Chapter07_图像压缩编码
文章目录
- 图像压缩编码
- 图像压缩编码基础
- 图像压缩的基本概念
- 信息相关
- 信息冗余
- 信源编码及其分类
- 图像编码模型
- 信源编码器模型
- 信源解码器模型
- 数字图像的信息熵
- 信源符号码字平均长度
- 信息熵
- 信息量
- 变长编码
- 费诺码
- 霍夫曼编码
- 位平面编码
- 格雷码
图像压缩编码
数字图像的压缩是指在满足一定的图像质量要求条件(比如保真度评分或信噪比值)下,通过寻求图像数据的更有效地表征形式,以便用最少的比特数表示图像或表示图像中所包含信息的技术
图像压缩编码基础
图像压缩的基本概念
信息相关
在绝大多数图像的像素之间, 各像素行和帧之间存在着较强的相关性
从统计观点出发,就是每个像素的灰度值(或颜色值)总是和其周围的其它像素的灰度值(或颜色值)存在某种关系,应用某种编码方法减少这些相关性就可实现图像压缩
【引例】

上图的黑白像素序列共41位
新的编码只需21位:1,0101,1111,0111,1011,0011
由此可见,利用图像中各像素之间存在的信息相关,可实现图像编码信息的压缩
信息冗余
从信息论的角度来看, 压缩就是去掉信息中的冗余。即保留确定信息,去掉可推知的确定信息,用一种更接近信息本质的描述来代替原有的冗余描述
图像数据存在的冗余可分为三类:
① 编码冗余;② 像素间的冗余;③ 心里视觉冗余
-
编码冗余
由于大多数图像的直方图不是均匀(水平)的,所以图像中某个或某些灰度级会比其它灰度级具有更大的出现概率,如果对出现概率大和出现概率小的灰度级都分配相同的比特数,必定会产生编码冗余,即如果一个图像的灰度级编码,使用了多于实际需要的编码符号,就称该图像包含了编码冗余
【例】

-
像素间的冗余
所谓“像素间的冗余”,是指单个像素携带的信息相对较少,单一像素对于一幅图像的多数视觉贡献是多余的, 它的值可以通过与其相邻的像素的值来推断
【例】

-
心里视觉冗余
心里视觉冗余是指,在正常的视觉处理过程中那些不十分重要的信息,即一些信息在一般的视觉处理中,比其他信息的相对重要程度要小,这种信息就被称为视觉心理冗余
信源编码及其分类
- 信源编码的概念:图像压缩的目标是在满足一定的图像质量的条件下,用尽可能少的比特数来表示原图像,以减少图像的存储容量和提高图像的传输效率,在信息论中,把这种通过减少冗余数据来实现数据压缩的过程称为信源编码
- 信源编码的分类:无失真编码和有失真编码
- 无失真压缩也称为无损压缩,是一种在不引入任何失真的条件下使表示图像的数据比特率为最小的压缩方法
- 有失真压缩也称为有损压缩,是一种在一定比特率下获得最佳保真度,或在给定的保真度下获得最小比特率的压缩方法
图像编码模型

- 信道编码器和信道解码器是一种用来实现抗干扰、抗噪声的可靠数字通信技术措施,信道编码器是通过向信源编码数据中插入可控制的冗余数据来减少对信道噪声的影响的
- 信源编码器的作用就是减少或消除输入图像中的编码冗余
信源编码器模型

-
映射变换器(减少像素冗余)
映射变换器将输入的图像数据转换为可以减少输入图像中像素间冗余的表示格式,其输出是比原始图像数据更适合于高效压缩的图像表示形式
典型的映射变换包括:线性预测变换、酉变换、多分辨率变换等
-
量化器
量化器用于对映射变换后的变换系数进行量化,以便产生表示被压缩图像的有限数量的符号
利用量化器对映射变换后的变换系数进行量化会导致部分信息的损失
-
符号编码器
符号编码器的作用是对量化器输出的每一个符号分配一个码字或二进制比特流

输入 X 称为信源符号集,集合中的每一个元素 x i x_i xi称为信源符号
输出W 称为代码,集合中的每一个元素 w i w_i wi 称为码字
A 称为码元集,集合中的每一个元素 a j a_j aj 称为码元
信源解码器模型

