【NLP 面经 7、常见transformer面试题】
目录
1. 为何使用多头注意力机制?
2. Q和K使用不同权重矩阵的原因
3. 选择点乘而非加法的原因
4. Attention进行scaled的原因
5. 对padding做mask操作
6. 多头注意力降维原因
7. Transformer Encoder模块简介
8. 乘以embedding size的开方的意义
9. 位置编码
10. 其他位置编码技术
11. Transformer中的残差结构及其意义
12. LayerNorm与BatchNorm
13. BatchNorm介绍
14. Transformer的前馈神经网络
15. Encoder与Decoder的交互
16. Decoder自注意力与Encoder的区别
17. Transformer的并行化
18. WordPiece Model与Byte Pair Encoding
19. Transformer训练中的学习率与Dropout
20. BERT与Transformer attention屏蔽技巧
你最擅长说狠话,然后转身就流泪
—— 25.4.5
1. 为何使用多头注意力机制?
多头注意力机制使得模型能够并行处理信息的不同方面,每个头可以专注于输入序列的不同位置或特征,从而捕捉更丰富、更细腻的上下文依赖。单头注意力虽然也能捕捉序列间的关系,但其关注范围相对有限。多头机制提高了模型的表达能力,相当于模型可以“多视角”地审视输入数据,每个多头可以学习到不同类型的注意力模式,共同提升整体性能。
2. Q和K使用不同权重矩阵的原因
Q(查询)和K(键)使用不同的权重矩阵是因为这样能够增加模型的非线性表达能力,允许模型从不同角度(或维度)分别编码查询和键的信息。如果Q和K共享相同的权重矩阵,则它们会生成相同或高度相关的向量空间表示,限制了模型识别不同模式的能力。不同矩阵生成的Q和K进行点乘,可以更灵活地衡量不同部分输入之间的相关性。
3. 选择点乘而非加法的原因
点乘在计算复杂度上与加法相似,但在效果上,点乘能够更好地捕捉向量间的相似度,因为它考虑了元素级别的乘积,这在数学上等价于内积,可以衡量两个向量的“方向”一致性。而加法则更多反映的是两个向量的总“大小”。在注意力机制中,我们关心的是向量间关系的密切程度,因此点乘更适合。
4. Attention进行scaled的原因
除以 dk 是为了避免点积的结果因向量长度的增加而过分放大,导致softmax函数在计算概率分布时出现梯度消失或饱和问题。这有助于模型训练更加稳定,尤其是在维度较大的情况下。公式上, Attention(Q,K,V)=softmax(QKTdk)V ,其中, dk 是分母的缩放因子。
5. 对padding做mask操作
在计算attention score时,可以为padding位置的值设置为非常小的负数(如-1e9),这样经过softmax后,这些位置的权重接近0,即在计算上下文表示时忽略padding位置的影响。
6. 多头注意力降维原因
每个头进行降维是为了在不增加过多计算成本的前提下,允许模型探索更多的注意力子空间。多个低维头相比于单个高维头,可以在同样计算资源下学习更丰富的特征组合。
7. Transformer Encoder模块简介
Encoder由多个相同的层堆叠而成,每一层包括Self-Attention子层和一个前馈神经网络(FFN)子层,两侧均有残差连接和Layer Normalization。Self-Attention帮助捕获输入序列的长距离依赖,FFN引入非线性,增强模型表达能力。
8. 乘以embedding size的开方的意义
在输入词嵌入后乘以 dmodel 主要是为了初始化时调整词向量的尺度,使其初始分布更为合理,避免训练初期的爆炸或消失梯度问题,提高模型训练的稳定性。
9. 位置编码
位置编码是为了让Transformer能够理解序列中元素的位置信息,因为Transformer架构本身不包含循环或卷积结构,无法直接捕获位置信息。位置编码通过在词嵌入上添加特定模式的向量来实现,这些模式通常是正弦和余弦函数的组合,能区分不同位置的输入。
10. 其他位置编码技术
绝对位置编码:如上述,直接添加到词嵌入中。
相对位置编码:仅编码词对之间的相对距离,更灵活,常用于Transformer-XL等模型中。
