大文件上传源码,支持单个大文件与多个大文件
大文件上传源码,支持单个大文件与多个大文件
- Ⅰ 思路
- Ⅱ 具体代码
- 前端--单个大文件
- 前端--多个大文件
- 前端接口
- 后端
Ⅰ 思路
具体思路请参考我之前的文章,这里分享的是上传流程与源码
https://blog.csdn.net/sugerfle/article/details/130829022
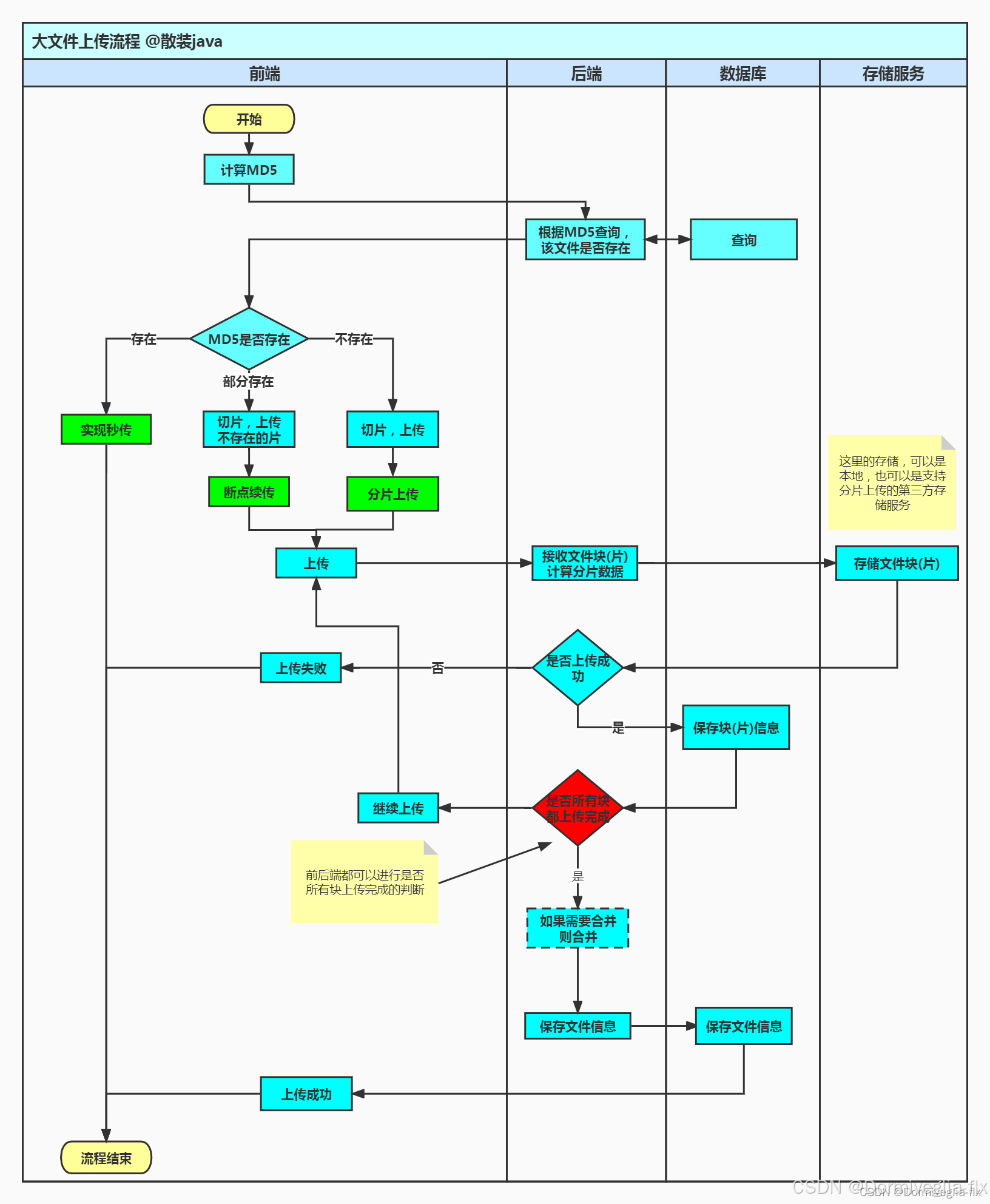
Ⅱ 具体代码
前端–单个大文件
<template><el-upload ref="fUploadFile"multipleaction="":show-file-list="false":http-request="fhandleFileUpload":limit="2":on-exceed="fhandleExceed":on-success="fhandleSuccess":on-change="fhandleChange":file-list="fFileList"><el-button class="button" type="primary">上传</el-button></el-upload>
</template><script>
import SparkMD5 from "spark-md5";
import {fcheckFileExists, fgetUploadedChunks, fMergeChunks, fUploadedChunks} from "@/api/record/recordfile";
export default {name: "VCUpload",props:['parentId'],data(){return{fFileList: [], // 文件列表fFile: null, // 当前文件fChunkSize: 3 * 1024 * 1024, // 分片大小:3MBfChunks: [], // 分片数组fUploadedChunks: [], // 已上传分片索引fFileType:"",fFileName:""}},methods:{fhandleChange(file){this.file = file.raw;var fileName = file.name;var fileArr = fileName.split('.');this.fFileType=fileArr[fileArr.length-1];this.fFileName = file.nameconsole.log("fhandleChange",file.raw)this.initChunks();},fhandleFileUpload(data){console.log("Flx组件",data)},fhandleExceed(){},fhandleSuccess(){this.$refs.fUploadFile.clearFiles();},// ========= 分片相关业务方法 =============// 初始化分片initChunks() {if (!this.file) return;const file = this.file;this.fChunks = [];let cur = 0;while (cur < file.size) {this.fChunks.push({index: this.fChunks.length,file: file.slice(cur, cur + this.fChunkSize),});cur += this.fChunkSize;}console.log("初始化分片",this.fChunks)this.calculateMD5(); // 计算文件 MD5},// 计算文件 MD5calculateMD5() {const spark = new SparkMD5.ArrayBuffer();const reader = new FileReader();reader.readAsArrayBuffer(this.file);reader.onload = (e) => {spark.append(e.target.result);const md5 = spark.end();this.checkFileExists(md5); // 检查文件是否已存在};},// 检查文件是否已存在(秒传逻辑)checkFileExists(md5) {console.log("秒传逻辑",md5)const data = {fileMd5:md5,parentId:this.parentId}fcheckFileExists(data).then(resp=>{console.log("检查文件是否已存在",resp)if(resp.data.data){this.$message.success('文件上传成功!');}else {this.getUploadedChunks(md5); // 获取已上传分片}}).catch(res=>{this.$message.success('文件检查失败!');})},// 获取已上传分片(断点续传逻辑)getUploadedChunks(md5) {const data = {md5: md5}fgetUploadedChunks(data).then(resp=>{console.log("获取数据库中已经上传分片",resp.data.data)this.fUploadedChunks = resp.data.data;// 开始上传this.startUpload(md5);})},// 开始上传async startUpload(md5) {const allChunkLength = this.fChunks.length;for(let i=0;i<allChunkLength;i++){console.log("是否需要继续上传",this.fUploadedChunks.includes(this.fChunks[i].index+""))if (!this.fUploadedChunks.includes(this.fChunks[i].index+"")) {const formData = new FormData();let formDataObj = {chunkIndex:this.fChunks[i].index,md5:md5}let sendData = JSON.stringify(formDataObj)formData.append('dto',new Blob([sendData],{type:"application/json"}))formData.append('chunkFile',this.fChunks[i].file)const result = await this.fetchUploadedChunks(formData);if(result=="error"){this.