13_pandas可视化_seaborn
导入库
import numpy as np
import pandas as pd
# import matplotlib.pyplot as plt #交互环境中不需要导入
import seaborn as sns
sns.set_context({'figure.figsize':[8, 6]}) # 设置图大小
# 屏蔽警告
import warnings
warnings.filterwarnings("ignore")
关系图
散点图(scatterplot)
散点图是利用散点来描述两个变量的联合分布,scatterplot 适用于变量都是数字的情况
#scatterplot参数
seaborn.scatterplot(x=None, y=None, hue=None, style=None, size=None, data=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=True, style_order=None,x_bins=None, y_bins=None, units=None, estimator=None, ci=95, n_boot=1000, alpha='auto', x_jitter=None, y_jitter=None, legend='brief', ax=None, **kwargs)
- x、y:传入的
特征名字或Python/Numpy数据,x表示横轴,y表示纵轴,一般为dataframe中的列。如果传入的是特征名字,那么需要传入data,如果传入的是Python/Numpy数据,那么data不需要传入。 - hue:分组变量,将产生不同颜色的点。可以是分类的,也可以是数字的。被视为类别。
- data: 传入的数据集,可选。一般是dataframe。
- style: 分组变量,将产生不同标记点的变量分组。被视为类别。
- size: 分组变量,将产生不同大小的点。可以是分类的,也可以是数字的。
- palette: 调色板,后面单独介绍。
- markers: 绘图的形状,后面单独介绍。
- ci: 允许的误差范围(空值误差的百分比,0-100之间),可为‘sd’,则采用标准差(默认95)
- n_boot(int): 计算置信区间要使用的迭代次数
- alpha: 透明度
- x_jitter, y_jitter: 设置点的抖动程度。
# 使用seaborn的数据
tips = sns.load_dataset('tips')
sns.scatterplot(x='total_bill',y='tip',data=tips)
# plt.show() # 交互环境中不需要调用sns.scatterplot(x='total_bill',y='tip',hue='day',style='time',size='size',data=tips)
# plt.show() # 交互环境中不需要调用
线图(lineplot)
seaborn.lineplot(x=None, y=None, hue=None, size=None, style=None,data=None, palette=None, hue_order=None, hue_norm=None, sizes=None,size_order=None, size_norm=None, dashes=True, markers=None, style_order=None, units=None, estimator='mean', ci=95, n_boot=1000, sort=True, err_style='band', err_kws=None, legend='brief', ax=None, **kwargs)
参数与scatterplot差不多
fmri = sns.load_dataset('fmri')
sns.lineplot(x="timepoint", y="signal", data=fmri)
# 阴影是默认的置信区间,可设置ci=0,将其去除sns.lineplot(x="timepoint", y="signal",hue="event", style="event",
markers=True, dashes=False, data=fmri)
# markers=True表示使用不同的标记
# dashes=True表示一条实线,一条虚线
同时画两个线图,显示不同的颜色
tips['day_num'] = tips['day']
tips['day_num'] = tips['day_num'].map({'Thur':4,'Fri':5,'Sat':6,'Sun':7})
# 绘制第一条线
sns.lineplot(y='total_bill',x='day',data=tips.sort_values('day_num'),ci=0,color='g')
# 绘制第二条线
sns.lineplot(y='tip',x='day',data=tips.sort_values('day_num'),ci=0,color='r')
# plt.show() # 交互环境中不需要调用
# 第一条线显示总金额,颜色显示为绿色
# 第一条线显示消费,颜色显示为红色
关系图(relplot)
seaborn.relplot(x=None, y=None, hue=None, size=None, style=None, data=None, row=None, col=None, col_wrap=None, row_order=None, col_order=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=None, dashes=None,style_order=None, legend='brief', kind='scatter', height=5, aspect=1,facet_kws=None, **kwargs)
相当于lineplot与scatterplot的规约可以通过kind参数指定画什么图形
- kind: 默认是’scatter’,也可以选择kind=‘line’
- sizes: List、dict或tuple,可选,会图点(或特殊样式标记)的大小,注意和size区分;(用途不大)
- col、row: col指定列的分组变量,row指定行的分组变量,具体看下面例子
g = sns.relplot(x="total_bill", y="tip", data=tips)
#两者效果一模一样
ax = sns.scatterplot(x="total_bill", y="tip", data=tips)
sns.relplot(x="total_bill", y="tip", hue="time", size="size",palette=["b", "r"], sizes=(10, 100),col="time",row='sex', data=tips)
# palette=["b", "r"] 设置颜色 blue,red
# 根据col="time",row='sex'分组
分类图
分类散点图
stripplot(分布散点图)
stripplot(分布散点图)就是其中一个bianl-是分类变量的scatterplot(散点图)。stripplot一般并不单独画,常常与boxplot和violinplot联合起来绘制,作为这两种图的补充。
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=True, dodge=False, orient=None, color=None, palette=None, size=5, edgecolor='gray', linewidth=0, ax=None, **kwargs)
- order:用order参数进行筛选分类类别,例如:order=[‘sun’,‘sat’];
- jitter:抖动项,表示抖动程度,可以是float或者True。如果不抖动的话,那么散点会呈现一条直线,并不利于可视化
- dodge:重叠区域是否分开,当使用hue时,将其设置为True,将沿着分类轴将不同颜色调级别的条带分开
- orient:‘v’|‘h’,vertiacl(垂直)和horizontal(水平)的意思;默认垂直(v),设置水平(h)显示时需要颠倒x,y
sns.stripplot(x="day", y="total_bill", hue="smoker",data=tips,jitter=True,palette="Set2", dodge=False)
# palette 设置颜色主题
swarmplot(分布密度散点图)
这个函数类似与stripplot()类似,但是对点进行了调整(只沿着分类轴),使每个点都不会重叠。这更好的表示了值的密度分布,但显然不适用大量观测的可视化。
seaborn.swarmplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, dodge=False, orient=None, color=None, palette=None, size=5,
