自编码器(AutoEncoder)概念解析与用法实例:压缩数字图像
目录
1. 前言
2. 自编码器的基本概念
2.1 自编码器的结构
2.2 损失函数
3. 使用 PyTorch 构建自编码器:压缩数字图像
3.1 导入必要的库
3.2 定义自编码器模型
3.3 准备数据集
3.4 训练模型
3.5 可视化重建结果
3.6 完整代码
4. 自编码器的应用场景
5. 总结
1. 前言
在深度学习领域,自编码器(AutoEncoder)是一种无监督学习模型,用于学习数据的压缩表示并从中重建原始数据。它的核心思想是通过一个“压缩-解压缩”的过程,提取数据的关键特征,同时尽可能保留原始信息。自编码器在降噪、图像压缩、异常检测等领域有着广泛的应用。
本文将从自编码器的基本原理入手,结合详细的 PyTorch 代码实现,帮助你全面理解自编码器的工作机制,并通过一个完整的实例展示如何使用 PyTorch 构建和训练自编码器。
2. 自编码器的基本概念
自编码器是一种神经网络模型,主要由以下两部分组成:
-
编码器(Encoder):将输入数据压缩为低维的潜在空间表示(特征提取)。
-
解码器(Decoder):从潜在空间表示中重建原始数据(特征还原)。
自编码器的目标是尽可能准确地重建输入数据,同时通过瓶颈层(低维表示)限制模型的容量,从而学习到数据的高效表示。
2.1 自编码器的结构
自编码器的结构通常对称,分为以下三个主要部分:
-
输入层:接收原始数据。
-
隐藏层(瓶颈层):低维的潜在空间表示,用于捕捉数据的关键特征。
-
输出层:重建的原始数据。
2.2 损失函数
自编码器通常使用均方误差(MSE)或二元交叉熵(BCE)作为损失函数,衡量重建数据与原始数据之间的差异。
3. 使用 PyTorch 构建自编码器:压缩数字图像
以下是使用 PyTorch 构建和训练自编码器的完整代码示例:
3.1 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt3.2 定义自编码器模型
class Autoencoder(nn.Module):def __init__(self):super(Autoencoder, self).__init__()# 编码器部分self.encoder = nn.Sequential(nn.Linear(28 * 28, 128), # 输入维度为 28x28,输出维度为 128nn.ReLU(True),nn.Linear(128, 64), # 输入维度为 128,输出维度为 64nn.ReLU(True),nn.Linear(64, 12) # 输入维度为 64,输出维度为 12(瓶颈层))# 解码器部分self.decoder = nn.Sequential(nn.Linear(12, 64), # 输入维度为 12,输出维度为 64nn.ReLU(True),nn.Linear(64, 128), # 输入维度为 64,输出维度为 128nn.ReLU(True),nn.Linear(128, 28 * 28), # 输入维度为 128,输出维度为 28x28nn.Sigmoid() # 使用 Sigmoid 激活函数,输出范围在 [0, 1])def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x3.3 准备数据集
# 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 将图像转换为 Tensor
])# 加载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=False)3.4 训练模型
# 初始化模型、损失函数和优化器
model = Autoencoder()
criterion = nn.MSELoss() # 使用均方误差作为损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用 Adam 优化器# 训练模型
num_epochs = 10
for epoch in range(num_epochs):for data in train_loader:img, _ = dataimg = img.view(img.size(0), -1) # 将图像展平为一维向量# 前向传播output = model(img)loss = criterion(output, img)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 每个 epoch 打印一次损失print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')3.5 可视化重建结果
# 测试模型并可视化重建结果
with torch.no_grad():for data in test_loader:img, _ = dataimg = img.view(img.size(0), -1)output = model(img)break# 可视化原始图像和重建图像
plt.figure(figsize=(10, 5))
for i in range(5):plt.subplot(2, 5, i+1)plt.imshow(img[i].reshape(28, 28).numpy(), cmap='gray')plt.title('Original')plt.axis('off')plt.subplot(2, 5, i+6)plt.imshow(output[i].reshape(28, 28).numpy(), cmap='gray')plt.title('Reconstructed')plt.axis('off')
