Kafka 中的事务
Kafka 中的 事务(Transactions) 是为了解决 消息处理的原子性和幂等性问题,确保一组消息要么全部成功写入、要么全部失败,不出现中间状态或重复写入。事务机制尤其适合于 “精确一次(Exactly-Once)” 的处理语义(EOS, Exactly Once Semantics)。
🧠 Kafka 中为什么需要事务?
在实际业务中,可能有这样的场景:
一个消费者从 Topic A 读取一条消息,然后处理它,并将处理结果写入 Topic B —— 我们希望这个“读取 + 写入”是一个整体,要么都成功,要么都失败,否则可能造成重复消费或数据不一致。
普通情况下 Kafka 只能做到:
- 最多一次(At most once):消息可能丢;
- 至少一次(At least once):消息可能重复;
- 不能保证精确一次,除非业务层做幂等控制。
因此 Kafka 引入了事务机制来支持真正的 Exactly Once Semantics(EOS)。
✅ Kafka 事务的核心概念
| 概念 | 说明 |
|---|---|
| Transactional Producer | 开启事务功能的生产者,可以保证一组写入的原子性。 |
| Transactional ID | 每个事务性生产者的唯一标识,用于区分和恢复未完成的事务。 |
| 事务协调器(Transaction Coordinator) | Kafka 集群中的一个 Broker 组件,负责管理事务的状态、提交与回滚。 |
| Producer ID(PID) | Kafka 为每个事务性生产者分配的唯一 ID,用于实现幂等性和事务追踪。 |
✅ Kafka 事务的使用流程(简化)
- 初始化事务生产者(开启事务功能):
Properties props = new Properties(); props.put("transactional.id", "txn-001"); KafkaProducer<String, String> producer = new KafkaProducer<>(props); producer.initTransactions(); - 开始事务:
producer.beginTransaction(); - 执行写入操作(可以写入多个 Topic、多个 Partition):
producer.send(new ProducerRecord<>("topicA", "key1", "msg1")); producer.send(new ProducerRecord<>("topicB", "key2", "msg2")); - 提交事务(成功)或 中止事务(失败):
producer.commitTransaction(); // 或者 producer.abortTransaction();
✅ Kafka 事务的特点与保障
1. 原子性
- 一次事务中的多条消息,要么全部写入成功,要么全部失败并回滚。
- 对消费者来说,要么能消费到完整事务内的消息,要么一条都看不到。
2. 幂等性(Idempotence)
- 自动启用,配合事务使用时,可以避免消息重复写入,即使重试也不会写入重复数据。
3. 隔离性
- Kafka 使用 读已提交(read_committed) 和 读未提交(read_uncommitted) 的消费模式控制事务可见性。
- 默认:消费者只能读取已提交的事务消息,未提交或中止的事务消息不会暴露给消费者。
✅ Kafka 事务与消费者的协作(消费 + 生产)
配合 enable.auto.commit=false 和 read_committed,可以实现精确一次语义:
producer.beginTransaction();
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理数据,并写入结果producer.send(new ProducerRecord<>("output-topic", process(record)));
}// 手动提交 offset,作为事务的一部分
Map<TopicPartition, OffsetAndMetadata> offsets = consumerOffsets(records);
producer.sendOffsetsToTransaction(offsets, consumerGroupId);producer.commitTransaction();
通过把 消费 Offset 的提交 和 生产消息的提交 绑定到同一个事务中,Kafka 实现了端到端的 Exactly-Once 保证。
