大数据(4.3)Hive基础查询完全指南:从SELECT到复杂查询的10大核心技巧
目录
- 背景
- 一、Hive基础查询核心语法
- 1. 基础查询(SELECT & FROM)
- 2. 条件过滤(WHERE)
- 3. 聚合与分组(GROUP BY & HAVING)
- 4. 排序与限制(ORDER BY & LIMIT)
- 二、复杂查询实战技巧
- 1. 多表关联(JOIN)
- 2. 子查询(Subquery)
- 3. 集合操作(UNION & UNION ALL)
- 4. 窗口函数(ROW_NUMBER)
- 三、10大实战案例
- 案例1:查询最新分区数据
- 案例2:统计每日活跃用户数
- 案例3:查询销售额最高的商品类别
- 案例4:分页查询(模拟OFFSET)
- 案例5:处理NULL值(COALESCE)
- 案例6:时间范围查询
- 案例7:正则表达式过滤(RLIKE)
- 案例8:动态分区插入查询结果
- 案例9:分桶表JOIN优化
- 案例10:复杂嵌套查询
- 四、避坑指南
- 1. 常见错误
- 2. 性能优化
- 3. 数据格式陷阱
- 五、总结
- 实践
- 大数据相关文章(推荐)
背景
在大数据处理中,Hive作为基于Hadoop的数据仓库工具,通过类SQL语法(HiveQL)实现了对海量数据的便捷分析。掌握Hive基础查询语句是数据工程师的核心技能,涉及以下场景:
- 数据筛选:通过SELECT、WHERE快速提取目标数据。
- 聚合分析:利用GROUP BY、HAVING实现数据统计。
- 多表操作:通过JOIN关联不同数据源,UNION合并数据集。
- 结果优化:结合分区、分桶设计提升查询性能。
本文将通过语法解析、10个实战案例及避坑指南,系统讲解Hive基础查询的核心操作。
一、Hive基础查询核心语法
1. 基础查询(SELECT & FROM)
-- 查询所有字段
SELECT * FROM employee; -- 查询指定字段并重命名
SELECT emp_id AS id, emp_name, salary * 0.9 AS tax_salary
FROM employee;
2. 条件过滤(WHERE)
-- 数值条件
SELECT * FROM sales WHERE amount > 1000; -- 字符串条件(LIKE)
SELECT * FROM user WHERE name LIKE 'John%'; -- 多条件组合(AND/OR)
SELECT * FROM logs
WHERE status = 'ERROR' AND (url LIKE '/api/%' OR url LIKE '/admin/%');
3. 聚合与分组(GROUP BY & HAVING)
-- 统计每个部门的平均薪资
SELECT dept_id, AVG(salary) AS avg_salary
FROM employee
GROUP BY dept_id
HAVING AVG(salary) > 5000;
4. 排序与限制(ORDER BY & LIMIT)
-- 按薪资降序排序,取前10条
SELECT emp_name, salary
FROM employee
ORDER BY salary DESC
LIMIT 10;
二、复杂查询实战技巧
1. 多表关联(JOIN)
-- 内连接(获取员工及其部门信息)
SELECT e.emp_name, d.dept_name
FROM employee e
JOIN department d ON e.dept_id = d.dept_id; -- 左外连接(保留未匹配部门的员工)
SELECT e.emp_name, d.dept_name
FROM employee e
LEFT JOIN department d ON e.dept_id = d.dept_id;
2. 子查询(Subquery)
-- 查询薪资高于部门平均薪资的员工
SELECT emp_name, salary
FROM employee
WHERE salary > ( SELECT AVG(salary) FROM employee GROUP BY dept_id HAVING dept_id = employee.dept_id
);
3. 集合操作(UNION & UNION ALL)
-- 合并两个表的数据(去重)
SELECT product_id FROM orders_2022
UNION
SELECT product_id FROM orders_2023; -- 合并数据(保留重复)
SELECT product_id FROM orders_2022
UNION ALL
SELECT product_id FROM orders_2023;
4. 窗口函数(ROW_NUMBER)
-- 按部门分组,为每个员工生成薪资排名
SELECT emp_name, dept_id, salary, ROW_NUMBER() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS rank
FROM employee;
三、10大实战案例
案例1:查询最新分区数据
SELECT * FROM logs
WHERE dt = '2023-10-01'
LIMIT 100;