plt.tight_layout()
plt.show()3.6 完整代码
完整代码如下用于调试
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as pltclass Autoencoder(nn.Module):def __init__(self):super(Autoencoder, self).__init__()# 编码器部分self.encoder = nn.Sequential(nn.Linear(28 * 28, 128), # 输入维度为 28x28,输出维度为 128nn.ReLU(True),nn.Linear(128, 64), # 输入维度为 128,输出维度为 64nn.ReLU(True),nn.Linear(64, 12) # 输入维度为 64,输出维度为 12(瓶颈层))# 解码器部分self.decoder = nn.Sequential(nn.Linear(12, 64), # 输入维度为 12,输出维度为 64nn.ReLU(True),nn.Linear(64, 128), # 输入维度为 64,输出维度为 128nn.ReLU(True),nn.Linear(128, 28 * 28), # 输入维度为 128,输出维度为 28x28nn.Sigmoid() # 使用 Sigmoid 激活函数,输出范围在 [0, 1])def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x# 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 将图像转换为 Tensor
])# 加载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=False)# 初始化模型、损失函数和优化器
model = Autoencoder()
criterion = nn.MSELoss() # 使用均方误差作为损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用 Adam 优化器# 训练模型
num_epochs = 10
for epoch in range(num_epochs):for data in train_loader:img, _ = dataimg = img.view(img.size(0), -1) # 将图像展平为一维向量# 前向传播output = model(img)loss = criterion(output, img)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 每个 epoch 打印一次损失print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')print(img.shape)# 测试模型并可视化重建结果
with torch.no_grad():for data in test_loader:img, _ = dataimg = img.view(img.size(0), -1)output = model(img)breakprint(img.shape)# 可视化原始图像和重建图像
plt.figure(figsize=(10, 5))
for i in range(6):plt.subplot(2, 6, i+1)plt.imshow(img[i].reshape(28, 28).numpy(), cmap='gray')plt.title('Original')plt.axis('off')plt.subplot(2, 6, i+7)plt.imshow(output[i].reshape(28, 28).numpy(), cmap='gray')plt.title('Reconstructed')plt.axis('off')
plt.tight_layout()
plt.show()4. 自编码器的应用场景
自编码器在许多领域都有广泛的应用,以下是一些典型的场景:
-
降噪:通过学习数据的干净和噪声版,可以去除图片的噪声。
-
图像压缩:通过有效的编码方式减少图像存储数据的需求。
-
异常检测:在工业监控和医疗影像中,识别未见过的模式。
-
特征提取:作为预训练模型,为下游任务(如分类)提供更好的特征表示。
5. 总结
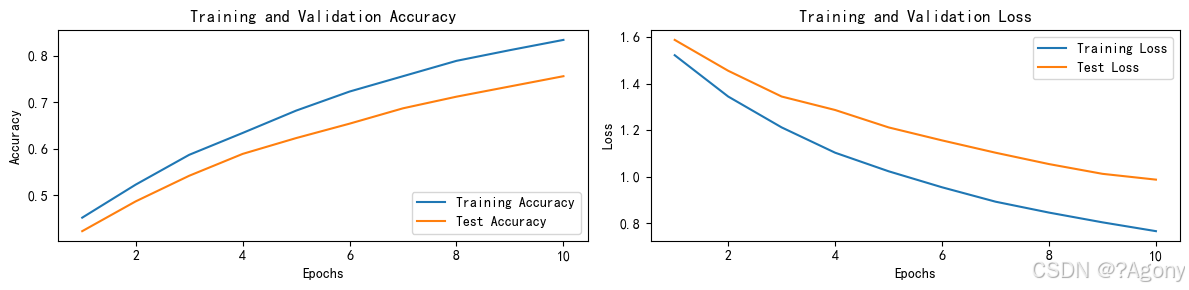
自编码器是一种强大的无监督学习模型,能够自动学习数据的特征表示并用于重建原始数据。通过 PyTorch,构建和训练自编码器变得简单高效。本文通过一个完整的实例,展示了如何使用 PyTorch 实现自编码器,并可视化了重建效果。
自编码器的核心在于通过“压缩-解压缩”的过程提取数据的关键特征,虽然它在某些任务上可能不如更复杂的模型(如变分自编码器或生成对抗网络),但它仍然是一个非常有用的工具,尤其是在特征提取和降维任务中。希望本文能帮助你入门自编码器的实现,并激发你在此领域的进一步探索!我是橙色小博,关注我,一起在人工智能领域学习进步!
相关文章:
概念解析与用法实例:压缩数字图像)
自编码器(AutoEncoder)概念解析与用法实例:压缩数字图像
目录 1. 前言 2. 自编码器的基本概念 2.1 自编码器的结构 2.2 损失函数 3. 使用 PyTorch 构建自编码器:压缩数字图像 3.1 导入必要的库 3.2 定义自编码器模型 3.3 准备数据集 3.4 训练模型 3.5 可视化重建结果 3.6 完整代码 4. 自编码器的应用场景 5. …...

