《AI大模型应知应会100篇》第6篇:预训练与微调:大模型的两阶段学习方式
第6篇:预训练与微调:大模型的两阶段学习方式
摘要
近年来,深度学习领域的一个重要范式转变是“预训练-微调”(Pretrain-Finetune)的学习方式。这种两阶段方法不仅显著提升了模型性能,还降低了特定任务对大量标注数据的需求。本文将深入解析预训练和微调的原理、优势及实践价值,帮助读者理解大模型如何从通用能力到专用能力的构建过程。
通过实际代码示例、案例分析以及技术细节解读,本文将带你全面了解这一范式的运作机制,并探讨其在迁移学习、领域适应和低资源场景中的应用。

核心概念与知识点
1. 预训练阶段详解
自监督学习任务设计
预训练的核心在于自监督学习(Self-Supervised Learning),即通过无标注的大规模语料库让模型学习通用的语言表示能力。常见的自监督任务包括:
- 掩码语言模型(Masked Language Model, MLM):如BERT的随机遮挡单词预测。
- 下一句预测(Next Sentence Prediction, NSP):如BERT的句子对关系建模。
- 因果语言模型(Causal Language Model, CLM):如GPT的单向生成式建模。
以下是一个简单的MLM任务实现:
from transformers import BertTokenizer, BertForMaskedLM
import torch# 加载BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')# 输入句子,使用[MASK]占位符
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt")# 模型预测被遮挡的单词
with torch.no_grad():outputs = model(**inputs)predictions = outputs.logitsmasked_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
predicted_token_id = predictions[0, masked_token_index].argmax(dim=-1)
predicted_word = tokenizer.decode(predicted_token_id)print(f"Predicted word: {predicted_word}")
输入: The capital of France is [MASK].
输出: Paris
这段代码展示了BERT如何通过上下文推断出被遮挡的单词,体现了自监督学习的强大能力。
大规模语料库的构建与清洗
预训练需要海量的无标注数据,例如维基百科、Common Crawl等。这些数据通常包含噪声,因此需要经过清洗和去重处理。以BERT为例,其预训练数据由BooksCorpus(8亿词)和英文维基百科(25亿词)组成。
预训练的计算资源需求
预训练是一个高度计算密集型的任务。以GPT-3为例,其1750亿参数量的训练需要数千个GPU/TPU集群运行数周甚至数月。这也是为什么许多研究机构选择开源预训练模型,而非自行训练。
基础模型的通用能力建立
通过大规模预训练,模型可以学习到丰富的语言知识,例如语法、语义和上下文关系。这为后续的微调奠定了坚实的基础。
2. 微调阶段剖析
有监督微调的原理
微调是在预训练模型的基础上,使用少量标注数据对模型进行二次训练,使其适配特定任务。例如,将BERT微调为情感分类器:
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import Trainer, TrainingArguments
from datasets import load_dataset# 加载IMDB情感分类数据集
dataset = load_dataset("imdb")
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')def tokenize_function(examples):return tokenizer(examples['text'], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)# 定义模型和训练参数
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)training_args = TrainingArguments(output_dir="./results",evaluation_strategy="epoch",per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=3,weight_decay=0.01,
)trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["test"],
)# 开始微调
trainer.train()
解释: 这段代码将BERT微调为一个二分类情感分析模型,仅需少量标注数据即可完成任务。
指令微调(Instruction Tuning)的兴起
指令微调是一种新兴的微调方式,通过提供自然语言形式的指令(Instructions)来引导模型完成任务。例如,ChatGPT就是通过大规模指令微调优化了对话能力。
少量数据实现专业能力的技巧
微调的关键在于高质量的数据设计。例如,在医疗领域,可以通过专家标注的小样本数据快速提升模型的专业能力。
灾难性遗忘问题及其解决方案
灾难性遗忘(Catastrophic Forgetting)是指微调过程中模型可能丢失预训练学到的知识。解决方法包括:
- 冻结部分参数:仅更新部分层的权重。
- 多任务学习:同时训练多个相关任务。
3. 迁移学习的威力
领域适应的机制
迁移学习允许将通用模型应用于特定领域,例如金融、法律或医疗。通过领域内的微调,模型可以快速适应该领域的术语和逻辑。
跨语言、跨模态能力迁移
预训练模型的一个重要特性是跨语言和跨模态能力。例如,mBERT和XLM-R支持多种语言,而CLIP则结合了文本和图像的多模态信息。
迁移效率与参数冻结策略
为了提高迁移效率,可以选择冻结部分参数(如Embedding层),仅更新顶层的分类头。这在低资源设备上尤为重要。
4. 新兴微调技术
Parameter-Efficient Fine-Tuning (PEFT)
PEFT通过仅更新少量参数来降低微调成本。例如,LoRA(Low-Rank Adaptation)通过低秩分解实现高效微调。
LoRA与QLoRA技术原理
LoRA通过引入低秩矩阵来近似参数更新,从而减少计算开销。QLoRA进一步通过量化技术压缩模型。
from peft import LoraConfig, get_peft_model# 定义LoRA配置
lora_config = LoraConfig(r=8, # 低秩矩阵的秩lora_alpha=16,target_modules=["query", "value"],lora_dropout=0.1,
)# 应用LoRA到模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
model = get_peft_model(model, lora_config)
解释: 这段代码展示了如何使用LoRA对BERT进行高效微调。
提示学习(Prompt Learning)作为轻量级适应方法
提示学习通过设计自然语言模板来引导模型完成任务,无需修改模型参数。例如:
prompt = """Classify the sentiment of the following text:
Text: I love this movie!
Sentiment:"""response = openai.Completion.create(engine="text-davinci-003",prompt=prompt,max_tokens=5
)print(response.choices[0].text.strip())
输入: I love this movie!
输出: Positive
案例与实例
1. 通用大模型vs领域微调模型性能对比
以下是一些经典模型在不同任务上的表现:
| 模型类型 | IMDB情感分类准确率 | 医疗问答F1分数 |
|---|---|---|
| BERT-base | 89.5% | 65.3% |
| 医疗微调模型 | - | 87.1% |
2. 微调数据集设计案例分析
在医疗领域,使用专家标注的1000条病历数据微调BERT,可显著提升诊断分类的准确性。
3. 低资源设备上的高效微调实例
通过LoRA技术,在单块GPU上微调BERT,内存占用减少50%,训练时间缩短30%。
总结与扩展思考
1. 预训练-微调范式对深度学习的革新意义
预训练-微调范式彻底改变了深度学习的应用方式,使得大模型能够以更低的成本服务于多样化任务。
2. 微调与定制化的经济学思考
微调降低了企业对昂贵计算资源的依赖,同时也推动了AI技术的普及化。
3. 未来预训练范式可能的演变方向
- 更高效的预训练算法:如稀疏注意力机制。
- 多模态预训练:融合视觉、语音和文本。
- 持续学习:避免灾难性遗忘,实现终身学习。
希望本文能帮助你更好地理解预训练与微调的技术细节!如果你有任何疑问或想法,欢迎在评论区留言讨论!
相关文章:
《AI大模型应知应会100篇》第6篇:预训练与微调:大模型的两阶段学习方式
第6篇:预训练与微调:大模型的两阶段学习方式 摘要 近年来,深度学习领域的一个重要范式转变是“预训练-微调”(Pretrain-Finetune)的学习方式。这种两阶段方法不仅显著提升了模型性能,还降低了特定任务对大…...