数字图像的信息熵
信源符号码字平均长度
设有信源符号集 X = { x 1 , x 2 , … , x n } X=\{ x_1,x_2 ,…,x_n \} X={x1,x2,…,xn},信源符号出现的概率为 { P ( x 1 ) , P ( x 2 ) , … , P ( x n ) } \{P(x_1),P(x_2),…,P(x_n)\} {P(x1),P(x2),…,P(xn)} ,对 X 编码得到的代码为 W = { w 1 , w 2 , … , w n } W=\{w_1,w_2,…,w_n\} W={w1,w2,…,wn},其中每个码字 w i w_i wi 的比特数(长度)为 L ( x i ) L(x_i) L(xi)
则表示每个信源符号码字的平均长度(比特数)为:
L ‾ = ∑ i = 1 n P ( x i ) ⋅ l ( x i ) \overline{L}=\displaystyle\sum^n_{i=1}P(x_i)·l(x_i) L=i=1∑nP(xi)⋅l(xi)
信息熵
信息熵是一个系统信息含量的量化指标,通常用来作为系统优化的目标或者参数选择的判据
信源的熵定义为: H ( X ) = ∑ i = 1 n P ( x i ) ⋅ l o g 2 P ( x i ) H(X)=\displaystyle\sum^n_{i=1}P(x_i)·log_2P(x_i) H(X)=i=1∑nP(xi)⋅log2P(xi) ,熵的单位是b/s,表示每个符号的比特数
【例1】设有一个随机变量 X 有8 种可能的状态 x i ( i = 1 , 2 , . . . , 8 ) x_i(i=1,2,...,8) xi(i=1,2,...,8) ,每个状态都是等可能的,则该随机变量的熵为:
H ( X ) = ∑ i = 1 8 1 8 ⋅ l o g 2 1 8 = − 8 × 1 8 l o g 2 1 8 = 3 b i t s H(X)=\displaystyle\sum^8_{i=1}\frac{1}{8}·log_2\frac{1}{8} =-8×\frac{1}{8}log_2\frac{1}{8}=3bits H(X)=i=1∑881⋅log281=−8×81log281=3bits
也就是说,为了把 X 的值传递给接收者,需要传输一个 3 比特的消息
【例2】设有一个随机变量X 有8 种可能的状态 { a , b , c , d , e , f , g , h } \{a,b,c,d,e,f,g,h\} {a,b,c,d,e,f,g,h},每个状态各自的概率为 { 1 2 , 1 4 , 1 8 , 1 16 , 1 64 , 1 64 , 1 64 , 1 64 } \{\frac{1}{2},\frac{1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{64},\frac{1}{64},\frac{1}{64},\frac{1}{64}\} {21,41,81,161,641,641,641,641} ,这种情况下该随机变量的熵为:
H ( X ) = − 1 2 l o g 2 1 2 − 1 4 l o g 2 1 4 − 1 8 l o g 2 1 8 − 1 16 l o g 2 1 16 − 4 × 1 64 l o g 2 1 64 } = 2 b i t s H(X)=-\frac{1}{2}log_2\frac{1}{2} -\frac{1}{4}log_2\frac{1}{4} -\frac{1}{8}log_2\frac{1}{8} -\frac{1}{16}log_2\frac{1}{16} -4×\frac{1}{64}log_2\frac{1}{64} \}=2bits H(X)=−21log221−41log241−81log281−161log2161−4×641log2641}=2bits
也就是说,随机变量非均匀分布时的熵,要比随机变量均匀分布时的熵小
信源符号码字的平均长度就与随机变量的熵相等,熵是编码所需比特数的下限
信息量
信息量是指从N个相等的可能事件中选出一个事件所需的信息度量或含量。假设 N 的大小为 2 的整次幂(比如 N = 2 n N=2^n N=2n ),则信息量可表示为:
I ( x ) = l o g 2 N = − l o g 2 1 N = − l o g 2 P ( x ) I(x)=log_2N=-log_2\frac{1}{N}=-log_2P(x) I(x)=log2N=−log2N1=−log2P(x)
每个信源符号的信息量实质上反映的是该信源符号的编码长度
变长编码
费诺码
费诺编码方法认为:在数字形式的码字中的 0 和 1 是相互独立的,因而其出现的概率也应是相等的(为0.5或接近 0.5),这样就可确保传输的每一位码含有 1 比特的信息量
假设输入的离散信源符号集为 X = { x 0 , x 1 , … , x n } X=\{x_0,x_1,…,x_n\} X={x0,x1,…,xn},其出现概率为 P ( x i ) P(x_i) P(xi),欲求的费诺码为 W = { w 0 , w 1 , … , w n } W=\{w_0,w_1,…,w_n\} W={w0,w1,…,wn},则费诺码编码方法的步骤为:
- 把输入的信源符号和其出现的概率按概率值的非递增顺序从上到下依次并列排列
- 按概率之和相等或相近的原则把 X 分成两组,并给上面或概率之和较大的组赋值 1,给下面或概率之和较小的组赋值 0
- 再按概率之和相等或相近的原则把现有的组分成两组,并给上面或概率之和较大的组赋值 1,给下面或概率之和较小的组赋值 0
- 重复 3 的分组和赋值过程,直至每个组只有一个符号为止
- 把对每个符号所赋的值依次排列,就可得到信源符号集 X 的费诺码
【例】设有信源符号集 X = { x 1 , x 2 , … , x 8 } X=\{x_1,x_2,…,x_8\} X={x1,x2,…,x8},其概率分布为 P ( x 1 ) = 0.25 P(x_1)=0.25 P(x1)=0.25, P ( x 2 ) = 0.125 P(x_2)=0.125 P(x2)=0.125, P ( x 3 ) = 0.0625 P(x_3)=0.0625 P(x3)=0.0625, P ( x 4 ) = 0.25 P(x_4)=0.25 P(x4)=0.25, P ( x 5 ) = 0.0625 P(x_5)=0.0625 P(x5)=0.0625, P ( x 6 ) = 0.125 P(x_6)=0.125 P(x6)=0.125, P ( x 7 ) = 0.0625 P(x_7)=0.0625 P(x7)=0.0625, P ( x 8 ) = 0.0625 P(x_8)=0.0625 P(x8)=0.0625,求其费诺码 W = { w 1 , w 2 , w 3 , w 4 , w 5 , w 6 , w 7 , w 8 } W=\{w_1,w_2,w_3,w_4,w_5,w_6,w_7,w_8\} W={w1,w2,w3,w4,w5,w6,w7,w8}
【解】由题意可得:
P ( x 1 ) = 0.25 = 1 4 P(x_1)=0.25=\frac{1}{4} P(x1)=0.25=41, P ( x 2 ) = 0.125 = 1 8 P(x_2)=0.125=\frac{1}{8} P(x2)=0.125=81,
P ( x 3 ) = 0.0625 = 1 16 P(x_3)=0.0625=\frac{1}{16} P(x3)=0.0625=161, P ( x 4 ) = 0.25 = 1 4 P(x_4)=0.25=\frac{1}{4} P(x4)=0.25=41,
P ( x 7 ) = 0.0625 = 1 16 P(x_7)=0.0625=\frac{1}{16} P(x7)=0.0625=161, P ( x 6 ) = 0.125 = 1 8 P(x_6)=0.125=\frac{1}{8} P(x6)=0.125=81,
P ( x 7 ) = 0.0625 = 1 16 P(x_7)=0.0625=\frac{1}{16} P(x7)=0.0625=161, P ( x 8 ) = 0.0625 = 1 16 P(x_8)=0.0625=\frac{1}{16} P(x8)=0.0625=161

