mysql对表,数据,索引的操作sql
对表的操作
新建表
创建一个名为rwh_test的表,id为主键自增
-- 新建表
CREATE TABLE rwh_test(`id` int NOT NULL auto_increment PRIMARY KEY COMMENT '主键id',`username` VARCHAR(20) DEFAULT NULL COMMENT '用户名',`age` int DEFAULT NULL COMMENT '年龄',`create_date` datetime DEFAULT NULL COMMENT '创建时间',`create_by` VARCHAR(20) DEFAULT NULL COMMENT '创建人',`update_date` datetime DEFAULT NULL COMMENT '修改时间',`update_by` VARCHAR(20) DEFAULT NULL COMMENT '修改人'
);查看表结构(表中所有字段)
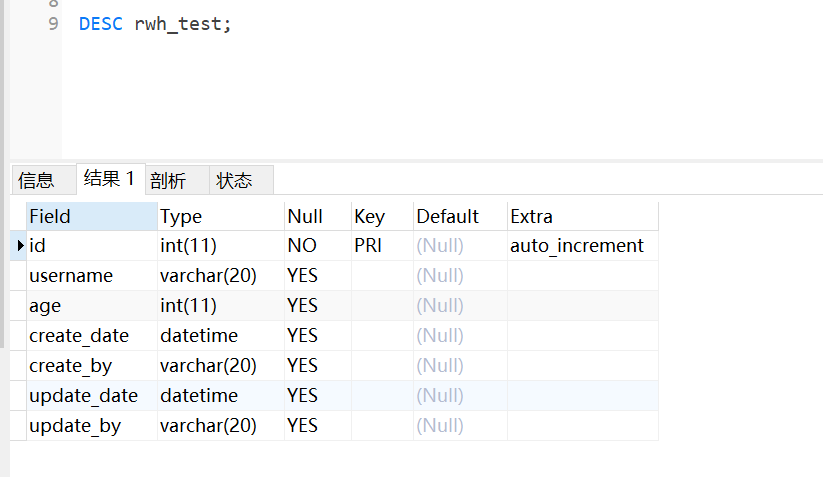
1,DESCRIBE 表名;
DESCRIBE rwh_test;或者简写成:DESC 表名;
DESC rwh_test;结果如下:
2,SHOW CREATE TABLE 表名;
-- SHOW CREATE TABLE 表名;
SHOW CREATE TABLE rwh_test;结果如下:
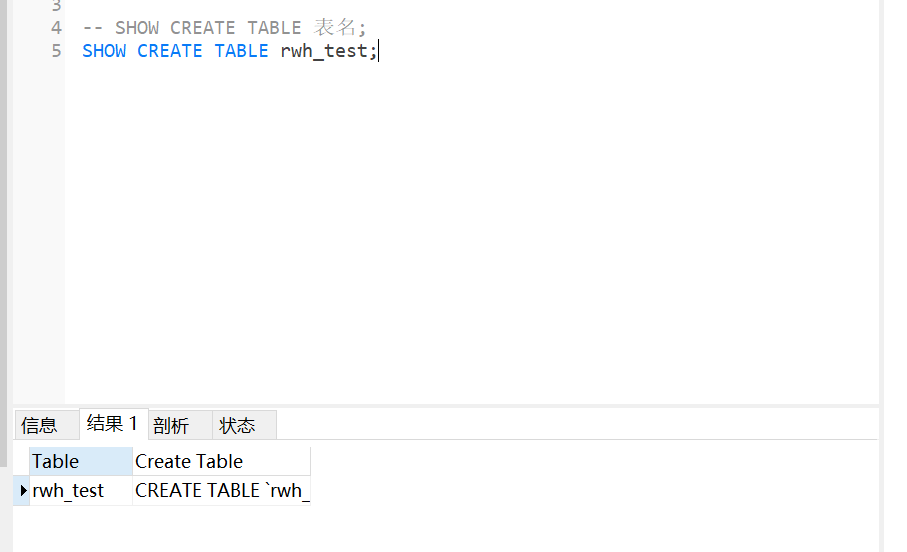
其中Create Tabel里面的内容如下:
CREATE TABLE `rwh_test` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',`username` varchar(20) DEFAULT NULL COMMENT '用户名',`age` int(11) DEFAULT NULL COMMENT '年龄',`create_date` datetime DEFAULT NULL COMMENT '创建时间',`create_by` varchar(20) DEFAULT NULL COMMENT '创建人',`update_date` datetime DEFAULT NULL COMMENT '修改时间',`update_by` varchar(20) DEFAULT NULL COMMENT '修改人',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8修改表名
RENAME TABLE 旧表名 TO 新表名;
RENAME TABLE rwh_test TO rwh_test1;ALTER TABLE 旧表名 RENAME TO 新表名;
ALTER TABLE rwh_test1 RENAME TO rwh_test;删除表
1,DROP TABLE 表名;
删除整个表,表没了,表中数据没了,表结构没了,释放了存储空间,啥都没了
DROP TABLE rwh_test;2,DELETE FROM 表名 WHERE id=1;
删除表中符合条件的数据
DELETE FROM rwh_test WHERE id=1;DELETE FROM 表名;
删除表中所有数据,数据没了,表和表结构都在,没有释放存储空间
DELETE FROM rwh_test;3,TRUNCATE TABLE 表名;
删除表中数据,数据没了,表和表结构都在,释放了存储空间
TRUNCATE TABLE rwh_test;修改表结构
新增字段
新增一个字段(默认放到所有字段最后面)
如:新增“备注”字段
ALTER TABLE rwh_test ADD COLUMN remark VARCHAR(32) DEFAULT NULL COMMENT '备注';新增一个字段到指定字段后面
如:在age字段新增字段address(地址)
ALTER TABLE rwh_test ADD COLUMN address VARCHAR(32) DEFAULT NULL COMMENT '地址' AFTER age;新增多个字段
如:新增haha字段和hehe字段
ALTER TABLE rwh_test
ADD COLUMN haha VARCHAR(32) DEFAULT NULL COMMENT '新字段1',
ADD COLUMN hehe VARCHAR(32) DEFAULT NULL COMMENT '新字段2';新增多个字段到指定字段后面
如:新增enen字段在haha字段后面,oo字段在hehe字段后面
ALTER TABLE rwh_test
ADD COLUMN enen VARCHAR(32) DEFAULT NULL COMMENT '新字段3' AFTER haha,
ADD COLUMN oo VARCHAR(32) DEFAULT NULL COMMENT '新字段4' AFTER hehe;修改字段
修改字段名字
如:把haha字段改为haha123
ALTER TABLE rwh_test CHANGE COLUMN haha haha123 VARCHAR(20) DEFAULT NULL COMMENT '新字段1';修改字段类型,大小,默认值,备注
如:把hehe字段的类型改为int,默认值改为0,备注改为“新字段222”
ALTER TABLE rwh_test MODIFY COLUMN hehe int DEFAULT 0 COMMENT '新字段222';删除字段
删除一个字段
如:删除字段oo
ALTER TABLE rwh_test DROP COLUMN oo;删除多个字段
如:删除haha123,enen,hehe字段
ALTER TABLE rwh_test
DROP COLUMN haha123,
DROP COLUMN enen;
DROP COLUMN hehe;对数据的操作
插入数据
插入一条完整的数据
INSERT INTO rwh_test
(id,username,age,address,create_date,create_by,update_date,update_by,remark)
VALUES
(1,'张三',18,'北京',NOW(),'rwh',NOW(),'rwh','这是备注');插入一条不完整的数据
备注:
这里的字段名和值要一个一个对应,比如第一个字段是username,第一个值就必须填姓名,不能填年龄或者其他值。
有些数据插入时可以不给值,有些必须给,not null 类型的就必须给值,这里id也是not null ,为啥可以不给值呢,因为id是自增的,你不给值,他会自增加1给一个默认值的。
不是not null 类型的字段都可以不给值。
INSERT INTO rwh_test
(username,age,address,create_date,create_by,update_date,update_by)
VALUES
('李四',20,'上海',NOW(),'rwh',NOW(),'rwh');一次插入多条数据
