本地化部署DeepSeek-R1蒸馏大模型:基于飞桨PaddleNLP 3.0的实战指南

目录
- 一、飞桨框架3.0:大模型推理新范式的开启
- 1.1 自动并行机制革新:解放多卡推理
- 1.2 推理-训练统一设计:一套代码全流程复用
- 二、本地部署DeepSeek-R1-Distill-Llama-8B的实战流程
- 2.1 机器环境说明
- 2.2 模型与推理脚本准备
- 2.3 启动 Docker 容器并挂载模型
- 2.4 推理执行命令(动态图)
- 2.5 predictor.py 脚本内容(精简版)
- 2.6 实测表现
- 这类问题考察:
- 三、部署技术亮点与实战体验
- 3.1 自动推理服务启动
- 3.2 显存控制与多卡并行
- 3.3 动静融合的训推复用
- 四、总结:国产大模型部署的高效通路
在大模型时代的浪潮中,开源框架与推理优化的深度融合,正推动人工智能从“可用”走向“高效可部署”。飞桨(PaddlePaddle)作为国内领先的自主深度学习平台,在3.0版本中重构了模型开发与部署链路,面向大模型时代提供了更智能的编译调度、更高效的资源利用与更统一的训推体验。
本文将围绕 飞桨3.0环境下,基于 Docker 成功部署 DeepSeek-R1-Distill-Llama-8B 蒸馏模型 的实战流程展开,涵盖从容器环境构建、模型加载优化,到推理测试与性能评估的完整流程,旨在为大模型部署实践提供工程级参考。
一、飞桨框架3.0:大模型推理新范式的开启
在AI大模型不断迈向更高参数规模和更强通用能力的当下,基础框架的演进已经成为大模型落地的关键支点。 飞桨框架3.0不仅在推理性能上进行了系统性优化,更通过“动静统一自动并行”“训推一体设计”“神经网络编译器”“异构多芯适配”等创新能力,打通了大模型从训练到部署的全链路,为模型开发者提供了高度一致的开发体验。
这些技术特性包括但不限于:
- ✅ 动静统一自动并行:将动态图的开发灵活性与静态图的执行效率深度融合,降低大模型在多卡训练与推理中的部署门槛。
- ✅ 训推一体设计:训练模型无需重构,即可用于部署推理,显著提升部署效率和一致性。
- ✅ 高阶微分与科学计算支持:通过自动微分和 CINN 编译器加速,广泛支持科学智能场景如气象模拟、生物建模等。
- ✅ 神经网络编译器 CINN:自动优化算子组合,提升推理速度,显著降低部署成本。
- ✅ 多芯适配与跨平台部署:兼容超过 60 款芯片平台,实现“一次开发,全栈部署”。
在这样的架构革新下,飞桨框架3.0为大模型的快速部署、灵活适配和性能压榨提供了坚实支撑。
1.1 自动并行机制革新:解放多卡推理
飞桨框架3.0引入的动静统一自动并行机制,彻底改变了传统手动编写分布式通信逻辑的繁琐方式。框架能够在保持动态图灵活性的同时,静态图部分自动完成策略选择、任务调度与通信优化,大大简化了多卡推理部署的流程。
在本次 DeepSeek-R1 的实际部署中,即便模型结构复杂、参数量庞大,也无需显式指定通信策略,仅需配置环境变量与设备列表,便可顺利完成 8 卡自动并行推理。
1.2 推理-训练统一设计:一套代码全流程复用