$message.success('文件分片上传失败!');return}console.log("上传分片成功",result)this.fUploadedChunks.push(this.fChunks[i].index);// 记录已上传分片if (this.fUploadedChunks.length === this.fChunks.length) {// 合并分片console.log("合并分片")this.mergeChunks(md5);}}}},fetchUploadedChunks(formData){return new Promise((resolve,reject)=>{fUploadedChunks(formData).then((resp)=>{resolve(resp.data.data)}).catch(err=>{reject("error")})})},mergeChunks(md5) {const data = {md5: md5,fileType:this.fFileType,parentId:this.parentId,name: this.fFileName,}fMergeChunks(data).then(resp=>{console.log("分片合并成功",resp.data.data)this.$message.success('文件上传完成!');this.fFileList = []})},}
}
</script><style scoped lang="scss"></style>前端–多个大文件
<template><div style="display: flex"><el-upload ref="fUploadFile"action="":auto-upload="false":show-file-list="false":multiple="true":http-request="fhandleFileUpload":limit="5":on-exceed="fhandleExceed":on-success="fhandleSuccess":file-list="fFileList"><el-button class="button" type="primary">选择文件</el-button></el-upload><el-button class="button" type="primary" @click.native="fsubmitUpload">上传</el-button></div>
</template><script>
import SparkMD5 from "spark-md5";
import {fcheckFileExists, fgetUploadedChunks, fMergeChunks, fUploadedChunks} from "@/api/record/recordfile";
export default {name: "VCUpload",props:['parentId'],data(){return{fFileList: [], // 文件列表fChunkSize: 3 * 1024 * 1024, // 分片大小:3MB}},methods:{// 自定义上传方法fhandleFileUpload(options){console.log("自定义上传方法",options)const { file } = options;const fileName = file.name;const fileArr = fileName.split('.');const fFileType=fileArr[fileArr.length-1];// 初始化分片const fChunks = this.initChunks(file);// 计算文件 MD5 并绑定到文件对象this.calculateMD5(file).then((md5) => {file.md5 = md5; // 将 MD5 值绑定到文件对象// 检查文件是否已存在(秒传逻辑)this.checkFileExists(md5).then((exists) => {if (exists) {this.$message.success(`${file.name} 已存在,无需上传!`);return;}// 获取已上传分片(断点续传逻辑)this.getUploadedChunks(md5).then(res=>{const fUploadedChunks = res;// 开始上传this.startUpload(md5,fChunks,fUploadedChunks,fileName,fFileType);});});});},// 文件超出限制时的回调fhandleExceed(files, fileList) {this.$message.warning(`最多只能上传5个文件!`);},fsubmitUpload(){this.$refs.fUploadFile.submit();},fhandleSuccess(){this.$refs.fUploadFile.clearFiles();},// ========= 分片相关业务方法 =============// 初始化分片initChunks(fArgsfile) {const file = fArgsfile;const fChunks = [];let cur = 0;while (cur < file.size) {fChunks.push({index: fChunks.length+"",file: file.slice(cur, cur + this.fChunkSize),});cur += this.fChunkSize;}console.log("初始化分片",fChunks)return fChunks;},// 计算文件 MD5calculateMD5(fArgsfile) {// 计算文件 MD5return new Promise((resolve) => {const spark = new SparkMD5.ArrayBuffer();const reader = new FileReader();reader.readAsArrayBuffer(fArgsfile);reader.onload = (e) => {spark.append(e.target.result);resolve(spark.end());};});},// 检查文件是否已存在(秒传逻辑)checkFileExists(md5) {return new Promise((resolve) => {const data = {fileMd5:md5,parentId:this.parentId}fcheckFileExists(data).then(resp=>{console.log("检查文件是否已存在",resp)resolve(resp.data.data)})})},// 获取已上传分片(断点续传逻辑)getUploadedChunks(md5) {return