强化学习课程:stanford_cs234 学习笔记(3)introduction to RL
文章目录
- 前言
- 7 markov 实践
- 7.1 markov 过程再叙
- 7.2 markov 奖励过程 MRP(markov reward process)
- 7.3 markov 价值函数与贝尔曼方程
- 7.4 markov 决策过程MDP(markov decision process)的 状态价值函数
- 7.4.1 状态价值函数
- 7.4.2 状态价值函数的 贝尔曼期望方程(Bellman Expectation Equation)
- 7.5 markov 决策过程MDP(markov decision process)的 动作价值函数
- 7.5.1 动作价值函数
- 7.5.2 动作价值函数和状态价值函数
- 7.5.3 动作价值函数的贝尔曼期望等式
- 7.6 动作价值和状态价值例子
- 7.6.1 边缘化(marginalization),就
前言
第一节课的后半段其实就是一个马尔可夫的实际案例教学,我这里在网上找到一个合适案例进行学习,cs234 的课程感觉有点空。

7 markov 实践
7.1 markov 过程再叙
markov 过程就是一个状态转移过程,且该当前状态只和上一个状态有关,和历史无关。
即: P ( s t ∣ s t − 1 ) = P ( s t ∣ s t − 1 , s t − 2 , s t − 3 , . . . , s n ) P(s_t| s_{t-1}) = P(s_t | s_{t-1}, s_{t-2}, s_{t-3},...,s_n) P(st∣st−1)=P(st∣st−1,st−2,st−3,...,sn)
markov 状态转移矩阵:
P = [ p s 1 ∣ s 1 p s 2 ∣ s 1 . . . p s n ∣ s 1 p s 2 ∣ s 1 p s 2 ∣ s 2 . . . p s n ∣ s 2 . . . p s 1 ∣ s n p s 2 ∣ s n . . . p s n ∣ s n ] P= \begin{equation} \begin{bmatrix} p_{s_1|s_1} & p_{s_2|s_1} &...& p_{s_n|s_1} \\ p_{s_2|s_1} & p_{s_2|s_2} &...& p_{s_n|s_2} \\ ... \\ p_{s_1|s_n} & p_{s_2|s_n} &...& p_{s_n|s_n} \end{bmatrix} \end{equation} P= ps1∣s1ps2∣s1...ps1∣snps2∣s1ps2∣s2ps2∣sn.........psn∣s1psn∣s2psn∣sn
矩阵中的 第i行第j列表示状态 s i s_i si 到 s j s_j sj 的概率 p ( s i ∣ s j ) = p ( s t + 1 = s j ∣ s t = s i ) p(s_i|s_j) = p(s_{t+1}=s_j | s_{t} = s_i) p(si∣sj)=p(st+1=sj∣st=si)。称
P ( s ′ ∣ s ) P(s' | s) P(s′∣s) 为转移函数。这里要求 从某个状态到其他所有状态的概率和必须为1, 即P矩阵每行概率和为1
如果我们按照满足markov 性,根据状态转移矩阵,得到一个状态转移序列
s1->s1->s2->s3->s4->s5->s6 那么就得到了一个markov chain 即马尔可夫链。
7.2 markov 奖励过程 MRP(markov reward process)
马尔可夫奖励过程是 [S, P r, γ \gamma γ]
S:状态集合
P:状态转移矩阵
r : reward
γ \gamma γ:discount factor
为什么要奖励(reward)?
(1)一个稳定的世界需要反馈,合理的反馈可以让我们趋于一个稳定。
因此引入奖励机制。我们将奖励机制和markov 过程结合,那么有
(2)我们针对不同场景,有不同的回报,因此奖励机制可以调整我们如何适应变化的环境。
为什么要折扣(discount factor)
(1)一个马尔可夫过程是有可能出现闭环,如果无限循环下去,那么奖励就有可能无限累加,要避免这种奖励因子不断累加,那么就需要折扣。在想想这句古话:一股做气,再而衰,三而竭。这不就是折扣因子么。
(2)有时候我们需要近期的效果,那么我们会将长远利益打一些折扣。相反,我们关注长远利益时,需要近期利益打折扣
将reward 和 discount factor 结合得到回报(Return)
G t = R t + γ ∗ R t + 1 + γ 2 ∗ R t + 2 + . . . = ∑ k = 0 ∞ γ k R t + k G_t=R_{t} + \gamma*R_{t+1} + \gamma^2*R_{t+2} + ... = \sum_{k=0}^{\infty}\gamma^kR_{t+k} Gt=Rt+γ∗Rt+1+γ2∗Rt+2+...=∑k=0∞γkRt+k
7.3 markov 价值函数与贝尔曼方程
价值(value):一个状态的期望回报,即从这个状态出发的未来累积奖励的期望值,被称为这个状态的价值:
V ( s ) = E [ R t + γ ∗ R t + 1 + γ 2 ∗ R t + 2 + . . . ∣ s = s t ] = E [ R t + γ ( R t + 1 + γ ∗ R t + 2 + . . . ∣ s = s t ) ] = E [ R t + γ G ( s = s t + 1 ∣ s = s t ) ] = E [ R t + γ G t + 1 ∣ s = s t ] = E [ R t ∣ s t ] + E γ G t + 1 ∣ s t = r ( s ) + γ V t + 1 ∣ s = s t = r ( s ) + γ ∑ p ( s t + 1 ∣ s t ) V t + 1 , 注:我第一遍推成 r ( s ) + γ ∑ p ( s t + 1 ∣ s t ) V t ,导致后面直接推不下去了 = r ( s ) + γ ∑ p ( s ′ ∣ s ) V ( s ′ ) , s ′ ∈ S = 贝尔曼方程( B e l l m a n E q u a t i o n ) V(s)\\ = E[R_{t} + \gamma*R_{t+1} + \gamma^2*R_{t+2} + ... | s=s_t]\\ = E[R_t + \gamma (R_{t+1} + \gamma*R_{t+2} + ...| s=s_t)]\\ = E[R_t + \gamma G(s=s_{t+1}|s=s_{t})]\\ = E[R_t + \gamma G_{t+1}|s=s_{t}]\\ = E[R_t|s_t] + E\gamma G_{t+1}| s_t\\ = r(s) + \gamma V_{t+1}|s=s_{t}\\ = r(s) + \gamma \sum{ p(s_{t+1}|s_t)V_{t+1}},\textcolor{#FF0000}{注:我第一遍推成r(s) + \gamma \sum{ p(s_{t+1}|s_t)V_t},导致后面直接推不下去了}\\ = r(s) + \gamma \sum{ p(s'|s)V(s')}, s' \in S \\ = 贝尔曼方程(Bellman Equation) V(s)=E[Rt+γ∗Rt+1+γ2∗Rt+2+...∣s=st]=E[Rt+γ(Rt+1+γ∗Rt+2+...∣s=st)]=E[Rt+γG(s=st+1∣s=st)]=E[Rt+γGt+1∣s=st]=E[Rt∣st]+EγGt+1∣st=r(s)+γVt+1∣s=st=r(s)+γ∑p(st+1∣st)Vt+1,注:我第一遍推成r(s)+γ∑p(st+1∣st)Vt,导致后面直接推不下去了=r(s)+γ∑p(s′∣s)V(s′),s′∈S=贝尔曼方程(BellmanEquation)
于是我们不难得到:
当s’= s1的时候:
[ V ( s 1 ) ] = [ r ( s 1 ) ] + γ [ p s 1 ∣ s 1 p s 2 ∣ s 1 . . . p s n ∣ s 1 ] [ V ( s 1 ) V ( s 2 ) . . . V ( s n ) ] \begin{equation} \begin{bmatrix} V(s_1) \\ \end{bmatrix} = \begin{bmatrix} r(s_1) \\ \end{bmatrix} + \gamma \begin{bmatrix} p_{s_1|s_1} & p_{s_2|s_1} &...& p_{s_n|s_1} \\ \end{bmatrix} \begin{bmatrix} V(s1) \\ V(s2) \\ ... \\ V(sn)\\ \end{bmatrix} \end{equation} [V(s1)]=[r(s1)]+γ[ps1∣s1ps2∣s1...psn∣s1] V(s1)V(s2)...V(sn)
当s’=s2的时候:
[ V ( s 2 ) ] = [ r ( s 2 ) ] + γ [ p s 1 ∣ s 2 p s 2 ∣ s 2 . . . p s n ∣ s 2 ] [ V ( s 1 ) V ( s 2 ) . . . V ( s n ) ] \begin{equation} \begin{bmatrix} V(s_2) \\ \end{bmatrix} = \begin{bmatrix} r(s_2) \\ \end{bmatrix} + \gamma \begin{bmatrix} p_{s_1|s_2} & p_{s_2|s_2} &...& p_{s_n|s_2} \\ \end{bmatrix} \begin{bmatrix} V(s1) \\ V(s2) \\ ... \\ V(sn)\\ \end{bmatrix} \end{equation} [V(s2)]=[r(s2)]+γ[ps1∣s2ps2∣s2...psn∣s2] V(s1)V(s2)...V(sn)