飞桨框架3.0秉承“训推一体”理念,解决了以往模型在训练与部署之间需要重复构建的难题。开发者在训练阶段构建的动态图结构,可通过高成功率的动转静机制直接导出为静态模型,并在推理阶段无缝复用,极大降低了代码维护与部署成本。
在本次实战中,我们仅通过一行 start_server 启动命令,即完成了推理服务部署与分布式调度,无需重写模型或服务逻辑,验证了“训推一致”的工程优势。
二、本地部署DeepSeek-R1-Distill-Llama-8B的实战流程
在飞桨 3.0 推理优化与大模型蒸馏模型的结合下,DeepSeek-R1-Distill-LLaMA-8B 成为当前国产模型部署中兼具性能与资源亲和力的代表。本节将基于 A100 环境,结合容器化方案,从环境准备到推理验证,完整走通部署流程。
2.1 机器环境说明
-
宿主机系统:Ubuntu 20.04
-
CUDA版本:12.4
-
Docker版本:23+
-
飞桨镜像:
paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1
2.2 模型与推理脚本准备
- 模型路径(本地)
模型来自 Hugging Face 的deepseek-ai/DeepSeek-R1-Distill-Llama-8B,使用量化版本weight_only_int8:
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Llama-8B \--revision paddle \--local-dir /root/deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8 \--local-dir-use-symlinks False
- 推理脚本路径(本地)
推理脚本命名为predictor.py,已在/mnt/medai_tempcopy/wyt/other目录中准备,内容为精简动态图推理代码(见 2.5)。
2.3 启动 Docker 容器并挂载模型
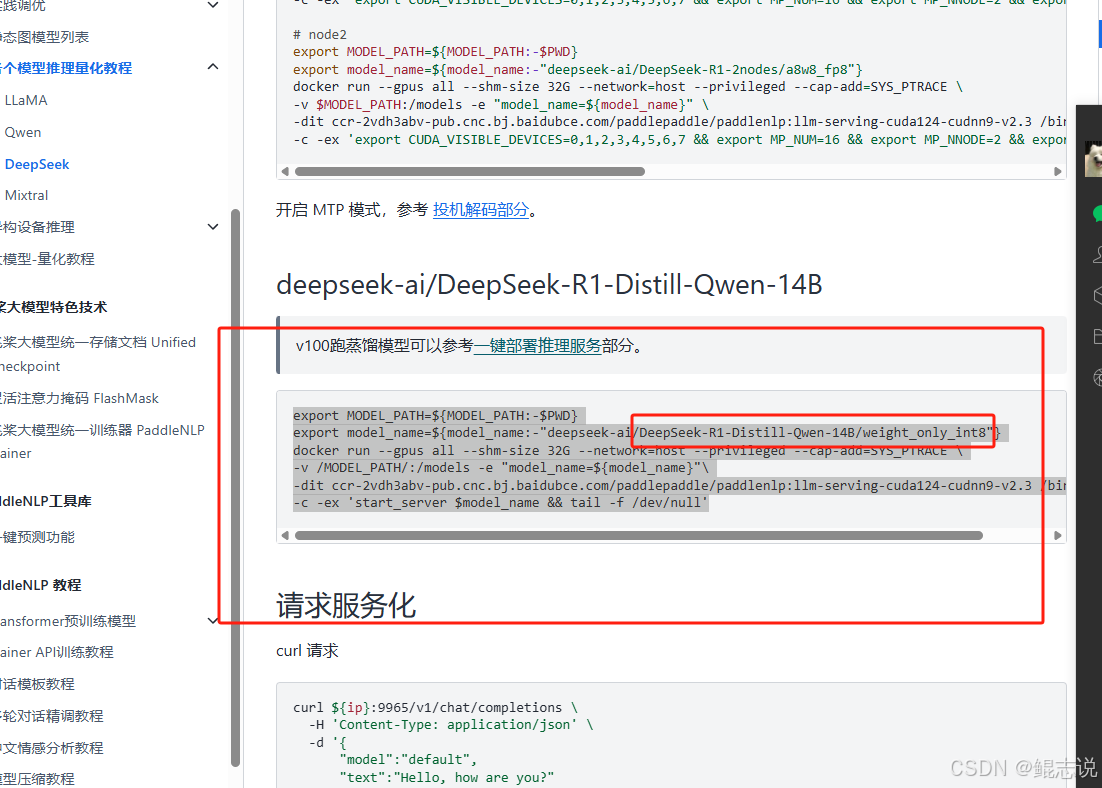
使用如下命令启动 LLM 推理容器:
docker run --gpus all \--name llm-runner \--shm-size 32G \--network=host \--privileged --cap-add=SYS_PTRACE \-v /root/deepseek-ai:/models/deepseek-ai \-v /mnt/medai_tempcopy/wyt/other:/workspace \-e "model_name=deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8" \-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 \/bin/bash
然后进入容器:
docker exec -it llm-runner /bin/bash
如果前期没有命名,也可以根据找到id然后进入。
在宿主机输入
docker ps
# 找到容器 ID,然后:
docker exec -it <容器ID> /bin/bash