案例2:统计每日活跃用户数
SELECT dt, COUNT(DISTINCT user_id) AS active_users
FROM user_activity
GROUP BY dt;
案例3:查询销售额最高的商品类别
SELECT category, SUM(amount) AS total_sales
FROM sales
GROUP BY category
ORDER BY total_sales DESC
LIMIT 1;
案例4:分页查询(模拟OFFSET)
SELECT * FROM employee
ORDER BY emp_id
LIMIT 10 OFFSET 20; -- 第3页(每页10条)
案例5:处理NULL值(COALESCE)
SELECT emp_name, COALESCE(salary, 0) AS salary
FROM employee;
案例6:时间范围查询
SELECT * FROM logs
WHERE log_time BETWEEN '2023-10-01 00:00:00' AND '2023-10-01 23:59:59';
案例7:正则表达式过滤(RLIKE)
SELECT * FROM user
WHERE email RLIKE '^[a-zA-Z0-9._%+-]+@gmail\\.com$';
案例8:动态分区插入查询结果
INSERT INTO TABLE logs_partitioned
PARTITION (dt)
SELECT ip, url, dt FROM raw_logs;
案例9:分桶表JOIN优化
SELECT a.user_id, b.order_amount
FROM user_bucketed a
JOIN orders_bucketed b
ON a.user_id = b.user_id;
案例10:复杂嵌套查询
SELECT dept_id, emp_name
FROM employee
WHERE dept_id IN ( SELECT dept_id FROM department WHERE location = 'Shanghai'
);
四、避坑指南
1. 常见错误
忽略NULL值:聚合函数(如COUNT)默认排除NULL,需用COUNT(*)统计所有行。
分区过滤失效:未在WHERE中指定分区字段导致全表扫描。
JOIN数据倾斜:大表JOIN小表未使用MapJoin优化,导致性能问题。
2. 性能优化
使用分区字段过滤:减少数据扫描量。
**避免SELECT ***:仅查询必要字段,降低IO开销。
启用向量化查询:SET hive.vectorized.execution.enabled=true;
3. 数据格式陷阱
TEXTFILE性能低:优先使用ORC/Parquet列式存储。
压缩算法选择:ORC表推荐使用SNAPPY压缩。
五、总结
| 查询场景 | 推荐语法 | 优化建议 |
|---|---|---|
| 简单数据筛选 | SELECT + WHERE | 结合分区字段过滤 |
| 聚合统计 | GROUP BY + HAVING | 预聚合中间结果 |
| 多表关联 | JOIN 或 MAPJOIN | 小表加载到内存 |
| 分页查询 | LIMIT + OFFSET | 避免深分页(使用ROW_NUMBER) |
| 复杂逻辑 | 子查询或CTE(Common Table Expression) | 拆分步骤提升可读性 |
实践
- 数据格式:优先使用ORC/Parquet存储格式。
- 分区设计:按时间、地域等业务逻辑分区。
- 避免全表扫描:在WHERE中明确分区条件。
大数据相关文章(推荐)
-
架构搭建:
中小型企业大数据平台全栈搭建:Hive+HDFS+YARN+Hue+ZooKeeper+MySQL+Sqoop+Azkaban 保姆级配置指南 -
大数据入门:大数据(1)大数据入门万字指南:从核心概念到实战案例解析
-
Yarn资源调度文章参考:大数据(3)YARN资源调度全解:从核心原理到万亿级集群的实战调优
-
Hive函数汇总:Hive函数大全:从核心内置函数到自定义UDF实战指南(附详细案例与总结)
-
Hive函数高阶:累积求和和滑动求和:Hive(15)中使用sum() over()实现累积求和和滑动求和
-
Hive面向主题性、集成性、非易失性:大数据(4)Hive数仓三大核心特性解剖:面向主题性、集成性、非易失性如何重塑企业数据价值?
-
Hive核心操作:大数据(4.2)Hive核心操作实战指南:表创建、数据加载与分区/分桶设计深度解析
相关文章:
Hive基础查询完全指南:从SELECT到复杂查询的10大核心技巧)
大数据(4.3)Hive基础查询完全指南:从SELECT到复杂查询的10大核心技巧
目录 背景一、Hive基础查询核心语法1. 基础查询(SELECT & FROM)2. 条件过滤(WHERE)3. 聚合与分组(GROUP BY & HAVING)4. 排序与限制(ORDER BY & LIMIT) 二、复杂查询实战…...
手搓多模态-03 顶层和嵌入层的搭建
声明:本代码非原创,是博主跟着国外大佬的视频教程编写的,本博客主要为记录学习成果所用。 我们首先开始编写视觉模型这一部分,这一部分的主要功能是接收一个batch的图像,并将其转化为上下文相关的嵌入向量,…...

