PyTorch复现线性模型
【前言】
本专题为PyTorch专栏。从本专题开始,我将通过使用PyTorch编写基础神经网络,带领大家学习PyTorch。并顺便带领大家复习以下深度学习的知识。希望大家通过本专栏学习,更进一步了解人更智能这个领域。
材料来源:2.线性模型_哔哩哔哩_bilibili
PyTorch编写思路
对于大部分的神经网络模型,我们应该要有以下编写思路:
1.构建数据集
2.设计模型
3.构造损失函数和优化器
4.周期训练模型
5.测试模型
一、构建数据集
import torch
#torch.Tensor()用来创建张量,即创建矩阵
x_data=torch.Tensor([[1.0],[2.0],[3.0]])
y_data=torch.Tensor([[2.0],[4.0],[6.0]])这里为大家扩充一个知识点:
【张量】张量(Tensor)是 PyTorch 中最基本的数据结构,类似于 NumPy 中的数组,但张量可以利用 GPU 加速计算,这使得它非常适合用于深度学习任务。张量可以表示从标量(0 维张量)到向量(1 维张量)、矩阵(2 维张量)以及更高维度的数据。
二、设计模型
1.构造计算图
当你有了一个计算图之后,你将会加深对神经网络计算过程的理解,更加便于你构造神经网络模型