从零开始打造HTML5拼图游戏:一个Canvas实战项目
从零开始打造HTML5拼图游戏:一个Canvas实战项目 先看效果: 你是否曾经被那些精美的网页拼图游戏所吸引?用 HTML5 的 Canvas 技术,从零开始,教你怎么画图、处理鼠标事件,还有游戏的核心逻辑,…...

每日一题洛谷P8649 [蓝桥杯 2017 省 B] k 倍区间c++
P8649 [蓝桥杯 2017 省 B] k 倍区间 - 洛谷 (luogu.com.cn) #include <iostream> #include <vector> using namespace std; #define int long long signed main() {int n, k;cin >> n >> k;vector<int> a(n 1);vector<int> sum(n 1);vec…...

在uniapp中,video比普通的标签层级高解决问题
<view style"position: relative;"><video style"position: absolute;z-index:-1"></video><view style"position: absolute;z-index:999"></view> </view> 上面代码并没有解决view的层级比video高的问题&…...

《探索边缘计算:重塑未来智能物联网的关键技术》
最近研学过程中发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击链接跳转到网站人工智能及编程语言学习教程。读者们可以通过里面的文章详细了解一下人工智能及其编程等教程和学习方法。下面开始对正文内容的…...
Linux(十二)信号
今天我们就要来一起学习信号啦!!!还记得小编在之前的文章中说过的ctrlc吗?之前小编没有详细介绍过,现在我们就要来学习啦!!! 一、信号的基本介绍 首先,小编带领大家先一…...

