整数序列。该层返回的是一个形状为(batch_size,sequence_length, embedding_dimensionality)的3阶浮点数张量。将Embedding层实例化时,它的权重(内部的词向量字典)是随机初始化的,就像其他层一样。在训练过程中,利用反向传播来逐渐调节这些词向量,改变空间结构,使其可以被下游模型利用。训练完成之后,嵌入空间会充分地显示结构。这种结构专门针对模型训练所要解决的问题。我们来构建一个包含Embedding层的模型,为我们的任务建立基准,如代码清单11-16所示。
代码清单11-16 从头开始训练一个使用Embedding层的模型
inputs = keras.Input(shape=(None,), dtype="int64")
embedded = layers.Embedding(input_dim=max_tokens, output_dim=256)(inputs)
x = layers.Bidirectional(layers.LSTM(32))(embedded)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",loss="binary_crossentropy",metrics=["accuracy"])
model.summary()callbacks = [keras.callbacks.ModelCheckpoint("embeddings_bidir_gru.keras",save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=10,callbacks=callbacks)
model = keras.models.load_model("embeddings_bidir_gru.keras")
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")
模型训练速度比one-hot模型快得多(因为LSTM只需处理256维向量,而不是20 000维),测试精度也差不多(87%)。然而,这个模型与简单的二元语法模型相比仍有一定差距。部分原因在于,这个模型所查看的数据略少:二元语法模型处理的是完整的评论,而这个序列模型在600个单词之后截断序列。
相关文章:
深度学习处理文本(6)
理解词嵌入 重要的是,进行one-hot编码时,你做了一个与特征工程有关的决策。你向模型中注入了有关特征空间结构的基本假设。这个假设是:你所编码的不同词元之间是相互独立的。事实上,one-hot向量之间都是相互正交的。对于单词而言…...
STL-vector的使用
1.STL-vector 向量是可以改变其大小的线性序列容器。向量使用连续的空间存储元素,表明向量可以像数组通过下标来访问元素,但是向量的大小可以动态变化。向量的容量可能大于其元素需要的实际容量,向量通过消耗更多的内存来换取存储管理效率。…...
MySQL深入
体系结构 连接层:主要处理客户端的连接进行授权认证、校验权限等相关操作 服务层:如sql的接口、解析、优化在这里完成,所有跨存储引擎的操作在这里完成 引擎层:索引是在存储引擎层实现的,所以不同的存储引擎他的索引…...

为什么LoRA在目标检测方向不奏效?
最近在思考,为啥目标检测方向没有出现LORA的相关用法,搜索到了一篇文章,挺有深度的。 Why LoRA Struggles with Object Detection (and Why I Learned This the Hard Way) 链接:https://medium.com/predict/why-lora-struggles-with-object-detection-and-why-i-learned-…...

Vue面试常考内容[从宏观到微观]
以下是Vue面试常考内容的系统性解析,从框架设计思想到源码实现细节,结合最新技术动态(截至2025年4月)整理而成: 一、宏观层面:Vue设计哲学与框架定位 渐进式框架核心 • 分层可扩展架构:从视图层核心逐步集成路由、状态管理等能力,支持"按需取用"的渐进式开发…...
Genspark:重新定义搜索体验的AI智能体引擎
关于我们 飞书-华彬智融知识库 由前百度高管景鲲(Eric Jing)和朱凯华(Kay Zhu)联合创立的AI搜索引擎Genspark,正以革命性的技术架构和用户导向的设计理念,为全球用户带来一场搜索体验的范式革命。本文将基…...

从零实现Json-Rpc框架】- 项目实现 - 服务端主题实现及整体封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
AI助力PPT制作,让演示变得轻松高效
AI助力PPT制作,让演示变得轻松高效!随着科技的进步,AI技术早已渗透到各行各业,特别是在办公领域,AI制作PPT已不再是未来的梦想,而是现实的工具。以前你可能需要花费数小时来制作一个完美的PPT,如…...

