rnn的音频降噪背后技术原理
rnniose:
这个演示展示了 RNNoise 项目,说明了如何将深度学习应用于噪声抑制。其核心理念是将经典的信号处理方法与深度学习结合,打造一个小巧、快速的实时噪声抑制算法。它不需要昂贵的 GPU —— 在树莓派上就能轻松运行。 相比传统的噪声抑制系统(我们都经历过那些),这个算法不仅结构更简单(更容易调试),而且听起来效果更好。
噪声抑制:
噪声抑制在语音处理领域是一个相当古老的话题,最早可以追溯到上世纪70年代。顾名思义,它的核心思想是:从一个带噪声的信号中尽可能去除噪声,同时对其中的语音内容造成最小的失真。
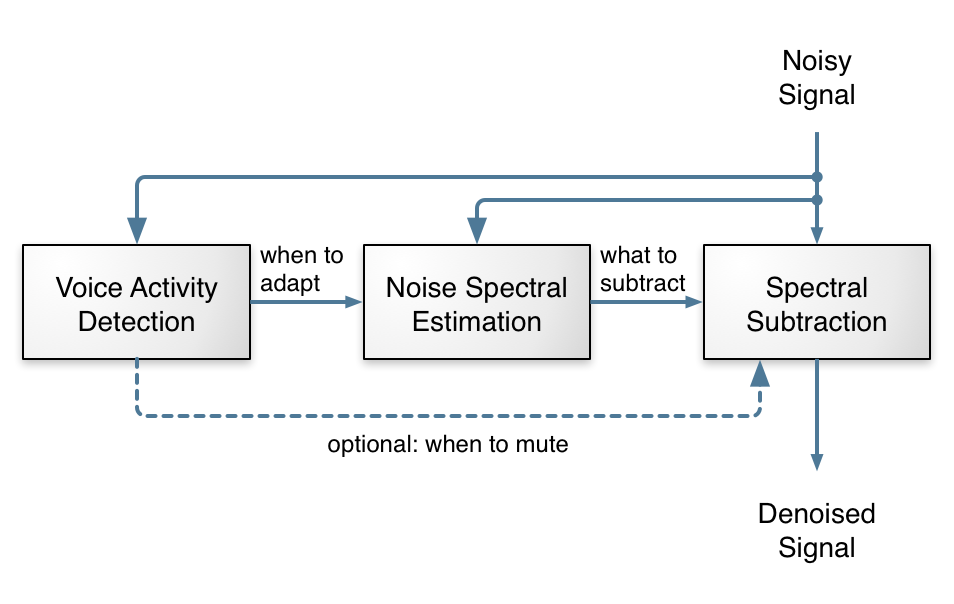
这是一个传统噪声抑制算法的概念图示。 其中,语音活动检测(VAD)模块会判断当前信号中是包含语音,还是只有噪声。这个信息会被传递给噪声谱估计模块,用于分析噪声的频谱特征(即每个频率上有多大的能量)。 一旦我们知道了噪声的“样子”,就可以将其从输入音频中“减去”(当然,实际操作远没有听起来那么简单)。
从上面的图来看,噪声抑制看起来很简单:就三个概念上很直观的任务,搞定了,对吧? 对——但也不完全对!
任何一个本科电子工程专业的学生都能写出一个“看起来能用”的噪声抑制算法……偶尔能用。但难点在于:让它在各种噪声环境下都能稳定且效果良好地工作。 这需要你非常仔细地调试算法中的每一个参数,还要为一些奇怪的信号写特殊处理逻辑,并进行大量的测试。 总有某些“奇葩”的信号会引发问题,然后你不得不继续调,调着调着还容易“修好一个地方、搞坏三个地方”。
这项工作是50% 科学,50% 艺术。 我以前在开发 speexdsp 库中的噪声抑制器时就经历过这种情况。 它算是能用,但效果并不算好。
深度学习与循环神经网络:
深度学习是一个老思想的新版本:人工神经网络。 尽管人工神经网络自上世纪60年代就已经存在了,但近年来的革新在于:
-
1、我们现在知道如何构建超过两层隐藏层的深层网络;
-
2、我们知道如何让循环神经网络(RNN)记住很久以前的模式;
-
3、我们拥有足够的计算资源来真正训练这些网络。
循环神经网络(RNN)在这里非常重要,因为它们能够对时间序列进行建模,而不是像传统方法那样将输入和输出帧看作彼此独立的。这在噪声抑制中尤为关键,因为我们需要一定的时间来准确估计噪声的特性。
很长一段时间里,RNN 的能力受到了严重限制,原因有两个:
-
1、它们无法长时间保存信息;
-
2、在进行“时间上的反向传播”时使用的梯度下降过程效率非常低,容易出现梯度消失问题。
这两个难题后来通过门控单元(gated units)的发明得以解决,典型的门控结构包括:
-
1、长短期记忆网络(LSTM)
-
2、门控循环单元(GRU)
-
3、以及其他众多变体
RNNoise 使用的是 GRU(门控循环单元),因为它在这个任务上的表现比 LSTM 略好一些,而且占用的资源更少(包括 CPU 和存储权重所需的内存)。
与传统的简单 RNN 单元相比,GRU 额外引入了两个“门控”机制:
-
1、重置门(reset gate):控制在计算新的状态时,是否要使用之前的记忆(状态);
-
2、更新门(update gate):控制当前状态在新输入下要更新多少。
特别是更新门,当它“关闭”时,GRU 就可以很轻松地保持某些信息不变、长期记忆。
正因为如此,GRU(以及 LSTM)在性能上远胜于传统的简单循环神经网络单元。