new Promise((resolve) => {const data = {md5: md5}fgetUploadedChunks(data).then(resp=>{console.log("获取数据库中已经上传分片",resp.data.data)resolve(resp.data.data)})})},// 开始上传async startUpload(md5,fChunks,fUploadedChunks,fileName,fFileType) {const allChunkLength = fChunks.length;for(let i=0;i<allChunkLength;i++){console.log("是否需要继续上传",fUploadedChunks,fChunks[i].index)if (!fUploadedChunks.includes(fChunks[i].index)) {const formData = new FormData();let formDataObj = {chunkIndex:fChunks[i].index,md5:md5}let sendData = JSON.stringify(formDataObj)formData.append('dto',new Blob([sendData],{type:"application/json"}))formData.append('chunkFile',fChunks[i].file)const result = await this.fetchUploadedChunks(formData);if(result=="error"){this.$message.success('文件分片上传失败!');return}console.log("上传分片成功",result)fUploadedChunks.push(fChunks[i].index);// 记录已上传分片if (fUploadedChunks.length === fChunks.length) {// 合并分片this.mergeChunks(md5,fileName,fFileType);}}}},fetchUploadedChunks(formData){return new Promise((resolve,reject)=>{fUploadedChunks(formData).then((resp)=>{resolve(resp.data.data)}).catch(err=>{reject("error")})})},mergeChunks(md5,fileName,fFileType) {const data = {md5: md5,fileType:fFileType,parentId:this.parentId,name: fileName,}fMergeChunks(data).then(resp=>{console.log("分片合并成功",resp.data.data)this.$message.success(fileName+'文件上传完成!');})},}
}
</script><style scoped lang="scss"></style>前端接口
export function fcheckFileExists(obj) {return request({url: '/admin/recordfile/check-file',method: 'post',data: obj})
}export function fgetUploadedChunks(obj) {return request({url: '/admin/recordfile/get-uploaded-chunks',method: 'post',data: obj})
}export function fUploadedChunks(obj) {return request({url: '/admin/recordfile/upload-chunk',method: 'post',data: obj})
}export function fMergeChunks(obj) {return request({url: '/admin/recordfile/merge-chunks',method: 'post',data: obj})
}后端
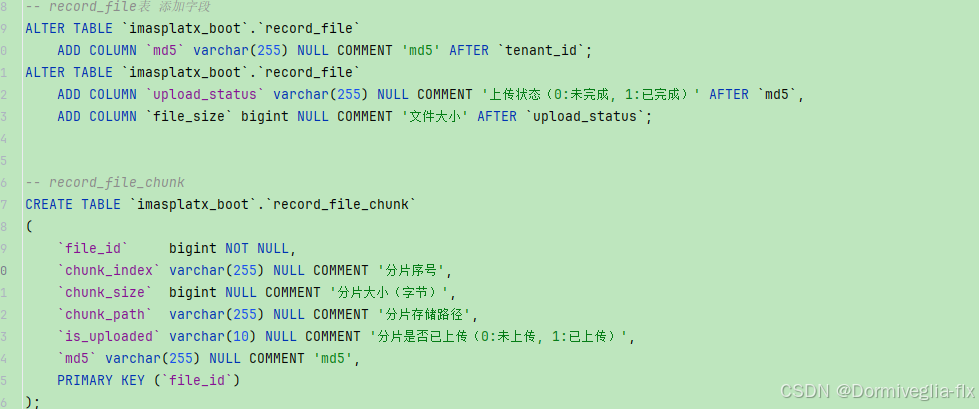
//============= 分片上传 ================@PostMapping("/check-file")public R<Boolean> checkFileExists(@RequestBody Map<String, String> request) {String fileMd5 = request.get("fileMd5");String parentId = request.get("parentId");QueryWrapper<RecordFile> q = new QueryWrapper<>();q.eq("md5",fileMd5);RecordFile recordFile = recordFileService.getOne(q);if (recordFile != null && Objects.equals(recordFile.getUploadStatus(), "1")) {// 文件已存在且已完成上传if(Long.parseLong(parentId)!=recordFile.getParentId()){RecordFile recordFile1 = new RecordFile();recordFile1.setName(recordFile.getName());recordFile1.setParentId(Long.parseLong(parentId));recordFile1.setPath(recordFile.getPath());recordFile1.setType("file");recordFile1.setFileType("upload");recordFile1.setUploadStatus("1");recordFileService.save(recordFile1);}return R.ok(Boolean.TRUE);}// 如果文件不存在,则创建新的文件记录,并设置初始状态为未完成if (recordFile == null) {recordFile = new RecordFile();recordFile.setMd5(fileMd5);recordFile.setUploadStatus("0"); // 设置初始状态为未完成recordFileService.save(recordFile);}// 文件不存在或未完成上传return R.ok(Boolean.FALSE);}@PostMapping("/get-uploaded-chunks")public