2.代码实现
class LinearModel(torch.nn.Module):"""定义了一个类,继承自PyTorch的torch.nn.Module模块.是 PyTorch 中所有神经网络模块的基类,所有自定义的模型都应该继承自这个类。""" def __init__(self):#是 PyTorch 中所有神经网络模块的基类,所有自定义的模型都应该继承自这个类。super(LinearModel,self).__init__()"""调用了父类 torch.nn.Module 的初始化方法。这是必要的,因为 torch.nn.Module 的初始化方法会进行一些内部的初始化操作,确保模型能够正常工作。"""self.linear=torch.nn.Linear(1,1)#创建了一个线性层#第一个参数为输入特征的数量。即输入张量的最后一个维度的大小。#第二个参数为输出特征的数量。即输出张量的最后一个维度的大小。#定义了一个前向传播def forward(self,x):y_pred=self.linear(x)return y_pred#类实例化
model=LinearModel()代码中的注释很详细,大家仔细看一下。
三、构造损失函数和优化器
#方差损失函数
criterion=torch.nn.MSELoss(size_average=False)
#优化器optim.SGD()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)1.【方差损失函数】
顾名思义,这种损失函数计算的是预测值与真实值的平方差。计算公式如下:
后面我们会讲到其他损失函数,如下一节课我们将要讲到的“交叉熵损失函数”
2.【优化器SGD】
torch.optim.SGD 是 PyTorch 中实现随机梯度下降优化算法的类。
SGD 是一种常用的优化算法,用于在训练过程中更新模型的参数,以最小化损失函数。
四、周期训练模型
我们定周期为100,并打印周期内的方差损失函数的损失值
for epoch in range(100):#前向传播y_pred=model(x_data)#计算预测值Y hatloss=criterion(y_pred,y_data)#损失函数print(epoch,loss)optimizer.zero_grad()loss.backward()#后向传播optimizer.step()#参数更新
1.loss.backward()的作用在 PyTorch 中,
loss.backward()方法实现了反向传播算法。当调用loss.backward()时,它会:
计算梯度:自动计算损失函数关于所有模型参数的梯度。
累加梯度:将计算得到的梯度累加到每个参数的
.grad属性中。
2.optimizer.zero_grad():
在每次反向传播之前,需要清空之前的梯度。这是因为 PyTorch 的梯度是累加的,不清空会导致梯度错误地累加。
这一步确保每次计算的梯度是当前批次的梯度,而不是之前批次的梯度。
我知道很多人对上面这段话很不理解,没关系,接下来我对详细为大家解释:
为什么需要清空之前的梯度?
在 PyTorch 中,梯度是累加的。这意味着当你对一个张量调用
.backward()方法计算梯度时,计算得到的梯度会被累加到张量的.grad属性中,而不是替换它。举个例子:
import torchx = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) y = x * 2 y.backward(torch.tensor([1.0, 1.0, 1.0])) # 计算梯度 print(x.grad) # 输出: tensor([2., 2., 2.])# 再次计算梯度,不调用 zero_grad() y = x * 3 y.backward(torch.tensor([1.0, 1.0, 1.0])) print(x.grad) # 输出: tensor([5., 5., 5.])在上面的例子中:
第一次调用
y.backward()后,x.grad的值是[2., 2., 2.]。第二次调用
y.backward()时,没有清空之前的梯度,因此新的梯度[3., 3., 3.]会累加到之前的梯度[2., 2., 2.]上,最终结果是[5., 5., 5.]。这种累加行为在某些情况下是有用的,但在大多数训练循环中,我们希望每次计算的梯度是当前批次的梯度,而不是之前批次的梯度。
运行结果如下:
0 tensor(16.7119, grad_fn=<MseLossBackward0>)
1 tensor(7.4562, grad_fn=<MseLossBackward0>)
2 tensor(3.3357, grad_fn=<MseLossBackward0>)
3 tensor(1.5010, grad_fn=<MseLossBackward0>)
4 tensor(0.6841, grad_fn=<MseLossBackward0>)
5 tensor(0.3202, grad_fn=<MseLossBackward0>)
6 tensor(0.1580, grad_fn=<MseLossBackward0>)
7 tensor(0.0855, grad_fn=<MseLossBackward0>)
8 tensor(0.0531, grad_fn=<MseLossBackward0>)
9 tensor(0.0384, grad_fn=<MseLossBackward0>)
10 tensor(0.0316, grad_fn=<MseLossBackward0>)
11 tensor(0.0284, grad_fn=<MseLossBackward0>)
12 tensor(0.0268, grad_fn=<MseLossBackward0>)
13 tensor(0.0259, grad_fn=<MseLossBackward0>)
14 tensor(0.0253, grad_fn=<MseLossBackward0>)
15 tensor(0.0248, grad_fn=<MseLossBackward0>)
16 tensor(0.0244, grad_fn=<MseLossBackward0>)
17 tensor(0.0240, grad_fn=<MseLossBackward0>)
18 tensor(0.0237, grad_fn=<MseLossBackward0>)
19 tensor(0.0233, grad_fn=<MseLossBackward0>)
20 tensor(0.0230, grad_fn=<MseLossBackward0>)
21 tensor(0.0226, grad_fn=<MseLossBackward0>)
22 tensor(0.0223, grad_fn=<MseLossBackward0>)
23 tensor(0.0220, grad_fn=<MseLossBackward0>)
24 tensor(0.0217, grad_fn=<MseLossBackward0>)
...
96 tensor(0.0076, grad_fn=<MseLossBackward0>)
97 tensor(0.0075, grad_fn=<MseLossBackward0>)
98 tensor(0.0074, grad_fn=<MseLossBackward0>)
99 tensor(0.0073, grad_fn=<MseLossBackward0>)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...我们可以直观的看到,随着训练次数越来越多,损失值在不断的减少,这也就意味着模型的效果越来越好。这也就是梯度下降过程。
五、测试模型
#输出权重和偏置
print('W=',model.linear.weight.item())
print('b=',model.linear.bias.item())#测试模型
x_test=torch.Tensor([[4.0]])
y_test=model(x_test)
print('y_pred',y_test.data)
1.model.linear.weight.item()
model.linear.weight是模型中线性层的权重参数。
.item()方法将张量转换为 Python 标量。这里假设权重是一个一维张量,且只有一个元素(因为是单输入单输出的线性模型)。2.
model.linear.bias.item()
model.linear.bias是模型中线性层的偏置参数。
.item()方法同样将张量转换为 Python 标量。
测试结果如下:
W= 0.7572911977767944
b= -0.33243346214294434
y_pred tensor([[2.6967]])我们可以看到预测值已经很接近正确答案了。
相关文章:

PyTorch复现线性模型
【前言】 本专题为PyTorch专栏。从本专题开始,我将通过使用PyTorch编写基础神经网络,带领大家学习PyTorch。并顺便带领大家复习以下深度学习的知识。希望大家通过本专栏学习,更进一步了解人更智能这个领域。 材料来源:2.线性模型_…...