edgecolor='gray', linewidth=0, ax=None, **kwargs)
sns.swarmplot(x="day", y="total_bill", data=tips)sns.swarmplot(x="day", y="total_bill", hue="smoker",data=tips,palette="Set2", dodge=True)
分类分布图
boxplot(箱型图)
boxplot(箱型图)就是描述变量关于不同类别的分布情况。框显示数据集的4分位数,线显示分布的其余部分,它能显示出一组数据的最大、最小、中位数以及上下4分位数,使用4分位数范围函数的方法可以确定“离群值”的点。
seaborn.boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, notch=False, ax=None, **kwargs)
- saturation : 饱和度,可设置为1
- width : float,控制箱型图的宽度大小
- fliersize : float,用于指示离群值观察的标记大小
- whis:可理解为异常值的上限IQR比例
sns.boxplot(x="day", y="total_bill", data=tips)
sns.boxplot(x="day", y="total_bill", hue="time",data=tips,linewidth=0.5,saturation=1,width=1,fliersize=3)
violinplot(小提琴图)
violinplot(小提琴图)就是绘制箱线图和核密度估计的组合。通过箱线图,可以得到数据对于类变量的分位数,通过核密度估计,可以知道哪些位置的密度大。
seaborn.violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, bw='scott', cut=2, scale='area', scale_hue=True, gridsize=100, width=0.8, inner='box', split=False, dodge=True, orient=None, linewidth=None, color=None, palette=None, saturation=0.75, ax=None, **kwargs)
- bw:‘scott’,‘silverman’,float
控制拟合程度。在计算内核宽带时,可以引用规则的名称(‘scott’,‘silverman’)或者使用比例(float)。实际内核大小将通过将比例乘以每个bin内数据的标准差来确定 - cut:空值外壳的延申超过极点的密度:float
- scale:’area‘,’count‘,’width‘,用来缩放每把小提琴的宽度的方法
- scale_hue:当使用hue分类后,设置为True时,此参数确定是否在主分组变量进行缩放
- gridsize:设置小提琴的平滑度,越高越平滑
- inner:’box‘,’quartile‘,’point‘,’stick‘,None,小提琴内部数据点的表示,分别是:箱子,四分位,点,数据线和不表示
- split:是否拆分,当设置True时,绘制经hue分类的每个级别画出一半的小提琴
sns.violinplot(x="day", y="total_bill", data=tips)# 设置按性别分类,调色为“Set2”,分割,以计数的方式,不表示内部。
sns.violinplot(x="day", y="total_bill", hue="sex",data=tips,palette="Set2", split=True,scale="count", inner=None)
分类估计图
barplot(条形图)
barplot(条形图)用举行条表示估计点和置信区间,使用误差线提供关于该估计值附近的不确定性的一些指示
seaborn.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=<function mean>, ci=95, n_boot=1000, units=None, orient=None, color=None, palette=None, saturation=0.75, errcolor='.26', errwidth=None,capsize=None, dodge=True, ax=None, **kwargs)
- estimator:用于估计每个分类箱内的统计函数,默认为mean。当然可以设置estimator=np.median/np.std/np.var…
- order :设置特征值的顺序,例如:order=[‘Sta’,‘Sun’]
- ci:允许的误差的范围(控制误差棒的百分比,在0-100之间),若填写‘std’,则使用标准误差(默认95),也可以设置ci=None;
- capsize:设置误差棒帽条(上下两根横线)的宽度,float;
- errcolor:表示置信区间的线条颜色
- errwidth:float,设置误差条线(和帽)的厚度
sns.barplot(x='day',y='total_bill',hue='sex',data=tips)sns.barplot(x='day',y='total_bill',hue='sex',data=tips,estimator=np.median,capsize=0.2,errcolor='c')
countplot(计数图)
countplot(计数图)用条形图显示各分类的观察次数,实际就是一个分类直方图。count是一个轴,然后特征是一个轴,因此不能同时输入x和y
seaborn.countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, dodge=True, ax=None, **kwargs)
sns.countplot(x='day',hue='sex',data=tips)
pointplot(点图)
pointplot(点图)使用散点图图形显示点估计和置信区间,并使用误差线提供关于该估计的不确定行的一些指示。点图比条形图更加聚焦与变量的不同值之间的比较,可以通过点连线的斜率差异来判断
seaborn.pointplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=<function mean>, ci=95, n_boot=1000, units=None, markers='o', linestyles='-', dodge=False, join=True, scale=1, orient=None, color=None, palette=None, errwidth=None, capsize=None, ax=None, **kwargs)
- join:默认两个统计点会相连接,若不想显示,可以设置join=False参数实现
- scale:float,均值点(默认)和连线的大小和粗细
sns.pointplot(x='time',y='total_bill',data=tips)
sns.pointplot(x='time',y='total_bill',hue='smoker',data=tips,estimator=np.median,dodge=True,palette='Set2',markers=['x','o'],linestyles=['-','--'])
catplot()
catplot() 其实就是对前面几个分类估计图的归纳,通过kind参数来选择具体的图形。
seaborn.catplot(x=None, y=None, hue=None, data=None, row=None, col=None, col_wrap=None, estimator=<function mean>, ci=95, n_boot=1000, units=None, order=None, hue_order=None, row_order=None, col_order=None, kind='strip',height=5, aspect=1, orient=None, color=None, palette=None, legend=True, legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, **kwargs)
和regplot(关系图)的使用方法差不多
- kind:默认strip(分布散点图),也可以选择‘point’,‘bar’,‘count’
- col,row:将决定网格的面数的分类变量,可以具体定制
- col_wrap:指定每行展示的子图个数,但是与row不兼容;
- row_order,col_order:字符串列表,安排行和列,以及推断数据中心的对象
- height,aspect:与图像的大小有关
- sharex,sharey:bool,‘color’,‘row’,是否共享x,y坐标轴