R<List<String>> getUploadedChunks(@RequestBody Map<String, String> request) {String md5 = request.get("md5");QueryWrapper<RecordFileChunk> q = new QueryWrapper<>();q.eq("md5",md5);List<RecordFileChunk> chunks = recordFileChunkService.list(q);List<String> uploadedChunkIndexes = chunks.stream().filter(chunk -> Objects.equals(chunk.getIsUploaded(), "1")).map(RecordFileChunk::getChunkIndex).collect(Collectors.toList());return R.ok(uploadedChunkIndexes);}@PostMapping("/upload-chunk")public R uploadChunk(@RequestPart("dto") RecordFileChunk recordFileChunk, @RequestPart(name = "chunkFile")MultipartFile file) {if(file!=null){R r = sysFileService.uploadFile222(file);RecordFileChunk myRecordFileChunk = new RecordFileChunk();myRecordFileChunk.setChunkPath((((Map<String, String>)r.getData()).get("url")));myRecordFileChunk.setChunkSize(file.getSize());myRecordFileChunk.setChunkIndex(recordFileChunk.getChunkIndex());myRecordFileChunk.setMd5(recordFileChunk.getMd5());myRecordFileChunk.setIsUploaded("1");R.ok(recordFileChunkService.save(myRecordFileChunk));return R.ok(Boolean.TRUE);}else {return R.ok(Boolean.FALSE);}}@PostMapping("/merge-chunks")public R mergeChunk(@RequestBody Map<String, String> request) {String md5 = request.get("md5");String fileType = request.get("fileType");String parentId = request.get("parentId");String myName = request.get("name");QueryWrapper<RecordFileChunk> q = new QueryWrapper<>();q.eq("md5",md5);List<RecordFileChunk> chunks = recordFileChunkService.list(q);List<RecordFileChunk> sortchunks = chunks.stream().sorted(Comparator.comparingInt(o -> Integer.parseInt(o.getChunkIndex()))).collect(Collectors.toList());String fileName = IdUtil.simpleUUID() + StrUtil.DOT + fileType;String filePath = String.format("/admin/sys-file/%s/%s", properties.getBucketName(), fileName);String var10000 = this.properties.getLocal().getBasePath();String dir = var10000 + FileUtil.FILE_SEPARATOR + properties.getBucketName();String MyUrl = dir + FileUtil.FILE_SEPARATOR + fileName;try (FileOutputStream fos = new FileOutputStream(MyUrl)) {// 遍历每个分片路径for (RecordFileChunk chunkPath : sortchunks) {try (FileInputStream fis = new FileInputStream(chunkPath.getChunkPath())) {// 缓冲区大小byte[] buffer = new byte[1024];int length;while ((length = fis.read(buffer)) > 0) {// 将分片内容写入目标文件fos.write(buffer, 0, length);}}}System.out.println("文件合并完成!");} catch (IOException e) {e.printStackTrace();throw new RuntimeException("文件合并失败!", e);}QueryWrapper<RecordFile> q22 = new QueryWrapper<>();q22.eq("md5",md5);RecordFile fileInfo = recordFileService.getOne(q22);if (fileInfo != null) {fileInfo.setUploadStatus("1"); // 更新文件状态为已完成fileInfo.setPath(filePath);fileInfo.setType("file");fileInfo.setFileType("upload");fileInfo.setParentId(Long.valueOf(parentId));fileInfo.setName(myName);recordFileService.saveOrUpdate(fileInfo);}return R.ok();}
相关文章:
大文件上传源码,支持单个大文件与多个大文件
大文件上传源码,支持单个大文件与多个大文件 Ⅰ 思路Ⅱ 具体代码前端--单个大文件前端--多个大文件前端接口后端 Ⅰ 思路 具体思路请参考我之前的文章,这里分享的是上传流程与源码 https://blog.csdn.net/sugerfle/article/details/130829022 Ⅱ 具体代码…...