INSERT INTO rwh_test
(username,age,address,create_date,create_by,update_date,update_by)
VALUES
('王五',20,'上海',NOW(),'rwh',NOW(),'rwh'),
('赵六',20,'上海',NOW(),'rwh',NOW(),'rwh'),
('孙七',20,'上海',NOW(),'rwh',NOW(),'rwh');查询数据
SELECT * FROM rwh_test;修改数据
UPDATE 表名
SET 字段1=值1,字段2=值2
WHERE 字段1=值1;UPDATE rwh_test
SET age=22,address='广州'
WHERE username='张三';删除数据
DELETE FROM rwh_test WHERE username = '孙七';对索引的操作
新建索引
新建表时创建索引
-- 创建主键索引,id
CREATE TABLE user_test(`id` int NOT NULL auto_increment PRIMARY KEY COMMENT '主键',·username· VARCHAR(20) COMMENT '姓名'
);-- 创建主键索引
CREATE TABLE user_test(`id` int NOT NULL COMMENT '主键',`username` VARCHAR(20) COMMENT '姓名',PRIMARY KEY (id)
);-- 创建唯一索引,给username字段创建唯一索引,索引名叫index_username
-- 格式:UNIQUE INDEX 索引名(字段)
CREATE TABLE user_test(`id` int NOT NULL auto_increment PRIMARY KEY COMMENT '主键',`username` VARCHAR(20) COMMENT '姓名',UNIQUE INDEX index_username(username)
);-- 创建普通索引,给email字段创建普通索引,索引名叫index_email
-- 格式:INDEX 索引名(字段)
CREATE TABLE user_test(`id` int NOT NULL auto_increment PRIMARY KEY COMMENT '主键',`username` VARCHAR(20) COMMENT '姓名',`email` VARCHAR(20) COMMENT '邮箱',INDEX index_email(email)
);-- 创建组合索引,给username和email字段创建组合索引,索引名叫index_username_email
-- 格式:INDEX 索引名(字段1,字段2...)
CREATE TABLE user_test(`id` int NOT NULL auto_increment PRIMARY KEY COMMENT '主键',`username` VARCHAR(20) COMMENT '姓名',`email` VARCHAR(20) COMMENT '邮箱',INDEX index_username_email(username,email)
);在已有的表中直接创建索引
-- 创建唯一索引,给username字段创建唯一
-- 格式:CREATE UNIQUE INDEX 索引名 ON 表名(字段);
CREATE UNIQUE INDEX index_username ON user_test(username);-- 创建普通索引,给email字段创建普通索引,索引名叫index_email
-- 格式:CREATE INDEX 索引名 ON 表名(字段名);
CREATE INDEX index_email ON user_test(email);-- 创建组合索引,给username和email字段创建组合索引,索引名叫index_username_email
-- 格式:CREATE INDEX 索引名 ON 表名(字段1,字段2...);
CREATE INDEX index_username_email ON user_test(username,email);通过修改表的方式创建索引
-- 创建主键索引
ALTER TABLE user_test ADD PRIMARY KEY (id);-- 创建唯一索引
ALTER TABLE user_test ADD UNIQUE INDEX index_username(username);-- 创建普通索引
ALTER TABLE user_test ADD INDEX index_email(email);-- 创建组合索引
ALTER TABLE user_test ADD INDEX index_username_email(username,email);查看索引
-- 这3种方式都可以
-- 格式:SHOW INDEX FROM 表名
SHOW INDEX FROM user_test;SHOW KEYS FROM user_test;SHOW indexes FROM user_test;各个字段含义
| 字段名 | 含义 |
| Table | 索引所在的数据表的名称 |
| Non_unique | 索引是否可以重复,0表示不可以,1表示可以 |
| Key_name | 索引的名称,如果索引是主键索引,则它的名称为PRIMARY |
| Seq_in_index | 建立索引的字段序号值,默认从1开始 |
| Column_name | 建立索引的字段 |
| Collation | 索引字段是否排序,A表示有排序,NULL表示没有排序 |
| Cardinality | MySQL连接时使用索引的可能性(精确度不高),值越大可能性越高 |
| Sub_part | 前缀索引的长度,如字段值都被索引,则 Sub_part 为NULL |
| Packed | 关键词如何被压缩,如果没有被压缩,则为NULL |
| Null | 索引字段是否含有NULL值,YES表示含有,NO表示不含有 |
| Index_type | 索引方式,可选值有FULLTEXT 、HASH 、BTREE 、RTREE |
| Comment | 索引字段的注释信息 |
| Index_comment | 创建索引时添加的注释信息 |
| Visible | 索引对查询优化器是否可见。YES表示可见,NO表示不可见 |
| Expression | 使用什么表达作为建立索引的字段,NULL表示没有 |
修改索引
没有修改索引的sql,所谓的修改索引,就是删除旧的索引,新建新的索引
删除索引
-- 删除索引,方式一
-- 格式:DROP INDEX 索引名 ON 表名;
DROP INDEX index_username ON user_test;-- 删除索引,方式二
-- 格式:ALTER TABLE 表名 DROP INDEX 索引名;