React-01React创建第一个项目(npm install -g create-react-app)
1. React特点 JSX是javaScript语法的扩展,React开发不一定使用JSX。单向响应的数据流,React实现单向数据流,减少重复代码,比传统数据绑定更简单。等等 JSX是js的语法扩展,允许在js中编写类似HTML的代码 const …...
)
HTML应用指南:利用POST请求获取三大运营商5G基站位置信息(二)
在当前信息技术迅猛发展的背景下,第五代移动通信(5G)技术作为新一代的无线通信标准,正逐步成为推动社会进步和产业升级的关键驱动力。三大电信运营商(中国移动、中国联通、中国电信)在全国范围内的5G基站部署,不仅极大地提升了网络性能,也为智能城市、物联网、自动驾驶…...

C++学习笔记之内存管理
仅用于记录学习理解 选择题答案及解析 globalVar:C(数据段 (静态区)) 解析:全局变量存放在数据段(静态区),生命周期从程序开始到结束,程序运行期间一直存在。 staticGlobalVar&…...

针对 MySQL 数据库中 主键/唯一约束的更新方法 和 ON DUPLICATE KEY UPDATE 语法的详细说明及示例,并以表格总结
以下是针对 MySQL 数据库中 主键/唯一约束的更新方法 和 ON DUPLICATE KEY UPDATE 语法的详细说明及示例,并以表格总结: 一、主键的更新 1. 更新主键的条件 允许更新:MySQL 允许更新主键列,但需满足以下条件: 唯一性…...

day21 学习笔记
文章目录 前言一、删除数据二、索引操作1.loc方法2.iloc方法 三、添加数据1.loc方法添加数据2.concat方法拼接数据 四、重置索引 前言 通过今天的学习,我掌握了对Pandas对象数据元素进行增删操作以及重置索引的操作 一、删除数据 DataFrame.drop(labelsNone, axis…...

【MyBatis】深入解析 MyBatis XML 开发:增删改查操作和方法命名规范、@Param 重命名参数、XML 返回自增主键方法
增删改查操作 接下来,我们来实现一下用户的增加、删除和修改的操作。 增( Insert ) UserInfoMapper接口: 我们写好UserInfoMapper接口后,自动生成 XML 代码; UserInfoMapper.xml实现: 增删改查方法命名规范 如果我们…...

【Pandas】pandas DataFrame select_dtypes
Pandas2.2 DataFrame Attributes and underlying data 方法描述DataFrame.index用于获取 DataFrame 的行索引DataFrame.columns用于获取 DataFrame 的列标签DataFrame.dtypes用于获取 DataFrame 中每一列的数据类型DataFrame.info([verbose, buf, max_cols, …])用于提供 Dat…...

使用Python构建Kafka示例项目
新建项目 mkdir python-kafka-test cd python-kafka-test 安装依赖 pip install confluent_kafka 创建配置文件 # Kafka配置文件# Kafka服务器配置 KAFKA_CONFIG {bootstrap.servers: localhost:9092,# 生产者特定配置producer: {client.id: python-kafka-producer,acks:…...

本地化部署DeepSeek-R1蒸馏大模型:基于飞桨PaddleNLP 3.0的实战指南
目录 一、飞桨框架3.0:大模型推理新范式的开启1.1 自动并行机制革新:解放多卡推理1.2 推理-训练统一设计:一套代码全流程复用 二、本地部署DeepSeek-R1-Distill-Llama-8B的实战流程2.1 机器环境说明2.2 模型与推理脚本准备2.3 启动 Docker 容…...

VBA 64位API声明语句第008讲
跟我学VBA,我这里专注VBA, 授人以渔。我98年开始,从源码接触VBA已经20余年了,随着年龄的增长,越来越觉得有必要把这项技能传递给需要这项技术的职场人员。希望职场和数据打交道的朋友,都来学习VBA,利用VBA,起码可以提高…...

