公司论坛数据构建情感标注数据集思考
公司论坛有一个评论区,会有小伙伴在上面进行评论,聊天,大部份都是积极向上的,但是也有小小的一部分消极的言论,“就像白纸上的一个黑点”,和产品对接的大佬如是说。所以想思考做一个情感标注数据集,对负面的言论有快的处理方案,当然公司采用了一套成熟的流程,但是作者本人也进行了思考,从数据分析到LLM,常见的对文本处理的需求包含:
1、实体抽取,实体关系分析
2、文本情感分析
3、文本简介
4、文本构建次韵
5、文本分类标注
等等(嘿嘿嘿)
大佬们聊的在我的理解当中就是对现有的论坛数据进行标注或者对已经在前几年人事运用的数据基础上训练一个情感标注数据集,然后对之后的评论进行分析,所以自己有了以下思考,欢迎各位大佬指点:
整体思路
构建情感标准数据集的核心流程包括:数据收集、数据清洗、情感标注、质量控制和数据集划分。公司论坛数据通常包含丰富的用户表达,是构建情感分析数据集的优质来源。
实施步骤
1. 数据收集与初步处理
步骤说明:
-
从公司论坛API或数据库导出原始数据
-
提取相关字段(如帖子内容、评论、时间戳、用户ID等)
-
去除明显无关的内容(如广告、版规等)
代码示例:
import pandas as pd
import sqlite3
# 从SQLite数据库导出数据
def extract_forum_data(db_path):conn = sqlite3.connect(db_path)query = """SELECT post_id, user_id, content, timestamp, likes FROM forum_posts WHERE is_deleted = 0 AND is_ad = 0"""df = pd.read_sql(query, conn)conn.close()return df
# 示例使用
forum_data = extract_forum_data('company_forum.db')
print(forum_data.head())
2. 数据清洗与预处理
步骤说明:
-
去除HTML标签、特殊字符
-
处理缩写、拼写错误
-
分词与词性标注
-
去除停用词
代码示例:
import re
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
nltk.download('punkt')
nltk.download('stopwords')
def clean_text(text):# 去除HTML标签text = re.sub(r'<[^>]+>', '', text)# 去除特殊字符和多余空格text = re.sub(r'[^\w\s]', '', text)text = re.sub(r'\s+', ' ', text).strip()return text
def preprocess_text(text):text = clean_text(text)# 分词tokens = word_tokenize(text.lower())# 去除停用词stop_words = set(stopwords.words('english'))tokens = [word for word in tokens if word not in stop_words]return ' '.join(tokens)
# 应用预处理
forum_data['cleaned_content'] = forum_data['content'].apply(preprocess_text)
3. 情感标注策略
标注方法选择:
-
人工标注:最准确但成本高
-
半自动标注:结合规则和人工校验
-
自动标注:使用已有情感词典或预训练模型初步标注
这里结合业务场景,后来了解到确实有人事部的同时对现有的评论(尤其不好的评论)进行标注和处理,所以可以采用人工标准,但是还是把半自动标注的思路给大家列出来一些,不知道对不对,还请大家多多指点。
代码示例(半自动标注):
from textblob import TextBlob import numpy as np def auto_sentiment_label(text):analysis = TextBlob(text)# TextBlob返回极性得分在[-1,1]之间if analysis.sentiment.polarity > 0.1:return 'positive'elif analysis.sentiment.polarity < -0.1:return 'negative'else:return 'neutral' # 自动标注 forum_data['auto_label'] = forum_data['cleaned_content'].apply(auto_sentiment_label) # 抽样人工校验 sample_for_review = forum_data.sample(frac=0.1, random_state=42) sample_for_review['manual_label'] = None # 留待人工填写
4. 质量控制与标注一致性
步骤说明:
-
计算标注者间一致性(如Cohen's Kappa)
-
解决标注分歧
-
建立标注指南
代码示例:
from sklearn.metrics import cohen_kappa_score
# 假设我们有三位标注者的结果
annotator1 = ['positive', 'negative', 'neutral', 'positive']
annotator2 = ['positive', 'neutral', 'neutral', 'positive']
annotator3 = ['positive', 'negative', 'negative', 'positive']
# 计算两两之间的一致性
print(f"Annotator 1 & 2: {cohen_kappa_score(annotator1, annotator2)}")
print(f"Annotator 1 & 3: {cohen_kappa_score(annotator1, annotator3)}")
print(f"Annotator 2 & 3: {cohen_kappa_score(annotator2, annotator3)}")
5. 数据集划分与平衡
步骤说明:
-
按比例划分训练集、验证集和测试集
-
处理类别不平衡问题
代码示例:
from sklearn.model_selection import train_test_split # 假设我们已经有最终标注的DataFrame labeled_data = forum_data.dropna(subset=['final_label']) # 划分训练集和测试集 train_df, test_df = train_test_split(labeled_data, test_size=0.2, random_state=42,stratify=labeled_data['final_label'] # 保持类别比例 ) # 处理类别不平衡(可选) from imblearn.over_sampling import RandomOverSampler ros = RandomOverSampler(random_state=42) X_resampled, y_resampled = ros.fit_resample(train_df[['cleaned_content']], train_df['final_label'] )
6. 数据集保存与文档编写
步骤说明:
-
保存为标准格式(CSV/JSON)
-
编写数据集文档(README)
代码示例:
# 保存数据集
final_dataset = pd.DataFrame({'text': X_resampled['cleaned_content'],'label': y_resampled
})
final_dataset.to_csv('company_forum_sentiment_dataset.csv', index=False)
# 保存测试集
test_df[['cleaned_content', 'final_label']].to_csv('company_forum_sentiment_test.csv', index=False
)
进阶考虑
-
上下文感知:考虑帖子的上下文和回复关系
-
情感强度:不仅标注情感极性,还可标注强度等级
相关文章:

公司论坛数据构建情感标注数据集思考
公司论坛有一个评论区,会有小伙伴在上面进行评论,聊天,大部份都是积极向上的,但是也有小小的一部分消极的言论,“就像白纸上的一个黑点”,和产品对接的大佬如是说。所以想思考做一个情感标注数据集…...

MSF上线到CS工具中 实战方案(可执行方案)
目录 实际案例背景 步骤详解 1. 获取低权限 Meterpreter 会话 1.1 使用 Metasploit 获取会话 2. 提权到 SYSTEM 权限 2.1 使用 getsystem 自动提权 2.2 如果 getsystem 失败:使用令牌冒充 (incognito 模块) 3. 上线到 Cobalt Strike 3.1 生成 Cobalt Strik…...

ffmpeg中格式转换需要注意点总结
某些封装格式(例如MP4/FLV/MKV等)的H.264码流的SPS和PPS信息存储在AVCodeccontext结构体的extradata中。分离某些封装格式(例如MP4/FLV/MKV等)中的H.264的时候,需要首先写入SPS和PPS,否则会导致分离出来的数据没有SPS、PPS而无法播。需要使用ffmpeg中名称…...
IntelliJ IDEA 2020~2024 创建SpringBoot项目编辑报错: 程序包org.springframework.boot不存在
目录 前奏解决结尾 前奏 哈!今天在处理我的SpringBoot项目时,突然遇到了一些让人摸不着头脑的错误提示: java: 程序包org.junit不存在 java: 程序包org.junit.runner不存在 java: 程序包org.springframework.boot.test.context不存在 java:…...
基于DeepSeek、ChatGPT支持下的地质灾害风险评估、易发性分析、信息化建库及灾后重建
前言: 地质灾害是指全球地壳自然地质演化过程中,由于地球内动力、外动力或者人为地质动力作用下导致的自然地质和人类的自然灾害突发事件。在降水、地震等自然诱因的作用下,地质灾害在全球范围内频繁发生。我国不仅常见滑坡灾害,还…...

Websoft9分享:在数字化转型中选择开源软件可能遇到的难题
引言:中小企业数字化转型的必由之路 全球94.57%的企业已采用开源软件(数据来源:OpenLogic 2024报告),开源生态估值达8.8万亿美元。中小企业通过开源软件构建EPR系统、企业官网、数据分析平台等,可节省80%软件采购成本。…...

《在 Ubuntu 22.04 上安装 CUDA 11.8 和 Anaconda,并配置环境变量》
安装 CUDA 11.8 和 Anaconda 并配置环境变量 在本教程中,我们将介绍如何在 Ubuntu 22.04 上安装 CUDA 11.8 和 Anaconda,并配置相应的环境变量。我们还将配置使用 阿里云镜像源 来加速软件包更新。以下是具体步骤。 步骤 1:更新软件源 首先…...

【蓝桥杯】算法笔记3
1. 最长上升子序列(LIS) 1.1. 题目 想象你有一排数字,比如:3, 1, 2, 1, 8, 5, 6 你要从中挑出一些数字,这些数字要满足两个条件: 你挑的数字的顺序要和原来序列中的顺序一致(不能打乱顺序) 你挑的数字要一个比一个大(严格递增) 问:最多能挑出多少个这样的数字? …...

