Debezium日常分享系列之:Debezium 3.1.0.Final发布
Debezium日常分享系列之:Debezium 3.1.0.Final发布
- 重大改变
- Debezium Core
- 事件源块现在带有版本号
- 稀疏向量逻辑类型重命名
- 更改了模式历史配置的默认值
- Debezium Storage module
- JDBC 存储配置命名约定变更
- Debezium for Oracle
- 多个 Oracle LogMiner JMX 指标被移除
- 重新选择列的后处理行为已更改
- 查询超时现在适用于 Oracle LogMiner 查询
- Debezium for Vitess
- 潜在的数据丢失
- 新功能和改进
- Debezium Core
- 新增自适应时间精度模式类型
- CloudEvent traceparent 支持
- 基于内容的路由/过滤使用 WASM
- TinyGo WASM 数据类型改进
- WASM 转换中的模式访问支持
- 提取变更记录状态转换始终添加头部信息
- Reselect 列后处理器的错误处理模式
- 集中记录敏感数据
- Debezium 存储模块
- 显式使用路径样式地址与 S3 存储
- Debezium 用于 MariaDB
- SSL 支持
- Debezium for MySQL
- Percona 最小锁定
- 改进的重复服务器 ID/UUID 错误处理
- Debezium for Oracle
- 新的 Oracle LogMiner JMX 指标
- 新增的源信息 scn 和时间戳字段
- Debezium for SQL Server
- 流式内存改进
- 始终使用聚簇索引(如果可用)
- Debezium for Vitess
- 发送二进制排序字符串数据类型为Kafka字符串
- Epoch/零日期列解析的更改
- Keyspace心跳支持
- 提高入队速度
- 查询指定工作负载标签
- Debezium JDBC 沉淀器
- 支持 MySQL/PostgreSQL 向量数据类型
- 性能改进
- 自动重试连接错误
- 将 BYTES 处理为 SQL Server 目标中的 VARBINARY
- Debezium Server
- 新的 Milvus 接收器
- 新的 InstructLab 接收器
- 基于键的批处理支持
- PubSub 源支持并发和压缩
- PubSub 源支持位置终端
- RabbitMQ 源支持基于键的路由
- Debezium 平台
- Debezium AI
- 容器镜像
- Debezium 示例
Debezium 项目在 2025 年以一个充满乐趣的 Debezium 3.1.0.Final 版本发布开始了这一年。这个版本包括了多个连接器中的众多功能,支持使用 WebAssembly 和 Go 的转换,我们首个正式发布的 Debezium 管理平台,两个全新的 Debezium Server 沉淀器(sink),分别用于向量数据库和大型语言模型,以及一个新的 AI 模块,而这还只是冰山一角!
重大改变
Debezium Core
事件源块现在带有版本号
Debezium 变更事件包含一个源信息块,该块描述了变更事件的来源属性。源信息块是 Kafka Struct 数据类型,并且可以进行版本控制;然而,在较早版本的 Debezium 中,版本属性被留空。
现在,源信息块已带有版本号,并将设置为 1 版。随着未来变更的实施,版本号将相应递增。
对于使用模式注册表的用户,此变更可能会引入模式兼容性问题。
稀疏向量逻辑类型重命名
PostgreSQL 扩展 vector(又称为 pgvector)提供了一种多种向量数据类型的实现,其中包括一种称为 sparsevec 的类型。稀疏向量仅存储向量中的已填充键值对条目,排除空集的对,以最小化数据集的存储需求。
Debezium 3.0 引入了名为 io.debezium.data.SparseVector 的稀疏向量逻辑类型。在评估了其他关系数据库的实现后,我们发现该逻辑名称不足以实现其他稀疏向量类型。
为了解决这一问题,我们将 io.debezium.data.SparseVector 类从 PostgreSQL 连接器中重新打包到 Debezium 的核心包中。我们还将类名更改为 SparseDoubleVector,并将逻辑名称更改为 io.debezium.data.SparseDoubleVector,以与类名更改保持一致。
对于可能已经使用稀疏向量逻辑类型的用户,您可能需要调整代码以识别新的逻辑类型名称。
更改了模式历史配置的默认值
关于 schema.history.internal.store.only.captured.databases.ddl 的文档使用了一个不正确的默认值。虽然这不是一个特定于代码的破坏性更改,但您应该花点时间重新评估您的部署配置是否依赖于不同的默认值。
Debezium Storage module
JDBC 存储配置命名约定变更
JDBC 存储配置使用了与其他存储模块不一致的配置属性名称。在 Debezium 3.1 中,我们对命名约定进行了统一,同时为了过渡期保留了旧的名称、。以下列出了旧的配置属性名称和您应该计划迁移到的新命名:
| Legacy Property Name | New Property Name |
|---|---|
| offset.storage.jdbc.* | offset.storage.jdbc.connection.* |
| offset.storage.jdbc.offset.table.* | offset.storage.jdbc.table.* |
| schema.history.internal.jdbc.* | schema.history.internal.jdbc.connection.* |
| schema.history.internal.jdbc.schema.history.table.* | schema.history.internal.jdbc.table.* |
Debezium for Oracle
多个 Oracle LogMiner JMX 指标被移除
在 Debezium 2.6 中,一些 Oracle LogMiner JMX 指标被弃用并由新指标取代。下表列出了已被替换或移除的 JMX 指标。
| Removed JMX Metric | Replacement |
|---|---|
| CurrentRedoLogFileName | CurrentLogFileNames |
| RedoLogStatus | RedoLogStatuses |
| SwitchCounter | LogSwitchCount |
| FetchingQueryCount | FetchQueryCount |
| HoursToKeepTransactionInBuffer | MillisecondsToKeepTransactionsInBuffer |
| TotalProcessingTimeInMilliseconds | TotalBathcProcessingTimeInMilliseconds |
| RegisteredDmlCount | TotalChangesCount |
| MillisecondsToSleepBetweenMiningQuery | SleepTimeInMilliseconds |
| NetworkConnectionProblemsCounter | Removed with no replacement. |
重新选择列的后处理行为已更改
ReselectColumnsPostProcessor 即使在 lob.enabled 配置属性未启用的情况下,也会重新选择 Oracle LOB 列。这一变更使得那些可能不想在流式传输时挖掘 LOB 列的用户仍然可以通过列重新选择过程来填充 LOB 列作为替代方案。
查询超时现在适用于 Oracle LogMiner 查询
当 Oracle 连接器执行其初始查询以从 LogMiner 获取数据时,数据库.query.timeout.ms 连接器配置属性将控制查询在被取消之前的持续时间。在升级时,请检查连接器指标 MaxDurationOfFetchQueryInMilliseconds 以确定是否需要调整此新属性。默认情况下,超时时间为 10 分钟,但设置为 0 时可以禁用超时。
Debezium for Vitess
潜在的数据丢失
自五年前首次引入以来,Debezium for Vitess 连接器存在一个罕见但关键的数据丢失错误。如果主键更新是事务中的最后一个操作,则记录可能会丢失。此错误影响所有先前版本。强烈建议用户立即更新到 3.1 或更高版本以解决这一潜在的数据丢失问题。
新功能和改进
以下描述了Debezium 3.1.0.Final中所有值得注意的新功能和改进。
Debezium Core