** Rotary Positional Embedding**:提出于RoPE,旋转式位置编码,利用复数旋转矩阵动态调整词嵌入,保持位置信息的相对性,适合长序列任务。
11. Transformer中的残差结构及其意义
残差连接允许信息直接跳过复杂的子层(如Self-Attention和FFN),直接传递到下一层,减轻了梯度消失问题,加速了模型收敛,并且增加了模型深度,提高表达能力。
12. LayerNorm与BatchNorm
LayerNorm在Transformer中用于每个样本的每个特征维度上标准化,保证了不同层间输入的分布一致,适用于Transformer这种没有固定批量大小(尤其是解码器自注意力时)和顺序无关的场景。
LayerNorm一般置于每个子层的输入或输出端,有助于训练稳定性和速度。
BatchNorm基于整个batch的数据进行标准化,不适合Transformer这类序列到序列模型,因其依赖于固定长度的批次。
13. BatchNorm介绍
BatchNorm在训练时对每个mini-batch的数据进行标准化,减少内部协变量偏移,加速收敛,提高模型泛化能力。缺点包括增加了训练时间,对小批量数据效果不佳,且不适用于RNN等序列模型。
14. Transformer的前馈神经网络
Transformer的FFN通常包含两个线性变换层,中间夹着ReLU或GELU激活函数。这种结构引入非线性,增强了模型的表达能力。GELU相比ReLU,具有更好的非线性表达和光滑性,有助于模型学习更复杂的特征。
15. Encoder与Decoder的交互
Encoder和Decoder通过编码器-解码器注意力(Encoder-Decoder Attention)机制交互。在Decoder阶段,每个位置的单词不仅关注自身序列内的其他单词(自注意力),还关注Encoder的输出,从而在生成目标序列时考虑源序列的全局信息。
16. Decoder自注意力与Encoder的区别
Decoder的多头自注意力机制在训练时需要加入“未来遮挡”(sequence mask),确保在生成当前位置的输出时,模型只能看到过去的位置信息,不能看到未来的信息,符合自然语言的生成逻辑,避免信息泄露。
17. Transformer的并行化
Transformer模型设计上天然支持并行计算,特别是在自注意力和前馈网络层。由于其计算可以被拆分为独立的向量运算,非常适合GPU等并行计算硬件。Decoder端虽然在自注意力层受到序列依赖的限制,但除自注意力外的其它部分仍可并行化。
18. WordPiece Model与Byte Pair Encoding
WordPiece: 是一种文本分词方法,将文本切分成一系列有意义的子词单元。广泛应用于BERT等模型,有利于处理罕见词汇。
Byte Pair Encoding (BPE): 通过统计文本中最频繁出现的字符对来构建词汇表。随着迭代,新的符号是由最频繁出现的字符对组成。适用于多种语言,包括稀有语种。
19. Transformer训练中的学习率与Dropout
学习率:通常采用预热(warmup)策略,初期缓慢增加,之后按预定策略衰减,如线性衰减或余弦退火,以平衡初期的快速学习和后期的精细调整。
Dropout:在训练期间随机“丢弃”一部分神经元,防止模型过度拟合。通常设置在0.1至0.5之间,应用在全连接层和自注意力输出。测试时不需要使用Dropout,以得到确定性的输出。
20. BERT与Transformer attention屏蔽技巧
BERT在训练过程中使用了Masked Language Model任务,但它并未直接在注意力机制上进行屏蔽操作。这是因为BERT主要关注于如何从掩码输入中预测缺失的token,而Transformer的自注意力机制中加入的mask是用来确保解码器生成时只依赖于过去的上下文,这是两种不同的应用场景和目的。
相关文章:
【NLP 面经 7、常见transformer面试题】
目录 1. 为何使用多头注意力机制? 2. Q和K使用不同权重矩阵的原因 3. 选择点乘而非加法的原因 4. Attention进行scaled的原因 5. 对padding做mask操作 6. 多头注意力降维原因 7. Transformer Encoder模块简介 8. 乘以embedding size的开方的意义 9. 位置编码 10. 其…...

