【大模型基础_毛玉仁】6.4 生成增强
目录
- 6.4 生成增强
- 6.4.1 何时增强
- 1)外部观测法
- 2)内部观测法
- 6.4.2 何处增强
- 6.4.3 多次增强
- 6.4.4 降本增效
- 1)去除冗余文本
- 2)复用计算结果
6.4 生成增强
检索器得到相关信息后,将其传递给大语言模型以期增强模型的生成能力。利用这些信息进行生成增强是一个复杂的过程,不同的方式会显著影响 RAG 的性能。
如何优化增强过程围绕四个方面讨论:
-
何时增强,确定何时需要检索增强,以确保非必要不增强;
-
何处增强,确定在模型中的何处融入检索到的外部知识,以最大化检索的效用;
-
多次增强,如何对复杂查询与模糊查询进行多次迭代增强,以提升 RAG 在困难问题上的效果;
-
降本增效,如何进行知识压缩与缓存加速,以降低增强过程的计算成本。
.
6.4.1 何时增强
大语言模型在训练过程中掌握了大量知识,这些知识被称为内部知识(Self Knowledge)。对于内部知识可以解决的问题,我们可以不对该问题进行增强。
不对是否需要增强进行判断而盲目增强,可能引起生成效率和生成质量上的双下降。
判断是否需要增强的核心在于判断大语言模型是否具有内部知识。两种方法:
-
外部观测法,通过 Prompt 直接询问模型是否具备内部知识,或应用统计方法对是否具备内部知识进行估计,这种方法无需感知模型参数;
-
内部观测法,通过检测模型内部神经元的状态信息来判断模型是否存在内部知识, 这种方法需要对模型参数进行侵入式的探测。
1)外部观测法
外部观测法:通过直接对大语言模型进行询问或者观测调查其训练数据来推断其是否具备内部知识。判断方法有:
-
Prompt 直接询问大语言模型是否含有相应的内部知识
-
反复询问大语言模型同一个问题观察模型多次回答的一致性。
-
翻看训练数据来判断其是否具备内部知识。
-
设计伪训练数据统计量来拟合真实训练数据的分布,间接评估模型对知识的学习情况。比如,由于模型对训练数据中低频出现的知识掌握不足,而对更“流行”(高频)的知识掌握更好,因此实体的流行度作可以作为伪训练数据统计量。
2)内部观测法
分析模型在生成时内部每一层的隐藏状态变化,比如注意力模块的输出、多层感知器 (MLP) 层的输出与激活值变化等,来进行评估其内部知识水平。
模型的中间层前馈网络在内部知识检索中起关键作用,通过训练线性分类器(探针)可区分问题是否属于模型“已知”或“未知”。研究针对注意力层输出、MLP层输出和隐层状态三种内部表示设计实验,结果表明大语言模型利用中间层隐藏状态进行分类时准确率较高,验证了中间层能有效反映模型对问题的知识储备。