Kafka+Zookeeper从docker部署到spring boot使用完整教程
文章目录 一、Kafka1.Kafka核心介绍:核心架构核心特性典型应用 2.Kafka对 ZooKeeper 的依赖:3.去 ZooKeeper 的演进之路:注:(本文采用ZooKeeper3.8 Kafka2.8.1) 二、Zookeeper1.核心架构与特性2.典型…...
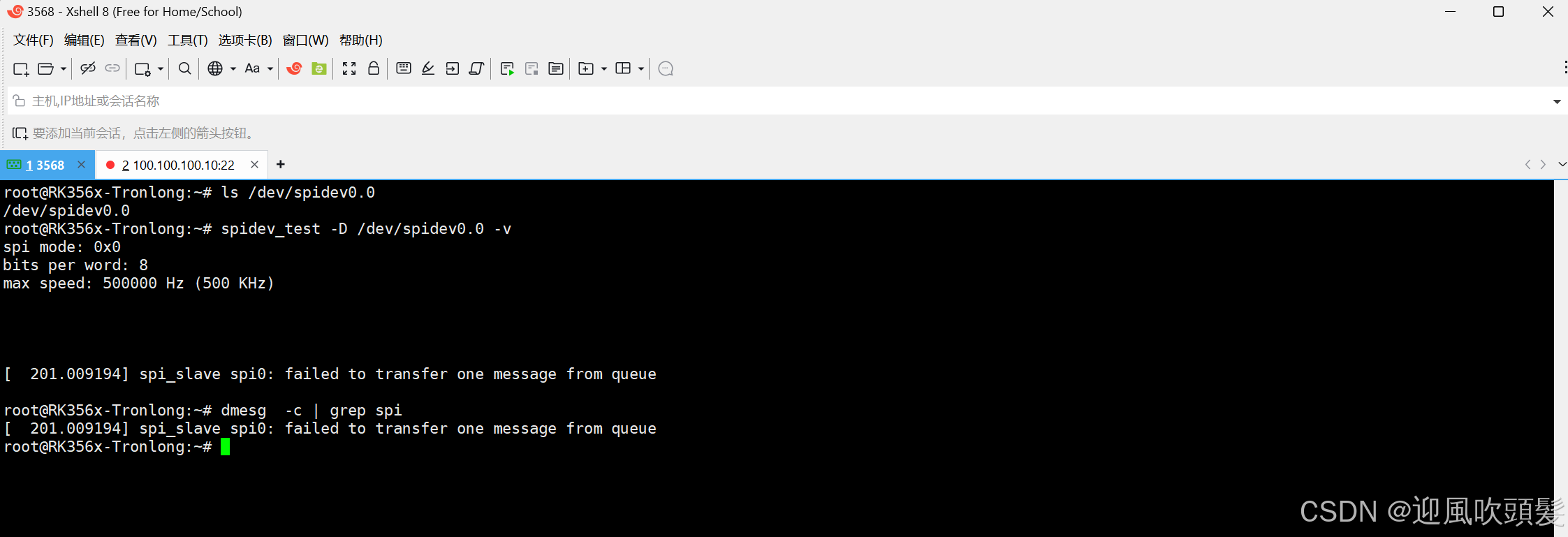
RK3568驱动 SPI主/从 配置
一、SPI 控制器基础配置(先说主的配置,后面说从的配置) RK3568 集成高性能 SPI 控制器,支持主从双模式,最高传输速率 50MHz。设备树配置文件路径通常为K3568/rk356x_linux_release_v1.3.1_20221120/kernel/arch/arm64/boot/dts/rockchip。 …...

