飞浆PaddlePaddle 猫狗数据大战
猫狗数据大战
- 1 数据集的准备以及处理操作
- 1.1 数据集
- 1.2 文件解压操作(python)
- 1.3 数据的分类
- 1.4 创建训练集和测试集
- 2 网络构建
- CNN版本--
- DeepID 人脸识别网络结构
- DeepID 与 CNN 网络结构的差异
- 3 深度学习模型训练和推理的核心设置
- 4 制图
- 5 训练
- 6 预测+结果
1 数据集的准备以及处理操作
1.1 数据集
在训练模型之前的时候我们需要提前准备数据集
数据集下载链接
1.2 文件解压操作(python)
# 第一步,把原数据解压
import zipfile
import os
import shutildef unzipFile(source_file, target_dir):''' 解压单个文件到目标文件夹。'''zf = zipfile.ZipFile(source_file)try:zf.extractall(path=target_dir)except RuntimeError as e:print(e)zf.close()sour = 'data/data20541/dogs-vs-cats.zip'
targ = ''
if not os.path.exists('data/dogCat/dog'): #用os.path.exists来判断'data/dogCat/dog'路径存不存在unzipFile(source_file = sour, target_dir = targ)os.remove('sample_submission.csv')
首先:我们需要制定一个函数来解压zip文件。
然后:通过python中的库中的文件操作函数ZipFile()来解压
最后:把解压好的文件在通过extractall()函数放在target_dir目录下
第二步:原数据解压之后是 形成 train.zip 和 test.zip 文件还需要解压一遍,让他们解压之后形成训练集和测试集。
if not os.path.exists('data/dogCat/dog'):# 先解压训练集train_file = 'train.zip'train_targetdir = 'data'unzipFile(source_file = train_file, target_dir = train_targetdir)os.remove(train_file)# 再解压测试集test_file = 'test.zip'test_targetdir = 'data'unzipFile(source_file = test_file, target_dir = test_targetdir)os.remove(test_file)
1.3 数据的分类
在训练计算机识别动物之前,我们需要进行区分,比如:你要让计算机进行猫狗的区分那么你的数据集中有其他的动物的图片,这样的话在训练过程中在识别关键信息的时候就出错!!!。因此我们需要排除干扰选项。
排除干扰项思路:把文件的所有图片都遍历一遍然后进行筛选出猫和狗的图片。
执行代码:
dataRootPath = 'data/dogCat'def copyFiles(fileDirs, targetDir):for fileDir in fileDirs:shutil.copy(fileDir, targetDir)def divideData():global dataRootPathclassDirs = os.listdir('data/train')dogDirs = [os.path.join('data/train',x) for x in classDirs if x.find('dog')>=0]catDirs = [os.path.join('data/train',x) for x in classDirs if x.find('cat')>=0]print('总图片数量为:%d'%len(classDirs))print('\t猫的图片数量为:%d'%len(catDirs))print('\t狗的图片数量为:%d'%len(dogDirs))# 遍历图片,转移数据集dogPath = os.path.join(dataRootPath, 'dog')if not os.path.exists(dogPath):os.makedirs(dogPath)copyFiles(dogDirs, dogPath)catPath = os.path.join(dataRootPath, 'cat')if not os.path.exists(catPath):os.makedirs(catPath)copyFiles(catDirs, catPath)if not os.path.exists('data/dogCat/dog'):divideData()
接下来我们来介绍以上提到的函数:
1 os.listdir(路径) ==== 这是把路径中的目录展开 。就是把目录展开了,然后就是目录中的子文件或者文件了。这里就是指的是图片!!!
2 os.path.join(路径,路径1)==== 这里就是列表的初始化 ,先是判断你的x有没有dog或者cat的文字(这一步就是先筛选图片名称为dog和cat)。 如果符合那么就把路径1链接到路劲之后。 如:os.path.join(‘data/dogcat/’,dog1.jpg) -> 结果:data/dogcat/dog1.jpg
3 os.path.exists(路径) 就是判断路径存不存在
4 os.mkdir(名称) 就是创建名称目录
5 shutil.copy(dest,source) 就是把文件进行复制
总结:以上代码就是为了把干扰选项给去掉,为了更好的训练出大模型!!!
1.4 创建训练集和测试集
在经过以上操作后:我们就可以开始进行对数据进行划分和创建数据集合测试集了
#Python os标准库,用于文件操作、 random随机数生成、 JSON解析和系统参数访问。
import os
import random
import json
import sys
#Paddle.fluid,paddle框架的核心模块,用于构建和训练深度学习模型。
import paddle
import paddle.fluid as fluid
#数值计算库,用于处理数组和矩阵.
import numpyfrom multiprocessing import cpu_count
from visualdl import LogWriter
#matplotlib.pyplot用于绘图和数据可视化
import matplotlib.pyplot as plt
import numpy as np#PIL 用于打开和处理图像
from PIL import Imageimport paddle
paddle.enable_static()#定义长度,和宽度
IMG_H =64
IMG_W =64#缓冲区大小,用来读取数据处理和预处理
BUFFER_SIZE = 1024#一次批量处理的个数
BATCH_SIZE =64#是否使用gpu
USE_CUDA = True
#训练次数
TRAIN_NUM = 150
#学习率
LEARNING_RATE = 0.005DATA_TRAIN = 0.75 #训练集在数据集中占多少数据 # 表示在训练模型时,使用多大规模的数据#每执行玩一个模型就放在work/model 中,这样方便模型的拿取
model_save_dir = "work/model"def genDataList(dataRootPath, trainPercent=0.8):# 函数会自动检测dataRootPath下的所有文件夹,每一个文件夹为1个类别的图片# 然后生成图片的list,即paddlepaddle能获取信息的形式# 默认随机抽取20%作为测试集(验证集)# random.seed(42) #设置随机种子。classDirs = os.listdir(dataRootPath)#os.listdir用来获取dataRootPath的所有文件和文件夹#os.isdir 判断是否为目录 #os.path.join 拼接classDirs = [x for x in classDirs if os.path.isdir(os.path.join(dataRootPath,x))]listDirTest = os.path.join(dataRootPath, "test.list")listDirTrain = os.path.join(dataRootPath, "train.list")# 清空原来的数据,当一‘w’模式打开文件夹时,1:文件已存在,那么就会清空数据 2:文件不存在,就会新建一个文件#避免旧数据干扰# with open(listDirTest, 'w') as f:# pass# with open(listDirTrain, 'w') as f:# passwith open(listDirTest, 'w') as f:pass # 清空测试集文件with open(listDirTrain, 'w') as f:pass # 清空训练集文件# 随机划分训练集与测试集classLabel = 0 # 初始化类别标签,从0开始class_detail = [] # 记录每个类别的描述classList = [] # 记录所有的类别名num_images = 0 # 统计图片的总数量for classDir in classDirs:classPath = os.path.join(dataRootPath,classDir) # 获取类别为classDir的图片所在的目录,拼接子目录 如:data/DogCat/dogimgPaths = os.listdir(classPath) # 获取类别为classDir的所有图片名# 从中取trainPercent(默认80%)作为训练集imgIndex = list(range(len(imgPaths))) #生成图片索引列表random.shuffle(imgIndex) #打乱图片索引imgIndexTrain = imgIndex[:int(len(imgIndex)*trainPercent)]#划分训练集与测试集imgIndexTest = imgIndex[int(len(imgIndex)*trainPercent):]#把代码追加到listDirTest 与 listDirTrain 目录下with open(listDirTest,'a') as f:for i in imgIndexTest:imgPath = os.path.join(classPath,imgPaths[i]) #打开目录listDirTest 把刚刚定义的imgIndexTest写入到该目录下 路劲大致如:data/DogCat/dog/dog.1jpg f.write(imgPath + '\t%d' % classLabel + '\n') # 写入格式图片路劲\t类别标签\nwith open(listDirTrain,'a') as f:for i in imgIndexTrain:imgPath = os.path.join(classPath,imgPaths[i])f.write(imgPath + '\t%d' % classLabel + '\n') num_images += len(imgPaths)classList.append(classDir) #将类别名称添加到classList中class_detail_list = {} #记录该类别的名称、标签、测试集图片数量和训练集图片数量class_detail_list['class_name'] = classDir #类别名称,如dogclass_detail_list['class_label'] = classLabel #类别标签,如cat 的标签是 0 dog的标签是 1class_detail_list['class_test_images'] = len(imgIndexTest) #该类数据的测试集数目class_detail_list['class_trainer_images'] = len(imgIndexTrain) #该类数据的训练集数目class_detail.append(class_detail_list) classLabel += 1# 说明的json文件信息readjson = {} #包含所有类别的名称、总类别数量、总图片数量以及每个类别的详细信息。readjson['all_class_name'] = classList # 文件父目录readjson['all_class_sum'] = len(classDirs) # 总类别数量readjson['all_class_images'] = num_images # 总图片数量readjson['class_detail'] = class_detail # 每种类别的情况jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))#json.dumps的作用是将Python对象转换成JSON格式的字符串。这里的参数看起来是用于格式化输出的。#sort_keys对字典的键(Key)按字母顺序排序。设置缩进为4个空格,使JSON字符串具有层次结构with open(os.path.join(dataRootPath,"readme.json"),'w') as f:#把jsons字符串写入到dataRootPath/readme.json中用于保存数据集的元信息(如类别名称、标签、图片数量等)f.write(jsons)print ('生成数据列表完成!')return readjson['all_class_sum']classNumber = genDataList(dataRootPath)#返回类别数量
print(classNumber)
我们还是一步一步来:
1 变量:
#定义长度,和宽度
IMG_H =64
IMG_W =64
#缓冲区大小,用来读取数据处理和预处理
BUFFER_SIZE = 1024
#一次批量处理的个数
BATCH_SIZE =64
#是否使用gpu
USE_CUDA = True
#训练次数
TRAIN_NUM = 150
#学习率
LEARNING_RATE = 0.005
DATA_TRAIN = 0.75 #训练集在数据集中占多少数据 # 表示在训练模型时,使用多大规模的数据
#每执行玩一个模型就放在work/model 中,这样方便模型的拿取
model_save_dir = "work/model"
这是我们在训练时进行定义的全局变量:
IMG_H IMG_W 定义的输出图像的长宽高度
BUFFER_SIZE 就是缓冲区的大小用于读取数据处理和预处理
BATCH_SIZE 就是在训练时一次读取的个数
USE_CUDA = True 这是使用GPU来进行训练,因为你使用CPU的话这个程序会训练的很慢或者训练不出来。
TRAIN_NUM 训练次数
LEARNING_RATE 学习率
DATA_TRAIN 训练集在数据集中占多少数据 表示在训练模型时,使用多大规模的数据
model_save_dir 每执行玩一个模型就放在work/model 中,这样方便模型的拿取
然后就是我们的genDataList函数:
def genDataList(dataRootPath, trainPercent=0.8):# 函数会自动检测dataRootPath下的所有文件夹,每一个文件夹为1个类别的图片# 然后生成图片的list,即paddlepaddle能获取信息的形式# 默认随机抽取20%作为测试集(验证集)# random.seed(42) #设置随机种子。classDirs = os.listdir(dataRootPath)#os.listdir用来获取dataRootPath的所有文件和文件夹#os.isdir 判断是否为目录 #os.path.join 拼接classDirs = [x for x in classDirs if os.path.isdir(os.path.join(dataRootPath,x))]listDirTest = os.path.join(dataRootPath, "test.list")listDirTrain = os.path.join(dataRootPath, "train.list")# 清空原来的数据,当一‘w’模式打开文件夹时,1:文件已存在,那么就会清空数据 2:文件不存在,就会新建一个文件#避免旧数据干扰# with open(listDirTest, 'w') as f:# pass# with open(listDirTrain, 'w') as f:# passwith open(listDirTest, 'w') as f:pass # 清空测试集文件with open(listDirTrain, 'w') as f:pass # 清空训练集文件# 随机划分训练集与测试集classLabel = 0 # 初始化类别标签,从0开始class_detail = [] # 记录每个类别的描述classList = [] # 记录所有的类别名num_images = 0 # 统计图片的总数量for classDir in classDirs:classPath = os.path.join(dataRootPath,classDir) # 获取类别为classDir的图片所在的目录,拼接子目录 如:data/DogCat/dogimgPaths = os.listdir(classPath) # 获取类别为classDir的所有图片名# 从中取trainPercent(默认80%)作为训练集imgIndex = list(range(len(imgPaths))) #生成图片索引列表random.shuffle(imgIndex) #打乱图片索引imgIndexTrain = imgIndex[:int(len(imgIndex)*trainPercent)]#划分训练集与测试集imgIndexTest = imgIndex[int(len(imgIndex)*trainPercent):]#把代码追加到listDirTest 与 listDirTrain 目录下with open(listDirTest,'a') as f:for i in imgIndexTest:imgPath = os.path.join(classPath,imgPaths[i]) #打开目录listDirTest 把刚刚定义的imgIndexTest写入到该目录下 路劲大致如:data/DogCat/dog/dog.1jpg f.write(imgPath + '\t%d' % classLabel + '\n') # 写入格式图片路劲\t类别标签\nwith open(listDirTrain,'a') as f:for i in imgIndexTrain:imgPath = os.path.join(classPath,imgPaths[i])f.write(imgPath + '\t%d' % classLabel + '\n') num_images += len(imgPaths)classList.append(classDir) #将类别名称添加到classList中class_detail_list = {} #记录该类别的名称、标签、测试集图片数量和训练集图片数量class_detail_list['class_name'] = classDir #类别名称,如dogclass_detail_list['class_label'] = classLabel #类别标签,如cat 的标签是 0 dog的标签是 1class_detail_list['class_test_images'] = len(imgIndexTest) #该类数据的测试集数目class_detail_list['class_trainer_images'] = len(imgIndexTrain) #该类数据的训练集数目class_detail.append(class_detail_list) classLabel += 1
根据我的注释可以得出:
这个函数第一步就是创建出数据集和测试集:
imgIndex = list(range(len(imgPaths))) #生成图片索引列表random.shuffle(imgIndex) #打乱图片索引imgIndexTrain = imgIndex[:int(len(imgIndex)*trainPercent)]#划分训练集与测试集imgIndexTest = imgIndex[int(len(imgIndex)*trainPercent):]......之后就是把文件写入操作第二步就是记录属性
classLabel = 0 # 初始化类别标签,从0开始class_detail = [] # 记录每个类别的描述classList = [] # 记录所有的类别名num_images = 0 # 统计图片的总数量
他们把记录出来的这些属性,用json进行连接。
得出:
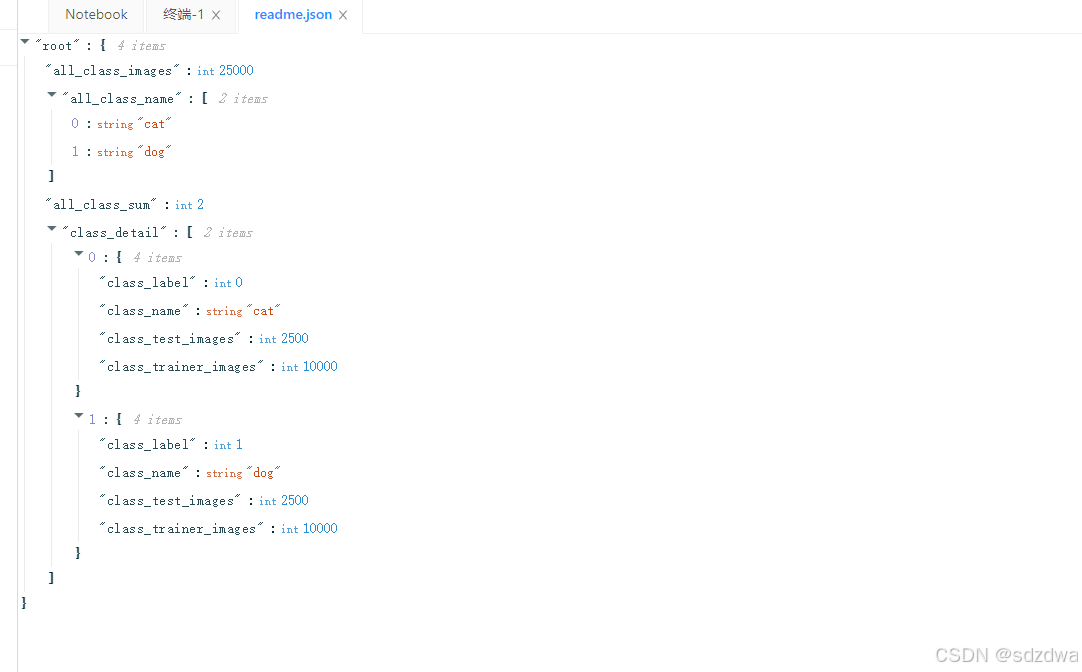