✅ Kafka 事务机制本质
Kafka 事务的回滚机制,并不是自动触发的,开发者必须在代码逻辑中显式地判断是否出错,然后手动调用:
producer.abortTransaction();
如果开发者只调用了
producer.commitTransaction(),而没有判断出错,也没有手动调用abortTransaction(),那么出问题时 Kafka 不会自动回滚!需要开发者自己判断、自己调用!
✅ 正确的事务控制流程应该是这样的:
try {producer.beginTransaction();// 消费 + 处理 + 发送producer.send(...);producer.send(...);// 提交 offsetproducer.sendOffsetsToTransaction(offsets, consumerGroupId);// 提交事务producer.commitTransaction(); // ✅ 成功,整个事务写入生效!} catch (Exception e) {// 出现任何异常,都应该回滚producer.abortTransaction(); // ❗回滚事务,所有写入 + offset 统统丢弃e.printStackTrace();
}
🚨 如果直接调用 commitTransaction() 会怎样?
如果前面的 send() 或 sendOffsetsToTransaction() 抛了异常,但没 try-catch 捕获,程序继续调用 commitTransaction(),结果是:
- Kafka 会检测到前面出了问题,会抛出
ProducerFencedException、IllegalStateException等; - 此时事务已经处于非法状态;
commitTransaction()会失败,Kafka 不会自动回滚!- 如果你不手动调用
abortTransaction(),这个事务就会卡在中间状态,不生效,也没回滚。
✅ 做法:必须写 try-catch 包住整个事务过程,出错就 abortTransaction()!
这就是标准的 事务控制模式(跟数据库事务的 try-catch 是一样的思路):
⚠️ 常见会触发事务失败的场景:
| 场景 | 会发生什么 |
|---|---|
| 网络波动、Broker 写入超时 | send() 抛异常 |
| offset 提交失败 | sendOffsetsToTransaction() 抛异常 |
重复使用 transactional.id 被踢出 | 抛 ProducerFencedException |
| 使用了错误的调用顺序 | 抛 IllegalStateException |
commitTransaction() 时事务非法 | 提交失败,不会自动回滚 |
✅ 补充一句
Kafka 的事务机制本质上是「声明式事务」,但实现方式是「编程式事务」,不像数据库事务那样自动提交或自动回滚 —— 所以你写代码的时候,一定要有清晰的事务控制逻辑。
✅ 总结一下你该怎么做
✅ 成功就
commitTransaction()
❌ 出错就abortTransaction()
🧠 判断错没错,靠自己的业务代码来 try-catch 控制
什么是事务非法?
commitTransaction()时事务非法,这句话是什么意思?“事务非法”到底是个啥意思?
在 Kafka 中,一个事务是有“状态”的,它不是你想提交就能提交的。只有当事务状态是“合法/活跃”的时候,才能 commitTransaction(),否则就会抛异常。
所以,“事务非法” = 事务已经处于异常、失效、终止状态,不能提交。
📊 Kafka 中事务的几种状态(简化理解)
| 事务状态 | 描述 |
|---|---|
Initialized | initTransactions() 调用后,初始化完成 |
Started | 调用 beginTransaction() 后,事务已开始 |
InFlight | 事务进行中,已发送消息,或 offset |
✅ ReadyToCommit | 一切正常,可以提交 |
❌ Invalid | 出现异常、被踢出、操作错误 → 事务非法 |
Committed | 已提交成功 |
Aborted | 已主动回滚 |
🚨 什么情况下事务会变成“非法状态”?
以下几种情况会让事务“非法化”,从而你调用 commitTransaction() 时直接失败:
1. ❌ 你调用顺序错了
比如你根本没有调用 beginTransaction(),就直接调用 send() 或 commitTransaction():