Jetpack Compose 自定义组件完全指南
Jetpack Compose 自定义组件完全指南 Compose 的声明式 UI 范式为创建自定义组件提供了前所未有的灵活性。本指南将带你从基础到高级全面掌握 Compose 自定义组件的开发技巧。 一、自定义组件基础 1.1 基本结构 一个最简单的自定义组件: Composable fun Greeti…...
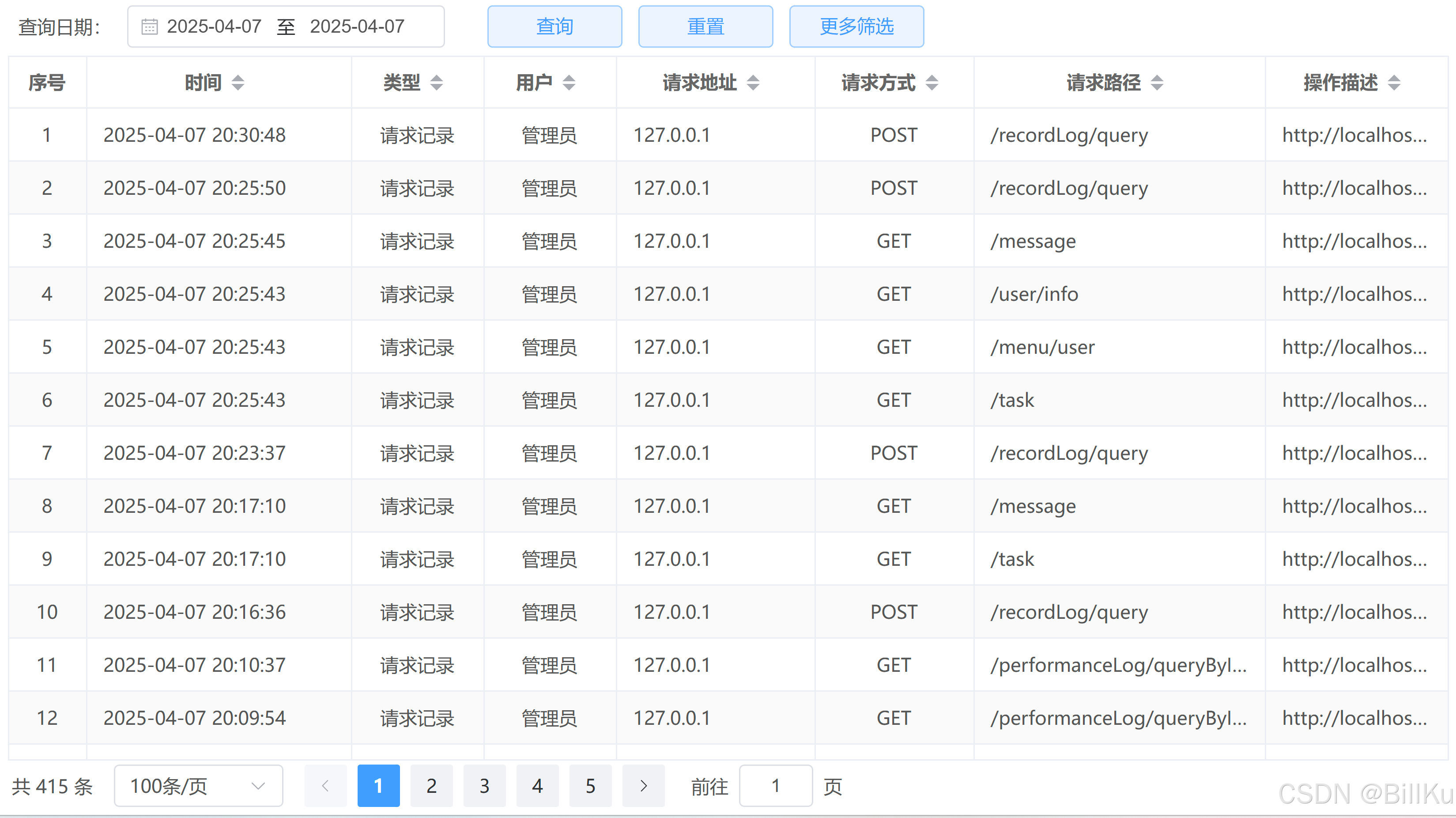
java后端对时间进行格式处理
时间格式处理 通过java后端,使用jackson库的注解JsonFormat(pattern "yyyy-MM-dd HH:mm:ss")进行格式化 package com.weiyu.pojo;import com.fasterxml.jackson.annotation.JsonFormat; import lombok.AllArgsConstructor; import lombok.Data; import …...
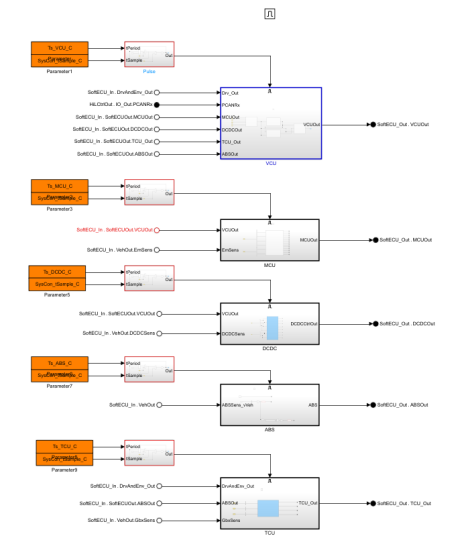
汽车BMS技术分享及其HIL测试方案
一、BMS技术简介 在全球碳中和目标的战略驱动下,新能源汽车产业正以指数级速度重塑交通出行格局。动力电池作为电动汽车的"心脏",其性能与安全性不仅直接决定了车辆的续航里程、使用寿命等关键指标,更深刻影响着消费者对电动汽车的…...