平均码字长度:
L ‾ = = ∑ i = 1 8 P ( x i ) ⋅ l ( x i ) = 1 4 × 2 + 1 4 × 2 + 1 8 × 3 + 1 8 × 3 + 1 16 × 4 + 1 16 × 4 + 1 16 × 4 + 1 16 × 4 = 11 4 ( b i t ) \begin{align} \overline{L} & = =\displaystyle\sum^8_{i=1}P(x_i)·l(x_i) \\ & = \frac{1}{4}×2+\frac{1}{4}×2+\frac{1}{8}×3+\frac{1}{8}×3+\frac{1}{16}×4+\frac{1}{16}×4+\frac{1}{16}×4+\frac{1}{16}×4 \\ & = \frac{11}{4} (bit) \end{align} L==i=1∑8P(xi)⋅l(xi)=41×2+41×2+81×3+81×3+161×4+161×4+161×4+161×4=411(bit)
霍夫曼编码
假设输入的离散信源符号集为 X = { x 0 , x 1 , … , x n } X=\{x_0,x_1,…,x_n\} X={x0,x1,…,xn},其出现概率为 P ( x i ) P(x_i) P(xi),欲求的费诺码为 W = { w 0 , w 1 , … , w n } W=\{w_0,w_1,…,w_n\} W={w0,w1,…,wn},则霍夫曼编码方法的步骤为:
- 统计信源(比如一幅图像)中的信源符号及每个信源符号出现的概率
设经统计有 n 个信源符号 x i x_i xi(i=0, …,n),其出现概率为 P ( x i ) P(x_i) P(xi) - 把把信源符号 x i x_i xi 和其概率 P ( x i ) P(x_i) P(xi) ,依序按概率值的递减顺序从上到下依次排列
- 把最末两个具有最小概率值的信源符号的概率值合并相加得到新的概率值
- 给最末两个具有最小概率值的信源符号的上面的信源符号编码“0”,给下面的信源符号编码“1”
- 如果最末两个信源符号的概率值合并相加后为 1.0,则转 7;否则继续下一步
- 把合并相加得到的新概率值与其余概率值按递减顺序从上到下依次排列,并转 3
- 寻找每一个信源符号到概率为 1.0 处的路径,并依次记录路径上的 “1” 和 “0” ,即可得到每个信源符号对应的二进制符号序列
- 逆序逐位地写出每个信源符号对应的二进制符号序列,即可得到每个信源符号的霍夫曼编码
【例】设有信源符号集 X = { x 1 , x 2 , … , x 6 } X=\{x_1,x_2,…,x_6\} X={x1,x2,…,x6},其概率分布为 P ( x 1 ) = 0.1 P(x_1)=0.1 P(x1)=0.1, P ( x 2 ) = 0.3 P(x_2)=0.3 P(x2)=0.3, P ( x 3 ) = 0.1 P(x_3)=0.1 P(x3)=0.1, P ( x 4 ) = 0.4 P(x_4)=0.4 P(x4)=0.4, P ( x 5 ) = 0.04 P(x_5)=0.04 P(x5)=0.04, P ( x 6 ) = 0.06 P(x_6)=0.06 P(x6)=0.06,求其霍夫曼码 W = { w 1 , w 2 , w 3 , w 4 , w 5 , w 6 } W=\{w_1,w_2,w_3,w_4,w_5,w_6\} W={w1,w2,w3,w4,w5,w6}

