Vanna:用检索增强生成(RAG)技术革新自然语言转SQL
引言:为什么我们需要更智能的SQL生成?
在数据驱动的业务环境中,SQL 仍然是数据分析的核心工具。然而,编写正确的 SQL 查询需要专业知识,而大型语言模型(LLM)直接生成的 SQL 往往存在**幻觉(hallucination)**或不符合业务逻辑的问题。
Vanna 是一个基于 检索增强生成(RAG) 的框架,专门优化自然语言到 SQL 的转换。它结合了 LLM 的强大推理能力和数据库的上下文信息,显著提高了 SQL 生成的准确性。
本文将深入探讨:
-
Vanna 的核心工作原理
-
它如何比纯 LLM 更可靠
-
如何快速集成到你的数据工作流
1. Vanna 的核心工作原理
Vanna 的工作流程分为 训练阶段 和 推理阶段,形成一个持续优化的闭环系统。
(1)训练阶段:构建知识库
Vanna 通过以下方式学习你的数据库:
-
数据库模式(DDL):存储表结构、字段类型、外键关系。
vn.train(ddl="CREATE TABLE sales (id INT, product_id INT, amount FLOAT, date TIMESTAMP)") -
业务规则文档:定义关键指标(如“销售额 =
SUM(amount)”)。vn.train(documentation="销售额是指销售表中 amount 列的总和") -
历史查询缓存:存储已验证的 SQL 及其自然语言问题,形成 QA 对。
这些数据会被向量化并存入向量数据库(如 Chroma、FAISS),供后续检索使用。
(2)推理阶段:动态生成SQL
当用户提问时(如 “2023年销售额最高的产品是什么?”),Vanna 执行以下步骤:
-
检索相关上下文
-
使用向量搜索召回:
-
相关表结构(
sales表、products表) -
业务规则(“销售额 =
SUM(amount)”) -
类似的历史查询(
SELECT product, SUM(amount) FROM sales GROUP BY product)
-
-
-
组装Prompt,输入LLM
你是一个SQL专家。根据以下信息生成查询: ### 数据库结构: - sales(id INT, product_id INT, amount FLOAT, date TIMESTAMP) - products(id INT, name VARCHAR)### 业务规则: - 销售额 = SUM(amount)### 类似查询: - "各产品销售额" → SELECT name, SUM(amount) FROM sales JOIN products ON sales.product_id = products.id GROUP BY name### 问题: 2023年销售额最高的产品是什么? -
生成并优化SQL
LLM 返回:SELECT p.name, SUM(s.amount) FROM sales s JOIN products p ON s.product_id = p.id WHERE YEAR(s.date) = 2023 GROUP BY p.name ORDER BY SUM(s.amount) DESC LIMIT 1 -
执行或人工审核
-
可自动执行并返回结果,或由数据团队验证后修正。
-
修正后的 SQL 会反馈到训练库,使模型持续改进。
-
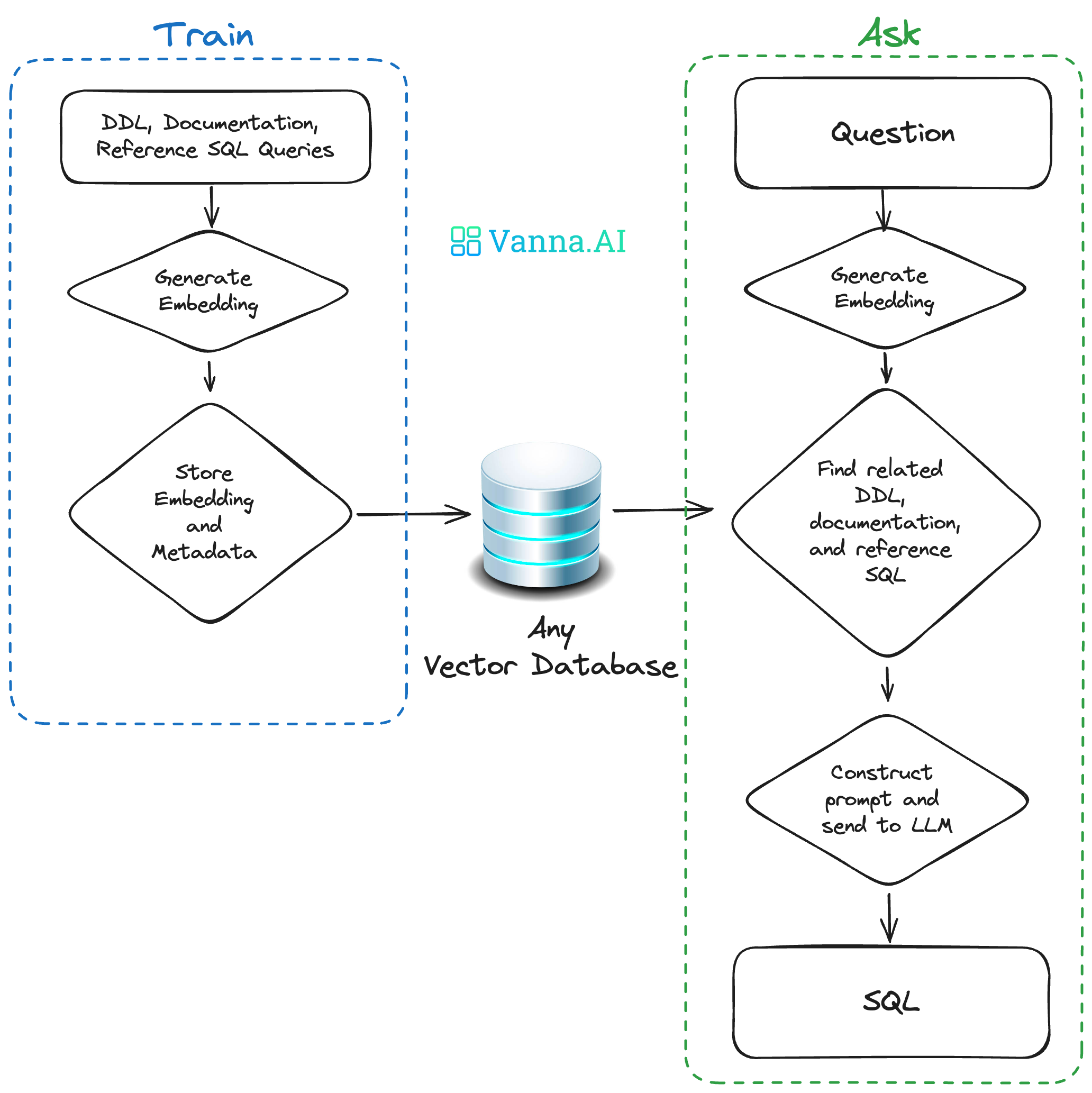
Vanna的工作原理
Vanna通过两个简单步骤工作:在你的数据上训练一个RAG“模型”,然后提出问题,返回可自动在数据库上运行的SQL查询。
- 对你的数据训练一个RAG“模型”。
