Transformers without Normalization论文翻译
论文信息:
作者:Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, Zhuang Liu
论文地址:arxiv.org/pdf/2503.10622
代码仓库:jiachenzhu/DyT: Code release for DynamicTanh (DyT)
摘要
归一化层在现代神经网络中无处不在,长期以来被认为是不可或缺的。本文证明,通过一种极其简单的技术,无归一化的Transformer可以达到相同或更好的性能。我们提出动态双曲正切(DyT),一种元素级操作DyT(x) = tanh(αx) ),作为Transformer中归一化层的直接替代。DyT的灵感源于观察到Transformer中的层归一化(Layer Norm)通常会产生类似双曲正切的S型输入-输出映射。通过整合DyT,无归一化的Transformer可以匹配或超越其归一化对应模型的性能,且大多无需超参数调优。我们在从识别到生成、监督到自监督学习、计算机视觉到语言模型的多样化场景中验证了DyT的有效性。这些发现挑战了归一化层在现代神经网络中不可或缺的传统认知,并为其在深度网络中的作用提供了新见解。
1. 引言
在过去十年中,归一化层已成为现代神经网络最基础的组件之一。其起源可追溯至2015年批量归一化(Batch Normalization, BN)的提出(Ioffe & Szegedy, 2015),该技术显著加速了视觉识别模型的收敛并提升了性能,并在随后几年迅速普及。此后,针对不同网络架构或领域提出了许多归一化变体(Ba et al., 2016; Ulyanov et al., 2016; Wu & He, 2018; Zhang & Sennrich, 2019)。如今,几乎所有现代网络都使用归一化层,其中层归一化(Layer Norm, LN)(Ba et al., 2016)尤其流行,特别是在主流的Transformer架构中(Vaswani et al., 2017; Dosovitskiy et al., 2020)。
归一化层的广泛应用主要得益于其在优化中的实证优势(Santurkar et al., 2018; Bjorck et al., 2018)。除了提升性能外,它们还能加速和稳定训练过程。随着神经网络变得更宽更深,这种必要性愈发关键(Brock et al., 2021a; Huang et al., 2023)。因此,归一化层被广泛视为深度网络有效训练的关键(即使不是必需)。近年来,新架构常试图替换注意力或卷积层(Tolstikhin et al., 2021; Gu & Dao, 2023; Sun et al., 2024; Feng et al., 2024),但几乎总是保留归一化层,这一现象微妙地印证了这一观点。
本文通过为Transformer引入归一化层的简单替代方案挑战了这一观点。我们的探索始于观察:LN层将输入映射为类似双曲正切的S型曲线,缩放输入激活同时压缩极值。受此启发,我们提出动态双曲正切(DyT)操作,定义为: ,其中α是可学习参数。该操作通过α学习适当的缩放因子,并利用有界双曲正切函数压缩极值,从而模拟LN的行为。值得注意的是,与归一化层不同,DyT无需计算激活统计量即可实现这两种效果。
DyT的集成非常简单,如图1所示:在视觉和语言Transformer等架构中,我们直接用DyT替换现有的归一化层。实验表明,使用DyT的模型在广泛场景中能够稳定训练并达到高性能,且通常无需调整原始架构的训练超参数。我们的工作挑战了归一化层是现代神经网络训练必需组件的观点,并为归一化层的性质提供了实证见解。此外,初步测量表明DyT可提升训练和推理速度,使其成为面向效率的网络设计候选。
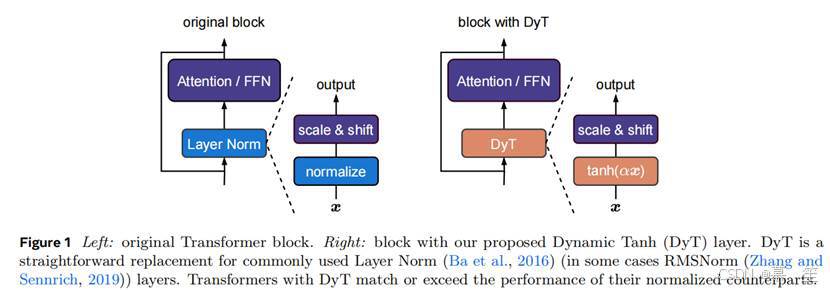
图 1 左:原始 Transformer 块。右:包含我们提出的动态双曲正切(DyT)层的块。DyT 是常用层归一化(Layer Norm)(Ba 等人,2016)(某些情况下为均方根归一化(RMSNorm)(Zhang 和 Sennrich,2019))的直接替代。使用 DyT 的 Transformer 模型可匹配或超越其归一化对应模型的性能。
2. 背景:归一化层
我们首先回顾归一化层。大多数归一化层共享通用公式。给定形状为(B, T, C)的输入x(其中B为批量大小,T为序列长度,C为嵌入维度),输出通常计算为:

其中ε是小常数,γ和β是形状为(C,)的可学习向量参数,作为“缩放”和“偏移”仿射参数,允许输出处于任意范围。μ和σ2分别表示输入的均值和方差。不同方法的主要区别在于这两个统计量的计算方式,导致μ和σ2的维度不同,计算时会应用广播机制。
批量归一化(BN)(Ioffe & Szegedy, 2015)是首个现代归一化层,主要用于卷积神经网络(ConvNet)(Szegedy et al., 2016; He et al., 2016; Xie et al., 2017)。其提出是深度学习架构设计的重要里程碑。BN在批量和序列维度上计算均值和方差,具体为:
 。ConvNet中流行的其他归一化层,如组归一化(Group Norm)(Wu & He, 2018)和实例归一化(Instance Norm)(Ulyanov et al., 2016),最初是为目标检测和图像风格化等特定任务提出的。它们共享相同的总体公式,但统计量计算的轴和范围不同。
。ConvNet中流行的其他归一化层,如组归一化(Group Norm)(Wu & He, 2018)和实例归一化(Instance Norm)(Ulyanov et al., 2016),最初是为目标检测和图像风格化等特定任务提出的。它们共享相同的总体公式,但统计量计算的轴和范围不同。
层归一化(LN)(Ba et al., 2016)和均方根归一化(RMSNorm)(Zhang & Sennrich, 2019)是Transformer架构中使用的两种主要归一化层。LN对每个样本的每个序列元素独立计算统计量: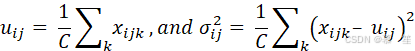 。
。
RMSNorm(Zhang & Sennrich, 2019)通过移除均值中心化步骤简化了LN,使用![]() 和
和
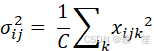 进行归一化。由于其简单性和通用性,LN目前被大多数现代神经网络采用。最近,RMSNorm在T5(Raffel et al., 2020)、LLaMA(Touvron et al., 2023a,b; Dubey et al., 2024)、Mistral(Jiang et al., 2023)、Qwen(Bai et al., 2023; Yang et al., 2024)、InternLM(Zhang et al., 2024; Cai et al., 2024)和DeepSeek(Liu et al., 2024; Guo et al., 2025)等语言模型中逐渐流行。本文研究的Transformer均使用LN,除非特别说明(如LLaMA使用RMSNorm)。
进行归一化。由于其简单性和通用性,LN目前被大多数现代神经网络采用。最近,RMSNorm在T5(Raffel et al., 2020)、LLaMA(Touvron et al., 2023a,b; Dubey et al., 2024)、Mistral(Jiang et al., 2023)、Qwen(Bai et al., 2023; Yang et al., 2024)、InternLM(Zhang et al., 2024; Cai et al., 2024)和DeepSeek(Liu et al., 2024; Guo et al., 2025)等语言模型中逐渐流行。本文研究的Transformer均使用LN,除非特别说明(如LLaMA使用RMSNorm)。
3. 归一化层的作用
分析设置:
我们首先实证研究训练网络中归一化层的行为。为此,我们选取了在ImageNet-1K(Deng et al., 2009)上训练的视觉Transformer模型(ViT-B)(Dosovitskiy et al., 2020)、在LibriSpeech(Panayotov et al., 2015)上训练的wav2vec 2.0大型Transformer模型(Baevski et al., 2020),以及在ImageNet-1K上训练的扩散Transformer(DiT-XL)(Peebles & Xie, 2023)。所有情况下,每个Transformer块和最终线性投影前均应用LN。
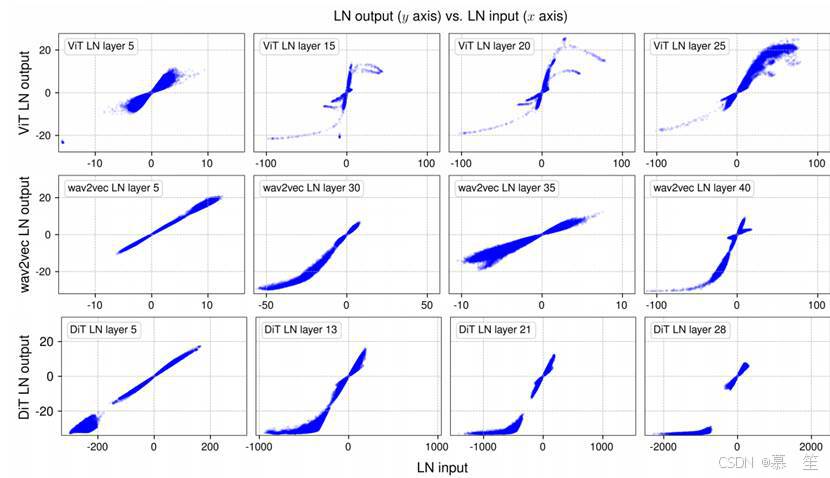
图2展示了视觉Transformer(ViT)(多索维茨基等人,2020)、wav2vec 2.0(一种用于语音处理的Transformer模型)(巴耶夫斯基等人,2020)以及扩散Transformer(DiT)(皮布尔斯和谢,2023)中选定层归一化(LN)层的输出与输入的关系。我们对一小批量样本进行采样,并绘制了每个模型中四个LN层的输入/输出值。这里的输出是指LN层进行仿射变换之前的值。这些S形曲线与双曲正切函数的曲线极为相似(见图3)。早期层中更接近线性的形状也可以用双曲正切曲线的中心部分来描述。这启发我们提出动态双曲正切(DyT)作为替代方案,通过可学习的缩放因子α来处理x轴上不同的尺度。
对于这三个训练好的网络,我们采样一个小批量样本并进行前向传播。然后测量归一化层的输入和输出(即归一化操作前的张量,以及仿射变换前的张量)。由于LN保持输入张量的维度,我们可以建立输入和输出张量元素的一一对应关系,从而直接可视化它们的关系。结果如图2所示。
层归一化的类双曲正切映射:对于所有三个模型,早期的LN层(图2的第一列)中,输入-输出关系基本呈线性,在x-y图中类似直线。然而,更深层的LN层揭示了更有趣的现象。
图2显示了视觉Transformer(ViT)、wav2vec 2.0(语音处理Transformer)和扩散Transformer(DiT)中选定层归一化(LN)层的输出与输入关系。我们采样小批量样本,绘制每个模型中四个LN层的输入/输出值(输出为LN仿射变换前的值)。S型曲线与双曲正切函数(图3)高度相似。早期层的线性形状也可由双曲正切曲线的中心部分捕获。这启发我们提出动态双曲正切(DyT)作为替代方案,通过可学习缩放因子(alpha)调整x轴的尺度。
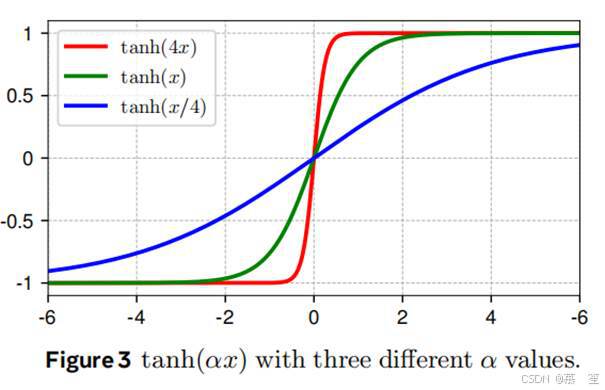
深层中一个引人注目的观察是,这些曲线的形状大多与双曲正切函数的完整或部分S型曲线高度相似(图3)。尽管LN通过减去均值和除以标准差进行线性操作,但由于每个序列元素独立归一化,整体输入张量的激活并不保持线性。然而,实际非线性变换与缩放双曲正切函数如此相似仍令人意外。
对于这种S型曲线,中心部分(x接近0的点)仍以线性为主,约99%的点落在该线性范围内。但仍有许多点明显超出此范围,即具有“极端”值(如ViT模型中x大于50或小于-50的点)。归一化层对这些值的主要作用是将其压缩到更接近大多数点的范围。这是归一化层无法用简单仿射变换层近似的原因。我们假设,这种对极值的非线性、非比例压缩效应正是归一化层重要且不可或缺的原因。
Ni等(2024)的最新研究同样强调了LN层引入的强非线性,表明其增强了模型的表示能力。此外,这种压缩行为与生物神经元对大输入的饱和特性类似,该现象约一个世纪前首次被观察到(Adrian, 1926; Adrian & Zotterman, 1926a,b)。
按序列元素和通道归一化:
为何LN层对每个序列元素进行线性变换,却能以非线性方式压缩极值?为理解这一点,我们分别按序列元素和通道对数据点进行分组可视化。图4选取了图2中ViT的第二和第三个子图,并采样部分点以更清晰展示。绘制通道时,我们确保包含具有极值的通道。
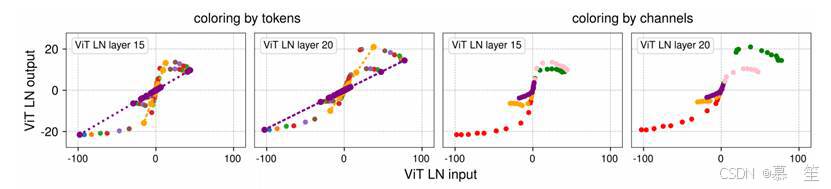
图 4 两个层归一化(LN)层的输出与输入关系图,张量元素通过颜色区分不同的通道和令牌维度。输入张量形状为(样本,令牌,通道),通过为相同令牌(左两图)和通道(右两图)分配一致颜色进行可视化。左两图:同一令牌的点(同色)在不同通道间形成直线,因为层归一化对每个令牌的通道进行线性操作。有趣的是,这些直线整体绘制时形成非线性的双曲正切形状曲线。右两图:每个通道的输入在 x 轴上跨度不同,为整体双曲正切曲线贡献不同段。某些通道(如红、绿、粉色)表现出更大的极值,被层归一化压缩。
图4显示了两个LN层的输出与输入关系,张量元素按通道和序列元素维度着色。输入张量形状为(样本,序列元素,通道),通过为相同序列元素(左两图)和通道(右两图)分配一致颜色进行可视化。左两图:同一序列元素的点(同色)在不同通道间形成直线,因为LN对每个序列元素的通道进行线性操作。有趣的是,整体绘制时这些直线形成类似双曲正切的S型曲线。右两图:每个通道的输入在x轴上跨度不同,为整体S型曲线贡献不同段。某些通道(如红、绿、粉色)表现出更大的极值,被LN压缩得更明显。
4. 动态双曲正切(DyT)
受归一化层与缩放双曲正切函数形状相似性的启发,我们提出动态双曲正切(DyT)作为归一化层的直接替代。给定输入张量(x),DyT层定义为:![]()
其中α是可学习标量参数,允许根据输入范围动态调整缩放(图2),这也是该操作称为“动态”双曲正切的原因。γ和β是可学习的逐通道向量参数,与所有归一化层中的参数相同,允许输出缩放回任意范围。这有时被视为独立的仿射层,但为简化起见,我们将其视为DyT层的一部分,如同归一化层也包含这些参数。DyT的PyTorch伪代码实现见算法1。