把狗做标记:为1 (class_label= 1)
然后圈红圈的分别是训练集的个数,和测试集的个数
猫同理。
1.5 数据处理和创建数据处理器
def trainMapper(sample):global IMG_H, IMG_Wimg, label = sample# 图像加载(兼容老版本)img = paddle.dataset.image.load_image(img) # 所有版本通用# 图像变换(老版本无水平翻转,需手动添加)img = paddle.dataset.image.simple_transform(im=img, resize_size=IMG_H, crop_size=IMG_W, is_color=True, is_train=True # 在1.x版本中此参数可能不触发翻转)img = img.flatten().astype('float32') / 255.0return img, label# 对自定义数据集创建训练集train的reader
def trainReader(train_list, buffered_size=1024):global DATA_TRAINdef reader():with open(train_list, 'r') as f:# 将train.list里面的标签和图片的地址放在一个list列表里面,中间用\t隔开'# 如data/dogCat/Cat_/1.jpg\t0'lines = [line.strip() for line in f]# 读取所有行并去除首尾空格np.random.shuffle(lines)#打乱数据顺序增强随机性lines = lines[:int(len(lines)*DATA_TRAIN)]for line in lines:# 图像的路径和标签是以\t来分割的,所以我们在生成这个列表的时候,使用\t就可以了img_path, lab = line.strip().split('\t')# 分割路径与标签yield img_path, int(lab) # 生成数据元组(路径, 标签)# 创建自定义数据训练集的train_readerreturn paddle.reader.xmap_readers(trainMapper, reader, cpu_count(), buffered_size)def testMapper(sample):global IMG_Hglobal IMG_Wimg, label = sampleimg = paddle.dataset.image.load_image(img)img = paddle.dataset.image.simple_transform(im=img, resize_size=IMG_H, crop_size=IMG_W, is_color=True, is_train=False)img= img.flatten().astype('float32')/255.0return img, label# 对自定义数据集创建验证集test的reader
def testReader(test_list, buffered_size=1024):global DATA_TRAINdef reader():with open(test_list, 'r') as f:lines = [line.strip() for line in f]np.random.shuffle(lines)lines = lines[int(len(lines)*DATA_TRAIN):]for line in lines:#图像的路径和标签是以\t来分割的,所以我们在生成这个列表的时候,使用\t就可以了img_path, lab = line.strip().split('\t')yield img_path, int(lab)return paddle.reader.xmap_readers(testMapper, reader, cpu_count(), buffered_size)
在这里呢,我们就讲解一下怎么处理数据的:
img = paddle.dataset.image.simple_transform(im=img, resize_size=IMG_H, crop_size=IMG_W, is_color=True, is_train=True # 在1.x版本中此参数可能不触发翻转)img = img.flatten().astype('float32') / 255.0
通过simple_transform 这个类成员函数进行处理数据:
resize_size=IMG_H 这里代表的是缩放,就比如:原本3232的照片 缩放成1616。
crop_size=IMG_W 这里代表着中心裁剪
is_color = True 这里就是代表有颜色额图片
is_train=True 如果是True的话,这里的函数有可能对图片进行随机裁剪(增强数据)
最后img = img.flatten().astype(‘float32’) / 255.0 代表这归一化 按(0,1)处理
而在测试的时候is_train=False 这就是不采用随机裁剪
创建数据集Reader
def createDataReader(BatchSize = 128):global BUFFER_SIZE# 把图片数据生成readertrainer_reader = trainReader(train_list = os.path.join(dataRootPath,"train.list"))train_reader = paddle.batch(paddle.reader.shuffle(reader=trainer_reader, buf_size=BUFFER_SIZE),batch_size=BatchSize)tester_reader = testReader(test_list = os.path.join(dataRootPath,"test.list"))test_reader = paddle.batch(tester_reader, batch_size=BatchSize)print('train_reader, test_reader创建完成!')return train_reader, test_reader
这里不做解释
2 网络构建
CNN版本–
def convolutional_neural_network(image, classNumber):# 第一个卷积-池化层 #修改第一步就是先是卷积池化->bn->激活 查找论文中 可以得出BN在激活前:在激活函数前进行 BN,能更有效地约束激活前的输入分布,#使网络更容易学习到合适的参数,ReLU 对负值输入会直接截断(输出0),如果激活后再 BN,可能丢失部分信息;而先 BN 再激活,可以确保激活函数的输入是归一化的正值,梯度更稳定。#论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》建议将 BN 放在激活前,以最大化其规范化效果。conv_pool_1 = fluid.nets.simple_img_conv_pool(input=image, # 输入图像filter_size=5, # 滤波器的大小num_filters=20, # filter 的数量pool_size=2, # 池化核大小pool_stride=2, # 池化步长act=None # 先不激活)conv_pool_1 = fluid.layers.batch_norm(conv_pool_1) # BNconv_pool_1 = fluid.layers.relu(conv_pool_1) # 激活# 第二个卷积-池化层conv_pool_2 = fluid.nets.simple_img_conv_pool(input=conv_pool_1,filter_size=5,num_filters=50,pool_size=2,pool_stride=2,act=None)conv_pool_2 = fluid.layers.batch_norm(conv_pool_2) # BNconv_pool_2 = fluid.layers.relu(conv_pool_2) # 激活# 第三个卷积-池化层conv_pool_3 = fluid.nets.simple_img_conv_pool(input=conv_pool_2,filter_size=5,num_filters=50,pool_size=2,pool_stride=2,act=None)conv_pool_3 = fluid.layers.batch_norm(conv_pool_3) # BNconv_pool_3 = fluid.layers.relu(conv_pool_3) # 激活# 全连接输出层prediction = fluid.layers.fc(input=conv_pool_3, size=classNumber, act='softmax')print('神经网络创建完成!')return prediction
~卷积层:nn.Conv2d用于提取特征,参数包括输入通道数、输出通道数、卷积核大小等。
~池化层:nn.MaxPool2d用于降维,通常使用最大池化。
~全连接层:nn.Linear用于将特征映射到最终输出空间。
~激活函数:F.relu是ReLU激活函数,增加非线性。
~展平操作:x.view将特征图展平为一维向量,以便输入全连接层。
这里就需要我们进行深度学习了!!!
如果是网络构建的话选择CNN就OK了!!!
DeepID 人脸识别网络结构
def DeepID(images, classNumber):# 第一个卷积-池化层conv_pool_1 = fluid.nets.simple_img_conv_pool(input=images,filter_size=5,num_filters=32,pool_size=2,pool_stride=2,act=None # 先不激活)conv_pool_1 = fluid.layers.batch_norm(conv_pool_1) # BNconv_pool_1 = fluid.layers.relu(conv_pool_1) # 激活# 第二个卷积-池化层conv_pool_2 = fluid.nets.simple_img_conv_pool(input=conv_pool_1,filter_size=3,num_filters=40,pool_size=2,pool_stride=1,act=None)conv_pool_2 = fluid.layers.batch_norm(conv_pool_2) # BNconv_pool_2 = fluid.layers.relu(conv_pool_2) # 激活# 第三个卷积-池化层conv_pool_3 = fluid.nets.simple_img_conv_pool(input=conv_pool_2,filter_size=3,num_filters=60,pool_size=2,pool_stride=2,act=None)conv_pool_3 = fluid.layers.batch_norm(conv_pool_3) # BNconv_pool_3 = fluid.layers.relu(conv_pool_3) # 激活# 全连接层 fc160_1fc160_1 = fluid.layers.fc(input=conv_pool_3, size=160)# 第四个卷积层(无池化)conv_4 = fluid.layers.conv2d(input=conv_pool_3,num_filters=128,filter_size=3,act=None # 先不激活)conv_4 = fluid.layers.batch_norm(conv_4) # BNconv_4 = fluid.layers.relu(conv_4) # 激活# 全连接层 fc160_2fc160_2 = fluid.layers.fc(input=conv_4, size=160)# 合并全连接层fc160 = fluid.layers.elementwise_add(fc160_1, fc160_2, act="relu") # 必须保留# 全连接输出层prediction = fluid.layers.fc(input=fc160, size=classNumber, act='softmax')return prediction
卷积层:提取人脸的局部特征。
池化层:降维并增强特征的鲁棒性。
全连接层:将高维特征映射到类别空间。
最后一层无激活函数:输出的是人脸特征向量,而不是直接的分类结果。
DeepID 与 CNN 网络结构的差异
| 特性 | CNN | DeepID |
|---|---|---|
| 网络结构 | 通用结构,适用于多种视觉任务 | 专为人脸识别设计,提取高维特征 |
| 输入数据 | 通用图像数据(如分类任务中的物体图像) | 固定大小的人脸图像(如 112x112 或 128x128) |
| 输出 | 类别概率(分类任务) | 高维特征向量(用于相似性计算) |
| 训练目标 | 最大化正确类别的概率(交叉熵损失等) | 学习高维、判别性强的人脸特征,结合联合贝叶斯模型优化特征空间 |
| 后续处理 | 直接输出结果(如分类标签) | 特征向量用于人脸验证或聚类,通常结合联合贝叶斯模型 |
| 应用场景 | 图像分类、目标检测、语义分割等 | 人脸识别、人脸验证、人脸聚类等 |
总结:
CNN 是一种通用框架,适用于多种视觉任务,网络结构和训练目标灵活多样。