- 提问。
2. Vanna vs. 纯LLM:为什么更可靠?
| 对比维度 | 纯LLM(如ChatGPT) | Vanna + RAG |
|---|---|---|
| 领域知识 | 通用知识,可能不了解你的数据库 | 动态注入表结构、业务规则 |
| 准确性 | 复杂查询错误率高 | 检索增强减少幻觉,实测提升30-50% |
| 可解释性 | 黑箱生成,难以调试 | 可查看检索到的上下文,定位问题 |
| 持续学习 | 静态模型,无法优化 | 用户反馈闭环,越用越准 |
典型案例:
-
纯LLM:提问“计算客户留存率”可能生成错误的 JOIN 逻辑。
-
Vanna:检索业务定义后,生成正确的 SQL(如使用日期差计算留存)。
3. 如何快速集成Vanna?
(1)安装与初始化
pip install vanna
from vanna.llm.openai import OpenAI_Chat
from vanna.vannadb import VannaDBvn = Vanna(model=OpenAI_Chat(), db_engine=your_db_connection)(2)训练模型
# 注入DDL
vn.train(ddl="CREATE TABLE products (id INT, name VARCHAR, price FLOAT)")# 添加业务文档
vn.train(documentation="高价值产品指价格超过1000元的商品")# 录入历史SQL
vn.train(question="哪些是高价值产品?",sql="SELECT name FROM products WHERE price > 1000"
)(3)生成SQL
question = "2023年最畅销的高价值产品是什么?"
sql = vn.generate_sql(question)
print(sql)(4)部署为API
Vanna 提供 Flask 快速部署:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()4. 未来展望
Vanna 的潜力不仅限于 SQL 生成:
-
BI 工具增强:为 Tableau/Power BI 提供自然语言查询接口。
-
自动化数据探查:通过对话式分析发现数据趋势。
-
多模态扩展:结合文本和图表,实现更智能的数据交互。
结论
Vanna 通过 RAG + 反馈学习,将 LLM 变成了一个“懂你业务”的 SQL 助手。它特别适合:
-
数据分析团队:减少重复的 SQL 编写工作。
-
非技术用户:通过自然语言查询数据库。
-
数据平台开发者:快速构建智能查询接口。
项目已开源(Apache 2.0),支持 Snowflake、BigQuery、PostgreSQL 等主流数据库,立即试用:GitHub - vanna-ai/vanna
📌 互动提问
-
你的团队是否尝试过自然语言转 SQL 工具?体验如何?
-
如果采用 Vanna,你希望优先解决哪些场景的问题?
欢迎在评论区分享你的想法! 🚀
相关文章:
Vanna:用检索增强生成(RAG)技术革新自然语言转SQL
引言:为什么我们需要更智能的SQL生成? 在数据驱动的业务环境中,SQL 仍然是数据分析的核心工具。然而,编写正确的 SQL 查询需要专业知识,而大型语言模型(LLM)直接生成的 SQL 往往存在**幻觉&…...
)
Unity:标签(tags)
为什么需要Tags? 在游戏开发中,游戏对象(GameObject)数量可能非常多,比如玩家、敌人、子弹等。开发者需要一种简单的方法来区分这些对象,并根据它们的类型执行不同的逻辑。 核心需求: 分类和管…...