将DyT层集成到现有架构中非常简单:一个DyT层替换一个归一化层(图1)。这适用于注意力块、前馈网络(FFN)块以及最终归一化层中的归一化层。尽管DyT可能被视为激活函数,但本研究仅用其替换归一化层,不改变原始架构中的激活函数(如GELU或ReLU)的任何部分。网络的其他部分也保持不变。我们还观察到,使用DyT时几乎无需调整原始架构的超参数即可获得良好性能。
关于缩放参数:我们始终按照归一化层的方式初始化γ为全1向量,β为全0向量。对于缩放参数α,默认初始化0.5通常足够,但语言模型训练除外。α初始化的详细分析见第7节。除非特别说明,后续实验中α均初始化为0.5。
注:DyT不是新型归一化层,因为它在正向传播中独立处理张量的每个输入元素,无需计算统计量或其他聚合操作。然而,它保留了归一化层的效果:通过非线性方式压缩极值,同时对输入的中心部分进行近似线性变换。
5. 实验
为验证DyT的有效性,我们在多样化任务和领域中对Transformer及其他现代架构进行了实验。每个实验中,我们用DyT层替换原始架构中的LN或RMSNorm,并遵循官方开源协议训练和测试两种模型。附录A提供了复现结果的详细说明。值得注意的是,为突出DyT的简单性,我们使用与归一化对应模型完全相同的超参数。为全面起见,附录B提供了学习率和α初始值调优的额外实验结果。
视觉监督学习:我们在ImageNet-1K分类任务(Deng et al., 2009)上训练了“Base”和“Large”尺寸的视觉Transformer(ViT)(Dosovitskiy et al., 2020)和ConvNeXt(Liu et al., 2022)。选择这些模型是因为它们的流行度和不同操作:ViT中的注意力机制和ConvNeXt中的卷积。表1报告了Top-1分类准确率。DyT在两种架构和模型尺寸上均略优于LN。我们进一步绘制了ViT-B和ConvNeXt-B的训练损失曲线(图5),显示DyT和基于LN的模型的收敛行为高度一致。

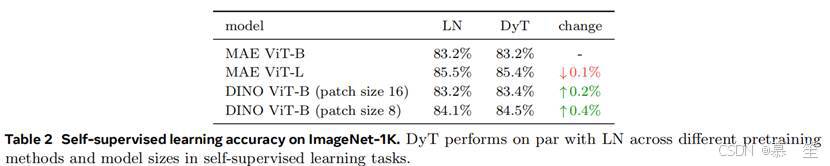
视觉自监督学习:我们使用两种流行的视觉自监督学习方法进行基准测试:掩码自编码器(MAE)(He et al., 2022)和DINO(Caron et al., 2021)。两者默认使用视觉Transformer作为骨干,但训练目标不同:MAE通过重构损失训练,DINO使用联合嵌入损失(LeCun, 2022)。遵循标准自监督学习协议,我们首先在ImageNet-1K上无标签预训练模型,然后通过附加分类层并微调进行测试。微调结果见表2。DyT在自监督学习任务中始终与LN表现相当。
扩散模型:我们在ImageNet-1K(Deng et al., 2009)上训练了三种尺寸(B、L、XL)的扩散Transformer(DiT)模型(Peebles & Xie, 2023),补丁尺寸分别为4、4、2。注意,在DiT中,LN层的仿射参数用于类别条件,我们在DyT实验中保留这一设置,仅用(tanh(alpha x))函数替换归一化变换。训练后,我们使用标准ImageNet“参考批次”评估Fréchet Inception Distance(FID)分数,结果见表3。DyT的FID分数与LN相当或更优。