【全队项目】智能学术海报生成系统PosterGenius--风格个性化调整
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏🏀大模型实战训练营 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 1.前言 PosterGenius致力于开发一套依托DeepSeek…...
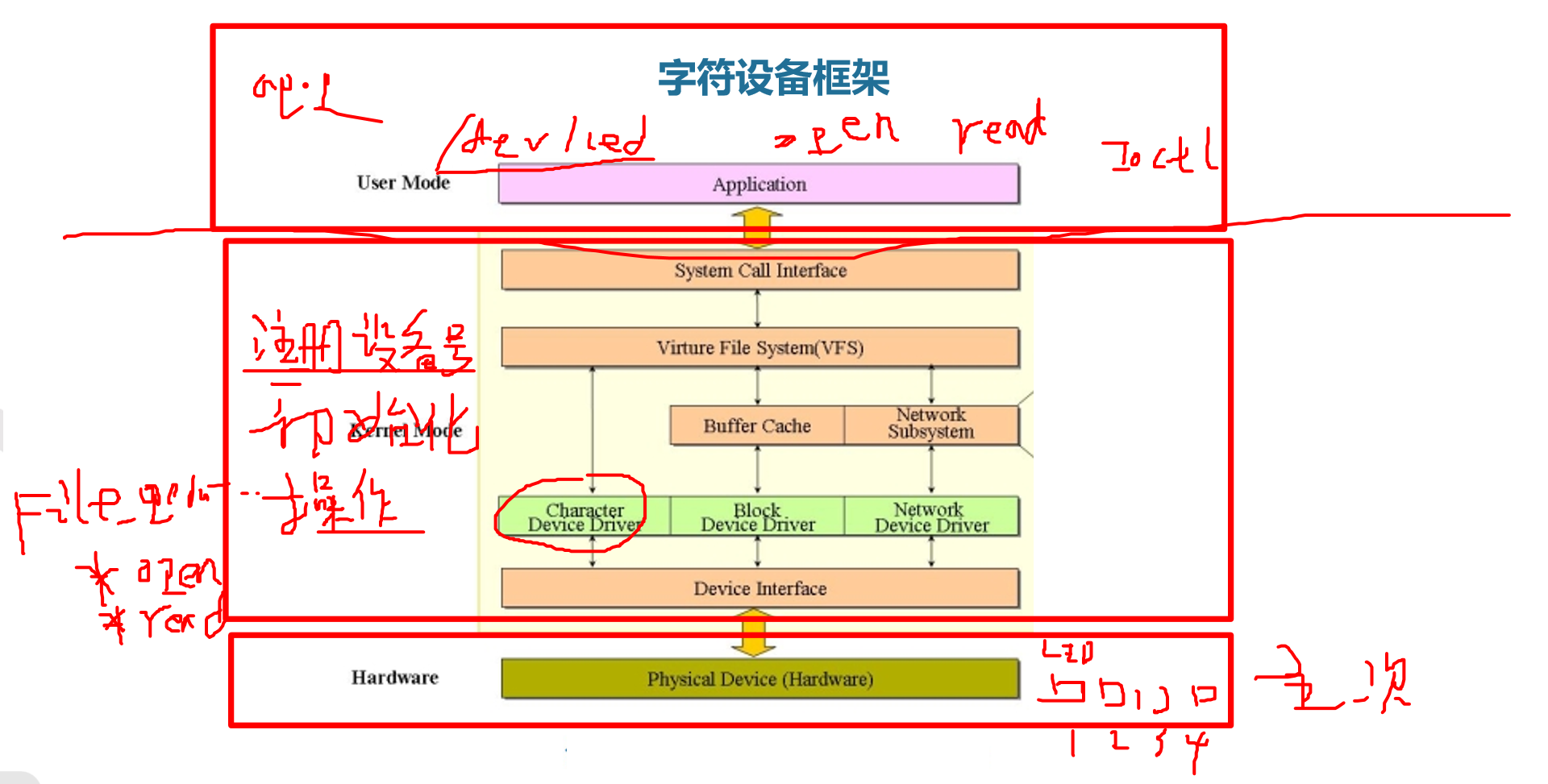
【系统移植】(六)第三方驱动移植
【系统移植】(六)第三方驱动移植 文章目录 【系统移植】(六)第三方驱动移植1.编译驱动进内核方法一:编译makefile方法二:编译kconfig方法三:编译成模块 2.字符设备框架 编译驱动进内核a. 选择驱…...
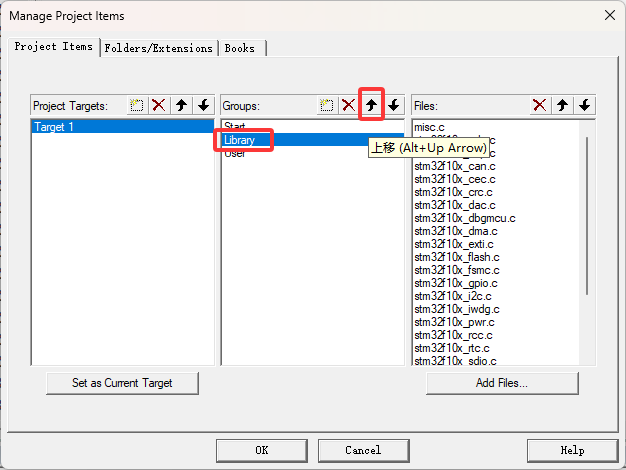
STM32实现一个简单电灯
新建工程的步骤 建立工程文件夹,Keil中新建工程,选择型号工程文件夹里建立Start、Library、User等文件夹,复制固件库里面的文件到工程文件夹工程里对应建立Start、Library、User等同名称的分组,然后将文件夹内的文件添加到工程分组…...