ALTER TABLE user_test DROP INDEX index_username_email;常用字段类型
数值类型
整数类型默认都是有符号整数,就是既可以存正数又可以存负数
| 类型名称 | 字节数 | 范围(有符号)含边界 | 范围(无符号)含边界 |
| tinyint | 1 | -128~127 | 0~255 |
| smallint | 2 | -32768~32767 | 0~65535 |
| mediumint | 3 | -8388608~8388607 | 0~16777215 |
| int | 4 | -2147483648~2147483647 | 0~4294967295 |
| bigint | 8 | -9223372036854775808~9223372036854775807 | 0~18446744073709551615 |
整型经常被用到,比如 tinyint、int、bigint 。默认是有符号的,若只需存储无符号值,可增加 unsigned 属性。
int(M)中的 M 代表最大显示宽度,并不是说 int(1) 就不能存储数值10了,不管设定了显示宽度是多少个字符,int 都是占用4个字节,即int(5)和int(10)可存储的范围一样。
存储字节越小,占用空间越小。所以本着最小化存储的原则,我们要尽量选择合适的整型,例如:存储一些状态值或人的年龄可以用 tinyint ;主键列,无负数,建议使用 int unsigned 或者 bigint unsigned,预估字段数字取值会超过 42 亿,使用 bigint 类型。
浮点型主要有 float,double 两个,浮点型在数据库中存放的是近似值,例如float(6,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位,整数部分最大是3位。float 和 double 平时用的不太多。
| 类型 | 大小 | 用途 |
| float | 4字节 | 单精度浮点数值 |
| double | 8字节 | 双精度浮点数值 |
定点型字段类型有 decimal 一个,主要用于存储有精度要求的小数。
| 类型 | 大小 | 用途 |
| decimal | 对decimal(M,D),如果M>D,则为M+2字节,否则为D+2字节 | 精确小数值 |
注意:存金额一定要用decimal类型,可以很精确,用float和double都不精确,且存储和查询结果不一样(会四舍五入,所以存的和取的不一致)。
DECIMAL 从 MySQL 5.1 引入,列的声明语法是 DECIMAL(M,D) 。NUMERIC 与 DECIMAL 同义,如果字段类型定义为 NUMERIC ,则将自动转成 DECIMAL 。
对于声明语法 DECIMAL(M,D) ,自变量的值范围如下:
M是最大位数(精度),范围是1到65。可不指定,默认值是10。
D是小数点右边的位数(小数位)。范围是0到30,并且不能大于M,可不指定,默认值是0。
例如字段 salary DECIMAL(5,2),能够存储具有五位数字和两位小数的任何值,因此可以存储在salary列中的值的范围是从-999.99到999.99。
字符串类型
| 类型 | 大小 | 用途 |
| char | 0~255字节 | 定长字符串 |
| varchar | 0~65535字节 | 变长字符串 |
| tinytext | 0~255字节 | 短文本字符串 |
| text | 0~65535字节 | 长文本数据 |
| longtext | 0~4294967295字节 | 极大文本数据 |
| tinyblob | 0~255字节 | 二进制字符串 |
| blob | 0~65535字节 | 二进制形式的长文本数据 |
| longbolb | 0~4294967295字节 | 二进制形式的极大文本数据 |
其中 char 和 varchar 是最常用到的。char 类型是定长的,MySQL 总是根据定义的字符串长度分配足够的空间。当保存 char 值时,在它们的右边填充空格以达到指定的长度,当检索到 char 值时,尾部的空格被删除掉。varchar 类型用于存储可变长字符串,存储时,如果字符没有达到定义的位数,也不会在后面补空格。
char(M) 与 varchar(M) 中的的 M 表示保存的最大字符数,单个字母、数字、中文等都是占用一个字符。char 适合存储很短的字符串,或者所有值都接近同一个长度。例如,char 非常适合存储密码的 MD5 值,因为这是一个定长的值。对于字符串很长或者所要存储的字符串长短不一的情况,varchar 更加合适。
我们在定义字段最大长度时应该按需分配,提前做好预估,能使用 varchar 类型就尽量不使用 text 类型。除非有存储长文本数据需求时,再考虑使用 text 类型。
BLOB 类型主要用于存储二进制大对象,例如可以存储图片,音视频等文件。日常很少用到,有存储二进制字符串时可以考虑使用。
时间类型
| 类型 | 大小 | 显示格式 | 存储范围 |
| year | 1字节 | YYYY | 1902~2155 |
| time | 3字节 | hh:mm:ss或hhh:mm:ss | -838:59:59~838:59:59 |
| date | 3字节 | YYYY-MM-DD | 1000-01-01~9999-12-31 23:59:59 |
| datetime | 8字节 | YYYY-MM-DD hh:mm:ss | 1000-01-01 00:00:00~9999-12-31 23:59:59 |
| timestamp | 4字节 | YYYY-MM-DD hh:mm:ss | UTC 1970-01-01 00:00:00~2038-01-19 03:14:07 |
涉及到日期和时间字段类型选择时,根据存储需求选择合适的类型即可。
关于 DATETIME 与 TIMESTAMP 两种类型如何选用,可以按照存储需求来,比如要求存储范围更广,则推荐使用 DATETIME ,如果只是存储当前时间戳,则可以使用 TIMESTAMP 类型。不过值得注意的是,TIMESTAMP 字段数据会随着系统时区而改变但 DATETIME 字段数据不会。总体来说 DATETIME 使用范围更广。
参考文献:
MySQL学习总结(索引的概述、索引的创建、索引的查看、索引的删除)_drop index删除索引-CSDN博客
常用MySQL字段类型解析_mysql常用的字段类型及简要说明-CSDN博客
相关文章:
mysql对表,数据,索引的操作sql
对表的操作 新建表 创建一个名为rwh_test的表,id为主键自增 -- 新建表 CREATE TABLE rwh_test(id int NOT NULL auto_increment PRIMARY KEY COMMENT 主键id,username VARCHAR(20) DEFAULT NULL COMMENT 用户名,age int DEFAULT NULL COMMENT 年龄,create_date d…...