分布式事务解决方案全解析:从经典模式到现代实践
前言 在分布式系统中,数据一致性是一个核心问题。随着微服务架构的普及,跨服务、跨数据库的操作变得越来越普遍,如何保证这些操作的原子性、一致性、隔离性和持久性(ACID)成为了一个极具挑战性的任务。本文将全面介绍…...
)
软件工程面试题(二十七)
1、j a v a 对象初始化顺序 1.类的初始化(initialization class & interface) 2.对象的创建(creation of new class instances) 顺序:应为类的加载肯定是第一步的,所以类的初始化在前。大体的初始化顺序是: 类初始化 -> 子类构造函数 -> 父类构造函数 -&g…...

fastGPT—nextjs—mongoose—团队管理之部门相关api接口实现
创建部门或者子部门 import type { NextApiRequest, NextApiResponse } from next; import { NextAPI } from /service/middleware/entry; import { MongoOrgModel } from fastgpt/service/support/permission/org/orgSchema;async function handler(req: NextApiRequest, res…...

C++ 数据竞态检查
-fsanitizethread 编译时,添加参数-fsanitizethread -g,可以运行态检查数据竞态问题,包括: 数据竞态死锁锁、条件变量错误使用 check_tsan 开源库 yalantinglibs有段检查编译器是否支持 fsanitize 编译参数的宏,挺…...

逛好公园的好处
逛公园和软件开发看似是两个不同的活动,但它们之间存在一些有趣的关联和相互促进的关系: 激发创造力:公园中的自然景观、多样的人群以及各种活动能为开发者带来新的灵感和创意。软件开发过程中,从公园中获得的创意可以帮助开发者设…...

C++开发工具全景指南
专业编译与调试工具深度解析 2025年4月 编译器套件 GNU Compiler Collection (GCC) GNU编译器套件是自由软件基金会开发的跨平台编译器系统,支持C、C、Objective-C、Fortran、Ada等多种编程语言。作为Linux系统的标准编译器,GCC以其强大的优化能力和…...

【网络安全】 防火墙技术
防火墙是网络安全防御的重要组成部分,它的主要任务是阻止或限制不安全的网络通信。在这篇文章中,我们将详细介绍防火墙的工作原理,类型以及如何配置和使用防火墙。我们将尽可能使用简单的语言和实例,以便于初学者理解。 一、什么…...
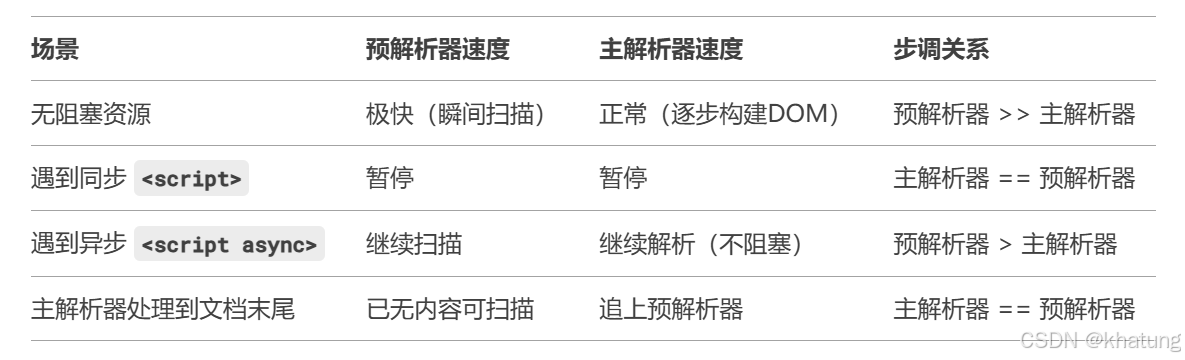
文档的预解析
1. 预解析的核心目标 浏览器在正式解析(Parsing)HTML 前,会启动一个轻量级的 预解析器(Pre-Parser),快速扫描文档内容,实现: 提前发现并加载关键资源(如 CSS、JavaScrip…...