sns.catplot(x='time',y='total_bill',hue='smoker',data=tips,estimator=np.median,dodge=True,palette='Set2',markers=['x','o'],linestyles=['-','--'],kind='point')
exercise = pd.read_csv('../exercise.csv')
sns.catplot(x='time',y='pulse',hue='kind',kind='bar',col='diet',data=exercise,height=4,aspect=0.8)
多个图绘制在一起
在qtconsole环境下,直接调用sns的绘图函数,就会绘制图;如果要多个图绘制在一起,可以多行代码一块执行(按下ctrl键再回车,当前行的代码不会立即执行,待后面的代码写完后再回车,就可以把多个图绘制在一起了)。
sns.violinplot(x='tip',y='day',data=tips,whis=np.inf,inner=None)
sns.swarmplot(x='tip',y='day',data=tips,color='c')
sns.boxplot(x="tip", y="day", data=tips, whis=np.inf)
sns.stripplot(x="tip", y="day", data=tips,jitter=True, color="c")
sns.boxplot(x="tip", y="day", data=tips, whis=np.inf)
sns.swarmplot(x="tip", y="day", data=tips, color="c")
分布图
histplot(直方图)
histplot(直方图)绘制单变量或者双变量直方图,以显示数据集的分布。该函数可以对每个bin内计算的统计进行归一化估计频率、密度或概率质量,可以添加一个平滑曲线的到使用内核密度估计。
histplot(data=None, *, x=None, y=None, hue=None, weights=None, stat="count", bins="auto", binwidth=None, binrange=None, discrete=None, cumulative=False, common_bins=True, common_norm=True, multiple="layer", element="bars", fill=True, shrink=1, kde=False, kde_kws=None, line_kws=None, thresh=0, pthresh=None, pmax=None, cbar=False, cbar_ax=None, cbar_kws=None, palette=None, hue_order=None, hue_norm=None, color=None, log_scale=None, legend=True, ax=None, **kwargs,)
- x,y:为DataFrame 中的列名或者两组数据,data指向dataframe
- bins : int或者list,控制直方图的划分,设置矩形图(就是块的多少)数量,除特殊要求,一般默认
- kde:是否显示核密度估计曲线
- common_norm:若为True,则直方图高度显示频率而非计数
np.random.seed(666)
x=np.random.randn(1000)
sns.histplot(x,kde=True)# 修改更多参数,设置方块的数量,颜色为‘k’
sns.histplot(x,kde=True,bins=100,color='k')
kdeplot(核密度图)
kdeplot(核密度图)使用核密度估计绘制单变量或者双变量数据分布
seaborn.kdeplot(data, *,x=None,y=None, shade=False, vertical=False, kernel='gau', bw='scott', gridsize=100, cut=3, clip=None, legend=True, cumulative=False, shade_lowest=True, cbar=False, cbar_ax=None, cbar_kws=None, ax=None, **kwargs)
- x,y:为DataFrame 中的列名或者两组数据,data指向dataframe
- shade:是否填充阴影,默认不填充
- vertical:放置方向,如果为真,则观测值位于y轴上(默认False,x轴上)
- kernel:{‘gau’,‘cos’,‘biw’,‘epa’,‘tri’,‘triw’}。默认高斯核(gau)二元KDE只能使用高斯核
- bw:{‘scott’ | ‘silverman’ | scalar | pair of scalars }。四类核密度带方法,默认scott (斯考特带宽法)
- gridsize:这个参数指的是每个格网里面,应该包含多少个点,越大,表示格网里面的点越多,越小表示格网里面的点越少;
- cut:绘制的时候,切除带宽往数轴极限数值的多少,这个参数可以配合bw参数使用
- cumulative:是否绘制累积分布
- shade_lowest:是否有最低值渲染,这个参数只有在二维密度图上有效
- clip:表示查看部分结果,是一个区间
- cbar:参数若为True,则会添加一个颜色棒(颜色棒在二元kde图中才有)
mean, cov = [0, 2], [(1, .5), (.5, 1)]
#这是一个多元正态分布,x和y都是长度为50的向量
x, y = np.random.multivariate_normal(mean, cov, size=50).T
sns.kdeplot(x)
#绘制双变量核密度图
sns.kdeplot(x=x,y=y,shade=True,shade_lowest=False,cbar=True,color='r')
iris = pd.read_csv('../iris.csv')
setosa = iris[iris.species == "setosa"]
virginica = iris[iris.species == "virginica"]sns.kdeplot(x=setosa.sepal_width, y=setosa.sepal_length,cmap="Reds",shade=True, shade_lowest=False)
sns.kdeplot(x=virginica.sepal_width, y=virginica.sepal_length,cmap="Blues",shade=True, shade_lowest=False)
jointplot(联合分布图)
jointplot(联合分布图)其实就是直方图与核密度图的组合
seaborn.jointplot(x, y, data=None, kind='scatter', stat_func=None, color=None, height=6, ratio=5, space=0.2, dropna=True, xlim=None, ylim=None, joint_kws=None,marginal_kws=None, annot_kws=None, **kwargs)
- x,y:为DataFrame 中的列名或者两组数据,data指向dataframe
- kind:{‘scatter’,‘reg’,‘resid’,‘kde’,‘hex’}。默认是散点图
- stat_func:用于计算统计量关系的函数
- ratio:中心图与侧边图的比例,越大,中心图占比越大
- dropna:删除缺失值
- height:图的尺度大小
- space:中心图与侧边图的间隔大小
- xlim,ylim:x,y的范围
sns.jointplot(x="total_bill", y="tip", data=tips,height=5)
sns.jointplot(x="sepal_width", y="petal_length", data=iris,kind="kde", space=0,ratio=6 ,color="r")
sns.jointplot(x="sepal_width", y="petal_length",hue='species', data=iris,kind="kde" ,color="r")
pairplot(变量关系组图)
pairplot(变量关系组图)描述数据集中的成对关系。默认情况下,该函数创建一个轴网格,对角线描述该变量的直方图,非对角线描述两个变量之间的联合分布。
seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, kind='scatter', diag_kind='auto', markers=None,height=2.5, aspect=1, dropna=True, plot_kws=None, diag_kws=None, grid_kws=None, size=None)
- vars:data中的子集,否则使用data中的每一列