producer.initTransactions();
// producer.beginTransaction(); // ❌ 忘了这行!producer.send(...); // ❌ 错误用法
producer.commitTransaction(); // ❌ 会抛 IllegalStateException
这时候 Kafka 会认为你“乱搞”,把事务标为非法状态。
2. ❌ 事务内某个操作失败(比如 send 抛异常)
producer.beginTransaction();try {producer.send(...); // ⚠️ 如果这里失败了,比如网络问题producer.commitTransaction(); // ❌ 事务状态非法,提交失败
} catch (Exception e) {producer.abortTransaction(); // ✅ 你得主动回滚!
}
3. ❌ 你被 Kafka 判定为“被踢出事务”
Kafka 是通过 transactional.id 标识一个事务性的 producer 的,一个 transactional.id 只能在一个 producer 实例中使用。
如果你重复使用了这个 ID(比如程序重启未清理),Kafka 会抛:
org.apache.kafka.common.errors.ProducerFencedException
这时,Kafka 会把你当前的事务标记为非法,你必须关闭 producer 实例,否则不能提交也不能继续。
4. ❌ offset 提交失败了
producer.sendOffsetsToTransaction(...); // 如果这里异常,事务就“坏了”
producer.commitTransaction(); // ❌ 再提交,事务非法
🧠 为什么 Kafka 要这么严格?
因为 Kafka 的事务要保证:
要么全写入、全提交,要么一个字节都不留下。
所以一旦你有步骤失败,它就会保护性地禁止你再提交,以免产生脏数据(比如你写了一半就崩了,还提交 offset,那就“假成功”了)。
✅ 那应该怎么做?
使用事务时,标准模板写法如下:
producer.initTransactions();while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));try {producer.beginTransaction();for (ConsumerRecord<String, String> record : records) {// 处理 + 转发producer.send(new ProducerRecord<>("output-topic", record.key(), process(record.value())));}// 把消费 offset 提交到事务中Map<TopicPartition, OffsetAndMetadata> offsets = ...;producer.sendOffsetsToTransaction(offsets, consumerGroupId);producer.commitTransaction(); // ✅ 事务提交} catch (Exception e) {producer.abortTransaction(); // ❗出现问题,事务回滚}
}
✅ 总结一句话
Kafka 中事务“非法” = 你违反了事务的规则(出错、顺序错、异常未处理等),Kafka 把这个事务锁住,不让你再提交,以避免脏数据。
你只要记得:
- 成功就
commitTransaction(); - 出错必须
abortTransaction(); - 所有事务逻辑必须放在 try-catch 中;
就不会踩坑 ✅
🚫 注意事项和限制
- 事务有开销:
- 每次事务需要额外的协调和状态管理,吞吐会略低于普通模式。
- 大量小事务不如少量大事务高效。
- 只能配合 Kafka 使用:
- Kafka 的事务不能覆盖外部数据库、Redis 等操作,无法实现跨系统的分布式事务。
- 事务状态会持久化到内存和日志中:
- 若事务未正常提交或中止,Kafka 会在恢复后重新协调这些事务状态。
- 事务 ID 要保持稳定:
- 如果你频繁变更 transactional.id,会导致事务协调器无法追踪事务状态。
🧠 总结一句话
Kafka 中的事务机制提供了跨多个 topic/partition 的消息写入 原子性,配合幂等性和 offset 提交绑定,可实现 精确一次语义(Exactly Once) —— 特别适用于金融、电商、订单系统、数据管道等对一致性要求极高的场景。
相关文章:

Kafka 中的事务
Kafka 中的 事务(Transactions) 是为了解决 消息处理的原子性和幂等性问题,确保一组消息要么全部成功写入、要么全部失败,不出现中间状态或重复写入。事务机制尤其适合于 “精确一次(Exactly-Once)” 的处理…...

C++ 内存访问模式优化:从架构到实践
内存架构概览:CPU 与内存的 “速度博弈” 层级结构:从寄存器到主存 CPU 堪称计算的 “大脑”,然而它与内存之间的速度差距,宛如高速公路与乡间小路。现代计算机借助多级内存体系来缓和这一矛盾,其核心思路是…...

Golang系列 - 内存对齐
Golang系列-内存对齐 常见类型header的size大小内存对齐空结构体类型参考 摘要: 本文将围绕内存对齐展开, 包括字符串、数组、切片等类型header的size大小、内存对齐、空结构体类型的对齐等等内容. 关键词: Golang, 内存对齐, 字符串, 数组, 切片 常见类型header的size大小 首…...

SOMEIP通信矩阵解读
目录 1 摘要2 SOME/IP通信矩阵详细属性定义与示例2.1 服务基础属性2.2 数据类型定义2.3 服务实例与网络配置参数2.4 SOME/IP-SD Multicast 配置(SOME/IP服务发现组播配置)2.5 SOME/IP-SD Unicast 配置2.6 SOME/IP-SD ECU 配置参数详解 3 总结 1 摘要 本…...

Excel + VBA 实现“准实时“数据的方法
Excel 本身是静态数据处理工具,但结合 VBA(Visual Basic for Applications) 可以实现 准实时数据更新,不过严格意义上的 实时数据(如毫秒级刷新)仍然受限。以下是详细分析: 1. Excel + VBA 实现“准实时”数据的方法 (1) 定时刷新(Timer 或 Application.OnTime) Appl…...

网络原理 - HTTP/HTTPS
1. HTTP 1.1 HTTP是什么? HTTP (全称为 “超文本传输协议”) 是⼀种应用非常广泛的应用层协议. HTTP发展史: HTTP 诞生于1991年. 目前已经发展为最主流使用的⼀种应用层协议 最新的 HTTP 3 版本也正在完善中, 目前 Google / Facebook 等公司的产品已经…...