【经验分享】将qt的ui文件转换为py文件
🌟 嗨,我是命运之光! 🌍 2024,每日百字,记录时光,感谢有你一路同行。 🚀 携手启航,探索未知,激发潜能,每一步都意义非凡。 首先简单的设计一个U…...

常用的国内镜像源
常见的 pip 镜像源 阿里云镜像:https://mirrors.aliyun.com/pypi/simple/ 清华大学镜像:https://pypi.tuna.tsinghua.edu.cn/simple 中国科学技术大学镜像:https://pypi.mirrors.ustc.edu.cn/simple/ 豆瓣镜像:https://pypi.doub…...
探秘JVM内部
在我们编写Java代码,点击运行后,会发生什么事呢? 首先,Java源代码会经过Java编译器将其编译成字节码,放在.class文件中 然后这些字节码文件就会被加载到jvm中,然后jvm会读取这些文件,调用相关…...

在HarmonyOS NEXT 开发中,如何指定一个号码,拉起系统拨号页面
大家好,我是 V 哥。 《鸿蒙 HarmonyOS 开发之路 卷1 ArkTS篇》已经出版上市了哈,有需要的朋友可以关注一下,卷2应用开发篇也马上要出版了,V 哥正在紧锣密鼓的写鸿蒙开发实战卷3的教材,卷3主要以项目实战为主࿰…...
利用空间-运动-回波稀疏性进行5D图像重建,以实现自由呼吸状态下肝脏定量磁共振成像(MRI)的加速采集|文献速递--深度学习医疗AI最新文献
Title 题目 5D image reconstruction exploiting space-motion-echo sparsity foraccelerated free-breathing quantitative liver MRI 利用空间-运动-回波稀疏性进行5D图像重建,以实现自由呼吸状态下肝脏定量磁共振成像(MRI)的加速采集 …...

Qt5 Mac系统检查休眠
在开发跨平台应用程序时,有时候我们需要检测系统的状态,比如是否处于休眠或唤醒状态。Qt是一个强大的跨平台应用开发框架,支持多种操作系统,包括Windows、Linux、macOS等。在这个场景下,我们关注的是如何在Qt5.10中检测到系统是否休眠以及在Mac上实现这一功能。本文将深入…...

ZKmall开源商城B2B2C电商用户隐私信息保护策略:数据脱敏全链路实践
随着业务的不断拓展和用户规模的持续扩大,用户隐私信息的保护也面临着前所未有的挑战。下面将深入探讨ZKmall开源商城在数据脱敏方面的实践,以及针对B2B2C电商用户隐私信息的具体保护策略。 数据脱敏,又称数据去标识化或数据匿名化࿰…...

Media streaming mental map
Media streaming is a huge topic with a bunch of scattered technologies, protocols, and formats. You may feel like hearing fragments without seeing the big picture. Let’s build that mental map together — here’s a high-level overview that connects everyt…...

linux Gitkraken 破解
ubuntu 安装 Gitkraken 9.x Pro 版本_gitcracken.git-CSDN博客...