LeetCode算法题(Go语言实现)_30
题目 给定单链表的头节点 head ,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。 第一个节点的索引被认为是 奇数 , 第二个节点的索引为 偶数 ,以此类推。 请注意,偶数组和奇数组内…...
:5G NR通信频带划分与应用场景)
无线通信技术(三):5G NR通信频带划分与应用场景
目录 一.5G NR频带划分概述 二.全球运营商5G频带分配对比 三.5G频带的应用场景 5G网络的发展离不开频谱资源的合理分配。不同的频段决定了5G的覆盖范围、传输速率和应用场景。本文将系统介绍5G NR频带划分,并结合实际应用场景,理解不同频段的特性及其适用环境。 …...
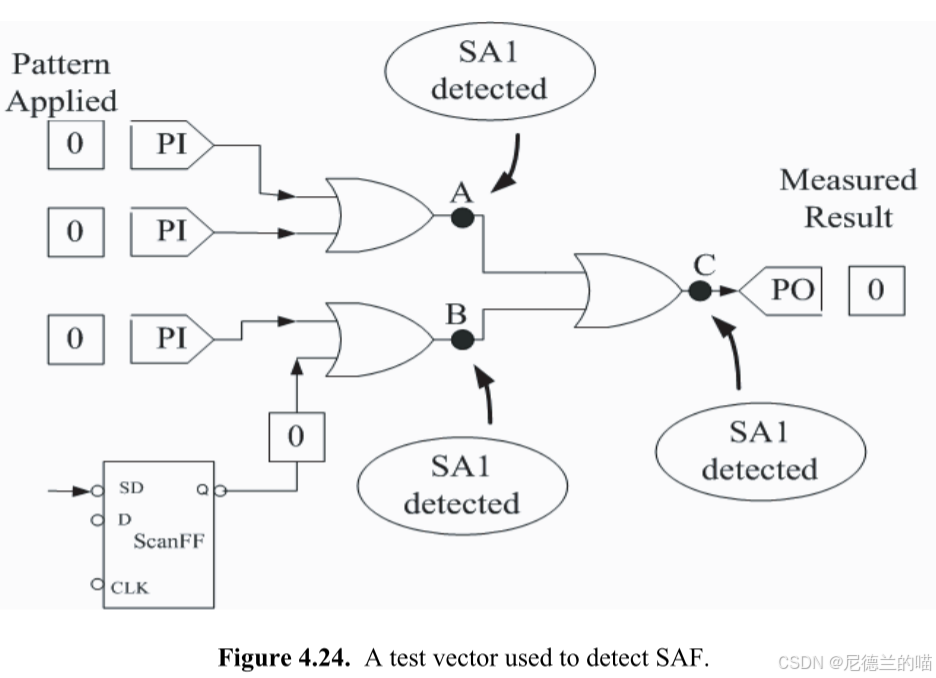
【读书笔记·VLSI电路设计方法解密】问题61:扫描插入的目的是什么
如问题60所述,要构建可测试电路,必须确保电路中每个节点都具有可控性和可观测性。但对于包含时序元件(如触发器、锁存器等存储元件)的电路,若不采取特殊设计则难以实现这两项特性。这是因为时序元件关联节点的逻辑状态不仅取决于当前输入,还受其先前存储状态影响——它们…...
VirtualBox安装FnOS
1.下载FnOS镜像 下载网址: https://www.fnnas.com/2.创建虚拟机 虚拟机配置如图所示(注意操作系统类型和网卡配置) (注意启动顺序) 3.启动虚拟机 网卡类型选择桥接的Virtual Adapter 如果没有IP地址或者IP地址无法…...