2.4 推理执行命令(动态图)
在容器内部,执行推理:
cd /workspace
python predictor.py
执行成功后,会输出包含中文响应的生成结果,以及 GPU 显存、tokens 生成信息等。
2.5 predictor.py 脚本内容(精简版)
以下是部署过程中使用的实际脚本,适用于 INT8 动态图部署:
import paddle
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLMmodel_path = "/models/deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8"# 设置GPU自动显存增长
paddle.set_flags({"FLAGS_allocator_strategy": "auto_growth"})
paddle.set_device("gpu")# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, dtype="float16")# 更复杂的 prompt,测试模型的推理与跨学科分析能力
text = ("假设你是一个通晓中英双语的跨学科专家,请从人工智能、经济学和哲学角度,分析以下现象:""在人工智能快速发展的背景下,大模型在提升生产力的同时,也可能造成部分行业就业结构失衡。""请列举三种可能的经济后果,提供相应的哲学反思,并建议一个基于技术伦理的政策干预方案。"
)# 编码输入
inputs = tokenizer(text, return_tensors="pd")# 推理
with paddle.no_grad():output = model.generate(**inputs,max_new_tokens=512,decode_strategy="greedy_search")# 解码输出
result = tokenizer.decode(output[0], skip_special_tokens=True)
print("模型输出:", result)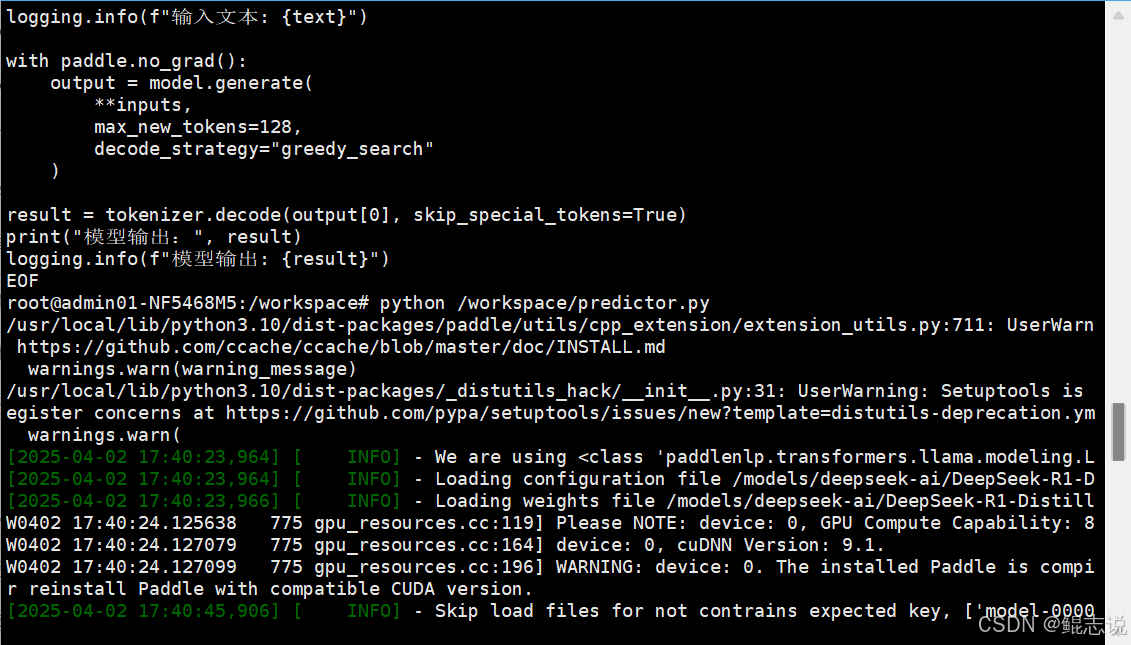
2.6 实测表现
-
推理耗时:2.8~3.2 秒
-
吞吐率:约 10–12 tokens/s
-
文本响应:可生成流畅中文内容,格式正常、逻辑清晰