DeepID 是一种专用网络,专注于人脸识别任务,通过网络提取高维特征并结合联合贝叶斯模型优化特征空间。
3 深度学习模型训练和推理的核心设置
def setPredictor(learning_rate =0.0001):image = fluid.layers.data(name='image', shape=[3, IMG_H, IMG_W], dtype='float32')#接收形状为 【3,H,W】 的输入图像label = fluid.layers.data(name='label', shape=[1], dtype='int64')#接收形状为 1 的标签# 建立网络# predict = convolutional_neural_network(image, classNumber)predict = DeepID(image, classNumber)#################################################################################### 获取损失函数和准确率cost = fluid.layers.cross_entropy(input=predict, label=label) # 交叉熵avg_cost = fluid.layers.mean(cost) # 计算cost中所有元素的平均值acc = fluid.layers.accuracy(input=predict, label=label) #使用输入和标签计算准确率# 定义优化方法# optimizer =fluid.optimizer.Adam(learning_rate=learning_rate)# optimizer.minimize(avg_cost)# 定义带动量的 SGD 优化器optimizer = fluid.optimizer.Momentum(learning_rate=learning_rate,momentum=0.9,regularization=fluid.regularizer.L2Decay(regularization_coeff=1e-4))optimizer.minimize(avg_cost)# 定义优化器时添加梯度裁剪 正则:原le-4 改成 le-3# optimizer = fluid.optimizer.Momentum(# learning_rate=learning_rate,# momentum=0.9,# regularization=fluid.regularizer.L2Decay(1e-4),# grad_clip=fluid.clip.GradientClipByGlobalNorm(clip_norm=5.0) # 全局范数裁剪# )# optimizer.minimize(avg_cost)# 定义使用CPU还是GPU,使用CPU时USE_CUDA = False,使用GPU时USE_CUDA = Trueplace = fluid.CUDAPlace(0) if USE_CUDA else fluid.CPUPlace()# 创建执行器,初始化参数exe = fluid.Executor(place) #就像请一个厨师(执行器)按照菜谱(模型结构)在指定的厨房(CPU或GPU)里做菜。exe.run(fluid.default_startup_program()) #运行模型的“启动程序”,初始化所有参数(比如神经网络的权重和偏置)feeder = fluid.DataFeeder( feed_list=[image, label],place=place)#创建一个“数据喂入器”,负责将输入数据(如图像和标签)传递给模型# 获取测试程序test_program = fluid.default_main_program().clone(for_test=True)return image, label, predict, avg_cost, acc, exe, feeder, test_program################################################################################### image, label, predict, avg_cost, acc, exe, feeder, test_program = setPredictor(LEARNING_RATE)
4 制图
import matplotlib.pyplot as plt
import numpy as npdef draw_figure(dictCostAccdictCostAcc, xlabel, ylabel_1, ylabel_2):plt.xlabel(xlabel, fontsize=20)plt.plot(dictCostAcc[xlabel], dictCostAcc[ylabel_1],color='red',label=ylabel_1) plt.plot(dictCostAcc[xlabel], dictCostAcc[ylabel_2],color='green',label=ylabel_2) plt.legend()plt.grid()def draw_train_process(epoch, dictCostAcc):# train的cost与accuray的变化plt.figure(figsize=(10, 3))plt.title('epoch - ' + str(epoch), fontsize=24)plt.subplot(1,3,1)draw_figure(dictCostAcc, 'iteration', 'iter_cost', 'iter_acc')plt.subplot(1,3,2)draw_figure(dictCostAcc, 'epoch', 'cost_train', 'cost_test')plt.subplot(1,3,3)draw_figure(dictCostAcc, 'epoch', 'acc_train', 'acc_test')plt.show()draw_figure() 功能:
绘制单个子图,展示两个指标的变化曲线。
通过 dictCostAcc 提供的数据绘制曲线,dictCostAcc 是一个字典,包含训练过程中的各种指标(如损失和准确率)
参数:
dictCostAcc
一个字典,包含训练过程中的数据。
键是指标名称(如 ‘iteration’、‘iter_cost’ 等),值是对应的数值列表
xlabel
X 轴的标签(如 ‘iteration’ 或 ‘epoch’)。
两个 Y 轴的指标名称(如 ‘iter_cost’ 和 ‘iter_acc’)。
draw_train_process()
功能
绘制整个训练过程的指标变化,包括:
每个迭代的损失和准确率。
每个 epoch 的训练和测试损失。
每个 epoch 的训练和测试准确率。
使用 matplotlib 的子图功能,将三个指标绘制在同一张图中。
5 训练
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
# 记录迭代过程中,每一个epoch的平均cost与accuracy
epoch_train_costs = []
epoch_test_costs = []
epoch_train_accs = []
epoch_test_accs = []train_reader, test_reader = createDataReader(BATCH_SIZE)if not os.path.exists(model_save_dir):os.makedirs(model_save_dir)print('开始训练...')
for pass_id in range(TRAIN_NUM):# train_reader, test_reader = createDataReader(BATCH_SIZE)print("epoch %d -------------" % pass_id)train_accs = [] #训练的损失值train_costs = [] #训练的准确率for batch_id, data in enumerate(train_reader()): #遍历train_reader的迭代器,并为数据加上索引batch_idtrain_cost, train_acc = exe.run(program=fluid.default_main_program(), #运行主程序feed=feeder.feed(data), #喂入一个batch的数据fetch_list=[avg_cost, acc]) #fetch均方误差和准确率all_train_iter=all_train_iter+BATCH_SIZEall_train_iters.append(all_train_iter)all_train_costs.append(train_cost[0])all_train_accs.append(train_acc[0])train_costs.append(train_cost[0])train_accs.append(train_acc[0])if batch_id % 50 == 0: #每10次batch打印一次训练、进行一次测试print("\tPass %d, Step %d, Cost %f, Acc %f" % (pass_id, batch_id, train_cost[0], train_acc[0]))epoch_train_costs.append(sum(train_costs) / len(train_costs)) #每个epoch的costepoch_train_accs.append(sum(train_accs)/len(train_accs)) #每个epoch的accprint('\t\tTrain:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, epoch_train_costs[-1], epoch_train_accs[-1]))# 开始测试test_accs = [] #测试的损失值test_costs = [] #测试的准确率# 每训练一轮 进行一次测试for batch_id, data in enumerate(test_reader()): # 遍历test_readertest_cost, test_acc = exe.run(program=test_program, # #运行测试主程序feed=feeder.feed(data), #喂入一个batch的数据fetch_list=[avg_cost, acc]) #fetch均方误差、准确率test_accs.append(test_acc[0]) #记录每个batch的误差test_costs.append(test_cost[0]) #记录每个batch的准确率epoch_test_costs.append(sum(test_costs) / len(test_costs))epoch_test_accs.append(sum(test_accs) / len(test_accs))print('\t\tTest:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, epoch_test_costs[-1], epoch_test_accs[-1]))if pass_id < 3:continueelse:dictCostAcc = {}dictCostAcc['iteration'] = all_train_itersdictCostAcc['iter_cost'] = all_train_costsdictCostAcc['iter_acc'] = all_train_accsdictCostAcc['epoch'] = list(range(pass_id+1))dictCostAcc['cost_train'] = epoch_train_costsdictCostAcc['cost_test'] = epoch_test_costsdictCostAcc['acc_train'] = epoch_train_accsdictCostAcc['acc_test'] = epoch_test_accsdraw_train_process(pass_id, dictCostAcc)# draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc","iter",'cost/acc')print('\n')if pass_id % 5 == 0:# 每5个epoch保存一个模型model_dir = os.path.join(model_save_dir,str(pass_id))if not os.path.exists(model_dir):os.makedirs(model_dir)fluid.io.save_inference_model(model_dir, ['image'], [predict], exe)print('第%d个epoch的训练模型保存完成!'%pass_id)
1 变量初始化
all_train_iter = 0
all_train_iters = []
all_train_costs = []
all_train_accs = []
epoch_train_costs = []
epoch_test_costs = []
epoch_train_accs = []
epoch_test_accs = []
功能:初始化变量,用于记录训练和测试过程中的损失和准确率。
变量说明:
all_train_iter:记录总的迭代次数。
all_train_iters:记录所有训练迭代的索引(累积的 batch 数)。
all_train_costs:记录每个 batch 的训练损失。
all_train_accs:记录每个 batch 的训练准确率。
epoch_train_costs:记录每个 epoch 的平均训练损失。
epoch_test_costs:记录每个 epoch 的平均测试损失。
epoch_train_accs:记录每个 epoch 的平均训练准确率。
epoch_test_accs:记录每个 epoch 的平均测试准确率。
2 数据读取器
train_reader, test_reader = createDataReader(BATCH_SIZE)
功能:创建训练和测试数据读取器。
createDataReader(BATCH_SIZE):
自定义函数,返回训练和测试数据的迭代器。
BATCH_SIZE:每个 batch 的样本数量。
3. 模型保存目录
if not os.path.exists(model_save_dir):os.makedirs(model_save_dir)功能:检查模型保存目录是否存在,如果不存在则创建。 model_save_dir:模型保存的路径。
4. 训练过程
for pass_id in range(TRAIN_NUM):print("epoch %d -------------" % pass_id)train_accs = []train_costs = []
功能:开始训练过程,TRAIN_NUM 是总的训练轮数(epoch)。
变量说明:
pass_id:当前是第几个 epoch。
train_accs:记录当前 epoch 的所有 batch 的训练准确率。
train_costs:记录当前 epoch 的所有 batch 的训练损失。
4.1 遍历训练数据
for batch_id, data in enumerate(train_reader()):train_cost, train_acc = exe.run(program=fluid.default_main_program(),feed=feeder.feed(data),fetch_list=[avg_cost, acc])
功能:遍历训练数据读取器,逐 batch 进行训练。
train_reader():
返回训练数据的迭代器,每次迭代返回一个 batch 的数据。
exe.run:
运行主程序,执行前向传播和反向传播。
program=fluid.default_main_program():指定运行的程序。
feed=feeder.feed(data):将当前 batch 的数据喂入模型。
fetch_list=[avg_cost, acc]:获取训练的损失和准确率。
train_cost 和 train_acc:
train_cost:当前 batch 的训练损失。
train_acc:当前 batch 的训练准确率。
4.2 记录训练数据
all_train_iter += BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
train_costs.append(train_cost[0])
train_accs.append(train_acc[0])
功能:记录每个 batch 的训练数据。
all_train_iter:累积迭代次数,每次增加一个 batch 的样本数(BATCH_SIZE)。
all_train_iters:记录总的迭代次数。
all_train_costs 和 all_train_accs:记录所有 batch 的训练损失和准确率。
train_costs 和 train_accs:记录当前 epoch 的所有 batch 的训练损失和准确率。
4.3 打印训练信息
if batch_id % 50 == 0:print("\tPass %d, Step %d, Cost %f, Acc %f" % (pass_id, batch_id, train_cost[0], train_acc[0]))
功能:每 50 个 batch 打印一次训练信息。
打印内容:
当前 epoch (pass_id)。
当前 batch 的索引 (batch_id)。
当前 batch 的训练损失 (train_cost[0])。
当前 batch 的训练准确率 (train_acc[0])。
4.4 计算并记录每个 epoch 的平均损失和准确率
epoch_train_costs.append(sum(train_costs) / len(train_costs))
epoch_train_accs.append(sum(train_accs) / len(train_accs))
功能:计算当前 epoch 的平均训练损失和准确率,并记录下来。
5. 测试过程
for batch_id, data in enumerate(test_reader()):test_cost, test_acc = exe.run(program=test_program,feed=feeder.feed(data),fetch_list=[avg_cost, acc])test_accs.append(test_acc[0])test_costs.append(test_cost[0])
功能:遍历测试数据读取器,逐 batch 进行测试。
test_reader():返回测试数据的迭代器,每次迭代返回一个 batch 的数据。
exe.run:运行测试程序,获取测试的损失和准确率。
test_cost 和 test_acc:当前 batch 的测试损失和准确率。
test_costs 和 test_accs:记录所有 batch 的测试损失和准确率。
5.1 计算并记录每个 epoch 的平均测试损失和准确率
epoch_test_costs.append(sum(test_costs) / len(test_costs))
epoch_test_accs.append(sum(test_accs) / len(test_accs))
功能:计算当前 epoch 的平均测试损失和准确率,并记录下来。
6 打印训练和测试信息
print('\t\tTrain:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, epoch_train_costs[-1], epoch_train_accs[-1]))
print('\t\tTest:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, epoch_test_costs[-1], epoch_test_accs[-1]))
功能:打印当前 epoch 的平均训练损失和准确率,以及测试损失和准确率。
7. 可视化训练过程
if pass_id < 3:continue
else:dictCostAcc = {'iteration': all_train_iters,'iter_cost': all_train_costs,'iter_acc': all_train_accs,'epoch': list(range(pass_id+1)),'cost_train': epoch_train_costs,'cost_test': epoch_test_costs,'acc_train': epoch_train_accs,'acc_test': epoch_test_accs}draw_train_process(pass_id, dictCostAcc)
功能:从第 4 个 epoch 开始,定期可视化训练过程。
dictCostAcc:
构造一个字典,包含训练和测试的所有数据。
键值对:
‘iteration’:总的迭代次数。
‘iter_cost’:每个 batch 的训练损失。
‘iter_acc’:每个 batch 的训练准确率。
‘epoch’:当前的 epoch 数。
‘cost_train’:每个 epoch 的平均训练损失。
‘cost_test’:每个 epoch 的平均测试损失。
‘acc_train’:每个 epoch 的平均训练准确率。
‘acc_test’:每个 epoch 的平均测试准确率。
2.draw_train_process:
调用可视化函数,绘制训练过程的曲线。
8. 定期保存模型
if pass_id % 5 == 0:model_dir = os.path.join(model_save_dir, str(pass_id))if not os.path.exists(model_dir):os.makedirs(model_dir)fluid.io.save_inference_model(model_dir, ['image'], [predict], exe)print('第%d个epoch的训练模型保存完成!' % pass_id)
功能:每 5 个 epoch 保存一次模型。
model_dir:
模型保存的路径,包含当前 epoch 的编号。
fluid.io.save_inference_model:
保存推理模型,供后续推理使用。
参数:
model_dir:模型保存的路径。
[‘image’]:输入数据的名称。
[predict]:需要保存的模型变量。
exe:执行器。
打印信息:
打印模型保存完成的提示。
6 预测+结果
def createInfer():global USE_CUDAplace = fluid.CUDAPlace(0) if USE_CUDA else fluid.CPUPlace()infer_exe = fluid.Executor(place)inference_scope = fluid.core.Scope()return infer_exe, inference_scopedef load_image(path):global IMG_H, IMG_Wimg = paddle.dataset.image.load_and_transform(path,IMG_H,IMG_W, False).astype('float32')img = img / 255.0 img = np.expand_dims(img, axis=0)return imgdef getClassList(path):with open(path,'r') as load_f:new_dict = json.load(load_f)return new_dict['all_class_name']def predImgs(pathImgList, optimalEpoch):pred_label_list = []pred_class_list = []modelpath = os.path.join(model_save_dir, str(optimalEpoch))for pathImg in pathImgList:infer_exe, inference_scope = createInfer()with fluid.scope_guard(inference_scope):#从指定目录中加载 推理model(inference model)[inference_program, # 预测用的programfeed_target_names, # 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。 fetch_targets] = fluid.io.load_inference_model(modelpath,#fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。infer_exe) #infer_exe: 运行 inference model的 executorimg = Image.open(pathImg)plt.imshow(img) plt.show() img = load_image(pathImg)results = infer_exe.run(inference_program, #运行预测程序feed={feed_target_names[0]: img}, #喂入要预测的imgfetch_list=fetch_targets) #得到推测结果# print('results',results)# print('results[0]',np.argmax(results[0]))label_list = getClassList(os.path.join(dataRootPath,'readme.json'))pred_label = np.argmax(results[0])pred_class = label_list[np.argmax(results[0])]print("infer results: %s" % label_list[np.argmax(results[0])])pred_label_list.append(pred_label)pred_class_list.append(pred_class)return pred_label_list, pred_class_listpathcat = 'data/test/100.jpg'
pathdog = 'data/test/1000.jpg'
predImgList = ['data/test/'+str(x)+'.jpg' for x in range(1,29)]
predImgs(predImgList,95)
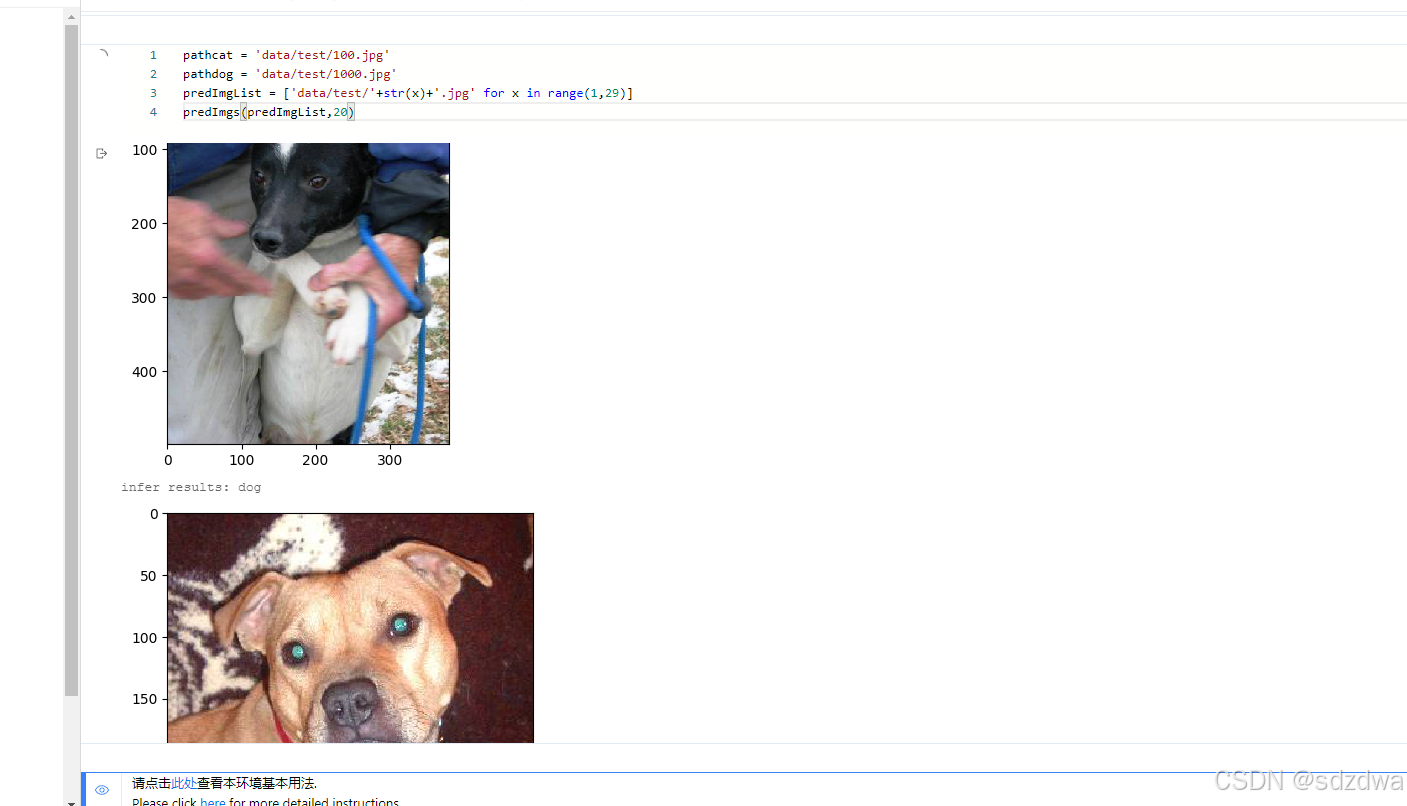
训练时候的图像:


好啦基本的就介绍到这里啦!!!
相关文章:
飞浆PaddlePaddle 猫狗数据大战
猫狗数据大战 1 数据集的准备以及处理操作1.1 数据集1.2 文件解压操作(python) 1.3 数据的分类1.4 创建训练集和测试集 2 网络构建CNN版本--DeepID 人脸识别网络结构DeepID 与 CNN 网络结构的差异 3 深度学习模型训练和推理的核心设置4 制图5 训练6 预测…...

嵌入式硬件篇---JSON通信以及解析
文章目录 前言一、JSON特点语法简单数据格式灵活轻量化跨语言使用二、JSON数据结构对象数组三、JSON在单片机之间通信的应用数据封装与传输四、JSON示例代码五、JSON在上位机与单片机之间通信的应用数据交互六、JSON示例代码七、JSON解析与生成解析生成八、Python中的数据解析1…...

递归典例---汉诺塔
https://ybt.ssoier.cn/problem_show.php?pid1205 #include<bits/stdc.h> #define endl \n #define pii pair<int,int>using namespace std; using ll long long;void move(int n,char a,char b,char c) // n 个盘子,通过 b,从 a 移动到 …...

使用高德api实现天气查询
创建应用获取 Key 天气查询-基础 API 文档-开发指南-Web服务 API | 高德地图API 代码编写 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-wid…...

蓝桥云客-修建灌木
1.修剪灌木 - 蓝桥云课 修剪灌木 问题描述 爱丽丝要完成一项修剪灌木的工作。 有 N 棵灌木整齐的从左到右排成一排。爱丽丝在每天傍晚会修剪一棵灌木,让灌木的高度变为0厘米。爱丽丝修剪灌木的顺序是从最左侧的灌木开始,每天向右修剪一棵灌木。当修剪…...
用于将笛卡尔坐标(x, y)转换为极坐标(magnitude, angle)函数cartToPolar())
OpenCV 图形API(7)用于将笛卡尔坐标(x, y)转换为极坐标(magnitude, angle)函数cartToPolar()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 计算二维向量的大小和角度。 cartToPolar 函数计算每个二维向量 (x(I), y(I)) 的大小、角度,或同时计算两者: magnitude…...
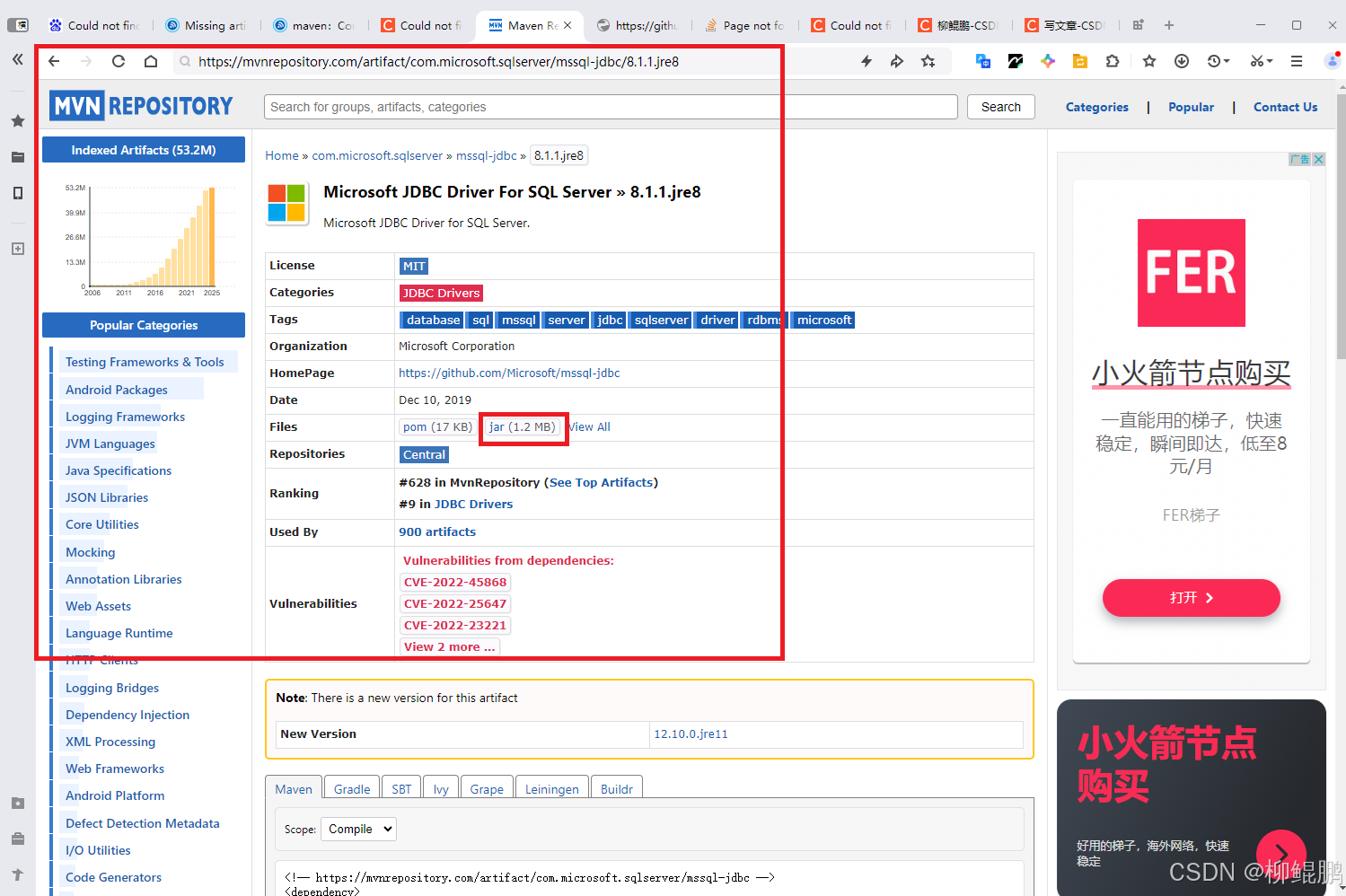
Could not find artifact com.microsoft.sqlserver:sqljdbc4:jar:4.0 in central
具体错误 [ERROR] Failed to execute goal on project datalink-resource: Could not resolve dependencies for project com.leon.datalink:datalink-resource:jar:1.0.0: Could not find artifact com.microsoft.sqlserver:sqljdbc4:jar:4.0 in central (https://repo.maven…...
Express学习笔记(三)——使用 Express 写接口
目录 1. 创建基本的服务器 2. 创建 API 路由模块 3. 编写 GET 接口 4. 编写 POST 接口 5. CORS 跨域资源共享 5.1 接口的跨域问题 5.2 使用 cors 中间件解决跨域问题 5.3 什么是 CORS 5.4 CORS 的注意事项 5.5 CORS 响应头部 - Access-Control-Allow-Origin 5.6 COR…...

