【c++深入系列】:类与对象详解(中)
🔥 本文专栏:c++
🌸作者主页:努力努力再努力wz



💪 今日博客励志语录:
不是因为看到希望才坚持,而是坚持了才能看到希望
那么上一篇博客我讲解了什么是类和对象以及类和对象是怎么定义的,那么本文就继续来补充类和对象的相关知识,那么废话不多说,让我们进入今天的正文
★★★ 本文前置知识:
类和对象(上)
看完本文,你会学到:
1、知道什么是构造函数以及如何运用以及其相关细节
2、知道什么是拷贝构造函数以及如何运用以及其相关细节
3、知道什么是析构函数以及如何运用以及其相关细节
4、知道什么是运算符重载函数以及如何运用以及其相关细节
构造函数
1.为什么要有构造函数以及构造函数是什么
那么对象本质上就是类中的成员变量的一个集合,那么创建一个对象其实就是为类中的成员变量分配空间,但是如果我们没有对对象中的成员变量的内容进行初始化的话,那么成员变量的值便是未定义或者说是随机值,那么我们通过对象来访问并且使用成员变量的话那么就会引发一系列的后果,所以对于对象中的成员变量的初始化是十分的重要
那么为了避免刚才的那种情况发生,那么我们可以在类中去定义一个初始化该类中的成员变量的成员函数来解决问题,那么则需要我们每次实例化出一个对象之后,手动的去调用该完成初始化的成员函数,但是就会有一个问题,也就是会有一些程序猿忘记手动调用该初始化函数,然后直接使用对象中的成员变量,那么假设对象中的成员变量中有指针,而我们没有初始化该对象中的成员变量,那么此时该指针就是野指针,那么解引用野指针就会引发段错误
所以在这样的场景下,构造函数便诞生了,那么构造函数本质上其实也是一个函数,只不过是一个特殊的函数,至于哪里特殊我会在下文说道,那么构造函数的作用无非也就是完成对于成员变量的初始化,但是跟我们的普通的成员函数相比,不同的是,当我们定义好一个类的时候,那么编译器会默认生成一个无参数的构造函数,那么当我们创建对象的时候,那么编译器会自动调用生成的无参数的构造函数来完成对成员变量的初始化,那么就不需要我们自己显示的定义初始化的成员函数以及手动调用该初始化的成员函数
2.构造函数怎么定义以及怎么用
那么我们从上文我们知道,编译器会默认为定义好的类生成一个无参的构造函数,那么每次实例化一个对象的同时,会自动的调用编该无参的构造函数,那么是不是意味着,我们可以不用自己定义构造函数,而是以后我们对象中成员变量的初始化工作全部交给编译器生成的无参的构造函数来完成了呢?
那么我先不急着给出结论,那么我们先来见一见编译器给的默认的构造函数的初始化的效果是怎么样的,那么这里我写一段简单的c++代码来实验,代码逻辑也很简单,就是定义了一个person类,然后实例化出一个person对象,我们通过调试看看实例化出的对象中各个成员变量的初始化的情况:
#include<iostream>
using namespace std;
class person
{
public:int age;char sex;char* name;void hello(){cout << "hello" << endl;}
};
int main()
{person a;return 0;
}

那么通过调试窗口我们可以看到对象中成员变量的初始化情况,发现其实编译器的默认生成的构造函数并没有
干什么事,此时实例化出的对象中的成员变量全部都是随机值,也就是未定义的,意味着此时编译器生成的无参的构造函数并没有做所谓的对成员变量的初始化工作
所以从上面的结果中,我们可以知道其实编译器生成的默认的无参的构造函数的初始化行为,其对于内置类型的成员变量不做任何处理,而对于自定义类型,那么则是调用该自定义类型的默认的无参的构造函数,所以我们要想完成对于对象中的资源的初始化任务,那么必然不能信任编译器默认生成的构造函数,而是得我们自定义构造函数
构造函数的定义
构造函数虽然名字带有函数两个字,但是它和成员函数以及普通函数的声明是不一样的,我们知道函数由三部分组成,分别是返回值以及函数名和参数列表,而对于构造函数来说,那么它没有返回值,而所谓的没有返回值不是说它的返回值是void,而是说它压根就没有返回值,并且它的函数名还得跟类名相同,那么这就是构造函数的声明,那么他是一个特殊的成员函数,那么声明好构造函数之后,那么构造函数体里面的内容就是我们自定义如何对成员变量的初始化行为
那么要注意的是一旦我们定义自己的构造函数,那么编译器就不在为我们提供默认的无参的构造函数了
其次是构造函数可以有参数列表并且它也支持函数的重载,因为要满足用户不同的初始化需求,所以我们可以在类中定义多个函数名相同但是参数列表不同的构造函数,而要注意的是,如果我们在类中只定义了带参数的构造函数,而没有定义不带参数的构造函数的话,由于我们一旦定义了自己的构造函数,那么编译器便不再为我们提供默认不带参数的构造函数,而构造函数的调用的时机是在实例化创建出对象的那一刻被调用的,所以此时我们创建对象的时候,就一定要显示的手动调用构造函数
那么我还是写一份简单的代码来熟悉一下我们自定义的构造函数:
那么我们用类来实现一个栈,采取的是用动态数组的方式,那么其中该类就包含三个成员变量,分别是一个指针用来指向在堆上动态开辟的数组的首元素的地址以及一个int类型的top变量用来跟踪栈顶元素以及一个maxszie来记录目前栈的最大的容量,那么接下来,我们可以实现一个带参数的构造函数来初始化我们的栈,其中就包括开辟一个初始容量大小的一个数组以及初始化栈顶指针
#include<iostream>
#include<stdlib.h>
using namespace std;
class stack
{
public:int* ptr;int top;int maxsize;stack(int deafult){ptr = (int*)malloc(deafult * sizeof(int));if (ptr == NULL){perror("malloc");return;}top = -1;maxsize = deafult;}void push(int x){if (top + 1 == maxsize){ptr = (int*)malloc(2 * maxsize * sizeof(int));if (ptr == NULL){perror("malloc");return;}maxsize = 2 * maxsize;}ptr[++top] = x;}void pop(){if (top == -1){return;}top--;}void print(){for (int i = 0;i < maxsize;i++){cout << "stack[i]=" << ptr[i] << endl;}}
};
int main()
{stack a(4);a.push(1);a.push(2);a.push(3);a.push(4);a.print();return 0;
}