如何创建一个自行设计的nginx的Docker Image
目录 前奏问题描述问题解决第一步:设置构建环境第二步:构建BoringSSL第三步:下载并构建Nginx第四步:创建最终镜像 整体的Dockerfile 前奏 你是否曾经想过,亲手打造一个属于自己的Nginx Docker镜像呢? 今天…...

CKPT文件是什么?
检查点(Checkpoint,简称ckpt)是一种用于记录系统状态或数据变化的技术,广泛应用于数据库管理、机器学习模型训练、并行计算以及网络安全等领域。以下将详细介绍不同领域中ckpt检查点的定义、功能和应用场景。 数据库中的ckpt检查点…...

zk基础—5.Curator的使用与剖析二
大纲 1.基于Curator进行基本的zk数据操作 2.基于Curator实现集群元数据管理 3.基于Curator实现HA主备自动切换 4.基于Curator实现Leader选举 5.基于Curator实现分布式Barrier 6.基于Curator实现分布式计数器 7.基于Curator实现zk的节点和子节点监听机制 8.基于Curator创…...

前端布局难题:父元素padding导致子元素无法全屏?3种解决方案
大家好,我是一诺。今天要跟大家分享一个我在实际项目中经常用到的CSS技巧——如何让子元素突破父元素的padding限制,实现真正的全屏宽度效果。 为什么会有这个需求? 记得我刚入行的时候,接到一个需求:要在内容区插入…...

Android使用OpenGL和MediaCodec录制
目录 一,什么是opengl 二,什么是Android OpenGL ES 三, OpenGL 绘制流程 四, OpenGL坐标系 五, OpenGL 着色器 六, GLSL编程语言 七,使用MediaCodec录制在Opengl中渲染架构 八,代码实现 8.1 自定义渲染view继承GLSurfaceView 8.2 自定义渲染器TigerRender 8.3 创建编…...

《如何避免虚无》速读笔记
文章目录 书籍信息概览躺派(出世)卷派(入世)虚无篇:直面虚无自我篇:认识自我孤独篇:应对孤独幸福篇:追寻幸福超越篇:超越自我 书籍信息 书名:《如何避免虚无…...

