Linux——文件(2)文件系统
我们知道,文件在没有被打开时是放在磁盘中的,通常我们未打开的文件数量要远远大于打开的文件数量,而且我们要想打开一个文件,首先需要知道文件在磁盘的位置才能打开,但问题是,面对磁盘中成百上千个文件,如何做到快速查找提高效率呢?这便是文件系统的任务。
一、磁盘结构
机械磁盘是计算机中唯一一个机械设备,且我们在之前说过,磁盘也属于外设,它的存储效率较慢,但容量大,价格也相对便宜,适合存储一些保存时间长久的数据,像我们现在的固态硬盘就相对存储速度快一些但也较贵。
1.磁盘的物理结构

物理结构主要是介绍一些零件的名称,我们来看看其储存结构
2.磁盘的储存结构
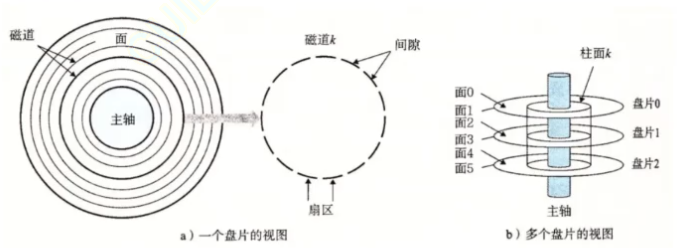
我们俯视一个盘片,其中整个盘片是一个以主轴为圆心,无数个半径不同的圆,其中每一个圆我们称为磁道(磁道之间也有间隙只不过很小),而这个磁道并不是连续不断的,是由一段段组成的一个圆(相当于一整个圆周被分为无数份),每一小段我们称为扇区,扇区是磁盘存储数据的基本单位,大小是512字节。
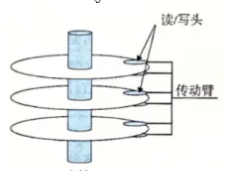
不过我们看似这个盘片只有一个,当我们横向观察时,就是图b的结构,会发现有多个盘片,而且每一个盘片的上下两面都可以存储数据,而就图中而言,我们确定了一个磁道,并把所有盘片相同的磁道组成的几何面就是柱面。而且,每一面都有一个磁头。所以我们读写哪一个磁头,就是在读写哪一个面。
在磁盘工作时,盘片会旋转,磁头会摆动,其中磁头摆动的本质就是确定磁道(柱面),盘片旋转的本质就是定位扇区。
那么如何定位一个扇区呢?
首先我们要知道在哪一面,即先定位磁头(header),然后要定位磁道(定位在哪个柱面)(cylinder),然后我们就可以让磁盘旋转,知道扇区转到磁头下即完成定位,也就说定位扇区(sector)。这种方法也叫CHS地址定位法。我们也可以定位多个扇区。
有一个细节是:传动臂上的磁头是共进退的(同时在某一柱面上工作)
在Linux上我们也可以查询自己的磁盘信息
sudo ls /dev/vda
3.磁盘的逻辑结构
盘片上的每一个扇区看似没有什么存储规律,但我们可以类比于磁带,磁带上面的长条就记录着数据,我们就可以把数据看成线性结构,而磁盘上的数据,我们就可以视为是磁带绕中心一圈圈卷起来的盘,如果把其拉长也可以看成线性结构存储,也就是数组,这样我们就可以通过数组下标定位数据扇区了。这种结构我们称LBA