C语言--插入排序
插入排序:简单而高效的排序算法 在计算机科学中,排序是一种常见的操作,用于将一组数据按照特定的顺序排列。插入排序(Insertion Sort)是一种简单直观的排序算法,它的工作原理类似于我们整理扑克牌的过程。…...

L2-024 部落 #GPLT,并查集 C++
文章目录 题目解读输入格式输出格式 思路Ac Code参考 题目解读 我们认为朋友的朋友都算在一个部落里,于是要请你统计一下,在一个给定社区中,到底有多少个互不相交的部落?并且检查任意两个人是否属于同一个部落。 输入格式 第一…...
:axios有哪些常用的方法)
前端面试题(三):axios有哪些常用的方法
Axios 是一个基于 Promise 的 HTTP 客户端,用于浏览器和 Node.js 中发送 HTTP 请求。它提供了一些常用的方法来处理不同类型的请求。以下是 Axios 中常用的一些方法: 1. axios.get() 用于发送 GET 请求,从服务器获取数据。 axios.get(/api/d…...
)
JSON 基础知识(一)
第一部分:JSON 基础知识 📢 快速掌握 JSON!文章 视频双管齐下 🚀 如果你觉得阅读文章太慢,或者更喜欢 边看边学 的方式,不妨直接观看我录制的 JSON 课程视频!🎬 视频里会用更直观…...
)
SSM框架学习(Day-1)
1.spring系统架构 自底而上进行,上层依赖于下层,首先最底层是Core Container -- 核心容器, 再往上是AOP(面向切面编程)和Aspects(AOP)思想的实现, 我个人的理解是, 它可以在不惊动你原始程序的基础上, 给它增强功能,类似于反射;再往上是数据访问层。 C…...