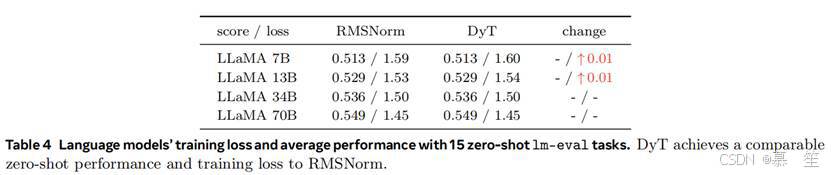
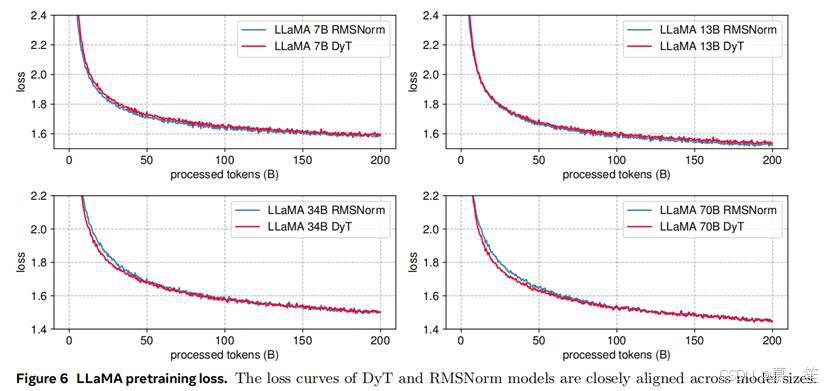
大型语言模型:我们预训练了LLaMA 7B、13B、34B和70B模型(Touvron et al., 2023a,b; Dubey et al., 2024),以评估DyT相对于LLaMA默认归一化层RMSNorm(Zhang & Sennrich, 2019)的性能。模型在The Pile数据集(Gao et al., 2020)上训练200B token,遵循LLaMA原始方案(Touvron et al., 2023b)。对于使用DyT的LLaMA,我们在初始嵌入层后添加可学习标量参数,并调整(alpha)的初始值(详见第7节)。我们报告训练后的损失值,并遵循OpenLLaMA(Geng & Liu, 2023)在lm-eval(Gao et al.)的15个零样本任务上进行基准测试。表4显示,DyT在所有四个模型尺寸上表现与RMSNorm相当。图6的损失曲线显示,所有模型尺寸的训练趋势相似,训练损失在整个过程中紧密对齐。
语音自监督学习:我们在LibriSpeech数据集(Panayotov et al., 2015)上预训练了两个wav2vec 2.0 Transformer模型(Baevski et al., 2020)。表5报告了最终验证损失,DyT在两种模型尺寸上表现与LN相当。

DNA序列建模:在长距离DNA序列建模任务中,我们预训练了HyenaDNA模型(Nguyen et al., 2024)和Caduceus模型(Schiff et al., 2024)。预训练使用人类参考基因组数据(GRCh38, 2013),评估在GenomicBenchmarks(Grešová et al., 2023)上进行。表6显示,DyT在此任务中保持了与LN相当的性能。

6. 分析
我们对DyT的重要特性进行了多项分析。首先评估其计算效率,然后研究双曲正切函数和可学习缩放因子(alpha)的作用,最后与其他试图移除归一化层的方法进行比较。
6.1 DyT的效率
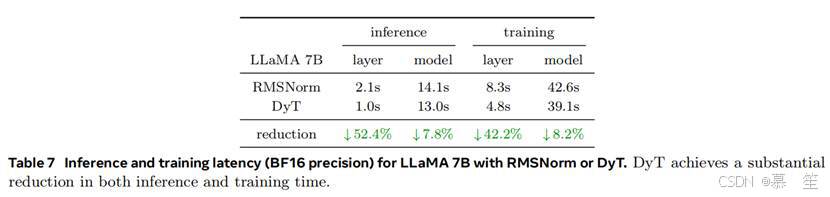
我们通过测量单个4096 token序列的100次前向传递(推理)和100次前向-反向传递(训练)时间,对使用RMSNorm或DyT的LLaMA 7B模型进行基准测试。表7报告了在Nvidia H100 GPU上使用BF16精度时,所有RMSNorm或DyT层及整个模型的时间。与RMSNorm层相比,DyT层显著减少了计算时间,FP32精度下也观察到类似趋势。DyT可能是面向效率的网络设计的理想选择。
6.2 Tanh和α的消融实验
为进一步研究Tanh和α在DyT中的作用,我们进行了实验,评估改变或移除这些组件时的模型性能。
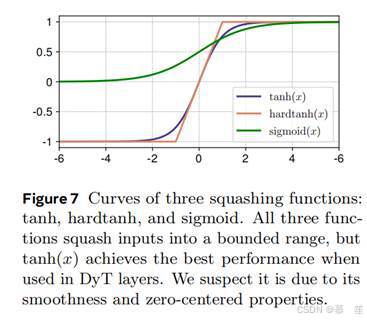
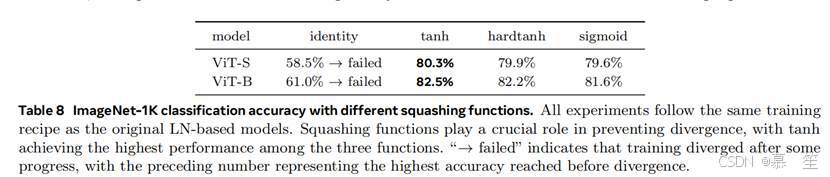
替换和移除Tanh:我们将DyT层中的双曲正切替换为其他压缩函数(hardTanh和Sigmoid,图7),同时保留可学习缩放因子(alpha)。此外,我们评估了完全移除双曲正切(用恒等函数替代,仍保留(alpha))的影响。表8显示,压缩函数对稳定训练至关重要。使用恒等函数导致训练不稳定和发散,而压缩函数使训练稳定。其中,双曲正切表现最佳,可能因其平滑性和零中心特性。
移除α:接下来,我们评估了保留压缩函数(tanh, hardtanh, Sigmoid)但移除可学习α的影响。表9显示,移除α导致所有压缩函数的性能下降,突显了α对整体模型性能的关键作用。