这类问题考察:
-
多学科融合(AI + 经济 + 哲学)
-
长 prompt 理解 & token 处理能力
-
推理、归纳、生成综合能力
-
回答结构化 & 梳理逻辑能力
但他回答的很好。
三、部署技术亮点与实战体验
3.1 自动推理服务启动
借助 start_server 和环境变量控制,我们可替代传统 Python 脚本调用,通过一行命令快速部署 RESTful 接口,适配企业级服务场景。
3.2 显存控制与多卡并行
通过 INT8 量化与 MLA(多级流水 Attention)支持,DeepSeek-R1 蒸馏版在 8 卡 A100 上只需约 60GB 显存即可运行,显著降低推理资源门槛。
3.3 动静融合的训推复用
Paddle3.0 的动态图/静态图切换无需代码重构,训推阶段保持一致逻辑,减少了模型部署对开发者的侵入性,大幅降低维护成本。
四、总结:国产大模型部署的高效通路
从本次部署可以看出,飞桨框架3.0在推理性能、资源适配与工程体验上均已接轨国际水准,配合 DeepSeek-R1 这类高性价比蒸馏模型,能极大提升本地部署的实用性。
-
算力成本压缩:INT8 量化让 8 卡部署变为可能;
-
部署效率提升:自动并行与动静融合减少90%以上的调参与硬件适配成本;
-
产业落地友好:支持 RESTful 调用,容器环境封装便于集群部署与迁移。
在“大模型国产化”的背景下,飞桨3.0 不仅是一套技术工具,更是一条从科研走向产业、从训练走向落地的智能之路。
如需部署更多轻量模型(如 Qwen1.5B、Baichuan2-7B 等),亦可套用本文流程,仅需替换模型路径即可实现快速部署。
相关文章:
本地化部署DeepSeek-R1蒸馏大模型:基于飞桨PaddleNLP 3.0的实战指南
目录 一、飞桨框架3.0:大模型推理新范式的开启1.1 自动并行机制革新:解放多卡推理1.2 推理-训练统一设计:一套代码全流程复用 二、本地部署DeepSeek-R1-Distill-Llama-8B的实战流程2.1 机器环境说明2.2 模型与推理脚本准备2.3 启动 Docker 容…...

VBA 64位API声明语句第008讲
跟我学VBA,我这里专注VBA, 授人以渔。我98年开始,从源码接触VBA已经20余年了,随着年龄的增长,越来越觉得有必要把这项技能传递给需要这项技术的职场人员。希望职场和数据打交道的朋友,都来学习VBA,利用VBA,起码可以提高…...

Linux信号——信号的保存(2)
关于core和term两种终止方式 core是什么? 将进程在内存中的核心数据(与调试有关)转存到磁盘中形成core,core.pid的文件。 core dump:核心转储。 core与term的区别: term只是普通的终止,而core终止方式还要…...

PyQt6实例_A股日数据维护工具_权息数据增量更新线程
目录 前置: 代码: 1 工作类 2 数据库交互 3 主界面启用子线程 视频: 前置: 1 本系列将以 “PyQt6实例_A股日数据维护工具” 开头放置在“PyQt6实例”专栏 专栏地址 https://blog.csdn.net/m0_37967652/category_12929760.h…...

【蓝桥杯嵌入式——学习笔记一】2016年第七届省赛真题重难点解析记录,闭坑指南(文末附完整代码)
在读题过程中发现本次使用的是串口2,需要配置串口2。 但在查看产品手册时发现PA14同时也是SWCLK。 所以在使用串口2时需要拔下跳线帽去连接CH340。 可能是用到串口2的缘故,在烧录时发现报了一个错误。这时我们要想烧录得按着复位键去点击烧录,…...

基础常问 (概念、代码)
读源码 代码题 Void方法 ,也可以提前rerun;结束 RandomAccessFile类(随机访问文件) 在 Java 中,可以使用RandomAccessFile类来实现文件指针操作。RandomAccessFile提供了对文件内容的随机访问功能,它的文件指针可以通…...
综述篇)
大学生机器人比赛实战(一)综述篇
大学生机器人比赛实战 参加机器人比赛是大学生提升工程实践能力的绝佳机会。本指南将全面介绍如何从零开始准备华北五省机器人大赛、ROBOCAN、RoboMaster等主流机器人赛事,涵盖硬件设计、软件开发、算法实现和团队协作等关键知识。 一、比赛选择与准备策略 1.1 主…...

