Flinksql--订单宽表
参考: https://chbxw.blog.csdn.net/article/details/115078261 (datastream 实现)
一、ODS
模拟订单表及订单明细表
CREATE TABLE orders (order_id STRING,user_id STRING,order_time TIMESTAMP(3),-- 定义事件时间及 Watermark(允许5秒乱序)WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka','topic' = 'orders','properties.bootstrap.servers' = 'chb1:9092',-- 如果source被多个任务使用,不在定义时指定group.id-- 通过hint指定 OPTIONS('properties.group.id'='test_group2') 注意是group.id 是点不是下划线-- 'properties.group.id' = 'flink-sql-group-orders', -- 消费者组 ID'scan.startup.mode' = 'earliest-offset','format' = 'json'
);CREATE TABLE order_details (detail_id STRING,order_id STRING,product_id STRING,price DECIMAL(10,2),quantity INT,detail_time TIMESTAMP(3),-- 定义事件时间及 Watermark(允许5秒乱序)WATERMARK FOR detail_time AS detail_time - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka','topic' = 'order_details','properties.bootstrap.servers' = 'chb1:9092',-- 'properties.group.id' = 'flink-sql-group-order_details', -- 消费者组 ID'scan.startup.mode' = 'earliest-offset','format' = 'json'
);-- 造数据
insert into order_details values ('d001', 'o001', 'car', 5000, 1, now());
insert into orders values('o001', 'u001', now());insert into orders values('o003', 'u003', now());insert into order_details values ('d003', 'o003', 'water', 2, 12, now());
insert into order_details values ('d003', 'o003', 'food', 50, 3, now());二、DWD 订单和订单明细关联
-- sink
CREATE TABLE dwd_trd_order (detail_id STRING,order_id STRING,product_id STRING,price DECIMAL(10,2),quantity INT,detail_time TIMESTAMP(3),user_id STRING,order_time TIMESTAMP(3),-- 定义事件时间及 Watermark(允许5秒乱序)WATERMARK FOR detail_time AS detail_time - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka','topic' = 'dwd_trd_order','properties.bootstrap.servers' = 'chb1:9092','scan.startup.mode' = 'earliest-offset','format' = 'json'
);insert into dwd_trd_order
SELECT d.detail_id,o.order_id,d.product_id,d.price,d.quantity,d.detail_time,user_id,order_time
FROM orders o
JOIN order_details d
ON o.order_id = d.order_id
AND d.detail_time BETWEEN o.order_time AND o.order_time + INTERVAL '10' MINUTE;报错:
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: The query contains more than one rowtime attribute column [detail_time, order_time] for writing into table 'default_catalog.default_database.dwd_trd_order'.
Please select the column that should be used as the event-time timestamp for the table sink by casting all other columns to regular TIMESTAMP or TIMESTAMP_LTZ.
在 Flink SQL 中,每个表只能有一个 行时间属性(rowtime attribute) 用于定义事件时间(Event Time)。当写入目标表时,若查询结果包含多个行时间属性字段(如 order_time 和 detail_time),会导致冲突。以下是解决方案:
1. 问题定位
错误信息表明目标表 dwd_trd_order 在写入时检测到多个行时间属性字段(detail_time 和 order_time)。
根本原因是:JOIN 后的结果保留了双表的事件时间字段,且未被转换为普通时间戳。
2. 解决方案
方案一:仅保留一个行时间属性
在查询中选择一个时间字段作为事件时间,将其他时间字段转为普通 TIMESTAMP 类型。
假设目标表 dwd_trd_order 使用 order_time 作为事件时间:
INSERT INTO dwd_trd_order