使用 PyTorch 的 `GradualWarmupScheduler` 实现学习率预热
使用 PyTorch 的 GradualWarmupScheduler 实现学习率预热 在深度学习中,学习率(Learning Rate, LR)是影响模型训练效果的关键超参数之一。为了提升模型的收敛速度和稳定性,学习率调度策略变得尤为重要。其中,学习率预热(Learning Rate Warmup) 是一种常用的策略,它通过…...
 和 ZSet(例如排行榜) 的详细对比,涵盖定义、特性、命令、适用场景及总结表格)
Redis 中 Set(例如标签) 和 ZSet(例如排行榜) 的详细对比,涵盖定义、特性、命令、适用场景及总结表格
以下是 Redis 中 Set 和 ZSet 的详细对比,涵盖定义、特性、命令、适用场景及总结表格: 1. 核心定义 数据类型SetZSet(Sorted Set)定义无序的、唯一的字符串集合,元素不重复。有序的、唯一的字符串集合,每个…...

在线记事本——支持Markdown
项目地址 https://github.com/Anyuersuper/CloudNotebook 百度网盘 通过网盘分享的文件:CloudNotebook-master.zip 链接: https://pan.baidu.com/s/1_Y--aBzNkKiFRIMHYmwPdA?pwdyuer 提取码: yuer 📝 云笔记 (Cloud Notebook) 云笔记是一个简洁、安全…...