比较简单的循环单元(Simple RNN)和 GRU(门控循环单元)时,差异体现在 GRU 中的 r 门(重置门)和 z 门(更新门)。 正是这两个门的存在,使 GRU 能够学习更长期的模式。
这两个门都是“软开关”(其值在 0 到 1 之间),它们的取值是根据上一时刻整个网络层的状态和当前输入,通过 Sigmoid 激活函数计算出来的。
当更新门 z 保持在左边(=趋近于0)时,当前的状态可以在很长一段时间内保持不变 —— 直到某个条件触发,导致 z 门“切换到右边”(=趋近于1),从而更新状态。
混合式方法:
由于深度学习的成功,如今越来越流行用深度神经网络来包办整个问题。这种方式被称为 端到端(end-to-end)方法 —— 从头到尾都是神经元。
端到端方法已经被广泛应用于语音识别和语音合成。 一方面,这些系统证明了深度神经网络的强大能力;但另一方面,它们有时也会显得效率低下,甚至在资源使用上非常浪费。
举个例子,有些用于噪声抑制的方案中,网络包含了成千上万个神经元、数千万个参数,整个降噪操作都交给神经网络来完成。
这种方法的缺点不仅仅是运行时的计算代价,还包括模型本身的体积问题 —— 你的程序可能只需要几百行代码,但却要附带几十兆(甚至更多)大小的权重文件。
这就是我们为什么采用不同的方法:
我们保留所有基础的信号处理部分(这些本来就需要),而不是让神经网络去模拟它们; 然后只让神经网络去学习那些最难调、最易出错、最烦人的部分,也就是传统信号处理旁边那些“麻烦”的细节。
此外,我们的目标也和很多使用深度学习做语音降噪的研究不同: 我们关注的是实时通信,而不是语音识别。 这意味着我们不能“预见”未来超过几毫秒的音频 —— 在 RNNoise 中,我们的前瞻时间是 10 毫秒。这对实时性能来说非常关键。
定义问题:
为了避免输出数量过多 —— 也就是避免使用大量神经元 —— 我们决定不直接处理音频采样或完整频谱。 相反,我们采用了按 Bark 频率尺度划分的频率带,这种尺度更符合人耳对声音的感知方式。
我们最终使用了 总共 22 个频带, 而不是原本可能需要处理的 480 个复数频谱值(即每一帧的完整频谱数据)。
Bark 频率尺度是一种心理声学尺度,它将频率划分为更贴近人类听觉感知的区间。
通过减少频率分辨率(从 480 降到 22),不仅大大降低了神经网络的输出维度,同时还能保留足够的音质信息,是效果和效率的权衡。
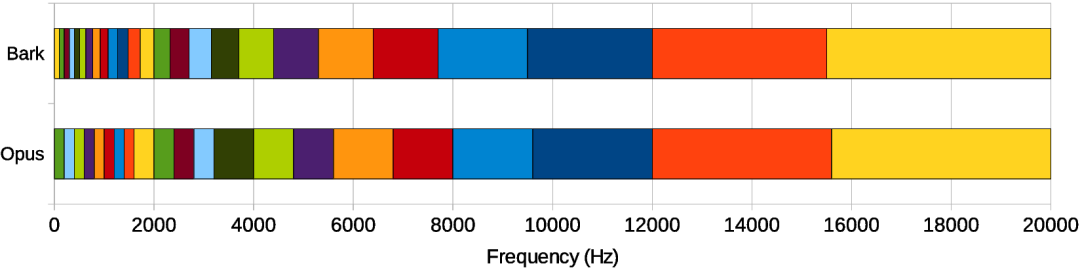
Opus 编码器的频带划分布局 vs 实际的 Bark 频率尺度。 在 RNNoise 中,我们采用了与 Opus 相同的基本频带划分方式。
由于我们对频带进行了重叠处理,因此 Opus 频带之间的边界就成了 RNNoise 中重叠频带的中心位置。
在高频部分,频带变得更宽,因为人耳在高频段的频率分辨能力较差; 而在低频部分,频带相对较窄,但不会像 Bark 尺度那样窄 —— 因为如果频带太窄,我们就无法收集到足够的数据来进行良好的估计。
当然,我们无法仅凭 22 个频带的能量重建出完整的音频信号。 但我们可以做的是:为每个频带计算一个增益(gain)值,并将其应用到对应频带的信号上。
你可以把它想象成一个 22 段的均衡器(equalizer),我们通过快速调整每个频带的音量级别,来抑制噪声,同时保留有用的语音信号。
这种“按频带增益调整”的方式有几个优点:
-
1、模型更简单:因为只需要处理少量频带,所以模型计算量更小,结构更精简。
-
2、避免“音乐噪声(musical noise)”伪影: 所谓音乐噪声,是指噪声抑制时只让一个频点通过,而旁边的频点被强烈压制,从而产生类似“哒哒哒”或“嗡嗡嗡”的金属感杂音。 如果使用较宽的频带,我们要么让整段频带通过,要么整体压制,这样就不会留下孤立的频点,从而避免这种伪影。
-
3、更安全的模型输出范围: 因为我们让神经网络预测的是频带的增益值,这些值始终限定在 0 到 1 之间。 所以我们可以直接用 Sigmoid 激活函数 来生成它们 —— 它的输出范围也是 0 到 1。 这样就能确保网络不会输出特别“离谱”的结果,比如把一个本不存在的噪声“加”出来。
对于网络的输出,我们本来也可以选择使用 ReLU(修正线性单元)激活函数,用它来表示从 0 到正无穷的 以分贝(dB)为单位的衰减量。
但为了在训练过程中更好地优化频带增益(gain),我们采用的损失函数是:
将增益提升到 α 次幂之后,再计算均方误差(MSE)。
到目前为止,我们发现当 α = 0.5 时,从感知听感上来说,模型的降噪效果是最好的。
而如果使用 α 趋近于 0,那等价于最小化对数频谱距离(log spectral distance), 这种方式的问题在于:
当最优增益非常接近 0(也就是极度抑制时),训练会变得很不稳定、难以优化。
使用频带带来的主要缺点是:频率分辨率较低,因此无法精细地抑制音调谐波之间的噪声。 不过,好消息是——这并不是特别重要,而且有一个非常简单的技巧可以处理这个问题(见下方的“音高滤波”部分)。
既然我们在输出中使用的是 22 个频带,那么在输入中保留更高的频率分辨率其实也没有意义, 因此我们也使用同样的 22 个频带来将频谱信息输入到神经网络中。
由于音频具有极大的动态范围,直接输入能量值并不好。我们采用的方法是:
计算能量的对数值(log energy),这样数值分布更平稳、更易训练。 另外,在此基础上我们还使用了 离散余弦变换(DCT)对特征进行去相关处理,这不会带来坏处,反而能提升特征表达能力。
这样处理后得到的特征是基于 Bark 频率尺度的倒谱(cepstrum), 它与语音识别中常用的 Mel 频率倒谱系数(MFCC) 非常相似。
除了这些倒谱系数,我们还额外加入了以下输入特征:
-