接下来,我们写成矩阵形式:
[ V ( s 1 ) V ( s 2 ) . . . V ( s n ) ] = [ r ( s 1 ) r ( s 2 ) . . . r ( s n ) ] + γ [ p s 1 ∣ s 1 p s 2 ∣ s 1 . . . p s n ∣ s 1 p s 2 ∣ s 1 p s 2 ∣ s 2 . . . p s n ∣ s 2 . . . p s 1 ∣ s n p s 2 ∣ s n . . . p s n ∣ s n ] [ V ( s 1 ) V ( s 2 ) . . . V ( s n ) ] \begin{equation} \begin{bmatrix} V(s1) \\ V(s2) \\ ... \\ V(sn)\\ \end{bmatrix} = \begin{bmatrix} r(s1) \\ r(s2) \\ ... \\ r(sn)\\ \end{bmatrix} + \gamma \begin{bmatrix} p_{s_1|s_1} & p_{s_2|s_1} &...& p_{s_n|s_1} \\ p_{s_2|s_1} & p_{s_2|s_2} &...& p_{s_n|s_2} \\ ... \\ p_{s_1|s_n} & p_{s_2|s_n} &...& p_{s_n|s_n} \end{bmatrix} \begin{bmatrix} V(s1) \\ V(s2) \\ ... \\ V(sn)\\ \end{bmatrix} \end{equation} V(s1)V(s2)...V(sn) = r(s1)r(s2)...r(sn) +γ ps1∣s1ps2∣s1...ps1∣snps2∣s1ps2∣s2ps2∣sn.........psn∣s1psn∣s2psn∣sn V(s1)V(s2)...V(sn)
于是就得到:
V = R + γ P V V=R+\gamma P V V=R+γPV
V − γ P V = R V - \gamma P V=R V−γPV=R
( I − γ P ) V = R (I - \gamma P)V = R (I−γP)V=R
V = ( I − γ P ) − 1 R V=(I - \gamma P)^{-1}R V=(I−γP)−1R
按照以往计算经验,这个矩阵解起来巨麻烦,所以会用 动态规划(dynamic programming)、 **蒙特卡罗(模拟特-Carlo method)**方法 或 时序差分(temporal difference)
7.4 markov 决策过程MDP(markov decision process)的 状态价值函数
7.4.1 状态价值函数
智能体(agent)的策略(Policy)通常用 π \pi π表示。策略 π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi(a|s) = P(A_t = a| S_t = s) π(a∣s)=P(At=a∣St=s)是一个函数,表示在s状态下采取a动作的概率。当一个策略是确定性策略(deterministic policy)的时候,那么智能体在每个状态只输出一个确定动作。
当智能体的策略是随机测策略(stochastic policy)时,那么这个函数输出的是关于动作的概率分布。
状态价值函数:
我们用 V π ( s ) V^{\pi}(s) Vπ(s)表示在MDP基于测率 π \pi π策略得到的价值函数期望:
V π ( s ) = E π [ G t ∣ S t = s ] V^{\pi}(s) = E_\pi[G_t | S_t= s] Vπ(s)=Eπ[Gt∣St=s],
我这里专门推敲了下: V π V^\pi Vπ和 V 是一回事,只是为了讲名是什么策略,因此加了 π \pi π,即乘以一个概率。
7.4.2 状态价值函数的 贝尔曼期望方程(Bellman Expectation Equation)
根据上面贝尔曼方程算 V ( s ) V(s) V(s):
V ( s ) = r ( s ) + γ ∑ p ( s ′ ∣ s ) V ( s ′ ) , s ′ ∈ S V(s) = r(s) + \gamma \sum{ p(s'|s)V(s')}, s' \in S V(s)=r(s)+γ∑p(s′∣s)V(s′),s′∈S
当我们要将在那个策略下时,不难得到:
V π ( s ) = E π [ G t ∣ S t = s ] = ∑ π ( a ∣ s ) [ r ( s ) + γ ∑ p ( s ′ ∣ s ) V ( s ′ ) ] , s ′ ∈ S V^{\pi}(s) = E_\pi[G_t | S_t= s]\\ =\sum \pi(a|s) [ r(s) + \gamma \sum{ p(s'|s)V(s') } ], s' \in S Vπ(s)=Eπ[Gt∣St=s]=∑π(a∣s)[r(s)+γ∑p(s′∣s)V(s′)],s′∈S——因为需要策略 π \pi π得概率,因此需要乘以 π \pi π
V π ( s ) = r ( s , a ) + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) ∑ a ′ ∈ A π ( a ∣ s ′ ) Q π ( s ′ , a ′ ) V^\pi(s)=r(s, a) + \gamma \sum_{s' \in S} p(s'|s, a) \sum_{a' \in A}\pi(a|s') Q^{\pi} (s',a') Vπ(s)=r(s,a)+γ∑s′∈Sp(s′∣s,a)∑a′∈Aπ(a∣s′)Qπ(s′,a′)
7.5 markov 决策过程MDP(markov decision process)的 动作价值函数
markov 决策过程MDP(markov decision process)—— 动作价值函数
7.5.1 动作价值函数
不同于MRP,在MDP过程中,由于动作的存在,额外定义一个动作价值函数(action-value function)。用 Q π Q^\pi Qπ 表示,在s 状态下,执行动作a的得到的期望:
Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] Q^\pi(s, a) = E_\pi[G_t | S_t = s, A_{t}=a] Qπ(s,a)=Eπ[Gt∣St=s,At=a] 。说实话我这里被定义给搞晕了,因此我理解这里就是不需要乘以 π ( a ∣ s ) \pi(a|s) π(a∣s)
7.5.2 动作价值函数和状态价值函数
所以得到 V π V^{\pi} Vπ和 Q π Q^\pi Qπ的关系:
(1) V π ( s ) = ∑ a ∈ A π ( a ∣ s ) Q π ( s , a ) V^{\pi}(s) = \sum_{a \in A} \pi(a|s) Q^\pi(s, a) Vπ(s)=∑a∈Aπ(a∣s)Qπ(s,a)
这个式子描述的是:使用策略 π \pi π, 状态 s的价值期望,等于动作价值函数乘以发生动作概率的乘积的总和。这里是动作未发生,需要乘上动作的概率和动作的价值
(2) Q π ( s , a ) = r ( s , a ) + γ ∑ P ( s ′ ∣ s , a ) V π ( s ′ ) Q^\pi(s, a) = r(s,a) + \gamma \sum P(s' | s, a) V^\pi(s') Qπ(s,a)=r(s,a)+γ∑P(s′∣s,a)Vπ(s′)
使用策略 π \pi π时,状态s下采取a动作后的价值期望 等于 当下的奖励加上 经过 γ \gamma γ衰减之后的所有状态状态转移概率与相应价值的乘积。
这里是动作已经确定,但是状态不确定,因此乘的是状态转移矩阵和状态
也就是说状态与状态之间不再是单纯的转移,还有动作的这个价值反馈加进去。
7.5.3 动作价值函数的贝尔曼期望等式
根据定义:
Q π ( s , a ) = r ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) V π ( s ′ ) Q^\pi(s, a) = r(s,a) + \gamma \sum_{s'\in S} P(s' | s, a) V^\pi(s') Qπ(s,a)=r(s,a)+γ∑s′∈SP(s′∣s,a)Vπ(s′)
又因为:
V π ( s ) = ∑ a ∈ A π ( a ∣ s ) Q π ( s , a ) V^{\pi}(s) = \sum_{a \in A} \pi(a|s) Q^\pi(s, a) Vπ(s)=∑a∈Aπ(a∣s)Qπ(s,a)
那么:
V π ( s ′ ) = ∑ a ∈ A π ( a ∣ s ′ ) Q π ( s ′ , a ) V^{\pi}(s') = \sum_{a \in A} \pi(a|s') Q^\pi(s', a) Vπ(s′)=∑a∈Aπ(a∣s′)Qπ(s′,a)
上面的式子可以再变个型,带入后:
Q π ( s , a ) = r ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) V π ( s ′ ) = r ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ∑ a ∈ A π ( a ∣ s ′ ) Q π ( s ′ , a ) Q^\pi(s, a)= r(s,a) + \gamma \sum_{s'\in S} P(s' | s, a) V^\pi(s')\\ =r(s,a) + \gamma \sum_{s'\in S} P(s' | s, a) \sum_{a \in A} \pi(a|s') Q^\pi(s', a) Qπ(s,a)=r(s,a)+γ∑s′∈SP(s′∣s,a)Vπ(s′)=r(s,a)+γ∑s′∈SP(s′∣s,a)∑a∈Aπ(a∣s′)Qπ(s′,a)
——————————————————————