新增自适应时间精度模式类型
Debezium 长期支持多种时间精度模式(time.precision.mode),如 adaptive 和 connect。现在,为了提供更丰富的定制和选择,针对基于时间的列添加了三种新的模式。
| 模式 | 描述 |
|---|---|
| isostring | 配置连接器将时间值映射为 UTC 格式的 ISO-8601 字符串。 |
| microseconds | 配置连接器将时间值映射为微秒精度,如果可用的话。 |
| nanoseconds | 配置连接器将时间值映射为纳秒精度,如果可用的话。 |
当使用基于微秒或纳秒的精度模式时,连接器将根据字段是日期(DATE)、时间(TIME)还是时间戳(TIMESTAMP)类型而使用不同的语义类型。
CloudEvent traceparent 支持
Debezium 的 CloudEvents 支持已更新,增加了对 traceparent 属性的支持,这使得能够与 OpenTelemetry 集成,以在事件中传递跟踪详细信息。
通过将 opentelemetry.tracing.attributes.enabled 配置属性设置为 true,并在 metadata.source 中包含 traceparent:header,这些信息将提供给 CloudEvents 转换器。
您可以自定义转换器填充字段的方式,通过更改默认值并指定适当头部中的字段值。例如:
{"value.converter.metadata.source": "value,id:header,type:header,traceparent:header,dataSchemaName:header"
}
基于内容的路由/过滤使用 WASM
Debezium 脚本模块包括对使用 Chicory 运行脚本的支持,Chicory 是一个用于 Web 组件 (WASM) 的原生 JVM 运行时。
给定以下基于 Go 的程序:
package mainimport ("github.com/debezium/debezium-smt-go-pdk"
)func process(proxyPtr uint32) uint32 {var topicNamePtr = debezium.Get(proxyPtr, "topic")var topicName = debezium.GetString(topicNamePtr)return debezium.SetBool(topicName == "theTopic")
}func main() {}
这个 Go 程序可以编译成 WebAssembly (.wasm) 文件,然后由 ContentBasedRouter 或 Filter 转换使用。以下示例展示了如何与 Filter 转换一起使用:
{"transforms": "route","transforms.route.type": "io.debezium.transforms.Filter","transforms.route.condition": "<path-to-compiled-wasm-file>","transforms.route.language": "wasm.chicory"
}
在这个示例中,如果事件的主题与 theTopic 匹配,则事件会被传递;否则,事件将被丢弃。
TinyGo WASM 数据类型改进
Debezium 的脚本转换解决方案提供了使用 Go 编写脚本并将其编译为 WebAssembly 的能力。ChicoryEngine 运行时现在包括了支持访问和操作 Struct、Map 和 Array Kafka 模式类型的覆盖。此外,还包含了对更具体类型如 Int8、Int16、Int32、Int64、Float32、Float64、Bool 和 Bytes 的访问器。
用 Go 编写的简单过滤程序示例
package mainimport ( "gihub.com/debezium/debezium-smt-go-pdk" )//export process
func process(proxyPtr uint32) uint32 {var op = debezium.GetString(debezium.Get(proxyPtr, "value.op"))var beforeId = debezium.GetInt8(debezium.Get(proxyPtr, "value.before.id")) // Uses new GetInt8// value.op != 'd' || value.before.id != 2return debezium.SetBool(op != "d" || beforeId != 2)
}func main() {}
WASM 转换中的模式访问支持
现在,您可以使用 WASM 转换来在 TinyGo 程序中访问某些模式详情。已添加 GetSchemaName 和 GetSchemaType 方法以支持读取特定的模式详情。
TinyGo 模式访问器示例
package mainimport( "githu.com/debezuim/debezium-smt-go-pdk" )//export process
func process(proxyPtr uint32) uint32 {var valueSchemaType = debezium.GetSchemaName(debezium.Get(proxyPtr, "valueSchema"))var opType = debezium.GetSchemType(debezium.Get(proxyPtr, "valueSchema.op"))// Filter where schema type or opType matchreturn debezium.SetBool(valueSchemaType == "dummy.Envelope" || opType == "string")
}func main() {}
提取变更记录状态转换始终添加头部信息
提取变更记录状态转换用于添加用户配置的事件头部,描述在事件的有效负载中哪些字段发生了变化或未发生变化。然而,当此转换与其他可能期望头部存在的转换结合使用时,可能会导致意外行为。尽管用户可以使用Kafka单消息转换谓词来解决这一限制,但我们认为任何有助于减少配置膨胀的措施都是有益的。
从现在开始,提取变更记录状态转换将始终为您的事件添加已更改和未更改的头部信息,即使事件是插入或删除操作,即使这些字段为空。
如果您依赖于提取变更记录状态转换的管道,我们不认为此变更会引入任何特定的向后兼容性问题。然而,我们建议您检查您的管道,以确保避免因使用谓词控制特定转换何时运行而可能产生的任何意外行为。
Reselect 列后处理器的错误处理模式
ReselectColumnsPostProcessor 设计用于补充流处理过程,根据连接器配置查询需要重新选择的特定列的当前值。此过程旨在无缝进行,如果查询失败,则会使用流式传输的列数据作为最后的手段。
已添加以下配置属性:
- reselect.error.handling.mode
- 指定在重新选择查询失败时如何处理错误。将其设置为 warn 时,当重新选择查询失败时会记录警告,并将流式传输的事件数据原样传递。将其设置为 fail 时,当重新选择查询失败时连接器将抛出异常。
reselect.error.handling.mode 的默认值为 warn,以保留旧的行为。
集中记录敏感数据
我们理解数据库中存储了各种信息,其中某些列可能包含敏感信息。我们非常重视确保这些信息的安全性和保密性。因此,通常情况下,我们倾向于避免在INFO、WARN或ERROR级别记录敏感信息。
然而,在某些潜在的特殊情况中,敏感列的值可能会在DEBUG或TRACE级别被记录。为了应对这种情况,我们在几个版本前添加了io.debezium.util.Loggings类以集中管理这一点,但并非所有实例都使用了这个Loggings类。
默认情况下,用户会注意到Loggings类会在日志中记录敏感信息,而不是将其包含在后续日志条目的原始记录器中。如果您希望省略敏感信息,可以通过日志配置为io.debezium.util.Loggings设置特定的日志级别。
例如,如果您需要将日志提供给某人但希望省略敏感信息,以下配置可以实现这一目标。
log4j.logger.io.debezium=TRACE,stdout
log4j.logger.io.debezium.util.Loggings=ERROR,stdout
此配置将在记录所有非敏感信息的同时省略所有敏感信息,日志级别为TRACE。
Debezium 存储模块
显式使用路径样式地址与 S3 存储
S3 SDK 在 2.18+ 版本中引入了一个小的行为变化,即 URL 的构建使用了虚拟主机样式而不是路径样式,这一点在 上游 S3 SDK 社区 中有讨论。虽然 S3 存储桶支持两种样式的 URL,但在某些情况下,包括测试案例,虚拟主机样式可能尚未得到支持。