而我们这里在stack类中自定义了带参数的构造函数,而没有定义无参的构造函数,那么实例化对象的时候,如果我们不传递参数的话,那么编译器就会报错:
#include<iostream>
#include<stdlib.h>
using namesapce std;
class stack
{........
}
int main()
{stack a;a.push(1);a.push(2);a.push(3);a.push(4);return 0;
}

所以如果我们没有自己定义无参的构造函数的话,那么意味着我们还要手动的去传参从而调用构造函数,那么这就和上文说的自己定义一个初始化函数,然后自己手动调用初始化函数没什么区别了,所以这里我们就一定要利用构造函数的重载,那么在类中既定义一个无参的构造函数同时定义带参的构造函数,那么这样我们就可以灵活的实现对象的初始化
比如在这里的栈中,那么如果说自己并不知道栈的具体容量该设置为多少合适,那么我们可以定义一个无参的构造函数,那么其中来初始化设置一个合适的值,那么在创建对象的时候,就不用传递任何参数,那么此时编译器会自动调用你定义的无参数的构造函数,而如果你知道栈的初始容量多大合适,那么你在实例化对象的时候,就显示的传参,那么编译器则会匹配调用对应的带参的构造函数
3.构造函数相关细节补充
那么我们知道了构造函数支持函数的重载来满足用户的不同的初始化需求,那么其中c++的构造函数还支持在声明的时候给参数缺省值,那么这里我们就要注意这样一种场景了,还是以栈为例,假设你在栈的类中定义了一个全缺省的构造函数以及一个无参的构造函数,那么这两个函数之间肯定满足函数重载,那么如果此时你想调用全缺省的构造函数,但是自己又不想传递任何参数,也就是说你想要调用全缺省的构造函数并且其中的所有参数的值都采用缺省值,那么此时你就面临一个问题,怎么调用这个全缺省的构造函数,那么其中就以栈的类为例:
class stack
{
public:.......stack(){ptr = (int*)malloc(2 * sizeof(int));if (ptr == NULL){perror("malloc");return;}top = -1;maxsize = 2;}stack(int deafult=4){ptr = (int*)malloc(deafult * sizeof(int));if (ptr == NULL){perror("malloc");return;}top = -1;maxsize = deafult;}........}
};
那么可能有的聪明的小伙伴采取的方式就是这样调用参数全部使用缺省值的全缺省的构造函数:
stack a();
还有的小伙伴可能认为就直接这样调用:
stack a;
那么对于你来说,你会选择怎样的方式呢?
那么我来公布一下正确答案,那么这两种方式都过不了编译,并且我们无法做到调用全部参数使用缺省值的全缺省的构造函数
那么对于第一种所谓的调用方式,也就是"stack a();",为什么做不到的原因是因为它会被解析为函数的声明而非调用构造,所以无法采取这种方式
而对于第二种来说,也就是"stcak a;"那么这里你不传任何参数,那么理论上是调用无参的构造函数,但是由于类中定义了一个全缺省的构造函数,那么此时这里编译器识别到全缺省的构造函数的参数列表也满足调用,那么也就是编译器既可以调用无参的构造函数也可以调用全缺省的构造函数,那么也会产生二义性问题
所以说结论就是类中定义带缺省值的构造函数,理论上可以设置全缺省的构造函数,但是就得在调用的时候注意只能显示的传递参数而不能不传参,所以建议有缺省值的构造函数还是设置为半缺省而不是全缺省
其次注意的是构造函数它只能被调用一次,也就是实例化对象的那一个时刻,那么编译器不会允许你在实例化对象之后仍然调用构造函数,那么之所以编译器禁止这样的行为也很好理解,所谓初始化,不就是在实化对象的那一刻来对其成员变量的内容给一个初始值避免未定义吗,所以之后再调用构造函数重新覆盖成员变量之前的内容是没有任何意义的,那么相信百分之99的程序猿是不会犯这么低级的错误的,那么这就是构造函数的全部内容
拷贝构造函数
那么上文我们知道了满足对象的初始化需求可以通过构造函数来实现,但是构造函数来实现对象的初始化只是其中的一个方式,那么另一个方式便是使用拷贝构造函数,所以拷贝构造函数的作用便是对对象进行初始化
1.拷贝构造函数是什么
那么拷贝构造函数从名字中带一个函数,所以拷贝构造函数也是一个函数,但是它也不同于成员函数以及普通的函数,因为它是构造函数的其中一个重载版本,那么从名字前面的拷贝,我们也能够大致猜出它实现初始化的原理:也就是通过一个拷贝一个已经初始化的对象来实现该对象的初始化。
2.拷贝构造函数的实现原理以及如何定义
那么我们知道了拷贝构造函数是构造函数的一个重载版本,那么它必然也是没有返回值,函数名和类名相同,并且编译器也会默认生成一个拷贝构造函数
那么拷贝构造函数的一个实现原理,就是其会获取到另一个已经初始化好的对象,然后将该对象中的成员变量给复制拷贝到未初始化的对象中的对应成员变量,那么编译器默认提供的拷贝构造函数的实现就是一个浅拷贝,那么所谓的浅拷贝就是只拷贝值,那么有的对象只需要浅拷贝即可初始化,但是有的对象就需要深拷贝,比如我们的栈就可以作为一个例子
那么我们知道栈的类中包含一个指针,那么其指向在堆上动态开辟的一个数组的首元素,那么如果我们是浅拷贝,也就是值的拷贝,那么假设现在有一个已经初始化好的对象b和一个未初始化的对象a,那么a对象就要拷贝复制b对象里面的内容,也那么浅拷贝就只是每一个成员变量的值给拷贝,那么也就意味着此时a对象中的指针ptr会和b中的指针指向同一块区域
那么指向同一块区域就会引发各种问题,那么如果此时a变量要压栈,那么它会通过指针访问到数组然后写入数据,那么由于a和b中的指针指向的是同样一块区域,那么a通过指针对其指向的空间进行访问以及修改,那么必然会影响b对象的数据,就会导致数据被重写或者覆盖的问题,其次当对象的生命周期结束,那么对象的资源会被清理以及回收,那么此时就会释放指针指向的那片空间,那么此时a和b都指向同一块空间,那么会导致那片空间被释放两次,所以在这个场景下,我们必然得自定义一个深拷贝的拷贝构造函数,而不是编译器默认提供的浅拷贝的拷贝构造函数
那么其中自定义的拷贝构造函数实现的一个逻辑就是重新在堆上申请一片空间,并且与初始化好的对象的指针指向相同的空间大小相同,然后将初始化好的对象的指针指向的空间给以字节为单位复制过来,那么就会涉及到调用memcpy函数,然后其他内置类型的成员变量就是直接复制值即可。
而拷贝构造函数是构造函数的重载版本,那么它没有返回值,并且函数名和类名相同,但是对于拷贝构造函数的参数来说,那么此时就有两个选择:
A.传值
B.传引用
那么你会选择什么那个参数呢?
那么我还是以栈为例,写一段简单的代码,先来验证结果:
#include<iostream>
#include<stdlib.h>
#include<cstring>
using namespace std;
class stack
{......//传值stack(stack a){ptr = (int*)malloc(a.maxsize * sizeof(int));memcpy(ptr, a.ptr, a.maxsize*sizeof(int));top = a.top;maxsize = a.maxsize;}//传引用stack(stack& a){ptr = (int*)malloc(a.maxsize * sizeof(int));memccpy(ptr, a.ptr, 1, a.maxsize);top = a.top;maxsize = a.maxsize;}};
int main()
{stack a(2);a.push(1);a.push(2);a.print();cout<<"______"<<endl;stack b(a);b.print();return 0;
}
传值截图:

传引用截图:

那么根据结果,我们知道传引用是正确的,而传值是错误的,那么为什么传值是错误的呢?
由于不管是构造函数也好,还是所谓的拷贝构造函数也好,那么它们本质上其实都是函数,那么既然是函数,那么调用函数就必然得为该函数在栈上开辟一段空间,也就是创建一个函数栈帧,那么栈帧中会为函数中定义的局部变量以及形参分配空间,而创建完栈帧后的第一步便是将实参给拷贝赋值给形参,而形参是是自定义类型,并且它此时的状态是未被初始化,所以此时便会调用形参的拷贝构造函数来完成实参到形参的拷贝,而调用形参的拷贝构造函数,那么意味着又会开辟一个函数栈帧,并且此时的形参便作为该函数的实参,要拷贝到刚刚创建的函数栈帧的形参中,所以便会无限递归下去,编译器对此进行了严格的检查,那么编译阶段就会报错
而对于传引用它为什么对,就是因为引用相当于给变量取了一个别名,所以引用不需要值拷贝,便不会出现上面说的那种情况,所以这里自定义拷贝构造函数的时候,一定不能是传值
还要注意的是,我们学会了自定义拷贝构造函数,那么我们不要对于任意一个类都要自己实现一个拷贝构造函数,那么编译器默认生成的拷贝构造函数不像默认生成的无参的拷贝构造函数那样出工不出力,人家只是一个浅拷贝而已,所以不要不信任编译器默认生成的拷贝构造,如果说类中的成员变量全是内置类型,那么便没有必要自定义拷贝构造,用编译器的浅拷贝即可,但是如果是由指针这样的成员变量,那么必然就要我们自己实现深拷贝的拷贝构造函数
析构函数
1,为什么要有析构函数以及析构函数是什么
那么既然有对象的创建,那么必然就有对象的销毁,而我们知道对象的实例化是在函数中的,而函数的空间是在栈上开辟,那么其中在函数中定义的局部变量以及形参都会在函数的栈帧中分配空间,而对象是在函数内创建不管是在main函数还是在自己定义的func函数中,那么也就意味着对象的空间一定也函数的栈帧中,所以对象的生命周期就和他所处的函数的生命周期一样长,那么一旦函数调用结束,那么函数所在的栈帧就会被销毁,那片空间就会被操作系统给清理然后回收,而对象也会随着函数的栈帧一起被销毁
假设对象中的成员变量中假设有指针这样的成员变量,那么此时它如果被初始化指向了堆上申请开辟的一段连续的空间,那么这片空间就需要用户手动的去释放,而如果用户没有自己手动的释放,那么根据上文,对象随着函数栈帧一起被销毁,那么其中就包括成员变量,那么一旦销毁,我们就无法通过指针来找到堆上申请开辟的这段空间,从而无法释放导致内存泄漏问题,那么内存泄漏可不要小看,那么它是很严重的问题
所以为了解决上面的情况,那么就需要用户在类中定义一个清理对象中资源的destroy函数,那么有了destroy函数,那么就需要我们在对象被销毁前手动调用destroy函数,那么此时和上文构造函数诞生的背景一样,肯定有很多粗心的程序猿经常忘记自己去手动调用destroy函数,所以避免这种情况发生,那么便有了析构函数,那么析构函数作用就是清理对象中的资源,但是与普通的成员函数不同的是,在我们定义类的时候,编译器会默认为该类提供析构函数,那么对象被销毁之后,那么会自动调用析构函数来清理对象中的资源
2.析构函数怎么定义以及如何使用
那么析构函数和拷贝构造函数很相似,析构函数没有返回值,但是析构函数的函数名则是在类名前面加一个取反符"~",并且析构函数不允许设置参数,那不允许设置参数的原因其实也很容易想到,那么析构函数的作用就是清理对象中的资源,那么这里传一个参数的目的难道说还要在析构函数中使用成员变量吗,那么这不就和析构函数本身要完成的工作就相违背了吗,所以析构函数不需要参数
其次就是析构函数不支持重载,那么构造函数支持重载是因为用户有自己不同的初始化需求,比如有的成员变量的初始值可以自己设置然后其他交给缺省值或者说全部的成员变量的初始值都由自己来设置,而这里析构函数不存在所谓不同的资源清理方式这一说,所以很容易理解析构函数为什么不支持重载
并且一旦自定义了我们自己的析构函数,那么编译器便不会调用默认生成的析构函数了,而自定义析构函数的场景就是我们上文说的对象中的成员变量中含有指针,并且指向了堆上申请的一片空间,那么此时就需要我们自定义析构函数来释放掉指针指向的这片空间