C++设计模式-解释器模式:从基本介绍,内部原理、应用场景、使用方法,常见问题和解决方案进行深度解析
一、解释器模式的基本介绍 1.1 模式定义与核心思想 解释器模式(Interpreter Pattern)是一种行为型设计模式,其核心思想是为特定领域语言(DSL)定义语法规则,并构建一个解释器来解析和执行该语言的句子。它…...
OCC Shape 操作
#pragma once #include <iostream> #include <string> #include <filesystem> #include <TopoDS_Shape.hxx> #include <string>class GeometryIO { public:// 加载几何模型:支持 .brep, .step/.stp, .iges/.igsstatic TopoDS_Shape L…...

深度学习入门(四):误差反向传播法
文章目录 前言链式法则什么是链式法则链式法则和计算图 反向传播加法节点的反向传播乘法节点的反向传播苹果的例子 简单层的实现乘法层的实现加法层的实现 激活函数层的实现ReLu层Sigmoid层 Affine层/SoftMax层的实现Affine层Softmax层 误差反向传播的实现参考资料 前言 上一篇…...
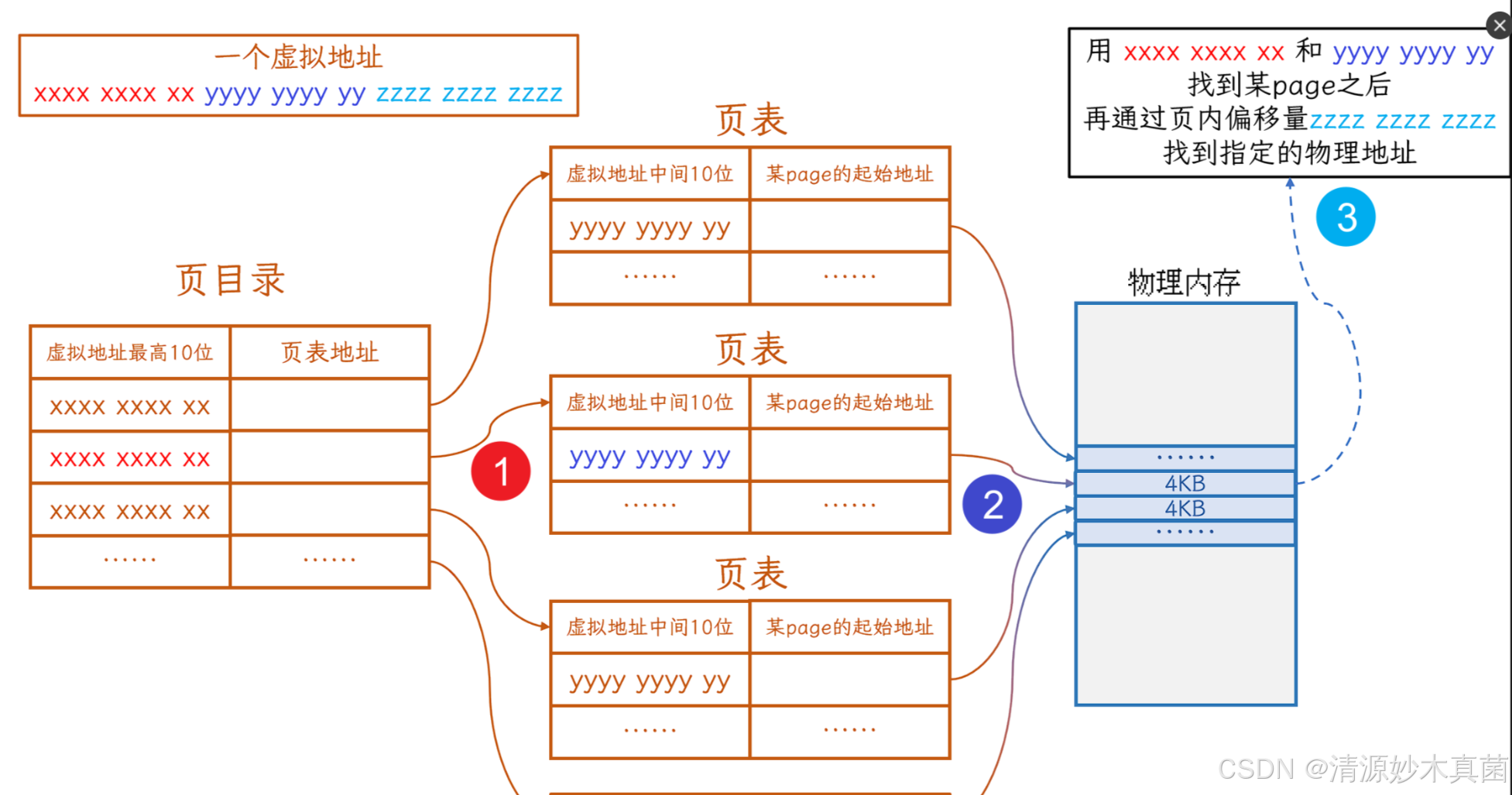
Linux:页表详解(虚拟地址到物理地址转换过程)
文章目录 前言一、分页式存储管理1.1 虚拟地址和页表的由来1.2 物理内存管理与页表的数据结构 二、 多级页表2.1 页表项2.2 多级页表的组成 总结 前言 在我们之前的学习中,我们对于页表的认识仅限于虚拟地址到物理地址转换的桥梁,然而对于具体的转换实现…...