动作价值函数和状态价值函数的贝尔曼方程很常见,所以我这里推敲了下。
——————————————————————
7.6 动作价值和状态价值例子
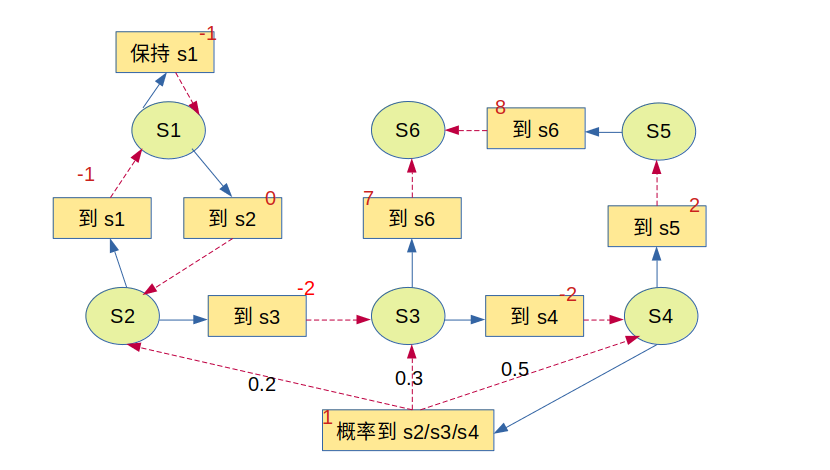
图中的
(1)虚线表示动作到状态
(2)图中的实现表示从当前状态开始当前动作
(3)红色的数字是标记状态奖励
(4)没有标记数字的线表示概率为1,如果标记了表示对应概率。
7.6.1 边缘化(marginalization),就
这里有个一般的计算MDP的方法,就是将测率的动作边缘化:
(1) 得到一个没有动作的mrp。即对于某个状态,我跟将根据动作策略进行加权,就得到r’(s)是该状态下的奖励:
s ′ = ∑ a ∈ A π ( a ∣ s ) r ( s , a ) s'=\sum_{a \in A} \pi(a|s)r(s,a) s′=∑a∈Aπ(a∣s)r(s,a)
(2)同理,将计算采取动作的概率 π \pi π与 将s转移到s’转移矩阵进行相乘再累加,就得到一个MRP的从s转移到s‘的转移概率。
这样的做法有如下好处:
简化问题结构
MDP 涉及状态和动作两层结构,分析和求解复杂。而给定策略后,动作选择就变成确定的概率分布,这时只剩下状态和状态之间的转移(+奖励)——正好就是 MRP 的结构。
MRP 更容易求解
MRP 没有动作维度,可以直接用线性代数(比如矩阵解法或贝尔曼方程迭代)来求解状态值函数 𝑉(𝑠)非常方便。
这个方法是*给定策略下的通用方法。 如果你要做最优策略求解(如值迭代、Q-learning),那就不能只转成 MRP,因为你需要在每一步决策中“寻找最优动作”,那就是另一套框架了(比如 Bellman Optimality Equation)。
实践代码如下:
import numpy as npdef join(str1, str2):return str1 + '-' + str2# markov_chain is a list that save the index of state
# for example:s1->s1->s2->s3->s4->s5->s6
# start_index: the start index for markov_chain, not the state index.
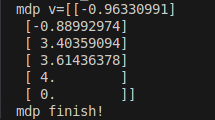
def get_return(start_index, markov_chain, rewards, gamma):G_t = 0# >>>>>>> the code is very tricky but effective! <<<<<<<for idx in reversed(range(start_index, len(markov_chain))):# the state index is start at 1 end in 6, so when we use the idx we need to minus 1G_t = gamma * G_t + rewards[markov_chain[idx] - 1]return G_tdef get_value(p_matrix, rewards, gamma):states_amount = len(rewards)rewards = np.array(rewards)rewards = rewards.reshape((-1, 1))value = np.dot(np.linalg.inv(np.eye(states_amount, states_amount) - gamma * p_matrix), rewards)return valuedef mrp_test():np.random.seed(0)p = [[0.8, 0.1, 0.1, 0.0, 0.0, 0.0],[0.0, 0.2, 0.5, 0.3, 0.0, 0.0],[0.0, 0.0, 0.5, 0.5, 0.0, 0.0],[0.1, 0.1, 0.1, 0.1, 0.3, 0.3],[0.2, 0.5, 0.1, 0.0, 0.1, 0.1],[0.0, 0.0, 0.2, 0.3, 0.4, 0.1],]p = np.array(p)# fist to checkt if the sum of each row is 1.0H, W = p.shapefor h in range(H):sum_h = np.sum(p[h,:])# for float compoare we can not suppose it will be exactly 1.0 actually is 0.999999999....if sum_h < 0.9999999 or sum_h > 1.0: print("error in line:" + str(h) + " sum:" + str(sum_h))exit()# s1, s2, s3, s4, s5, s6rewards = [-1, -2, 0, 1, 2, 4] gamma = 0.7markov_chain = [1, 1, 2, 3, 4, 5, 6, 1]# get the return for agentG_t = get_return(0, markov_chain, rewards, gamma)# get the value for agentV_t = get_value(p, rewards, gamma)print(">>> markov finish!")def mdp_test():states = ["s1", "s2", "s3", "s4", "s5", "s6"]actions = ["hold_s1", "arrival_s2","arrival_s3","arrival_s4", "arrival_s5", "arrival_s6", "stochastic_arrival"]p = {"s1-hold_s1-s1": 1.0,"s1-arrival_s2-s2": 1.0,"s2-arrival_s1-s1": 1.0,"s2-arrival_s3-s3": 1.0,"s3-arrival_s4-s4": 1.0,"s3-arrival_s6-s6": 1.0,"s4-arrival_s5-s5": 1.0,"s5-arrival_s6-s6": 1.0,"s4-stochastic_arrival_s2": 0.2,"s4-stochastic_arrival_s3": 0.3,"s4-stochastic_arrival_s4": 0.5,}rewards = {"s1-hold_s1": -1,"s1-arrival_s2": 0,"s2-arrival_s1":-1,"s2-arrival_s3":-2,"s3-arrival_s4":-2,"s3-arrival_s6": 7,"s4-arrival_s5": 2,"s5-arrival_s6": 8,"s4-stochastic_arrival_s2": 1,"s4-stochastic_arrival_s3": 1,"s4-stochastic_arrival_s4": 1 }gamma = 0.5mdp = (states, actions, p, gamma)pi_1 = {"s1-hold_s1": 0.5,"s1-arrival_s2": 0.5,"s2-arrival_s1": 0.5,"s2-arrival_s3": 0.5,"s3-arrival_s4": 0.5,"s3-arrival_s5": 0.5,"s4-arrival_s5": 0.5,"s4-stochastic_arrival": 0.5,} pi_2 = {"s1-hold_s1": 0.6,"s1-arrival_s2": 0.4,"s2-arrival_s1": 0.3,"s2-arrival_s3": 0.7,"s3-arrival_s4": 0.5,"s3-arrival_s5": 0.5,"s4-arrival_s5": 0.1,"s4-stochastic_arrival": 0.9,} # 转化后的MRP的状态转移矩阵p_mdp2mrp_pi_1 = [# s1, s2, s3, s4, s5, s6[1.0 * 0.5, 1.0 * 0.5, 0.0, 0.0, 0.0, 0.0 ],[1.0 * 0.5, 0.0, 1.0 * 0.5, 0.0, 0.0, 0.0 ],[0.0, 0.0, 0.0, 1.0 * 0.5, 0.0, 1.0 * 0.5],[0.0, 0.2 * 0.5, 0.3 * 0.5, 0.5, 1.0 * 0.5, 0.0 ],[0.0, 0.0, 0.0, 0.0, 0.0, 1.0 * 0.5],[0.0, 0.0, 0.0, 0.0, 0.0, 1.0 ],]p_mdp2mrp_pi_1 = np.array(p_mdp2mrp_pi_1)R_mdp2mrp_pi_1 = [-1 * 0.5, -1 * 0.5 + -2 * 0.5,7 * 0.5 + -2 * 0.5,2 * 0.5 + 1 * 0.5, 8 * 0.5,0]# get the mrp base on mdpv = get_value(p_mdp2mrp_pi_1, R_mdp2mrp_pi_1, gamma)print("mdp v=" + str(v))print("mdp finish!")if __name__ == "__main__":#mrp_test()mdp_test()
运行结果:
相关文章:
强化学习课程:stanford_cs234 学习笔记(3)introduction to RL
文章目录 前言7 markov 实践7.1 markov 过程再叙7.2 markov 奖励过程 MRP(markov reward process)7.3 markov 价值函数与贝尔曼方程7.4 markov 决策过程MDP(markov decision process)的 状态价值函数7.4.1 状态价值函数7.4.2 状态…...