SELECT o.order_id,o.user_id,d.product_id,d.price,d.quantity,o.order_time, -- 保留为行时间属性(需与目标表定义一致)CAST(d.detail_time AS TIMESTAMP(3)) AS detail_time -- 转为普通时间戳
FROM orders o
JOIN order_details d ON o.order_id = d.order_id;
方案二:调整目标表定义
若业务需要同时保留两个时间字段,需在目标表 DDL 中 仅定义一个行时间属性,其他字段转为普通时间戳:
CREATE TABLE dwd_trd_order (order_id STRING,user_id STRING,product_id STRING,price DECIMAL(10,2),quantity INT,order_time TIMESTAMP(3), -- 行时间属性detail_time TIMESTAMP(3), -- 普通时间戳WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND -- 仅一个事件时间
) WITH (...);
3. 关键步骤说明
-
检查目标表 DDL:
确保目标表仅有一个WATERMARK定义,且对应字段为行时间属性。 -
转换多余的行时间属性:
在查询中使用CAST将非主时间字段转为普通TIMESTAMP或TIMESTAMP_LTZ:CAST(detail_time AS TIMESTAMP(3)) -- 转为非行时间属性 -
验证查询结果:
使用DESCRIBE确认查询结果的字段类型:DESCRIBE (SELECT ... FROM ...);
目标表 DDL(仅一个行时间属性)
CREATE TABLE dwd_trd_order (order_id STRING,user_id STRING,product_id STRING,price DECIMAL(10,2),quantity INT,order_time TIMESTAMP(3), -- 行时间属性detail_time TIMESTAMP(3), -- 普通时间戳WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);
写入数据的 SQL(转换多余时间字段)
INSERT INTO dwd_trd_order
SELECT o.order_id,o.user_id,d.product_id,d.price,d.quantity,o.order_time, -- 保留为行时间属性CAST(d.detail_time AS TIMESTAMP(3)) AS detail_time -- 转为普通时间戳
FROM orders o
JOIN order_details d ON o.order_id = d.order_id;
三、DWS
CREATE TABLE dws_trd_order (window_start TIMESTAMP(3),window_end TIMESTAMP(3),product_num bigint,uv bigint,total_amount DECIMAL(10,2)
) WITH ('connector' = 'kafka','topic' = 'dws_trd_order','properties.bootstrap.servers' = 'chb1:9092','scan.startup.mode' = 'earliest-offset','format' = 'json'
);-- dws
insert into dws_trd_order
SELECTwindow_start, window_end,COUNT(1) AS product_num,COUNT(DISTINCT user_id) AS uv,SUM(price * quantity) AS total_amount
FROM TABLE(CUMULATE(TABLE dwd_trd_order, DESCRIPTOR(detail_time), INTERVAL '5' SECOND, INTERVAL '1' DAY)
)
GROUP BY window_start, window_end;有个问题: 为什么窗口结束时间从 2025-04-02 20:48:50.000 开始???
dwd_trd_order 表的时间如下order_time detail_time2025-04-02 20:06:01.281 2025-04-02 20:07:35.4942025-04-02 20:50:27.975 2025-04-02 20:50:33.2332025-04-02 20:50:27.975 2025-04-02 20:50:34.405累计窗口运算如下selectwindow_start, window_end,count(1) product_num,count(distinct user_id) uv,sum(price*quantity) as total_amountfrom TABLE(CUMULATE(TABLE dwd_trd_order, DESCRIPTOR(detail_time ), INTERVAL '5' SECOND, INTERVAL '1' DAY)
)
group by window_start,window_end;
为什么窗口结束时间从 2025-04-02 20:48:50.000 开始???window_start window_end product_num uv total_amount2025-04-02 00:00:00.000 2025-04-02 20:48:50.000 1 1 5000.002025-04-02 00:00:00.000 2025-04-02 20:48:55.000 1 1 5000.002025-04-02 00:00:00.000 2025-04-02 20:49:00.000 1 1 5000.002025-04-02 00:00:00.000 2025-04-02 20:49:05.000 1 1 5000.002025-04-02 00:00:00.000 2025-04-02 20:49:10.000 1 1 5000.002025-04-02 00:00:00.000 2025-04-02 20:49:15.000 1 1 5000.002025-04-02 00:00:00.000 2025-04-02 20:49:20.000 1 1 5000.002025-04-02 00:00:00.000 2025-04-02 20:49:25.000 1 1 5000.002025-04-02 00:00:00.000 2025-04-02 20:49:30.000
相关文章:

Flinksql--订单宽表
参考: https://chbxw.blog.csdn.net/article/details/115078261 (datastream 实现) 一、ODS 模拟订单表及订单明细表 CREATE TABLE orders (order_id STRING,user_id STRING,order_time TIMESTAMP(3),-- 定义事件时间及 Watermark(允许5秒乱序&#x…...
 打开文件操作)
C# 窗体应用(.FET Framework ) 打开文件操作
一、 打开文件或文件夹加载数据 1. 定义一个列表用来接收路径 public List<string> paths new List<string>();2. 打开文件选择一个文件并将文件放入列表中 OpenFileDialog open new OpenFileDialog(); // 过滤 open.Filter "(*.jpg;*.jpge;*.bmp;*.png…...

极客天成NVFile:无缓存直击存储性能天花板,重新定义AI时代并行存储新范式
在AI算力需求呈指数级爆发的今天,存储系统正面临一场前所未有的范式革命。传统存储架构中复杂的缓存机制、冗余的数据路径、僵化的扩展能力,已成为制约千卡GPU集群算力释放的重要因素。极客天成NVFile并行文件存储系统以全栈并行化架构设计和无缓存直通数…...
Java实现N皇后问题的双路径探索:递归回溯与迭代回溯算法详解
N皇后问题要求在NN的棋盘上放置N个皇后,使得她们无法互相攻击。本文提供递归和循环迭代两种解法,并通过图示解释核心逻辑。 一、算法核心思想 使用回溯法逐行放置皇后,通过冲突检测保证每行、每列、对角线上只有一个皇后。发现无效路径时回退…...

【代码艺廊】pyside6桌面应用范例:homemade-toolset
在研发测试日常工作中,通常会遇到很多琐碎的事情,占用我们工作的时间和精力,从而导致我们不能把大部分的注意力放在主要的工作上面。为了解决这个问题,除了加人之外,我们通常会开发一些日常用的效率工具,比…...

LeetCode 3047 求交集区域内的最大正方形面积
探寻矩形交集中的最大正方形面积 在算法与数据结构的探索之路上,二维平面几何问题一直占据着独特的地位,它们不仅考验我们的空间思维能力,还要求我们能够巧妙地运用算法逻辑。今天,我们将深入剖析一道极具代表性的二维平面几何算…...

谷歌开源单个 GPU 可运行的Gemma 3 模型,27B 超越 671B 参数的 DeepSeek
自从 DeepSeek 把训练成本打下来之后,各个模型厂家现在不再堆参数进行模型的能力对比。而是转向了训练成本优化方面,且还要保证模型能力不减反增的效果。包括使用较少的模型参数,降低 GPU 使用数量,降低模型内存占用等等技术手段。…...

C++_类和对象(下)
【本节目标】 再谈构造函数Static成员友元内部类匿名对象拷贝对象时的一些编译器优化再次理解封装 1. 再谈构造函数 1.1 构造函数体赋值 在创建对象时,编译器通过调用构造函数,给对象中各个成员变量一个合适的初始值。 class Date { public:Date(in…...

《Java实战:素数检测算法优化全解析——从暴力枚举到筛法进阶》
文章目录 摘要一、需求分析二、基础实现代码与问题原始代码(暴力枚举法)问题分析 三、优化版代码与解析优化1:平方根范围剪枝优化2:偶数快速跳过完整优化代码 四、性能对比五、高阶优化:埃拉托斯特尼筛法算法思想代码实…...