我们添加了一个新的配置选项 schema.history.internal.s3.forcePathStyle,默认值为 false。在需要路径样式 URL 而不是虚拟主机样式 URL 的情况下,将此选项设置为 true 可以恢复旧的 URL 行为。
Debezium 用于 MariaDB
SSL 支持
我们引入了几个新的 MariaDB 特定模式,这些模式旨在允许 MariaDB 连接器使用 SSL 进行连接,并与 MariaDB 驱动程序兼容。下表描述了这些模式以及与 MySQL 模式的对应关系,如果您是从旧的 MySQL 连接器部署迁移到新的独立 MariaDB 连接器。
| 模式 | 描述 |
|---|---|
| disable | 禁用 SSL/TLS 连接。所有连接都是不安全的。这相当于 MySQL 的禁用模式。 |
| trust | 使用 SSL/TLS 进行加密,但不执行证书或主机名验证。这相当于 MySQL 的必需模式。 |
| verify-ca | 使用 SSL/TLS 进行加密并执行证书验证,但不执行主机验证。这相当于 MySQL 的 verify_ca 模式。 |
| verify-full | 使用 SSL/TLS 进行加密并执行证书和主机验证。这相当于 MySQL 的 verify_identity 模式。 |
对于 MariaDB,这些属性是通过 database.ssl.mode 属性传递的。
Debezium for MySQL
Percona 最小锁定
为了减少快照期间发生的锁定数量,针对使用 Percona 的 Debezium for MySQL 用户新增了一个 snapshot.locking.mode 选项。新的模式 minimal_percona_no_table_locks 提供了与 minimal_percona 相同的语义,但额外省略了表级锁的应用。这为某些不允许表锁的环境提供了一种替代方案。
改进的重复服务器 ID/UUID 错误处理
对于大多数连接器,Debezium 采用重试所有与 SQLException 或 IOException 相关的失败的策略。这一策略非常有用,允许用户根据需要利用运行时重试机制。
然而,对于 MySQL,当配置的服务器 ID/UUID 发生冲突时,会出现一个独特的边缘情况。MySQL 使用服务器 ID/UUID 在集群拓扑中唯一标识一个实例。如果多于一个服务器使用相同的 ID/UUID,实例将抛出 SQLException 并在启动时进入重试/退避循环。
我们调整了错误处理方式,使得在这种特定的唯一情况下优先采用快速失败的方法。如果您是 MySQL 用户,并且发现您的连接器更频繁地进入 FAILED 状态,我们建议您检查这是否适用于您的情况。如果是,请确保您的配置始终使用唯一的服务器 ID/UUID 值。
Debezium for Oracle
新的 Oracle LogMiner JMX 指标
我们为 Debezium Oracle 连接器添加了一个新的 JMX 指标,即 MinedLogFileNames。此指标返回一个字符串数组(String[]),包含当前 LogMiner 会话中正在读取的日志文件名。
当用户报告 Oracle 连接器存在延迟时,我们首先检查的是在挖掘会话中读取的日志数量。如果添加了异常大量的日志,这可能会在 Oracle LogMiner 从磁盘读取所有这些日志时造成瓶颈。
该指标提供了对挖掘日志数量的可见性,而无需调整连接器的日志记录级别。如果您观察到延迟,首先需要检查的就是这个指标中的日志数量。
大量的日志通常表明您的数据库可能存在高活动窗口期。
新增的源信息 scn 和时间戳字段
在 Oracle 变更事件的源信息块中添加了几个新字段。这些新的源字段包括:
- commit_ts_ms这指定了事件事务提交的时间(以毫秒为单位)。
- start_scn这指定了事件事务中观察到的第一个事件的 SCN。
- start_ts_ms这指定了事件事务中第一个事件被用户更改的时间(以毫秒为单位)。
- 这些新字段是可选的,因此使用模式注册表的用户应该发现这些更改是向后兼容的。
- Oracle 的 SCN 值不是唯一的,因此多个事件可能具有相同的 SCN 值和时间戳。在使用这些值进行任何类型的事件排序时应谨慎。
Debezium for SQL Server
流式内存改进
Microsoft SQL Server 驱动程序在同一个连接上执行多个查询时无法复用连接。这通常会导致所有数据都被缓冲到内存中,这不仅效率低下,还可能导致内存问题。
Debezium 引入了一个新的配置选项 streaming.fetch.size,以帮助解决 SQL Server 驱动程序的这一限制。此配置选项指定了在流式读取时从每个表中一次性读取的最大行数。默认情况下,该值设置为 0,以便连接器行为保持不变。当设置为正数时,这将导致数据库进行多次数据往返,根据配置的读取大小分批获取数据。
始终使用聚簇索引(如果可用)
当 data.query.mode 设置为 direct 时,查询的 order by 子句可能性能较差,因为查询没有利用捕获表上的聚簇索引。这通常需要自定义数据库索引来实现良好的性能。
我们调整了查询以考虑这一点,并现在在结果集的 order by 子句中包含了 __$command_id。这使得数据库能够使用聚簇索引,大幅降低了查询成本,从而在不进行任何数据库索引自定义的情况下提高了整体性能。
Debezium for Vitess
发送二进制排序字符串数据类型为Kafka字符串
在较早的更改中,作为DBZ-6748的一部分,我们将连接器更改为将具有二进制排序的varchar列类型序列化为Kafka字符串类型。然而,其他基于字符的数据类型如text、tinytext、mediumtext、longtext、enum和set被忽略了,这些类型继续被序列化为字节数组。
现在行为已经统一,所有变体的text、enum和set数据类型都始终以Kafka字符串类型发出,即使列使用二进制排序(DBZ-8679,DBZ-8694)。
请注意,如果您使用模式注册表,这些列类型在使用二进制排序时的序列化方式的变化可能会引入向后兼容性问题。
Epoch/零日期列解析的更改
当一个日期列是零日期值时,根据该列的可选性,字段可能被发出为null或Unix纪元。这为消费者创建了一个无法解决的情况,因为它们无法区分提供纪元值时,它表示的是实际的纪元值还是源系统中的零日期的哨兵值。
为了解决这个问题,我们添加了override.datetime.to.nullable配置属性。当设置为默认的false时,这种情况下将继续使用旧的行为,在列不是可空但包含零日期时发出Unix纪元。这意味着消费者将继续无法区分这两种情况。
当设置为true时,所有日期和datetime列都被设置为可选,并且如果列的值代表零日期,则序列化为null。这允许消费者轻松地区分使用情况,并更适当地处理这些情况。
Keyspace心跳支持
在Vitess 21版本中为VStream引入了一种新的binlog水印策略。此新功能发送一个类似于“心跳”的事件,表示到所提供时间戳为止,该分片的binlog事件已被VStream客户端接收。
可以通过将新的配置选项vitess.stream.keyspace.heartbeats设置为true来包括写入keyspace心跳表的心跳事件(DBZ-8775)。table.include.list也应该包括心跳表,格式为<keyspace>.heartbeat。
提高入队速度
在对连接器进行性能测试时,识别出几个操作在每次事件调度时不必要的执行,浪费了宝贵的CPU周期。这导致内部队列经常为空,限制了连接器的整体吞吐量。
现在这些代码热点使用缓存值来最小化浪费的CPU周期。在负载下,缓冲区保持满载,性能是之前观察到的两倍(DBZ-8757)。
查询指定工作负载标签
大多数查询现在包含一个SQL提示/注释/*vt+ WORKLOAD_NAME=debezium */,以标识查询是由Debezium连接器执行的(DBZ-8861)。
Debezium JDBC 沉淀器
支持 MySQL/PostgreSQL 向量数据类型
在 2024 年末,作为 Debezium 3.0 的一部分,我们引入了多种向量数据类型,包括 MySQL/PostgreSQL 的向量以及 PostgreSQL 的 halfvec 和 sparsevec。随着 Debezium 3.1,我们扩展了这些数据类型的 JDBC 沉淀器支持()。这一新的映射包括几条规则:
MySQL 到 MySQL 或 MySQL 到 PostgreSQL,向量数据类型将自动映射。
PostgreSQL 向量到 PostgreSQL 或 MySQL,向量数据类型将自动映射。
如果目标是 PostgreSQL,则 halfvec 和 sparsevec 的复制将自动映射。