verl单机多卡与多机多卡使用经验总结
文章目录 I. 前言II. SFT2.1 单机多卡2.2 多机多卡 III. RL (GRPO)3.1 单机多卡3.2 多机多卡2.3 模型转换 I. 前言 在上一篇文章verl:一个集SFT与RL于一体的灵活大模型post-training框架 (快速入门) 中,初步探讨了verl框架的基础使用方法。在实际工业级…...

胶铁一体化产品介绍
•一体化结构特点介绍 胶框/铁框一体化技术最早在韩国采用,07年以来由于要求背光越做越薄。在采用0.4mm及以下厚度的LGP时,胶框及背光就会变得异常软,胶框不易组装,铁框松动等问题。 由于胶框和铁框是紧紧粘合在一起的,这正可以解…...

蓝桥杯刷题记录【并查集001】(2024)
主要内容:并查集 并查集 并查集的题目感觉大部分都是模板题,上板子!! class UnionFind:def __init__(self, n):self.pa list(range(n))self.size [1]*n self.cnt ndef find(self, x):if self.pa[x] ! x:self.pa[x] self.fi…...

基于BusyBox构建ISO镜像
1. 准备 CentOS 7.9 3.10.0-957.el7.x86_64VMware Workstation 建议:系统内核<3.10.0 使用busybox < 1.33.2版本 2. 安装busybox # 安装依赖 yum install syslinux xorriso kernel-devel kernel-headers glibc-static ncurses-devel -y# 下载 wget https://…...
Multisim14.3的安装步骤
Multisim14.3的安装步骤 安装包链接 右击Install.exe,以管理员身份运行 激活前关闭杀毒软件 右击,以管理员身份运行 依次右键【Base Edition】、【Full Edition】、【Power ProEdition】、【Full Edition】、【Power ProEdition】,选择【…...
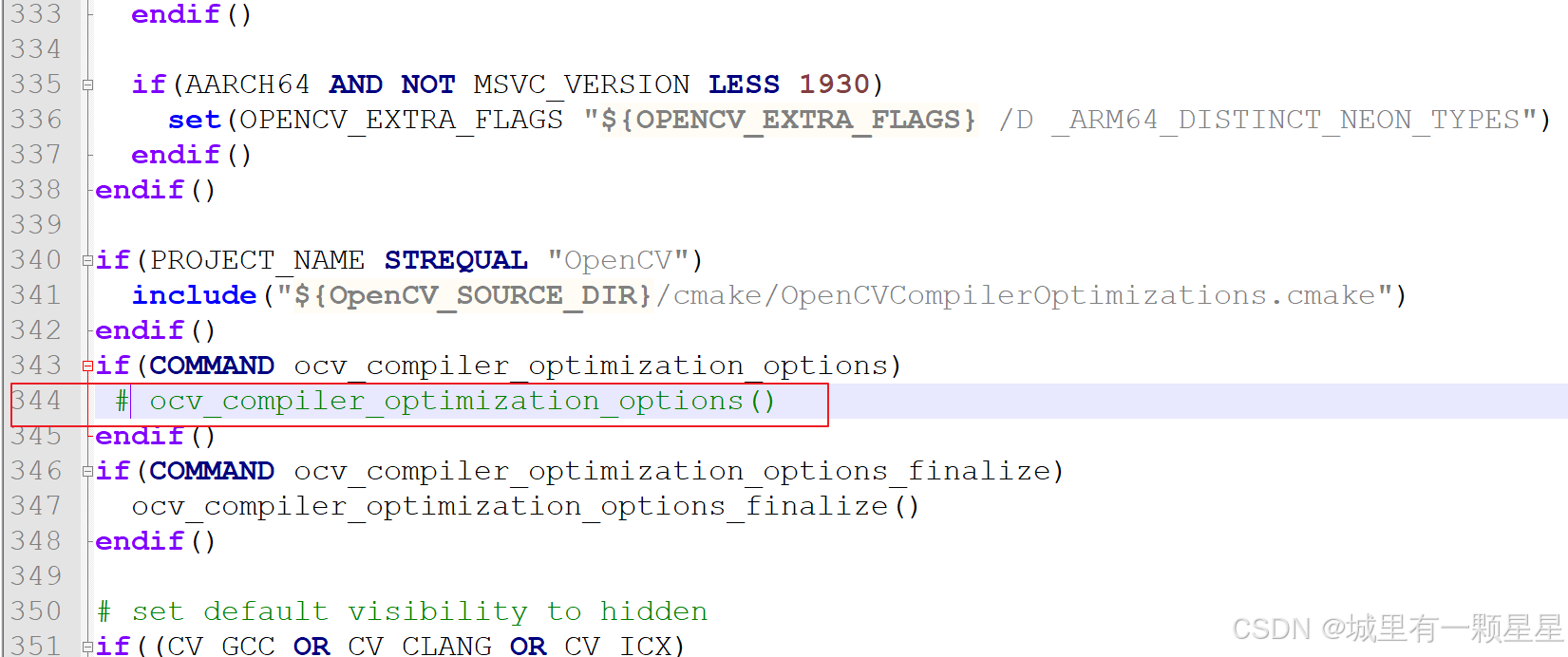
搭建环境-opencv-qt
CMake Error at cmake/OpenCVCompilerOptimizations.cmake:647 (message): Compiler doesnt support baseline optimization flags: Call Stack (most recent call first): cmake/OpenCVCompilerOptions.cmake:344 (ocv_compiler_optimization_options) CMakeList 解决方…...