基于Python+Flask的服装零售商城APP方案,用到了DeepSeek AI、个性化推荐和AR虚拟试衣功能
首先创建项目结构: fashion_store/ ├── backend/ │ ├── app/ │ │ ├── __init__.py │ │ ├── models/ │ │ ├── routes/ │ │ ├── services/ │ │ └── utils/ │ ├── config.py │ ├── requirements.t…...

二,<FastApi>FastApi的两个核心组件
FastAPI的两个核心组件Pydantic和Starlette。 Starlette 负责Web部分(Asyncio),Starlette Starlette是一个轻量级的ASGI框架/工具包,非常适合在Python构建异步Web服务。 它已经准备好生产,并为您提供以下内容: 轻巧的低复杂性HTTP Web框架。W…...
Docker设置代理
目录 前言创建代理文件重载守护进程并重启Docker检查代理验证 前言 拉取flowable/flowable-ui失败,用DaoCloud源也没拉下来,不知道是不是没同步。索性想用代理拉镜像。在此记录一下。 创建代理文件 创建docker代理配置 sudo mkdir -p /etc/systemd/s…...

一键自动备份:数据安全的双重保障
随着数字化时代的到来,数据已成为企业和个人不可或缺的核心资产。在享受数据带来的便捷与高效的同时,数据丢失的风险也随之增加。因此,备份文件的重要性不言而喻。本文将深入探讨备份文件的重要性,并介绍两种实用的自动备份方法&a…...
HeidiSQL:多数据库管理工具
HeidiSQL 是一款广受欢迎的免费开源数据库管理工具,专为数据库管理员及开发者设计。无论您是刚接触数据库领域的新手,还是需要同时处理多种数据库系统的专业开发者,该工具都能凭借其直观的界面和强大的功能,助您轻松完成数据管理任…...
医药档案区块链系统
1. 医生用户模块 目标用户:医护人员 核心功能: 检索档案:通过关键词或筛选条件快速定位患者健康档案。请求授权:向个人用户发起档案访问权限申请,需经对方确认。查看档案…...

【Python学习】列表/元组等容器的常用内置函数详解
文章目录 map使用示例: filter示例:注意事项: sortedsorted() 与 list.sort() 的区别: any示例: all示例: any 与 all 的对比zip示例:常见用途: enumerate示例:常见用途&…...
蓝桥云客--浓缩咖啡液
4.浓缩咖啡液【算法赛】 - 蓝桥云课 问题描述 蓝桥杯备赛选手小蓝最近刷题刷到犯困,决定靠咖啡续命。他手上有 N 种浓缩咖啡液,浓度分别是 A1%, A2%, …, AN%,每种存货都是无限的。为了提神又不炸脑,小蓝需要按比例混合这…...