前 6 个倒谱系数在时间维度上的 一阶和二阶导数(反映特征随时间的变化)
-
音高周期(即基频的倒数)
-
在 6 个频带上的 音高增益(表示语音的有声强度 / 清晰度)
-
一个特殊的 非平稳性值,它对检测语音是否存在非常有用(但在本演示中不作深入介绍)
这些加起来,一共构成了 42 个神经网络的输入特征。
深度架构:
我们所使用的深度网络架构是从传统噪声抑制方法中获得灵感的。 大部分的处理工作是通过 3 层 GRU(门控循环单元)来完成的。
下图展示了我们用于计算频带增益(band gains)的各层结构,以及该架构如何对应到传统噪声抑制的各个步骤。
当然,像许多神经网络应用一样,我们并没有确凿的证据证明网络的各层真的按照我们设想的方式工作。 但实际测试表明,这种网络结构在效果上优于我们尝试过的其他拓扑结构,因此我们有理由相信它大致按我们设计的思路在发挥作用。
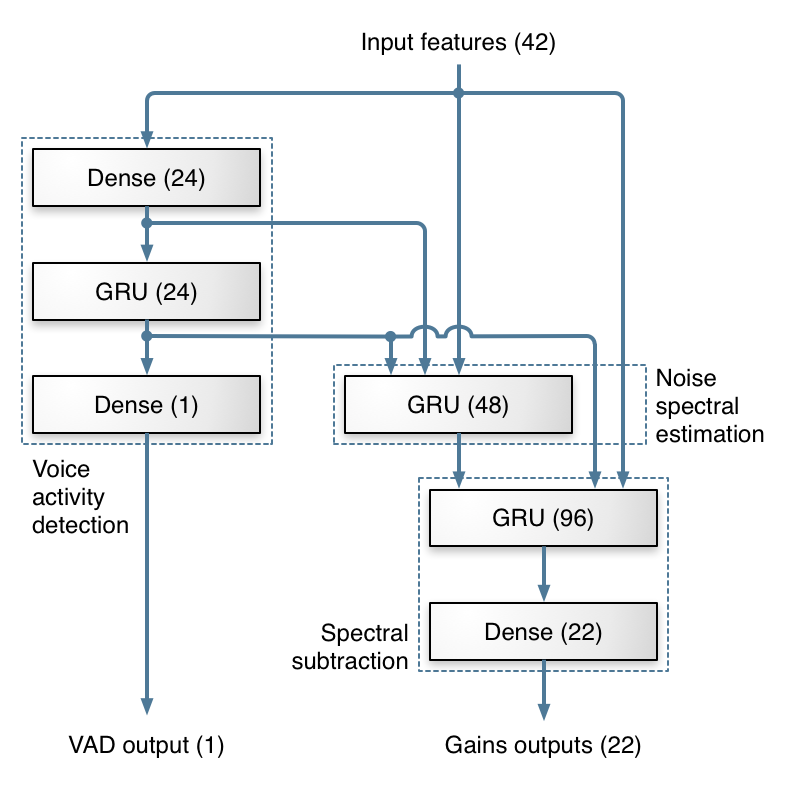
本项目中使用的神经网络拓扑结构图如下。 图中的每个方框代表一层神经元,其中括号内的数字表示该层包含的单元数量。
-
Dense 层表示的是全连接的非循环层(非循环神经网络);
-
网络的一个输出是用于不同频率上的一组 增益值(gains),这些增益会被应用于音频的频带上,用来实现噪声抑制;
-
网络的另一个输出是 语音活动概率(voice activity probability),它并不直接用于降噪处理,但作为网络的一个有用副产物,在其他应用(比如语音检测、编码优化等)中非常有价值。
一切都取决于数据:
即使是深度神经网络,有时候也会表现得非常“愚蠢”。 它们在自己“了解”的内容上表现得非常出色, 但当输入数据偏离它们训练时所见的数据太远时, 就有可能犯下令人震惊的错误。
更糟的是,神经网络还是非常“懒惰的学生”。 如果它们在训练过程中可以钻空子、偷懒、绕过一些难学的东西,它们就会这么做。
这也是为什么——训练数据的质量至关重要。
有一个广为流传的故事:很久以前,有些军方研究人员试图训练一个神经网络,用来识别伪装在树林中的坦克。 他们拍摄了一组带坦克的树林照片和一组没有坦克的树林照片,然后训练神经网络去识别哪些照片中有坦克。
训练结果出奇地好,网络的识别效果非常棒! 但问题是——照片中的“坦克”并不是网络真正识别的内容。
因为:
-
含有坦克的照片是在阴天拍的,
-
而不含坦克的照片则是在晴天拍的。
结果,神经网络实际上学会的只是:如何分辨阴天和晴天。
虽然如今的研究人员已经意识到这种问题,并且尽量避免这种明显的失误, 但这类“更隐蔽版本”的问题仍然会发生, (我自己过去也栽过这种跟头)。
在噪声抑制的场景中,我们无法直接收集用于监督学习的输入/输出数据, 因为我们几乎不可能同时获得干净语音和对应的带噪语音。
因此,我们必须通过人工合成的方式来构建训练数据, 也就是从单独录制的干净语音和噪声中合成带噪语音。 其中最棘手的部分是:
要收集足够多样化的噪声数据来混合到语音中。
我们还必须确保训练数据能涵盖各种不同的录音条件。 例如,早期的一个版本只在全频带音频(0–20 kHz)上训练, 结果在测试时,如果音频被低通滤波到 8 kHz,模型就无法正常工作。
与语音识别中常见的做法不同,我们没有对特征应用倒谱均值归一化(Cepstral Mean Normalization,CMN), 而且我们保留了第一个倒谱系数 —— 也就是代表音频能量的那一项。
正因为如此,我们必须确保训练数据中包含各种现实中可能出现的音量水平的音频。 此外,我们还对音频应用了随机滤波,以增强系统对不同麦克风频率响应的适应能力 —— 而这类问题通常是在语音识别中通过 CMN 来处理的。
基音滤波:
由于我们所使用的频带在频率分辨率上过于粗糙,无法细致地抑制音高谐波之间的噪声, 因此我们通过基础的信号处理方法来解决这个问题。 这也体现了我们所采用的“混合式方法(hybrid approach)”的一部分。
当我们对同一个变量有多次测量时,提高精度(减少噪声)最简单的方法就是—— 取平均值。
当然,直接对相邻的音频采样点取平均显然不是我们想要的,因为那样只会导致低通滤波。 但如果信号是周期性的(比如清晰的语音),我们就可以以音高周期为间隔来取样点平均。
这样做的效果就是形成一个梳状滤波器(comb filter), 它可以保留音高谐波的位置(即周期性成分),而衰减位于其间的频率分量——这些通常就是噪声所在的频率区域。
为了不扭曲语音信号,我们对这个梳状滤波器的应用做了两点设计:
每个频带上独立应用(以减少整体失真)
滤波强度依赖于两项信息:
-
当前帧的音高相关性(pitch correlation);
-
神经网络输出的该频带的增益值(band gain)
我们目前在音高滤波中使用的是 FIR 滤波器(有限冲击响应滤波器), 但其实也可以使用 IIR 滤波器(无限冲击响应滤波器) ——这个改进目前已经被列入我们的 TODO 清单。
使用 IIR 滤波器可以在相同条件下实现更强的噪声衰减效果, 但如果滤波强度设置得过于激进,也有可能带来更大的信号失真。
FIR(Finite Impulse Response):稳定、易控制、不会引入反馈,但滤波能力相对温和;
IIR(Infinite Impulse Response):效率更高、能实现更陡的滤波器特性,但风险是容易引起过度增强或失真,尤其在参数调节不当时。
翻译参考来源:https://jmvalin.ca/demo/rnnoise/
相关文章:
rnn的音频降噪背后技术原理
rnniose: 这个演示展示了 RNNoise 项目,说明了如何将深度学习应用于噪声抑制。其核心理念是将经典的信号处理方法与深度学习结合,打造一个小巧、快速的实时噪声抑制算法。它不需要昂贵的 GPU —— 在树莓派上就能轻松运行。 相比传统的噪声抑制系统&…...