Pycharm(十二)列表练习题
一、门和钥匙 小X在一片大陆上探险,有一天他发现了一个洞穴,洞穴里面有n道门, 打开每道门都需要对应的钥匙,编号为i的钥匙能用于打开第i道门, 而且只有在打开了第i(i>1)道门之后,才能打开第i1道门&#…...
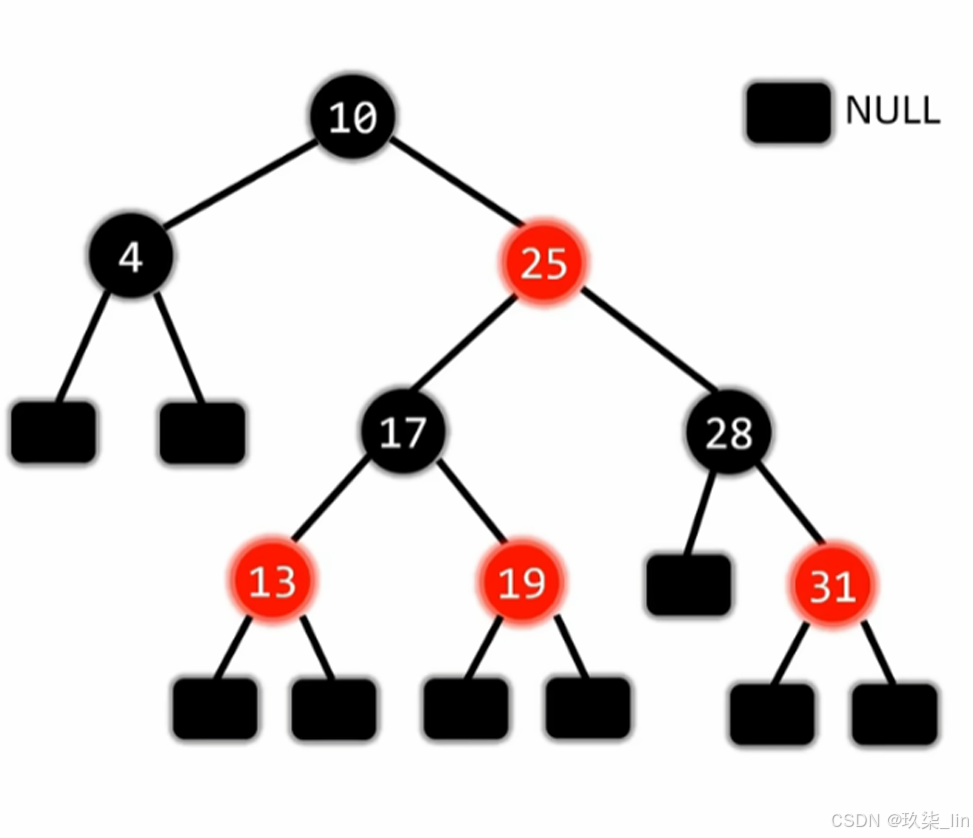
集合与容器:List、HashMap(II)
一、ArrayList 是集合框架中最核心的动态数组实现,高频使用的容器之一。 1. 核心数据结构 基于数组实现,维护elementData数组存储元素: transient修饰的elementData不会被默认序列化(通过自定义序列化逻辑优化存储)…...
)
Eclipse 视图(View)
Eclipse 视图(View) Eclipse 视图(View)是 Eclipse 界面的重要组成部分,它提供了用户交互的平台,使得用户可以通过图形界面来编辑、调试、分析代码等。在本文中,我们将深入探讨 Eclipse 视图的功能、使用方法以及它们在软件开发中的作用。 1. 视图的功能 Eclipse 视图具…...

《AI大模型应知应会100篇》第3篇:大模型的能力边界:它能做什么,不能做什么
第3篇:大模型的能力边界:它能做什么,不能做什么 摘要 在人工智能飞速发展的今天,大语言模型(LLM)已经成为许多领域的核心技术。然而,尽管它们展现出了惊人的能力,但也有明显的局限性…...