SQLark(百灵连接):一款面向信创应用开发者的数据库开发和管理工具
SQLark(百灵连接)是一款面向信创应用开发者的数据库开发和管理工具,用于快速查询、创建和管理不同类型的数据库系统。 目前可以支持达梦数据库、Oracle 以及 MySQL。 SQL 智能编辑器 基于语法语义解析实现代码补全能力,为你提供…...
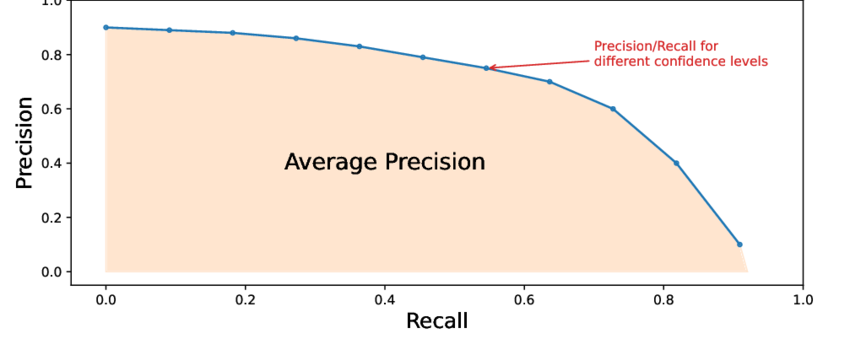
计算机视觉——为什么 mAP 是目标检测的黄金标准
概述 在目标检测领域,有一个指标被广泛认为是衡量模型性能的“黄金标准”,它就是 mAP(Mean Average Precision,平均精确率均值)。如果你曾经接触过目标检测模型(如 YOLO、Faster R-CNN 或 SSD)…...
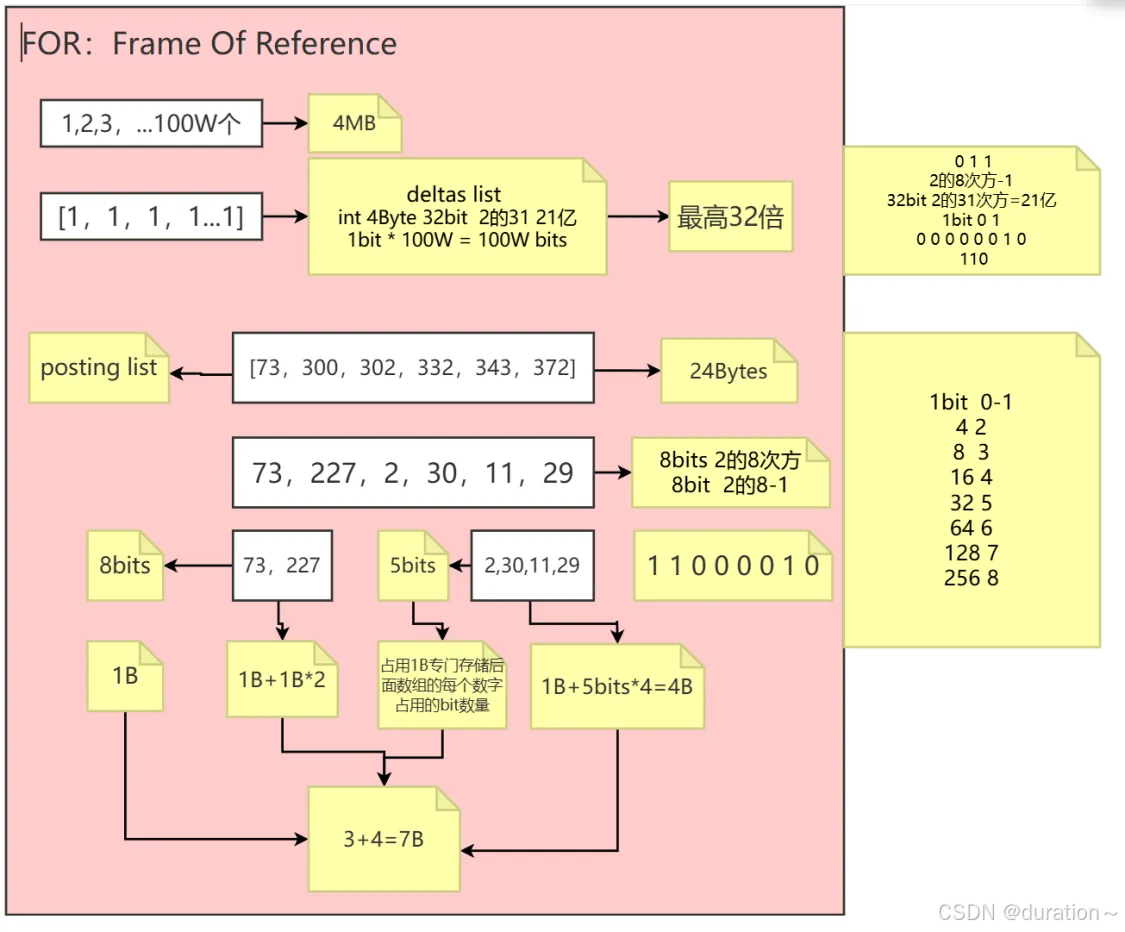
Frame Of Reference压缩算法
文章目录 1_概述2_算法基本步骤3_过程优化4_优势以及局限5_模拟实现6_总结 1_概述 Frame of Reference(FoR)压缩算法 是一种用于压缩数值数据的算法,特别是在处理大规模数据集时,利用数据的局部性和重复性来减少存储和传输的开销…...