AF3 OpenFoldDataLoader类解读
AlphaFold3 data_modules 模块的 OpenFoldDataLoader 类继承自 PyTorch 的 torch.utils.data.DataLoader。该类主要对原始 DataLoader 做了批数据增强与控制循环迭代次数(recycling)相关的处理。 源代码: class OpenFoldDataLoader(torch.utils.data.DataLoader):def __in…...

初见TypeScript
类型语言,在代码规模逐渐增大时,类型相关的错误难以排查。TypeScript 由微软开发,它本质上是 JavaScript 的超集,为 JavaScript 添加了静态类型系统,让开发者在编码阶段就能发现潜在类型错误,提升代码质量&…...

常见的 JavaScript 框架和库
在现代前端开发中,JavaScript框架和库成为了构建高效、可维护应用程序的关键工具。本文将介绍四个常见的JavaScript框架和库:React、Vue.js、Angular 和 Node.js,并探讨它们的特点、使用场景及适用场合。 1. React — 构建用户界面的JavaScri…...

机器学习代码基础——ML2 使用梯度下降的线性回归
ML2 使用梯度下降的线性回归 牛客网 描述 编写一个使用梯度下降执行线性回归的 Python 函数。该函数应将 NumPy 数组 X(具有一列截距的特征)和 y(目标)作为输入,以及学习率 alpha 和迭代次数,并返回一个…...
PostgreSQL 一文从安装到入门掌握基本应用开发能力!
本篇文章主要讲解 PostgreSQL 的安装及入门的基础开发能力,包括增删改查,建库建表等操作的说明。navcat 的日常管理方法等相关知识。 日期:2025年4月6日 作者:任聪聪 一、 PostgreSQL的介绍 特点:开源、免费、高性能、关系数据库、可靠性、稳定性。 官网地址:https://w…...
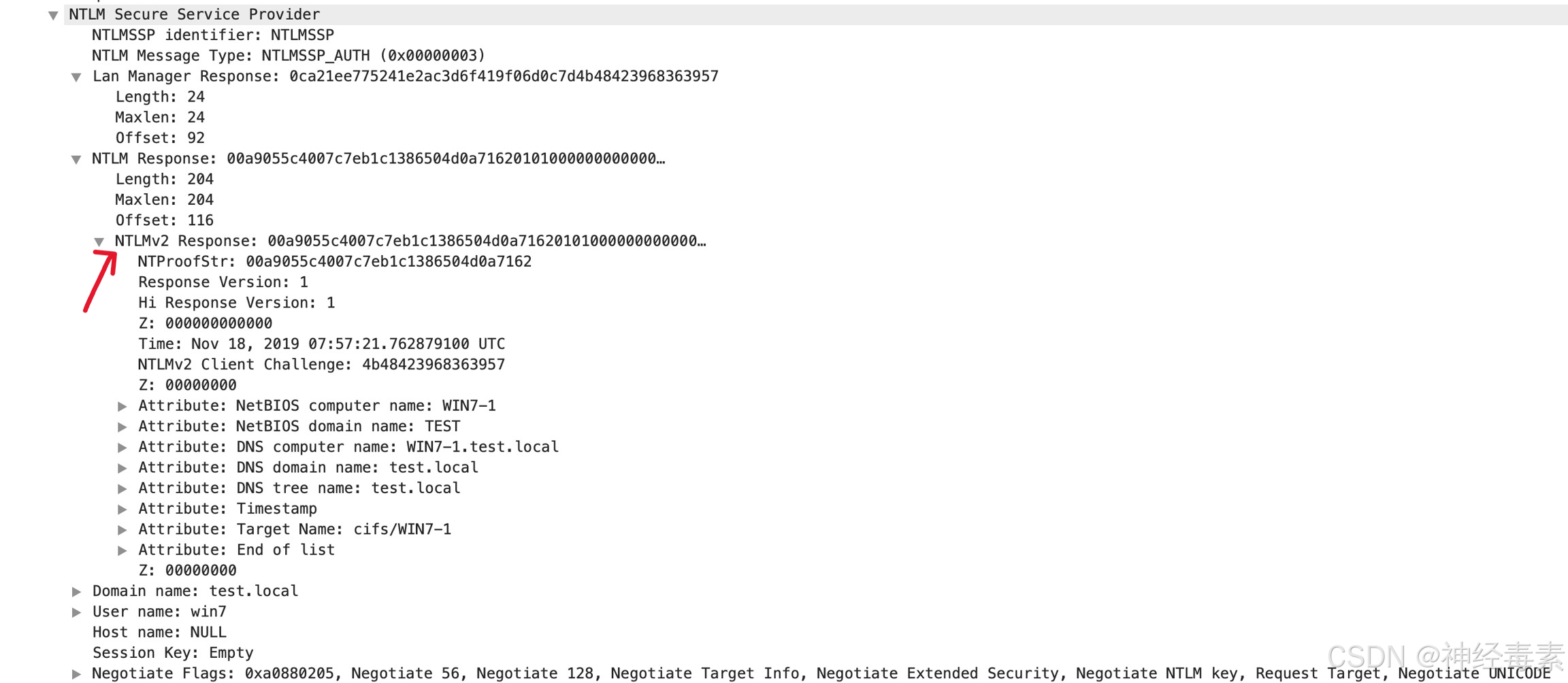
WEB安全--内网渗透--LMNTLM基础
一、前言 LM Hash和NTLM Hash是Windows系统中的两种加密算法,不过LM Hash加密算法存在缺陷,在Windows Vista 和 Windows Server 2008开始,默认情况下只存储NTLM Hash,LM Hash将不再存在。所以我们会着重分析NTLM Hash。 在我们内…...