4. 磁盘存储数据的真实过程
我们说过:传动臂上的磁头是共进退的(同时在某一柱面上工作),也就说我们存储数据时是在同一个柱面上工作,因此真实的过程是:把盘面的某一磁道展开形成一维数组,
但同时柱面有好几个盘面,所以把整个柱面展开就形成了二维数组
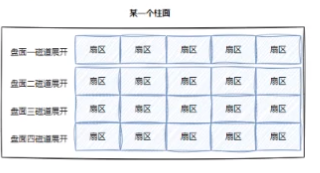
而把所有的柱面(二维数组)结合在一起,就构成了整个磁盘。
所以我们的操作系统想访问磁盘就是用LBA地址的方式,但我们还需要CHS的方法去定位扇区,因此我们需要知道LBA和CHS是如何相互转化的。
二、LBA和CHS的相互转化
CHS转LBA:
首先我们需要知道的是,转换之前我们肯定知道C、H、S都为多少。
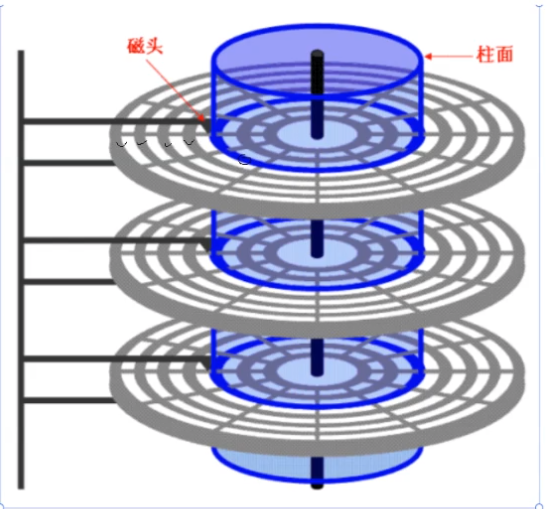
磁头数*每磁道扇区数=单个柱面扇区总数
LBA=柱面号C(每个柱面都有编号,从0开始)*单个柱面扇区总数+磁头号H(从上往下依次编号)*每磁道扇区数+扇区号S-1。
我们用两个”+“来把式子分成三个部分,第一部分代表此柱面前存储的总数(假设我现在要存3号柱面,那么代表0,1,2号柱面已经存储满了),第二部分是此盘面前存储的总数(假设现在要存储第3个磁头(面),说明0,1,2面已经存储满了,第三部分就是我们正要存储的磁道把前面已经存储的个数加上再减一(根据数组下标从0开始)。
LBA转换成CHS:
注:“//”表示除取整
柱面号C=LBA//(磁头数 *每磁道扇区数)->单个柱面的扇区总数
磁头号H=(LBA%(磁头数*每磁道扇区数))//每磁道扇区数
扇区号S=(LBA%每磁道扇区数)+1
但我们操作系统进行IO时,要是以每个扇区为基本单位,每次的数据量有些少,所以我们大多数都是以1,2,4,8KB等为单位进行IO,而Linux每次是以4KB(8个扇区)为单位进行IO,所以每八个扇区我们称为数据块。我们也可以把每个块进行编号,也就是块号。由块找到扇,只需要块号*8+[1,8]即可。
三、OS对磁盘空间的管理
假设我们有一块500GB的磁盘,直接让OS来管理效率有些低,所以,操作系统把磁盘分成了诸如100/100/100/200的分配形式,这个操作我们叫分区。我们windows中的C盘D盘等看似是好几个硬盘,实际上只是OS把一个盘进行了不同分区。Linux中同样也有分区操作。分区不只是把一块磁盘分成若干个盘,对于每一个分盘,它还会分成若干个组,只要管理好其中一组,那么其他部分自然就没问题了。
四、Ext*系列文件系统
我们先来介绍一下每个组中的各个区域
boot block属于开机时用到的模块,单独成组,我们不作解释。
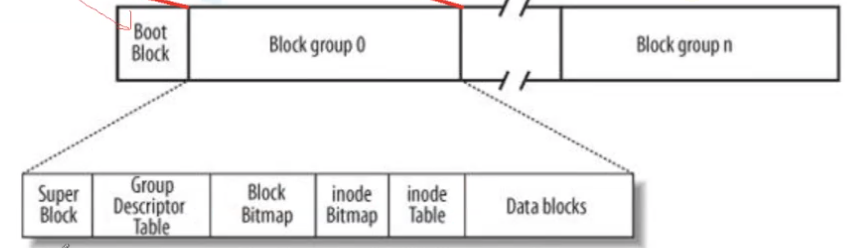
inode Table
我们知道,文件=内容+属性,属性也是数据,根据我们所讲的,文件的属性会被结构体包起来,这个结构体就是inode,每一个文件只有一个inode结构体,这个结构体就是属性数据的集合。当文件被创建时,这个struct inode就会放在inode Table中。每个文件的inode都有自己的编号,查看可以用命令ls -i选项。在Linux中,文件名不保存在inode中。
我们创建inode时,就会在inode Table申请空间然后放入,其实inode Table也可以看成是一个数组,每一个位置都放入一个inode,但是,我怎么知道哪个位置已经放入,哪些位置还是空的?这就需要inode Bitmap的作用。
inode Bitmap
与inode Table相匹配,是一个位图,当放入一个inode时,就会在所在位置的位图标记为1,这样下次只要找到位图位置为0就是空了。
data blocks
此区域就是放文件内容的,该区域分为无数个4KB的块,方便我们存储数据,所以Linux下文件内容和属性分开存储。
block Bitmap和inode Bitmap功能类似,就不多说了。
同时,我们也需要衡量inode Table的占用程度,一旦空间不足,就需要在其他组存放inode,因此我们还需要一个量来衡量这个因素——GDT块组描述符(结构体)
还有一个super block,它记录了整个分区的信息,包括起始块号和终止块号以及其他信息,比如block和inode的数量,使用量,修改时间等。其实它表示的就是文件系统,而每一个分区都有文件系统,且彼此不一定相同。在一个分区中,super block也不只有一个,可能在两三个组中有(但信息完全相同),其他组则没有,这是防止其中一个损坏而造成整个分区无法使用的危险。一旦某一个损坏,就会在其他组中寻找然后覆盖即可完成修复。
这是一个分区所要记录的信息,如果我们分区内一个文件也没有,也不意味着这些模块都没有信息,比如我们的各分区内部要清零,super block要记录其他模块的信息。每个分区都是如此,这个过程我们称格式化。格式化的本质是向一个分区中写入空的文件系统。
五、文件系统的进一步理解
对于一个组,inode号的个数以及block个数都是固定的。
对于inode:
inode以分区为单位,即一个分区一套inode。此外,inode分配时,只需要确定每个组的其起始inode编号即可,那么就可以知道每一个组内有多少个inode了。
对于block:
块号与inode号同理,这些信息都会被GDT、super block记录,所以组内所有部分都是确定的。所以OS对于文件管理就是通过super block以及GDT,然后描述+组织的方法实现文件系统管理。
因此,我们就可以通过inode来对文件进行增删查改了。但是,我们如何获得inode?在我们的操作中,往往都是通过文件名来进行文件的操作。
还记得我们说过,Linux中文件名并没有在inode中保存,实际上,它存在了目录文件中,而目录文件也有对应的内容+属性,有内容就要有对应的数据块,而文件名就存在这数据块内,而我们的inode就是通过文件名与inode的映射获取的。
但是,当我们想知道一个文件名时,我需要知道它在哪个目录的数据块下,可是目录也有名字,我们也需要知道目录的名字,一直递归下去,就是路径的逆向解析,知道找到根目录,因为根目录是写死的,我们也就知道文件的具体位置了,所以我们讲,文件必须要有路径。对此我们引入一个情况:假设在同一目录下,我们创建了test.txt和test1.txt,在我们第一次访问test.txt时,我们知道它是通过逆向目录解析完成的,但第二次访问test1.txt也是如此吗?我们换个角度,Linux会存储我们的文件路径吗?不会!
当我们第一次访问时,确实是需要路径递归,但同时,Linux会把文件路径以多叉树的形式缓存(内核数据结构struct dentry),这个缓存只是文件系统中的文件的很小一部分,第二次访问路径时,就不需要访问磁盘了,直接访问这个缓存结构即可找到文件。
六、文件操作符与进程的关系
我们可以通过fd来找到对应的struct file,而在这个结构体中就记录了文件的各种信息,比如:
struct file_operations //操作表
struct address_space //缓冲区
struct path //路径
而这个路径内部又记录着很多关键信息
struct path
{struct vfsmount *mnt;
struct dentry *dentry;
}
第二个就是我们所说的缓存路径,里面记录着文件的inode,引用计数,super block等信息。而且,每一个文件都有一个struct dentry,所以OS对文件的管理到最后就是对路径缓存上的节点的管理。 因此我们可以通过fd来查找文件的各种信息。
七、对文件系统的整体认识
首先,我们的磁盘会有很多分区,就对于一个组而言,当我们要在某一路径下进行文件操作时(比如新建文件)首先OS会对路径进行解析,解析之后会把路径加载到缓存中并把inode标记添加。此时进入内存层面,OS要对文件创建struct file,其中的inode 、path等就会一一对应这些信息。最后把磁盘的文件放在内核缓冲区(struct file中创建的结构)。
补充一点,虽然我们磁盘有许多分区,但是如果只有分区是无法直接使用的,需要进行一步”挂载“的操作,把分区挂载到目录上才可以使用(可以理解为把每一个分区标记上路径),这样我们的任一分区天然就有了基本路径。
相关文章:
Linux——文件(2)文件系统
我们知道,文件在没有被打开时是放在磁盘中的,通常我们未打开的文件数量要远远大于打开的文件数量,而且我们要想打开一个文件,首先需要知道文件在磁盘的位置才能打开,但问题是,面对磁盘中成百上千个文件&…...