哈尔滨工业大学:大模型时代的具身智能
大家好,我是樱木。 机器人在工业领域,已经逐渐成熟。具身容易,智能难。 机器人-》智能机器人,需要自主能力,加上通用能力。 智能机器人-》人类,这个阶段就太有想象空间了。而最受关注的-类人机器人。 如何…...

19.go日志包log
核心功能与接口 基础日志输出 Print 系列:支持 Print()、Println()、Printf(),输出日志不中断程序。 log.Print("常规日志") // 输出: 2025/03/18 14:47:13 常规日志 log.Printf("格式化: %s", "数据") Fatal…...
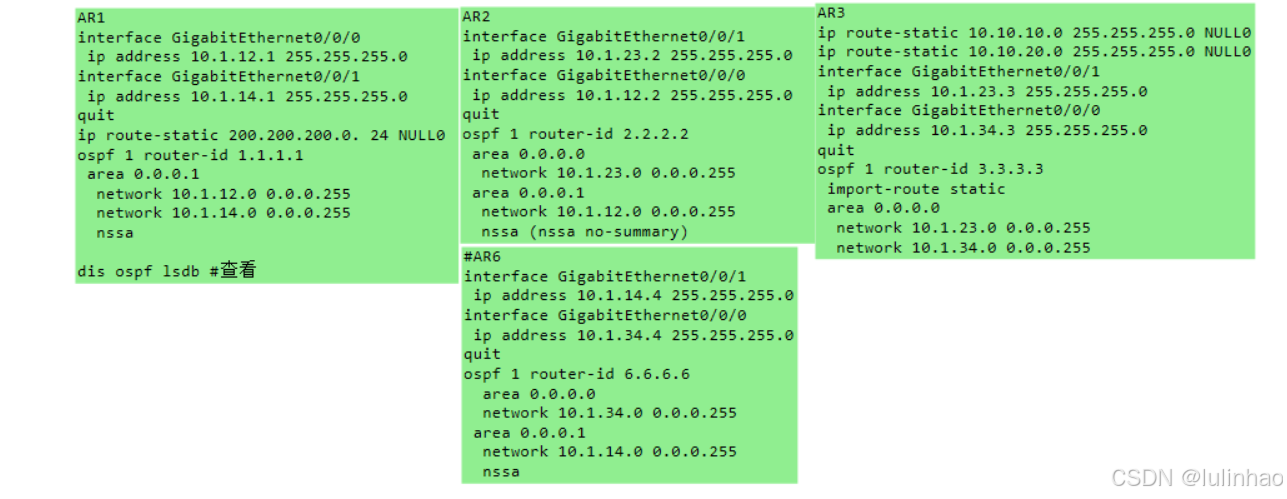
理解OSPF 特殊区域NSSA和各类LSA特点
本文基于上文 理解OSPF Stub区域和各类LSA特点 在理解了Stub区域之后,我们再来理解一下NSSA区域,NSSA区域用于需要引入少量外部路由,同时又需要保持Stub区域特性的情况 一、 网络总拓扑图 我们在R1上配置黑洞路由,来模拟NSSA区域…...

如何通过优化HMI设计大幅提升产品竞争力?
一、HMI设计的重要性与竞争力提升 HMI(人机交互界面)设计在现代产品开发中扮演着至关重要的角色。良好的HMI设计不仅能够提升用户体验,还能显著增强产品的竞争力。在功能趋同的市场环境中,用户体验成为产品竞争的关键。HMI设计通…...

Linux信号——信号的处理(3)
信号是什么时候被处理? 进程从内核态,切换到用户态的时候,信号会被检测处理。 内核态:操作系统的状态,权限级别高 用户态:你自己的状态 内核态和用户态 进程地址空间第三次 所谓的系统调用本质其实是一堆…...
Pod的调度
在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某些节点上&…...
LabVIEW面向对象编程设计方法
一、概述 面向对象编程(OOP)在软件开发中占据重要地位,尤其是在大规模软件项目中。它与小型程序开发思路不同,更注重未来功能的升级与扩展。在设计阶段,需思考如何构建既灵活又稳定的系统,这涉及众多设计方…...

Spring常见问题复习
############Spring############# Bean的生命周期是什么? BeanFactory和FactoryBean的区别? ApplicationContext和BeanFactory的区别? BeanFactoryAware注解,还有什么其它的Aware注解 BeanFactoryAware方法和Bean注解的方法执行顺…...