理解“功能内聚”
链接: 理解“偶然内聚” 理解“逻辑内聚” 理解“时间内聚” 理解“过程内聚” 理解“通信内聚” 理解“顺序内聚” 理解“功能内聚” 功能内聚(Functional Cohesion)是最高级别的内聚形式,指的是模块内的所有元素都紧密地围绕着一…...

windows 常用命令总结
工作中用到的 Linux 总结(持续更新中...)_linux工作经验-CSDN博客 PS: 推荐使用 powershell 而不是 cmd,因为PowerShell 是一个更先进和功能更强大的工具( powershell 有命令记忆功能,比较方便)…...
记一次表格数据排序优化(一)--排序30000条数据有多卡
目录 需求 第一次尝试 运行环境 思路 存储 排序 触发排序操作 如何实现高效的排序 关键1 关键2 关键3 磨刀不误砍柴工 关键4 代码 效果 卡顿原因分析 原因1 原因2 第二次尝试 需求 1 我的qt程序通过表格显示30000条数据。数据来自udp,udp每隔10秒…...
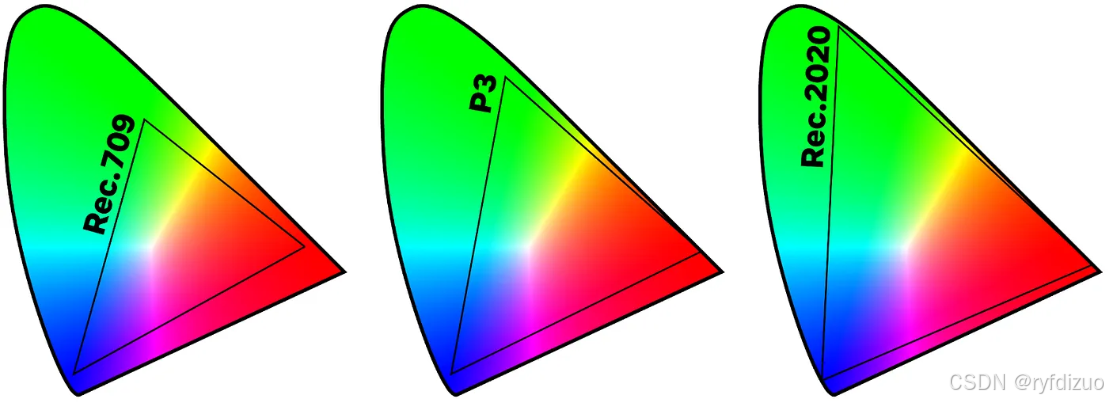
图形渲染中的定点数和浮点数
三种API的NDC区别 NDC全称,Normalized Device Coordinates Metal、Vulkan、OpenGL的区别如下: featureOpenGL NDCMetal NDCVulkan NDC坐标系右手左手右手z值范围[-1,1][0,1][0,1]xy视口范围[-1,1][-1,1][-1,1] GPU渲染的定点数和浮点数 定点数类型&a…...

【深度学习】CNN简述
文章目录 一、卷积神经网络(CNN)二、CNN结构特性1. CNN 典型结构2. 局部连接3. 权重共享4.空间或时间上的次采样 三、理解层面 一、卷积神经网络(CNN) 卷积神经网络(Convolutional Neural Network,CNN)是一种用于处理…...
强化学习课程:stanford_cs234 学习笔记(3)introduction to RL
文章目录 前言7 markov 实践7.1 markov 过程再叙7.2 markov 奖励过程 MRP(markov reward process)7.3 markov 价值函数与贝尔曼方程7.4 markov 决策过程MDP(markov decision process)的 状态价值函数7.4.1 状态价值函数7.4.2 状态…...