那么栈依旧是一个很好的例子,那么此时就需要我们自定义析构函数:
class stack
{public:......~stack(){free(ptr);ptr=nullptr;}
};
而如果类中的成员变量全是内置类型,那么就没有必要定义析构函数了,直接调用编译器默认提供的析构函数即可
运算符重载函数
1.为什么要有运算符重载函数以及运算符重载函数是什么
在c++中,我们可以将数据大致分为两种类型,分别是内置类型以及自定义类型,而内置类型其中就包括int以及double类型的变量,而自定义类型就是我们通过类或者结构体实例化出的对象
而对于内置类型来说,那么当内置类型进行所谓的运算,比如进行算术运算以及逻辑运算或者位运算等等,那么内置类型的这些相关的运算,编译器是知道他们的运算规则是怎么样的,并且内部是由对应的指令来处理的,而对于自定义类型来说,它也可以进行所谓的算术运算以及逻辑运算等等,但是由于自定义类型是我们自己定义的,那么编译器是不知道自定义类型的具体的运算规则是怎么样的,所以我们就得告诉编译器该自定义类型的运算规则是什么,那么告诉的方式就是通过运算符重载函数来告诉编译器
2.运算符重载函数如何定义以及如何使用
运算重载函数本质上就是一个函数,那么既然是函数,那么它的声明必然由三部分所组成,分别是返回值以及函数名和参数列表,只不过对于运算符重载函数来说,那么它的函数名前面需要加一个operator关键字作为标识,那么函数体内部就是我们自定义该类型的一个运算规则以及运算逻辑
bool operator<(type& d1,type& d2)
{.....
}
知道了如何定义之后,我们再来说一下这里的定义的一些注意的细节:
1.首先我们运算符重载函数支持的运算符符号,比如+,-,*,<<等等,而其他不是运算符的符号不能进行重载比如@
2.不是所有的运算符都支持运算符重载函数,那么有5个运算符就不支持,分别是
.*
sizeof
::
? :
.
3.关于运算符重载函数的参数个数一定得满足该运算符所涉及到的操作数,比如+运算符,那么它涉及到的操作数为2,所以我们参数列表的个数只能是2,不能出现大于或者小于2个,而如果我们是定义在类中作为成员函数,那么成员函数会隐的传递一个this指针,所以成员函数在声明的时候,参数个数得少一个,而全局函数的个数则得满足运算符规定的操作数
所以现在我们可以写一个简单的代码来熟悉一下运算符重载函数:
那么我定义一个日期类,那么给类包含三个成员变量分别表示年和月以及天,那么其中我们重载一个比较日期的大于以及等于的运算符重载函数
#include<iostream>
using namespace std;
class date
{
public:int _year;int _day;int _month;date(int year, int month, int day){_year = year;_month = month;_day = day;}bool operator>(date& d1){if (_year > d1._year){return true;}else if (_year == d1._year){if (_month > d1._month){return true;}}else if (_month == d1._month){if (_day > d1._day){return true;}}return false;}bool operator==(date& d1){if (_year == d1._year && _month == d1._month && _day == d1._day){return true;}return false;}};
int main()
{date a(2025, 12, 3);date b(2025,12,18);if (a ==b){cout << "日期一样" << endl;}if (a > b){cout << "a is max" << endl;}else{cout << "b is max" << endl;}return 0;
}