【愚公系列】《高效使用DeepSeek》050-外汇交易辅助
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...
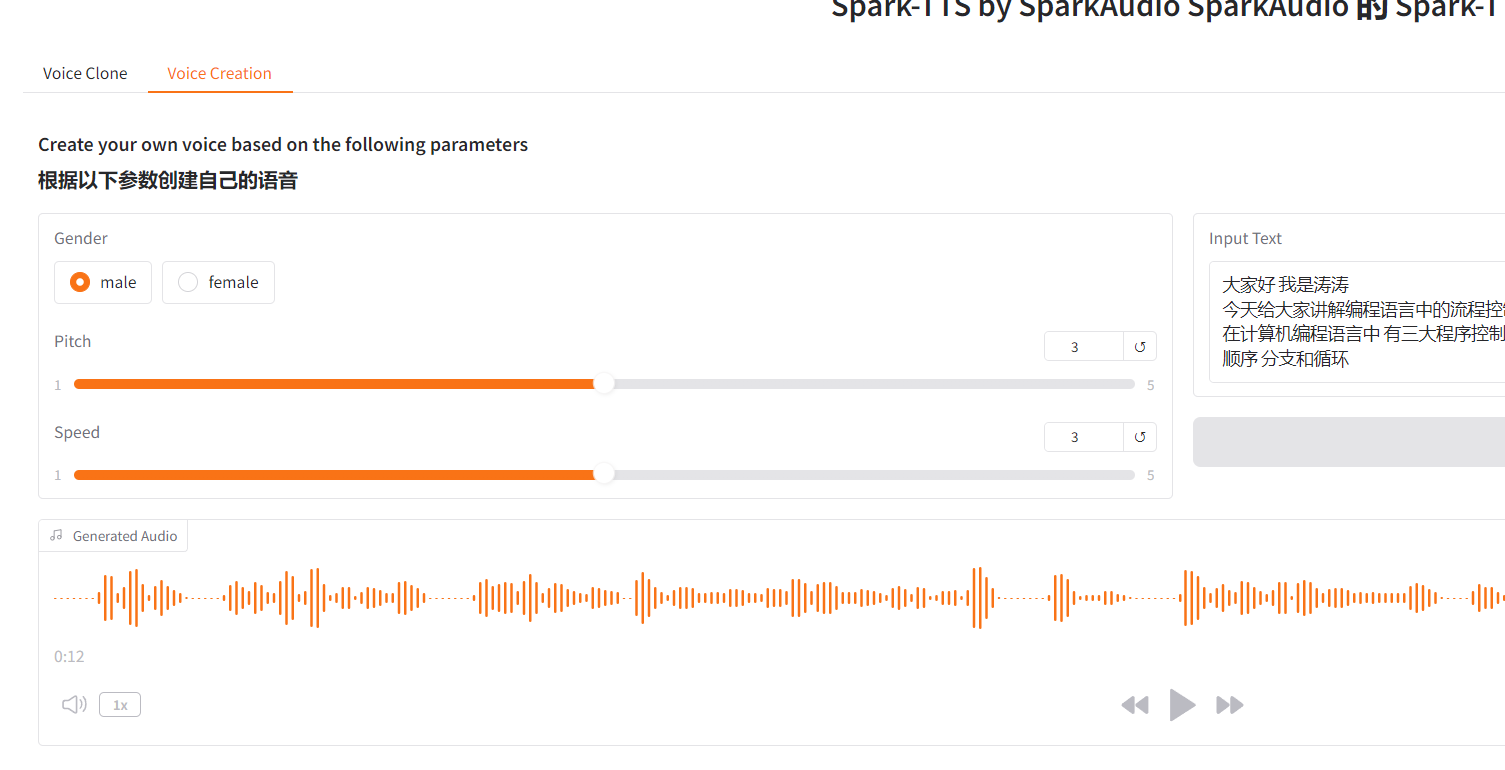
SparkAudio 是什么,和其他的同类 TTS 模型相比有什么优势
欢迎来到涛涛聊AI 在当今数字化时代,音频处理技术已经成为人们生活和工作中不可或缺的一部分。无论是制作有声读物、开发语音助手,还是进行影视配音,我们都离不开高效、精准的音频处理工具。然而,传统的音频处理技术往往存在诸多…...