紫檀博物馆一游与软件开发
今天去逛了中国紫檀博物馆,里边很多层展品,也有一些清代的古物,檀木,黄花梨木家具和各种摆件,馆主陈丽华女士也是发心复原、保留和弘扬中国的传统文化,和西游记唐僧扮演者迟成瑞先生一家。 每一件展品都精…...
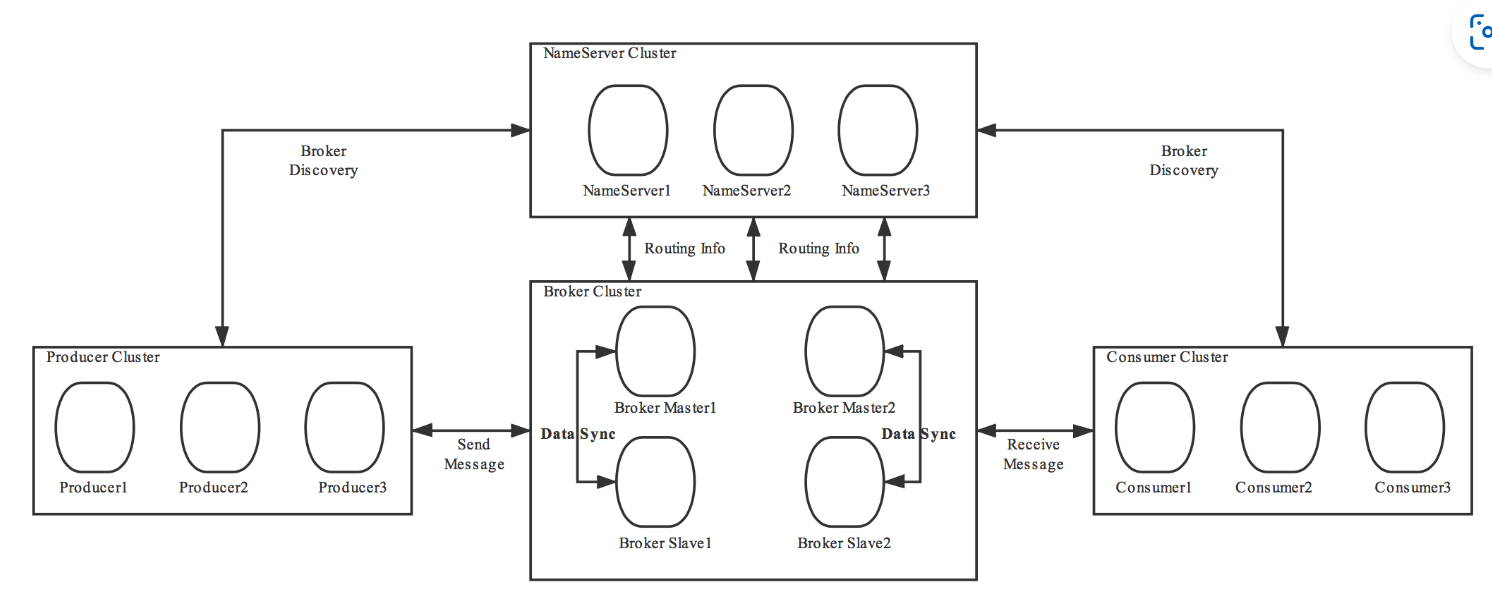
RocketMQ初认识
ProducerCustomerNameServer: Broker的注册服务发现中心BrokerServer:主要负责消息的存储、投递和查询以及服务高可用保证 RocketMQ的集群部署: 单个master的分支多个Master 模式:集群中有多个 Master 节点,彼此之间相互独立。生产者可以将消…...