对于没有原生向量数据类型映射或不支持此类类型的数据库,字段无法直接写入目标系统。对于这种情况,可以使用 io.debezium.transforms.VectorToJsonConverter 转换来动态地将事件负载转换为 JSON 表示形式,这是大多数数据库普遍支持的格式。数据库中的目标列类型将根据数据库供应商不同,可能是 json、clob 或基于文本的列类型之一。
随着更多源数据库向量类型的加入,我们将在未来继续扩展这一功能。
性能改进
我们收到了社区的几份报告,在高流量期间,某些数据库经历了异常高的 CPU 使用率。经过调查,我们发现某些 SQL 查询执行过于频繁,导致高 CPU 使用率并减少了连接器的写入吞吐量()。现在用户应该会发现 JDBC 沉淀器的写入吞吐量更高,CPU 使用率也更加合理。
自动重试连接错误
对于 Kafka Connect 生产者,如果连接器抛出 RetriableException 并且 Kafka Connect 配置为支持错误重试,运行时将自动停止并重新启动连接器。这提供了一种处理资源释放和重新创建资源(如数据库连接)的有效方法。
但对于 Kafka Connect 消费者(沉淀器),连接器的工作生命周期有所不同。当连接器抛出错误时,不会停止并重新启动连接器,而是再次调用 put 方法。这在某些连接错误的情况下可能存在问题,因为特定资源不会自动重新创建。
从 Debezium 3.1 开始,一个新的 JDBC 沉淀器属性 connection.restart.on.errors 将允许 JDBC 沉淀器重试连接失败()。
将 BYTES 处理为 SQL Server 目标中的 VARBINARY
添加了一个新的 JDBC 沉淀器映射,用于将 Kafka BYTES 字段转换为 SQL Server 的 VARBINARY 列数据类型()。这使得源连接器可以将未知或其他二进制数据序列化为 Kafka BYTES 字段,并正确映射到具有 VARBINARY 列数据类型的 SQL Server 目标。
Debezium Server
新的 Milvus 接收器
Milvus 是一个开源的向量数据库,设计用于搜索和检索高维数据,如来自机器学习模型的嵌入。您可以使用 Milvus 处理从源数据库捕获的向量数据类型,或者通过转换从消息字段计算向量,然后将它们用作嵌入。
Milvus 接收器会摄入传入的消息,并将Debezium变更事件的“after”部分插入或更新到集合中。当观察到 Debezium 删除变更事件时,与之匹配的记录将从集合中移除。
要开始使用这个新的接收器,可以指定以下配置:
debezium.sink.type=milvus
debezium.sink.milvus.url=http://localhost:19530
debezium.sink.milvus.database=default
此外,您还可以通过应用自定义逻辑来修改 Milvus 汇的 Behavior,这些自定义逻辑为特定功能提供了替代实现。这些扩展点包括:
io.milvus.v2.client.MilvusClientV2.MilvusClientV2配置为访问目标集合的自定义 MilvusClientV2 客户端实例。io.debezium.server.StreamNameMapper自定义实现,将计划的目标主题名称映射到 Milvus 集合。默认情况下,名称中的点会被替换为下划线。
新的 InstructLab 接收器
InstructLab 是一个开源项目,旨在通过提供社区驱动的方法来增强大型语言模型(LLMs)的技能和知识训练,从而实现生成式人工智能的民主化。该项目使用了一种称为 LAB(大规模对齐聊天机器人)的技术。
InstructLab 接收器接收传入的消息,并根据映射到负载字段的上下文值生成一系列问题和答案,然后近乎实时地更新您的分类法技能和知识领域。
要开始使用这个新的接收器,必须指定几种关键类型的配置。
{"debezium.sink.type": "instructlab","debezium.sink.instructlab.taxonomy.base.path": "/mnt/ilab/taxonomy","debezium.sink.instructlab.taxonomies": "domainA,domainB","debezium.sink.instructlab.taxonomy.domainA.topic": ".*","debezium.sink.instructlab.taxonomy.domainA.question": "header:question","debezium.sink.instructlab.taxonomy.domainA.answer": "header:answer","debezium.sink.instructlab.taxonomy.domainA.domain": "a/subdir-a/subpath-a2/","debezium.sink.instructlab.taxonomy.domainB.topic": "my_topic","debezium.sink.instructlab.taxonomy.domainB.question": "value:field","debezium.sink.instructlab.taxonomy.domainB.answer": "value:field","debezium.sink.instructlab.taxonomy.domainB.context": "value:context","debezium.sink.instructlab.taxonomy.domainB.domain": "b/subdir-b/"
}
分类映射均使用 debezium.sink.instructlab.taxonomy.* 命名空间定义。这些映射使用了命名键,就像转换一样,为给定的分类定义了一组配置映射。每个分类映射定义了一个问题、答案和一个可选的上下文配置,该配置定义了事件中将用于该分类映射部分的值的来源位置。
每个分类域映射可以根据域的主题配置属性应用于一个或多个事件。这定义了一个正则表达式,用于匹配事件的主题。默认值是 .*,因此如果你省略主题配置属性,映射将始终应用于所有传入事件。
最后,域配置属性指定了一个以 / 分隔的目录列表,这些目录将附加到 taxonomy.base.path 属性后,唯一标识存储库中将创建或更新包含源映射值的 qna.yml 文件的目录。
基于键的批处理支持
我们在使用 Apache Pulsar 的 KeyShared 订阅时,增加了一个新的改进的吞吐量选项。配置选项 debezium.sink.pulsar.producer.batchBuilder 可以设置为 KEY_BASED,但默认值为 DEFAULT(DBZ-8563)。
当设置为使用 KEY_BASED 时,这种订阅模型会按顺序将具有相同键的消息交付给一个消费者。关于 Key_Shared 订阅模型的更多信息可以在 Apache Pulsar 文档中找到。
PubSub 源支持并发和压缩
为了提高与 Google PubSub 的吞吐量和容量,我们引入了几个新的配置属性来支持 PubSub 的并发和压缩。这些新的配置属性可以用于任何现有的 PubSub 配置中。
pubsub.concurrency.threads
这指定了用于向 Google PubSub 发布消息的线程数。这可用于扩大或限制由 Google PubSub 客户端库创建的 PubSub 线程数量。默认情况下,PubSink 使用客户端库的默认行为。
pubsub.compression.threshold.bytes
当设置为 0 或更大的值时,PubSub 源启用可选的压缩功能,以传输事件批次到 PubSub 终端。是否使用压缩由提供的阈值决定。如果批次的总字节数小于阈值,则不使用压缩。如果批次的总字节数等于或大于阈值,则使用压缩。
PubSub 源支持位置终端
在使用 PubSub 源时,pubsub.address 通常不足以满足生产系统的需求,特别是在需要与特定地理位置(即区域)终端交互的情况下。为了解决这个问题,我们引入了一个新的配置属性 pubsub.region。
新的 pubsub.region 属性允许指定要连接的 Google Cloud 区域,例如 us-central1 或 asia-northeast1。当指定后,Debezium 将使用特定于位置的 PubSub 终端,格式为 <region>-pubsub.googleapis.com:443。这允许连接到特定位置的终端而不是全局终端。
pubsub.region 和 pubsub.address 配置属性是互斥的。如果在配置中提供了 pubsub.address,则 pubsub.region 将被忽略。
RabbitMQ 源支持基于键的路由
我们改变了使用配置路由事件的方式。这种新方法采用基于策略的设计,保留了旧的行为并引入了新的基于键的路由机制(DBZ-8752)。