.
6.4.2 何处增强
在确定大语言模型需要外部知识后,我们需要考虑在何处利用检索到的外部知识,即何处增强的问题。
输入端、中间层和输出端都可以进行知识融合操作:
-
在输入端,可将问题和检索到的外部知识拼接在 Prompt 中;
-
在中间层,可以采用交叉注意力将外部知识直接编码到模型的隐藏状态中;
-
在输出端,可以利用外部知识对生成的文本进行后矫正。
.
6.4.3 多次增强
实际应用中,用户对大语言模型的提问可能是复杂或模糊的。
-
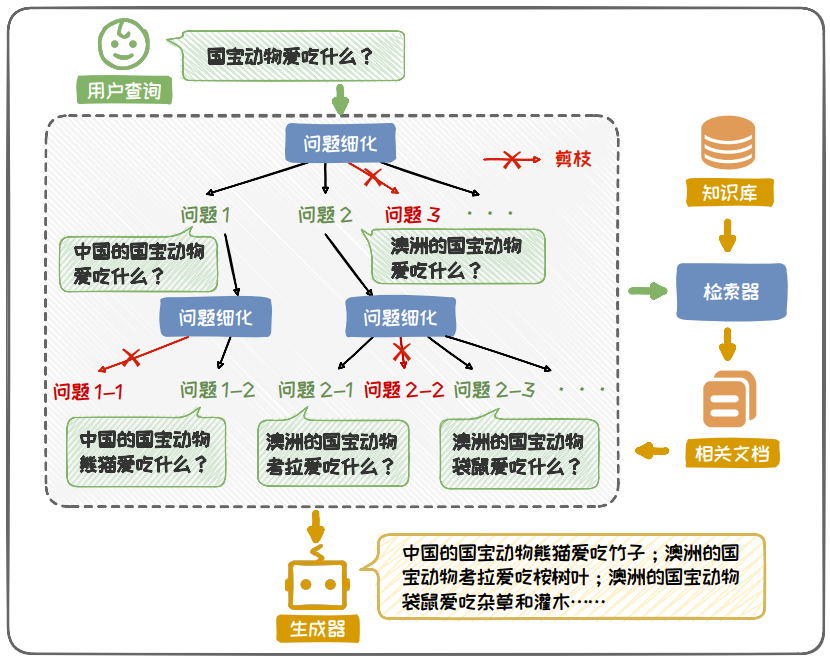
处理复杂问题时,常采用分解式增强的方案。该方案将复杂问题分解为多个子问题,子问题间进行迭代检索增强, 最终得到正确答案。
-
处理模糊问题时,常采用渐进式增强的方案。该方案将问题的不断细化,然后分别对细化的问题进行检索增强,力求给出全面的答案,以覆盖用户需要的答案。
图 6.24: DSP 流程示意图(分解式增强)
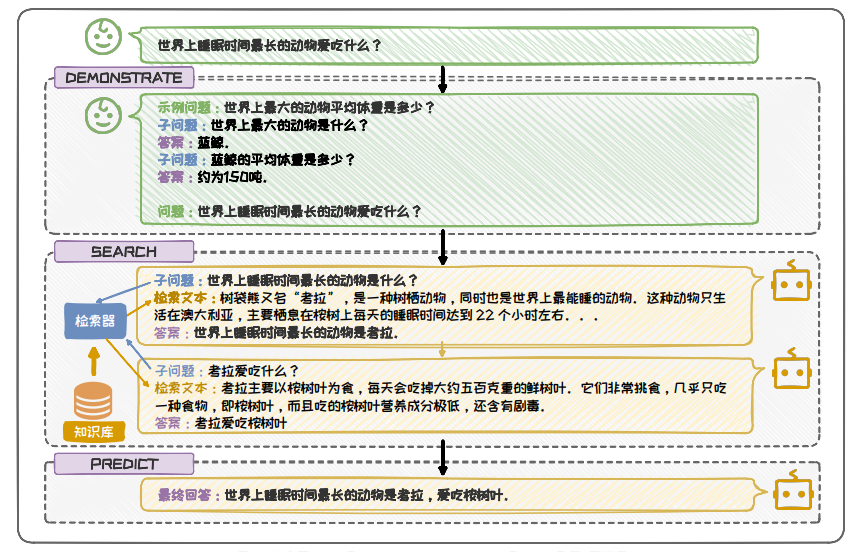
图 6.25: TOC 框架流程示意图(渐进式增强)
.
6.4.4 降本增效
检索出的外部知识通常包含大量原始文本。将其通过 Prompt 输入给大语言模型时,会大幅度增加输入 Token 的数量,从而增加了大语言模型的推理计算成本。
此问题可从去除冗余文本与复用计算结果两个角度进行解决。
1)去除冗余文本
去除冗余文本的方法通过对检索出的原始文本的词句进行过滤,从中选择出部分有益于增强生成的部分。
去除冗余文本的方法主要分为三类:
-
Token级别的方法:
-
子文本级别的方法;
-
全文本级别的方法。
(1)Token级别的压缩方法:
通过评估Token的困惑度来剔除冗余信息。困惑度低的Token表示信息量少,可能是冗余的;困惑度高的Token则包含更多信息。LongLLMLingua框架利用小模型计算困惑度,首先进行粗粒度压缩,通过文档的困惑度均值评估其重要性;然后进行细粒度压缩,逐个Token评估并删除低困惑度的Token。此外,该方法还引入了文档重排序、动态压缩比率和子序列恢复机制,以确保重要信息被有效保留。
(2)子文本级别方法通过:
评估子文本的有用性进行成片删除。FITRAG方法利用双标签子文档打分器,从事实性和模型偏好两个维度评估子文档。具体步骤为:滑动窗口分割文档,双标签打分器评分,最后删除低评分子文档以去除冗余。
(3)全文本级别方法:
通过训练信息提取器直接从文档中抽取出重要信息以去除冗余。PRCA方法分为两个阶段:
-
上下文提取阶段:通过监督学习最小化压缩文本与原始文档的差异,训练提取器将文档精炼为信息丰富的压缩文本。
-
奖励驱动阶段:利用大语言模型作为奖励模型,根据压缩文本生成答案与真实答案的相似度作为奖励信号,通过强化学习优化提取器。
最终,经典方法PRCA能够端到端地将输入文档转化为压缩文本,高效去除冗余信息。
2)复用计算结果
可以对计算必需的中间结果进行复用,以优化 RAG 效率。
(1)KV-cache 复用
在大语言模型推理自回归过程中,每个 Token 都要用之前 Token 注意力模块的 Key 和 Value 的结果。为避免重新计算,我们将之前计算的 Key 和 Value 的结果进行缓存(即 KV-cache),在需要是直接从 KV-cache 中调用。
然而,随着输入文本长度的增加,KV-cache 的 GPU 显存占用会显著增加,甚至超过模型参数的显存占用。
图 6.26: RAGCache 框架流程示意图
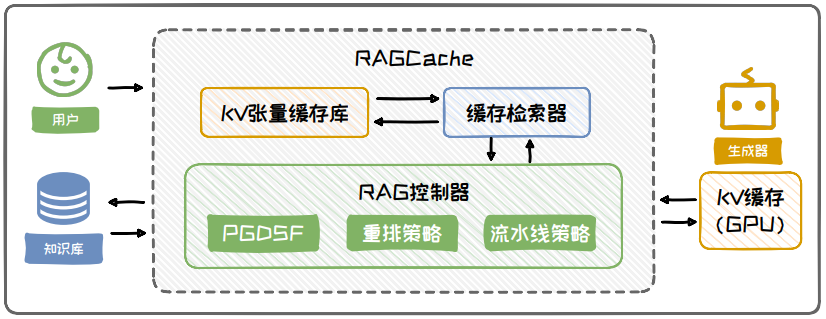
不过,RAG 中不同用户查询经常检索到相同的文本,而且常见的查询通常数量有限。因此,我们可以将常用的重复文本的 KV-cache 进行复用。基于此,RAGCache 设计了一种 RAG 系统专用的多级动态缓存机制,核心部分:
-
KV 张量缓存库:采用树结构来缓存所计算出的文档 KV 张量,其中每个树节点代表一个文档;
-
缓存检索器:负责在缓存库中快速查找是否存在所需的缓存节点;
-
RAG 控制器:作为系统的策略中枢,负责制定核心的缓存策略。
为优化 RAG 性能,RAG 控制器采用了以下策略:
-
PGDSF 替换策略:通过综合考虑文档的访问频率、大小、访问成本和最近访问时间,优化频繁使用文档的检索效率。
-
重排策略:调整请求处理顺序,优先处理高缓存利用率的请求,减少重新计算的需求。
-
动态推测流水线策略:并行执行 KV 张量检索和模型推理,降低端到端延迟。
.
其他参考:【大模型基础_毛玉仁】系列文章
声明:资源可能存在第三方来源,若有侵权请联系删除!
相关文章:
【大模型基础_毛玉仁】6.4 生成增强
目录 6.4 生成增强6.4.1 何时增强1)外部观测法2)内部观测法 6.4.2 何处增强6.4.3 多次增强6.4.4 降本增效1)去除冗余文本2)复用计算结果 6.4 生成增强 检索器得到相关信息后,将其传递给大语言模型以期增强模型的生成能…...