依据步骤 7 ,可得信源符号及其对应的二进制符号序列为:
{ x 1 , x 2 , x 3 , x 4 , x 5 , x 6 } \{x_1,x_2,x_3,x_4,x_5,x_6\} {x1,x2,x3,x4,x5,x6} ➡️ {110,00,0010,1,11010,01010}
根据步骤 8 ,将上述二进制符号序列逆序排列,即可得到霍夫曼编码为:
{011,00,0100,1,01011,01010}
平均码字长度:
L ‾ = ∑ i = 1 6 P ( x i ) ⋅ l ( x i ) = 0.1 × 3 + 0.3 × 2 + 0.1 × 4 + 0.4 × 1 + 0.04 × 5 + 0.06 × 5 = 2.2 ( b i t ) \begin{align} \overline{L} & =\displaystyle\sum^6_{i=1}P(x_i)·l(x_i) \\ & = 0.1×3+0.3×2+0.1×4+0.4×1+0.04×5+0.06×5 \\ & = 2.2 (bit) \end{align} L=i=1∑6P(xi)⋅l(xi)=0.1×3+0.3×2+0.1×4+0.4×1+0.04×5+0.06×5=2.2(bit)
霍夫曼编码的优点:
- 当对独立信源符号进行编码时,霍夫曼编码可对每个信源符号产生可能是最少数量(最短)码元的码字
- 霍夫曼编码是所有变长编码中平均码长最短的。如果所有信源符号的概率都是2的指数,霍夫曼编码的平均长度将达到最低限,即信源的熵
- 对于二进制的霍夫曼编码,平均码字的平均长度满足关系: H < L ‾ < H + 1 H<\overline{L}<H+1 H<L<H+1
位平面编码
所谓位平面编码,就是将一幅灰度图像或彩色图像分解为多幅二值图像,然后对二值图像应用二值图像编码方法,以达到对多值图像编码的目的
位平面分解:对于一幅 N×N 的灰度图像,若每个像素用 m 位表示,就可以从每个像素的二进制表示中取出相同位置上的一位,这样就形成了一幅 N×N 的二值图像,称该二值图像为原灰度图像的一个位平面
【举例】对于一幅 256 灰度级的图像来说,每个像素用一个 8 位的字节表示,该图像就可以分解成 8 个位平面,平面 0 由原图像中像素的最低位组成,平面 1 由原图像中像素的此低位组成,… ,平面 7 由原图像中像素的最高位组成


格雷码
多数图像中的大多数相邻像素值具有渐变的特征,但若采用二进制码进行位平面分解,就会导致各位平面中相关性的减小
比如:若灰度图像中的两个相邻像素是127和128,它们显然比较接近,但其二进制编码却分别为:0 1 1 1 1 1 1 1 和 1 0 0 0 0 0 0 0
灰度图像中相邻像素间的很小变化,却引起了所有位平面值的突变,从而降低了位平面图像的相关性,也即降低了位平面图像的压缩效率
由于两个相邻值的格雷码之间只有一位是不同的,这样就可保持相邻像素间较强的相关性,所以一般采用格雷码(Gray)进行位平面分解编码
格雷码进行位平面分解编码的思想:如果用一个 m 位的灰度编码 g m − 1 … g 2 g 1 g 0 g_{m-1}…g_2g_1g_0 gm−1…g2g1g0 表示图像,那么图像中这个 m 位的灰度编码 g m − 1 … g 2 g 1 g 0 g_{m-1}…g_2g_1g_0 gm−1…g2g1g0 的所有 g i g_i gi 就组成了第 i 个位平面二值图像

【举例】

相关文章:
Chapter07_图像压缩编码
文章目录 图像压缩编码图像压缩编码基础图像压缩的基本概念信息相关信息冗余信源编码及其分类 图像编码模型信源编码器模型信源解码器模型 数字图像的信息熵信源符号码字平均长度信息熵信息量 变长编码费诺码霍夫曼编码 位平面编码格雷码 图像压缩编码 数字图像的压缩是指在满…...