紫檀博物馆一游与软件开发
今天去逛了中国紫檀博物馆,里边很多层展品,也有一些清代的古物,檀木,黄花梨木家具和各种摆件,馆主陈丽华女士也是发心复原、保留和弘扬中国的传统文化,和西游记唐僧扮演者迟成瑞先生一家。 每一件展品都精…...
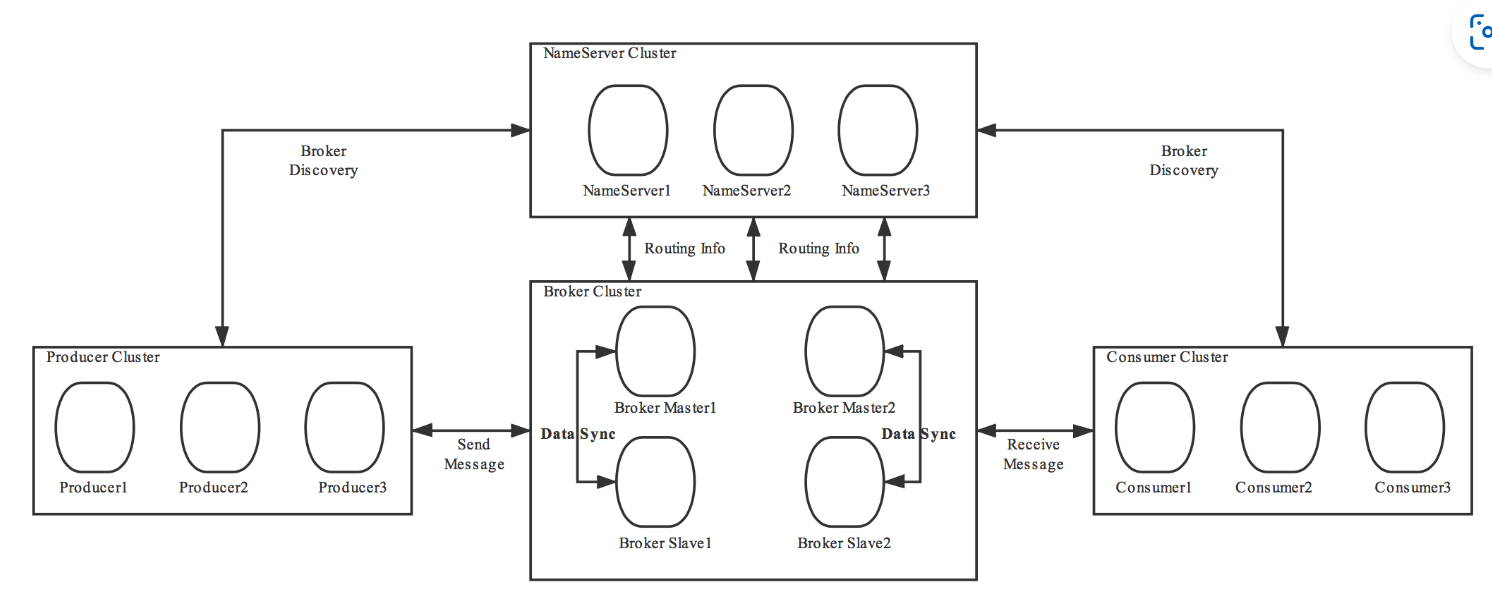
RocketMQ初认识
ProducerCustomerNameServer: Broker的注册服务发现中心BrokerServer:主要负责消息的存储、投递和查询以及服务高可用保证 RocketMQ的集群部署: 单个master的分支多个Master 模式:集群中有多个 Master 节点,彼此之间相互独立。生产者可以将消…...