jvm 的attach 和agent机制
Java 的 Attach 和 Agent 机制在实际应用中得到了广泛的成功应用,尤其是在监控、调试、性能分析、故障排查等方面。以下是这两种机制在实际场景中的一些成功应用案例: 1. 性能监控与分析 Java Agent 和 Attach 机制广泛应用于性能监控和分析࿰…...
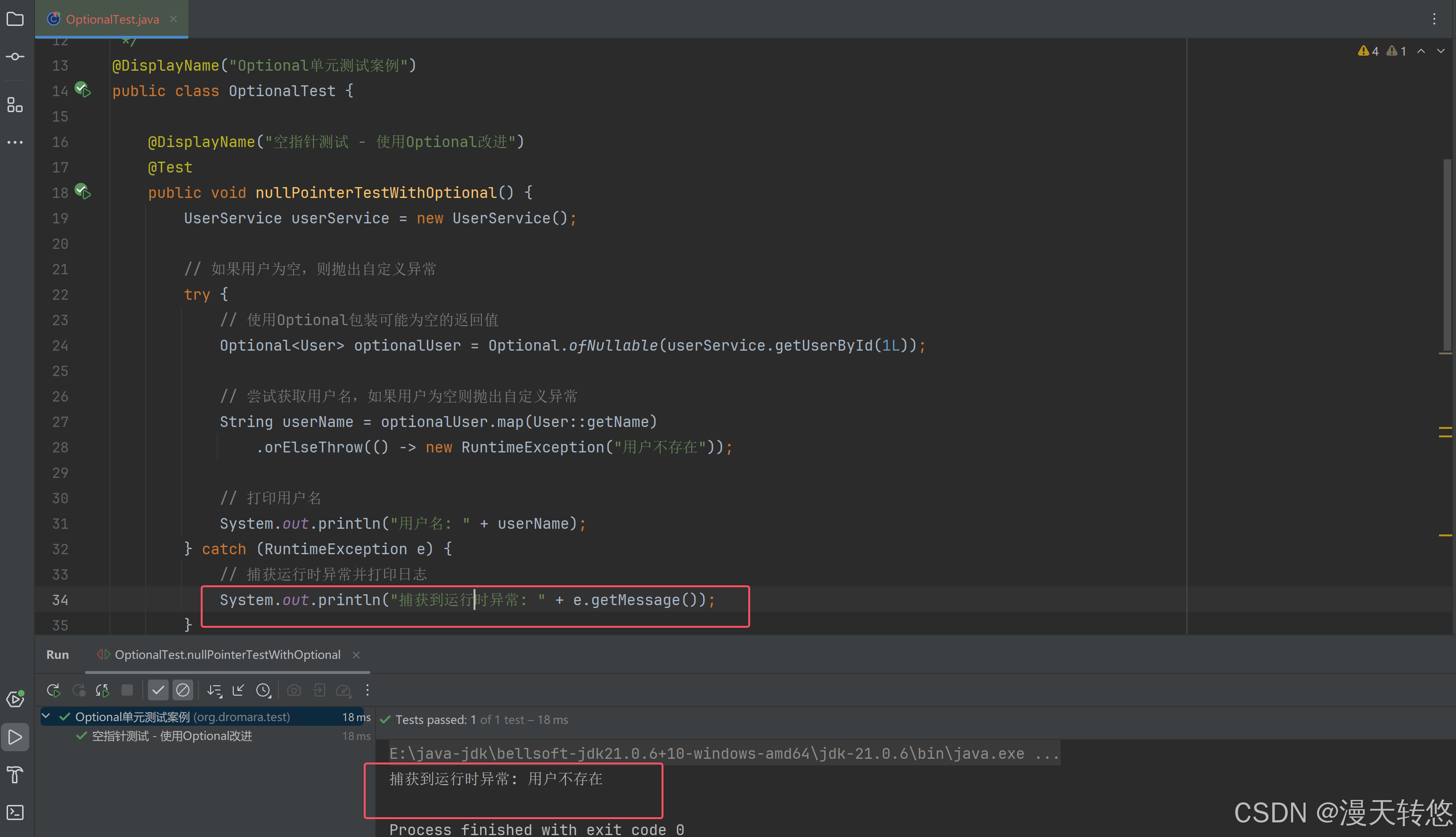
Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8)
Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8) 系列目录 Java8 到 Java21 系列之 Lambda 表达式:函数式编程的开端(Java 8)Java 8 到 Java 21 系列之 Stream API:数据处理的…...
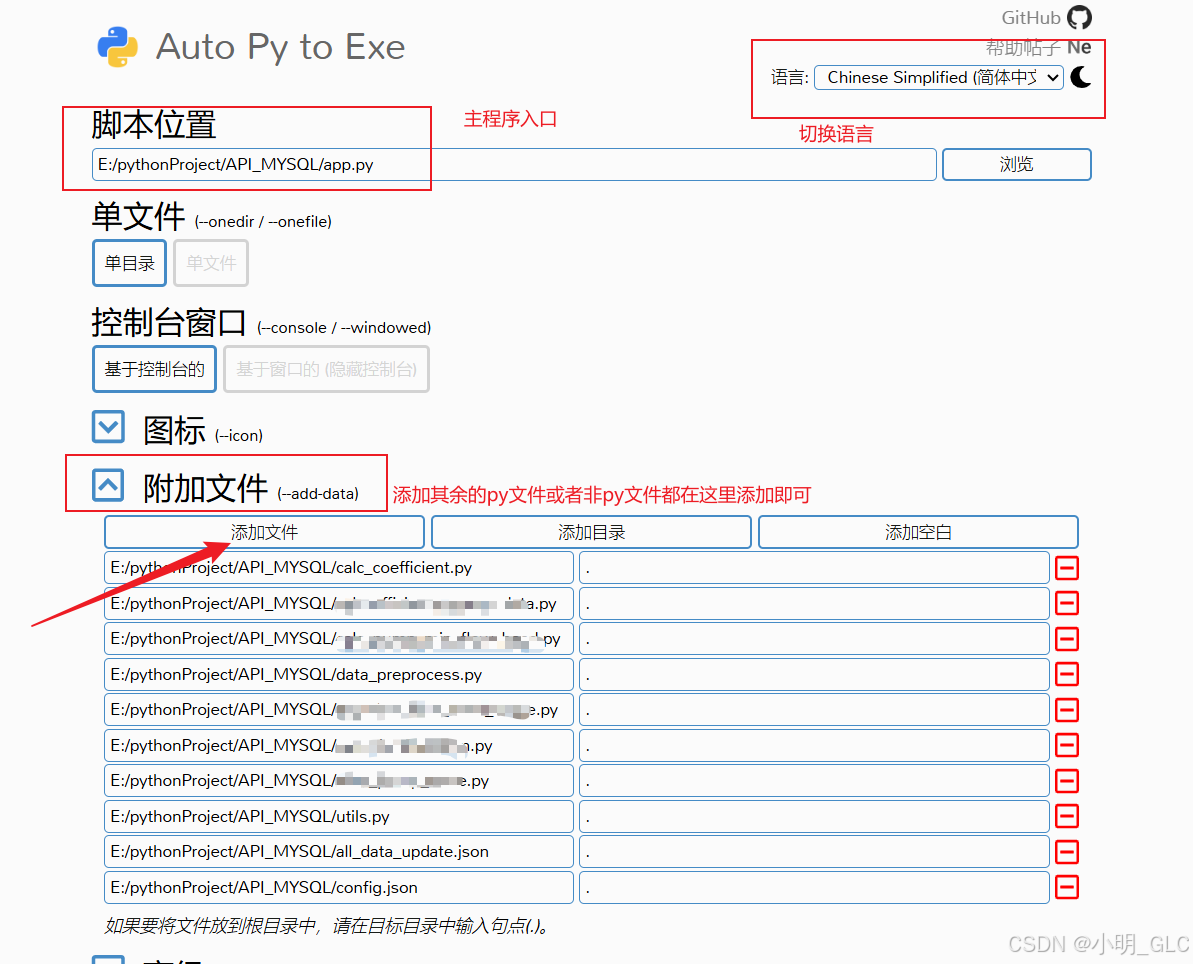
py文件打包为exe可执行文件,涉及mysql连接失败
py文件打包为exe可执行文件,涉及mysql连接失败 项目场景:使用flask框架封装算法接口,并使用pyinstaller打包为exe文件。使用pyinstaller打包多文件的场景,需要自己手动去.spec文件中添加其他文件,推荐使用auto-py-to-e…...