蓝桥杯 web 水果拼盘 (css3)
做题步骤: 看结构:html 、css 、f12 分析: f12 查看元素,你会发现水果的高度刚好和拼盘的高度一样,每一种水果的盘子刚好把页面填满了,所以咱们就只要让元素竖着排列,加上是竖着,排不下的换行…...
【eNSP实验】RIP协议
RIP协议介绍 RIP(路由信息协议)是一种基于距离向量的内部网关协议,适用于小型网络。它通过跳数(最多15跳)衡量路径成本,定期与相邻路由器交换路由表。RIPv1使用广播更新且不支持子网,RIPv2新增…...
)
SQL Server常见问题的分类解析(二)
SQL Server常见问题解析100例(31-60) 七、数据库设计与维护问题 表设计不合理导致性能瓶颈问题:大表缺少分区,字段类型过大(如VARCHAR(MAX))。解决方案:使用分区表(PARTITION BY RANGE),优化字段类型。 索引过多导致写入性能下降问题:过度索引导致INSERT/UPDATE变慢…...
JAVA反序列化深入学习(十三):Spring2
让我们回到Spring Spring2 在 Spring1 的触发链上有所变换: 替换了 spring-beans 的 ObjectFactoryDelegatingInvocationHandler使用了 spring-aop 的 JdkDynamicAopProxy ,并完成了后续触发 TemplatesImpl 的流程 简而言之,换了一个chain&am…...
Matlab:三维绘图
目录 1.三维曲线绘图命令:plot3 实例——绘制空间直线 实例——绘制三角曲线 2.三维曲线绘图命令:explot3 3.三维网格命令:mesh 实例——绘制网格面 实例——绘制山峰曲面 实例——绘制函数曲线 1.三维曲线绘图命令:plot3 …...
学透Spring Boot — 016. 魔术师 - Spring MVC Conversion Service 类型转换
本文是我的《学透Spring Boot》专栏的第16篇文章,了解更多请移步我的专栏: Postnull的专栏《学透Spring Boot》 目录 遇到问题 日期格式的转换 实现需求 创建转换器 注册转换器 编写Controller 访问测试 存在的问题 解决问题 源码分析 总结 …...