Python项目打包指南:PyInstaller与SeleniumWire的兼容性挑战及解决方案
前言 前段时间做一个内网开发的需求,要求将selenium程序打包成.exe放在内网的win7上运行,在掘金搜了一圈也没有发现相关文章,因此将过程中踩到的坑记录分享一下。 本文涵盖了具体打包操作、不同模块和依赖项的兼容性解决方案,以…...

【题解】AtCoder AT_abc400_c 2^a b^2
题目大意 我们定义满足下面条件的整数 X X X 为“好整数”: 存在一个 正整数 对 ( a , b ) (a,b) (a,b) 使得 X 2 a ⋅ b 2 X2^a\cdot b^2 X2a⋅b2。 给定一个正整数 N N N( 1 ≤ N ≤ 1 0 18 1\le N\le 10^{18} 1≤N≤1018)ÿ…...
ubuntu 配置固定ip
在装服务器系统的时候,DHCP自动获取ip时,路由可能会重新分配ip,为避免产生影响,可以关闭DHCP将主机设置为静态ip。 系统环境 Ubuntu 22.04-Desktop 配置方式 一、如果是装的Ubuntu图形化(就是可以用鼠标操作点击应用…...

基于Coze平台实现工程项目管理SaaS软件的在线化客户服务
一、引言 在数字化转型浪潮下,SaaS(软件即服务)模式已成为企业级软件的主流交付方式。然而,随着用户规模的增长,传统人工客服模式面临响应速度慢、人力成本高、知识库更新滞后等痛点。如何利用AI技术实现客户服务的智…...

vue3实现markdown工具栏的点击事件监听
这里以监听全屏事件为例 监听 Vditor 编辑器的全屏事件 要监听 Vditor 编辑器的全屏事件,你可以使用 Vditor 提供的 API 和事件系统。以下是几种实现方法: 方法一:使用 Vditor 的 after 钩子函数 const vditor new Vditor(editor, {afte…...

QT ARM开发板调试
QT 应用程序在 ARM 开发板上完全可以进行调试。以下是完整的调试方案和配置方法: 1. 调试方式概览 调试方式适用场景所需工具特点GDB 远程调试代码级调试gdbserver gdb-multiarch最强大的调试方式QT Creator 远程调试集成开发环境调试QT Creator gdbserver开发体…...
逐像素操作)
OpenCV 图形API(21)逐像素操作
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在OpenCV的G-API模块中,逐像素操作指的是对图像中的每个像素单独进行处理的操作。这些操作可以通过G-API的计算图(Graph …...

Mysql连接池报错
报错信息如下 com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failureThe last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.at com.mysql.cj.jdbc.exceptions.SQ…...