Windows修改hosts文件让向日癸软件联网
Windows修改hosts文件让向日癸软件联网 前言一、查看向日葵软件使用的网址及IP1.清除dns记录2.打开向日葵软件并将dns记录导出txt 二、修改Windows服务器的hosts文件1.winx选择Windows PowerShell(管理员)2.在Windows PowerShell中输入如下内容:3.在hosts文件最后添…...

2021 CCF CSP-S2.括号序列
题目 4091. 括号序列 算法标签: 区间 d p dp dp 思路 区间 d p dp dp添加维表示形态 f [ i ] [ j ] [ k ] f[i][j][k] f[i][j][k], 对于每种形态考虑状态如何进行转移, 枚举的时候不能重复, 星号也要定义唯一的解析方式, 算法时间复杂度 O ( n 3 ) O(n ^ 3) O(n3) 代码 #…...
Uni-app 项目 PDF 批注插件库在线版 API 示例教程
本文章介绍 Uni-app 项目中 PDF 批注插件库 ElasticPDF 在线版 API 示例教程,API 包含 ① 导出批注后PDF数据;② 导出纯批注 json 数据;③ 加载旧批注;④ 切换文档;⑤ 切换用户;⑥ 清空批注 等数据处理功能…...
学透Spring Boot — 010. 单元测试和Spring Test
系列文章目录 这是CSDN postnull 博客《学透Spring Boot》系列的一篇,更多文章请移步:Postnull - 学透Spring Boot系列文章 文章目录 系列文章目录前言1. 基本概念UT 单元测试TDD 测试驱动开发UT测试框架Mock框架 3. Spring Test为什么要用Spring Test引…...

TortoiseGit多账号切换配置
前言 之前配置好的都是,TortoiseGit与Gitee之间的提交,突然有需求要在GitHub上提交,于是在参考网上方案和TortoiseGit的帮助手册后,便有了此文。由于GitHub已经配置完成,所以下述以配置Gitee为例。因为之前是单账号使用…...
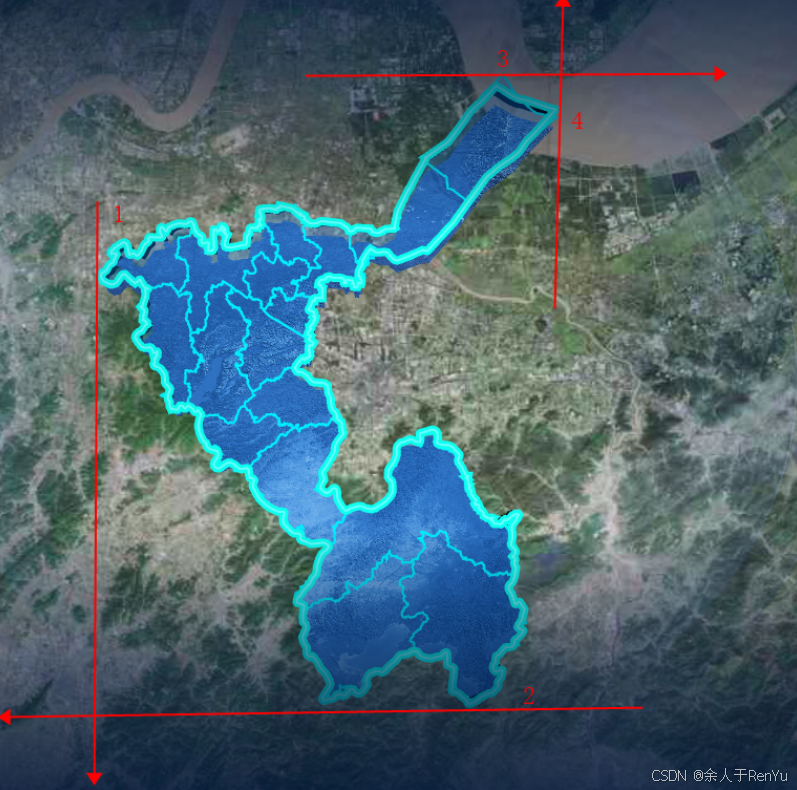
3D 地图渲染-区域纹理图添加
引入-初始化地图(关键代码) // 初始化页面引入高德 webapi -- index.html 文件 <script src https://webapi.amap.com/maps?v2.0&key您申请的key值></script>// 添加地图容器 <div idcontainer ></div>// 地图初始化应该…...

