非阻塞IO,fcntl,多路转接,select,poll,epoll,reactor
IO次数会影响程序的效率,在编程中往往会尽量减少IO次数,用以提高程序的效率,例如缓冲区,就是减少IO次数提高效率的一种方式;而IO影响效率的最大原因其实是因为IO=等+拷贝,在进行IO时往往需要拷贝的数据就绪,或者其他资源就绪,才能进行拷贝,所以其中等是占据了IO的最大时间的;
1.五种IO模型
IO模型大致可以分为以下五种:
1.阻塞式
2.非阻塞,非阻塞轮询
3.信号激发式
4.异步IO(操作系统做等待动作)
5.多路复用/转接
主要讲解2.非阻塞轮询与4.多路复用
1.1 阻塞式 I/O (Blocking I/O)简述
- 描述:在阻塞式 I/O 模型中,当一个应用程序执行 I/O 操作(如读写文件、网络数据等)时,它会一直等待直到 I/O 操作完成。也就是说,程序会阻塞在该 I/O 操作上,直到数据被完全读取或写入。
- 优缺点:
- 优点:编程模型简单,易于理解和实现。
- 缺点:阻塞会导致 CPU 被空闲浪费。每次进行 I/O 操作时,进程必须等待,不能执行其他任务,效率较低。
例子:使用
read()或write()进行 I/O 操作时,如果没有数据可读,或者目标设备不可写,程序会一直等待,直到数据准备好。
1.2 非阻塞 I/O 和 非阻塞轮询
- 描述:在非阻塞 I/O 模型中,当执行 I/O 操作时,如果资源当前不可用(例如文件、网络等没有数据),操作会立即返回错误,通常是
EAGAIN或EWOULDBLOCK,而不是阻塞进程的执行。这样,应用程序可以继续执行其他任务,并定期检查 I/O 操作是否完成(即轮询)。- 优缺点:
- 优点:应用程序可以继续执行其他任务,避免了 I/O 操作的等待时间,适合需要高响应能力的场景。
- 缺点:需要不断地轮询检查 I/O 操作是否完成,可能会增加 CPU 的使用,造成一定的性能消耗。
例子:通过
open()加上O_NONBLOCK标志打开文件描述符,在调用read()或write()时,如果无法立即执行,函数会返回EAGAIN或EWOULDBLOCK错误,应用程序需要手动检查并再次尝试。
下面我们通过一些代码和例子来实现一下:
要实现非阻塞轮询的IO方式,只需要在打开文件时设置文件的flag标志位,就可以改变文件在不同情况下的等待方式,而想设置非阻塞等待方式,我们可以这样操作:
1.在open打开文件时设置O_NONBLOCK标志位
int openNoBlock(const string& file)
{int fd=open(file.c_str(),O_RDONLY|O_NONBLOCK,0666);if(fd<0){cout<<"open fail"<<endl;exit(-1);}return fd;
}上面的函数在打开file中路径时设置了O_NONBLOCK标志位,让file以非阻塞和只读的方式打开,之后在对这个file文件进行读操作时,就可以使用while循环非阻塞式的等待;
2.使用fcntl函数直接设置已经打开了的文件
void setNonBlock(int fd)//可以传递不同文件,修改不同文件为非阻塞等待
{int flag = fcntl(fd, F_GETFL);if (flag < 0){lg(ERROR, "fcntl file erroron:%d,%s", errno, strerror(errno));exit(-1);}else{fcntl(0, F_SETFL, flag | O_NONBLOCK);}
}完整代码:
network_code/IO_2025_2_27/testFcntl · future/Linux - 码云 - 开源中国
我们可以看到通过上面的fcntl函数也是可以将某个文件描述符代表的文件直接设置为非阻塞状态的;
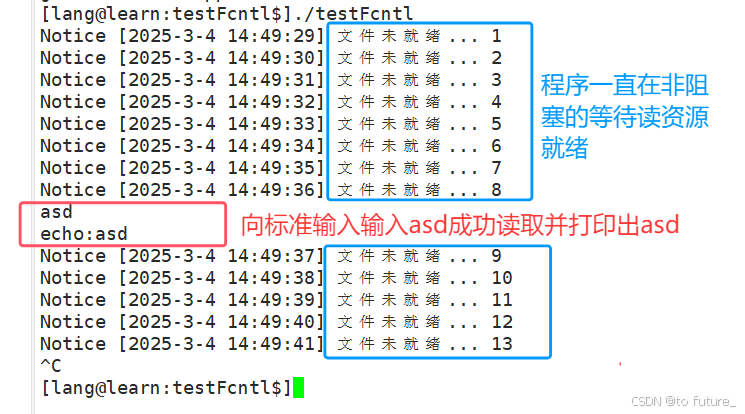
运行现象:
程序在一直打印的情况下读取到了键盘输入的字符"asd"并在读取到后直接输出;
还需要注意的是:使用非阻塞轮询时read返回值小于0并不一定是read错误,还有可能是文件未就绪,会返回
EWOULDBLOCK宏;
1.3 信号激发式 (Signal-driven I/O)简述
- 描述:在信号驱动 I/O 模型中,I/O 操作不会阻塞进程,且进程不会主动轮询 I/O 操作。相反,操作系统通过信号通知进程何时进行 I/O 操作。例如,当数据准备好时,内核通过发送一个信号(如
SIGIO)通知应用程序可以进行 I/O 操作。- 优缺点:
- 优点:进程不需要轮询或持续检查 I/O 状态,降低了 CPU 消耗。
- 缺点:信号处理机制可能会增加程序的复杂性,程序必须能正确处理这些信号。
例子:这个情况没有使用过,但是似乎和之前使用signal函数的情况差不多,在资源准备就绪的时候通过发送信号唤醒IO;
1.4 异步 I/O (Asynchronous I/O)简述
- 描述:在异步 I/O 模型中,应用程序发起 I/O 操作后,不需要等待操作完成,操作系统会在 I/O 完成时通知应用程序。异步 I/O 完全依赖操作系统来管理 I/O 操作的等待,应用程序不需要进行轮询或处理信号,而是通过回调函数、事件通知等机制来处理 I/O 操作的结果。将IO交给OS来处理,程序自己处理其他事件;
- 优缺点:
- 优点:极大地减少了 I/O 等待时间,CPU 可以继续执行其他任务,直到 I/O 操作完成。
- 缺点:实现复杂,应用程序需要能够处理回调或事件通知,并且操作系统也需要支持异步 I/O。
1.5 多路复用 (Multiplexing) / 多路转接
- 描述:多路复用是一种允许单一进程同时处理多个 I/O 操作的机制。在这个模型中,进程通过
select()或poll()等系统调用来检查多个文件描述符,判断哪些文件描述符准备好进行读写操作。当有一个或多个文件描述符准备好时,进程就会进行操作。- 优缺点:
- 优点:适用于需要同时处理多个 I/O 操作的场景,能够避免阻塞和过多的线程或进程切换。
- 缺点:虽然多路复用减少了阻塞和线程切换的开销,但它的实现仍然需要轮询文件描述符,且当描述符数量非常多时,性能可能会下降。
例子:
select()或poll()等调用允许程序监视多个文件描述符,直到某个描述符有数据可以读取,进程就可以进行相应的 I/O 操作。使用情况:一般是在网络服务器,如 Web 服务器,需要同时处理多个客户端请求时;
1.5.1 select