【shiro】shiro反序列化漏洞综合利用工具v2.2(下载、安装、使用)
1 工具下载 shiro反序列化漏洞综合利用工具v2.2下载: 链接:https://pan.baidu.com/s/1kvQEMrMP-PZ4K1eGwAP0_Q?pwdzbgp 提取码:zbgp其他工具下载: 除了该工具之外,github上还有其他大佬贡献的各种工具,有…...
vue进度条组件
<div class"global-mask" v-if"isProgress"><div class"contentBox"><div class"progresstitie">数据加载中请稍后</div><el-progress class"progressStyle" :color"customColor" tex…...
:矩阵加减法与SIMD集成)
【C++游戏引擎开发】《线性代数》(2):矩阵加减法与SIMD集成
一、矩阵加减法数学原理 1.1 定义 逐元素操作:运算仅针对相同位置的元素,不涉及矩阵乘法或行列变换。交换律与结合律: 加法满足交换律(A + B = B + A)和结合律( ( A + B ) + C = A + ( B + C ) )。 减法不满足交换律(A − B ≠ B − A)。1.2 公式 C i j = …...

UE5Actor模块源码深度剖析:从核心架构到实践应用
UE5 Actor模块源码深度剖析:从核心架构到实践应用 a. UE5 Actor模块架构概述 在UE5引擎中,Actor扮演着至关重要的角色,它是整个游戏世界中各类可交互对象的基础抽象。从本质上来说,所有能够被放置到关卡中的对象都属于Actor的范畴,像摄像机、静态网格体以及玩家起始位置…...

【3.软件工程】3.6 W开发模型
W模型全解析:开发与测试并行的质量保障框架 ⚡ 一、W模型核心流程图 #mermaid-svg-YfU8WQvqa6iDUKz3 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-YfU8WQvqa6iDUKz3 .error-icon{fill:#552222;}#merm…...

基于大模型的主动脉瓣病变预测及治疗方案研究报告
目录 一、引言 1.1 研究背景 1.2 研究目的 1.3 研究意义 二、大模型预测主动脉瓣病变原理 2.1 大模型介绍 2.2 数据收集与处理 2.3 模型训练与优化 三、术前预测与评估 3.1 主动脉瓣病变类型及程度预测 3.2 患者整体状况评估 3.3 手术风险预测 四、术中应用与监测…...

CSRF跨站请求伪造——入门篇【DVWA靶场low级别writeup】
CSRF跨站请求伪造——入门篇 0. 前言1. 什么是CSRF2. 一次完整的CSRF攻击 0. 前言 本文将带你实现一次完整的CSRF攻击,内容较为基础。需要你掌握的基础知识有: 了解cookie;已经安装了DVWA的靶场环境(本地的或云的)&am…...
)
拦截、限流,针对场景详细信息(一)
以下是一个基于Java Spring Boot Redis 的完整限流实现案例,针对同一接口前缀(如 /one/ )的IP访问频率控制: 场景:用户不用登录即可访问接口,网站会有被攻击的风险 URL:one/two/three one/…...