查询条件与查询数据的ajax拼装
下面我将介绍如何使用 AJAX 动态拼装查询条件和获取查询数据,包括前端和后端的完整实现方案。 一、前端实现方案 1. 基础 HTML 结构 html 复制 <div class"query-container"><!-- 查询条件表单 --><form id"queryForm">…...
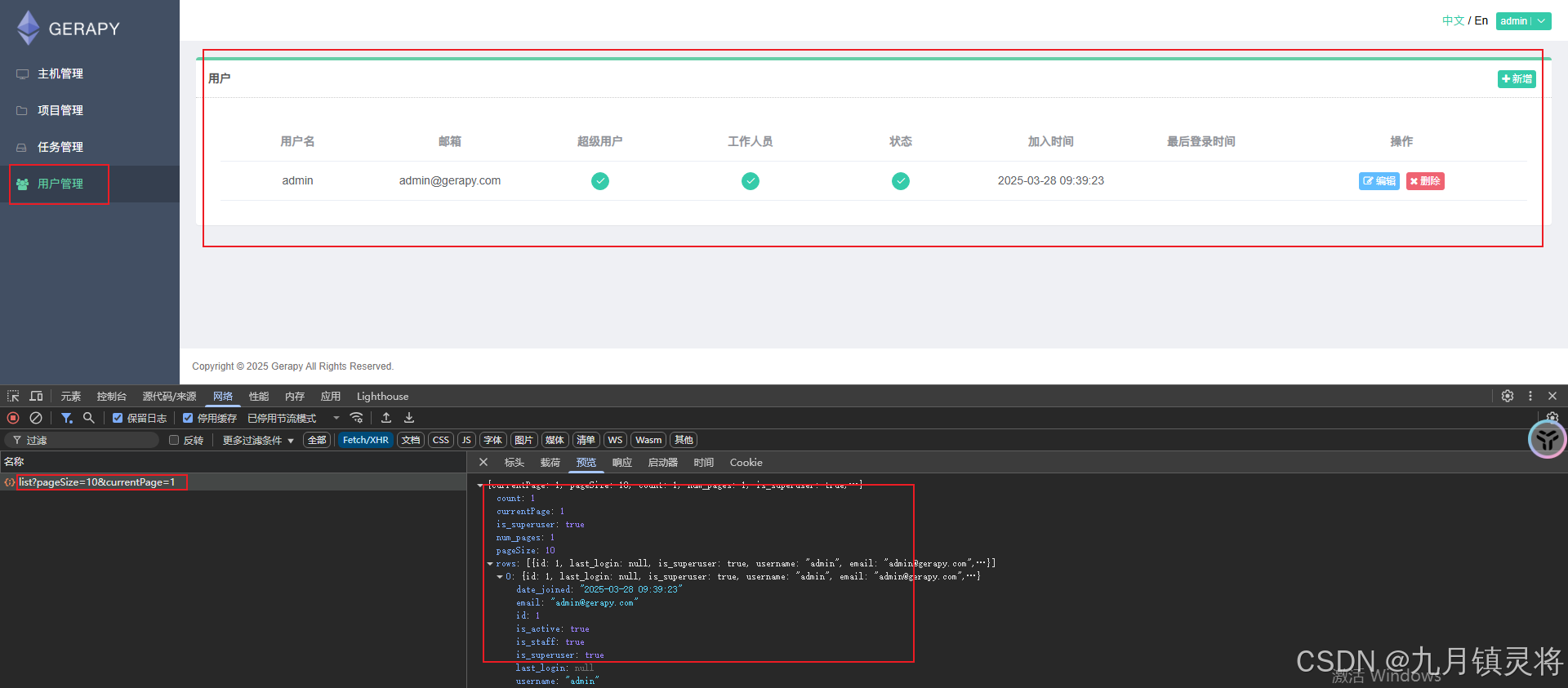
8.用户管理专栏主页面开发
用户管理专栏主页面开发 写在前面用户权限控制用户列表接口设计主页面开发前端account/Index.vuelangs/zh.jsstore.js 后端Paginator概述基本用法代码示例属性与方法 urls.pyviews.py 运行效果 总结 欢迎加入Gerapy二次开发教程专栏! 本专栏专为新手开发者精心策划了…...

室内指路机器人是否支持与第三方软件对接?
嘿,你知道吗?叁仟室内指路机器人可有个超厉害的技能,那就是能和第三方软件 “手牵手” 哦,接下来就带你一探究竟! 从技术魔法角度看哈:好多室内指路机器人都像拥有超能力的小魔法师,采用开放式…...

Apache BookKeeper Ledger 的底层存储机制解析
Apache BookKeeper 的 ledger(账本)是其核心数据存储单元,底层存储机制结合了日志追加(append-only)、分布式存储和容错设计。Ledger 的数据存储在 Bookie 节点的磁盘上,具体实现涉及 Journal(日…...

从代码上深入学习GraphRag
网上关于该算法的解析都停留在大概流程上,但是具体解析细节未知,由于代码是PipeLine形式因此阅读起来比较麻烦,本文希望通过阅读项目代码来解析其算法的具体实现细节,特别是如何利用大模型来完成图谱生成和检索增强的实现细节。 …...

通俗地讲述DDD的设计
通俗地讲述DDD的设计 前言为什么要使用DDDDDD架构分层重构实践关键问题解决方案通过领域事件机制解耦服务依赖:防止逻辑下沉 领域划分电商场景下的领域划分 结语完结撒花,如有需要收藏的看官,顺便也用发财的小手点点赞哈,…...
【Redis】通用命令
使用者通过redis-cli客户端和redis服务器交互,涉及到很多的redis命令,redis的命令非常多,我们需要多练习常用的命令,以及学会使用redis的文档。 一、get和set命令(最核心的命令) Redis中最核心的两个命令&…...