透视飞鹤2024财报:如何打赢奶粉罐里的科技战?
去年乳制品行业压力还是不小的,尼尔森IQ指出2024年国内乳品市场仍处在收缩区间。但是,总有龙头能抗住压力,飞鹤最近交出的2024财报中就有很多亮点。 比如,2024年飞鹤营收207.5亿元、同比增长6%,净利润36.5亿元&#x…...
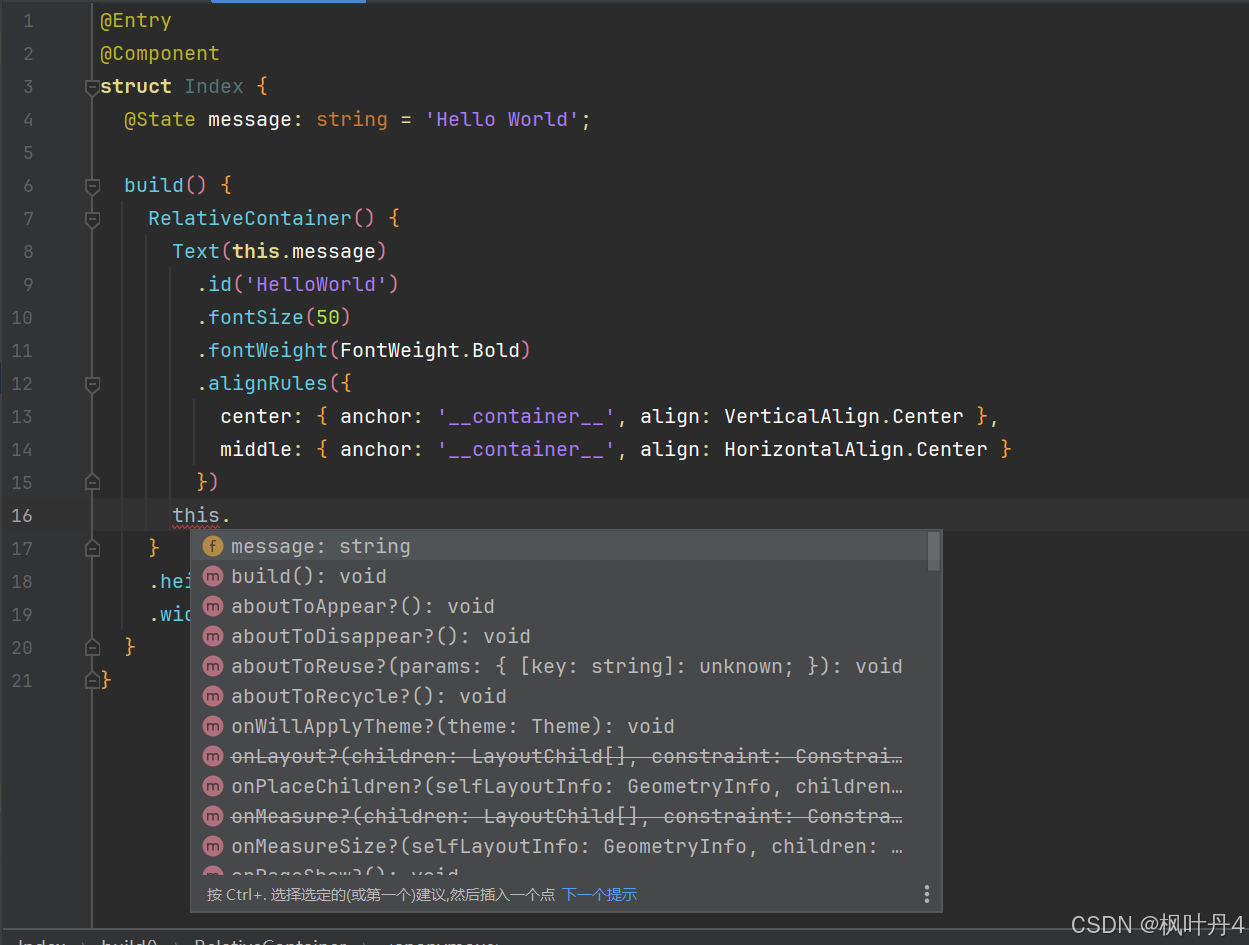
【HarmonyOS Next之旅】DevEco Studio使用指南(十)
目录 1 -> Optimize Imports功能 2 -> 父/子类快速跳转 3 -> 查看接口/类的层次结构 4 -> 代码自动补全 1 -> Optimize Imports功能 使用编辑器提供的Optimize Imports,可以快速清除未使用的import,并根据设置的规则对import进行合并…...

数据框的添加
在地图制图中,地图全图显示的同时希望也能够显示局部放大图,以方便查看地物空间位置的同时,也能查看地物具体的相对位置。例如,在一个名为airport的数据集全图制图过程中,希望能附上机场区域范围的局部地图,…...

java并发编程-并发容器
并发容器 CopyOnWriteArrayListCopyOnWriteArraySetConcurrentHashMapConcurrentSkipListMap迭代器的fail-fast与fail-safe机制应用场景 CopyOnWriteArrayList 线程不安全容器:ArrayList代替Vector、synchronizedList适用于读多写少的场景,对读操作不加…...

【3.软件工程】3.2 瀑布模型
瀑布模型全解析:从理论到实践的经典软件开发框架 🌊 一、瀑布模型核心流程图 #mermaid-svg-87uBSLYlWEdrgikJ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-87uBSLYlWEdrgikJ .error-icon{…...

使用 PyTorch 的 `torch.rot90` 进行张量旋转:数据增强的利器
使用 PyTorch 的 torch.rot90 进行张量旋转:数据增强的利器 在深度学习和计算机视觉领域,数据增强是一项至关重要的技术。通过对训练数据进行各种变换,如旋转、翻转、裁剪等,我们可以增加数据的多样性,从而提高模型的泛化能力。PyTorch 提供的 torch.rot90 函数是一个简单…...