【Linux】条件变量封装类及环形队列的实现
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
离线部署kubesphere(已有k8s和私有harbor的基础上)
前言说明:本文是在已有k8s集群和私有仓库harbor上进行离线安装kubesphere;官网的离线教程写都很详细,但是在部署部份把搭建集群和搭建仓库也写一起了,跟着做踩了点坑,这里就记录下来希望可以帮助到需要的xdm。 1.根据官…...

非阻塞IO,fcntl,多路转接,select,poll,epoll,reactor
IO次数会影响程序的效率,在编程中往往会尽量减少IO次数,用以提高程序的效率,例如缓冲区,就是减少IO次数提高效率的一种方式;而IO影响效率的最大原因其实是因为IO等拷贝,在进行IO时往往需要拷贝的数据就绪,或…...

Redis常用的数据结构及其使用场景
字符串(String) string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。 string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据,比如jpg图片或者序列化的对象。 string 类型是 R…...

PhotoShop学习04
1.背景图层 最下面的被锁锁住的图层为背景图层,背景图层充当整个图层的背景,名字标注为背景,无法修改背景图层的排序始终位于图层最底部。 当我想把上方的图层移动到背景图层之后,发现无法移动图层无法移动,把背景图层…...
服务器有2张显卡,在别的虚拟环境部署运行了Xinference,然后又建个虚拟环境再部署一个可以吗?
环境: 云服务器Ubuntu系统 2张 NVIDIA H20 96GB Qwen2.5-VL-72B-Instruct-AWQ Qint4量化 AWQ 是 “Activation - Aware Weight Quantization” 的缩写,即激活感知权重量化。它是一种针对大型模型的先进量化算法,通过在权重量化过程中引入对激活值的感知,最小化量化误差…...

K8s中CPU和Memory的资源管理
资源类型 在 Kubernetes 中,Pod 作为最小的原子调度单位,所有跟调度和资源管理相关的属性都属于 Pod。其中最常用的资源就是 CPU 和 Memory。 CPU 资源 在 Kubernetes 中,一个 CPU 等于 1 个物理 CPU 核或者一个虚拟核,取决于节…...
任务挂起和恢复
任务挂起和恢复API函数 下面用按键和震动传感器验证任务挂起和恢复API函数: PA7接震动传感器,按键引脚为PA0,提前初始化好GPIO引脚 key.c #include "key.h" #include "stm32f10x.h"void KeyInit() {GPIO_InitTypeDef …...
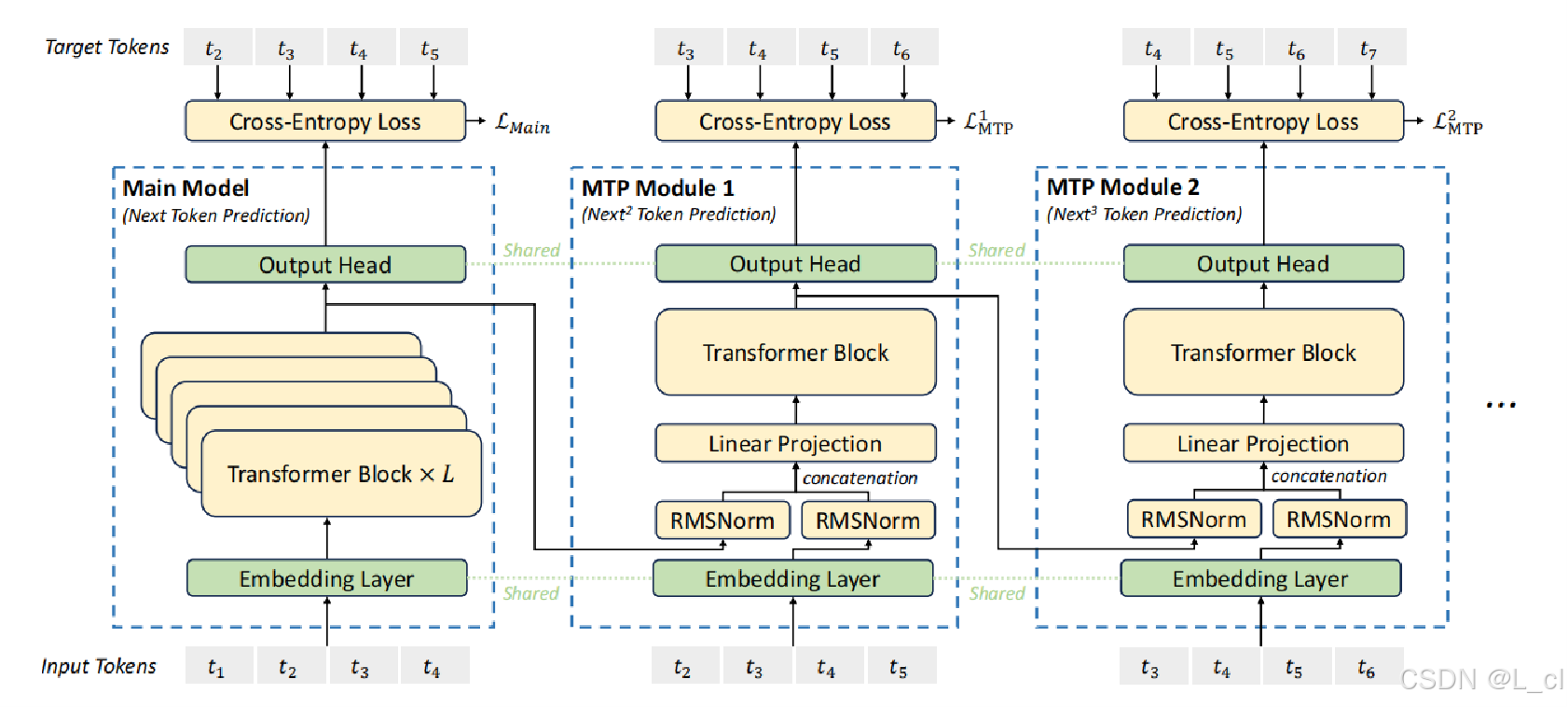
【NLP 55、投机采样加速推理】
目录 一、投机采样 二、投机采样改进:美杜莎模型 流程 改进 三、Deepseek的投机采样 流程 Ⅰ、输入文本预处理 Ⅱ、引导模型预测 Ⅲ、候选集筛选(可选) Ⅳ、主模型验证 Ⅴ、生成输出与循环 骗你的,其实我在意透了 —— 25.4.4 一、…...
如何在 Windows 上安装 Python
Python是一种高级编程语言,由于其简单性、多功能性和广泛的应用范围而变得越来越流行。如何在 Windows 操作系统中安装 Python 的过程相对简单,只需几个简单的步骤。 本文旨在指导您完成在 Windows 计算机上下载和安装 Python 的过程。 如何在 Windows…...