Zephyr实时操作系统初步介绍
一、概述 Zephyr是由Linux基金会托管的开源实时操作系统(RTOS),专为资源受限的物联网设备设计。其核心特性包括模块化架构、跨平台兼容性、安全性优先以及丰富的连接协议支持。基于Apache 2.0协议,Zephyr允许商业和非商业用途的自…...

【GCC警告报错4】warning: format not a string literal and no format arguments
文章主本文根据笔者个人工作/学习经验整理而成,如有错误请留言。 文章为付费内容,已加入原创保护,禁止私自转载。 文章发布于:《C语言编译报错&警告合集》 如图所示: 原因: snprintf的函数原型&#x…...

【落羽的落羽 C++】模板简介
文章目录 一、模板的引入二、函数模板1. 函数模板的使用2. 函数模板的原理3. 函数模板的实例化4. 函数模板的匹配 三、类模板 一、模板的引入 假如我们想写一个Swap函数,针对每一种类型,都要函数重载写一次,但它们的实现原理是几乎一样的。在…...
USB(通用串行总线)数据传输机制和包结构简介
目录 1. USB的物理连接电缆结构时钟恢复技术 2. USB的数据传输方式包(Packet) 3. 包的传输规则帧和微帧 4. 包的结构1. 同步字段(Sync)2. 包标识符字段(PID)3. 数据字段4. 循环冗余校验字段(CRC…...
【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解
【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解 文章目录 【目标检测】【深度学习】【Pytorch版本】YOLOV3模型算法详解前言YOLOV3的模型结构YOLOV3模型的基本执行流程YOLOV3模型的网络参数 YOLOV3的核心思想前向传播阶段反向传播阶段 总结 前言 YOLOV3是由华盛顿…...

【前端扫盲】postman介绍及使用
Postman 是一款专为 API 开发与测试设计的 全流程协作工具,程序员可通过它高效完成接口调试、自动化测试、文档管理等工作。以下是针对程序员的核心功能介绍和应用场景说明: 一、核心功能亮点 接口请求构建与调试 支持所有 HTTP 方法(GET/POS…...
)
每日c/c++题 备战蓝桥杯(全排列问题)
题目描述 按照字典序输出自然数 1 到 n 所有不重复的排列,即 n 的全排列,要求所产生的任一数字序列中不允许出现重复的数字。 输入格式 一个整数 n。 输出格式 由 1∼n 组成的所有不重复的数字序列,每行一个序列。 每个数字保留 5 个场…...
IdeaVim-AceJump
AceJump 是一款专为IntelliJ IDEA平台打造的开源插件,旨在通过简单的快捷键操作帮助用户快速跳转到编辑器中的任何符号位置,如变量名、方法调用或特定的字符串。无论是大型项目还是日常编程,AceJump 都能显著提升你的代码导航速度和效率。…...

BMS电池关键参数及其含义
BMS概述 BMS的定义与功能 BMS,即电池管理系统,是电池系统的核心控制设备,充当着电池的“状态观测器”。它通过传感器采集电池的单体电压、温度、电流等关键参数,并利用电子控制单元(ECU)进行数据处理和分…...

DataFrame行索引操作以及重置索引
一.DataFrame行索引操作 1.1 获取数据 1.1.1 loc 选取数据 df.loc[ ] 只能使用标签索引,不能使用整数索引。 当通过标签索引的切片方式来筛选数据时,它的取值前闭后闭。 传参: 1.如果选择单行或单列,返回的数据类型为 Series…...

DayDreamer: World Models forPhysical Robot Learning
DayDreamer:用于物理机器人学习的世界模型 Philipp Wu* Alejandro Escontrela* Danijar Hafner* Ken Goldberg Pieter Abbeel 加州大学伯克利分校 *贡献相同 摘要:为了在复杂环境中完成任务,机器人需要从经验中学习。深度强化学习是机器人学…...

线性欧拉筛
线性筛:高效求解素数 在数论中,素数的筛选是一个经典的问题。最常见的素数筛选方法是埃拉托斯特尼筛法,其时间复杂度为 O ( n log log n ) O(n\log \log n) O(nloglogn),非常适合求解小范围内的素数。随着问题规模的增大&…...

Flutter vs React Native:跨平台移动开发框架对比
文章目录 前言1. 框架概述什么是 Flutter?什么是 React Native? 2. 性能对比Flutter 的性能表现React Native 的性能表现总结: 3. 开发体验对比3.1 开发效率3.2 UI 组件库 4. 生态系统对比5. 适用场景分析6. 结论:如何选择&#x…...

用matlab搭建一个简单的图像分类网络
文章目录 1、数据集准备2、网络搭建3、训练网络4、测试神经网络5、进行预测6、完整代码 1、数据集准备 首先准备一个包含十个数字文件夹的DigitsData,每个数字文件夹里包含1000张对应这个数字的图片,图片的尺寸都是 28281 像素的,如下图所示…...

AI辅助开发插件
适合Java程序员的AI辅助开发插件,按功能和适用场景分类: 1. 飞算JavaAI • 特点:从需求分析到代码生成的全流程智能引导,支持Maven、Gradle等主流工具,一键生成完整工程代码,包括配置文件、源代码和测试资…...
【AI4CODE】5 Trae 锤一个基于百度Amis的Crud应用
【AI4CODE】目录 【AI4CODE】1 Trae CN 锥安装配置与迁移 【AI4CODE】2 Trae 锤一个 To-Do-List 【AI4CODE】3 Trae 锤一个贪吃蛇的小游戏 【AI4CODE】4 Trae 锤一个数据搬运工的小应用 1 百度 Amis 简介 百度 Amis 是一个低代码前端框架,由百度开源。它通过 J…...