1.0 软件测试全流程解析:从计划到总结的完整指南
软件测试全流程解析:从计划到总结的完整指南 摘要 本文档详细介绍了软件测试的完整流程,包括测试计划、测试设计、测试执行、测试报告和测试总结等主要阶段。每个阶段都从目标、主要工作、输出物和注意事项等方面进行了详细说明。通过本文档࿰…...

嵌入式AI简介
嵌入式AI是一种将人工智能算法部署在终端设备中运行的技术,使智能硬件能够在本地实时完成感知、交互和决策功能,无需依赖云端计算。以下是其核心要点: 一、核心特点 1. 本地化处理:数据在设备端直接处理,无需联网&a…...
esp32cam 开发板搭载ov3660摄像头在arduino中调用kimi进行图像识别
首先呢,最近搞一个项目,需要一个摄像头拍摄图片 就买了个ov3660开发板,用的esp32S芯片 淘宝商家给的教程是arduino的,所以先用arduino跑起来 arduino配置esp32-cam开发环境 - 简书1、安装arduino https://www.arduino.cc/en/Main/Software?setlang=cn 2、配置esp32 打开…...

二十种中药果实识别分类系统,Python/resnet18/pytorch
二十种中药果实识别分类系统,Python/resnet18/pytorch 基于pytorch训练, resnet18网络,可用于训练其他分类问题,也可自己重新训练 20类中药材具体包括:(1) 补骨脂,(2) 草豆蔻,(3) 川楝子,(4) 地肤子&…...
如何实现两个视频融合EasyCVR平台的数据同步?详细步骤指南
有用户咨询,现场需要数据库同步,如何将两个EasyCVR平台的数据进行同步呢? 这篇文章我们将详细介绍如何通过简单的接口调用,高效完成两个平台的数据同步操作。 1)获取token 使用Postman调用登录接口,获取…...

WindowsPE文件格式入门05.PE加载器LoadPE
https://bpsend.net/thread-316-1-1.html LoadPE - pe 加载器 壳的前身 如果想访问一个程序运行起来的内存,一种方法就是跨进程读写内存,但是跨进程读写内存需要来回调用api,不如直接访问地址来得方便,那么如果我们需要直接访问地址,该怎么做呢?.需要把dll注进程,注进去的代码…...
使用Cusor 生成 Figma UI 设计稿
一、开发环境 系统:MacOS 软件版本: Figma(网页或APP版) 注:最好是app版,网页版figma 没有选项 import from manifest app下载地址:Figma Downloads | Web Design App for Desktops & …...