SSL证书颁发机构有哪些呢
证书颁发机构(Certificate Authority, CA)是负责签发和管理数字证书的权威机构,分为公共信任的 CA 和私有/内部 CA。以下是常见的公共信任的 CA 分类及代表机构: 1. 国际知名公共 CA(浏览器/操作系统默认信任ÿ…...

13_pandas可视化_seaborn
导入库 import numpy as np import pandas as pd # import matplotlib.pyplot as plt #交互环境中不需要导入 import seaborn as sns sns.set_context({figure.figsize:[8, 6]}) # 设置图大小 # 屏蔽警告 import warnings warnings.filterwarnings("ignore")关系图 …...

Pgvector的安装
Pgvector的安装 向量化数据的存储,可以为 PostgreSQL 安装 vector 扩展来存储向量化数据 注意:在安装vector扩展之前,请先安装Postgres数据库 vector 扩展的步骤 1、下载vs_BuildTools 下载地址: https://visualstudio.microso…...

如何在大型项目中组织和管理 Vue 3 Hooks?
众所周知,Vue Hooks(通常指 Composition API 中的功能)是 Vue 3 引入的一种代码组织方式,用于更灵活地组合和复用逻辑。但是在项目中大量使用这种写法该如何更好的搭建结构呢?以下是可供参考实践的案例。 一、Hooks 组织原则 单一职责每个 Hook 应专注于完成单一功能,避…...

Django接入 免费的 AI 大模型——讯飞星火(2025年4月最新!!!)
上文有介绍deepseek接入,但是需要 付费,虽然 sliconflow 可以白嫖 token,但是毕竟是有限的,本文将介绍一款完全免费的 API——讯飞星火 目录 接入讯飞星火(免费) 测试对话 接入Django 扩展建议 接入讯飞星火…...
路由器学习
路由器原理 可以理解成把不同的网络打通,实现通信的设备。比如家里的路由器,他就是把家里的内网和互联网(外网)打通。 分类 1.(按应用场景分类) 路由器分为家用的,企业级的,运营…...

Redis 连接:深入解析与优化实践
Redis 连接:深入解析与优化实践 引言 Redis 作为一款高性能的键值型数据库,广泛应用于缓存、会话存储、消息队列等领域。Redis 的连接管理是确保其性能和稳定性的关键。本文将深入探讨 Redis 连接的原理、配置、优化方法以及常见问题,帮助您更好地掌握 Redis 连接技术。 …...
UE5学习记录part14
第17节 enemy behavior 173 making enemies move: AI Pawn Navigation 按P查看体积 So its very important that our nav mesh bounds volume encompasses all of the area that wed like our 因此,我们的导航网格边界体积必须包含我们希望 AI to navigate in and …...

【中间件】使用ElasticSearch提供的RestClientAPI操作ES
一、简介 ElasticSearch提供了RestClient来操作ES,包括对数据的增删改查,可参照官方文档:Java High Level REST Client 二、使用步骤: 可参照官方文档操作 导包 <dependency><groupId>org.elasticsearch.client<…...

Docker的备份与恢复
一、两种基本方式 docker export / import 在服务器上导出容器docker export container_name > container_backup.tar这里使用 > 重定向时默认保存路径为当前运行命令的路径,可以自行指定绝对路径来保存,后续加载时也使用对应的路径即可。 恢复为…...
)
C++ string 对象的操作(三十五)
1. string 对象的常见操作 下面的表格列出了 string 类型最常用的一些操作以及它们的功能: 操作说明示例os << s将字符串对象 s 写入输出流 os,返回 os。std::cout << s;is >> s从输入流 is 中读取字符串赋给 s(以空白分…...
DAPP实战篇:规划下我们的开发线路
前言 在DApp实战篇:先用前端起个项目一文中我们起了一个前端项目,在后续开发中笔者将带领大家一步步完成这个DAPP,为了方便后续讲解,本篇将完整说明后续我们要进行的开发和思路。 主打前端 实际上一个完整的DAPP是由前端和智能…...
)
[leetcode] 面试经典 150 题——篇9:二叉树(番外:二叉树的遍历方式)
二叉树的遍历是指按照某种顺序访问二叉树中的每个节点。常见的遍历方式有四种:前序遍历(Pre-order Traversal)、中序遍历(In-order Traversal)、后序遍历(Post-order Traversal)以及层序遍历&am…...