什么是宽带拨号?
宽带拨号(PPPoE拨号)是一种通过账号密码认证接入互联网的方式,常见于家庭宽带、企业专线等场景。用户需要通过路由器或电脑进行拨号连接,运营商验证身份后分配IP地址,才能正常上网。 1. 宽带拨号的工作原理 PPPoE协议&…...

J1 ResNet-50算法实战与解析
🍨 本文為🔗365天深度學習訓練營 中的學習紀錄博客🍖 原作者:K同学啊 | 接輔導、項目定制 一、理论知识储备 1. 残差网络的由来 ResNet主要解决了CNN在深度加深时的退化问题(梯度消失与梯度爆炸)。 虽然B…...

[MySQL初阶]MySQL(8)索引机制:下
标题:[MySQL初阶]MySQL(8)索引机制:下 水墨不写bug 文章目录 四、从问题到底层,从现象到本质1.为什么插入的数据默认排好序2.MySQL的Page(1)为什么选择用Page?(2&#x…...
Muduo网络库实现 [九] - EventLoopThread模块
目录 设计思路 类的设计 模块的实现 私有接口 公有接口 设计思路 我们说过一个EventLoop要绑定一个线程,未来该EventLoop所管理的所有的连接的操作都需要在这个EventLoop绑定的线程中进行,所以我们该如何实现将EventLoop和线程绑定呢?…...

Vim操作指令全解析
Vim是我们在Linux日常工作中不可或缺的文本编辑器。它强大的功能和高效的编辑方式可以极大提升工作效率。本文将全面解析Vim的各种操作指令,从基础操作到高级技巧。 一、Vim模式解析 Vim是一个模式化编辑器,理解不同模式是掌握Vim的关键: …...

《K230 从熟悉到...》识别机器码(AprilTag)
《K230 从熟悉到...》识别机器码(aprirltag) tag id 《庐山派 K230 从熟悉到...》 识别机器码(AprilTag) AprilTag是一种基于二维码的视觉标记系统,最早是由麻省理工学院(MIT)在2008年开发的。A…...

VMware ESXi:企业级虚拟化平台详解
VMware ESXi:企业级虚拟化平台详解 目录 什么是VMware ESXi? ESXi的发展历史 ESXi的核心特性 3.1 裸机架构(Type-1 Hypervisor) 3.2 轻量化与高性能 3.3 集中管理(vCenter集成) ESXi的架构与工作原理…...

使用 PyTorch 的 `optim.lr_scheduler.CosineAnnealingLR` 学习率调度器
使用 PyTorch 的 optim.lr_scheduler.CosineAnnealingLR 学习率调度器 在深度学习中,学习率(Learning Rate, LR)是影响模型训练效果的一个关键超参数。一个合适的学习率调度策略可以帮助模型更快地收敛,同时避免陷入局部最优或振荡。PyTorch 提供了多种学习率调度器,其中…...
栈和队列的概念
1.栈的概念 只允许在固定的一端进行插入和删除,进行数据的插入和数据的删除操作的一端数栈顶,另一端称为栈底。 栈中数据元素遵循后进先出LIFO (Last In First Out) 压栈:栈的插入。 出栈:栈的删除。出入数据在栈顶。 那么下面…...

常用的元素操作API
click 触发当前元素的点击事件 clear() 清空内容 sendKeys(...) 往文本框一类元素中写入内容 getTagName() 获取元素的的标签名 getAttribute(属性名) 根据属性名获取元素属性值 getText() 获取当前元素的文本值 isDisplayed() 查看元素是否显示 get(String url) 访…...

红日靶场一实操笔记
一,网络拓扑图 二,信息搜集 1.kali机地址:192.168.50.129 2.探测靶机 注:需要win7开启c盘里面的phpstudy的服务。 nmap -sV -Pn 192.168.50.128 或者扫 nmap -PO 192.168.50.0/24 可以看出来win7(ip为192.168.50.128)的靶机开…...