第十三章:持久化存储_《凤凰架构:构建可靠的大型分布式系统》
第十三章 持久化存储 一、Kubernetes存储设计核心概念 (1)存储抽象模型 PersistentVolume (PV):集群级别的存储资源抽象(如NFS卷/云存储盘)PersistentVolumeClaim (PVC):用户对存储资源的声明请求&#…...
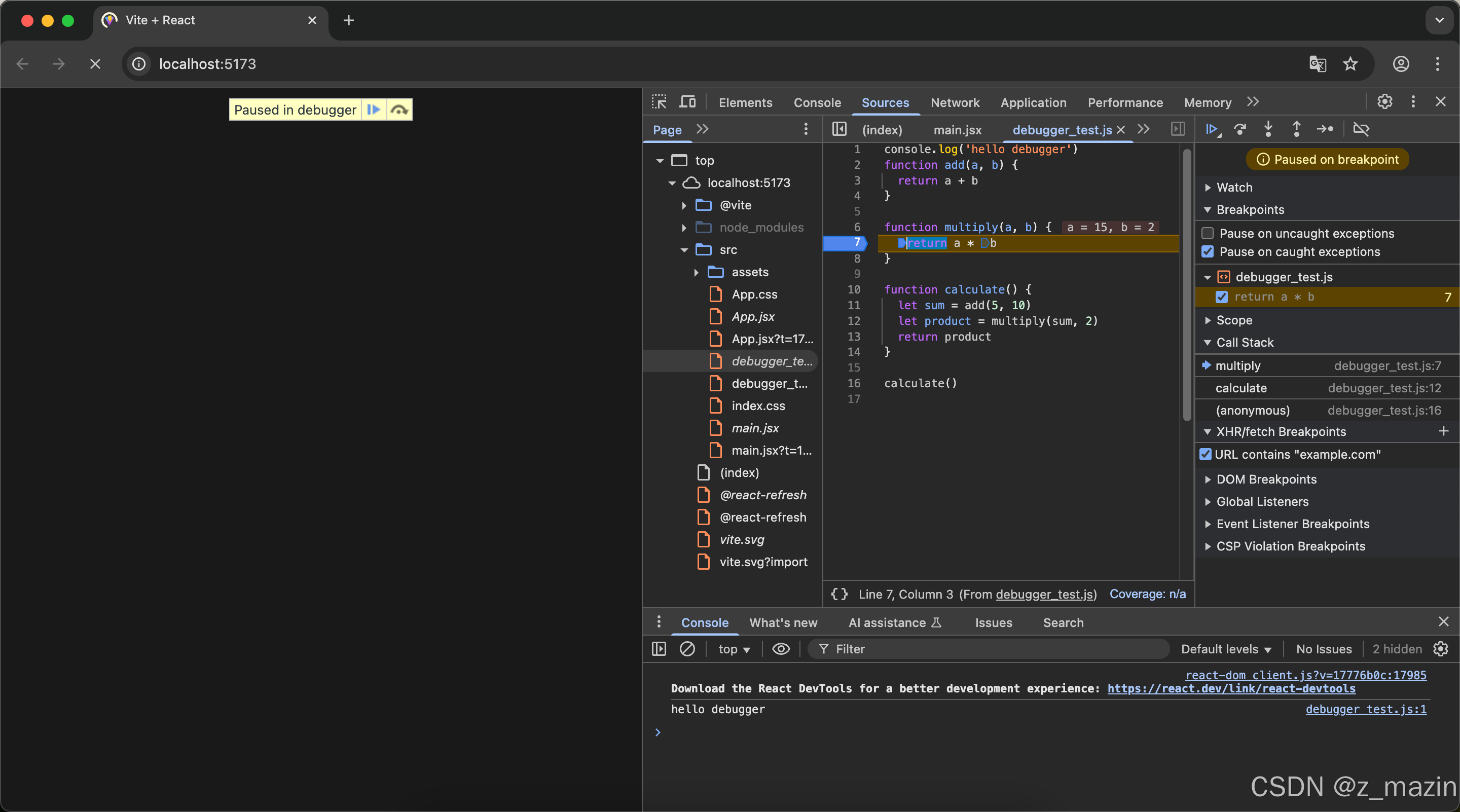
Chrome开发者工具实战:调试三剑客
在前端开发的世界里,Chrome开发者工具就是我们的瑞士军刀,它集成了各种强大的功能,帮助我们快速定位和解决代码中的问题。今天,就让我们一起来看看如何使用Chrome开发者工具中的“调试三剑客”:断点调试、调用栈跟踪和…...