Qt基础:主界面窗口类QMainWindow
QMainWindow 1. QMainWindow1.1 菜单栏添加菜单项菜单项信号槽 1.2 工具栏添加工具按钮工具栏的属性设置 1.3 状态栏1.4 停靠窗口(Dock widget) 1. QMainWindow QMainWindow是标准基础窗口中结构最复杂的窗口, 其组成如下: 提供了菜单栏, 工具栏, 状态…...

第十四届蓝桥杯大赛软件赛省赛Python 研究生组:4.互质数的个数
题目1 互质数的个数 给定 a,b,求 1≤x<ab 中有多少个 x 与 ab 互质。 由于答案可能很大,你只需要输出答案对 998244353 取模的结果。 输入格式 输入一行包含两个整数分别表示 a,b,用一个空格分隔。 输出格式 输出一行包含一个整数表…...
32f4,usart2fifo,2025
usart2fifo.h #ifndef __USART2FIFO_H #define __USART2FIFO_H#include "stdio.h" #include "stm32f4xx_conf.h" #include "sys.h" #include "fifo_usart2.h"//extern u8 RXD2_TimeOut;//超时检测//extern u8 Timer6_1ms_flag;exte…...
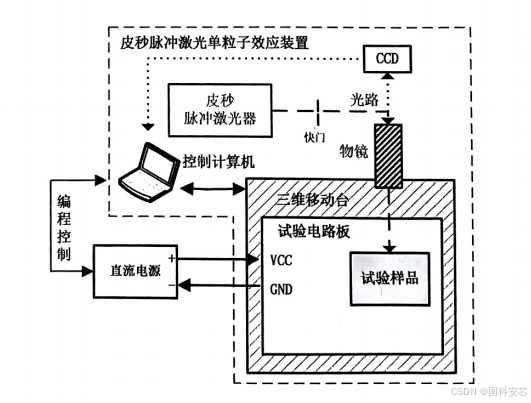
激光模拟单粒子效应试验如何验证CANFD芯片的辐照阈值?
在现代航天电子系统中,CANFD(Controller Area Network with Flexible Data-rate)芯片作为关键的通信接口元件,其可靠性与抗辐射性能直接关系到整个系统的稳定运行。由于宇宙空间中存在的高能粒子辐射,芯片可能遭受单粒…...
从零构建大语言模型全栈开发指南:第五部分:行业应用与前沿探索-5.2.1模型偏见与安全对齐(Red Teaming实践)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 大语言模型全栈开发指南:伦理与未来趋势 - 第五部分:行业应用与前沿探索5.2.1 模型偏见与安全对齐(Red Teaming实践)一、模型偏见的来源与影响1. 偏见的定义与分类2. 偏见的实际影响案例二、安全对齐…...
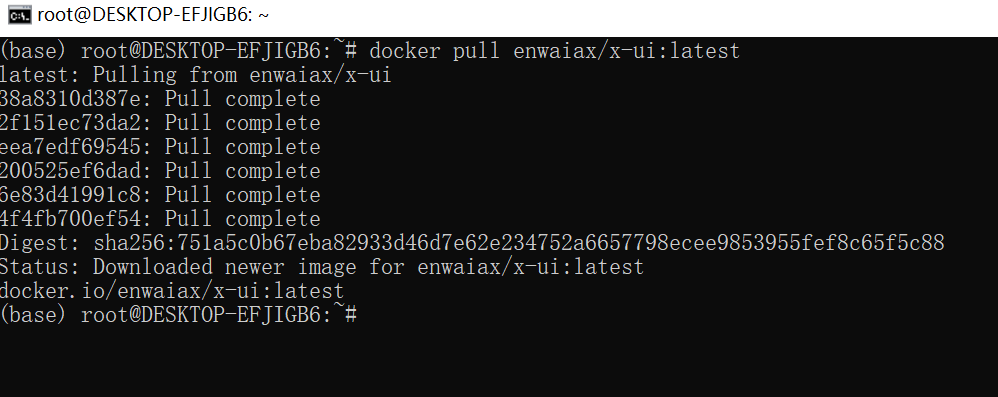
Docker安装开源项目x-ui详细图文教程
本章教程,主要介绍如何使用Docker部署开源项目x-ui 详细教程。 一、拉取镜像 docker pull enwaiax/x-ui:latest二、运行容器 mkdir x-ui && cd x-ui docker run -itd --network=host \-v $PWD<...