使用git clone的时候部分文件夹克隆不下来
当使用git clone命令克隆一个仓库时,有可能出现部分文件夹没有被克隆下来的情况。这种问题通常有以下几个可能的原因: 权限问题:检查一下你对该仓库的访问权限。如果你没有足够的权限,可能无法克隆某些文件夹。 仓库设置…...
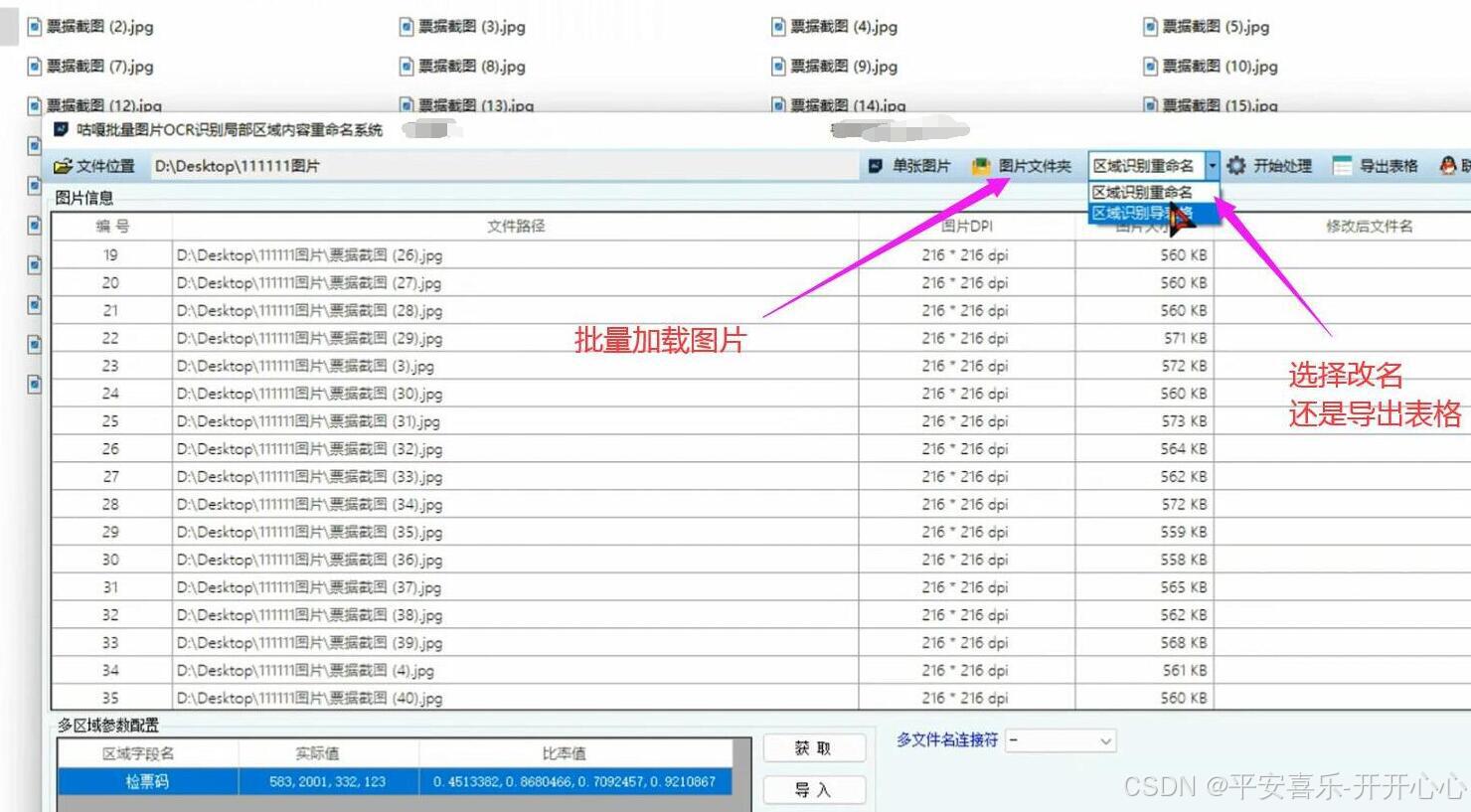
批量图片文本识别重命名,批量ocr识别图片重命名,基于WPF和腾讯OCR云部署实,现批量对图片局部提取文字后重命名的操作详细步骤
1. 项目背景 在日常工作中,我们经常需要处理大量图片文件,这些图片可能包含重要的文字信息。为了提高工作效率,我们需要一种自动化的方式,从图片中提取文字,并根据提取的文字对图片进行重命名。 本项目基于 WPF 框架开发桌面应用程序,结合 腾讯 OCR…...
Linux——冯 • 诺依曼体系结构操作系统初识
目录 1. 冯 • 诺依曼体系结构 1.1 冯•诺依曼体系结构推导 1.2 内存提高冯•诺依曼体系结构效率的方法 1.3 理解数据流动 2. 初步认识操作系统 2.1 操作系统的概念 2.2 设计OS的目的 3. 操作系统的管理精髓 1. 冯 • 诺依曼体系结构 1.1 冯•诺依曼体系结构推导 计算…...

洛谷题单3-P5724 【深基4.习5】求极差 最大跨度值 最大值和最小值的差-python-流程图重构
题目描述 给出 n n n 和 n n n 个整数 a i a_i ai,求这 n n n 个整数中的极差是什么。极差的意思是一组数中的最大值减去最小值的差。 输入格式 第一行输入一个正整数 n n n,表示整数个数。 第二行输入 n n n 个整数 a 1 , a 2 … a n a_1,…...