- x_vars/y_vars:可以具体细分,谁与谁比较
- kind:{‘scatter’ , ‘reg’}
- diag_kind:{‘auto’,‘hist’,‘kde’}。对角线的图样,默认情况取决于是否只用’hue’
sns.pairplot(iris)sns.pairplot(iris,hue='species',markers=['o','s','D'])
回归图
regplot(回归图)
regplot(回归图)在绘制图时自动进行线性回归模型拟合
seaborn.regplot(x, y, data=None, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=False, dropna=True, x_jitter=None, y_jitter=None, label=None, color=None, marker='o', scatter_kws=None, line_kws=None, ax=None)
- order:多项式回归没控制回归的幂次,设定指数,可以用多项式拟合
- logistic:逻辑回归
- x_jitter,y_jitter:给x,y轴随机增加噪音点,设置这两个参数比不影响最后的回归直线
sns.regplot(x='total_bill',y='tip',data=tips)
lmplot(网格+回归图)
implot(网格+回归图)相当于regplot(回归图)和网格图的组合
seaborn.lmplot(x, y, data, hue=None, col=None, row=None, palette=None, col_wrap=None, height=5, aspect=1, markers='o', sharex=True, sharey=True, hue_order=None, col_order=None, row_order=None, legend=True, legend_out=True, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=False, x_jitter=None, y_jitter=None, scatter_kws=None, line_kws=None, size=None)
- col,row:根据所指的属性列、行上分类
- col_wrap:指定每行的列数,最多等于col参数所对应的不同类别的数量
- aspect:控制图的长宽比
- robust:如果式True,使用statsmodels来估计一个稳健的回归(鲁棒线性模型)。这将减少异常值。请注意 logistic回归和robust回归相较于简单线性回归需要更大的计算量,其置信区间的产生也依赖于bootstrap采样,你可以关掉置信区间估计来提高速度(ci=None)
- lowess:如果式True,使用statsmodels来估计一个非参数的模型(局部加权线性回归)。这种方法具有最少的假设,尽管它是计算密集型的,但目前无法为这类模型绘制置信区间;
sns.lmplot(x='total_bill',y='tip',hue='smoker',data=tips)
sns.lmplot(x='total_bill',y='tip',hue='day',col='day',data=tips,col_wrap=2)
矩阵图
heatmap(热力图)
利用热力图可以看数据表里多个特性两两的相关性,类似于彩色矩阵
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
- data:矩阵数据集,可以使用numpy的数组(array),如果是pandas的dataframe,则df的index/column信息会分别对应到heatmap的columns和rows;
- vmax,vmin:图例中最大值和最小值的显示值,没有该参数默认不显示
- cmap:从数字到色彩空间的映射,取值是matplotlib包里的colormap名称或颜色对象,或者表示颜色的列表;
- center:数据表取值有差异时,设置热力图的色彩中心对齐值。通过设置center值,可以调整生成的图像颜色的整体深浅;设置center数据时,如果有数据溢出,则手动设置的vmax、vmin会自动改变 ;
- annot:annotate的缩写,默认False,如果是True,在热力图每个方格写入数据;如果是矩阵,在热力图每个方格写入该矩阵对应位置数据
- fmt:字符串格式化码,矩阵上标识数字的数据格式,比如保留小数点后几位
- annot_kws:默认取值False,如果是True,设置热力图矩阵上数字的大小颜色字体
- square:设置热力图矩阵小方块形状,默认False
- xticklabels、yticklabels:控制每行、列签名的输出。默认值是auto,自动选择签的标注间距,将标签名不重叠的部分(或全部)输出。如果是True,则以DataFrame的列名作为标签名;
- mask:控制某个矩阵块是否显示出来。默认值是None。如果是布尔型的DataFrame,则将DataFrame里True的位置用白色覆盖掉
# 绘制一个简单的numpy数组的热力图:
x = np.random.rand(10, 12)
sns.heatmap(x)
# 显示数字和保留几位小数,并修改数字大小字体颜色格式:
x= np.random.rand(10, 10)
sns.heatmap(x,annot=True,annot_kws={'size':9,'weight':'bold', 'color':'w'},fmt='.2f')
clustermap(聚类图)
clustermap()可以将矩阵数据集绘制为层次聚类热图;(更符合生物信息分析的要求)
seaborn.clustermap(data, pivot_kws=None, method='average', metric='euclidean', z_score=None, standard_scale=None, figsize=None, cbar_kws=None, row_cluster=True, col_cluster=True, row_linkage=None, col_linkage=None, row_colors=None, col_colors=None, mask=None, **kwargs)
iris = sns.load_dataset("iris")
species = iris.pop("species")
sns.clustermap(iris)
FacetGrid
FacetGrid用于初始化网格对象,每个子图都称为一个格子。其实就是relplt()、catplt()、lmplot()函数的一个上层类,可以根据自己的需求定制每个格子中画什么样的图
在大多数情况下,与直接使用FacetGrid相比,使用图形级函数(例如relplot)要好的多
seaborn.FacetGrid(data, row=None, col=None, hue=None, col_wrap=None, sharex=True, sharey=True, height=3, aspect=1, palette=None, row_order=None, col_order=None, hue_order=None, hue_kws=None, dropna=True, legend_out=True, despine=True, margin_titles=False, xlim=None, ylim=None, subplot_kws=None, gridspec_kws=None, size=None)
FacetGrid并不能直接绘制我们想要的图像,它的基本工作流程是FacetGrid使用数据集和用于构造网格的变量初始化对象。然后,可以通过调用FacetGrid.map()或将一个或多个绘图函数应用于每个子集 FacetGrid.map_dataframe(),最后,可以使用其他修改参数的方法调整绘图。
sns.FacetGrid(tips,col='time',row='smoker') # 2 * 2网格g = sns.FacetGrid(tips,col='time',row='smoker') # 2 * 2网格
g.map(plt.scatter,'total_bill','tip',color='c')
PairGrid
PairGrid() 用于绘制数据集中成对关系的子图网格。它的原理和pairplot是一样的,但是pairplot绘制的图像上、下三角形是关于主对角线对称的,而PairGrid则可修改上、下三角形和主对角线的图像形状。
iris = sns.load_dataset("iris")
g = sns.PairGrid(iris,hue="species")
g = g.map_upper(sns.scatterplot)#在上对角线子图上用二元函数绘制的图
g = g.map_lower(sns.kdeplot)#在下对角线子图上用二元函数绘制的图
g = g.map_diag(sns.kdeplot)#对角线单变量子图
相关文章:

13_pandas可视化_seaborn
导入库 import numpy as np import pandas as pd # import matplotlib.pyplot as plt #交互环境中不需要导入 import seaborn as sns sns.set_context({figure.figsize:[8, 6]}) # 设置图大小 # 屏蔽警告 import warnings warnings.filterwarnings("ignore")关系图 …...

Pgvector的安装
Pgvector的安装 向量化数据的存储,可以为 PostgreSQL 安装 vector 扩展来存储向量化数据 注意:在安装vector扩展之前,请先安装Postgres数据库 vector 扩展的步骤 1、下载vs_BuildTools 下载地址: https://visualstudio.microso…...

如何在大型项目中组织和管理 Vue 3 Hooks?
众所周知,Vue Hooks(通常指 Composition API 中的功能)是 Vue 3 引入的一种代码组织方式,用于更灵活地组合和复用逻辑。但是在项目中大量使用这种写法该如何更好的搭建结构呢?以下是可供参考实践的案例。 一、Hooks 组织原则 单一职责每个 Hook 应专注于完成单一功能,避…...

Django接入 免费的 AI 大模型——讯飞星火(2025年4月最新!!!)
上文有介绍deepseek接入,但是需要 付费,虽然 sliconflow 可以白嫖 token,但是毕竟是有限的,本文将介绍一款完全免费的 API——讯飞星火 目录 接入讯飞星火(免费) 测试对话 接入Django 扩展建议 接入讯飞星火…...
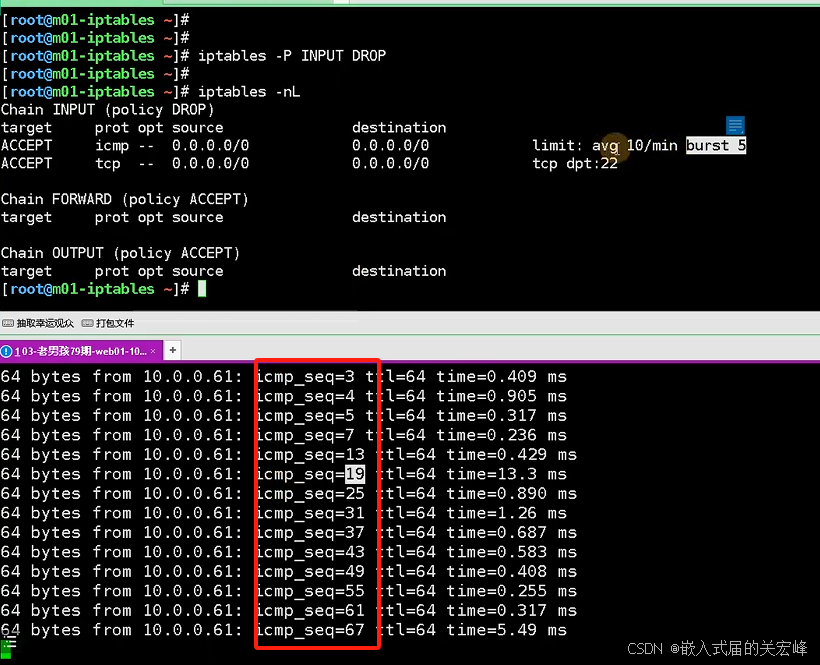
路由器学习
路由器原理 可以理解成把不同的网络打通,实现通信的设备。比如家里的路由器,他就是把家里的内网和互联网(外网)打通。 分类 1.(按应用场景分类) 路由器分为家用的,企业级的,运营…...

Redis 连接:深入解析与优化实践
Redis 连接:深入解析与优化实践 引言 Redis 作为一款高性能的键值型数据库,广泛应用于缓存、会话存储、消息队列等领域。Redis 的连接管理是确保其性能和稳定性的关键。本文将深入探讨 Redis 连接的原理、配置、优化方法以及常见问题,帮助您更好地掌握 Redis 连接技术。 …...
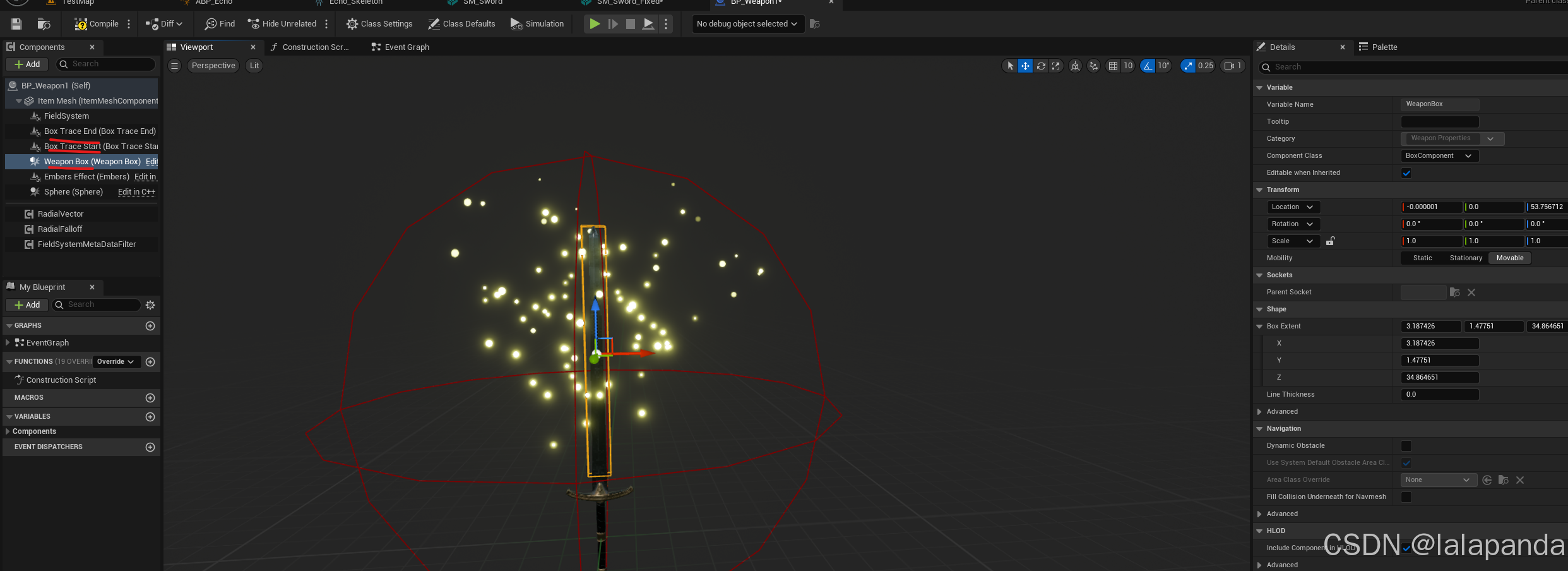
UE5学习记录part14
第17节 enemy behavior 173 making enemies move: AI Pawn Navigation 按P查看体积 So its very important that our nav mesh bounds volume encompasses all of the area that wed like our 因此,我们的导航网格边界体积必须包含我们希望 AI to navigate in and …...