Golang的文件同步与备份
Golang的文件同步与备份 一、Golang介绍 也称为Go语言,是谷歌开发的一种编程语言,具有高效的并发编程能力和出色的内存管理。由于其快速的编译速度和强大的标准库,Golang在网络应用、云平台和大数据等领域得到了广泛应用。 二、文件同步与备份…...
如何用人工智能大模型,进行作业批改?
今天我们学习人工智能大模型如何进行作业批改。手把手学习视频请访问https://edu.csdn.net/learn/40402/666452 第一步,进入讯飞星火。打开google浏览器,输入百度地址后,搜索”讯飞星火”,在搜索的结果中,点第一个讯飞…...
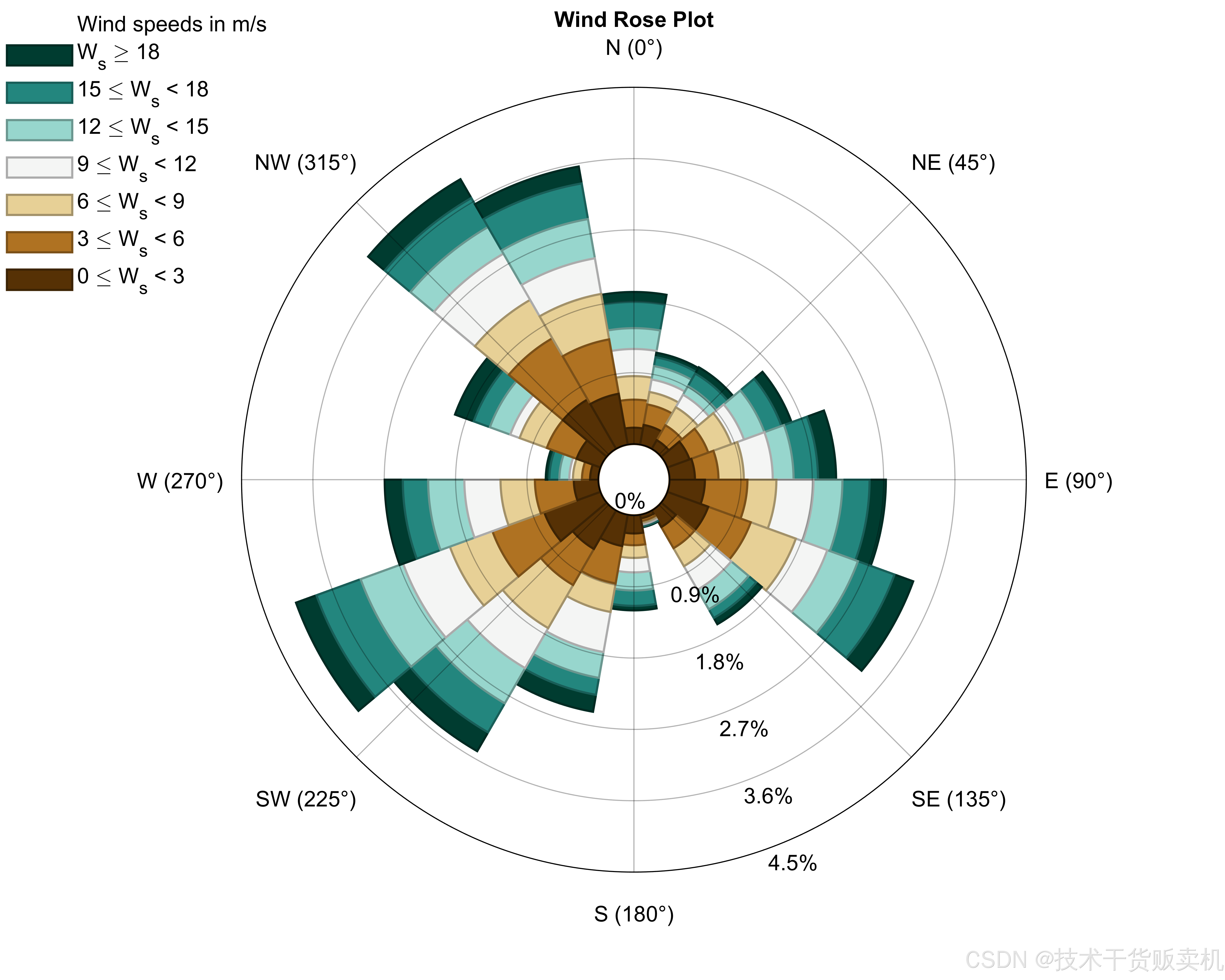
MATLAB之数据分析图系列 三
三维堆叠柱状图 Bar3StackPlot.m文件 clc; clear; close all; %三维堆叠柱状图 %% 数据准备 % 读取数据 load data.mat % 初始化 dataset X; s 0.4; % 柱子宽度 n size(dataset,3); % 堆叠组数%% 图片尺寸设置(单位:厘米) figureUnits c…...