Ubuntu 系统 Docker 中搭建 CUDA cuDNN 开发环境
CUDA 是 NVIDIA 推出的并行计算平台和编程模型,利用 GPU 多核心架构加速计算任务,广泛应用于深度学习、科学计算等领域。cuDNN 是基于 CUDA 的深度神经网络加速库,为深度学习框架提供高效卷积、池化等操作的优化实现,提升模型训练…...
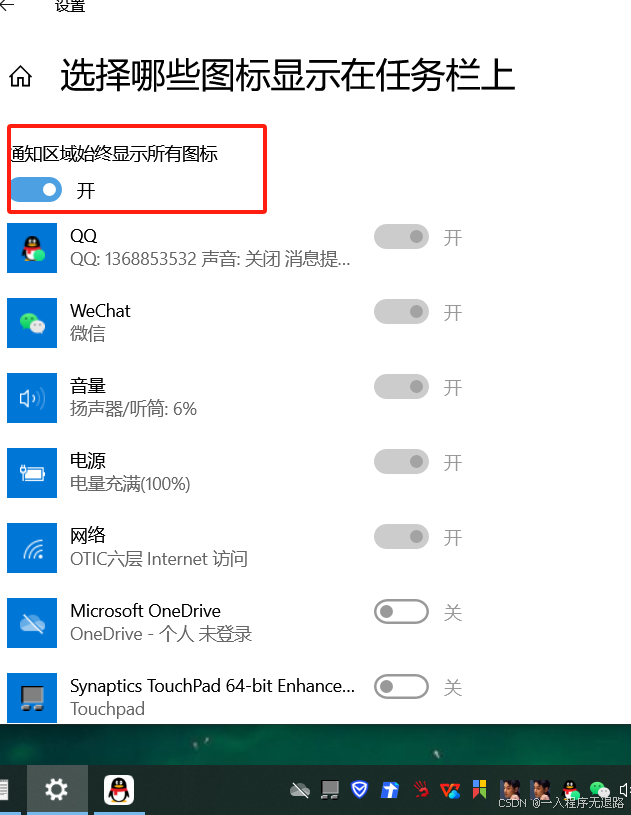
win10彻底让图标不显示在工具栏
关闭需要不显示的软件 打开 例此时我关闭了IDEA的显示 如果说只是隐藏,鼠标拖动一个道理 例QQ 如果说全部显示不隐藏...