第十三章:持久化存储_《凤凰架构:构建可靠的大型分布式系统》
第十三章 持久化存储 一、Kubernetes存储设计核心概念 (1)存储抽象模型 PersistentVolume (PV):集群级别的存储资源抽象(如NFS卷/云存储盘)PersistentVolumeClaim (PVC):用户对存储资源的声明请求&#…...
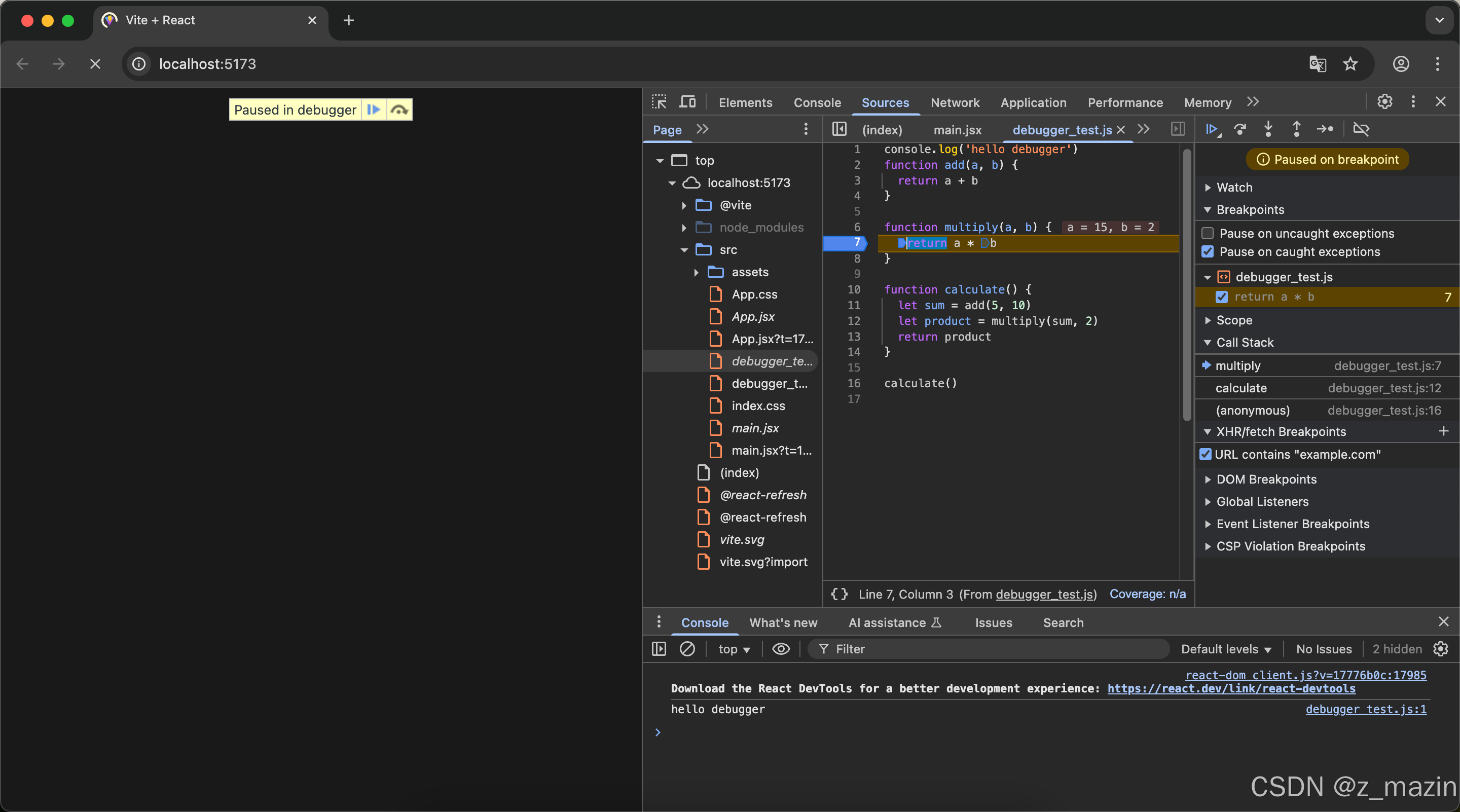
Chrome开发者工具实战:调试三剑客
在前端开发的世界里,Chrome开发者工具就是我们的瑞士军刀,它集成了各种强大的功能,帮助我们快速定位和解决代码中的问题。今天,就让我们一起来看看如何使用Chrome开发者工具中的“调试三剑客”:断点调试、调用栈跟踪和…...