Spring Boot开发三板斧:高效构建企业级应用的核心技法
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,获得2024年博客之星荣誉证书,高级开发工程师,数学专业,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开发技术,…...
)
人脸考勤管理一体化系统(人脸识别系统,签到打卡)
人脸考勤管理一体化系统 项目介绍 本项目是基于Flask、SQLAlchemy、face_recognition库的人脸考勤管理一体化系统。 系统通过人脸识别技术实现员工考勤打卡、人脸信息采集、人脸模型训练等功能。 项目采用前后端分离的技术框架,基于Flask轻量级Web框架搭建后端服务…...
Hive基础查询完全指南:从SELECT到复杂查询的10大核心技巧)
大数据(4.3)Hive基础查询完全指南:从SELECT到复杂查询的10大核心技巧
目录 背景一、Hive基础查询核心语法1. 基础查询(SELECT & FROM)2. 条件过滤(WHERE)3. 聚合与分组(GROUP BY & HAVING)4. 排序与限制(ORDER BY & LIMIT) 二、复杂查询实战…...
手搓多模态-03 顶层和嵌入层的搭建
声明:本代码非原创,是博主跟着国外大佬的视频教程编写的,本博客主要为记录学习成果所用。 我们首先开始编写视觉模型这一部分,这一部分的主要功能是接收一个batch的图像,并将其转化为上下文相关的嵌入向量,…...

【经验分享】将qt的ui文件转换为py文件
🌟 嗨,我是命运之光! 🌍 2024,每日百字,记录时光,感谢有你一路同行。 🚀 携手启航,探索未知,激发潜能,每一步都意义非凡。 首先简单的设计一个U…...

常用的国内镜像源
常见的 pip 镜像源 阿里云镜像:https://mirrors.aliyun.com/pypi/simple/ 清华大学镜像:https://pypi.tuna.tsinghua.edu.cn/simple 中国科学技术大学镜像:https://pypi.mirrors.ustc.edu.cn/simple/ 豆瓣镜像:https://pypi.doub…...
探秘JVM内部
在我们编写Java代码,点击运行后,会发生什么事呢? 首先,Java源代码会经过Java编译器将其编译成字节码,放在.class文件中 然后这些字节码文件就会被加载到jvm中,然后jvm会读取这些文件,调用相关…...