JJJ:generic netlink例程分析
接嵌入式毕设、课设辅导、技术咨询,欢迎私信 完整代码:github代码仓链接 若想要和指定的generic netlink family通信,如: 994 static struct genl_family genl_ctrl __ro_after_init { // generic netlink子协议995 .module THIS_MODU…...
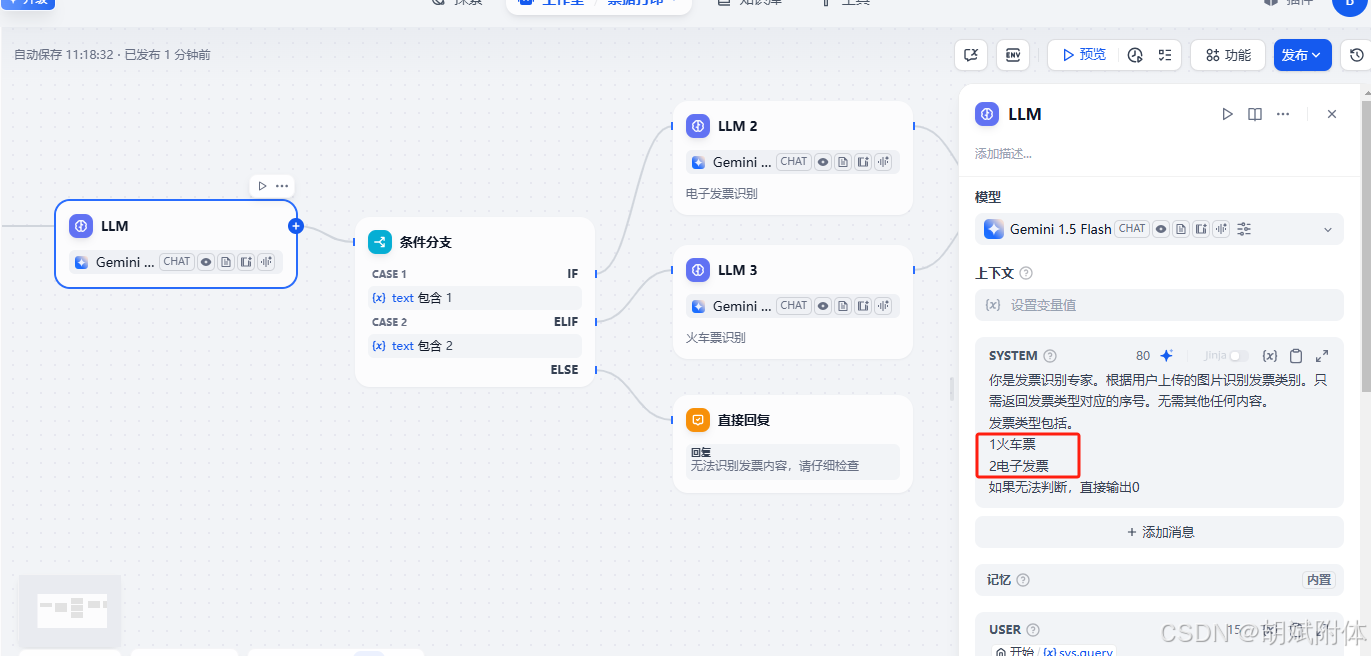
Dify票据识别遇到的分支判断不准确问题
已测试这篇文章中 https://zhuanlan.zhihu.com/p/5465385787 使用多分支条件判断使用不同的大模型识别图片内容 发现了细节问题。在使用时若不注意,分支会出现走向不准的问题。 需要关注部分 下方红框处。1,2后不能跟点。否则会出问。除此之外࿰…...
《全栈+双客户端Turnkey方案》架构设计图
今天分享一些全栈双客户端Turnkey方案的架构与结构图。 1:三种分布式部署方案:网关方案,超级服务器单服方案,直连逻辑服方案 2: 单服多线程核心架构: 系统服务逻辑服服务 3: 系统服务的多线程池调度设计 4:LogicServer Update与ECS架构&…...
某碰瓷国赛美赛,号称第三赛事的数模竞赛
首先我非常不能理解的就是怎么好意思自称第三赛事的呢?下面我们进行一个简单讨论,当然这里不对国赛和美赛进行讨论。首先我们来明确一点,比赛的含金量由什么来定?这个可能大家的评价指标可能不唯一,我通过DeepSeek选取…...