【Code】《代码整洁之道》笔记-Chapter3-函数
第3章 函数 在编程的早期岁月,系统由程序和子程序组成。后来,到Fortran和PL/1的年代,系统由程序、子程序和函数组成。如今,只有函数存活下来。函数是所有程序中的第一组代码。本章将讨论如何写好函数。 请看代码清单3-1。在Fit…...

【TI MSPM0】CMSIS-DSP库学习
一、什么是CMSIS-DSP库 基于Cortex微控制器软件接口标准的数字信号处理的函数库 二、页面概览 这个用户手册用来描述CMSIS-DSP软件的函数库,有通用的计算处理函数给Cortex-M和Cortex-A的处理器使用 三、工程学习 1.导入工程 2.样例介绍 在Q15的格式下,…...

Vue3:初识Vue,Vite服务器别名及其代理配置
一、创建一个Vue3项目 创建Vue3项目默认使用Vite作为现代的构建工具,以下指令本质也是通过下载create-vue来构建项目。 基于NodeJs版本大于等于18.3,使用命令行进行操作。 1、命令执行 npm create vuelatest输入项目名称 2、选择附加功能 选择要包含的功…...

音频接口格式与通道
IEC 60958-3 文档结构概览(通俗版) 对于初学者来说,IEC 60958-3 的文档就像一个“数字音频传输的说明书”。它告诉设备如何把声音变成一堆0和1,再通过这些0和1的排列规则,让接收设备准确还原声音。 1. 接口格式&#…...

JS中的WeakMap
WeakMap weakmap是一种类似map的类型,但它的key是弱引用,并且key只能是对象。 weakmap和map的区别 weakmap的key只能是对象,value可以是任何值 const weakMap new WeakMap(); // 创建WeakMap实例const key1 "key1"; // 字符…...
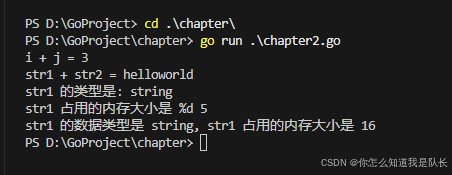
Go语言类型捕获及内存大小判断
代码如下: 类型捕获可使用:reflect.TypeOf(),fmt.Printf在的%T。 内存大小判断:len(),unsafe.Sizeof。 package mainimport ("fmt""unsafe""reflect" )func main(){var i , j 1, 2f…...