Vue3 实现进度条组件
样式如下,代码如下 <script setup> import { computed, defineEmits, defineProps, onMounted, ref, watch } from vue// 定义 props const props defineProps({// 初始百分比initialPercentage: {type: Number,default: 0,}, })// 定义 emits const emits…...
35.[前端开发-JavaScript基础]Day12-for循环中变量-华为商城-商品列表-轮播图
for循环中监听函数中打印变量 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"wi…...
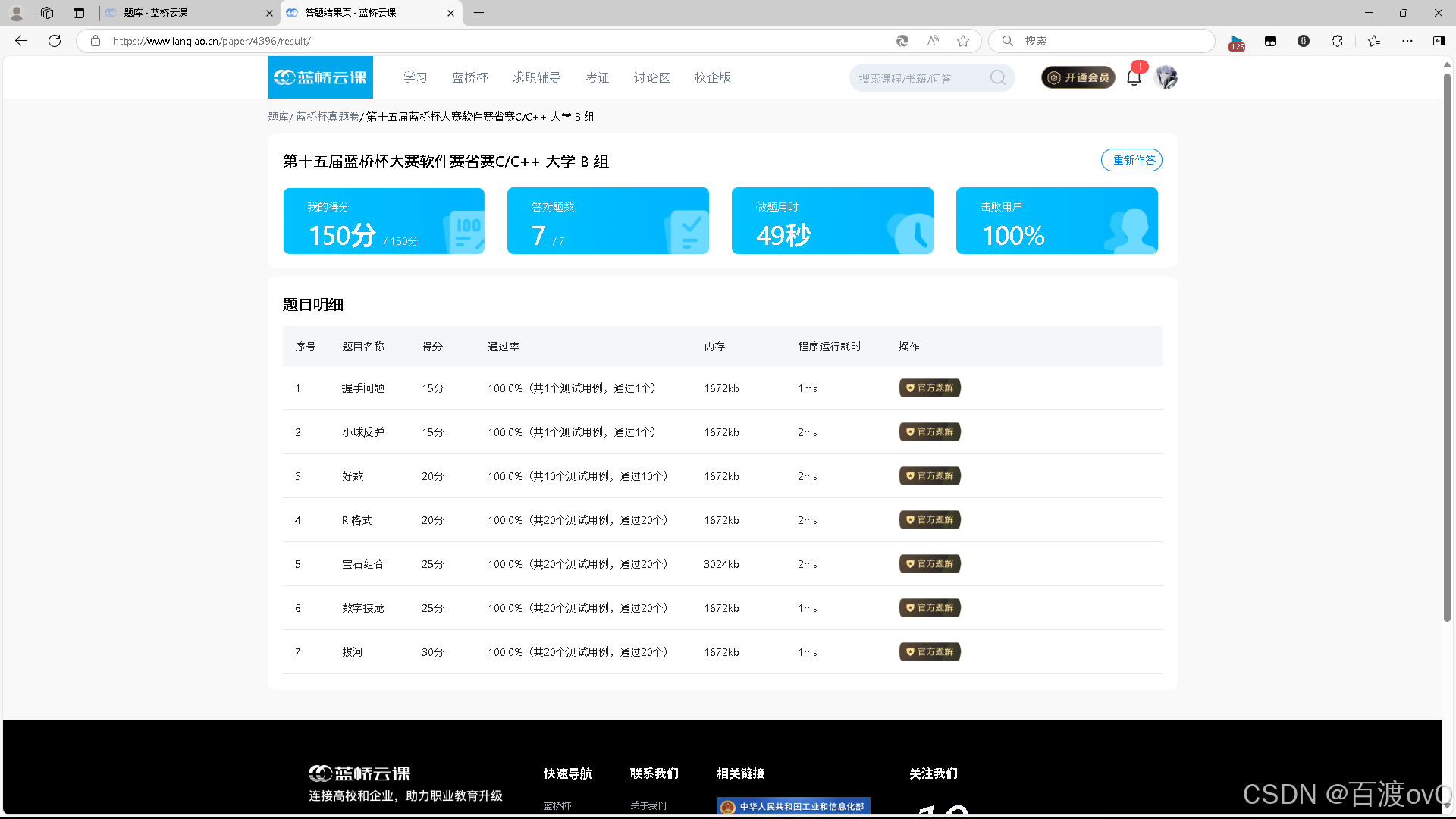
【蓝桥杯】十五届省赛B组c++
目录 前言 握手问题 分析 排列组合写法 枚举 小球反弹 分析 代码 好数 分析 代码 R 格式 分析 代码 宝石组合 分析 代码 数字接龙 分析 代码 拔河 分析 代码 总结 前言 主播这两天做了一套蓝桥杯的省赛题目(切实感受到了自己有多菜&#x…...

scala-集合2
可变数组 定义变长数组 val arr01 ArrayBuffer[Any](3, 2, 5) (1)[Any]存放任意数据类型 (2)(3, 2, 5)初始化好的三个元素 (3)ArrayBuffer 需要引入 scala.collection.mutable.ArrayBuffer 案例实操 Arra…...