3.运算符重载函数相关补充
我们知道我们可以在全局域定义运算符重载函数,也可以在类域中定义运算符重载函数,那么当编译器识别到我们编写的代码中涉及到了运算符的相关运算,并且该运算符涉及到的操作数中含有自定义类型,那么此时编译器就需要知道该自定义类型的运算规则,那么编译器就会有意识的去寻找对应匹配的运算符重载函数。
假设我们在全局域中以及对应的类中都定义了该运算符的重载函数,那么此时编译器会怎么调用呢,也就是编译器调用运算符重载函数的调用机制是什么呢?
那么如果说该运算符的左操作数是一个自定义类型,并且其对应的类中有匹配对应的运算符重载函数,那么编译器会优先调用类中定义的运算符重载函数,然后将左操作数的对象作为this指针指向的对象来传递进该成员函数中,但是现在就是有一个问题
假设有这样一个场景,比如a+b,假设a是自定义类型,那么此时a类中有对应匹配的运算符重载函数并且全局域中也有满足匹配的运算符重载函数,那么此时编译器会去调用哪一个运算符重载函数呢?
这就涉及到运算符重载函数的优先级了,还是以刚到的例子说明,a+b,那么其中a是自定义类型,那么此时如果a对象的类中定义了+的运算符重载函数并且全局函数也有对应的运算符重载函数,那么此时编译器手上会持有满足调用的不同的运算符重载函数,其中就包括成员函数以及全局函数,那么接下来编译器会从中筛选出最满足最匹配的运算符重载函数,那么首先它就分别检查这些候选函数的声明也就是参数列表谁更匹配,那么参数越匹配,那么意味着调用它的优先级就越高
那么我举一个例子:比如a是一个自定义类型type,而b是int类型,那么假设a对应的类中有对应的运算符重载函数,那么它的声明是这样的:
type operator+(double b)
那么首先假设全局域中没有对应的运算符重载函数,那么它会不会被调用呢?
那么答案是会的,因为这里虽然参数是double类型,但是编译器是会进行隐式类型转换,将实参传递给形参的过程中,会发生类型转化来匹配形参的类型,所以说它能够被调用,但是如果说你的类中还有另一个关于该运算符的重载函数:
type operator+(int b)
那么此时理论上来说,这两个运算重载函数都能够调用,但是只能选择其中一个来调用,那么编译器肯定会选择下面这个而不是上面这个,因为下面的参数更匹配,不需要经历类型转化,所以说上面的运算符重载函数的调用的优先级是低于下面的运算符重载函数的
这里的优先级针对的是候选函数,也就是理论上能够调用的运算符重载函数而不考虑那些参数都不匹配的运算符重载函数,那么编译器就会调用优先级最高的运算符重载函数,那么这里就会有一个坑
那么所谓的优先级最高的运算符重载函数,那么也就是它的参数列表符合代码中运算符涉及到的操作数类型,那么如果此时有全局域中的运算符重载函数的参数列表完全符合也就是没有发生所谓的隐式类型转换并且同时成员函数也同样满足这个情况,那么此时编译器就持有多个具有相同并且最高的优先级的函数,那么此时就会规定编译器优先调用成员函数而不是全局函数,但是要注意其中的二义性问题:
也就是成员函数的参数列表与全局函数的参数列表是一样的,那么编译器无法区分,就会产生二义性问题,比如:
#include<iostream>
using namespace std;
class date
{
public:........
bool operator>(date& d1)
{if (d0._year > d1._year){return true;}else if (d0._year == d1._year){if (d0._month > d1._month){return true;}}else if (d0._month == d1._month){if (d0._day > d1._day){return true;}}return false;
}
};
bool operator>( date& d0,date& d1)
{if (d0._year > d1._year){return true;}else if (d0._year == d1._year){if (d0._month > d1._month){return true;}}else if (d0._month == d1._month){if (d0._day > d1._day){return true;}}return false;
}
int main()
{date a(2025, 12, 3);date b(2025, 12, 18);if (a == b){cout << "日期一样" << endl;}if (a > b){cout << "a is max" << endl;}else{cout << "b is max" << endl;}return 0;
}

那么上面的代码中,对于成员函数来说,那么它会隐式的传递一个this指针,而由于引用底层是用指针来实现的,所以这里我们可以得到成员函数的参数列表是(date *,date * (date&)) ,而全局函数的参数列表则是(date * (date&), date *(date&)),那么他们的参数列表完全一样,那么就会引发二义性,编译器不知道调用哪一个,所以这里如果我修改一下参数,比如全局函数的参数,我将第一个参数设置为const date&,那么我们知道添加const之后,那么此时参数列表不同,那么编译器就优先调用成员函数,所以此时编译就能够通过了
所以这就是我们编译器调用运算符的一个机制
其次注意的j就是如果你的左操作数是内置类型,那么即使你的右操作数是自定义类型,并且类中有对应匹配的运算符重载函数,那么也不会调用,因为this只能绑定左操作数
结语
那么这就是本篇文章关于类和对象的介绍的全部内容了,那么类和对象的内容还有其他的各种玩法,那么这些内容就得放到下一期博客中讲解了,并且下一篇博客,我还会综合前面类和对象的所有知识来完成一个完整功能模块的类,那么我会持续更新,希望你多多关注,如果本文有帮组到你,还请三连加关注哦,你的支持就是我最大的动力!

相关文章:
【c++深入系列】:类与对象详解(中)
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 不是因为看到希望才坚持,而是坚持了才能看到希望 那么上一篇博客我讲解了什么是类和对象以及类和对象是怎么定义的࿰…...

解锁界面设计密码,打造极致用户体验
界面设计是对软件、网站、移动应用等产品的用户界面进行设计的过程,旨在为用户提供美观、易用、高效的交互体验。以下是关于界面设计的一些主要方面: 一、设计原则 用户中心原则:以用户为中心,了解用户的需求、期望、行为和习惯…...

用Python和Pygame创造粉色粒子爱心:3D渲染的艺术
引言 在计算机图形学中,3D效果的2D渲染是一个迷人的领域。今天,我将分享一个使用Python和Pygame库创建的粉色粒子爱心效果。这个项目不仅视觉效果惊艳,而且代码简洁易懂,非常适合图形编程初学者学习3D渲染的基础概念。 项目概述…...

汽车 HMI 设计的发展趋势与设计要点
一、汽车HMI设计的发展历程与现状 汽车人机交互界面(HMI)设计经历了从简单到复杂、从单一到多元的演变过程。2012年以前,汽车HMI主要依赖物理按键进行操作,交互方式较为单一。随着特斯拉Model S的推出,触控屏逐渐成为…...

《AI大模型应知应会100篇》第56篇:LangChain快速入门与应用示例
第56篇:LangChain快速入门与应用示例 前言 最近最火的肯定非Manus和OpenManus莫属,因为与传统AI工具仅提供信息不同,Manus能完成端到端的任务闭环。例如用户发送“筛选本月抖音爆款视频”,它会自动完成: 爬取平台数据…...
预览的vue组件库)
vue-office 支持预览多种文件(docx、excel、pdf、pptx)预览的vue组件库
官网地址:https://github.com/501351981/vue-office 支持多种文件(docx、excel、pdf、pptx)预览的vue组件库,支持vue2/3。也支持非Vue框架的预览。 1.在线预览word文件(以及本地上传预览) 1.1:下载组件库 npm inst…...