教程:如何使用 JSON 合并脚本
目录 1. 介绍 2. 使用方法 3. 注意事项 4. 示例 5.完整代码 1. 介绍 该脚本用于将多个 COCO 格式的 JSON 标注文件合并为一个 JSON 文件。COCO 格式常用于目标检测和图像分割任务,包含以下三个主要部分: "images":图像信息&a…...
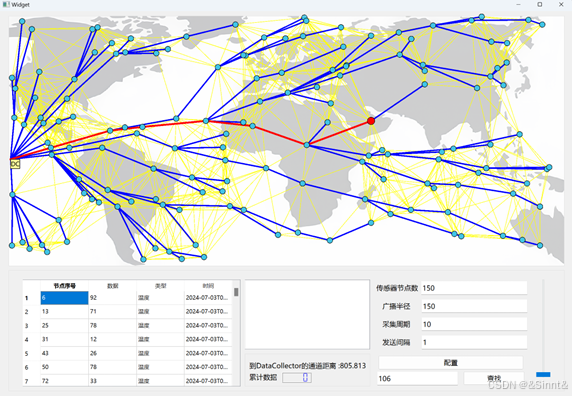
C++/Qt 模拟sensornetwork的工作
C/Qt 可视化模拟sensornetwork的工作 C/Qt 模拟sensornetwork的工作 C/Qt 可视化模拟sensornetwork的工作内容简介(一) 需求和规格说明(1)问题描述(2)设计目的(3)基本要求࿰…...

ffmpeg音频分析
对一个16k 单声道音频,生成频谱图 ./ffmpeg -i input.wav -lavfi "showspectrumpics800x400:modecombined:scalelin:gain1.5" spectrum.png...

【多线程】CAS机制
目录 一. CAS的概念 二. CAS的原理 三.标准库中的CAS 四. CAS的应用 (1)原子类的使用 (2) 自旋锁的实现 五. CAS的ABA问题 一. CAS的概念 CAS(Compare And Swap)机制是一种无锁的并发控制技术&#…...
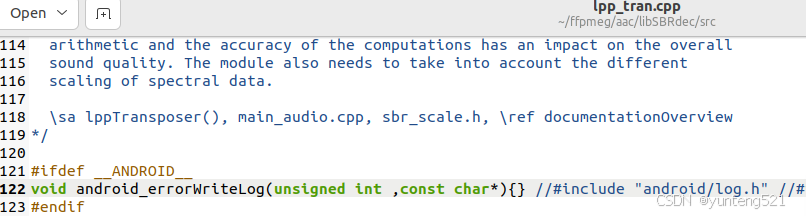
音视频(四)android编译
前言 前面已经讲了在windows上应用了,这章主要讲述android上编译 1:环境 git 如果失败 直接跑到相应网站 手动下载 ubuntu22.* android ndk r21e download:https://developer.android.google.cn/ndk/downloads/index.html?hluk 为什么用这个࿰…...

Chapter07_图像压缩编码
文章目录 图像压缩编码图像压缩编码基础图像压缩的基本概念信息相关信息冗余信源编码及其分类 图像编码模型信源编码器模型信源解码器模型 数字图像的信息熵信源符号码字平均长度信息熵信息量 变长编码费诺码霍夫曼编码 位平面编码格雷码 图像压缩编码 数字图像的压缩是指在满…...