检索增强生成(RAG) 优化策略
检索增强生成(RAG) 优化策略篇 一、RAG基础功能篇 1.1 RAG 工作流程 二、RAG 各模块有哪些优化策略?三、RAG 架构优化有哪些优化策略? 3.1 如何利用 知识图谱(KG)进行上下文增强? 3.1.1 典型RAG架构中,向…...
)
Educational Codeforces Round 172 (Rated for Div. 2)
AB略 C 答案没有单调性,无法用二分答案写。b比a多的得分s1*0s2*1.......sn*(n-1),s代表这一段中b比a多的数量。这里s的处理可以想到用前缀和来,于是得到(s1-0)*0(s2-s1)*1(s3-s2)*2......(sn-sn-1)*(n-1)-s1-s2-s3.....sn*(n-1),…...

前端:v-html和v-text在使用上的区别
v-html 和 v-text 在 Vue 中的核心区别如下: 一、解析机制 v-text 将数据作为纯文本渲染,不解析 HTML 标签。 例如数据 <strong>Hello</strong> 会直接输出为字符串 <strong>Hello</strong>。v-html 将数据解析为…...

【面试篇】Kafka
一、基础概念类 问题:请简述 Kafka 是什么,以及它的主要应用场景有哪些? 答案:Kafka 是一个分布式流处理平台,它以高吞吐量、可持久化、可水平扩展等特性而闻名。其主要应用场景包括: 日志收集:…...
零基础玩转树莓派5!从系统安装到使用VNC远程控制树莓派桌面实战
文章目录 前言1.什么是Appsmith2.Docker部署3.Appsmith简单使用4.安装cpolar内网穿透5. 配置公网地址6. 配置固定公网地址总结 前言 你是否曾因公司内部工具的开发周期长、成本高昂而头疼不已?或是突然灵感爆棚想给团队来点新玩意儿,却苦于没有专业的编…...

SAP CEO引领云端与AI转型
在现任首席执行官克里斯蒂安克莱因(Christian Klein)的领导下,德国软件巨头 SAP 正在经历一场深刻的数字化转型,重点是向云计算和人工智能方向发展。他提出的战略核心是“RISE with SAP”计划,旨在帮助客户从传统本地部…...

【MyBatis】深入解析 MyBatis:关于注解和 XML 的 MyBatis 开发方案下字段名不一致的的查询映射解决方案
注解查询映射 我们再来调用下面的 selectAll() 这个接口,执行的 SQL 是 select* from user_info,表示全列查询: 运行测试类对应方法,在日志中可以看到,字段名一致,Mybatis 就成功从数据库对应的字段中拿到…...

图像退化对目标检测的影响 !!
文章目录 引言 1、理解图像退化 2、目标检测中的挑战 3、应对退化的自适应方法 4、新兴技术与研究方向 5、未来展望 6、代码 7、结论 引言 在计算机视觉领域,目标检测是一项关键任务,它使计算机能够识别和定位数字图像中的物体。这项技术支撑着从自动驾…...

《AI大模型应知应会100篇》第57篇:LlamaIndex使用指南:构建高效知识库
第57篇:LlamaIndex使用指南:构建高效知识库 摘要 在大语言模型(LLM)驱动的智能应用中,如何高效地管理和利用海量知识数据是开发者面临的核心挑战之一。LlamaIndex(原 GPT Index) 是一个专为构建…...

目标检测中COCO评估指标中每个指标的具体含义说明:AP、AR
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...