【中间件】使用ElasticSearch提供的RestClientAPI操作ES
一、简介 ElasticSearch提供了RestClient来操作ES,包括对数据的增删改查,可参照官方文档:Java High Level REST Client 二、使用步骤: 可参照官方文档操作 导包 <dependency><groupId>org.elasticsearch.client<…...

Docker的备份与恢复
一、两种基本方式 docker export / import 在服务器上导出容器docker export container_name > container_backup.tar这里使用 > 重定向时默认保存路径为当前运行命令的路径,可以自行指定绝对路径来保存,后续加载时也使用对应的路径即可。 恢复为…...
)
C++ string 对象的操作(三十五)
1. string 对象的常见操作 下面的表格列出了 string 类型最常用的一些操作以及它们的功能: 操作说明示例os << s将字符串对象 s 写入输出流 os,返回 os。std::cout << s;is >> s从输入流 is 中读取字符串赋给 s(以空白分…...
DAPP实战篇:规划下我们的开发线路
前言 在DApp实战篇:先用前端起个项目一文中我们起了一个前端项目,在后续开发中笔者将带领大家一步步完成这个DAPP,为了方便后续讲解,本篇将完整说明后续我们要进行的开发和思路。 主打前端 实际上一个完整的DAPP是由前端和智能…...
)
[leetcode] 面试经典 150 题——篇9:二叉树(番外:二叉树的遍历方式)
二叉树的遍历是指按照某种顺序访问二叉树中的每个节点。常见的遍历方式有四种:前序遍历(Pre-order Traversal)、中序遍历(In-order Traversal)、后序遍历(Post-order Traversal)以及层序遍历&am…...