在HarmonyOS NEXT 开发中,如何指定一个号码,拉起系统拨号页面
大家好,我是 V 哥。 《鸿蒙 HarmonyOS 开发之路 卷1 ArkTS篇》已经出版上市了哈,有需要的朋友可以关注一下,卷2应用开发篇也马上要出版了,V 哥正在紧锣密鼓的写鸿蒙开发实战卷3的教材,卷3主要以项目实战为主࿰…...
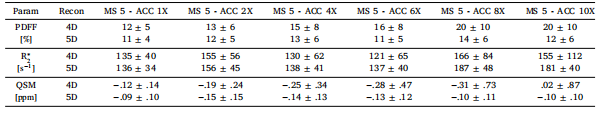
利用空间-运动-回波稀疏性进行5D图像重建,以实现自由呼吸状态下肝脏定量磁共振成像(MRI)的加速采集|文献速递--深度学习医疗AI最新文献
Title 题目 5D image reconstruction exploiting space-motion-echo sparsity foraccelerated free-breathing quantitative liver MRI 利用空间-运动-回波稀疏性进行5D图像重建,以实现自由呼吸状态下肝脏定量磁共振成像(MRI)的加速采集 …...

Qt5 Mac系统检查休眠
在开发跨平台应用程序时,有时候我们需要检测系统的状态,比如是否处于休眠或唤醒状态。Qt是一个强大的跨平台应用开发框架,支持多种操作系统,包括Windows、Linux、macOS等。在这个场景下,我们关注的是如何在Qt5.10中检测到系统是否休眠以及在Mac上实现这一功能。本文将深入…...

ZKmall开源商城B2B2C电商用户隐私信息保护策略:数据脱敏全链路实践
随着业务的不断拓展和用户规模的持续扩大,用户隐私信息的保护也面临着前所未有的挑战。下面将深入探讨ZKmall开源商城在数据脱敏方面的实践,以及针对B2B2C电商用户隐私信息的具体保护策略。 数据脱敏,又称数据去标识化或数据匿名化࿰…...

Media streaming mental map
Media streaming is a huge topic with a bunch of scattered technologies, protocols, and formats. You may feel like hearing fragments without seeing the big picture. Let’s build that mental map together — here’s a high-level overview that connects everyt…...

linux Gitkraken 破解
ubuntu 安装 Gitkraken 9.x Pro 版本_gitcracken.git-CSDN博客...

SSL证书颁发机构有哪些呢
证书颁发机构(Certificate Authority, CA)是负责签发和管理数字证书的权威机构,分为公共信任的 CA 和私有/内部 CA。以下是常见的公共信任的 CA 分类及代表机构: 1. 国际知名公共 CA(浏览器/操作系统默认信任ÿ…...

13_pandas可视化_seaborn
导入库 import numpy as np import pandas as pd # import matplotlib.pyplot as plt #交互环境中不需要导入 import seaborn as sns sns.set_context({figure.figsize:[8, 6]}) # 设置图大小 # 屏蔽警告 import warnings warnings.filterwarnings("ignore")关系图 …...

Pgvector的安装
Pgvector的安装 向量化数据的存储,可以为 PostgreSQL 安装 vector 扩展来存储向量化数据 注意:在安装vector扩展之前,请先安装Postgres数据库 vector 扩展的步骤 1、下载vs_BuildTools 下载地址: https://visualstudio.microso…...

如何在大型项目中组织和管理 Vue 3 Hooks?
众所周知,Vue Hooks(通常指 Composition API 中的功能)是 Vue 3 引入的一种代码组织方式,用于更灵活地组合和复用逻辑。但是在项目中大量使用这种写法该如何更好的搭建结构呢?以下是可供参考实践的案例。 一、Hooks 组织原则 单一职责每个 Hook 应专注于完成单一功能,避…...

Django接入 免费的 AI 大模型——讯飞星火(2025年4月最新!!!)
上文有介绍deepseek接入,但是需要 付费,虽然 sliconflow 可以白嫖 token,但是毕竟是有限的,本文将介绍一款完全免费的 API——讯飞星火 目录 接入讯飞星火(免费) 测试对话 接入Django 扩展建议 接入讯飞星火…...
路由器学习
路由器原理 可以理解成把不同的网络打通,实现通信的设备。比如家里的路由器,他就是把家里的内网和互联网(外网)打通。 分类 1.(按应用场景分类) 路由器分为家用的,企业级的,运营…...