Linux信号——信号的保存(2)
关于core和term两种终止方式 core是什么? 将进程在内存中的核心数据(与调试有关)转存到磁盘中形成core,core.pid的文件。 core dump:核心转储。 core与term的区别: term只是普通的终止,而core终止方式还要…...

PyQt6实例_A股日数据维护工具_权息数据增量更新线程
目录 前置: 代码: 1 工作类 2 数据库交互 3 主界面启用子线程 视频: 前置: 1 本系列将以 “PyQt6实例_A股日数据维护工具” 开头放置在“PyQt6实例”专栏 专栏地址 https://blog.csdn.net/m0_37967652/category_12929760.h…...

【蓝桥杯嵌入式——学习笔记一】2016年第七届省赛真题重难点解析记录,闭坑指南(文末附完整代码)
在读题过程中发现本次使用的是串口2,需要配置串口2。 但在查看产品手册时发现PA14同时也是SWCLK。 所以在使用串口2时需要拔下跳线帽去连接CH340。 可能是用到串口2的缘故,在烧录时发现报了一个错误。这时我们要想烧录得按着复位键去点击烧录,…...

基础常问 (概念、代码)
读源码 代码题 Void方法 ,也可以提前rerun;结束 RandomAccessFile类(随机访问文件) 在 Java 中,可以使用RandomAccessFile类来实现文件指针操作。RandomAccessFile提供了对文件内容的随机访问功能,它的文件指针可以通…...
综述篇)
大学生机器人比赛实战(一)综述篇
大学生机器人比赛实战 参加机器人比赛是大学生提升工程实践能力的绝佳机会。本指南将全面介绍如何从零开始准备华北五省机器人大赛、ROBOCAN、RoboMaster等主流机器人赛事,涵盖硬件设计、软件开发、算法实现和团队协作等关键知识。 一、比赛选择与准备策略 1.1 主…...

什么是宽带拨号?
宽带拨号(PPPoE拨号)是一种通过账号密码认证接入互联网的方式,常见于家庭宽带、企业专线等场景。用户需要通过路由器或电脑进行拨号连接,运营商验证身份后分配IP地址,才能正常上网。 1. 宽带拨号的工作原理 PPPoE协议&…...

J1 ResNet-50算法实战与解析
🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客🍖 原作者:K同学啊 | 接輔導、項目定制 一、理论知识储备 1. 残差网络的由来 ResNet主要解决了CNN在深度加深时的退化问题(梯度消失与梯度爆炸)。 虽然B…...

