从代码学习深度学习 - NLP之文本预处理 PyTorch版
文章目录
- 前言
- 1. 文本预处理理论知识
- 1.1 文本清洗与标准化
- 1.2 分词(Tokenization)
- 1.3 词频统计与词汇表构建
- 1.4 序列表示与批次生成
- 1.5 预处理的意义
- 2. 文本预处理的核心代码解析
- 2.1 读取数据集:`read_time_machine`
- 2.2 分词处理:`tokenize`
- 2.3 词频统计:`count_corpus`
- 2.4 构建词表:`Vocab` 类
- 2.5 加载语料库:`load_corpus_time_machine`
- 2.6 随机采样生成批次:`seq_data_iter_random`
- 2.7 顺序分区生成批次:`seq_data_iter_sequential`
- 2.8 数据加载器:`SeqDataLoader` 类
- 2.9 数据加载接口:`load_data_time_machine`
- 2.10 测试代码与验证
- 总结
前言
在自然语言处理(NLP)中,文本预处理是构建深度学习模型的第一步。无论是语言模型还是文本分类任务,我们都需要将原始文本转化为模型可以理解的数值形式。PyTorch 作为一个强大的深度学习框架,提供了灵活的工具来实现这一过程。本文将通过一个完整的代码示例,带你从零开始理解 NLP 中的文本预处理流程。我们将以《时间机器》(The Time Machine)数据集为例,逐步解析如何读取文本、分词、构建词表、生成训练数据批次等关键步骤。所有代码都基于 PyTorch,并配有详细的测试验证。
通过这篇博客,你将学会如何将理论转化为实践,并掌握文本预处理的核心技术。让我们开始吧!
1. 文本预处理理论知识
在自然语言处理(NLP)中,文本预处理是将原始文本转化为机器可理解的数值形式的关键步骤。自然语言具有高度的复杂性和多样性,包括词汇的歧义、句法的变化以及语义的上下文依赖性。因此,文本预处理的理论基础旨在解决这些挑战,为深度学习模型提供结构化、高质量的输入数据。以下是文本预处理的核心理论概念:
1.1 文本清洗与标准化
原始文本通常包含噪声,例如标点符号、大小写不一致、特殊字符甚至拼写错误。文本清洗的目标是去除这些无关信息,保留语义核心内容。例如,将所有字符转换为小写可以消除大小写带来的冗余,而移除非字母字符(如数字或标点)则能简化后续处理。这种标准化过程确保模型专注于语言的本质,而非格式上的差异。
1.2 分词(Tokenization)
分词是将连续的文本拆分为离散单元(词元)的过程。词元可以是单词、字符甚至子词单元(如词根或词缀),具体选择取决于任务需求。单词级分词适用于大多数任务,因为它直接对应人类语言的基本单位,但可能面临词汇表过大或未登录词(OOV, Out-Of-Vocabulary)的问题。字符级分词则更细粒度,能有效减少词汇表大小并处理未见词,但会增加序列长度和计算复杂度。分词的理论意义在于将连续的自然语言转化为离散的符号序列,为后续的数值化奠定基础。
1.3 词频统计与词汇表构建
自然语言中,词元的出现频率遵循幂律分布(如 Zipf 定律),即少量高频词占据大部分语料,而大量低频词出现次数极少。词频统计的目的是量化这种分布,为词汇表构建提供依据。词汇表是词元到索引的映射,通常会过滤掉低频词以控制模型复杂度,同时引入特殊词元(如 <unk> 表示未知词)处理未见词。这种方法在理论上平衡了表示能力与计算效率,是词嵌入和语言模型的基础。
1.4 序列表示与批次生成
深度学习模型通常以固定长度的数值序列作为输入,而文本长度往往不一。序列表示的目标是将词元序列转化为索引序列,并通过截断或填充统一长度。批次生成则进一步将长序列分割为小批量数据,供模型分步训练。理论上,批次生成有两种策略:随机采样和顺序分区。随机采样通过打乱数据顺序增强模型的鲁棒性,适合捕捉全局模式;顺序分区则保留序列的连续性,更适合学习局部依赖关系(如语言模型中的上下文预测)。这两种方法的选择取决于任务目标和模型架构。
1.5 预处理的意义
文本预处理的理论核心在于将非结构化的自然语言转化为结构化的数值数据,同时尽量保留语义信息。它不仅是技术实现的第一步,也是连接人类语言与机器计算的桥梁。通过清洗、分词、构建词表和生成批次,我们将复杂的语言现象简化为可计算的数学问题,为后续的神经网络训练提供了坚实基础。
2. 文本预处理的核心代码解析
2.1 读取数据集:read_time_machine
文本预处理的第一步是从文件中读取数据。以下函数 read_time_machine 将《时间机器》数据集加载为文本行列表,并进行初步清洗:
def read_time_machine():"""将时间机器数据集加载到文本行的列表中"""with open('timemachine.txt', 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
这个函数的工作原理很简单:
- 使用
open读取timemachine.txt文件的每一行。 - 对每行文本使用正则表达式
re.sub('[^A-Za-z]+', ' ', line),将所有非字母字符替换为空格。 - 通过
strip()去除首尾多余空格,并用lower()将文本转换为小写。
例如,如果文件内容为:
The Time Machine
By H.G. Wells
输出将是:
['the time machine', 'by h g wells']
2.2 分词处理:tokenize
读取文本后,我们需要将其拆分为词元(token),可以是单词或字符。tokenize 函数提供了两种分词方式:
def tokenize(lines, token='word'):"""将文本行拆分为单词或字符词元"""if token == 'word':return [line.split() for line in lines]elif token == 'char':return [list(line) for line in lines]else:print(f'错误:未知词元类型:{token}')
- 当
token='word'时,按空格将每行拆分为单词列表。例如,'the time machine'变为['the', 'time', 'machine']。 - 当
token='char'时,将每行拆分为字符列表。例如,'the'变为['t', 'h', 'e']。 - 如果传入未知类型,会提示错误。
2.3 词频统计:count_corpus
为了构建词表,我们需要统计每个词元的出现频率。count_corpus 函数实现了这一功能:
def count_corpus(tokens):"""统计词元的频率"""if not tokens:return Counter()if isinstance(tokens[0], list):flattened_tokens = [token for sublist in tokens for token in sublist]else:flattened_tokens = tokensreturn Counter(flattened_tokens)
- 输入可以是一维列表(如
['a', 'b'])或二维列表(如[['a', 'b'], ['c']])。 - 如果是二维列表,会先展平为一维列表。
- 使用
Counter对象统计每个词元的频率。例如,[['the', 'time'], ['the']]输出Counter({'the': 2, 'time': 1})。
2.4 构建词表:Vocab 类
Vocab 类是文本预处理的核心,用于将词元映射为索引:
class Vocab:"""文本词表类,用于管理词元及其索引的映射关系"""def 相关文章:

从代码学习深度学习 - NLP之文本预处理 PyTorch版
文章目录 前言1. 文本预处理理论知识1.1 文本清洗与标准化1.2 分词(Tokenization)1.3 词频统计与词汇表构建1.4 序列表示与批次生成1.5 预处理的意义2. 文本预处理的核心代码解析2.1 读取数据集:`read_time_machine`2.2 分词处理:`tokenize`2.3 词频统计:`count_corpus`2.…...
WebRTC技术简介及应用场景
写在前面 本文是参考稀土掘金的文章,整理得出,版权归原作者所有!参考链接请点击跳转 WebRTC(Web Real-Time Communication) 是一项开源技术,允许浏览器和移动应用直接进行实时音视频通信和数据传输,无需安装插件或第三方软件。它…...

介绍几种创意登录页(含完整源码)
今天为大家收集了几种不同风格的登录页,搭配动态渐变背景,效果绝对惊艳! CSS3实现动态渐变玻璃拟态登录页 一、开篇语 纯CSS实现当下最火的玻璃拟态(Morphism)风格登录页,搭配动态渐变背景,效果绝对惊艳! …...

git分布式控制工具详解
1. 版本控制器的方式 1.1 集中式版本控制工具 特点: 版本库集中存放在中央服务器必须联网才能工作(局域网/互联网)个人修改后提交到中央版本库 举例:SVN、CVS 1.2 分布式版本控制工具 特点: 无"中央服务器&qu…...
Uni-app入门到精通:uni-app的基础组件
1、view view是容器组件,类似于HTML中的<div></div>标签,用于包裹各种元素内容,是页面布局常用的组件。view组件的属性如下 属性类型默认值说明hover-classStringnone指定按下去的样式类。当hover-class"none"时&…...

R语言从专家到小白
文章目录 下载安装R下载安装R StudioCRAN 下载安装R Index of /bin https://cran.r-project.org/ 下载安装R Studio https://posit.co/download/rstudio-desktop/ CRAN R综合档案网络。 CRAN 镜像是一个提供 R 语言软件和包的在线服务,用户可以从不同的地区选择…...