C# 中充血模型和贫血模型
在C#中,充血模型(Rich Domain Model)和贫血模型(Anemic Domain Model)是两种截然不同的领域建模方式,核心区别在于业务逻辑的归属。以下是通俗易懂的解释: 1. 贫血模型ÿ…...

Java技术生态前沿洞察:虚拟线程引领并发革命,框架创新赋能云原生时代
Java技术生态正迎来新一轮变革浪潮。虚拟线程的落地成为高并发编程范式转折点,其极低资源开销特性在电商秒杀场景中展现出3倍吞吐量提升,彻底改写传统线程模型性能边界。Spring Boot 3.2原生支持虚拟线程,结合Observation API与HTTP客户端优化…...

Day2:前端项目uniapp壁纸实战
先来做一个轮番图。 效果如下: common-style.css view,swiper,swiper-item{box-sizing: border-box; } index.vue <template><view class"homeLayout"><view class"banner"><swiper circular indicator-dots autoplay…...

人工智能赋能工业制造:智能制造的未来之路
一、引言 随着人工智能技术的飞速发展,其应用场景不断拓展,从消费电子到医疗健康,从金融科技到交通运输,几乎涵盖了所有行业。而工业制造作为国民经济的支柱产业,也在人工智能的浪潮中迎来了深刻的变革。智能制造&…...

V-SHOW和箭头函数在VUE项目的踩坑点
v-show和v-if v-show控制显示隐藏是通过控制CSS的display决定dom节点的显示和隐藏。v-if通过控制dom节点的渲染与否实现元素的显示和隐藏。 在vue中,template标签不参与页面渲染,也不会破坏代码的层级结构,所以多和v-if结合控制元素的显示隐…...

LeetCode Hot100 刷题笔记(3)—— 链表
目录 前言 1. 相交链表 2. 反转链表 3. 回文链表 4. 环形链表 5. 环形链表 II 6. 合并两个有序链表 7. 两数相加 8. 删除链表的倒数第 N 个结点 9. 两两交换链表中的节点 10. K 个一组翻转链表 11. 随机链表的复制 12. 排序链表 13. 合并 K 个升序链表 14. LRU 缓存 前言 一、…...

Spring 概念
Spring 是一个功能强大、灵活且广泛使用的 Java 企业级开发框架,它诞生于 2003 年,由 Rod Johnson 创建,初衷是简化 Java EE 的开发过程。 一、Spring 是什么? 简单来说: Spring 是一个轻量级的 Java 开发框架&#…...
状态机思想编程
1. LED流水灯的FPGA代码 在这个任务中,首先我们会使用状态机的思想来设计一个LED流水灯的控制逻辑。LED流水灯一般需要依次点亮不同的LED,并且循环播放。我们将其分为几个状态,每个状态控制一个或一组LED灯。 状态机设计 假设我们有8个LED…...

第二十八章:Python可视化图表扩展-和弦图、旭日图、六边形箱图、桑基图和主题流图
一、引言 在数据可视化领域,除了常见的折线图、柱状图和散点图,还有一些高级图表类型可以帮助我们更直观地展示复杂数据关系。本文将介绍五种扩展图表:和弦图、旭日图、六边形箱图、桑基图和主题流图。这些图表在展示数据关系、层次结构和流量…...

基于vue框架的重庆美食网站的设计与实现kt945(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,美食分类,美食菜品 开题报告内容 基于Vue框架的重庆美食网站的设计与实现开题报告 一、选题背景与意义 (一)选题背景 重庆,作为中国西南地区的璀璨明珠,以其独特的地理位置和丰富…...

Metal学习笔记十三:阴影
在本章中,您将了解阴影。阴影表示表面上没有光。当另一个表面或对象使对象与光线相遮挡时,您会看到对象上的阴影。在项目中添加阴影可使您的场景看起来更逼真,并提供深度感。 阴影贴图 阴影贴图是包含场景阴影信息的纹理。当光线照射到物体…...
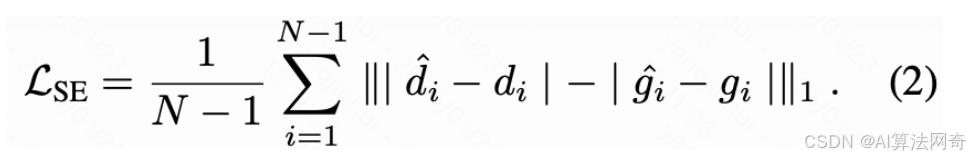
时间梯度匹配损失 TGMLoss
目录 时间梯度匹配损失(Temporal Gradient Matching Loss, TGM Loss) 完整示例,该损失函数常用于视频预测、运动平滑等任务,通过约束预测序列的时间梯度与真实序列一致来提升时序连续性 训练测试demo代码: 时间梯度匹配损失(Temporal Gradient Matching Loss, TGM Los…...