Java服务端性能优化:从理论到实践的全面指南
目录 引言:性能优化的重要性 用户体验视角 性能优化的多维度 文章定位与价值 Java代码层性能优化方案 实例创建与管理优化 单例模式的合理应用 批量操作策略 并发编程优化 Future模式实现异步处理 线程池合理使用 I/O性能优化 NIO提升I/O性能 压缩传输…...
人脸识别和定位别的签到系统
1、功能 基于人脸识别及定位的宿舍考勤管理小程序 (用户:宿舍公告、宿舍考勤查询、宿舍考勤(人脸识别、gps 定 位)、考勤排行、请假申请 、个人中心 管理员:宿舍管理、宿舍公告管理 学生信息管理、请假审批、发布宿舍…...

基于YOLOv8的热力图生成与可视化:支持自定义模型与置信度阈值的多维度分析
目标检测是计算机视觉领域的重要研究方向,而YOLO(You Only Look Once)系列算法因其高效性和准确性成为该领域的代表性方法。YOLOv8作为YOLO系列的最新版本,在目标检测任务中表现出色。然而,传统的目标检测结果通常以边…...

echarts+HTML 绘制3d地图,加载散点+散点点击事件
首先,确保了解如何本地引入ECharts库。 html 文件中引入本地 echarts.min.js 和 echarts-gl.min.js。 可以通过官网下载或npm安装,但这里直接下载JS文件更简单。需要引入 echarts.js 和 echarts-gl.js,因为3D地图需要GL模块。 接下来是HTM…...
Design Compiler:库特征分析(ALIB)
相关阅读 Design Compilerhttps://blog.csdn.net/weixin_45791458/category_12738116.html?spm1001.2014.3001.5482 简介 在使用Design Compiler时,可以对目标逻辑库进行特征分析,并创建一个称为ALIB的伪库(可以被认为是缓存)&…...

便携式雷达信号模拟器 —— 打造实战化电磁环境的新利器
在现代战争中,雷达信号的侦察与干扰能力直接关系到作战的成败。为了提升雷达侦察与干扰装备的实战能力,便携式雷达信号模拟器作为一款高性能设备应运而生,为雷达装备的训练、测试和科研提供了不可或缺的支持。 核心功能 便携式雷达信号模拟…...

TypeScript工程集成
以下是关于 TypeScript 工程集成 的系统梳理,涵盖基础配置、进阶优化、开发规范及实际场景的注意事项,帮助我们构建高效可靠的企业级 TypeScript 项目: 一、基础知识点 1. 项目初始化与配置 tsconfig.json 核心配置:{"compilerOptions": {"target": &…...

《P1246 编码》
题目描述 编码工作常被运用于密文或压缩传输。这里我们用一种最简单的编码方式进行编码:把一些有规律的单词编成数字。 字母表中共有 26 个字母 a,b,c,⋯,z,这些特殊的单词长度不超过 6 且字母按升序排列。把所有这样的单词放在一起,按字典…...

基于Transformer框架实现微调后Qwen/DeepSeek模型的非流式批量推理
在基于LLamaFactory微调完具备思维链的DeepSeek模型之后(详见《深入探究LLamaFactory推理DeepSeek蒸馏模型时无法展示<think>思考过程的问题》),接下来就需要针对微调好的模型或者是原始模型(注意需要有一个本地的模型文件,全量微调就是saves下面的文件夹,如果是LoRA,…...

什么是 CSSD?
文章目录 一、什么是 CSSD?CSSD 的职责 二、CSSD 是如何工作的?三、CSSD 为什么会重启节点?情况一:网络和存储都断联(失联)情况二:收到其他节点对自己的踢出通知(外部 fencing&#…...

服务器磁盘io性能监控和优化
服务器磁盘io性能监控和优化 全文-服务器磁盘io性能监控和优化 全文大纲 磁盘IO性能评价指标 IOPS:每秒IO请求次数,包括读和写吞吐量:每秒IO流量,包括读和写 磁盘IO性能监控工具 iostat:监控各磁盘IO性能,…...

CentOS Linux升级内核kernel方法
目录 一、背景 二、准备工作 三、升级内核 一、背景 某些情况需要对Linux发行版自带的内核kernel可能版本较低,需要对内核kernel进行升级。例如:CentOS 7.x 版本的系统默认内核是3.10.0,该版本的内核在Kubernetes社区有很多已知的Bug&#…...
入门)
使用MetaGPT 创建智能体(1)入门
metagpt一个多智能体框架 官网:MetaGPT | MetaGPT 智能体 在大模型领域,智能体通常指一种基于大语言模型(LLM)构建的自主决策系统,能够通过理解环境、规划任务、调用工具、迭代反馈等方式完成复杂目标。具备主动推理…...

AF3 OpenFoldMultimerDataset类解读
AlphaFold3 data_modules 模块的 OpenFoldMultimerDataset 类是 OpenFoldDataset 类的子类,专门用于 多链蛋白质(Multimer) 数据集的训练。它通过引入 AlphaFold Multimer 论文 中描述的过滤步骤,来实现多链蛋白质的训练。这个类扩展了父类的功能,特别是为了处理多链蛋白质…...
【C++】多态功能细节问题分析
多态是在不同继承关系的类对象去调用同一函数,产生了不同的行为。值得注意的是,虽然多态在功能上与隐藏是类似的,但是还是有较大区别的,本文也会进行多态和隐藏的差异分析。 在继承中要构成多态的条件 1.1必须通过基类的指针或引用…...

[CISSP] [5] 保护资产安全
数据状态 1. 数据静态存储(Data at Rest) 指存储在磁盘、数据库、存储设备上的数据,例如: 硬盘、SSD服务器、数据库备份存储、云存储 安全措施 加密(Encryption):如 AES-256 加密磁盘和数据…...