Java 大视界 -- Java 大数据在智能农业无人机植保作业路径规划与药效评估中的应用(165)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

哈希表系列一>两数之和
目录 题目:方法:暴力代码:优化后代码: 题目: 链接: link 方法: 暴力代码: public int[] twoSum(int[] nums, int target) {解法一:暴力解法:int n nums.length;for(int…...

【SPP】深入解析蓝牙 L2CAP 协议在SPP中的互操作性要求
在蓝牙协议体系中,L2CAP(Logical Link Control and Adaptation Protocol)作为基带协议与高层协议之间的桥梁,承担着数据分帧、协议复用、QoS协商等核心功能。当涉及串行端口通信时,L2CAP的规范实现直接决定了设备间数据传输的可靠性、效率及兼容性。本文基于《Serial Port…...

CAD插件实现:自动递增编号(前缀、后缀、位数等)——CADc#实现
cad中大量输入一定格式的递增编号时,可用插件实现,效果如下: ①本插件可指定数字位数、起始号码、加前缀、后缀、文字颜色等(字体样式和文字所在图层为cad当前图层和当前字体样式)。 ②插件采用Jig方式,即…...

Spring | Spring、Spring MVC 和 Spring Boot 的区别
关注:CodingTechWork 引言 在 Java 开发领域,Spring、Spring MVC 和 Spring Boot 是三个经常被提及的概念。它们之间既有联系又有区别,对于初学者来说可能会感到困惑。本文将详细介绍它们的区别,并通过示例代码帮助读者更好地理解…...

观察者模式在Java微服务间的使用
一.、使用RabbitMQ来实现 (1) 生产者(订单微服务) import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.stereotype.Service;Service public class OrderService {private final RabbitTemplate rabbitTemplate;…...

C语言--回文字符串
输入:字符串,判断是否是回文字符串,例如abcba输出Yes 输出:是否 代码 思路:使用两个指针分别指向头和尾,依次对比第一个元素和最后一个元素,第二个和倒数第二个元素,如果遇到不相同…...

【云计算物理网络】数据中心网络架构设计
云计算的物理基础:数据中心网络架构设计 一、技术背景:从“三层架构”到“云原生网络”二、技术特点:云数据中心网络的四大支柱三、技术细节:CLOS架构的实现挑战四、未来方向:从“连接设备”到“感知服务”结语&#x…...
Coco-AI 支持嵌入,让你的网站拥有 AI 搜索力
在之前的实践中,我们已经成功地把 Hexo、Hugo 等静态博客和 Coco-AI 检索系统打通了:只要完成向量化索引,就可以通过客户端问答界面实现基于内容的智能检索。 这一层已经很好用了,但总觉得少了点什么—— 比如用户还得专门打开一…...

批处理脚本的主要解析规则
批处理脚本的主要解析规则 批处理脚本(Batch files)有一套独特的解析规则,这些规则在很多情况下不太直观,但了解它们对于编写可靠的脚本至关重要。以下是最重要的一些规则: 1. 变量扩展规则 标准变量扩展 (%变量%) 解析时扩展:…...

TRDI 公司的RiverPro 和 RioPro ADCP 用户指南
TRDI 公司 RiverPro 和 RioPro ADCP 用户指南 简介第一章 - 概述第二章 - 安装第三章 - 采集数据第四章 - 维护第五章 - 测试RIVERPRO/RIOPRO第六章 - 故障排除第七章 - 将系统返回TRDI进行维修第八章 - 规格第九章 - 命令第十章 - 输出数据格式附录A-合规通知首次完整翻译《Ri…...

Linux 基础入门操作 前言 linux操作指令介绍
1 linux 目录介绍 Linux 文件系统采用层次化的目录结构,所有目录都从根目录 / 开始 1.1 核心目录 / (根目录) 整个文件系统的起点、包含所有其他目录和文件 /bin (基本命令二进制文件) 存放系统最基本的shell命令:如 ls, cp, mv, rm, cat 等&#…...