教程:如何使用 JSON 合并脚本
目录 1. 介绍 2. 使用方法 3. 注意事项 4. 示例 5.完整代码 1. 介绍 该脚本用于将多个 COCO 格式的 JSON 标注文件合并为一个 JSON 文件。COCO 格式常用于目标检测和图像分割任务,包含以下三个主要部分: "images":图像信息&a…...
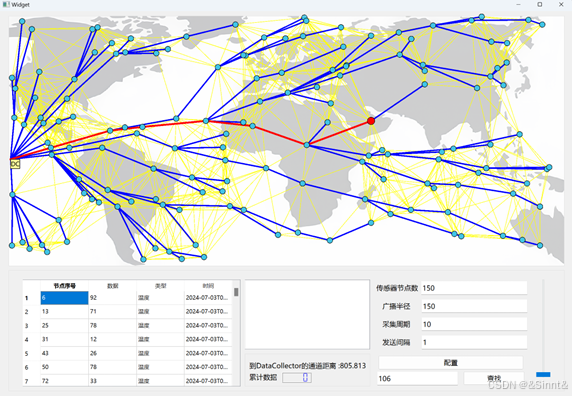
C++/Qt 模拟sensornetwork的工作
C/Qt 可视化模拟sensornetwork的工作 C/Qt 模拟sensornetwork的工作 C/Qt 可视化模拟sensornetwork的工作内容简介(一) 需求和规格说明(1)问题描述(2)设计目的(3)基本要求࿰…...