参数说明:
nfds:监视的文件描述符集合中最大的文件描述符加 1。通常用
FD_SETSIZE(例如:1024是linux中大小)来定义文件描述符的最大数量,nfds是文件描述符的范围,从 0 到nfds-1readfds:指向一个文件描述符集合,
select()会检查这些文件描述符是否可以进行读取操作。文件描述符会被加入集合(通常使用FD_SET,FD_CLR,FD_ISSET等宏来操作集合)
writefds:指向一个文件描述符集合,
select()会检查这些文件描述符是否可以进行写入操作。exceptfds:指向一个文件描述符集合,
select()会检查这些文件描述符是否有异常条件(例如,出错等)timeout:指定超时时间,用来限制等待文件描述符变为“准备就绪”的时间。
timeout是一个结构体,包含两个字段:tv_usec:表示微秒数。tv_sec:表示秒数。struct timeval {time_t tv_sec; // 秒数suseconds_t tv_usec; // 微秒数 };如果
timeout为NULL,则select()会一直阻塞,直到有文件描述符就绪或者信号中断。如果timeout的值为{0, 0},则select()会立即返回,不会阻塞。
返回值:
select与下面要讲的poll的返回值意义只在于辨别是否有准备就绪的文件,意义并不大
成功:
select()返回就绪的文件描述符数量,表示多少个文件描述符已经准备好进行相应的操作(读取、写入或异常)。失败:如果发生错误,返回
-1,并设置errno来指示具体错误类型。
errno错误代码:
EBADF:其中某个文件描述符无效。
EINVAL:nfds参数值无效。
ENOMEM:内存不足。使用注意事项:
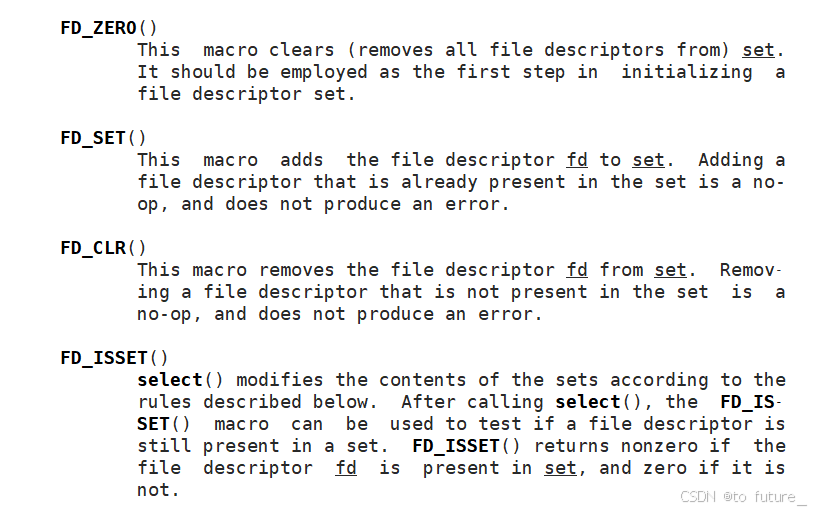
select()是一种阻塞式的 I/O 多路复用机制,适用于监控少量的文件描述符。当文件描述符数量较多时,select()的性能可能会降低。- 为了避免重复设置文件描述符集合,通常会在每次调用
select()前使用FD_ZERO()初始化集合,并使用FD_SET()添加文件描述符。
代码实现:
network_code/IO_2025_2_27/select · future/Linux - 码云 - 开源中国
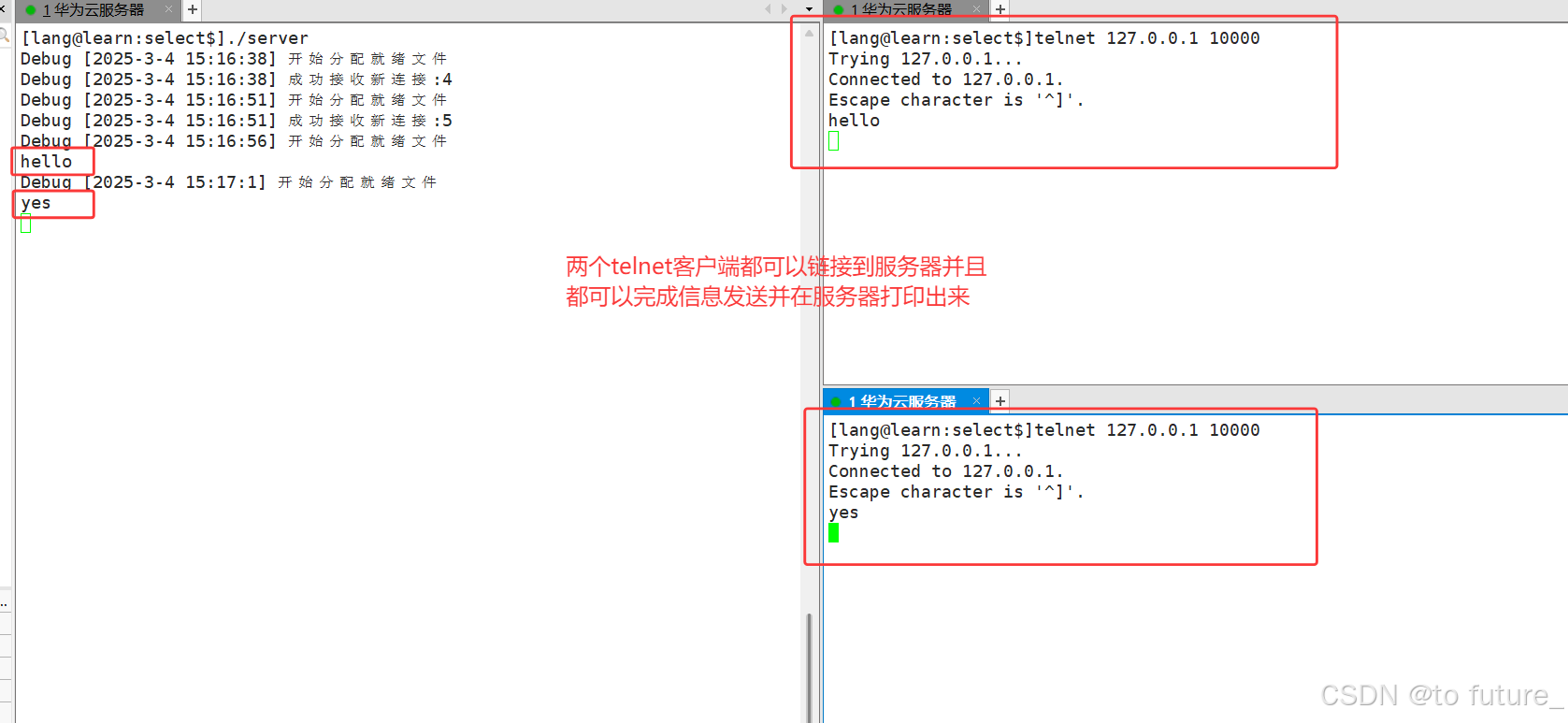
现象:
实现了允许程序监视多个文件描述符,直到某个描述符有数据可以读取,进程就可以进行相应的 I/O 操作。
select函数虽然可以完成对多个文件描述符的监视,但是这样的监视面临着大量的拷贝,需要不断地将fd_set这个内核数据结构从用户与内核之间拷贝,所以会大大降低效率;但其实这不是IO方式的问题,而是这个函数参数的问题,函数的fds表参数都是输入输出型参数所以会导致fds表被覆盖,所以需要不断的进行拷贝修改fds表;为了提高select的效率,我们接下来看看poll对其的提升(select改进的历史);
1.5.2 poll
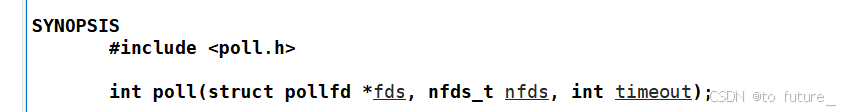
参数:
fds: 一个指向
struct pollfd数组的指针。每个struct pollfd结构表示一个文件描述符及其感兴趣的事件。struct pollfd {int fd; /* file descriptor */short events; /* requested events */short revents; /* returned events */};其中events是发送给poll,告诉它需要关系的事件,当某些事件就绪时就会返回revents;也就是说我们只需要填数据到events中,调用poll后返回的pollfd数据结构中的revents参数就会告诉我们哪些事件就绪了;
events与revents都是宏标志位,是short类型可以标识16个标志;
下面是参数可以填写的事件:
nfds: 要监视的文件描述符集合的大小(即
fds数组中元素的个数)timeout: 超时时间,单位为毫秒。
如果
timeout为-1,表示无限期等待,直到有事件发生。如果
timeout为0,表示不等待,立即返回。如果
timeout为正数,表示最大等待时间(以毫秒为单位)返回值:
- 成功: 返回就绪文件描述符的数量,即有多少文件描述符的事件已发生。
- 失败: 返回
-1,并设置errno以指示错误。- 超时: 如果在指定时间内没有事件发生,返回
0。
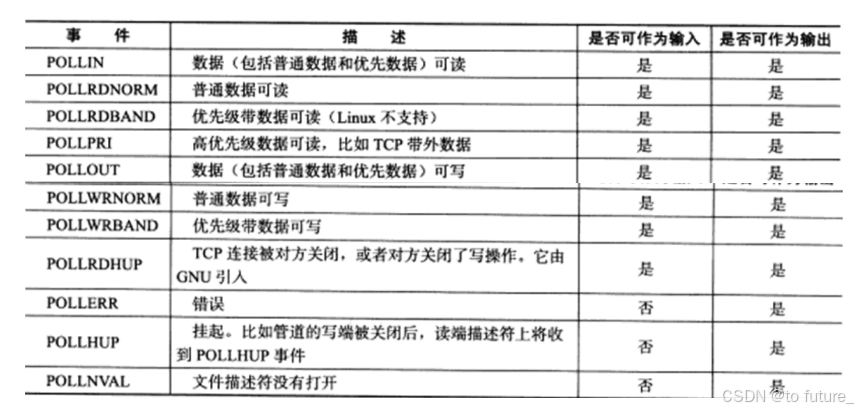
实现代码:
network_code/IO_2025_2_27/poll · future/Linux - 码云 - 开源中国
实现现象:
成功实现了和前面select一样的现象,并且代码简化了很多,而且提高了效率,这归咎于select的参数设置的并不是很好,文件描述符fd与关心的事件是分离的原因,而poll通过pollfd表这个数据结构将fd与fd需要关心的事件联系起来放在一个数据结构中,让用户使用更加方便,大大改善了select的不足;
poll成功的解决了select的这些缺点:
1.等待的fd是有上限
2.输入输出型参数比较多数据拷贝的频率比较高
3.输入输出型参数比较多每次都要对关心的fd进行事件重置
4·用户层,使用第三方数组管理用户的fd,用户层需要很多次遍历,内核中检测fd事件就绪,也要遍历
1.5.3 epoll
目前服务器编写公认的效率最高的多路转接方案;
epoll模型不再需要用户来维护需要关注的文件描述符表,而是将这个文件描述符表交给epoll模型来维护,只开放修改接口给用户,下面是交给用户的接口:
epoll_create:

参数:
size:该参数的含义在现代 Linux 系统中已不再重要,早期用于指定
epoll实例的大小,实际上现在的 Linux 内核忽略它。因此,size只需传递一个大于 0 的值,通常设置为1。但在一些文档或旧版本的内核中,它曾表示用于epoll内部的事件队列的大小。
返回值:
- 成功时,返回一个非负整数,这个整数是
epoll实例的文件描述符。你可以使用这个文件描述符在后续的操作(如epoll_ctl和epoll_wait)中进行访问和操作。- 失败时,返回
-1,并设置errno以指示错误原因。

epoll_wait:

参数:
epfd:
这是由epoll_create或epoll_create1返回的epoll实例的文件描述符,表示你要等待的事件来源。
events(输出型参数):返回已经就绪的文件描述符和事件:下面是
events的类型数据结构epoll_event中events中关心的事件一般有这些:
EPOLLIN:对应文件描述符可读。
EPOLLOUT:对应文件描述符可写。
EPOLLERR:对应文件描述符发生错误。
EPOLLHUP:对应文件描述符被挂起。
EPOLLET:边缘触发模式。
EPOLLONESHOT:一次性触发事件,事件发生后自动从epoll中移除。而data作用是:可以存放用户自定义的数据,通常是一个
void*类型的指针,方便在处理事件时关联文件描述符或其他数据。
maxevents:
指定events数组的大小,表示可以返回的最大事件数。如果发生的事件数超过这个值,epoll_wait会返回最大值。这个值通常应该设置为你期望处理的最大事件数。
timeout:
指定等待事件的超时值,单位是毫秒。可以设置以下几种:
-1:无限等待,直到至少一个事件发生。0:非阻塞模式,立即返回,不等待任何事件。- 正整数:表示等待时间,单位是毫秒。等待的最大时间。
返回值:
成功时: 返回发生的事件数,也就是
epoll_event数组中填充的事件个数。返回的事件数可以小于maxevents,表示当前发生的事件数目。失败时: 返回
-1,并设置errno来表示错误原因。
epoll_ctl:

参数说明:
epfd(int):epfd是由epoll_create()或epoll_create1()创建的epoll实例的文件描述符,用来标识一个epoll实例。
op(int):op表示操作类型,决定了epoll_ctl对文件描述符fd的处理方式,可能的值为:
EPOLL_CTL_DEL:从epoll实例中删除文件描述符,停止对其的监视。EPOLL_CTL_MOD:修改已经添加到epoll实例中的文件描述符的监视事件。EPOLL_CTL_ADD:将文件描述符fd添加到epoll实例中,开始监视该文件描述符。
fd(int):
fd是需要进行操作的文件描述符,通常是一个套接字、文件或管道的文件描述符。- 这个文件描述符会在
op为EPOLL_CTL_ADD或EPOLL_CTL_MOD时进行处理。
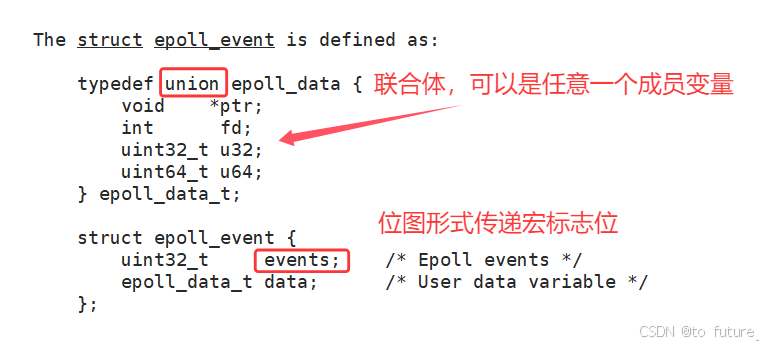
event(struct epoll_event *):
event是一个指向epoll_event结构体的指针,该结构体定义了感兴趣的事件以及附加的用户数据。epoll_event结构体的定义如下:struct epoll_event {__uint32_t events; // 事件类型,如 EPOLLIN, EPOLLOUT 等epoll_data_t data; // 用户数据,可以存储文件描述符、指针等 };events字段定义了感兴趣的事件类型,如:
EPOLLIN:可读事件EPOLLOUT:可写事件EPOLLERR:错误事件EPOLLHUP:挂起事件- 这里的事件是和上面的epoll_wait的event相同的;
data字段可以用于存储与文件描述符相关的任意数据,通常存储文件描述符或者其他相关的结构。data的数据结构也是和上面的epoll_wait中的data一样的;返回值:
- 成功:返回
0。- 失败:返回
-1,并设置errno来指示错误类型。常见的
errno错误值:
EBADF:epfd或fd不是有效的文件描述符。参数无效,通常是由于
EINVAL:op的值不正确,或者event为NULL,或其它不符合要求的情况。内存不足,无法分配内存来完成操作。
ENOMEM:权限不足,通常发生在没有足够权限执行某些操作时。
EPERM:
了解了epoll模型的接口后,接下来了解一下epoll模型的底层原理:
epoll模型其实和poll与select类似,都需要一个数据结构来存储用户要关心的文件描述符,但epoll不同与前面两种多路转接方式的地方是,epoll不再需要用户对这个文件描述符表数据结构直接进行维护,用户只需要调用epoll开放的接口来对这个文件描述符表来修改,而epoll模型底层维护的文件描述符表其实是一颗红黑树,红黑树的查找效率非常高(logn),在用户关心的文件描述符的某个事件在这个文件描述符表中可以查找到并且事件就绪时,这个时候就可以将这个文件描述符放入就绪队列,用户拿到就绪队列,就可以进行相对应事件的操作了
原理图片(复习用):
图片/epoll原理.png · future/my_road - 码云 - 开源中国
下面是我实现的epoll的代码:
network_code/IO_2025_2_27/4_epoll · future/Linux - 码云 - 开源中国
1.5.4 epoll工作模式
epoll有两种工作模式:
LT水平触发(epoll默认模式)
ET边缘触发
复习用:
图片/epoll工作模式.png · future/my_road - 码云 - 开源中国
其中LT模式,是epoll的默认模式,当我们epoll中关心的文件描述符中关心的事件就绪时,epoll会不断返回这些就绪的文件描述符的个数,通过epoll中维护的数据结构告诉我们哪些文件描述符的哪些事件就绪了,LT模式的重点就在于这个不断上,只有事件就绪我们不对这个事件做处理,那么epoll就会不断提醒(只要调用就会返回事件就绪);
而对于ET模式,当epoll中关心的文件描述符中关心的事件就绪时,epoll只会提醒一次,就是说我们下次调用epoll时,如果我们的就绪事件没有任何更新,那么epoll就不会再提醒了;
我们可以结合物理上的边缘触发和水平触发来理解,LT模式,电压高是就一直为高电平(有事件就绪就一直提醒),ET模式,只有电压发生变化时电平才发生改变(只有就绪事件发生改变时才会进行提醒)
那么我们在实际代码实现中,对于epoll我们应该如何设置这两种模式呢?首先LT模式的不断提醒的机制,虽然可以方便我们程序员编写代码,但是这样的机制其实相比于ET模式,效率会低一些;那么在编写代码时如果想使用ET模式编写(因为LT是默认模式所以一般不用直接设置),应该如何设置呢?我们在为epoll添加事件时就需要添加一个EPOLLET边缘触发模式的事件,让epoll以边缘触发ET的模式来关心事件;其次由于ET模式只在就绪事件发生变化(增加)时才提醒,如果我们处理就绪事件时只处理了一部分,那么这部分的就绪事件由于是一直存在的如果没有新的就绪事件添加,那么就会导致epoll不会再提醒,所以我们在处理就绪事件时需要一次处理完(用循环或者设置一个很大的缓冲区,一次将就绪事件内容全部获取走);但这样还不够,如果当我们获取事件时获取发现事件全部获取完了,我们继续获取由于获取函数的底层一般是阻塞的(例如read,如果文件暂时没有数据可以获取那么就会阻塞住),而我们的epoll是用来给服务器接受链接的,所以是万万不能阻塞的,那么我们就需要将我们的获取就绪事件的文件描述符设置为非阻塞模式(如何设置?可以通过我们前面讲的1.2中的fcntl函数来设置);所以自此我们的ET模式就设置好了;
设置ET模式:
1.在添加关心事件时多添加一个EPOLLET(例如我们关心读那么就添加EPOLLIN|EPOLLET)
2.将获取事件的文件描述符设置为非阻塞模式(fcntl设置O_NONBLOCK进fd的flag中)
小tip:LT模式效率设置文件描述符为非阻塞后像ET模式一样可以快速全部将就绪事件全部处理完,之后LT模式就不会提醒了,那么此时LT模式与ET模式就基本上没有什么区别了;
我们讲解了这么多接下来我们看看基于ET模式的代码实现吧:
1.5.5 reactor
这是一个基于epoll的ET模式的服务器,通过epoll不断添加或者去除关心的文件描述符中的事件,当这些事件就绪时进行提醒,从而形成了一个可以同步式处理多个用户请求的服务器;这样相比与我们前面使用的线程池来接收多个链接消耗会更小并且也可以接受多个链接;
代码实现:
network_code/IO_2025_2_27/5_reactor · future/Linux - 码云 - 开源中国
代码中有注释我就不详细讲解了,可以让AI来辅助理解;
这份代码值得注意的地方(复习用):
这份代码中对于写事件的处理:
对于智能指针的问题:
对于智能指针我们最好是先创建一个智能指针让后将其存储起来,创建这个智能指针的原因是我们要保存一份引用计数来确保智能指针指向的对象不会被析构;当我们还需要拷贝或者使用这个对象时,我们采用拷贝智能指针的方式来间接使用对象,以此来保证内存安全,当真正不需要这个对象时我们就可以对这个最后的保存进行释放即可,这样防止二次析构的情况出现;
相关文章:

非阻塞IO,fcntl,多路转接,select,poll,epoll,reactor
IO次数会影响程序的效率,在编程中往往会尽量减少IO次数,用以提高程序的效率,例如缓冲区,就是减少IO次数提高效率的一种方式;而IO影响效率的最大原因其实是因为IO等拷贝,在进行IO时往往需要拷贝的数据就绪,或…...

Redis常用的数据结构及其使用场景
字符串(String) string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。 string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据,比如jpg图片或者序列化的对象。 string 类型是 R…...

PhotoShop学习04
1.背景图层 最下面的被锁锁住的图层为背景图层,背景图层充当整个图层的背景,名字标注为背景,无法修改背景图层的排序始终位于图层最底部。 当我想把上方的图层移动到背景图层之后,发现无法移动图层无法移动,把背景图层…...
服务器有2张显卡,在别的虚拟环境部署运行了Xinference,然后又建个虚拟环境再部署一个可以吗?
环境: 云服务器Ubuntu系统 2张 NVIDIA H20 96GB Qwen2.5-VL-72B-Instruct-AWQ Qint4量化 AWQ 是 “Activation - Aware Weight Quantization” 的缩写,即激活感知权重量化。它是一种针对大型模型的先进量化算法,通过在权重量化过程中引入对激活值的感知,最小化量化误差…...