首先,rabbitmq.routingKeyFromTopicName 已被弃用,并将在未来的版本中移除。此功能已被合并到新的 rabbitmq.routingKey.source 配置属性中,它可以设置为以下值之一:
static
当使用静态路由源时,RabbitMQ 源将使用在源配置中指定的 rabbitmq.routingKey 静态值。由于该值是在配置中设置并在源启动时读取的,因此它是静态的,在源运行期间不会改变。
topic
当使用主题路由源时,RabbitMQ 源将根据目标主题名称获取路由键。这种模式替换了已弃用的 rabbitmq.routingKeyFromTopicName 配置属性的行为。
key
当使用新的键路由源时,RabbitMQ 源将根据事件记录的键获取路由键。这提供了灵活性,可以控制 RabbitMQ 使用原始 Debezium 变更事件的键进行路由,或者通过使用自定义转换在发送事件到 RabbitMQ 之前更改事件的键。
Debezium 平台
什么是 Debezium 平台?
一年前,我们开始了这一段令人难以置信的旅程,旨在为 Debezium Server 创建一个新的、现代化的用户界面,以简化在 Kubernetes 上部署 Debezium 的过程。我们非常兴奋地宣布,Debezium 3.1 是这一多年努力的第一个正式版本。
新的 Debezium 平台提供了一种基于现代管道的方法,可以在几秒钟内设计源和目标配置、转换链等。您可以使用 Helm 按照以下方式安装 Debezium 平台:
helm install debezium-platform --set domain.url=<您的域名> --version 3.1.0-final oci://quay.io/debezium-charts/debezium-platform
此外,此版本特别添加了一些用户界面的最终润色,包括新的搜索/列表视图切换、显示应用的转换和编辑连接器管道的功能,以及在配置管道时为有经验的用户提供智能编辑器。
谓词支持在转换用户界面中
团队一直在努力改进新的和即将推出的 Debezium 管理平台,这是一个用于在 Kubernetes 上部署 Debezium 的现代管理界面。
在此次发布中,我们很高兴地宣布,我们已经在单消息转换界面中添加了定义谓词的支持。以下是该新界面的快速预览。
夜间构建镜像
我们已经开始发布Debezium管理平台的夜间构建镜像,这是一个用于Kubernetes上Debezium部署的现代管理界面。
quay.io/debezium/platform-conductor:nightly
提供管理API的后端服务,用于编排和控制Kubernetes上的Debezium部署。
可以使用 docker pull quay.io/debezium/platform-conductor:nightly 获取此镜像。
quay.io/debezium/platform-stage:nightly
提供用户界面以与基于conductor的后端交互的前端。可以使用 docker pull quay.io/debezium/platform-stage:nightly 获取此镜像。
Debezium AI
介绍
Debezium AI 模块是 Debezium 3.1 中的一个全新组件。该模块的目标是将所有与人工智能相关的功能、实用工具等纳入 Debezium 的产品组合中。
如果您有兴趣在自己的项目中使用 Debezium Embedded 包含 Debezium AI 模块,可以通过导入以下 POM 文件到您的项目中来实现:
<dependency><groupId>io.debezium</groupId><artifactId>debezium-ai</artifactId><version>3.1.0.Final</version><type>pom</type>
</dependency>
基于 LangChain4j 的嵌入转换
作为 Debezium AI 模块的首批功能之一,基于 LangChain4j 的嵌入转换(Embeddings Transformation)使用了一种配置驱动的方法来定义一个输入值,该输入值将被提供给您选择的大型语言模型(LLM),并在事件的有效负载中附加一个生成的嵌入字段。
Debezium 支持 MiniLM 和 Ollama,但通过代码可以扩展以支持使用 LangChain4j 库的广泛模型。让我们花一些时间来讨论 Debezium 内置的实现。
MiniLM
all-MiniLM-L6-v2 模型是一个句子转换器,它可以将句子和段落映射为一个 384 维的密集向量。这些向量可用于聚类、语义搜索或比较等任务。
要在您的转换链中添加 MiniLM 的嵌入转换,只需添加以下内容:
{...,"transforms": "minilm","transforms.minilm.type": "io.debezium.ai.embeddings.FieldToEmbedding","transforms.minilm.field.source": "after.documentation","transforms.minilm.field.embedding": "after.embedded_documentation"
}在这个示例中,after.documentation 字段将被提供给 MiniLM 模型,模型生成的向量结果将添加到事件的 after.embedded_documentation 字段中。embeddings 字段将使用 Debezium 语义类型 io.debezium.data.vector.FloatVector,该类型包含一系列 32 位浮点值。
Ollama
Ollama 是一个开源解决方案,允许在本地运行、创建和共享大型语言模型(LLM),为基于云的AI服务提供了一种成本效益更高的替代方案。
要将 Ollama 的嵌入转换添加到您的转换链中,只需添加以下内容:
{...."transforms": "ollama","transforms.ollama.type": "io.debezium.ai.embeddings.FieldToEmbedding","transforms.ollama.embeddings.ollama.url": "<url-to-ollama>","transforms.ollama.embeddings.ollama.model.name": "<model-name>","transforms.ollama.embeddings.field.source": "after.documentation","transforms.ollama.embeddings.field.embedding": "after.embedded_documentation"
}
在这个例子中,after.documentation 字段将被提供给 Ollama 模型,模型生成的向量结果将添加到事件的 after.embedded_documentation 字段中。embeddings 字段将使用 Debezium 语义类型 io.debezium.data.vector.FloatVector,其中包含一系列 32 位浮点值。
Debezium AI Embeddings 实现使用 Java ServiceLoader 从类路径加载特定实现。你应该确保类路径上只有一个 Embeddings 依赖项,以保证转换使用正确的实现。
容器镜像
根据条件在 connect-base 镜像中包含组件
Debezium 的 Kafka 和 Connect 镜像都是从一个名为 connect-base 的单一公共镜像派生而来的。默认情况下,这个基础镜像会安装 Apicurio、Jolokia 和 OpenTelemetry 依赖项。这对于测试目的来说非常棒,但如果你希望使用 Debezium 的镜像作为你自己的基础镜像,可能更希望在这些依赖项对你的环境不必要时省略它们。
现在,connect-base 镜像可以根据条件省略这些依赖项中的任何一个。通过将 OTL_ENABLED、APICURIO_ENABLED 和 JOLOKIA_ENABLED 环境变量设置为 no,可以在构建镜像时省略这些依赖项,从而创建一个更小的镜像体积。
默认情况下,connect-base 镜像将继续安装这些依赖项,因此开箱即用的情况下没有镜像行为的变化。
Debezium 示例
Debezium 优化用于 GraalVM
变更数据捕获(CDC)在各种场景中被广泛使用,例如微服务通信、遗留系统现代化和缓存失效。这种模式的核心思想是检测和跟踪数据源(如数据库)中的变化,并将这些变化实时或近实时地传播到其他系统。Debezium 是一个提供多种数据源连接器的 CDC 平台。除了捕捉变化外,它还通过直观的用户界面提供了定义 Debezium 实例的转换能力。
相关文章:

Debezium日常分享系列之:Debezium 3.1.0.Final发布
Debezium日常分享系列之:Debezium 3.1.0.Final发布 重大改变Debezium Core事件源块现在带有版本号稀疏向量逻辑类型重命名更改了模式历史配置的默认值 Debezium Storage moduleJDBC 存储配置命名约定变更 Debezium for Oracle多个 Oracle LogMiner JMX 指标被移除重…...

LLaMA-Factory大模型微调全流程指南
该文档为LLaMA-Factory大模型微调提供了完整的技术指导,涵盖了从环境搭建到模型训练、推理和合并模型的全流程,适用于需要进行大模型预训练和微调的技术人员。 一、docker 容器服务 请参考如下资料制作 docker 容器服务,其中,挂…...

为什么芯片半导体行业需要全星APQP系统?--行业研发项目管理软件系统
为什么芯片半导体行业需要全星APQP系统?--行业研发项目管理软件系统 在芯片半导体行业,严格的合规性要求、复杂的供应链协同及高精度质量管理是核心挑战。全星研发项目管理APQP系统专为高门槛制造业设计,深度融合APQP五大阶段(从设…...

Linux make 检查依赖文件更新的原理
1. 文件的时间戳 make 主要依靠文件的时间戳来判断依赖文件是否有更新。每个文件在文件系统中都有一个时间戳,记录了文件的三种重要时间: 访问时间(Accesstime):文件最后一次被访问的时间。修改时间&…...