【Groovy快速上手 ONLY ONE】Groovy与Java的核心差异
最近在使用的平台上写脚本的语言是Groovy,所以也学习一下,作为 Java 开发者,Groovy 对我们来说会非常友好,而且它的语法更简洁且支持动态类型,所以其实了解下Java和Groovy的差异点就可以快速上手了,以下是 …...

计算机系统---CPU
定义与功能 中央处理器(Central Processing Unit,CPU),是电子计算机的主要设备之一,是计算机的核心部件。CPU是计算机的运算核心和控制核心,负责执行计算机程序中的指令,进行算术运算、逻辑运算…...

WEB安全--提权思路
一、情形 在我们成功上传webshell到服务器中并拿到权限时,发现我们的权限很低无法执行特定的命令,这时为了能做更多的操作,我们就需要提升权限。 二、方式 2.1、Windows提权 1、普通用户执行systeminfo命令获取服务器的基本信息࿰…...

多layout 布局适配
安卓多布局文件适配方案操作流程 以下为通过多套布局文件适配不同屏幕尺寸/密度的详细步骤,结合主流适配策略及最佳实践总结: 一、创建多套布局资源目录 按屏幕尺寸划分 在 res 目录下创建以下文件夹(根据设备特性自动匹配ÿ…...

selectdb修改表副本
如果想修改doris(也就是selectdb数据库)表的副本数需要首先确定是否分区表,当前没有数据字典得知哪个表是分区的,只能先show partitions看结果 首先,副本数不应该大于be节点数 其次,修改期间最好不要跑业务…...
Metabase:一个免费开源的BI平台
今天给大家介绍一个开源数据可视化分析工具:Metabase。它可以帮助用户快速连接数据库、执行查询并创建交互式仪表盘,即使非技术人员也能快速上手。 Metabase 支持多种数据源,包括 MySQL、PostgreSQL、Oracle、SQL Server、SQLite、MongoDB、P…...