【Elasticsearch】开启大数据分析的探索与预处理之旅
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...
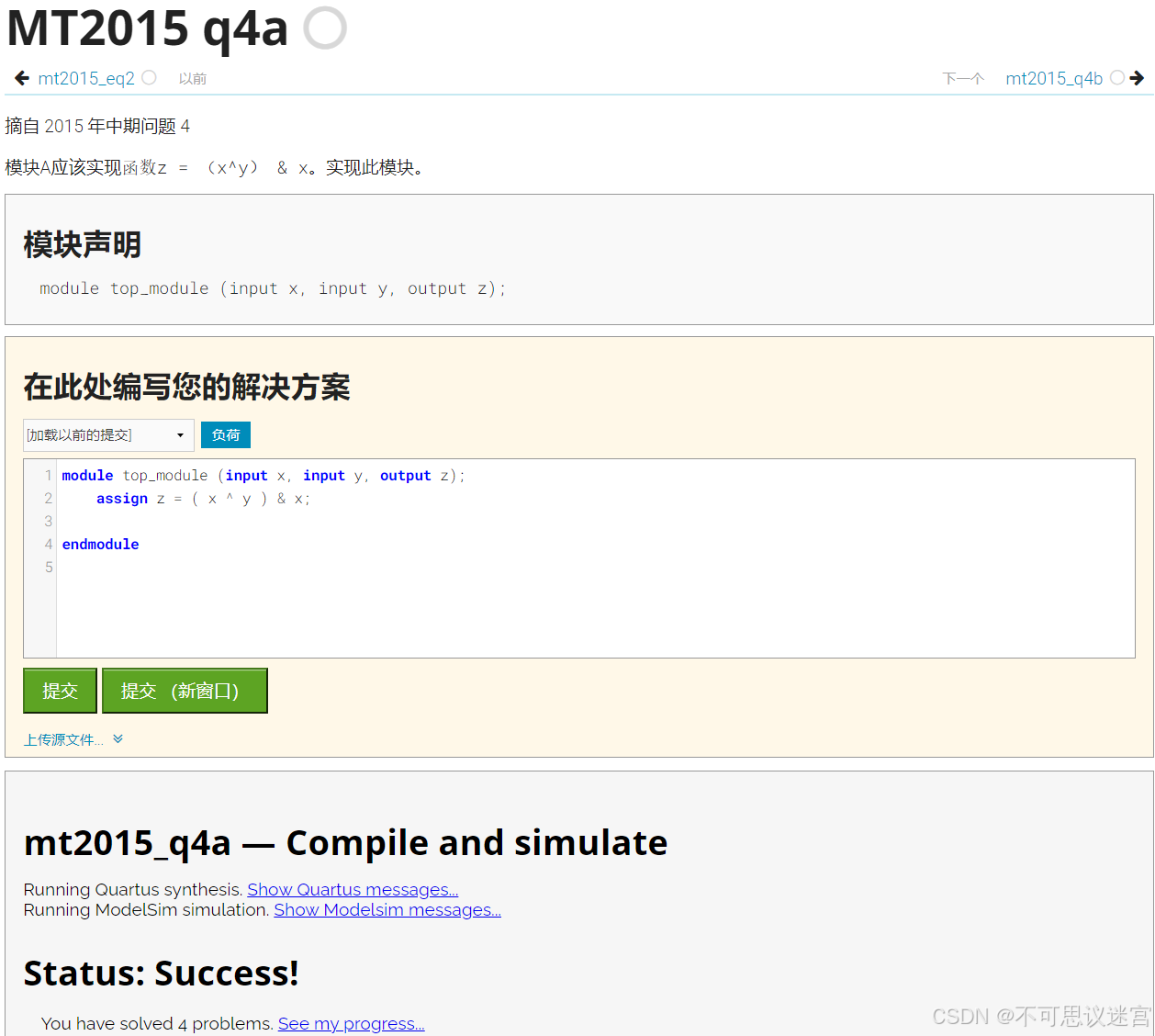
状态机思想编程练习
状态机实现LED流水灯 本次实验,我们将利用状态机的思想来进行Verilog编程实现一个LED流水灯,并通过Modelsim来进行模拟仿真,再到DE2-115开发板上进行验证。 首先进行主要代码的编写。 module led (input sys_clk,input sys_…...
)
C#:接口(interface)
目录 接口的核心是什么? 1. 什么是接口(Interface),为什么要用它? 2. 如何定义和使用接口? 3.什么是引用接口? 如何“引用接口”? “引用接口”的关键点 4. 接口与抽象类的区…...
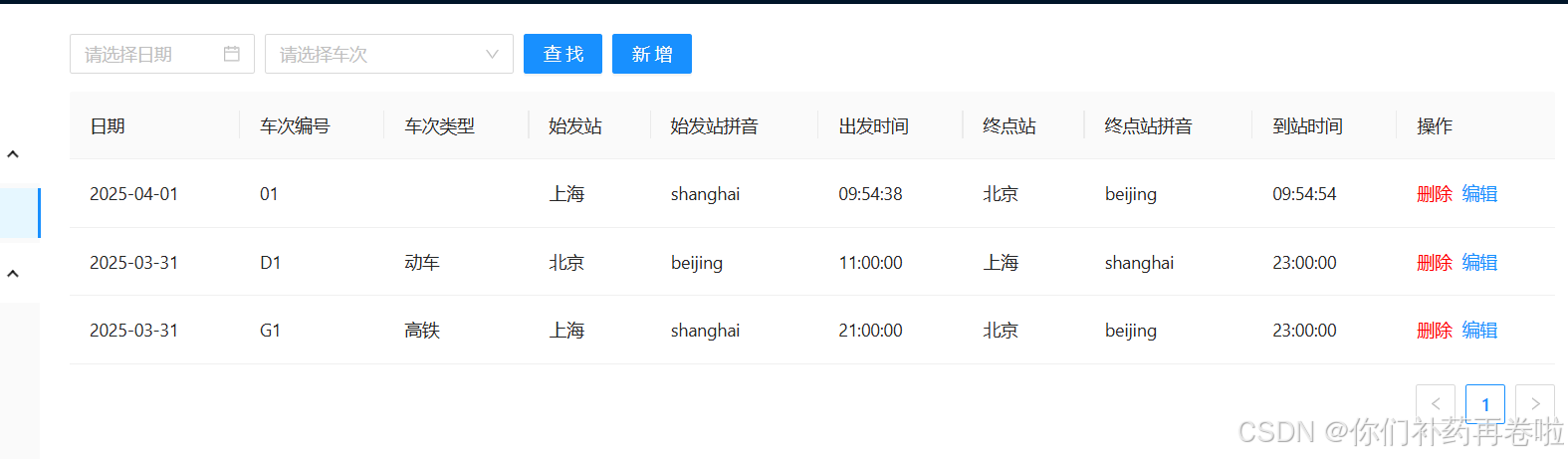
前端新增数据,但数据库里没有新增的数据
先看情况: 1.前端,可以进行删查改,但是新增数据之后,显示保存成功,也增加了空白的一行,但是数据没有显示出来。 2.后端接收到了数据,但返回结果的列表里面是空的;同时数据库里面没…...

Go语言的测试框架
Go语言测试框架详解 Go语言(Golang)自发布以来,因其简洁、高效和并发支持而受到广泛欢迎。在软件开发过程中,测试是确保代码质量与稳定性的重要环节。Go语言内置的测试框架为开发者提供了灵活而强大的测试工具,使得编…...

堆结构——面试算法题高频汇总
目录 引言 堆创建&增删改 堆构造过程 举个例子 堆插入元素 删除元素 在数组中找第k大的元素 举例 堆排序原理 合并k个排序链表 数据流中位数问题 引言 堆是将一组数据按照完全二叉树的存储顺序,将数据存储在一个一维数组中的结构。堆有两种结构&…...

httpx模块的使用
在使用requests模块发起请求时,报以下错误,表示服务器有可能使用的是http2.0协议版本,导致requests无法爬取。 此时就可以使用httpx模块爬取。 先下载httpx模块: pip install httpx[http2]然后用httpx发起请求: impo…...

Linux的: /proc/sys/net/ipv6/conf/ 笔记250405
Linux的: /proc/sys/net/ipv6/conf/ /proc/sys/net/ipv6/conf/ 是 Linux 系统中用于 动态配置 IPv6 网络接口参数 的核心目录。它允许针对不同网络接口(如 eth0、wlan0)或全局设置(all)调整 IPv6 协议栈的行为。 它通过虚拟文件系…...
论文阅读10——解开碳排放与碳足迹之间的关系:文献回顾和可持续交通框架
原文地址: Unraveling the relation between carbon emission and carbon footprint: A literature review and framework for sustainable transportation | npj Sustainable Mobility and TransportTransportation decarbonization has drawn enormous attention globally,…...

新一代AI架构实践:数字大脑AI+智能调度MCP+领域执行APP的黄金金字塔体系
新一代AI架构实践:数字大脑智能调度领域执行的黄金金字塔体系 一、架构本质的三层穿透性认知 1.1 核心范式转变(CPS理论升级) 传统算法架构:数据驱动 → 特征工程 → 模型训练 → 业务应用 新一代AI架构:物理规律建…...
Winform MQTT客户端连接方式
项目中使用到Winform的数据转发服务,所以记录下使用到的方法。 一.创建单例模板 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;namespace ConsoleApp.Scripts {public class SingleTon&…...