团体设计程序天梯赛L2-025 # 分而治之
文章目录 题目解读输入格式输出格式 思路Ac Code参考 题目解读 在战争中,我们希望首先攻下敌方的部分城市,使其剩余的城市变成孤立无援,然后再分头各个击破。为此参谋部提供了若干打击方案。本题就请你编写程序,判断每个方案的可…...
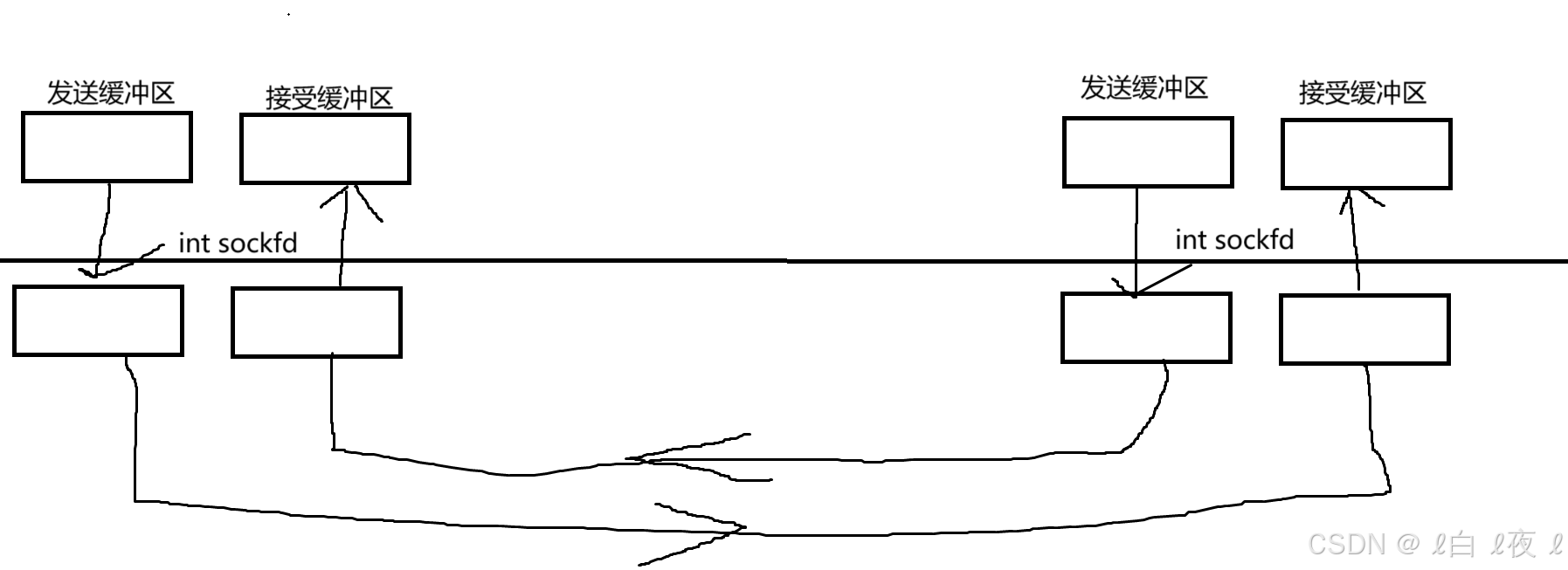
Linux网络套接字
Socket 编程 UDP 本章将函数介绍和代码编写实战一起使用。 IPv4 的 socket 网络编程,sockaddr_in 中的成员 struct in_addr.sin_addr 表示 32 位 的 IP 地址 但是我们通常用点分十进制的字符串表示 IP 地址,以下函数可以在字符串表示和in_addr 表示之间转换; 字符串转 in_addr…...

看爬山虎学本领 软爬机器人来创新 各种场景能适应
*本文只做阅读笔记分享* 一、灵感来源:向植物取经 大家好!今天来聊一款超酷的软爬机器人,它的灵感来自会攀爬的植物——爬山虎。 大家都知道,爬墙高手爬山虎能在各种复杂墙面轻松生长攀爬,可现有的攀爬机器人在复杂…...