【总结】SQL注入防护手段
1、对提交的数据进行数据类型判断,比如id值必须是数字:is_numeric($id) 2、对提交的数据进行正则匹配,禁止出现注入语句,比如union、or、and等 3、对提交数据进行特殊符号转义,比如单引号、双引…...
OpenCV 图形API(11)对图像进行掩码操作的函数mask()
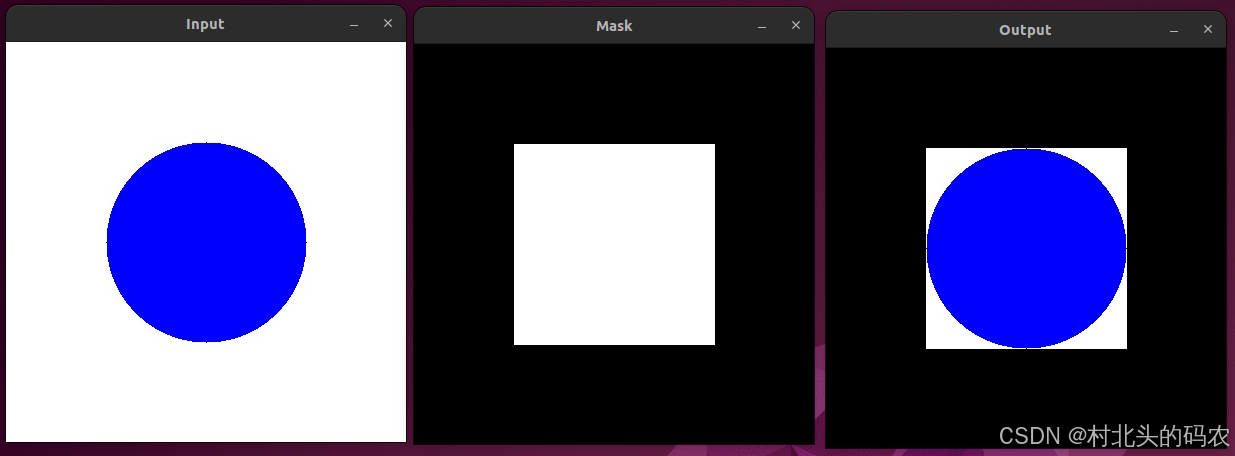
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 描述 对矩阵应用掩码。 该函数mask设置来自给定矩阵的值,如果掩码矩阵中对应的像素值设为true,否则将矩阵的值设为0。 支持的源矩阵…...
使用C#写的一个Kafka的使用工具
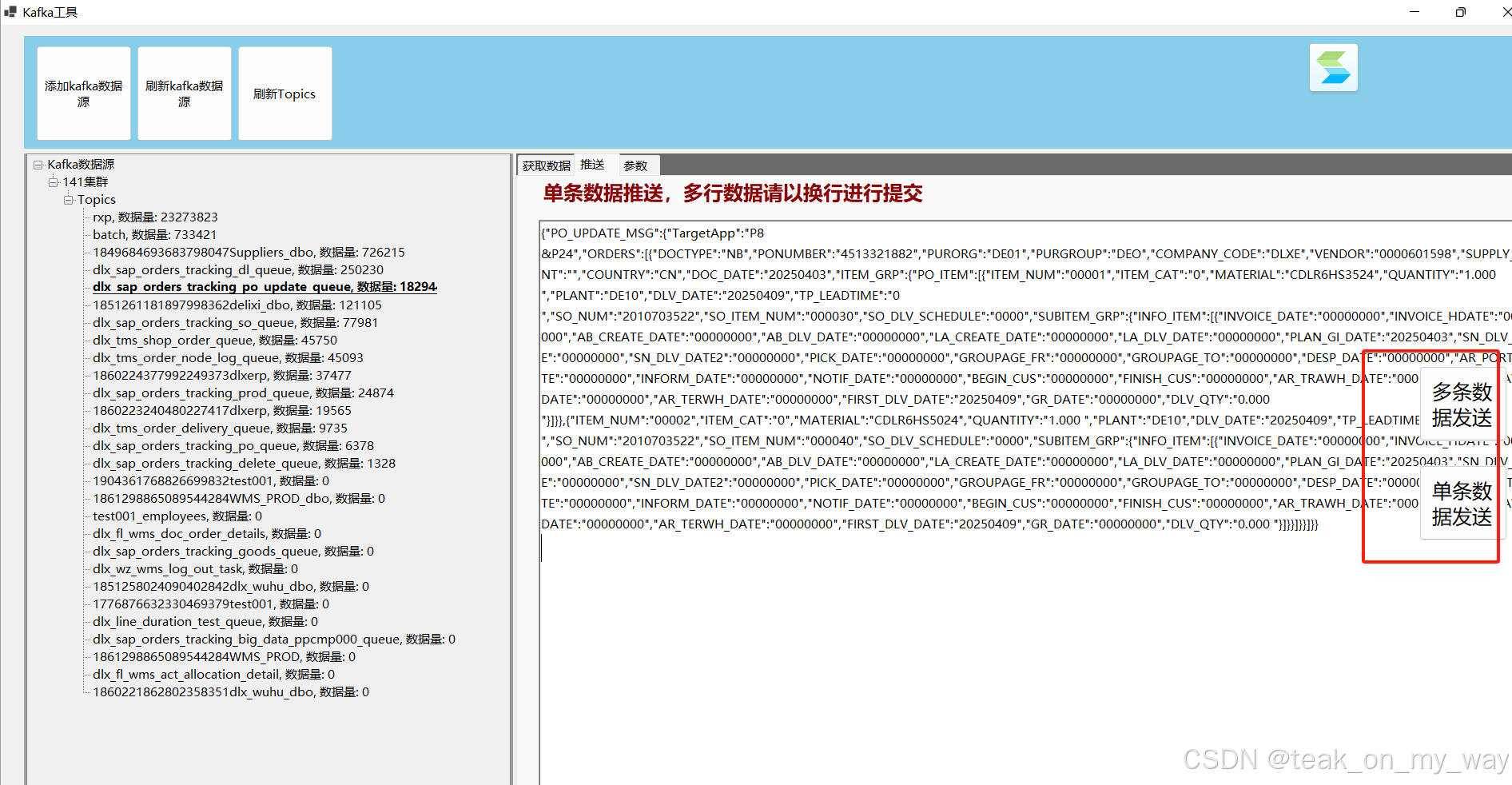
由于offset不支持通过界面推送数据,所以我写了一个kafka的连接工具,能够直接从界面推送数据,方便使用。由于使用的是C#写的,所以比offset要流畅的多。 1、数据源连接 2、获取集群的topic 3、点击获取数据能够获取最新的100条数…...

【通知】STM32MP157驱动开发课程全新升级!零基础入门嵌入式Linux驱动,掌握底层开发核心技能!
在嵌入式Linux系统开发中,驱动程序开发是一项关键技术,它作为硬件与软件之间的桥梁,实现了操作系统对硬件设备的控制。相较于嵌入式Linux应用开发,驱动开发由于涉及底层硬件且抽象程度较高,往往让初学者感到难度较大。…...