K8s中CPU和Memory的资源管理
资源类型 在 Kubernetes 中,Pod 作为最小的原子调度单位,所有跟调度和资源管理相关的属性都属于 Pod。其中最常用的资源就是 CPU 和 Memory。 CPU 资源 在 Kubernetes 中,一个 CPU 等于 1 个物理 CPU 核或者一个虚拟核,取决于节…...
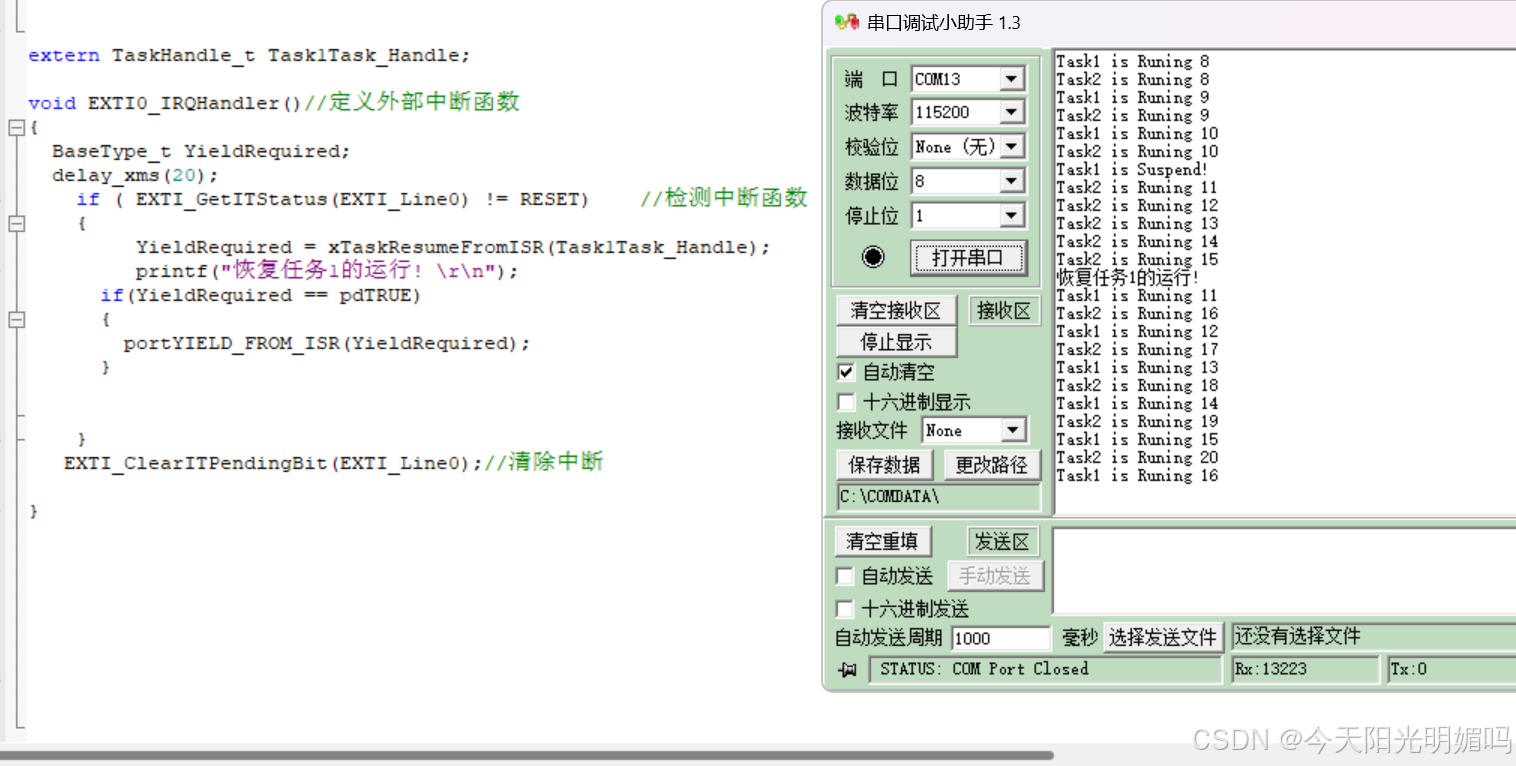
任务挂起和恢复
任务挂起和恢复API函数 下面用按键和震动传感器验证任务挂起和恢复API函数: PA7接震动传感器,按键引脚为PA0,提前初始化好GPIO引脚 key.c #include "key.h" #include "stm32f10x.h"void KeyInit() {GPIO_InitTypeDef …...
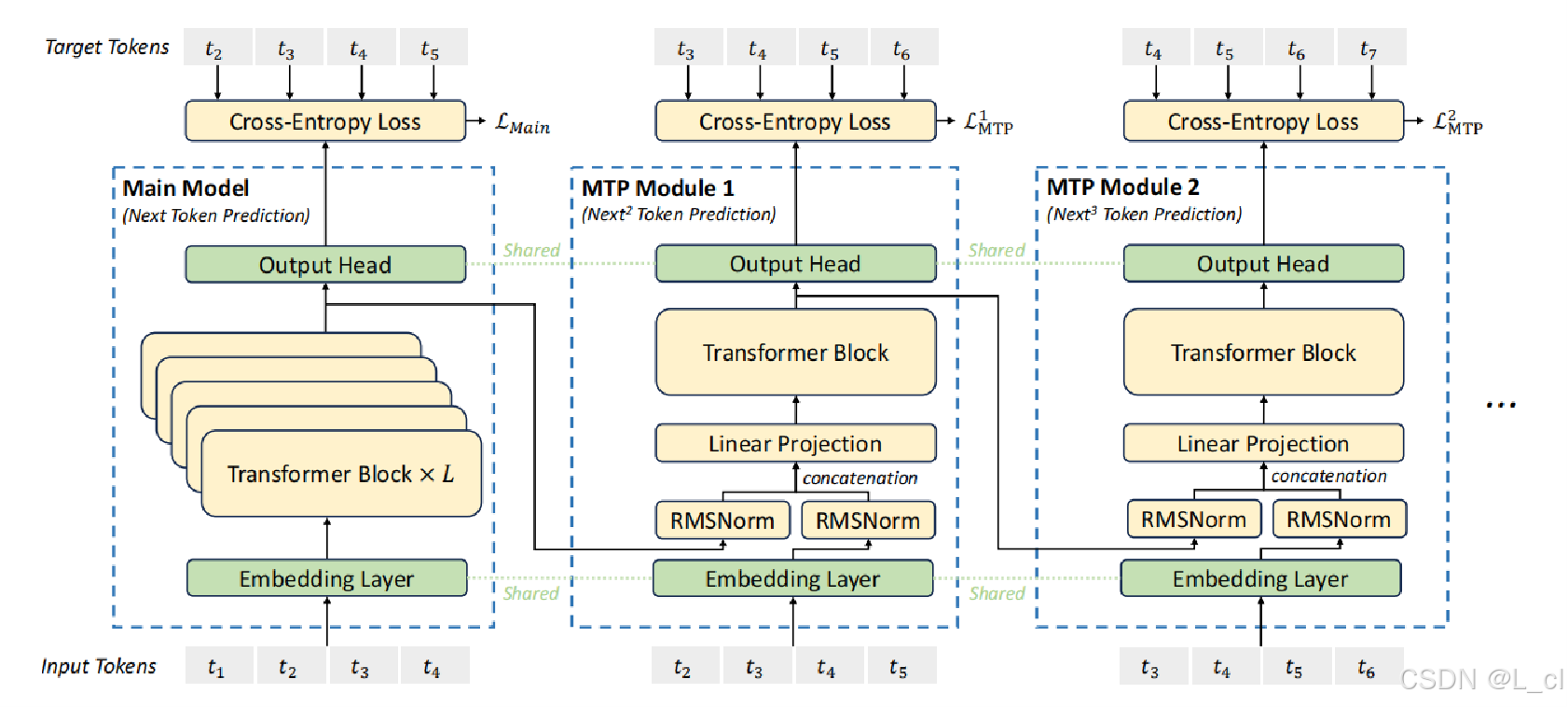
【NLP 55、投机采样加速推理】
目录 一、投机采样 二、投机采样改进:美杜莎模型 流程 改进 三、Deepseek的投机采样 流程 Ⅰ、输入文本预处理 Ⅱ、引导模型预测 Ⅲ、候选集筛选(可选) Ⅳ、主模型验证 Ⅴ、生成输出与循环 骗你的,其实我在意透了 —— 25.4.4 一、…...
如何在 Windows 上安装 Python
Python是一种高级编程语言,由于其简单性、多功能性和广泛的应用范围而变得越来越流行。如何在 Windows 操作系统中安装 Python 的过程相对简单,只需几个简单的步骤。 本文旨在指导您完成在 Windows 计算机上下载和安装 Python 的过程。 如何在 Windows…...

【Groovy快速上手 ONLY ONE】Groovy与Java的核心差异
最近在使用的平台上写脚本的语言是Groovy,所以也学习一下,作为 Java 开发者,Groovy 对我们来说会非常友好,而且它的语法更简洁且支持动态类型,所以其实了解下Java和Groovy的差异点就可以快速上手了,以下是 …...

计算机系统---CPU
定义与功能 中央处理器(Central Processing Unit,CPU),是电子计算机的主要设备之一,是计算机的核心部件。CPU是计算机的运算核心和控制核心,负责执行计算机程序中的指令,进行算术运算、逻辑运算…...

WEB安全--提权思路
一、情形 在我们成功上传webshell到服务器中并拿到权限时,发现我们的权限很低无法执行特定的命令,这时为了能做更多的操作,我们就需要提升权限。 二、方式 2.1、Windows提权 1、普通用户执行systeminfo命令获取服务器的基本信息࿰…...

多layout 布局适配
安卓多布局文件适配方案操作流程 以下为通过多套布局文件适配不同屏幕尺寸/密度的详细步骤,结合主流适配策略及最佳实践总结: 一、创建多套布局资源目录 按屏幕尺寸划分 在 res 目录下创建以下文件夹(根据设备特性自动匹配ÿ…...