1-Docker安装
1.准备环境 1.第一步:创建以自己的姓名全拼的用户名 [roothadoop ~]# useradd qiwenyong [roothadoop ~]# passwd qiwenyong Changing password for user qiwenyong. New password: BAD PASSWORD: The password is shorter than 7 characters Retype new passwor…...
-- 第三部分:JS宏编程语言开发基础)
WPS JS宏编程教程(从基础到进阶)-- 第三部分:JS宏编程语言开发基础
第三部分:JS宏编程语言开发基础 @[TOC](第三部分:JS宏编程语言开发基础)**第三部分:JS宏编程语言开发基础**1. 变量与数据类型**变量声明:三种方式****示例代码****数据类型判断****实战:动态处理单元格类型**2. 运算符全解析**算术运算符****易错点:字符串拼接 vs 数值相…...

BT-Basic函数之首字母T
BT-Basic函数之首字母T 文章目录 BT-Basic函数之首字母Ttabtesttest conttest monitortest on boardstest scanworkstest shortstesthead cleanuptesthead configurationtesthead istesthead power on/offtesthead statustestjet print level istestordertestplan generationth…...

经典算法 约数之和
原题目链接 问题描述 假设现在有两个自然数 A 和 B,设 S 为 A^B 的所有约数之和。 请你计算:S mod 9901 的值。 输入格式 在一行中输入两个用空格隔开的整数 A 和 B。 输出格式 输出一个整数,表示 S mod 9901 的值。 数据范围 0 ≤ A, …...

Flinksql--订单宽表
参考: https://chbxw.blog.csdn.net/article/details/115078261 (datastream 实现) 一、ODS 模拟订单表及订单明细表 CREATE TABLE orders (order_id STRING,user_id STRING,order_time TIMESTAMP(3),-- 定义事件时间及 Watermark(允许5秒乱序&#x…...
 打开文件操作)
C# 窗体应用(.FET Framework ) 打开文件操作
一、 打开文件或文件夹加载数据 1. 定义一个列表用来接收路径 public List<string> paths new List<string>();2. 打开文件选择一个文件并将文件放入列表中 OpenFileDialog open new OpenFileDialog(); // 过滤 open.Filter "(*.jpg;*.jpge;*.bmp;*.png…...

极客天成NVFile:无缓存直击存储性能天花板,重新定义AI时代并行存储新范式
在AI算力需求呈指数级爆发的今天,存储系统正面临一场前所未有的范式革命。传统存储架构中复杂的缓存机制、冗余的数据路径、僵化的扩展能力,已成为制约千卡GPU集群算力释放的重要因素。极客天成NVFile并行文件存储系统以全栈并行化架构设计和无缓存直通数…...
Java实现N皇后问题的双路径探索:递归回溯与迭代回溯算法详解
N皇后问题要求在NN的棋盘上放置N个皇后,使得她们无法互相攻击。本文提供递归和循环迭代两种解法,并通过图示解释核心逻辑。 一、算法核心思想 使用回溯法逐行放置皇后,通过冲突检测保证每行、每列、对角线上只有一个皇后。发现无效路径时回退…...

【代码艺廊】pyside6桌面应用范例:homemade-toolset
在研发测试日常工作中,通常会遇到很多琐碎的事情,占用我们工作的时间和精力,从而导致我们不能把大部分的注意力放在主要的工作上面。为了解决这个问题,除了加人之外,我们通常会开发一些日常用的效率工具,比…...

LeetCode 3047 求交集区域内的最大正方形面积
探寻矩形交集中的最大正方形面积 在算法与数据结构的探索之路上,二维平面几何问题一直占据着独特的地位,它们不仅考验我们的空间思维能力,还要求我们能够巧妙地运用算法逻辑。今天,我们将深入剖析一道极具代表性的二维平面几何算…...

谷歌开源单个 GPU 可运行的Gemma 3 模型,27B 超越 671B 参数的 DeepSeek
自从 DeepSeek 把训练成本打下来之后,各个模型厂家现在不再堆参数进行模型的能力对比。而是转向了训练成本优化方面,且还要保证模型能力不减反增的效果。包括使用较少的模型参数,降低 GPU 使用数量,降低模型内存占用等等技术手段。…...

C++_类和对象(下)
【本节目标】 再谈构造函数Static成员友元内部类匿名对象拷贝对象时的一些编译器优化再次理解封装 1. 再谈构造函数 1.1 构造函数体赋值 在创建对象时,编译器通过调用构造函数,给对象中各个成员变量一个合适的初始值。 class Date { public:Date(in…...