团体设计程序天梯赛L2-025 # 分而治之
文章目录 题目解读输入格式输出格式 思路Ac Code参考 题目解读 在战争中,我们希望首先攻下敌方的部分城市,使其剩余的城市变成孤立无援,然后再分头各个击破。为此参谋部提供了若干打击方案。本题就请你编写程序,判断每个方案的可…...
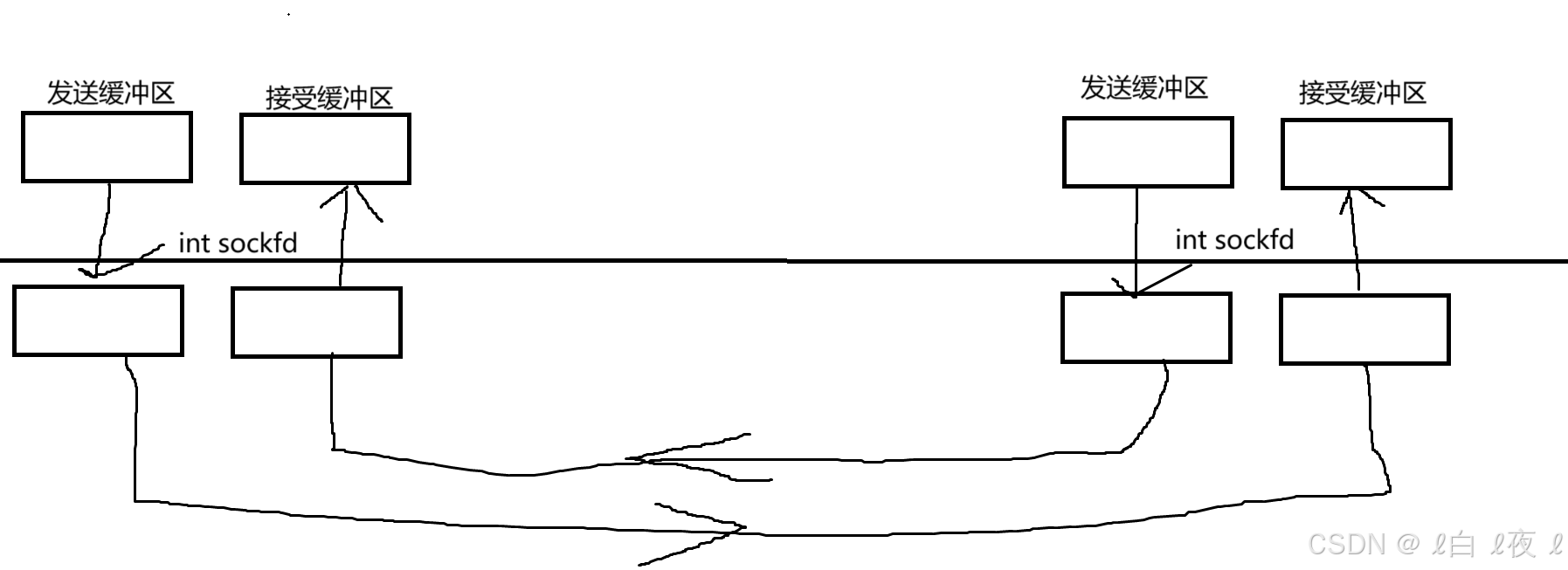
Linux网络套接字
Socket 编程 UDP 本章将函数介绍和代码编写实战一起使用。 IPv4 的 socket 网络编程,sockaddr_in 中的成员 struct in_addr.sin_addr 表示 32 位 的 IP 地址 但是我们通常用点分十进制的字符串表示 IP 地址,以下函数可以在字符串表示和in_addr 表示之间转换; 字符串转 in_addr…...

看爬山虎学本领 软爬机器人来创新 各种场景能适应
*本文只做阅读笔记分享* 一、灵感来源:向植物取经 大家好!今天来聊一款超酷的软爬机器人,它的灵感来自会攀爬的植物——爬山虎。 大家都知道,爬墙高手爬山虎能在各种复杂墙面轻松生长攀爬,可现有的攀爬机器人在复杂…...

1-Docker安装
1.准备环境 1.第一步:创建以自己的姓名全拼的用户名 [roothadoop ~]# useradd qiwenyong [roothadoop ~]# passwd qiwenyong Changing password for user qiwenyong. New password: BAD PASSWORD: The password is shorter than 7 characters Retype new passwor…...
-- 第三部分:JS宏编程语言开发基础)
WPS JS宏编程教程(从基础到进阶)-- 第三部分:JS宏编程语言开发基础
第三部分:JS宏编程语言开发基础 @[TOC](第三部分:JS宏编程语言开发基础)**第三部分:JS宏编程语言开发基础**1. 变量与数据类型**变量声明:三种方式****示例代码****数据类型判断****实战:动态处理单元格类型**2. 运算符全解析**算术运算符****易错点:字符串拼接 vs 数值相…...