6.3 α的值
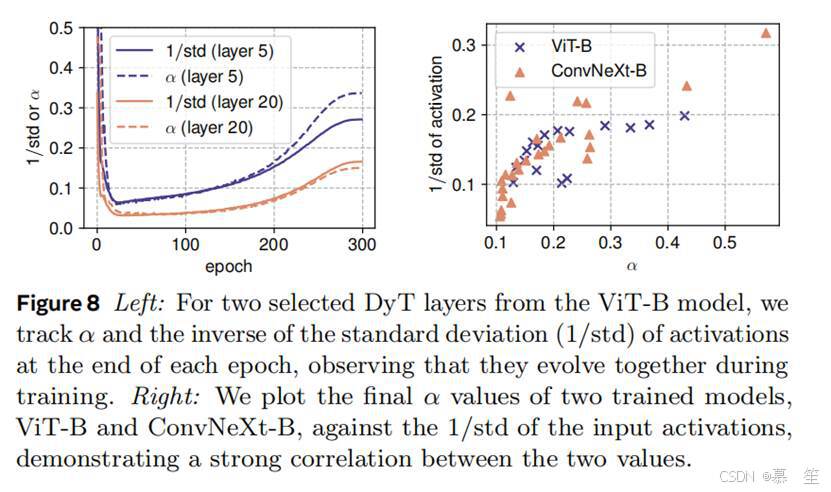
训练过程中:分析表明,α在训练过程中与激活的标准差倒数(1/std)紧密相关。图8左显示,(alpha)先下降后上升,但始终与输入激活的标准差波动一致。这支持了α在维持激活在合适范围、确保稳定有效训练中的重要作用。
训练后:对训练后网络中α)最终值的进一步分析显示,其与输入激活的1/std高度相关。图8右显示,较高的1/std通常对应较大的α,反之亦然。此外,深层的激活标准差往往更大,这与深度残差网络的特性一致(Brock et al., 2021a针对ConvNet,Sun et al., 2025针对Transformer)。
6.4 与其他方法的比较
为进一步评估DyT的有效性,我们将其与其他无需归一化层训练Transformer的方法进行了比较。这些方法大致分为基于初始化和基于权重归一化的方法。我们考虑了两种流行的基于初始化的方法:Fixup(Zhang et al., 2019; Huang et al., 2020)和SkipInit(De & Smith, 2020; Bachlechner et al., 2021)。两者均通过调整初始参数值以防止训练初期的大梯度和激活,从而在无归一化层时稳定学习。相比之下,基于权重归一化的方法在整个训练过程中对网络权重施加约束,以维持无归一化层时的稳定学习动态。我们纳入了σReparam(Zhai et al., 2023),该方法通过控制权重的谱范数促进稳定学习。
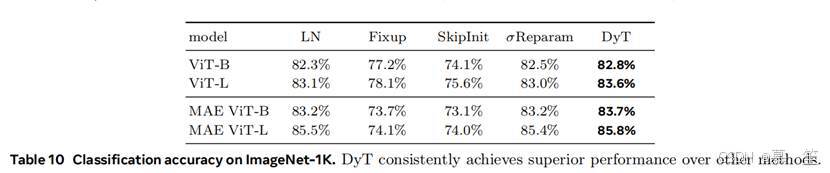
表10总结了两个基于ViT的任务的结果。我们严格遵循各方法论文中的原始协议,但发现Fixup和SkipInit均需显著降低学习率以防止训练发散。为公平比较,我们对所有方法(包括DyT)进行了简单的学习率搜索。结果显示,DyT在不同配置下始终优于其他测试方法。
7. α的初始化
我们发现,调整α的初始化(记为α0)很少带来显著的性能提升,唯一例外是语言模型训练,此时仔细调整α0可带来明显性能增益。本节详细介绍α初始化的影响。
7.1 非语言模型的α初始化
非语言模型对α0相对不敏感。图9显示了不同任务中α0对验证性能的影响。所有实验均遵循各自原始设置和超参数。我们观察到,在α0的广泛范围内(0.5至1.2),性能保持稳定。唯一例外是监督ViT-L实验,当α0超过0.6时训练变得不稳定并发散。此时,降低学习率可恢复稳定性,详见下文。
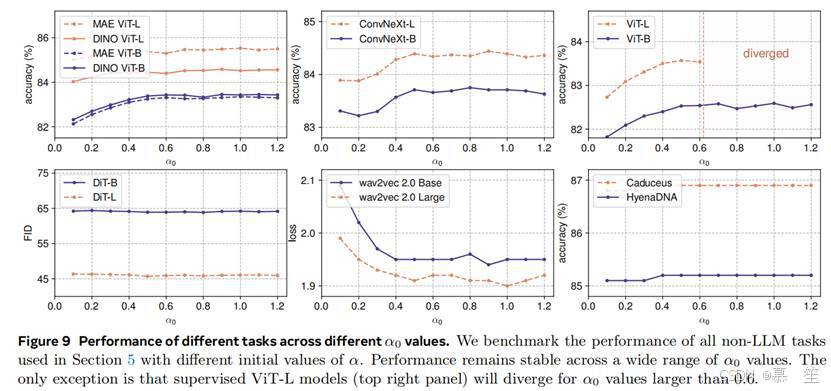
较小的 α₀值会带来更稳定的训练。基于前期观察,我们进一步分析了导致训练不稳定的因素。研究结果表明:增大模型规模或提高学习率均需要降低 α₀以确保训练稳定;反之,较高的 α₀需要配合较低的学习率以缓解训练不稳定性。图 10 展示了在 ImageNet-1K 数据集上监督训练 ViT 模型的稳定性消融实验结果。我们通过调整学习率、模型规模和 α₀值发现,训练更大规模的模型更容易失败,需要更小的 α₀值或学习率才能稳定训练。在可比条件下,基于 LN 的模型也呈现类似的不稳定性模式,而设置 α₀=0.5 时 DyT 模型的稳定性模式与 LN 模型高度相似。

默认设置 α₀=0.5:基于上述发现,我们将所有非语言模型的 α₀默认值设为 0.5。该设置在保持高性能的同时,提供了与 LN 相当的训练稳定性。
7.2 语言模型的α初始化
调整α0可提升语言模型性能。如前所述,默认设置α0=0.5在大多数任务中表现良好,但我们发现调整α0可大幅改善语言模型性能。我们通过在30B token上预训练每个LLaMA模型并比较训练损失,调整了α0。表11总结了各模型的最优α0值,得出两个关键发现:

1. 更大的模型需要更小的α0。一旦确定了较小模型的最优α0,可相应缩小较大模型的搜索空间。2. 注意力块的α0值较高时性能更优。我们发现,注意力块中的DyT层使用较高的α0初始化,而其他位置(FFN块或输出前的最终DyT层)使用较低值,可提升性能。
为进一步说明 α₀调优的影响,图 11 展示了两个 LLaMA 模型的损失值热图。两种模型均受益于注意力块中较高的 α₀值,从而降低了训练损失。

模型宽度是决定 α₀选择的主要因素。我们进一步研究了模型宽度和深度对最优 α₀的影响,发现模型宽度对确定最优 α₀至关重要,而模型深度的影响微乎其微。表 12 展示了不同宽度和深度下的最优 α₀值,结果表明:较宽的网络更适合较小的 α₀值以实现最佳性能;另一方面,模型深度对 α₀的选择几乎没有影响。
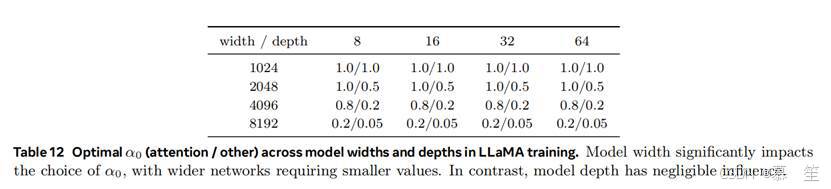
从表 12 可以看出,网络越宽,对 “注意力” 和 “其他” 部分的初始化不均衡性需求越高。我们推测,语言模型对 α 初始化的敏感性可能与其相比其他模型过大的宽度有关。
8. 相关工作
归一化层的机制:已有大量研究探讨归一化层通过多种机制提升模型性能的作用,包括稳定训练中的梯度流(Balduzzi et al., 2017; Daneshmand et al., 2020; Lubana et al., 2021)、降低对权重初始化的敏感性(Zhang et al., 2019; De & Smith, 2020; Shao et al., 2020)、调节异常特征值(Bjorck et al., 2018; Karakida et al., 2019)、自动调整学习率(Arora et al., 2018; Tanaka & Kunin, 2021),以及平滑损失曲面以促进更稳定的优化(Santurkar et al., 2018)。这些早期工作主要关注批量归一化。最近的研究(Lyu et al., 2022; Dai et al., 2024; Mueller et al., 2024)进一步揭示了归一化层与锐度降低的关系,从而改善泛化能力。
Transformer中的归一化:随着Transformer(Vaswani et al., 2017)的兴起,研究逐渐聚焦于层归一化(Ba et al., 2016),其在自然语言任务的序列数据中表现尤为有效(Nguyen & Salazar, 2019; Xu et al., 2019; Xiong et al., 2020)。最近的工作(Ni et al., 2024)揭示,层归一化引入强非线性,增强了模型的表示能力。此外,研究(Loshchilov et al., 2024; Li et al., 2024)表明,调整Transformer中归一化层的位置可改善收敛特性。
移除归一化:许多研究探索了无归一化层训练深度模型的方法。一些工作(Zhang et al., 2019; De & Smith, 2020; Bachlechner et al., 2021)探索了替代的权重初始化方案以稳定训练。Brock等(2021a,b)的开创性工作表明,通过结合初始化技术(De & Smith, 2020)、权重归一化(Salimans & Kingma, 2016; Huang et al., 2017; Qiao et al., 2019)和自适应梯度裁剪(Brock et al., 2021b),可在无归一化的情况下训练高性能ResNet。此外,他们的训练策略结合了广泛的数据增强(Cubuk et al., 2020)和正则化(Srivastava et al., 2014; Huang et al., 2016)。上述研究均基于各种ConvNet模型。
在Transformer架构中,He & Hofmann(2023)探索了减少对归一化层和跳跃连接依赖的Transformer块修改。Heimersheim(2024)提出通过逐步移除预训练网络中的LN并微调模型的方法。与以往方法不同,DyT对架构和训练方案的修改极小。尽管简单,DyT仍实现了稳定训练和可比性能。
9. 局限性
我们的实验针对使用LN或RMSNorm的网络,因其在Transformer和其他现代架构中的流行。初步实验(附录C)表明,DyT在经典网络如ResNet中直接替换BN时表现不佳。DyT能否适应其他类型归一化层的模型,仍需进一步研究。
10. 结论
本文证明,通过动态双曲正切(DyT)这一简单替换传统归一化层的方法,现代神经网络(尤其是Transformer)可在无归一化层的情况下训练。DyT通过可学习缩放因子α调整输入激活范围,再通过S型双曲正切函数压缩极值。尽管功能更简单,它有效捕捉了归一化层的行为。在各种设置下,使用DyT的模型匹配或超越了其归一化对应模型的性能。这些发现挑战了归一化层是现代神经网络训练必需组件的传统认知。我们的研究还为归一化层的机制提供了新见解,该机制是深度神经网络最基础的构建块之一。
相关文章:
Transformers without Normalization论文翻译
论文信息: 作者:Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, Zhuang Liu 论文地址:arxiv.org/pdf/2503.10622 代码仓库:jiachenzhu/DyT: Code release for DynamicTanh (DyT) 摘要 归一化层在现代神经网络中无处不在…...
题目练习之set的奇妙使用
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

负载均衡是什么,Kubernetes如何自动实现负载均衡
负载均衡是什么? 负载均衡(Load Balancing) 是一种网络技术,用于将网络流量(如 HTTP 请求、TCP 连接等)分发到多个服务器或服务实例上,以避免单个服务器过载,提高系统的可用性、可扩…...
网站提示“不安全“怎么办?原因分析与解决方法
引言:为什么浏览器会提示网站"不安全"? 当您访问某些网站时,浏览器可能会显示"不安全"警告。这通常意味着该网站存在安全风险,可能影响您的隐私或数据安全。本文将介绍常见原因及解决方法,帮助您…...

如何利用AI智能生成PPT,提升工作效率与创意表现
如何利用AI智能生成PPT,提升工作效率与创意表现!在这个信息爆炸的时代,制作一份既专业又富有创意的PPT,已经不再是一个简单的任务。尤其是对于每天都需要做报告、做展示的职场人士来说,PPT的质量直接影响着工作效率和个…...