《Java实战:素数检测算法优化全解析——从暴力枚举到筛法进阶》
文章目录 摘要一、需求分析二、基础实现代码与问题原始代码(暴力枚举法)问题分析 三、优化版代码与解析优化1:平方根范围剪枝优化2:偶数快速跳过完整优化代码 四、性能对比五、高阶优化:埃拉托斯特尼筛法算法思想代码实…...

基于Python+Flask的服装零售商城APP方案,用到了DeepSeek AI、个性化推荐和AR虚拟试衣功能
首先创建项目结构: fashion_store/ ├── backend/ │ ├── app/ │ │ ├── __init__.py │ │ ├── models/ │ │ ├── routes/ │ │ ├── services/ │ │ └── utils/ │ ├── config.py │ ├── requirements.t…...

二,<FastApi>FastApi的两个核心组件
FastAPI的两个核心组件Pydantic和Starlette。 Starlette 负责Web部分(Asyncio),Starlette Starlette是一个轻量级的ASGI框架/工具包,非常适合在Python构建异步Web服务。 它已经准备好生产,并为您提供以下内容: 轻巧的低复杂性HTTP Web框架。W…...
Docker设置代理
目录 前言创建代理文件重载守护进程并重启Docker检查代理验证 前言 拉取flowable/flowable-ui失败,用DaoCloud源也没拉下来,不知道是不是没同步。索性想用代理拉镜像。在此记录一下。 创建代理文件 创建docker代理配置 sudo mkdir -p /etc/systemd/s…...

一键自动备份:数据安全的双重保障
随着数字化时代的到来,数据已成为企业和个人不可或缺的核心资产。在享受数据带来的便捷与高效的同时,数据丢失的风险也随之增加。因此,备份文件的重要性不言而喻。本文将深入探讨备份文件的重要性,并介绍两种实用的自动备份方法&a…...
HeidiSQL:多数据库管理工具
HeidiSQL 是一款广受欢迎的免费开源数据库管理工具,专为数据库管理员及开发者设计。无论您是刚接触数据库领域的新手,还是需要同时处理多种数据库系统的专业开发者,该工具都能凭借其直观的界面和强大的功能,助您轻松完成数据管理任…...
医药档案区块链系统
1. 医生用户模块 目标用户:医护人员 核心功能: 检索档案:通过关键词或筛选条件快速定位患者健康档案。请求授权:向个人用户发起档案访问权限申请,需经对方确认。查看档案…...

【Python学习】列表/元组等容器的常用内置函数详解
文章目录 map使用示例: filter示例:注意事项: sortedsorted() 与 list.sort() 的区别: any示例: all示例: any 与 all 的对比zip示例:常见用途: enumerate示例:常见用途&…...
蓝桥云客--浓缩咖啡液
4.浓缩咖啡液【算法赛】 - 蓝桥云课 问题描述 蓝桥杯备赛选手小蓝最近刷题刷到犯困,决定靠咖啡续命。他手上有 N 种浓缩咖啡液,浓度分别是 A1%, A2%, …, AN%,每种存货都是无限的。为了提神又不炸脑,小蓝需要按比例混合这…...