【代码模板】如何用FILE操作符打开文件?fopen、fclose
#include "stdio.h" #include "unistd.h"int main(int argc, char *argv[]) {FILE *fp fopen("1.log", "wb");if (!fp) {perror("Failed open 1.log");return -1;}fclose(fp); }关于权限部分参考兄弟篇【代码模板】C语言中…...
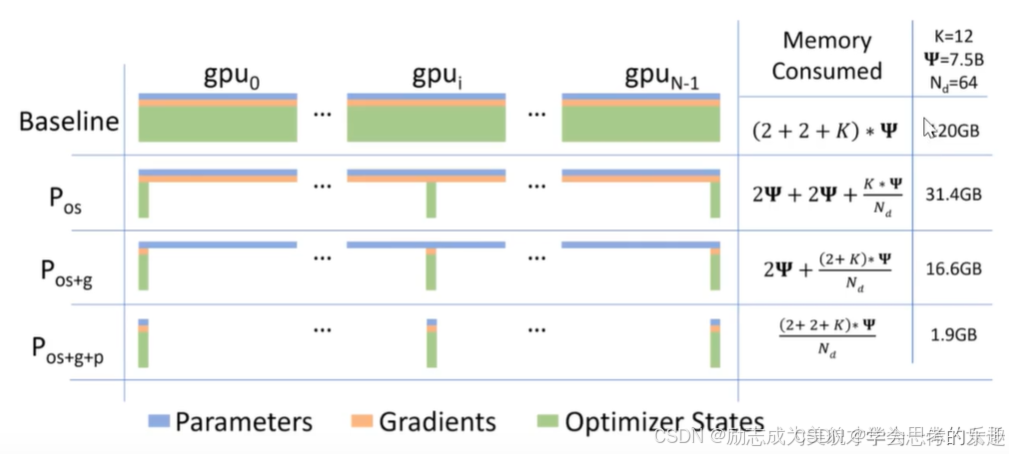
【大模型深度学习】如何估算大模型需要的显存
一、模型参数量 参数量的单位 参数量指的是模型中所有权重和偏置的数量总和。在大模型中,参数量的单位通常以“百万”(M)或“亿”(B,也常说十亿)来表示。 百万(M):表示…...

Mysql 数据库编程技术01
一、数据库基础 1.1 认识数据库 为什么学习数据库 瞬时数据:比如内存中的数据,是不能永久保存的。持久化数据:比如持久化至数据库中或者文档中,能够长久保存。 数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长…...

Class<?> 和Class<T >有什么区别
Class<?> 和 Class<T> 在 Java 中都表示 Class 类型的对象,但它们的使用方式和作用略有不同。让我们详细分析它们的区别: 1. Class<?>(通配符 Class 类型) ? 代表一个未知类型(Wildcard…...

[自制调试工具]利用模板函数打造通用调试工具
引言 上一篇文章 我们介绍了调式类工具,这篇文章我们补充一下 点击这里查看 在软件开发的过程中,调试是必不可少的环节。为了能更高效地定位和解决问题,我们常常需要在代码中插入一些调试信息,来输出变量的值、函数的执行状态等。传统的调试…...

Python地理数据处理 28:基于Arcpy批量操作实现——按属性提取和分区统计
Arcpy批量操作 1. 批量按属性提取2. 批量分区统计(最大值、最小值和像元个数等) 1. 批量按属性提取 # -*- coding: cp936 -*- """ PROJECT_NAME: ArcPy FILE_NAME: batch_attribute_extract AUTHOR: JacksonZhao DATE: 2025/04/05 &qu…...