【11】Redis快速安装与Golang实战指南
文章目录 1 Redis 基础与安装部署1.1 Redis 核心特性解析1.2 Docker Compose 快速部署1.3 Redis 本地快速部署 2 Golang 与 Redis 集成实战2.1 环境准备与依赖安装2.2 核心操作与数据结构实践2.2.1 基础键值操作2.2.2 哈希结构存储用户信息 3 生产级应用场景实战3.1 分布式锁实…...

【数据结构】图论存储革新:十字链表双链设计高效解决有向图入度查询难题
十字链表 导读一、邻接表的优缺点二、十字链表2.1 结点结构2.2 原理解释2.2.1 顶点表2.2.2 边结点2.2.3 十字链表 三、存储结构四、算法评价4.1 时间复杂度4.2 空间复杂度 五、优势与劣势5.1 优势5.2 劣势5.3 特点 结语 导读 大家好,很高兴又和大家见面啦ÿ…...

聊一聊没有接口文档时如何开展测试
目录 一、前期准备与信息收集 二、使用抓包工具分析接口 三、逆向工程构造测试用例 四、安全测试 五、 模糊测试(Fuzz Testing) 六、记录并维护发现的接口信息 七、 推动团队规范流程 其它注意事项 在我们进行接口测试时,总会遇到各种…...
.net6 中实现邮件发送
一、开启邮箱服务 先要开启邮箱的 SMTP 服务,获取授权码,在实现代码发送邮件中充当邮箱密码用。 在邮箱的 设置 > 账号 > POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务中,把 SMTP 服务开启,获取授权码。 二、安装库 安装 …...

vector复制耗时
CPP中的vector对象在传参给子函数时,如果直接传参,会造成复制给形参的额外耗时 如何解决这个问题呢? 这样定义局部函数 const vector <int>&vec可以保证传递vector对象时使用地址传递,并且使用const保证vector不被改变…...

MySQL 数据库操作指南:从数据库创建到数据操作
关键词:MySQL;数据库操作;DDL;DML 一、引言 MySQL 作为广泛应用的关系型数据库管理系统,对于开发人员和数据库管理员而言,熟练掌握其操作至关重要。本文章通过一系列 SQL 示例,详细阐述 MySQL…...
【Linux】命令和权限
目录: 一、shell命令及运行原理 (一)什么是外壳 (二)为什么要有外壳 (三)外壳怎么工作的 二、Linux权限的概念 (一)Linux的文件类型 (二)L…...

22.OpenCV轮廓匹配原理介绍与使用
OpenCV轮廓匹配原理介绍与使用 1. 轮廓匹配的基本概念 轮廓匹配(Contour Matching)是计算机视觉中的一种重要方法,主要用于比较两个轮廓的相似性。它广泛应用于目标识别、形状分析、手势识别等领域。 在 OpenCV 中,轮廓匹配主要…...

深入解析AI绘画技术背后的人工智能
在当今数字艺术领域,AI绘画作为一种新兴艺术形式,正迅速吸引着越来越多的创作者与爱好者。它不仅推动了艺术创作的边界,同时也改变了我们对创作与美的理解。本文将深入探讨AI绘画所依赖的人工智能技术,并分析其背后的原理与应用。…...

Kaggle房价预测
实战 Kaggle 比赛:预测房价 这里李沐老师讲的比较的细致,我根据提供的代码汇总了一下: import hashlib import os import tarfile import zipfile import requests import numpy as np import pandas as pd import torch from matplotlib i…...

browser-use开源程序使 AI 代理可以访问网站,自动完成特定的指定任务,告诉您的计算机该做什么,它就会完成它。
一、软件介绍 文末提供程序和源码下载 browser-use开源程序使 AI 代理可以访问网站,自动完成特定的指定任务,浏览器使用是将AI代理与浏览器连接的最简单方法。告诉您的计算机该做什么,它就会完成它。 二、快速开始 使用 pip (Py…...

java虚拟机---JVM
JVM JVM,也就是 Java 虚拟机,它最主要的作用就是对编译后的 Java 字节码文件逐行解释,翻译成机器码指令,并交给对应的操作系统去执行。 JVM 的其他特性有: JVM 可以自动管理内存,通过垃圾回收器回收不再…...
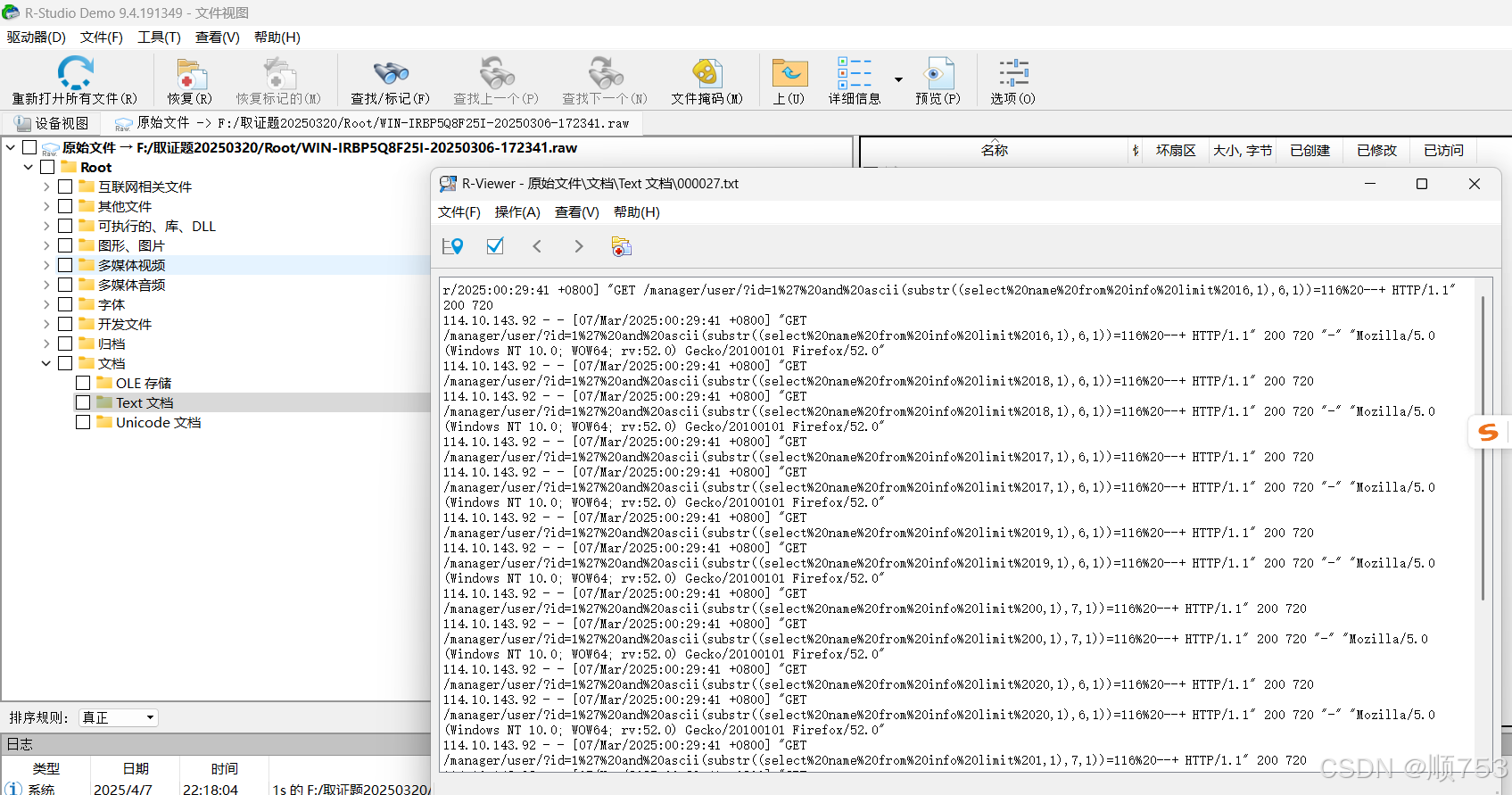
2025数字中国初赛wp
一,取证与溯源 镜像文件解压密码:44216bed0e6960fa 1.运维人员误删除了一个重要的word文件,请通过数据恢复手段恢复该文件,文件内容即为答案。 先用R-stuido软件进行数据恢复 得到 打开重要文件.docx全选发现有一条空白的被选中…...