Springboot----@Role注解的作用
Role(BeanDefinition.ROLE_INFRASTRUCTURE) 是 Spring 框架中的一个注解,用于显式标记 Bean 的角色,表明该 Bean 是 Spring 容器内部的基础设施组件(如后置处理器、工具类等),而非用户直接使用的业务 Bean。其核心作用…...
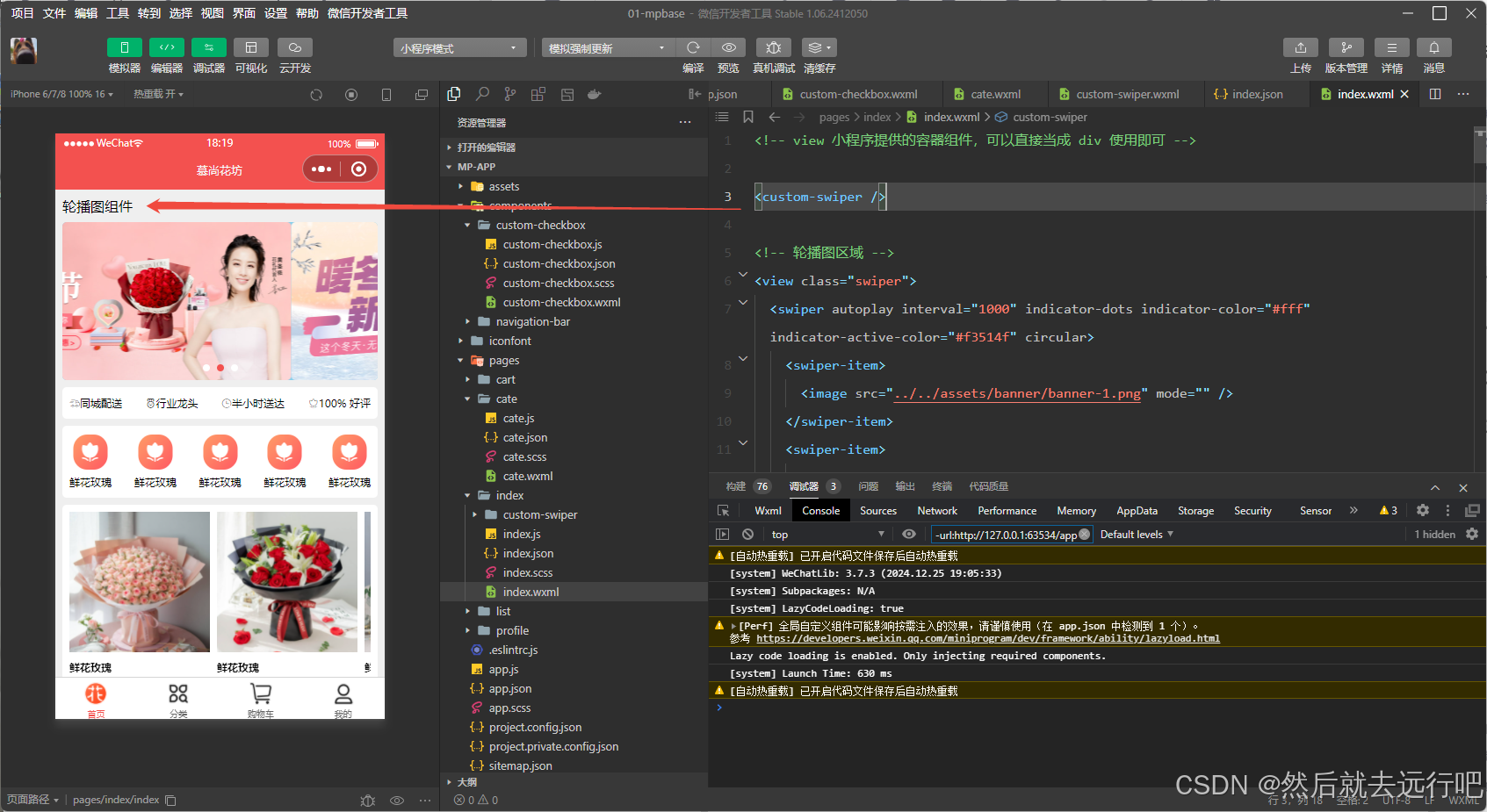
小程序API —— 58 自定义组件 - 创建 - 注册 - 使用组件
目录 1. 基本介绍2. 全局组件3. 页面组件 1. 基本介绍 小程序目前已经支持组件化开发,可以将页面中的功能模块抽取成自定义组件,以便在不同的页面中重复使用;也可以将复杂的页面拆分成多个低耦合的模块,有助于代码维护࿱…...
前端页面鼠标移动监控(鼠标运动、鼠标监控)鼠标节流处理、throttle、限制触发频率(setTimeout、clearInterval)
文章目录 使用lodashjs库手动实现节流(通过判断之前设定的定时器setTimeout是否存在) 使用lodashjs库 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Com…...
在 Android Studio 中运行安卓应用到 MuMu 模拟器
一、准备工作 1、确保 MuMu 模拟器已正确安装并启动 从官网下载安装最新版 MuMu 模拟器。启动后,建议在设置中调整性能参数(如 CPU 核心数和内存分配),以保证流畅运行。 2、配置 Android Studio 环境(按…...