vulkanscenegraph显示倾斜模型(5.6)-vsg::RenderGraph的创建
前言 上一章深入分析了vsg::CommandGraph的创建过程及其通过子场景遍历实现Vulkan命令录制的机制。本章将在该基础上,进一步探讨Vulkan命令录制中的核心封装——vsg::RenderGraph。作为渲染流程的关键组件,RenderGraph封装了vkCmdBeginRenderPass和vkCmd…...
深度解析与优化之道)
解锁 Python 多线程的潜力:全局解释器锁(GIL)深度解析与优化之道
解锁 Python 多线程的潜力:全局解释器锁(GIL)深度解析与优化之道 引言 Python,这门以简洁和优雅著称的编程语言,自诞生以来在 Web 开发、数据分析、人工智能等领域大放异彩。然而,Python 的多线程性能却常被诟病,其核心原因之一便是全局解释器锁(Global Interpreter …...

基于阿里云可观测产品构建企业级告警体系的通用路径与最佳实践
前言 1.1 日常生活中的告警 任何连续稳定运行的生产系统都离不开有效的监控与报警机制。通过监控,我们可以实时掌握系统和业务的运行状态;而报警则帮助我们及时发现并响应监控指标及业务中的异常情况。 在日常生活中,我们也经常遇到各种各样…...
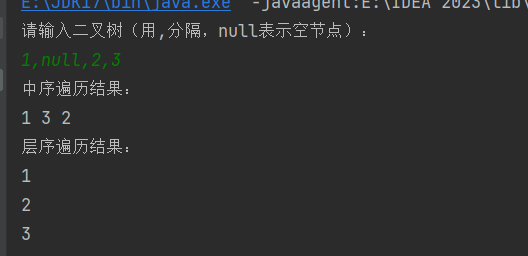
二叉树的ACM板子(自用)
package 二叉树的中序遍历;import java.util.*;// 定义二叉树节点 class TreeNode {int val; // 节点值TreeNode left; // 左子节点TreeNode right; // 右子节点// 构造函数TreeNode(int x) {val x;} }public class DMain {// 构建二叉树(层序遍历方式&…...

架构思维:查询分离 - 表数据量大查询缓慢的优化方案
文章目录 Pre引言案例何谓查询分离?何种场景下使用查询分离?查询分离实现思路1. 如何触发查询分离?方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。方式二:修改业务代码:…...

Qt进阶开发:QFileSystemModel的使用
文章目录 一、QFileSystemModel的基本介绍二、QFileSystemModel的基本使用2.1 在 QTreeView 中使用2.2 在 QListView 中使用2.3 在 QTableView 中使用 三、QFileSystemModel的常用API3.1 设置根目录3.2 过滤文件3.2.1 仅显示文件3.2.2 只显示特定后缀的文件3.2.3 只显示目录 四…...

后端开发常见的面试问题
目录 编程语言 python Linux环境 web框架 数据处理与分析 数据库 图数据库 什么是图数据库?它与传统关系型数据库有什么区别? 图数据库中的节点、边和属性分别代表什么? 常见的图数据库有哪些?它们各自有什么特点&#…...

List结构之非实时榜单实战
像京东、淘宝等电商系统一般都会有热销的商品榜单,比如热销手机榜单,热销电脑榜单,这些都是非实时的榜单。为什么是非实时的呢?因为完全实时的计算和排序对于资源消耗较大,尤其是当涉及大量交易数据时。 一般来说&…...
【C语言】字符串处理函数:strtok和strerror
在C语言中,字符串处理是编程的基础之一。本文将详细讲解两个重要的字符串处理函数:strtok和strerror 一、strtok函数 strtok函数用于将字符串分割成多个子串,这些子串由指定的分隔符分隔。其原型定义如下: char *strtok(char *s…...

如何提升后端开发效率:从Spring Boot到微服务架构
在现代软件开发中,后端开发的效率直接决定了项目的成败。随着技术的快速发展,Spring Boot、微服务架构、Docker等工具和技术已经成为提升后端开发效率的核心利器。在这篇文章中,我们将探讨如何通过使用Spring Boot及微服务架构来提升开发效率…...

go语言:开发一个最简单的用户登录界面
1.用deepseek生成前端页面: 1.提问:请你用html帮我设计一个用户登录页面,要求特效采用科技感的背景渲染加粒子流动,用css、div、span标签,并给出最终合并后的代码。 生成的完整代码如下: <!DOCTYPE h…...

基于 .NET 8 + Lucene.Net + 结巴分词实现全文检索与匹配度打分实战指南
文章目录 前言一、技术选型与优势1.1 技术栈介绍1.2 方案优势 二、环境搭建与配置2.1 安装 NuGet 包2.2 初始化核心组件 三、索引创建与文档管理3.1 构建索引3.2 动态更新策略 四、搜索与匹配度排序4.1 执行搜索4.2 自定义评分算法(扩展) 五、高级优化技…...

Docker安装、配置Nacos
1.如果没有docker-compose.yml文件的话,先创建docker-compose.yml 配置文件一般长这个样子 version: 3services:nacos:image: nacos/nacos-server:v2.1.1container_name: nacos2ports:- "8848:8848"- "9848:9848"environment:- MODEstandalone…...
《Maven高级应用:继承聚合设计与私服Nexus实战指南》
一、 Maven的继承和聚合 1.什么是继承 Maven 的依赖传递机制可以一定程度上简化 POM 的配置,但这仅限于存在依赖关系的项目或模块中。当一个项目的多个模块都依赖于相同 jar 包的相同版本,且这些模块之间不存在依赖关系,这就导致同一个依赖…...