SpringBoot集成Redis 灵活使用 TypedTuple 和 DefaultTypedTuple 实现 Redis ZSet 的复杂操作
以下是 Spring Boot 集成 Redis 中 TypedTuple 和 DefaultTypedTuple 的详细使用说明,包含代码示例和场景说明: 1. 什么是 TypedTuple 和 DefaultTypedTuple? TypedTuple<T> 接口: 定义了 Redis 中有序集合(ZSet…...

7-4 BCD解密
BCD数是用一个字节来表达两位十进制的数,每四个比特表示一位。所以如果一个BCD数的十六进制是0x12,它表达的就是十进制的12。但是小明没学过BCD,把所有的BCD数都当作二进制数转换成十进制输出了。于是BCD的0x12被输出成了十进制的18了&#x…...

Golang改进后的任务调度系统分析
以下是整合了所有改进点的完整代码实现: package mainimport ("bytes""context""fmt""io""log""net/http""sync""time""github.com/go-redis/redis/v8""github.com/robfig/…...
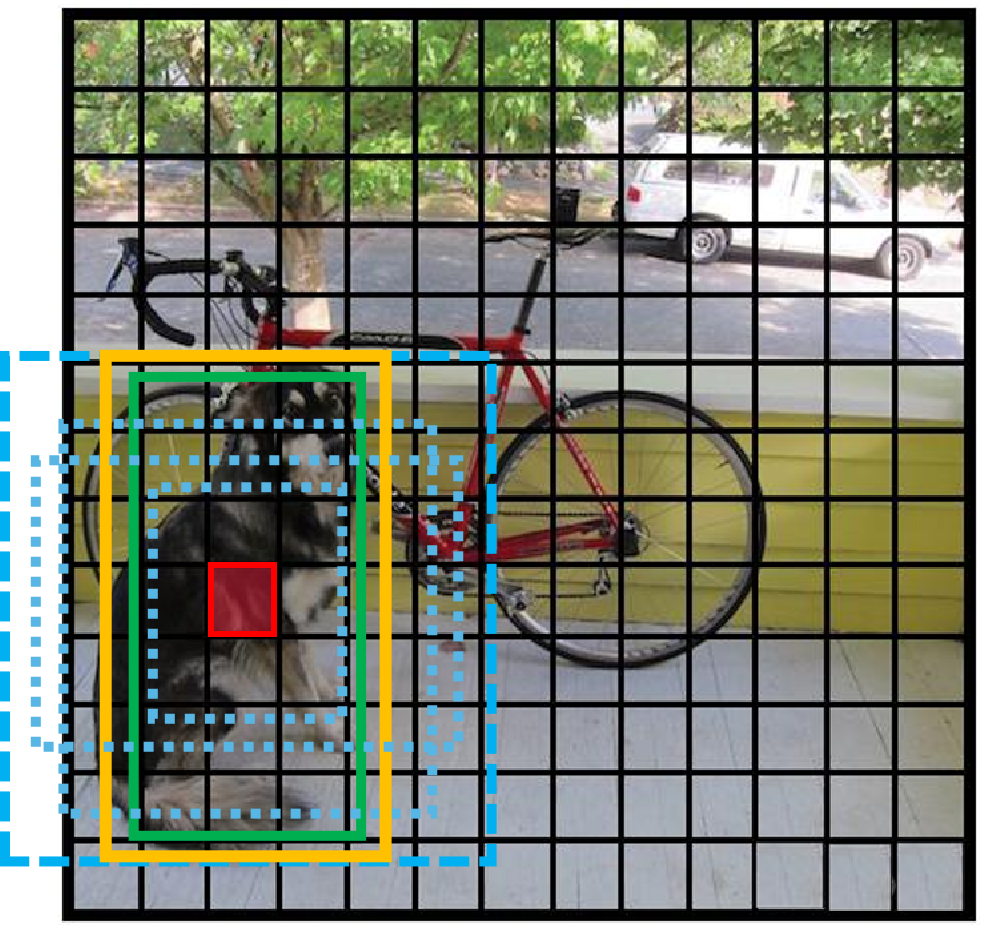
【目标检测】【深度学习】【Pytorch版本】YOLOV2模型算法详解
【目标检测】【深度学习】【Pytorch版本】YOLOV2模型算法详解 文章目录 【目标检测】【深度学习】【Pytorch版本】YOLOV2模型算法详解前言YOLOV2的模型结构YOLOV2模型的基本执行流程YOLOV2模型的网络参数YOLOV2模型的训练方式 YOLOV2的核心思想前向传播阶段反向传播阶段 总结 前…...