ffmpeg音频分析
对一个16k 单声道音频,生成频谱图 ./ffmpeg -i input.wav -lavfi "showspectrumpics800x400:modecombined:scalelin:gain1.5" spectrum.png...

【多线程】CAS机制
目录 一. CAS的概念 二. CAS的原理 三.标准库中的CAS 四. CAS的应用 (1)原子类的使用 (2) 自旋锁的实现 五. CAS的ABA问题 一. CAS的概念 CAS(Compare And Swap)机制是一种无锁的并发控制技术&#…...
音视频(四)android编译
前言 前面已经讲了在windows上应用了,这章主要讲述android上编译 1:环境 git 如果失败 直接跑到相应网站 手动下载 ubuntu22.* android ndk r21e download:https://developer.android.google.cn/ndk/downloads/index.html?hluk 为什么用这个࿰…...

Chapter07_图像压缩编码
文章目录 图像压缩编码图像压缩编码基础图像压缩的基本概念信息相关信息冗余信源编码及其分类 图像编码模型信源编码器模型信源解码器模型 数字图像的信息熵信源符号码字平均长度信息熵信息量 变长编码费诺码霍夫曼编码 位平面编码格雷码 图像压缩编码 数字图像的压缩是指在满…...

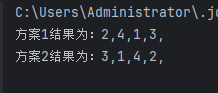
团体设计程序天梯赛L2-025 # 分而治之
文章目录 题目解读输入格式输出格式 思路Ac Code参考 题目解读 在战争中,我们希望首先攻下敌方的部分城市,使其剩余的城市变成孤立无援,然后再分头各个击破。为此参谋部提供了若干打击方案。本题就请你编写程序,判断每个方案的可…...
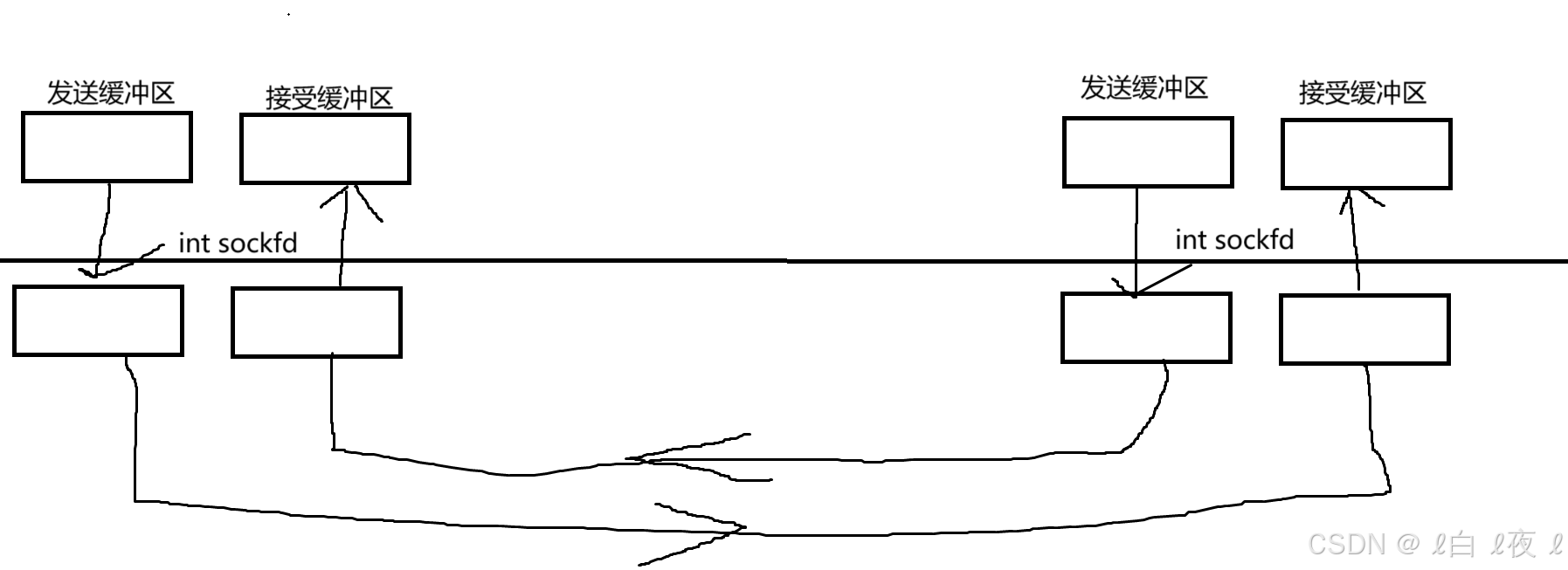
Linux网络套接字
Socket 编程 UDP 本章将函数介绍和代码编写实战一起使用。 IPv4 的 socket 网络编程,sockaddr_in 中的成员 struct in_addr.sin_addr 表示 32 位 的 IP 地址 但是我们通常用点分十进制的字符串表示 IP 地址,以下函数可以在字符串表示和in_addr 表示之间转换; 字符串转 in_addr…...

看爬山虎学本领 软爬机器人来创新 各种场景能适应
*本文只做阅读笔记分享* 一、灵感来源:向植物取经 大家好!今天来聊一款超酷的软爬机器人,它的灵感来自会攀爬的植物——爬山虎。 大家都知道,爬墙高手爬山虎能在各种复杂墙面轻松生长攀爬,可现有的攀爬机器人在复杂…...

1-Docker安装
1.准备环境 1.第一步:创建以自己的姓名全拼的用户名 [roothadoop ~]# useradd qiwenyong [roothadoop ~]# passwd qiwenyong Changing password for user qiwenyong. New password: BAD PASSWORD: The password is shorter than 7 characters Retype new passwor…...
-- 第三部分:JS宏编程语言开发基础)
WPS JS宏编程教程(从基础到进阶)-- 第三部分:JS宏编程语言开发基础
第三部分:JS宏编程语言开发基础 @[TOC](第三部分:JS宏编程语言开发基础)**第三部分:JS宏编程语言开发基础**1. 变量与数据类型**变量声明:三种方式****示例代码****数据类型判断****实战:动态处理单元格类型**2. 运算符全解析**算术运算符****易错点:字符串拼接 vs 数值相…...