Mysql慢查询设置 和 建立索引
1 .mysql慢查询的设置 slow_query_log ON //或 slow_query_log_file /usr/local/mysql/data/slow.log long_query_time 2 修改后重启动mysql 1.1 查看设置后的参数 mysql> show variables like slow_query%; --------------------------------------------------…...
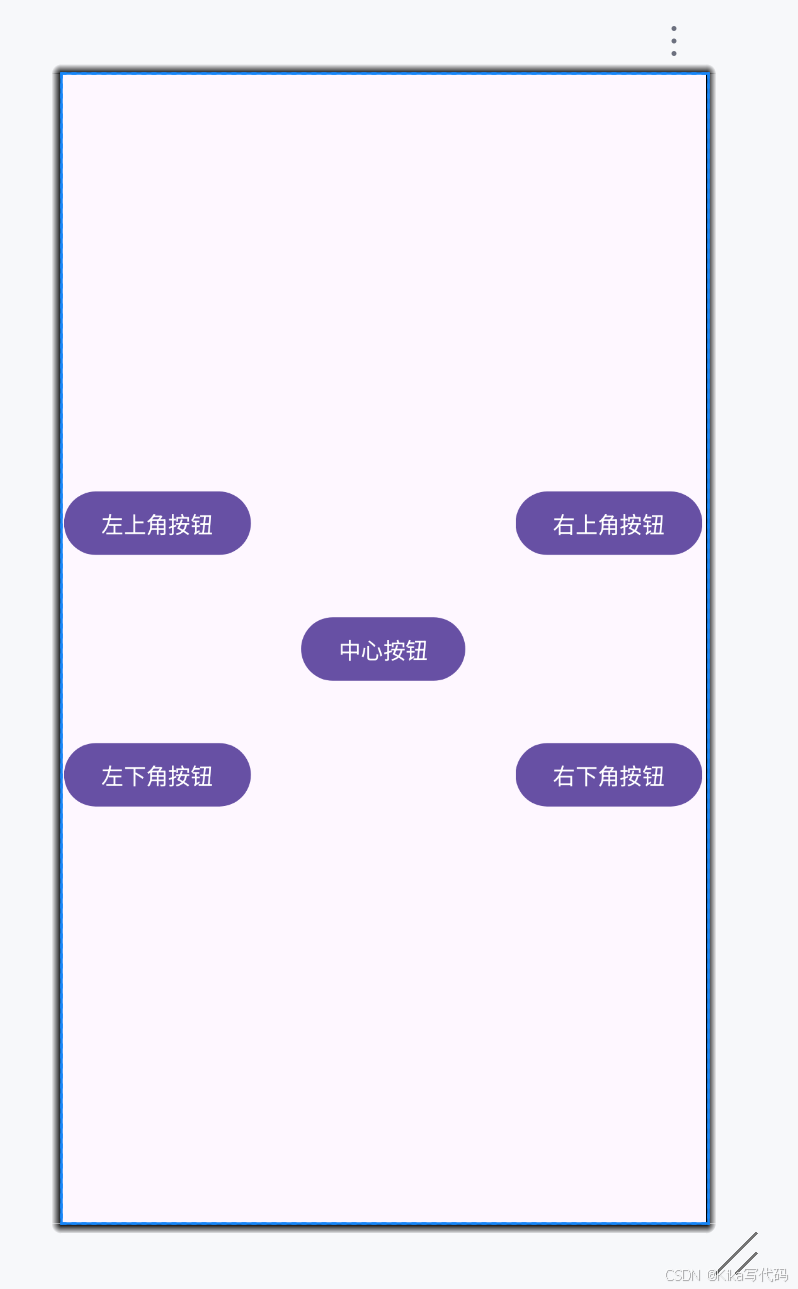
【Android】界面布局-相对布局RelativeLayout-例子
题目 完成下面相对布局,要求: 中间的button在整个屏幕的中央,其他的以它为基准排列。Hints:利用layout_toEndof,_toRightof,_toLeftof,_toStartof完成。 结果演示 代码实现 <?xml version"1.0" encoding"u…...

Spring Boot 中使用 Redis:从入门到实战
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...

【ROS】 CMakeLists 文件详解
【ROS】 CMakeLists文件详解 前言标准的CMAKELIST.TXT文件的组成部分CMake 版本要求和项目名称指定编译器和设置构建规则查找 ROS 依赖消息和服务文件catkin_package设置头文件目录路径添加可执行文件的构建规则设置编译依赖关系(构建顺序)设置目标文件的…...