显示器工艺简介
华星光电显示器的生产工艺流程介绍,从入厂原料到生产出显示器的整体工艺介绍 华星光电显示器的生产工艺流程主要包括以下几个阶段,从原材料入厂到最终显示器的生产: 原材料准备 玻璃基板:显示器的核心材料,通常采用超…...
大文件上传源码,支持单个大文件与多个大文件
大文件上传源码,支持单个大文件与多个大文件 Ⅰ 思路Ⅱ 具体代码前端--单个大文件前端--多个大文件前端接口后端 Ⅰ 思路 具体思路请参考我之前的文章,这里分享的是上传流程与源码 https://blog.csdn.net/sugerfle/article/details/130829022 Ⅱ 具体代码…...

C语言--插入排序
插入排序:简单而高效的排序算法 在计算机科学中,排序是一种常见的操作,用于将一组数据按照特定的顺序排列。插入排序(Insertion Sort)是一种简单直观的排序算法,它的工作原理类似于我们整理扑克牌的过程。…...

L2-024 部落 #GPLT,并查集 C++
文章目录 题目解读输入格式输出格式 思路Ac Code参考 题目解读 我们认为朋友的朋友都算在一个部落里,于是要请你统计一下,在一个给定社区中,到底有多少个互不相交的部落?并且检查任意两个人是否属于同一个部落。 输入格式 第一…...
:axios有哪些常用的方法)
前端面试题(三):axios有哪些常用的方法
Axios 是一个基于 Promise 的 HTTP 客户端,用于浏览器和 Node.js 中发送 HTTP 请求。它提供了一些常用的方法来处理不同类型的请求。以下是 Axios 中常用的一些方法: 1. axios.get() 用于发送 GET 请求,从服务器获取数据。 axios.get(/api/d…...
)
JSON 基础知识(一)
第一部分:JSON 基础知识 📢 快速掌握 JSON!文章 视频双管齐下 🚀 如果你觉得阅读文章太慢,或者更喜欢 边看边学 的方式,不妨直接观看我录制的 JSON 课程视频!🎬 视频里会用更直观…...
)
SSM框架学习(Day-1)
1.spring系统架构 自底而上进行,上层依赖于下层,首先最底层是Core Container -- 核心容器, 再往上是AOP(面向切面编程)和Aspects(AOP)思想的实现, 我个人的理解是, 它可以在不惊动你原始程序的基础上, 给它增强功能,类似于反射;再往上是数据访问层。 C…...

使用 PyTorch 的 `GradualWarmupScheduler` 实现学习率预热
使用 PyTorch 的 GradualWarmupScheduler 实现学习率预热 在深度学习中,学习率(Learning Rate, LR)是影响模型训练效果的关键超参数之一。为了提升模型的收敛速度和稳定性,学习率调度策略变得尤为重要。其中,学习率预热(Learning Rate Warmup) 是一种常用的策略,它通过…...
 和 ZSet(例如排行榜) 的详细对比,涵盖定义、特性、命令、适用场景及总结表格)
Redis 中 Set(例如标签) 和 ZSet(例如排行榜) 的详细对比,涵盖定义、特性、命令、适用场景及总结表格
以下是 Redis 中 Set 和 ZSet 的详细对比,涵盖定义、特性、命令、适用场景及总结表格: 1. 核心定义 数据类型SetZSet(Sorted Set)定义无序的、唯一的字符串集合,元素不重复。有序的、唯一的字符串集合,每个…...

在线记事本——支持Markdown
项目地址 https://github.com/Anyuersuper/CloudNotebook 百度网盘 通过网盘分享的文件:CloudNotebook-master.zip 链接: https://pan.baidu.com/s/1_Y--aBzNkKiFRIMHYmwPdA?pwdyuer 提取码: yuer 📝 云笔记 (Cloud Notebook) 云笔记是一个简洁、安全…...

C# 中充血模型和贫血模型
在C#中,充血模型(Rich Domain Model)和贫血模型(Anemic Domain Model)是两种截然不同的领域建模方式,核心区别在于业务逻辑的归属。以下是通俗易懂的解释: 1. 贫血模型ÿ…...

Java技术生态前沿洞察:虚拟线程引领并发革命,框架创新赋能云原生时代
Java技术生态正迎来新一轮变革浪潮。虚拟线程的落地成为高并发编程范式转折点,其极低资源开销特性在电商秒杀场景中展现出3倍吞吐量提升,彻底改写传统线程模型性能边界。Spring Boot 3.2原生支持虚拟线程,结合Observation API与HTTP客户端优化…...

Day2:前端项目uniapp壁纸实战
先来做一个轮番图。 效果如下: common-style.css view,swiper,swiper-item{box-sizing: border-box; } index.vue <template><view class"homeLayout"><view class"banner"><swiper circular indicator-dots autoplay…...