BT-Basic函数之首字母T
BT-Basic函数之首字母T 文章目录 BT-Basic函数之首字母Ttabtesttest conttest monitortest on boardstest scanworkstest shortstesthead cleanuptesthead configurationtesthead istesthead power on/offtesthead statustestjet print level istestordertestplan generationth…...

经典算法 约数之和
原题目链接 问题描述 假设现在有两个自然数 A 和 B,设 S 为 A^B 的所有约数之和。 请你计算:S mod 9901 的值。 输入格式 在一行中输入两个用空格隔开的整数 A 和 B。 输出格式 输出一个整数,表示 S mod 9901 的值。 数据范围 0 ≤ A, …...

Flinksql--订单宽表
参考: https://chbxw.blog.csdn.net/article/details/115078261 (datastream 实现) 一、ODS 模拟订单表及订单明细表 CREATE TABLE orders (order_id STRING,user_id STRING,order_time TIMESTAMP(3),-- 定义事件时间及 Watermark(允许5秒乱序&#x…...
 打开文件操作)
C# 窗体应用(.FET Framework ) 打开文件操作
一、 打开文件或文件夹加载数据 1. 定义一个列表用来接收路径 public List<string> paths new List<string>();2. 打开文件选择一个文件并将文件放入列表中 OpenFileDialog open new OpenFileDialog(); // 过滤 open.Filter "(*.jpg;*.jpge;*.bmp;*.png…...

极客天成NVFile:无缓存直击存储性能天花板,重新定义AI时代并行存储新范式
在AI算力需求呈指数级爆发的今天,存储系统正面临一场前所未有的范式革命。传统存储架构中复杂的缓存机制、冗余的数据路径、僵化的扩展能力,已成为制约千卡GPU集群算力释放的重要因素。极客天成NVFile并行文件存储系统以全栈并行化架构设计和无缓存直通数…...
Java实现N皇后问题的双路径探索:递归回溯与迭代回溯算法详解
N皇后问题要求在NN的棋盘上放置N个皇后,使得她们无法互相攻击。本文提供递归和循环迭代两种解法,并通过图示解释核心逻辑。 一、算法核心思想 使用回溯法逐行放置皇后,通过冲突检测保证每行、每列、对角线上只有一个皇后。发现无效路径时回退…...

【代码艺廊】pyside6桌面应用范例:homemade-toolset
在研发测试日常工作中,通常会遇到很多琐碎的事情,占用我们工作的时间和精力,从而导致我们不能把大部分的注意力放在主要的工作上面。为了解决这个问题,除了加人之外,我们通常会开发一些日常用的效率工具,比…...

LeetCode 3047 求交集区域内的最大正方形面积
探寻矩形交集中的最大正方形面积 在算法与数据结构的探索之路上,二维平面几何问题一直占据着独特的地位,它们不仅考验我们的空间思维能力,还要求我们能够巧妙地运用算法逻辑。今天,我们将深入剖析一道极具代表性的二维平面几何算…...

谷歌开源单个 GPU 可运行的Gemma 3 模型,27B 超越 671B 参数的 DeepSeek
自从 DeepSeek 把训练成本打下来之后,各个模型厂家现在不再堆参数进行模型的能力对比。而是转向了训练成本优化方面,且还要保证模型能力不减反增的效果。包括使用较少的模型参数,降低 GPU 使用数量,降低模型内存占用等等技术手段。…...

C++_类和对象(下)
【本节目标】 再谈构造函数Static成员友元内部类匿名对象拷贝对象时的一些编译器优化再次理解封装 1. 再谈构造函数 1.1 构造函数体赋值 在创建对象时,编译器通过调用构造函数,给对象中各个成员变量一个合适的初始值。 class Date { public:Date(in…...

《Java实战:素数检测算法优化全解析——从暴力枚举到筛法进阶》
文章目录 摘要一、需求分析二、基础实现代码与问题原始代码(暴力枚举法)问题分析 三、优化版代码与解析优化1:平方根范围剪枝优化2:偶数快速跳过完整优化代码 四、性能对比五、高阶优化:埃拉托斯特尼筛法算法思想代码实…...

基于Python+Flask的服装零售商城APP方案,用到了DeepSeek AI、个性化推荐和AR虚拟试衣功能
首先创建项目结构: fashion_store/ ├── backend/ │ ├── app/ │ │ ├── __init__.py │ │ ├── models/ │ │ ├── routes/ │ │ ├── services/ │ │ └── utils/ │ ├── config.py │ ├── requirements.t…...

二,<FastApi>FastApi的两个核心组件
FastAPI的两个核心组件Pydantic和Starlette。 Starlette 负责Web部分(Asyncio),Starlette Starlette是一个轻量级的ASGI框架/工具包,非常适合在Python构建异步Web服务。 它已经准备好生产,并为您提供以下内容: 轻巧的低复杂性HTTP Web框架。W…...
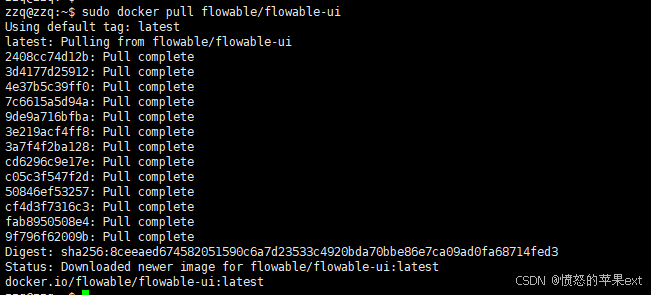
Docker设置代理
目录 前言创建代理文件重载守护进程并重启Docker检查代理验证 前言 拉取flowable/flowable-ui失败,用DaoCloud源也没拉下来,不知道是不是没同步。索性想用代理拉镜像。在此记录一下。 创建代理文件 创建docker代理配置 sudo mkdir -p /etc/systemd/s…...