[Linux系统编程]多线程
多线程 1. 线程1.1 线程的概念1.2 进程与线程对比1.3 轻量级进程 2. Linux线程控制2.1 POSIX 线程(pthread)2.2 线程ID、pthread_t、和进程地址空间的关系2.2.1 pthread_self2.2.2 pthread_create2.2.3 pthread_join2.2.4 线程终止的三种方式2.2.5 pthre…...
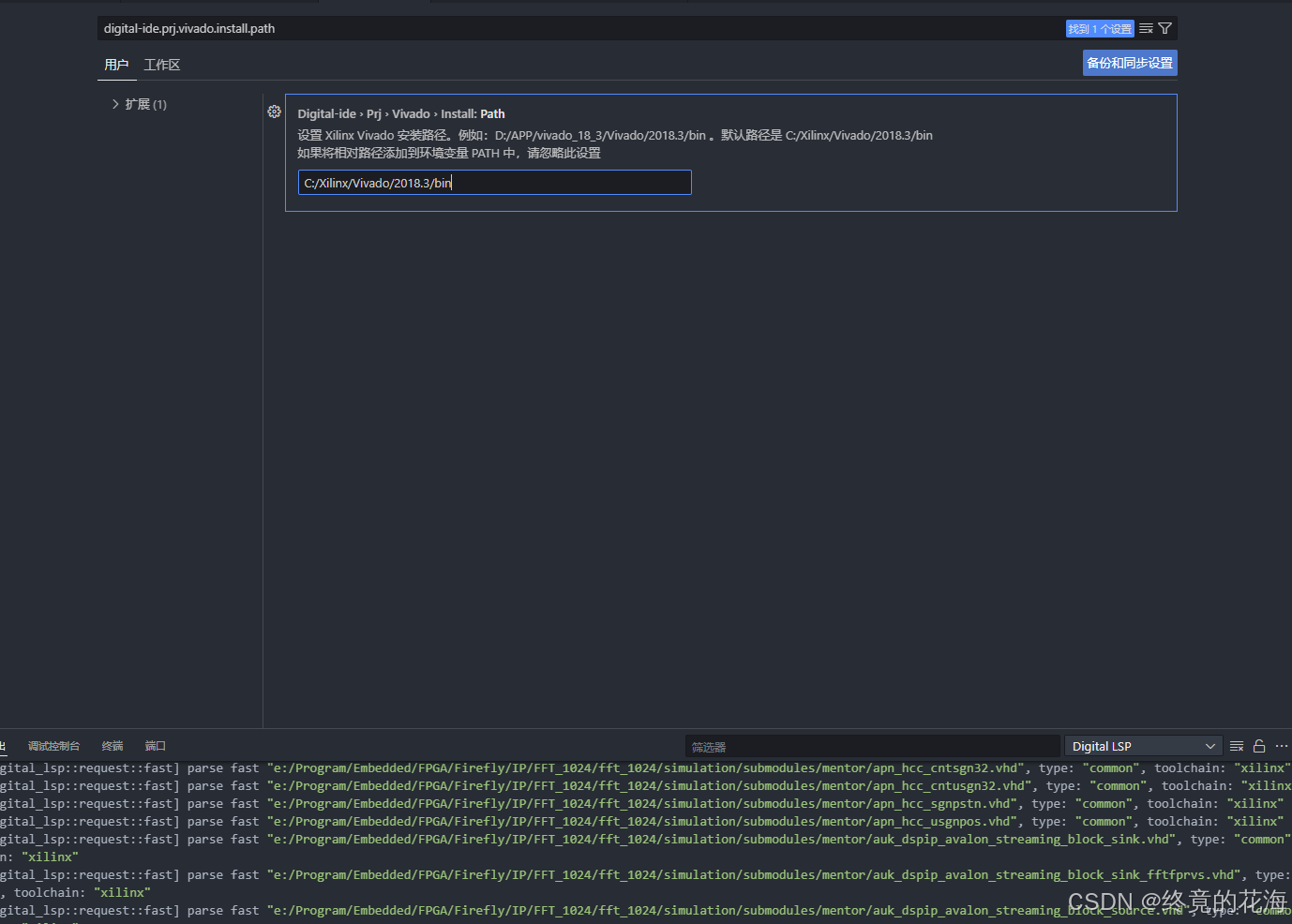
IntelliJ IDEA下开发FPGA——FPGA开发体验提升__下
前言 由于Quartus写代码比较费劲,虽然新版已经有了代码补全,但体验上还有所欠缺。于是使用VS Code开发,效果如下所示,代码样式和基本的代码补全已经可以满足开发,其余工作则交由Quartus完成 但VS Code的自带的git功能&…...
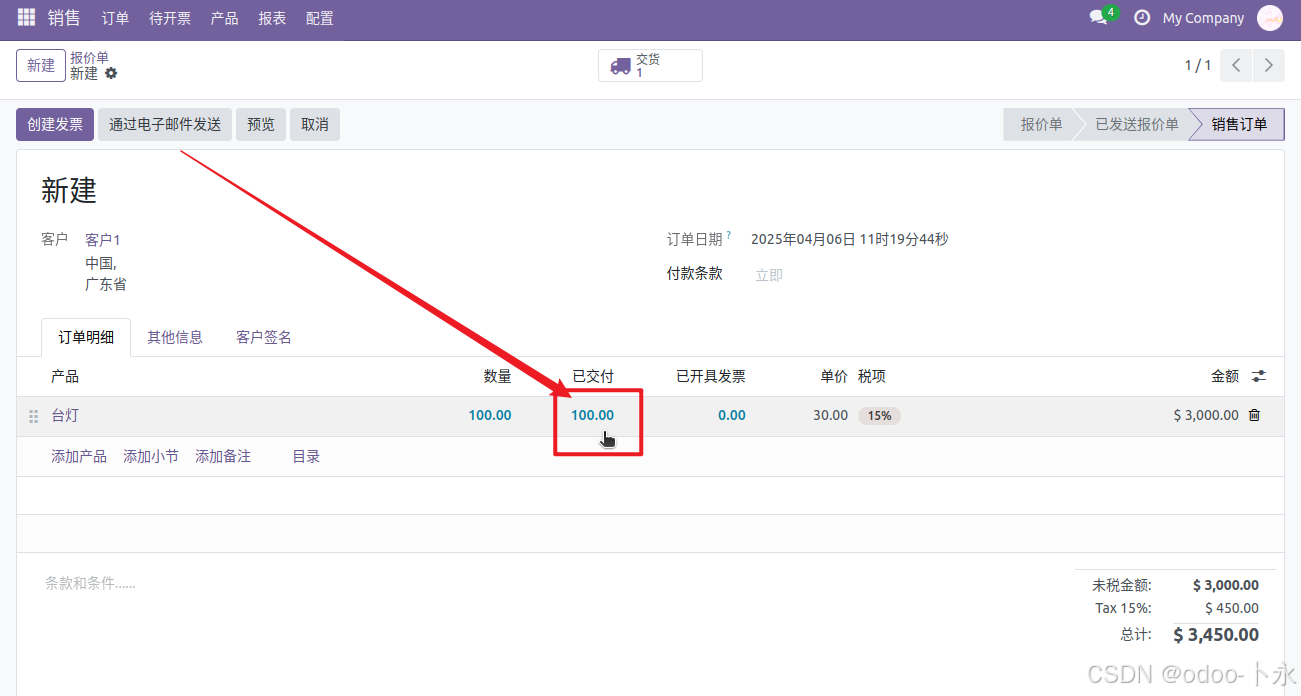
odo18实施——销售-仓库-采购-制造-制造外包-整个流程自动化单据功能的演示教程
安装模块 安装销售 、库存、采购、制造模块 2.开启外包功能 在进入制造应用点击 配置—>设置 勾选外包,点击保存 添加信息 一、添加客户信息 点击到销售应用 点击订单—>客户 点击新建 创建客户1,及其他客户相关信息,点…...
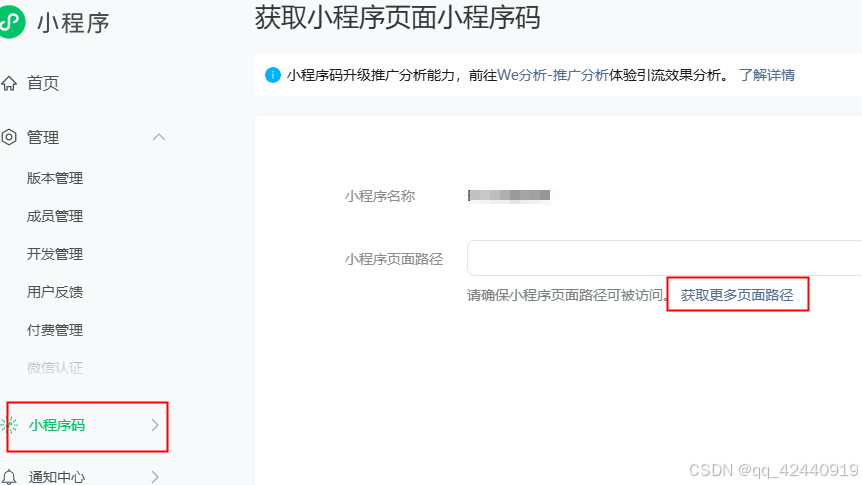
微信小程序生成某个具体页面的二维码
微信小程序,如果要生成某个具体页面,而非首页的二维码,体验和正式的生成方法如下: 1、体验版二维码: 管理---版本管理---修改页面路径,输入具体页面的路径以及参数,生成的是二维码 2、正式小程…...
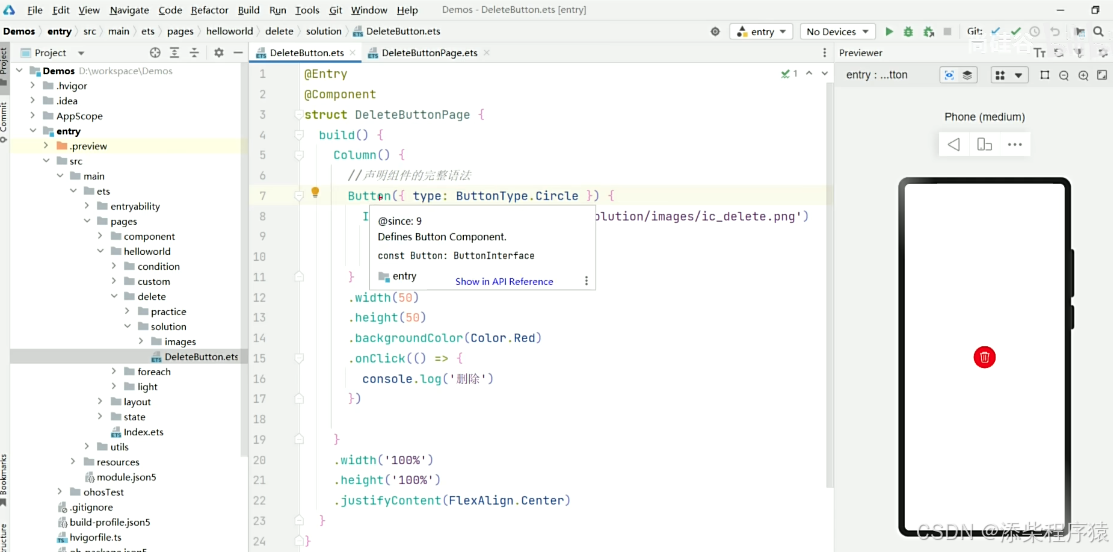
鸿蒙开发_ARKTS快速入门_语法说明_组件声明_组件手册查看---纯血鸿蒙HarmonyOS5.0工作笔记010
然后我们来看如何使用组件 可以看到组件的组成 可以看到我们使用的组件 然后看一下组件的语法.组件中可以使用子组件. 然后组件中可以有参数,来修改组件的样式等 可以看到{},这种方式可以设置组件参数,当然在下面. 的方式也可以的 然后再来...