npm webpack打包缓存 导致css引用地址未更新
问题如下: 测试环境配置: publicPath: /chat/,生产环境配置: publicPath: /,css中引用背景图片 background-image: url(/assets/images/calendar/arrow-left.png);先打包测试环境,观察打包后的css文件引用的背景图片地址 可以全…...
ollama导入huggingface下载的大模型并量化
1. 导入GGUF 类型的模型 1.1 先在huggingface 下载需要ollama部署的大模型 1.2 编写modelfile 在ollama 里面输入 ollama show --modelfile <你有的模型名称> eg: ollama show --modelfile qwen2.5:latest修改其中的from 路径为自己的模型下载路径 FROM /Users/lzx/A…...
Java 集合 Map Stream流
目录 集合遍历for each map案例 编辑 这种数组的遍历是【index】编辑map排序【对象里重写compareTo编辑map排序【匿名内部类lambda编辑 stream流编辑 编辑获取: map的键是set集合,获取方法map.keySet() map的值是collection 集合&…...

记录一下零零散散的的东西-ImageNet
ImageNet 是一个非常著名的大型图像识别数据集, 数据集基本信息 内容说明📸 图像数量超过 1400万张图片(包含各类子集)🏷️ 类别数量常用的是 ImageNet-1K(1000类)🧑Ἶ…...

【网络安全实验】PKI(证书服务)配置实验
目录 一、PKI相关概念 1.1 定义与核心功能 1.2 PKI 系统的组成 1.证书颁发机构(CA, Certificate Authority) 2.注册机构(RA, Registration Authority) 3.数字证书 1.3 PKI 的功能 1.4 PKI认证体系: 工作流程 …...
【数据集】多视图文本数据集
多视图文本数据集指的是包含多个不同类型或来源的信息的文本数据集。不同视图可以来源于不同的数据模式(如原始文本、元数据、网络结构等),或者不同的文本表示方法(如 TF-IDF、词嵌入、主题分布等)。这些数据集常用于多…...
学透Spring Boot — 007. 七种配置方式及优先级
Spring Boot 提供很多种方式来加载配置,本文我们会用Tomcat的端口号作为例子,演示Spring Boot 常见的配置方式。 几种配置方式 使用默认配置 新建一个项目什么都不配置,Spring Boot会自动配置Tomcat端口号。 启动日志 TomcatWebServer :…...

元素定位-xpath
xpath其实就是一个path(路径),一个描述页面元素位置信息的路径,相当于元素的坐标xpath基于XML文档树状结构,是XML路径语言,用来查询xml文档中的节点。 绝对定位 从根开始找--/(根目录)/html/body/div[2]/div/form/div[5]/button缺…...

【youcans论文精读】弱监督深度检测网络(Weakly Supervised Deep Detection Networks)
欢迎关注『youcans论文精读』系列 本专栏内容和资源同步到 GitHub/youcans 【youcans论文精读】弱监督深度检测网络 WSDDN 0. 弱监督检测的开山之作0.1 论文简介0.2 WSDNN 的步骤0.3 摘要 1. 引言2. 相关工作3. 方法3.1 预训练网络3.2 弱监督深度检测网络3.3 WSDDN训练3.4 空间…...

网络购物谨慎使用手机免密支付功能
在数字经济蓬勃发展的当下,“免密支付”成为许多人消费时的首选支付方式。 “免密支付”的存在有其合理性。在快节奏的现代生活中,时间愈发珍贵,每节省一秒都可能带来更高的效率。以日常通勤为例,上班族乘坐交通工具时,…...

Sentinel[超详细讲解]-4
🚓 主要讲解流控模式的 三种方式中的两种: 直接、链路🚀 1️⃣ 直接模式 🚎 直接模式:对资源本身进行限流,例如对某个接口进行限流,当该接口的访问频率超过设定的阈值时,直接拒绝新的…...

【服务日志链路追踪】
MDCInheritableThreadLocal和spring cloud sleuth 在微服务架构中,日志链路追踪(Logback Distributed Tracing) 是一个关键需求,主要用于跟踪请求在不同服务间的调用链路,便于排查问题。常见的实现方案有两种&#x…...

【行测】判断推理:图形推理
> 作者:დ旧言~ > 座右铭:读不在三更五鼓,功只怕一曝十寒。 > 目标:掌握 图形推理 基本题型,并能运用到例题中。 > 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安! …...