selectdb修改表副本
如果想修改doris(也就是selectdb数据库)表的副本数需要首先确定是否分区表,当前没有数据字典得知哪个表是分区的,只能先show partitions看结果 首先,副本数不应该大于be节点数 其次,修改期间最好不要跑业务…...
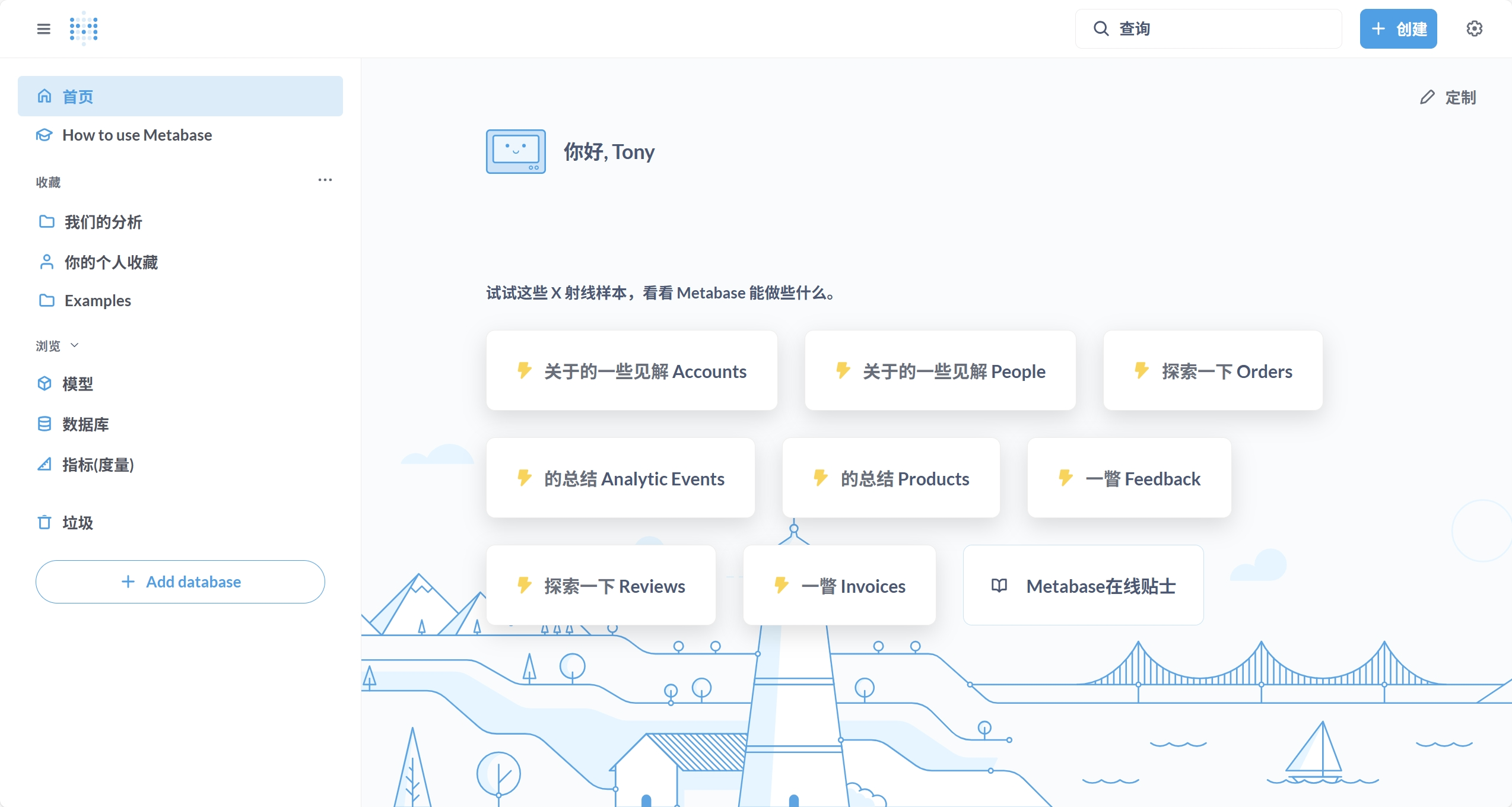
Metabase:一个免费开源的BI平台
今天给大家介绍一个开源数据可视化分析工具:Metabase。它可以帮助用户快速连接数据库、执行查询并创建交互式仪表盘,即使非技术人员也能快速上手。 Metabase 支持多种数据源,包括 MySQL、PostgreSQL、Oracle、SQL Server、SQLite、MongoDB、P…...

第15届蓝桥杯省赛python组A,B,C集合
过几天就省赛了,一直以来用的是C,Python蓝桥杯也是刚刚开始准备(虽然深度学习用的都是python,但是两者基本没有任何关系),这两天在做去年题时犯了很多低级错误,因此记录一下以便自己复查 PS&am…...

AWS 云运维管理指南
一、总体目标 高可用性:通过跨可用区 (AZ) 和跨区域 (Region) 的架构设计,确保系统运行可靠。性能优化:优化AWS资源使用,提升应用性能。安全合规:利用AWS内置安全服务,满足行业合规要求(如GDPR、ISO 27001、等保2.0)。成本管控:通过成本优化工具,减少浪费,实现FinOp…...

为什么有的深度学习训练,有训练集、验证集、测试集3个划分,有的只是划分训练集和测试集?
在机器学习和深度学习中,数据集的划分方式取决于任务需求、数据量以及模型开发流程的严谨性。 1. 三者划分:训练集、验证集、测试集 目的 训练集(Training Set):用于模型参数的直接训练。验证集(Validati…...