重要头文件下的函数
1、<cctype> #include<cctype>加入这个头文件就可以调用以下函数: 1、isalpha(x) 判断x是否为字母 isalpha 2、isdigit(x) 判断x是否为数字 isdigit 3、islower(x) 判断x是否为小写字母 islower 4、isupper(x) 判断x是否为大写字母 isupper 5、isa…...
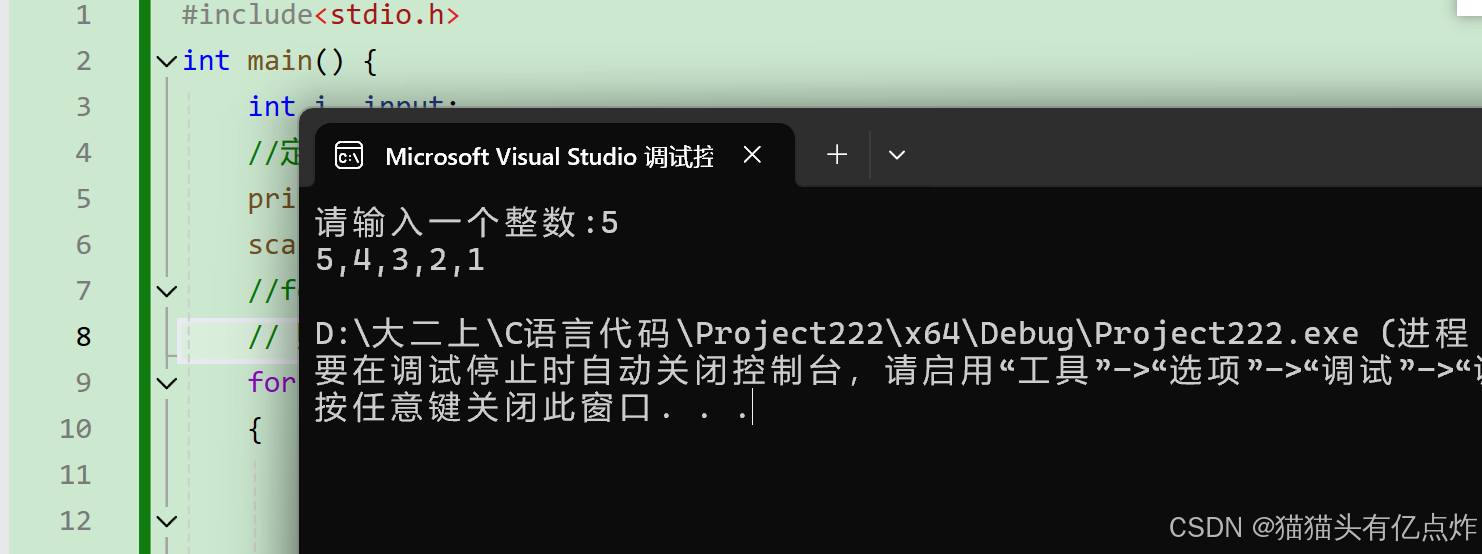
C语言数字分隔题目
一、题目引入 编写一个程序,打印出从用户输入的数字开始,递减到1的序列。要求每次打印一行,数字之间用逗号分隔,最后一个数字后面没有逗号。 二、代码展示 三、运行结果 四、思路分析 1.先用一个for循环对输入的数字进行递减 2.再对for循环里面的数字进行筛选 如果大于1 …...

DigitalOcean 发布 AMD Instinct MI300X GPU 裸金属服务器
DigitalOcean 宣布现已提供 AMD Instinct MI300X GPU,并搭载 ROCm 软件,以支持用户的 AI 任务。 在 DigitalOcean,我们致力于为你的项目提供更多选择。AMD Instinct MI300X 是目前带宽最高的 GPU 之一(5.3 TB/s 的 HBM3 内存带宽&…...
)
CentOS 7 镜像源失效解决方案(2025年)
执行 yum update 报错: yum install -y yum-utils \ > device-mapper-persistent-data \ > lvm2 --skip-broken 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile Could not retrieve mirrorlist http://mirror…...

应对高并发的根本挑战:思维转变【大模型总结】
以下是对这篇技术总结的详细解析,以分步说明的形式呈现,帮助理解亿万并发场景下的核心策略与创新思维: 一、应对高并发的根本挑战:思维转变 1. 传统架构的局限 问题:传统系统追求零故障和强一致性,但在海…...

ARM-外部中断,ADC模数转换器
根据您提供的图片,我们可以看到一个S3C2440微控制器的中断处理流程图。这个流程图展示了从中断请求源到CPU的整个中断处理过程。以下是流程图中各个部分与您提供的寄存器之间的关系: 请求源(带sub寄存器): 这些是具体的…...
git克隆数据失败
场景:当新到一家公司,然后接手了上一个同时的电脑,使用git克隆代码一直提示无法访问,如图 原因:即使配置的新的用户信息。但是window记录了上一个同事的登录信息,上一个同事已经被剔除权限,再拉…...
自动化备份全网服务器数据平台
自动化备份全网服务器数据平台 项目背景知识 总体需求 某企业里有一台Web服务器,里面的数据很重要,但是如果硬盘坏了数据就会丢失,现在领导要求把数据做备份,这样Web服务器数据丢失在可以进行恢复。要求如下:1.每天0…...

大模型如何优化数字人的实时交互与情感表达
标题:大模型如何优化数字人的实时交互与情感表达 内容:1.摘要 随着人工智能技术的飞速发展,数字人在多个领域的应用愈发广泛,其实时交互与情感表达能力成为提升用户体验的关键因素。本文旨在探讨大模型如何优化数字人的实时交互与情感表达。通过分析大模…...

AI Agent系列(八) -基于ReAct架构的前端开发助手(DeepSeek)
AI Agent系列【八】 项目目标一、核心功能设计二、技术栈选择三、Python实现3.1 设置基础环境3.2 定义AI前端生成的类3.4 实例化3.5 Flask路由3.6 主程序执行 四、 功能测试 项目目标 开发一个能够协助HTMLJSCSS前端设计的AI Agent,通过在网页中输入相应的问题&am…...

二级索引详解
二级索引详解 二级索引(Secondary Index)是数据库系统中除主键索引外的附加索引结构,用于加速基于非主键列的查询操作。以下是关于二级索引的全面解析: 一、核心概念 特性主键索引 (Primary Index)二级索引 (Secondary Index)唯一性必须唯一可以唯一或非唯一数量每表只有…...
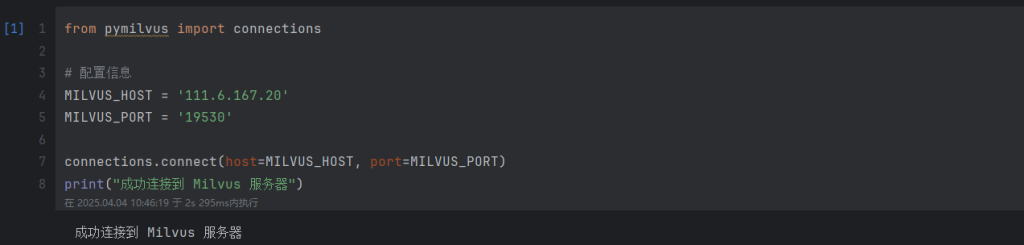
一文学会云服务器配置Milvus向量数据库
服务器准备 首先,我们需要进行服务器的准备,这里准备的是RTX-4090服务器 连接我们已经创建好的服务器,这里可使用MobaXterm进行ssh连接 ssh funhpcIP地址 一键完成Docker配置 注:docker的旧版本不一定被称为docker,doc…...