MCP协议java开发的servers,已开源
访问地址: mcp-server-java 已实现的filesystem提高性能和效率,比Python的操作更顺畅。java实现,让部署更容易。...
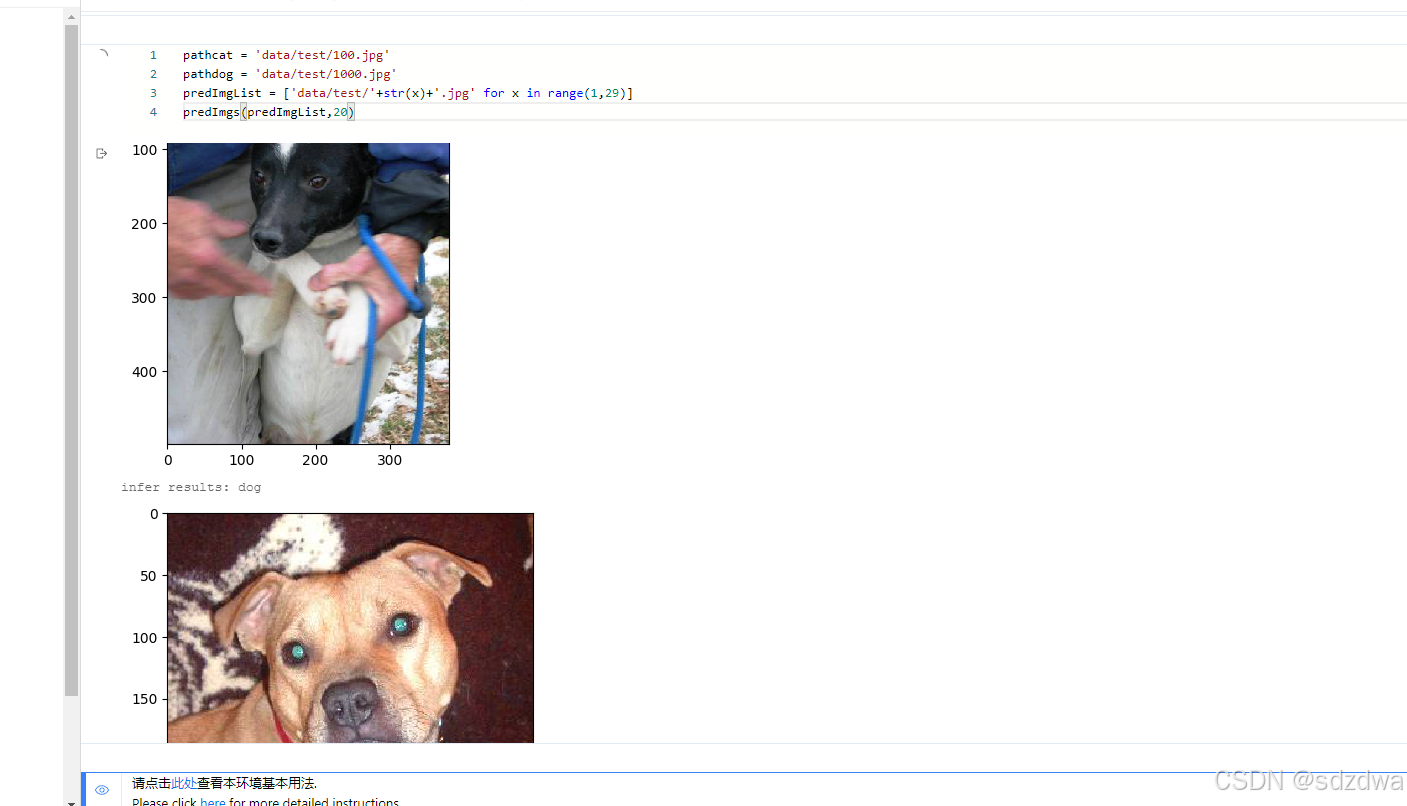
飞浆PaddlePaddle 猫狗数据大战
猫狗数据大战 1 数据集的准备以及处理操作1.1 数据集1.2 文件解压操作(python) 1.3 数据的分类1.4 创建训练集和测试集 2 网络构建CNN版本--DeepID 人脸识别网络结构DeepID 与 CNN 网络结构的差异 3 深度学习模型训练和推理的核心设置4 制图5 训练6 预测…...

嵌入式硬件篇---JSON通信以及解析
文章目录 前言一、JSON特点语法简单数据格式灵活轻量化跨语言使用二、JSON数据结构对象数组三、JSON在单片机之间通信的应用数据封装与传输四、JSON示例代码五、JSON在上位机与单片机之间通信的应用数据交互六、JSON示例代码七、JSON解析与生成解析生成八、Python中的数据解析1…...

递归典例---汉诺塔
https://ybt.ssoier.cn/problem_show.php?pid1205 #include<bits/stdc.h> #define endl \n #define pii pair<int,int>using namespace std; using ll long long;void move(int n,char a,char b,char c) // n 个盘子,通过 b,从 a 移动到 …...

使用高德api实现天气查询
创建应用获取 Key 天气查询-基础 API 文档-开发指南-Web服务 API | 高德地图API 代码编写 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-wid…...

蓝桥云客-修建灌木
1.修剪灌木 - 蓝桥云课 修剪灌木 问题描述 爱丽丝要完成一项修剪灌木的工作。 有 N 棵灌木整齐的从左到右排成一排。爱丽丝在每天傍晚会修剪一棵灌木,让灌木的高度变为0厘米。爱丽丝修剪灌木的顺序是从最左侧的灌木开始,每天向右修剪一棵灌木。当修剪…...
用于将笛卡尔坐标(x, y)转换为极坐标(magnitude, angle)函数cartToPolar())
OpenCV 图形API(7)用于将笛卡尔坐标(x, y)转换为极坐标(magnitude, angle)函数cartToPolar()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 计算二维向量的大小和角度。 cartToPolar 函数计算每个二维向量 (x(I), y(I)) 的大小、角度,或同时计算两者: magnitude…...
Could not find artifact com.microsoft.sqlserver:sqljdbc4:jar:4.0 in central
具体错误 [ERROR] Failed to execute goal on project datalink-resource: Could not resolve dependencies for project com.leon.datalink:datalink-resource:jar:1.0.0: Could not find artifact com.microsoft.sqlserver:sqljdbc4:jar:4.0 in central (https://repo.maven…...