iPhone XR:一代神机,止步于此
什么样的 iPhone ,才配称为一代神机? 我曾经用过iPhone 4S、iPhone 6S Plus、iPhone 8 Plus,iPhone SE2、iPhone XR、iPhone 13、iPhone 14 Plus、iPhone 15/Pro。 不管硬件再怎么卷,不管囊中是否羞涩,主力机基本没考…...

第十四届蓝桥杯省赛真题解析(含C++详细源码)
第十四届蓝桥杯省赛 整数删除满分思路及代码solution1 (40% 双指针暴力枚举)solution 2(优先队列模拟链表 AC) 冶炼金属满分代码及思路 子串简写满分思路及代码solution 1(60% 双指针)solution 2࿰…...

OpenAI即将开源!DeepSeek“逼宫”下,AI争夺战将走向何方?
OpenAI 终于要 Open 了。 北京时间 4 月 1 日凌晨,OpenAI 正式宣布:将在未来几个月内开源一款具备推理能力的语言模型,并开放训练权重参数。这是自 2019 年 GPT-2 部分开源以来,OpenAI 首次向公众开放核心模型技术。 【图片来源于…...

mysql 8.0.27-docker
安装 可以略过本步 https://dev.mysql.com/downloads/https://dev.mysql.com/downloads/ 镜像查询与安装 先查询: docker search mysql 明显会报错 Error response from daemon: Get "https://index.docker.io/v1/search?qmysql&n25": dial tcp…...
使用NVM下载Node.js管理多版本
提示:我解决这个bug跟别人思路可能不太一样,因为我是之前好用,换个项目就不好使了,倦了 文章目录 前言项目场景一项目场景二解决方案:下载 nvm安装 nvm重新下载所需Node 版本nvm常用命令 项目结构说明 前言 提示&…...

交易引擎中的设计模式
在WtHftEngine.cpp中,主要运用了以下几种设计模式,结合代码结构具体分析如下: 1. 观察者模式(Observer Pattern) 核心应用场景:实时市场数据的分发机制 代码体现: // 行情到达时分发给订阅…...
WebSocket创建流程)
(自用)WebSocket创建流程
在Spring Boot项目中新建WebSocket服务,可以按照以下详细步骤进行操作: 1.创建Spring Boot项目 可以通过Spring Initializr(<>)快速创建一个新的Spring Boot项目,添加Spring Web和Spring Boot DevTools依赖&…...
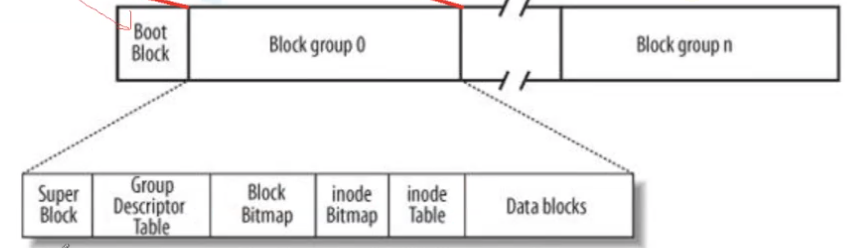
Linux——文件(2)文件系统
我们知道,文件在没有被打开时是放在磁盘中的,通常我们未打开的文件数量要远远大于打开的文件数量,而且我们要想打开一个文件,首先需要知道文件在磁盘的位置才能打开,但问题是,面对磁盘中成百上千个文件&…...

蓝桥杯 web 水果拼盘 (css3)
做题步骤: 看结构:html 、css 、f12 分析: f12 查看元素,你会发现水果的高度刚好和拼盘的高度一样,每一种水果的盘子刚好把页面填满了,所以咱们就只要让元素竖着排列,加上是竖着,排不下的换行…...