SQLark(百灵连接):一款面向信创应用开发者的数据库开发和管理工具
SQLark(百灵连接)是一款面向信创应用开发者的数据库开发和管理工具,用于快速查询、创建和管理不同类型的数据库系统。 目前可以支持达梦数据库、Oracle 以及 MySQL。 SQL 智能编辑器 基于语法语义解析实现代码补全能力,为你提供…...
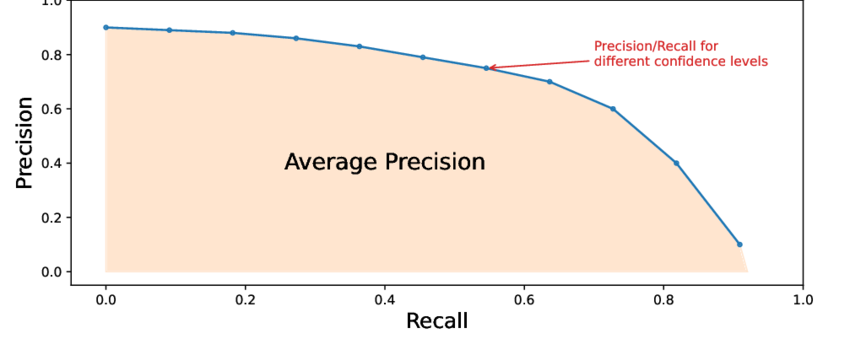
计算机视觉——为什么 mAP 是目标检测的黄金标准
概述 在目标检测领域,有一个指标被广泛认为是衡量模型性能的“黄金标准”,它就是 mAP(Mean Average Precision,平均精确率均值)。如果你曾经接触过目标检测模型(如 YOLO、Faster R-CNN 或 SSD)…...
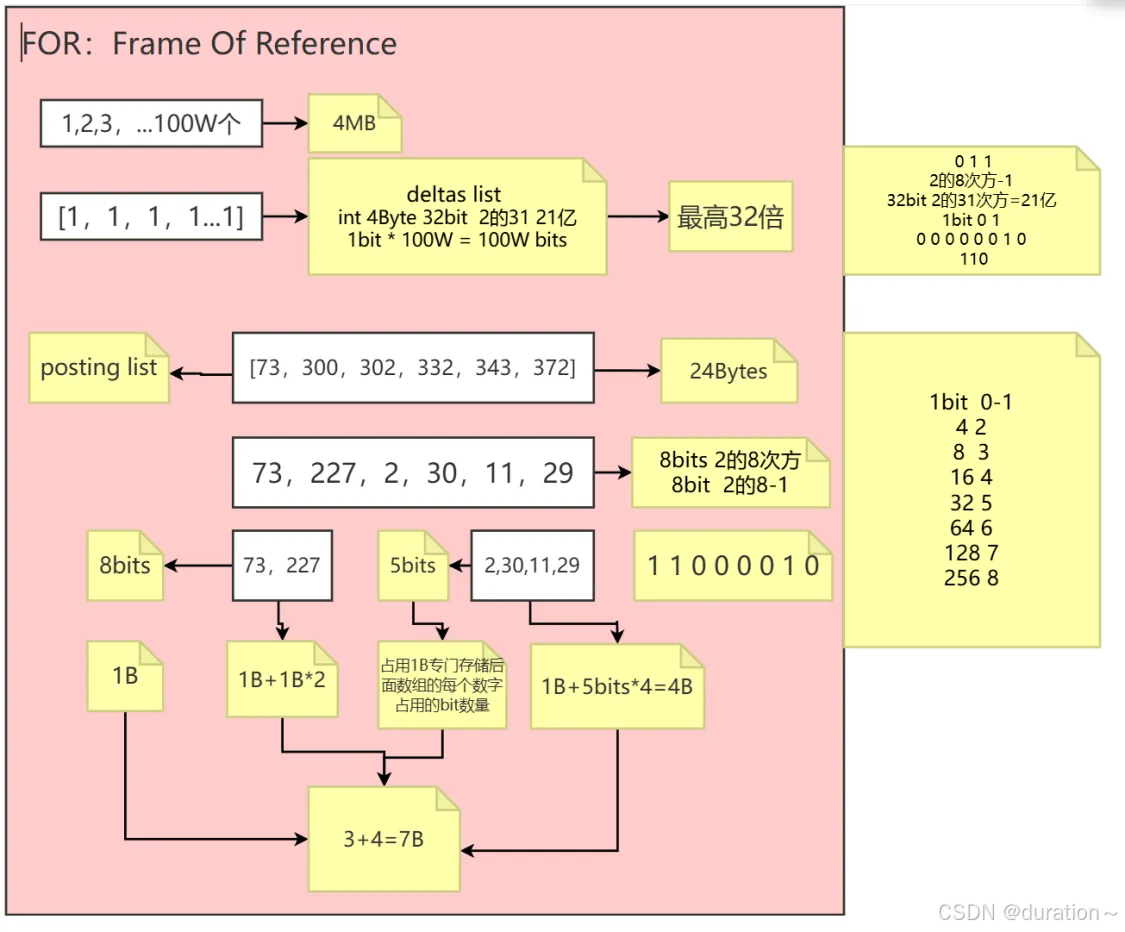
Frame Of Reference压缩算法
文章目录 1_概述2_算法基本步骤3_过程优化4_优势以及局限5_模拟实现6_总结 1_概述 Frame of Reference(FoR)压缩算法 是一种用于压缩数值数据的算法,特别是在处理大规模数据集时,利用数据的局部性和重复性来减少存储和传输的开销…...

1.0 软件测试全流程解析:从计划到总结的完整指南
软件测试全流程解析:从计划到总结的完整指南 摘要 本文档详细介绍了软件测试的完整流程,包括测试计划、测试设计、测试执行、测试报告和测试总结等主要阶段。每个阶段都从目标、主要工作、输出物和注意事项等方面进行了详细说明。通过本文档࿰…...

嵌入式AI简介
嵌入式AI是一种将人工智能算法部署在终端设备中运行的技术,使智能硬件能够在本地实时完成感知、交互和决策功能,无需依赖云端计算。以下是其核心要点: 一、核心特点 1. 本地化处理:数据在设备端直接处理,无需联网&a…...