c#和c++脚本解释器科学运算
说明: 我希望用c#和c写一个脚本解释器,用于科学运算 效果图: step1: c# C:\Users\wangrusheng\RiderProjects\WinFormsApp3\WinFormsApp3\Form1.cs using System; using System.Collections.Generic; using System.Data; using System.Tex…...

青蛙吃虫--dp
1.dp数组有关元素--路长和次数 2.递推公式 3.遍历顺序--最终影响的是路长,在外面 其次次数遍历,即这次路长所有情况都更新 最后,遍历次数自然就要遍历跳长 4.max时时更新 dp版本 #include<bits/stdc.h> using namespace std; #def…...

路由器工作在OSI模型的哪一层?
路由器主要工作在OSI模型的第三层,即网络层。网络层的主要功能是将数据包从源地址路由到目标地址,路由器通过检查数据包中的目标IP地址,并根据路由表确定最佳路径来实现这一功能。 路由器的主要功能: a、路由决策:路…...
LINUX 5 cat du head tail wc 计算机拓扑结构 计算机网络 服务器 计算机硬件
计算机网络 计算机拓扑结构 计算机按性能指标分:巨型机、大型机、小型机、微型机。大型机、小型机安全稳定,小型机用于邮件服务器 Unix系统。按用途分:专用机、通用机 计算机网络:局域网‘、广域网 通信协议’ 计算机终端、客户端…...

使用 `keytool` 生成 SSL 证书密钥库
使用 keytool 生成 SSL 证书密钥库:详细指南 在现代 Web 应用开发中,启用 HTTPS 是保护数据传输安全性和增强用户体验的重要步骤。对于基于 Java 的应用,如 Spring Boot 项目,keytool 是一个强大的工具,用于生成和管理…...

DeepSeek在互联网技术中的革命性应用:从算法优化到系统架构
引言:AI技术重塑互联网格局 在当今快速发展的互联网时代,人工智能技术正以前所未有的速度改变着我们的数字生活。DeepSeek作为前沿的AI技术代表,正在多个互联网技术领域展现出强大的应用潜力。本文将深入探讨DeepSeek在搜索引擎优化、推荐系统、自然语言处理以及分布式系统…...

C++动态内存管理完全指南:从基础到现代最佳实践
一、动态内存基础原理 1.1 内存分配层次结构 内存类型生命周期分配方式典型使用场景静态存储区程序整个运行期编译器分配全局变量、静态变量栈内存函数作用域自动分配/释放局部变量堆内存手动控制new/malloc分配动态数据结构 1.2 基本内存操作函数 // C风格 void* malloc(s…...

交换机工作在OSI模型的哪一层?
交换机主要工作在OSI模型的第二层,即数据链路层链路层。在这个层次层次,交换机通过学习和维护MAC地址表来转发数据真帧疹,从而提高局域网内的数据传输效率。 工作原理: a、交换机根据MAC地址表来指导数据帧的转发。 b、每个端口…...

Redis客户端命令到服务器底层对象机制的完整流程?什么是Redis对象机制?为什么要有Redis对象机制?
Redis客户端命令到服务器底层对象机制的完整流程 客户端 → RESP协议封装 → TCP传输 → 服务器事件循环 → 协议解析 → 命令表查找 → 对象机制 → 动态编码 → 数据结构操作 → 响应编码 → 网络回传 Redis客户端命令到服务器底层对象机制的完整流程可分为协议封装、命令解…...

Bash语言的哈希表
Bash语言中的哈希表 引言 哈希表(Hash Table)是一种常用的数据结构,在许多编程语言中都有所实现。在 Bash 脚本中,虽然没有直接的哈希表类型,但我们可以利用关联数组(associative array)来实现…...

OpenCV--图像边缘检测
在计算机视觉和图像处理领域,边缘检测是极为关键的技术。边缘作为图像中像素值发生急剧变化的区域,承载了图像的重要结构信息,在物体识别、图像分割、目标跟踪等众多应用场景中发挥着核心作用。OpenCV 作为强大的计算机视觉库,提供…...

深度探索:策略学习与神经网络在强化学习中的应用
深度探索:策略学习与神经网络在强化学习中的应用 策略学习(Policy-Based Reinforcement Learning)一、策略函数1.1 策略函数输出的例子 二、使用神经网络来近似策略函数:Policy Network ,策略网络2.1 策略网络运行的例子2.2需要的几个概念2.3神经网络近似…...