[MySQL初阶]MySQL(8)索引机制:下
标题:[MySQL初阶]MySQL(8)索引机制:下 水墨不写bug 文章目录 四、从问题到底层,从现象到本质1.为什么插入的数据默认排好序2.MySQL的Page(1)为什么选择用Page?(2&#x…...
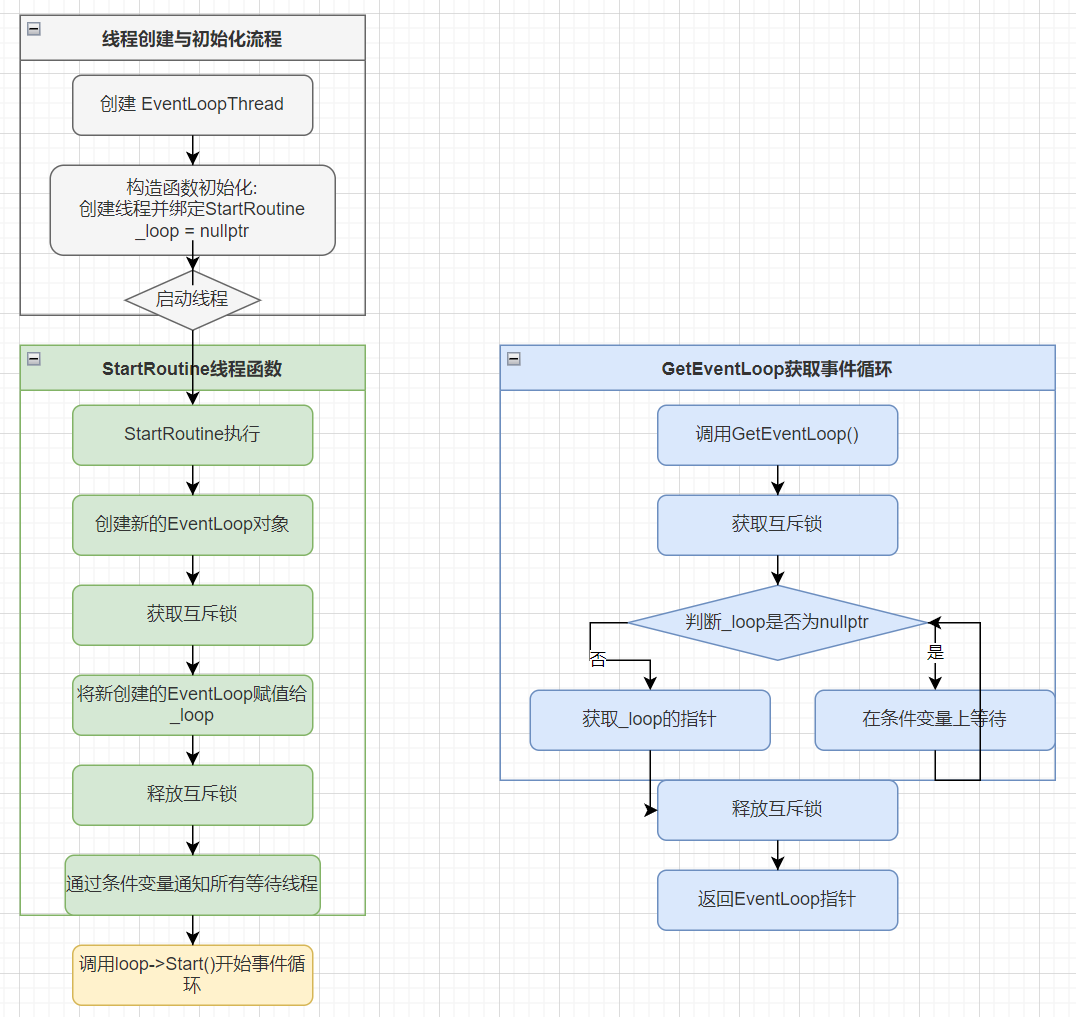
Muduo网络库实现 [九] - EventLoopThread模块
目录 设计思路 类的设计 模块的实现 私有接口 公有接口 设计思路 我们说过一个EventLoop要绑定一个线程,未来该EventLoop所管理的所有的连接的操作都需要在这个EventLoop绑定的线程中进行,所以我们该如何实现将EventLoop和线程绑定呢?…...

Vim操作指令全解析
Vim是我们在Linux日常工作中不可或缺的文本编辑器。它强大的功能和高效的编辑方式可以极大提升工作效率。本文将全面解析Vim的各种操作指令,从基础操作到高级技巧。 一、Vim模式解析 Vim是一个模式化编辑器,理解不同模式是掌握Vim的关键: …...

《K230 从熟悉到...》识别机器码(AprilTag)
《K230 从熟悉到...》识别机器码(aprirltag) tag id 《庐山派 K230 从熟悉到...》 识别机器码(AprilTag) AprilTag是一种基于二维码的视觉标记系统,最早是由麻省理工学院(MIT)在2008年开发的。A…...

VMware ESXi:企业级虚拟化平台详解
VMware ESXi:企业级虚拟化平台详解 目录 什么是VMware ESXi? ESXi的发展历史 ESXi的核心特性 3.1 裸机架构(Type-1 Hypervisor) 3.2 轻量化与高性能 3.3 集中管理(vCenter集成) ESXi的架构与工作原理…...