利用解析差异SSRF + sqlite注入 + waf逻辑漏洞 -- xyctf 2025 fate WP
本文章附带TP(Thinking Process)! #!/usr/bin/env python3 # 导入所需的库 import flask # Flask web框架 import sqlite3 # SQLite数据库操作 import requests # HTTP请求库 import string # 字符串处理 import json # JSON处理app flask.Flask(__name__) # 创建Flask应…...
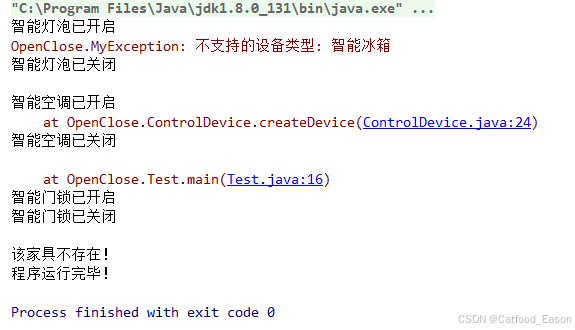
接口异常数组基础题
题目描述 设想你正在构建一个智能家居控制系统。这个系统可以连接多种不同类型的智能设备,如智能灯泡、智能空调和智能门锁。每种设备都有其独特的功能,不过它们也有一些通用的操作,像开启、关闭和获取设备状态等。系统需要提供一个方法来控…...

rustdesk折腾手记
背景 我的工作环境:主力电脑是macPro, 另外一台ThinkPad W530作为开发机,装的是LinuxMint,还有一台ThinkPad P15作为服务器。平常显示器接到macPro,在macOS上通过微软的远程桌面连接到另外两台Linux。基本访问比较流畅࿰…...
使用el-tab 实现两个tab切换
1、主页面 index.vue 2、tab1:school.vue 3、tab2:parent.vue 具体代码如下: <template><div class"app-container"><!-- 使用el-tabs 实现两个组件的切换 --><el-tabs v-model"activeName" typ…...
的使用)
JAVA--流(Stream)的使用
一、概念 JDK8新特性,简单方便的对集合和数组进行处理。 Stream(流)是一个来自数据源的元素队列 数据源:流的来源,指的是集合或数组 元素队列:元素是特定类型的对象,形成一个队列 Stream 并…...

使用ExcelJS实现专业级医疗数据导出功能:从数据到Excel报表的完整指南
在现代医疗信息系统中,数据导出是医护人员和行政人员日常工作中的重要需求。本文将详细介绍如何使用ExcelJS库在前端实现专业级的医疗数据导出功能,特别是针对住院缴费记录这类关键业务数据。 功能概述 这个exportExcel函数实现了以下核心功能…...

使用Pholcus编写Go爬虫示例
想用Pholcus库来写一个Go的爬虫程序。首先,我得确认Pholcus的当前状态,因为之前听说过它可能已经不再维护了。不过用户可能还是需要基于这个库的示例,所以得先提供一个基本的框架。 首先,我应该回忆一下Pholcus的基本用法。Pholc…...

深入解析大型应用架构:以dify为例进行分析
原文:https://juejin.cn/post/7437015214351286309 Dify 是一款开源的大语言模型(LLM)应用开发平台,旨在简化和加速生成式 AI 应用的创建和部署。 它融合了后端即服务(Backend as a Service, BaaS)和 LLM…...