NineData云原生智能数据管理平台新功能发布|2025年3月版
本月发布 15 项更新,其中重点发布 3 项、功能优化 11 项、性能优化 1 项。 重点发布 基础服务 - MFA 多因子认证 新增 MFA 多因子认证,提升账号安全性。系统管理员开启后,所有组织成员需绑定认证器,登录时需输入动态验证码。 数…...

破局与赋能:信息系统战略规划方法论
信息系统战略规划是将组织的战略目标和发展规划转化为信息系统的战略目标和发展规划的过程,常见的方法有以下几种: 一、企业系统规划法(BSP) 1.基本概念:通过全面调查,分析企业信息需求,确定信…...

GLSL(OpenGL 着色器语言)基础语法
GLSL(OpenGL 着色器语言)基础语法 GLSL(OpenGL Shading Language)是 OpenGL 计算着色器的语言,语法类似于 C 语言,但提供了针对 GPU 的特殊功能,如向量运算和矩阵运算。 着色器的开头总是要声明…...

Redis基础知识-3
RedisTemplate对多种数据结构的操作 1. String类型 示例代码: // 保存数据 redisTemplate.opsForValue().set("user:1001", "John Doe"); // 设置键值对,无过期时间 redisTemplate.opsForValue().set("user:1002", &qu…...

Git Rebase 操作中丢失提交的恢复方法
背景介绍 在团队协作中,使用 Git 进行版本控制是常见实践。然而,有时在执行 git rebase 或者其他操作后,我们可能会发现自己的提交记录"消失"了,这往往让开发者感到恐慌。本文将介绍几种在 rebase 后恢复丢失提交的方法。 问题描述 当我们执行以下操作时,可能…...
】dataset 工具,Parquet和Arrow 数据文件格式,load dataset 方法)
【diffusers 进阶(十五)】dataset 工具,Parquet和Arrow 数据文件格式,load dataset 方法
系列文章目录 【diffusers 极速入门(一)】pipeline 实际调用的是什么? call 方法!【diffusers 极速入门(二)】如何得到扩散去噪的中间结果?Pipeline callbacks 管道回调函数【diffusers极速入门࿰…...
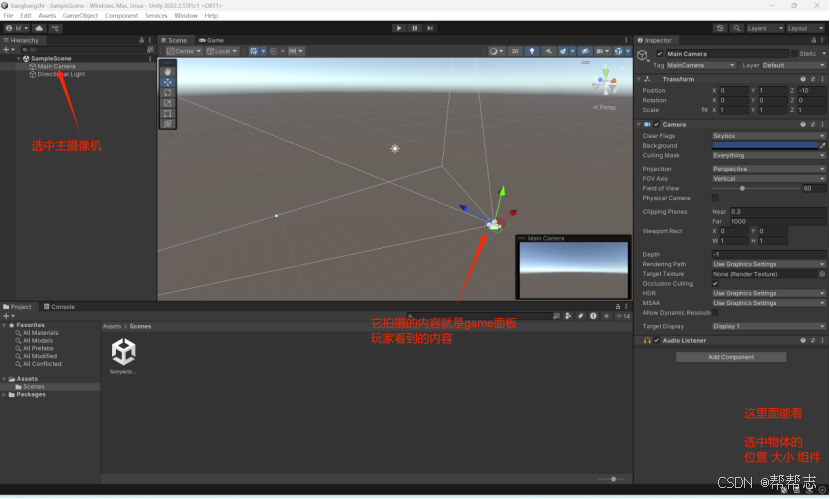
unity各个面板说明
游戏开发,unity各个面板说明 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是Python基础语法。前后每一小节的内容是存在的有:学习and理解的关联性,希望对您有用~ unity简介-unity基础…...

游戏引擎学习第199天
回顾并发现我们可能破坏了某些东西 目前,我们的调试 UI 运行得相对顺利,可以创建可修改的调试变量,也可以插入分析器(profiler)等特殊视图组件,并进行一些交互操作。然而,在上一次结束时&#…...