Redis 连接:深入解析与优化实践
Redis 连接:深入解析与优化实践 引言 Redis 作为一款高性能的键值型数据库,广泛应用于缓存、会话存储、消息队列等领域。Redis 的连接管理是确保其性能和稳定性的关键。本文将深入探讨 Redis 连接的原理、配置、优化方法以及常见问题,帮助您更好地掌握 Redis 连接技术。 …...
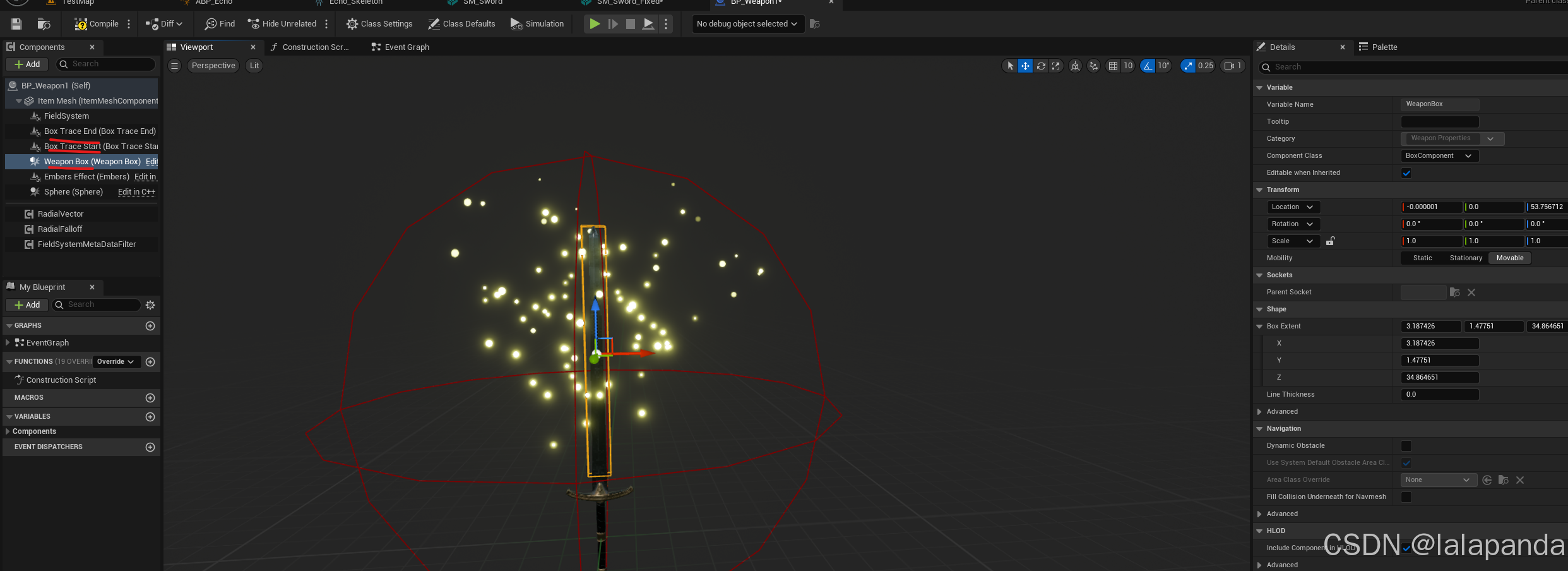
UE5学习记录part14
第17节 enemy behavior 173 making enemies move: AI Pawn Navigation 按P查看体积 So its very important that our nav mesh bounds volume encompasses all of the area that wed like our 因此,我们的导航网格边界体积必须包含我们希望 AI to navigate in and …...

【中间件】使用ElasticSearch提供的RestClientAPI操作ES
一、简介 ElasticSearch提供了RestClient来操作ES,包括对数据的增删改查,可参照官方文档:Java High Level REST Client 二、使用步骤: 可参照官方文档操作 导包 <dependency><groupId>org.elasticsearch.client<…...

Docker的备份与恢复
一、两种基本方式 docker export / import 在服务器上导出容器docker export container_name > container_backup.tar这里使用 > 重定向时默认保存路径为当前运行命令的路径,可以自行指定绝对路径来保存,后续加载时也使用对应的路径即可。 恢复为…...