【Elasticsearch】开启大数据分析的探索与预处理之旅
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...
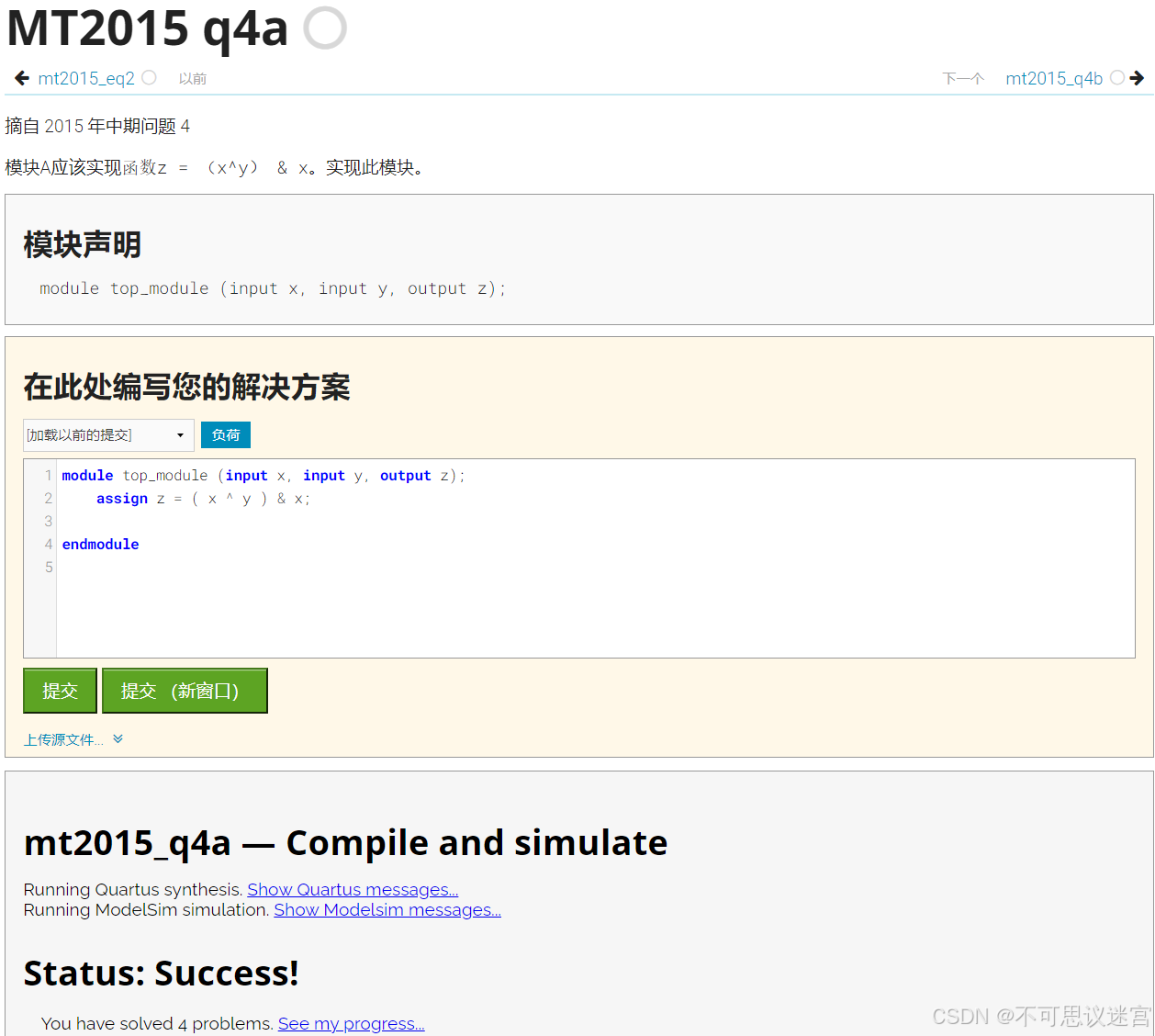
状态机思想编程练习
状态机实现LED流水灯 本次实验,我们将利用状态机的思想来进行Verilog编程实现一个LED流水灯,并通过Modelsim来进行模拟仿真,再到DE2-115开发板上进行验证。 首先进行主要代码的编写。 module led (input sys_clk,input sys_…...
)
C#:接口(interface)
目录 接口的核心是什么? 1. 什么是接口(Interface),为什么要用它? 2. 如何定义和使用接口? 3.什么是引用接口? 如何“引用接口”? “引用接口”的关键点 4. 接口与抽象类的区…...