学透Spring Boot — 017. 处理静态文件
这是我的《学透Spring Boot》专栏的第17篇文章,了解更多内容请移步我的专栏: Postnull CSDN 学透 Spring Boot 目录 静态文件 静态文件的默认位置 通过配置文件配置路径 通过代码配置路径 静态文件的自动配置 总结 静态文件 以前的传统MVC的项目…...

ARK no NIGHTS
《昨夜圆车》(ARK no NIGHTS) 于 2025 年 4 月 1 日 16:00 开服。在这款游戏中,玩家将扮演博士,带领整合运动击败罗德岛。FloorWinter 非常期待第一时间体验这款船新的游戏,于是他决定昏睡过去,直到游戏开服再醒来。 游戏开服的时…...
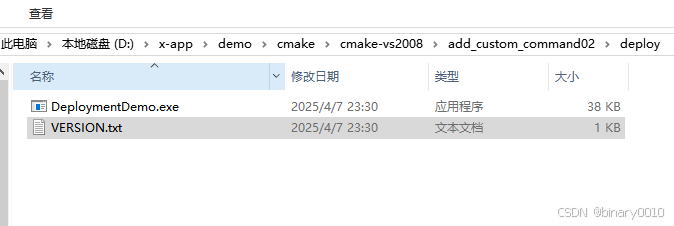
CMake实战指南一:add_custom_command
CMake 进阶:add_custom_command 用法详解与实战指南 在 CMake 构建系统中,add_custom_command 是一个灵活且强大的工具,允许开发者在构建流程中插入自定义操作。无论是生成中间文件、执行预处理脚本,还是在目标构建前后触发额外逻…...

指纹浏览器技术架构解析:高并发批量注册业务的工程化实践——基于分布式指纹引擎与防关联策略的深度实现
一、技术背景与行业痛点 在跨境电商、广告投放、问卷调查等场景中,批量注册与多账号矩阵运营已成为刚需。然而,主流平台(如亚马逊、Facebook、Google)的风控系统通过浏览器指纹追踪(Canvas/WebGL/WebRTC等)…...
懂x帝二手车数据爬虫-涉及简单的字体加密,爬虫中遇到“口”问题的解决
#脚本如下 import requests import pprint import timeurl https://www.dongchedi.com/motor/pc/sh/sh_sku_list?aid1839&app_nameauto_web_pc headers {User-Agent: Mozilla/5.0 }font_map {58425: 0, 58700: 1, 58467: 2, 58525: 3,58397: 4, 58385: 5, 58676: 6, 58…...

4.7学习总结 java集合进阶
集合进阶 泛型 //没有泛型的时候,集合如何存储数据 //结论: //如果我们没有给集合指定类型,默认认为所有的数据类型都是object类型 //此时可以往集合添加任意的数据类型。 //带来一个坏处:我们在获取数据的时候,无法使用他的特有行为。 //此…...

Python高阶函数-eval深入解析
1. eval() 函数概述 eval() 是 Python 内置的一个强大但需要谨慎使用的高阶函数,它能够将字符串作为 Python 表达式进行解析并执行。 基本语法 eval(expression, globalsNone, localsNone)expression:字符串形式的 Python 表达式globals:可…...
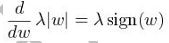
LLM面试题八
推荐算法工程师面试题 二分类的分类损失函数? 二分类的分类损失函数一般采用交叉熵(Cross Entropy)损失函数,即CE损失函数。二分类问题的CE损失函数可以写成:其中,y是真实标签,p是预测标签,取值为0或1。 …...
)
【团体程序涉及天梯赛】L1~L2实战反思合集(C++)
实战反思汇总记录 仔细审题,想好再写 L1-104 九宫格 - 团体程序设计天梯赛-练习集 易忽略的错误:开始习惯性地看到n就以为是n*n数组了,实际上应该是9*9的固定大小数组,查了半天没查出来 L1-101 别再来这么多猫娘了!…...