Linux Bash 脚本实战:自动监控域名证书过期并发送邮件告警
在日常运维工作中,SSL 证书的管理是一个非常重要的环节,尤其对于线上业务来说,证书到期会直接导致服务不可用。为了避免证书到期带来的风险,我们可以编写一个 Bash 脚本来自动检测域名的 SSL 证书过期时间,并在证书即将到期时发送告警邮件。 目录 脚本功能概述 代码实现…...

什么是异步?
什么是异步? 异步是一个术语,用于描述不需要同时行动或协调就能独立运行的流程。这一概念在技术和计算领域尤为重要,它允许系统的不同部分按自己的节奏运行,而无需等待同步信号或事件。在区块链技术中,异步是指网络中…...
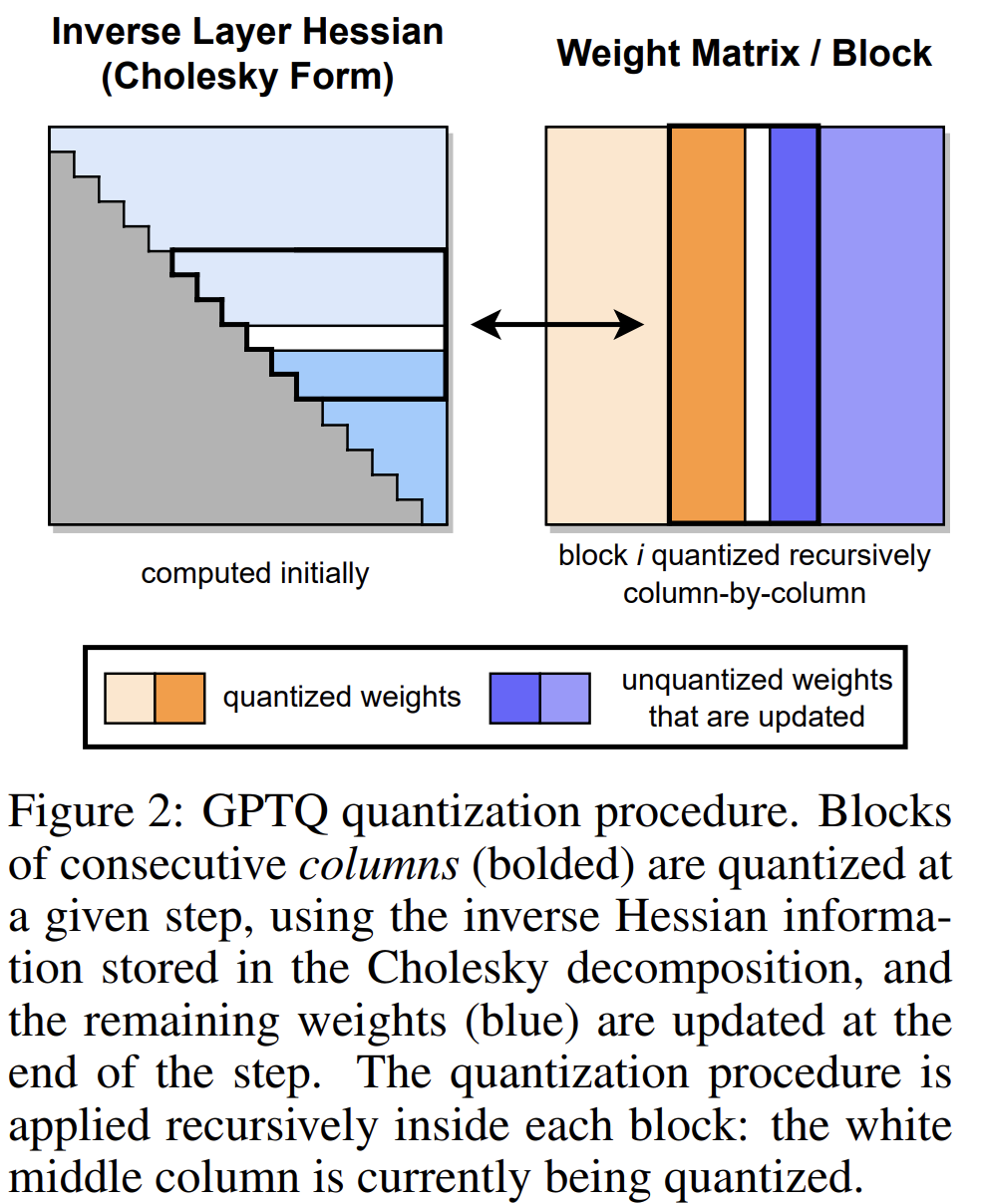
【模型量化】GPTQ 与 AutoGPTQ
GPTQ是一种用于类GPT线性最小二乘法的量化方法,它使用基于近似二阶信息的一次加权量化。 本文中也展示了如何使用量化模型以及如何量化自己的模型AutoGPTQ。 AutoGPTQ:一个易于使用的LLM量化包,带有用户友好的API,基于GPTQ算法(仅…...
学透Spring Boot — 018. 优雅支持多种响应格式
这是我的专栏《学透Spring Boot》的第18篇文章,想要更系统的学习Spring Boot,请访问我的专栏:学透 Spring Boot_postnull咖啡的博客-CSDN博客。 目录 返回不同格式的响应 Spring Boot的内容协商 控制器不用任何修改 启动内容协商配置 访…...
Ma)
Java小白-管理项目工具Maven(3)Ma
一、pom.xml文件 pom.xml 文件是 Maven(Apache Maven)项目的核心配置文件,它定义了项目的构建、依赖管理和项目元数据等信息。Maven 是一个流行的 Java 项目管理和构建自动化工具,而 pom.xml 是 Maven 项目中不可或缺的一部分。 …...
C++中的多态和模板
#include <iostream> #include <cstdlib> #include <ctime> #include <string>using namespace std;// 武器基类 class Weapon { public:virtual ~Weapon() {}virtual string getName() const 0; // 获取武器名称virtual int getAtk() const 0; …...
)
Java 类型转换和泛型原理(JVM 层面)
一、类型转换 概念解释: 编译类型:在编译时确定,保存在虚拟机栈的栈帧中的局部变量表中; 运行类型:在运行时确定,由保存在局部变量表中变量指向的堆中对象实例的类型决定(存储在对象头中&…...