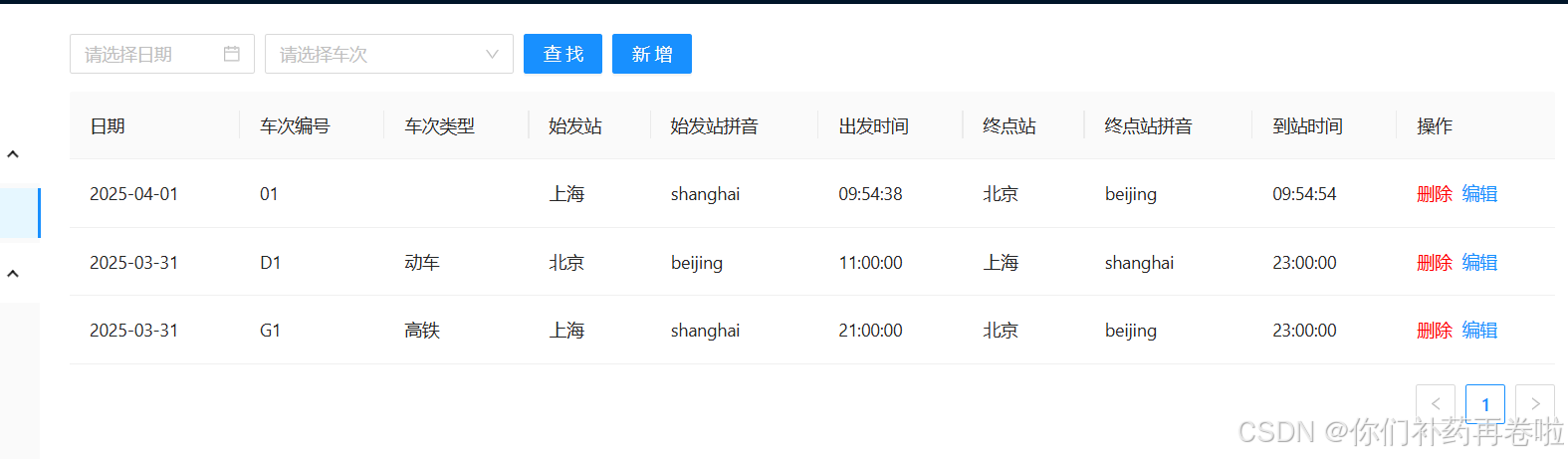
前端新增数据,但数据库里没有新增的数据
先看情况: 1.前端,可以进行删查改,但是新增数据之后,显示保存成功,也增加了空白的一行,但是数据没有显示出来。 2.后端接收到了数据,但返回结果的列表里面是空的;同时数据库里面没…...

Go语言的测试框架
Go语言测试框架详解 Go语言(Golang)自发布以来,因其简洁、高效和并发支持而受到广泛欢迎。在软件开发过程中,测试是确保代码质量与稳定性的重要环节。Go语言内置的测试框架为开发者提供了灵活而强大的测试工具,使得编…...

堆结构——面试算法题高频汇总
目录 引言 堆创建&增删改 堆构造过程 举个例子 堆插入元素 删除元素 在数组中找第k大的元素 举例 堆排序原理 合并k个排序链表 数据流中位数问题 引言 堆是将一组数据按照完全二叉树的存储顺序,将数据存储在一个一维数组中的结构。堆有两种结构&…...