网络安全技术文档
网络安全技术文档 1. 概述 网络安全是指通过技术手段和管理措施,保护网络系统的硬件、软件及其数据不受偶然或恶意破坏、更改、泄露,确保系统连续可靠运行,网络服务不中断。 2. 常见网络威胁 2.1 攻击类型 DDoS攻击:分布式拒…...
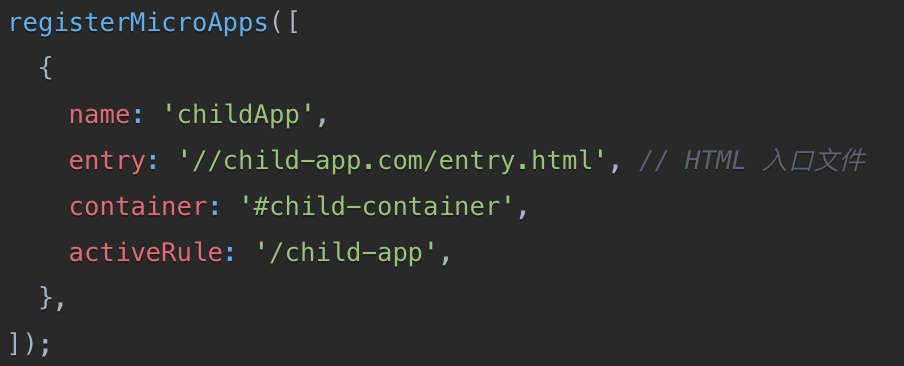
微前端随笔
✨ single-spa: js-entry 通过es-module 或 umd 动态插入 js 脚本 ,在主应用中发送请求,来获取子应用的包, 该子应用的包 singleSpa.registerApplication({name: app1,app: () > import(http://localhost:8080/app1.js),active…...

【36期获取股票数据API接口】如何用Python、Java等五种主流语言实例演示获取股票行情api接口之沪深A股当天逐笔大单交易数据及接口API说明文档
在量化分析领域,实时且准确的数据接口是成功的基石。经过多次实际测试,我将已确认可用的数据接口分享给正在从事量化分析的朋友们,希望能够对你们的研究和工作有所帮助,接下来我会用Python、JavaScript(Node.js&…...
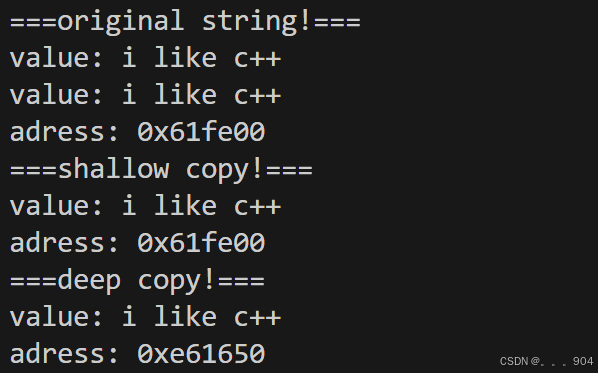
C++中的浅拷贝和深拷贝
浅拷贝只是将变量的值赋予给另外一个变量,在遇到指针类型时,浅拷贝只会把当前指针的值,也就是该指针指向的地址赋予给另外一个指针,二者指向相同的地址; 深拷贝在遇到指针类型时,会先将当前指针指向地址包…...

二叉树与红黑树核心知识点及面试重点
二叉树与红黑树核心知识点及面试重点 一、二叉树 (Binary Tree) 1. 基础概念 定义:每个节点最多有两个子节点(左子节点和右子节点) 术语: 根节点:最顶层的节点 叶子节点:没有子节点的节点 深度…...
)
GitHub 趋势日报 (2025年04月01日)
GitHub 趋势日报 (2025年04月01日) 本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星语言1punkpeye/awesome-mcp-serversA collection of MCP servers.⭐ 3280未指定2th-ch/youtube-musicYouTu…...

Java的SeleniumChromeDriver的常用方法
启动和关闭浏览器: driver.get(url):打开指定的URL。driver.quit():关闭浏览器并结束ChromeDriver会话。 元素定位: driver.findElement(By.id("elementId")):通过元素的ID定位。driver.findElement(By.cl…...