从文本到多模态:如何将RAG扩展为支持图像+文本检索的增强生成系统?
目录 从文本到多模态:如何将RAG扩展为支持图像文本检索的增强生成系统? 一、为什么需要扩展到多模态? 二、多模态 RAG 系统的基本架构 三、关键技术点详解 (一)多模态嵌入(Embedding)技术 …...

【JavaEE】网络原理详解
1.❤️❤️前言~🥳🎉🎉🎉 Hello, Hello~ 亲爱的朋友们👋👋,这里是E绵绵呀✍️✍️。 如果你喜欢这篇文章,请别吝啬你的点赞❤️❤️和收藏📖📖。如果你对我的…...
)
Python项目-基于Flask的个人博客系统设计与实现(2)
源代码 续 {% extends base.html %}{% block title %}评论管理{% endblock %}{% block content %} <div class"container py-4"><div class"row"><div class"col-md-3"><div class"list-group mb-4"><a h…...
-python-流程图重构)
洛谷题单3-P1720 月落乌啼算钱(斐波那契数列)-python-流程图重构
题目描述 给定一个整数 N N N,请将该数各个位上数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零(参见样例 2)。 输入格式 一个整数 N N N。 …...

NOIP2013提高组.华容道
题目 509. 华容道 算法标签: 搜索, b f s bfs bfs, s p f a spfa spfa 思路 不难发现, 在人移动的过程中, 箱子是不动的, 从当前位置到下一个箱子旁边的位置不会移动箱子, 可以预处理出人在每个位置到其他位置的距离预处理, 从某一个状态出发, 走到另一个状态的最短路使…...

政安晨【超级AI工作流】—— 基于COZE探索有趣的主题互动问答工作流(同宇宙儿童提问机)
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本例,我们将从零展示如何创建一款专门针对儿童对某项主题进行问答的对话流智能体…...

Derivatives and Differentiation (导数和微分)
Derivatives and Differentiation {导数和微分} 1. Derivatives and Differentiation (导数和微分)1.1. Visualization Utilities 2. Chain Rule (链式法则)3. DiscussionReferences For a long time, how to calculate the area of a circle remained a mystery. Then, in Anc…...
P17_ResNeXt-50
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、模型结构 ResNeXt-50由多个残差块(Residual Block)组成,每个残差块包含三个卷积层。以下是模型的主要结构࿱…...

Ubuntu上离线安装ELK(Elasticsearch、Logstash、Kibana)
在 Ubuntu 上离线安装 ELK(Elasticsearch、Logstash、Kibana)的完整步骤如下: 一.安装验证 二.安装步骤 1. 在联网机器上准备离线包 (1) 安装依赖工具 #联网机器 sudo apt update sudo apt install apt-rdepends wget(2) 下载 ELK 的 .deb 安装包 #创建目录将安装包下载…...
PyCharm 下载与安装教程:从零开始搭建你的 Python 开发环境
PyCharm 是一款专为 Python 开发设计的集成开发环境(IDE),它提供了强大的代码编辑、调试、版本控制等功能,是 Python 开发者的必备工具之一。如果你是初学者,或者正在寻找一款高效的开发工具,这篇文章将帮助…...

TSMaster在新能源汽车研发测试中的硬核应用指南
——从仿真到标定,全面赋能智能汽车开发 引言:新能源汽车测试的挑战与TSMaster的破局之道 新能源汽车的快速发展对研发测试提出了更高要求:复杂的电控系统、高实时性通信需求、多域融合的验证场景,以及快速迭代的开发周期。传统测…...

C/C++的条件编译
一、什么是条件编译? 条件编译是指在编译阶段根据某些条件来决定是否编译某段代码。这通常通过预处理指令来实现,比如 #if、#ifdef、#ifndef、#else、#elif 和 #endif。 二、为什么使用条件编译? 跨平台开发:不同的操作…...