人工智能赋能工业制造:智能制造的未来之路
一、引言 随着人工智能技术的飞速发展,其应用场景不断拓展,从消费电子到医疗健康,从金融科技到交通运输,几乎涵盖了所有行业。而工业制造作为国民经济的支柱产业,也在人工智能的浪潮中迎来了深刻的变革。智能制造&…...

V-SHOW和箭头函数在VUE项目的踩坑点
v-show和v-if v-show控制显示隐藏是通过控制CSS的display决定dom节点的显示和隐藏。v-if通过控制dom节点的渲染与否实现元素的显示和隐藏。 在vue中,template标签不参与页面渲染,也不会破坏代码的层级结构,所以多和v-if结合控制元素的显示隐…...

LeetCode Hot100 刷题笔记(3)—— 链表
目录 前言 1. 相交链表 2. 反转链表 3. 回文链表 4. 环形链表 5. 环形链表 II 6. 合并两个有序链表 7. 两数相加 8. 删除链表的倒数第 N 个结点 9. 两两交换链表中的节点 10. K 个一组翻转链表 11. 随机链表的复制 12. 排序链表 13. 合并 K 个升序链表 14. LRU 缓存 前言 一、…...

Spring 概念
Spring 是一个功能强大、灵活且广泛使用的 Java 企业级开发框架,它诞生于 2003 年,由 Rod Johnson 创建,初衷是简化 Java EE 的开发过程。 一、Spring 是什么? 简单来说: Spring 是一个轻量级的 Java 开发框架&#…...
状态机思想编程
1. LED流水灯的FPGA代码 在这个任务中,首先我们会使用状态机的思想来设计一个LED流水灯的控制逻辑。LED流水灯一般需要依次点亮不同的LED,并且循环播放。我们将其分为几个状态,每个状态控制一个或一组LED灯。 状态机设计 假设我们有8个LED…...

第二十八章:Python可视化图表扩展-和弦图、旭日图、六边形箱图、桑基图和主题流图
一、引言 在数据可视化领域,除了常见的折线图、柱状图和散点图,还有一些高级图表类型可以帮助我们更直观地展示复杂数据关系。本文将介绍五种扩展图表:和弦图、旭日图、六边形箱图、桑基图和主题流图。这些图表在展示数据关系、层次结构和流量…...

基于vue框架的重庆美食网站的设计与实现kt945(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,美食分类,美食菜品 开题报告内容 基于Vue框架的重庆美食网站的设计与实现开题报告 一、选题背景与意义 (一)选题背景 重庆,作为中国西南地区的璀璨明珠,以其独特的地理位置和丰富…...

Metal学习笔记十三:阴影
在本章中,您将了解阴影。阴影表示表面上没有光。当另一个表面或对象使对象与光线相遮挡时,您会看到对象上的阴影。在项目中添加阴影可使您的场景看起来更逼真,并提供深度感。 阴影贴图 阴影贴图是包含场景阴影信息的纹理。当光线照射到物体…...
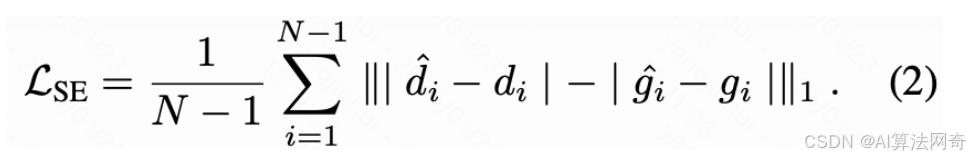
时间梯度匹配损失 TGMLoss
目录 时间梯度匹配损失(Temporal Gradient Matching Loss, TGM Loss) 完整示例,该损失函数常用于视频预测、运动平滑等任务,通过约束预测序列的时间梯度与真实序列一致来提升时序连续性 训练测试demo代码: 时间梯度匹配损失(Temporal Gradient Matching Loss, TGM Los…...

iPhone XR:一代神机,止步于此
什么样的 iPhone ,才配称为一代神机? 我曾经用过iPhone 4S、iPhone 6S Plus、iPhone 8 Plus,iPhone SE2、iPhone XR、iPhone 13、iPhone 14 Plus、iPhone 15/Pro。 不管硬件再怎么卷,不管囊中是否羞涩,主力机基本没考…...

第十四届蓝桥杯省赛真题解析(含C++详细源码)
第十四届蓝桥杯省赛 整数删除满分思路及代码solution1 (40% 双指针暴力枚举)solution 2(优先队列模拟链表 AC) 冶炼金属满分代码及思路 子串简写满分思路及代码solution 1(60% 双指针)solution 2࿰…...