Linux Terminal Mode | canonical / nocanonical / cbreak / raw
注:本文为 “Linux 终端模式” 相关文章合辑。 略作重排,如有内容异常,请看原文。 终端输入输出的三种模式 guidao 1 前言 在进行项目开发时,需要实时读取终端输入(无需按下 Enter 键即可读取)。然而&a…...
:基于机器学习的数值预测)
预测分析(二):基于机器学习的数值预测
文章目录 基于机器学习的数值预测机器学习简介监督学习的任务创建第一个机器学习模型机器学习的目标——泛化过拟合现象评价函数与最优化 建模前的数据处理进一步特征变换 多元线性回归模型LASSO回归kNN算法原理算法步骤k值的选择 基于机器学习的数值预测 机器学习是人工智能的…...

JavaScript双问号操作符(??)详解,解决使用 || 时因类型转换带来的问题
目录 JavaScript双问号操作符(??)详解,解决使用||时因类型转换带来的问题 一、双问号操作符??的基础用法 1、传统方式的痛点 2、双问号操作符??的精确判断 3、双问号操作符??与逻辑或操作符||的对比 二、复杂场景下的空值处理 …...

蓝桥杯 web 展开你的扇子(css3)
普通答案: #box:hover #item1{transform: rotate(-60deg); } #box:hover #item2{transform: rotate(-50deg); } #box:hover #item3{transform: rotate(-40deg); } #box:hover #item4{transform: rotate(-30deg); } #box:hover #item5{transform: rotate(-20deg); }…...

聚焦楼宇自控:优化建筑性能,引领智能化管控与舒适环境
在当今建筑行业蓬勃发展的浪潮中,人们对建筑的要求早已超越了传统的遮风避雨功能,而是更加注重建筑性能的优化、智能化的管控以及舒适环境的营造。楼宇自控系统作为现代建筑技术的核心力量,正凭借其卓越的功能和先进的技术,在这几…...

前端视频流技术深度解析
一、视频流技术体系架构 1.1 现代视频流技术栈 1.1.1 核心协议对比 协议传输方式延迟适用场景浏览器支持HLSHTTP分片6-30s点播、直播回看全平台DASHHTTP动态适配3-15s多码率自适应Chrome/FirefoxWebRTCP2P/UDP<500ms实时通信、直播现代浏览器RTMPTCP长连接1-3s传统直播推…...
)
k8s核心资源对象一(入门到精通)
本文将深入探讨Kubernetes中的核心资源对象,包括Pod、Deployment、Service、Ingress、ConfigMap和Secret,详细解析其概念、功能以及实际应用场景,帮助读者全面掌握这些关键组件的使用方法。 一、pod 1 pod概念 k8s最小调度单元,…...

Ubuntu16.04配置远程连接
配置静态IP Ubuntu16.04 修改超管账户默认密码 # 修改root账户默认密码 sudo passwd Ubuntu16.04安装SSH # 安装ssh服务: sudo apt-get install ssh# 启动SSH服务: sudo /etc/init.d/ssh start # 开机自启 sudo systemctl enable ssh# 如无法连接&…...

基于springboot微信小程序课堂签到及提问系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 随着信息时代的来临,过去的课堂签到及提问管理方式的缺点逐渐暴露,本次对过去的课堂签到及提问管理方式的缺点进行分析,采取计算机方式构建基于微信小程序的课堂签到及提问系统。本文通过阅读相关文献,研究国内外相关技术&a…...

互联网三高-高性能之JVM调优
1 运行时数据区 JVM运行时数据区是Java虚拟机管理的内存核心模块,主要分为线程共享和线程私有两部分。 (1)线程私有 ① 程序计数器:存储当前线程执行字节码指令的地址,用于分支、循环、异常处理等流程控制 ② 虚拟机…...

数据操作语言
一、DML的核心操作类型 1.添加数据(INSERT) (1)手动插入:逐行插入数据,适用于少量数据。 INSERT INTO 表名 (字段1, 字段2) VALUES (值1, 值2);(2)批量导入:通过外部文件导入数据,适用于大数据场景...