数据一体化/数据集成对于企业数据架构的重要性
在数字化时代,企业的核心竞争力已经从传统的资源和规模优势转向数据驱动的智能化能力。数据一体化作为信息化发展的核心趋势,不仅是技术升级的必然选择,更是企业实现数字化转型的关键路径。 一、数据一体化/数据集成:数字化转型的…...
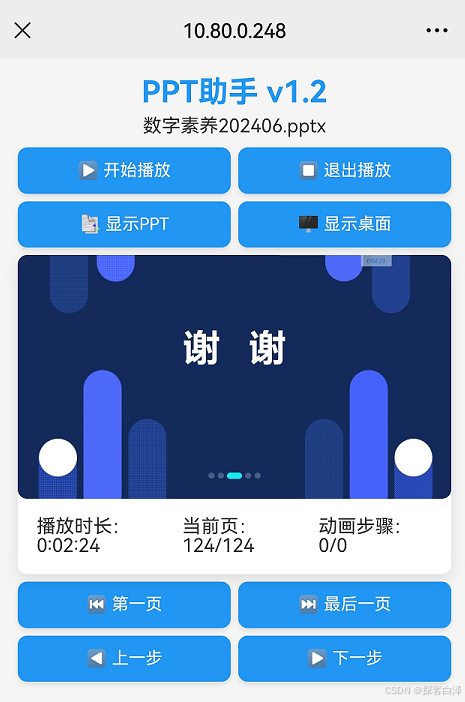
PPT助手:一款集计时、远程控制与多屏切换于一身的PPT辅助工具
PPT助手:一款集计时、远程控制与多屏切换于一身的PPT辅助工具 📝🎤 在现代化的演讲和演示中,如何高效地控制PPT进程、保证展示的流畅性与精准性,成为了每个演讲者必须面对的挑战。无论是商务汇报、学术演讲࿰…...

Oracle中的UNION原理
Oracle中的UNION操作用于合并多个SELECT语句的结果集,并自动去除重复行。其核心原理可分为以下几个步骤: 1. 执行各个子查询 每个SELECT语句独立执行,生成各自的结果集。 如果子查询包含过滤条件(如WHERE)、排序&…...

算法设计学习7
实验目的及要求: 目标是通过实验深入理解堆栈(Stack)和队列(Queue)这两种常见的数据结构,掌握它们的基本操作及应用场景,提高对数据结构的认识和应用能力。通过本实验,学生将深化对堆…...

AF3 OpenFoldDataset类解读
AlphaFold3 data_modules 模块的 OpenFoldDataset 类是一个自定义的数据集类,继承自 torch.utils.data.Dataset。它的目的是在训练时实现 随机过滤器(stochastic filters),用于从多个不同的数据集(OpenFoldSingleDataset 或 OpenFoldSingleMultimerDataset)中进行样本选择…...
Hive数仓三大核心特性解剖:面向主题性、集成性、非易失性如何重塑企业数据价值?)
大数据(4)Hive数仓三大核心特性解剖:面向主题性、集成性、非易失性如何重塑企业数据价值?
目录 背景:企业数据治理的困境与破局一、Hive数据仓库核心特性深度解析1. 面向主题性(Subject-Oriented):从业务视角重构数据2. 集成性(Integrated):打破数据孤岛的统一视图3. 非易失…...

AI模拟了一场5亿年的进化
蛋白质是生命的基石。从驱动肌肉运动的分子引擎,到捕捉光能的光合作用机器,再到细胞内的信息处理系统,这些功能复杂的分子贯穿了生命的每一个环节。尽管科学界早已解析了蛋白质的化学结构,但蛋白质的设计逻辑于人类而言࿰…...
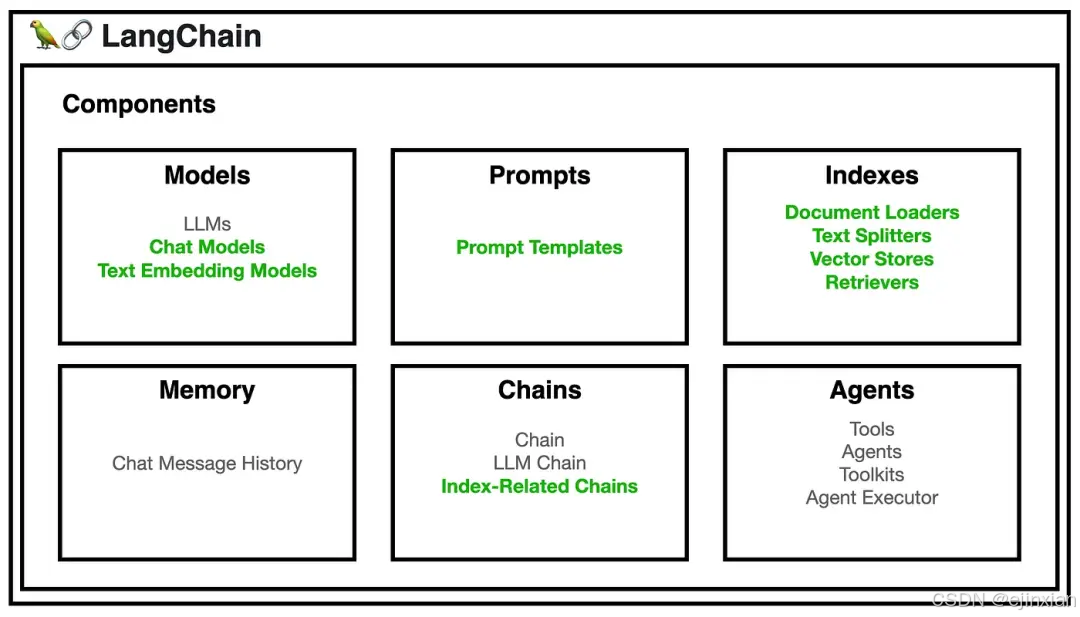
大模型应用初学指南
随着人工智能技术的快速发展,检索增强生成(RAG)作为一种结合检索与生成的创新技术,正在重新定义信息检索的方式,RAG 的核心原理及其在实际应用中的挑战与解决方案,通用大模型在知识局限性、幻觉问题和数据安…...

如何通过管理系统提升团队协作效率
在现代企业管理中,团队协作效率的高低直接关系到企业的竞争力和运营效率。随着信息技术的不断发展,管理系统作为提升团队协作效率的重要工具,逐渐受到企业的重视。本文将深入探讨如何通过管理系统提升团队协作效率,为企业提供实用…...

云手机如何防止设备指纹被篡改
云手机如何防止设备指纹被篡改 云手机作为虚拟化设备,其设备指纹的防篡改能力直接关系到账户安全、反欺诈和隐私保护。以下以亚矩阵云手机为例,讲解云手机防止设备指纹被篡改的核心技术及实现方式: 系统层加固:硬件级安全防护 1…...

XT1870 同步升压 DC-DC 变换器
1、 产品概述 XT1870 系列产品是一款低功耗、高效率、低纹波、工 作频率高的 PFM 控制升压 DC-DC 变换器。 XT1870 系列产品仅需要 3 个外部元器 , 即可完成低输 入的电池电压输入。 2、用途 数码相机、电子词典 LED 手电筒、 LED 灯 血压计、MP3 、遥控玩具 …...
、1、sentinel介绍、安装及初始化服务监控)
Sentinel实战(一)、1、sentinel介绍、安装及初始化服务监控
spring cloud Alibaba -Sentinel、sentinel介绍、安装及初始化服务监控 一、Sentinel简单了解一)、Sentinel基本概念二)、Sentinel设计理念1、流量控制2、熔断降级1)、什么是熔断降级2)、熔断降级的设计理念3、系统负载保护三)、Sentinel工作机制二、Sentinel服务安装一)…...

如何重构前端项目
重构前端项目是指对现有的前端代码进行重新设计和改造,以提高代码质量、可维护性、可扩展性和性能。 重构前端项目的一般步骤: 1.评估项目: 了解项目的规模、复杂度、技术栈和现有的问题和挑战,以及重构的目标和范围。 2.制定计划: 制定一个详细的计划…...

seaweedfs分布式文件系统
seaweedfs https://github.com/seaweedfs/seaweedfs.git go mod tidy go -o bin ./… seaweed占不支持smb服务,只能用fuse的方式mount到本地文件系统 weed master 默认端口:9333,支持浏览器访问 weed volume 默认端口:8080 weed …...

Spring Boot后端开发全攻略:核心概念与实战指南
🧑 博主简介:CSDN博客专家、全栈领域优质创作者、高级开发工程师、高级信息系统项目管理师、系统架构师,数学与应用数学专业,10年以上多种混合语言开发经验,从事DICOM医学影像开发领域多年,熟悉DICOM协议及…...

PostgreSQL pg_repack 重新组织表并释放表空间
pg_repack pg_repack是 PostgreSQL 的一个扩展,它允许您从表和索引中删除膨胀,并可选择恢复聚集索引的物理顺序。与CLUSTER和VACUUM FULL不同,它可以在线工作,在处理过程中无需对已处理的表保持独占锁定。pg_repack 启动效率高&a…...