虚拟现实 UI 设计:打造沉浸式用户体验
VR UI 设计基础与特点 虚拟现实技术近年来发展迅猛,其独特的沉浸式体验吸引了众多领域的关注与应用。在 VR 环境中,UI 设计扮演着至关重要的角色,它是用户与虚拟世界交互的桥梁。与传统 UI 设计相比,VR UI 设计具有显著的特点。传…...
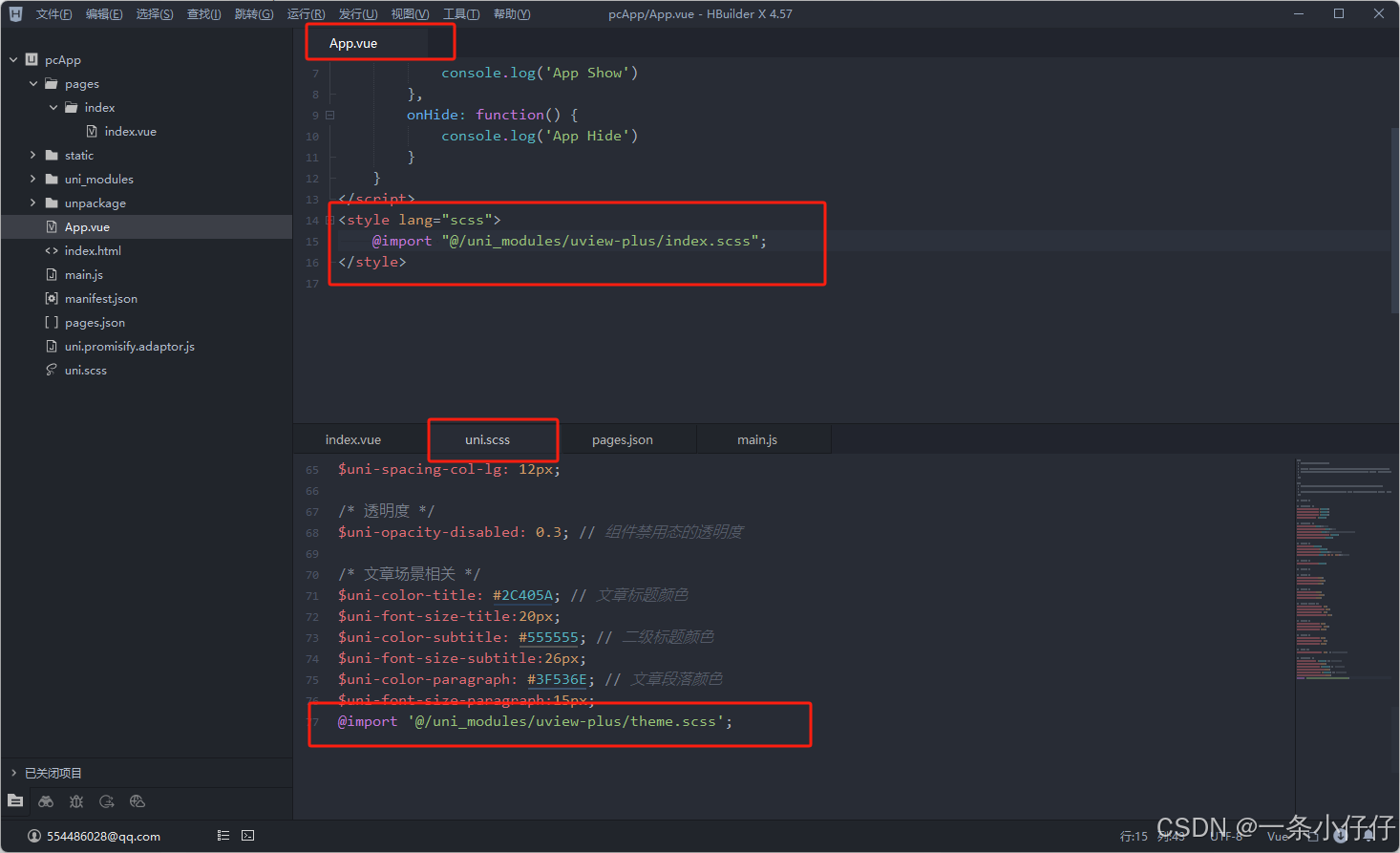
前端Uniapp接入UviewPlus详细教程!!!
相信大家在引入UviewPlusUI时遇到很头疼的问题,那就是明明自己是按照官网教程一步一步的走,为什么到处都是bug呢?今天我一定要把这个让人头疼的问题解决了! 1.查看插件市场 重点: 我们打开Dcloud插件市场搜素uviewPl…...

【性能优化点滴】odygrd/quill在编译期做了哪些优化
Quill 是一个高性能的 C 日志库,它在编译器层面进行了大量优化以确保极低的运行时开销。以下是 Quill 在编译器优化方面的关键技术和实现细节: 1. 编译时字符串解析与格式校验 Quill 在编译时完成格式字符串的解析和校验,避免运行时开销&…...

02 反射 泛型(II)
目录 一、反射 1. 反射引入 2. 创建对象 3. 反射核心用法 二、泛型 1. 泛型的重要性 (1)解决类型安全问题 (2)避免重复代码 (3)提高可读性和维护性 2. 泛型用法 (1)泛型类 …...

Spring Boot 七种事务传播行为只有 REQUIRES_NEW 和 NESTED 支持部分回滚的分析
Spring Boot 七种事务传播行为支持部分回滚的分析 支持部分回滚的传播行为 REQUIRES_NEW:始终开启新事务,独立于外部事务,失败时仅自身回滚。NESTED:在当前事务中创建保存点(Savepoint),可局部…...

ZLMediaKit 源码分析——[5] ZLToolKit 中EventPoller之延时任务处理
系列文章目录 第一篇 基于SRS 的 WebRTC 环境搭建 第二篇 基于SRS 实现RTSP接入与WebRTC播放 第三篇 centos下基于ZLMediaKit 的WebRTC 环境搭建 第四篇 WebRTC学习一:获取音频和视频设备 第五篇 WebRTC学习二:WebRTC音视频数据采集 第六篇 WebRTC学习三…...

元宇宙浪潮下,前端开发如何“乘风破浪”?
一、元宇宙对前端开发的新要求 元宇宙的兴起,为前端开发领域带来了全新的挑战与机遇。元宇宙作为一个高度集成、多维互动的虚拟世界,要求前端开发不仅具备传统网页开发的能力,还需要掌握虚拟现实(VR)、增强现实&#…...
2025年3月 Scratch 图形化(二级)真题解析 中国电子学会全国青少年软件编程等级考试
2025.03Scratch图形化编程等级考试二级真题试卷 一、选择题 第 1 题 甲、乙、丙、丁、戊五人参加100米跑比赛,甲说:“我的前面至少有两人,但我比丁快。”乙说:“我的前面是戊。”丙说:“我的后面还有两个人。”请从前往后(按照速度快慢&a…...

【新能源汽车整车动力学模型深度解析:面向MATLAB/Simulink仿真测试工程师的硬核指南】
1. 前言 作为MATLAB/Simulink仿真测试工程师,掌握新能源汽车整车动力学模型的构建方法和实现技巧至关重要。本文将提供一份6000+字的深度技术解析,涵盖从基础理论到Simulink实现的完整流程。内容经过算法优化设计,包含12个核心方程、6大模块实现和3种验证方法,满足SEO流量…...

MCP协议的Streamable HTTP:革新数据传输的未来
引言 在数字化时代,数据传输的效率和稳定性是推动技术进步的关键。MCP(Model Context Protocol)作为AI生态系统中的重要一环,通过引入Streamable HTTP传输机制,为数据交互带来了革命性的变化。本文将深入解读MCP协议的…...
dify中配置使用Ktransformer模型
一共是两个框架一个是Ktransformer,一个是dify。 Ktransformer用来部署LLM,比如Deepseek,而LLm的应用框架平台Dify主要用来快速搭建基于LLM应用。 这篇教程主要是用来介绍两个框架的交互与对接的,不是部署Ktransformer也部署部署Dify,要部署Dify、Ktransformer可以直接参考…...

从代码学习深度学习 - GRU PyTorch版
文章目录 前言一、GRU模型介绍1.1 GRU的核心机制1.2 GRU的优势1.3 PyTorch中的实现二、数据加载与预处理2.1 代码实现2.2 解析三、GRU模型定义3.1 代码实现3.2 实例化3.3 解析四、训练与预测4.1 代码实现(utils_for_train.py)4.2 在GRU.ipynb中的使用4.3 输出与可视化4.4 解析…...

二叉树 递归
本篇基于b站灵茶山艾府的课上例题与课后作业。 104. 二叉树的最大深度 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出&…...